实验3:卷积神经网络
| 姓名和学号? | |
|---|---|
| 本实验属于哪门课程? | 中国海洋大学25秋《软件工程原理与实践》 |
| 实验名称? | 实验3:卷积神经网络 |
| 博客链接: | 选做 |
学习要求
- CNN的基本结构:卷积、池化、全连接
- 典型的⽹络结构:AlexNet、VGG、GoogleNet、ResNet
实验内容
【第⼀部分:代码练习】
实验3:MNIST数据集分类
实验过程:

实验4:CIFAR10 数据集分类
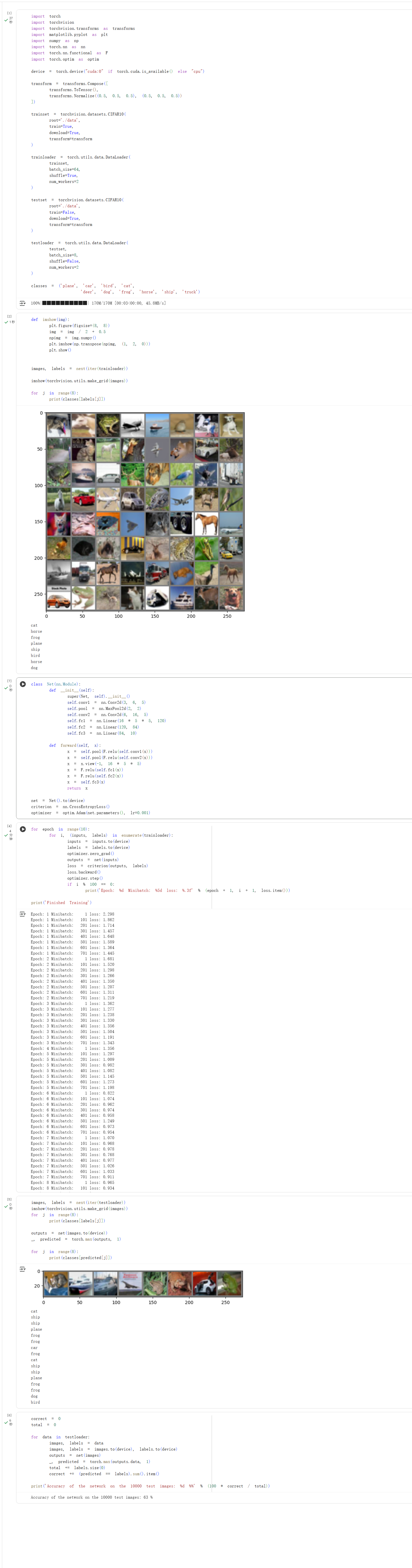
实验5:VGG16对CIFAR10分类

问题总结
【第⼆部分:问题总结】思考下⾯的问题:
dataloader ⾥⾯ shuffle 取不同值有什么区别?
- 在模型训练阶段,通常会对数据集进行顺序打乱(即设置 shuffle = True)。这种做法有助于避免样本原有的排列顺序对模型训练造成干扰,从而提升训练过程的稳定性与泛化能力。
- 而在模型测试或验证阶段,一般会保持数据的原始顺序(即设置 shuffle = False),因为此时的目标是在一个固定的数据子集上评估模型性能,数据的先后顺序不会对评估结果产生影响。
transform ⾥,取了不同值,这个有什么区别?
transform 是数据预处理和增强的关键环节,在本实验中主要应用了以下几种操作:ToTensor、Normalize、RandomCrop 以及 RandomHorizontalFlip。
ToTensor 的作用是将图像数据转换为 PyTorch 框架可处理的 Tensor 格式,同时将原始像素值从 [0, 255] 的范围线性映射到 [0.0, 1.0] 的区间内。
Normalize 即数据标准化,通过对输入数据进行中心化和缩放,使其分布更为集中和稳定,从而有助于提升模型训练的收敛速度与训练过程的稳定性。
RandomCrop 是一种数据增强技术,通过对图像进行随机区域裁剪,可以模拟不同视角下的图像输入,进而提升模型对于物体位置变化的鲁棒性,增强其泛化能力。
RandomHorizontalFlip 同样是常用的数据增强方法,它以一定概率对图像进行水平方向的随机翻转,这有助于增加训练样本的多样性,使模型能够学习到更具不变性的特征表示
epoch 和 batch 的区别?
在训练过程中,epoch 是轮"轮次" 指模型完整遍历一次整个训练集的周期。batch 是批,为了高效处理海量数据,每个轮次的数据会被划分为多个"批次"。模型每学习完一个批次的数据,就会执行一次参数更新,通过这种小步快跑的方式逐步优化。
1x1的卷积和 FC 有什么区别?主要起什么作⽤?
全连接层在处理特征图时,会将其展平为一维向量,这不仅丢失了特征图原有的空间结构信息,还会因与每个神经元相连而产生巨大的参数量。相比之下,1x1卷积通过在空间维度上进行点式卷积,能实现跨通道的信息整合与维度变换。这种方式不仅显著减少了参数,更重要的是,它完整保留了特征图的空间结构,使得特征处理更加高效。
residual leanring 为什么能够提升准确率?
随着网络深度增加,梯度在反向传播过程中可能会逐渐变小甚至消失,这使得靠近输入端的浅层网络参数难以得到有效的梯度更新,从而导致模型训练困难。残差学习机制通过引入“快捷连接”巧妙地解决了这一问题。它不再要求网络层直接学习一个完整的目标输出,而是转而学习输出与输入之间的残差(即变化量)。这种将学习目标从“完整映射”简化为“残差映射”的做法,极大地降低了优化难度。即使某个残差块未能学到有效特征(残差趋近于零),其输出也至少等于输入,保证了网络性能不会发生退化,从而为构建更深的模型奠定了基础。
代码练习⼆⾥,⽹络和1989年 Lecun 提出的 LeNet 有什么区别?
代码所构建的网络是一个经过改良的LeNet变体。其核心改进在于:激活函数部分,用ReLU替代了传统的S型函数,利用其稀疏激活性和梯度特性,有效抑制了梯度消失,加快了模型收敛;输出层部分,则采用了现今主流的“全连接层 + LogSoftmax”结构,替代了LeNet最初设计中的高斯连接层,这使得网络能够直接输出归一化的对数概率,与负对数似然损失函数完美配合,优化了训练过程。
代码练习⼆⾥,卷积以后feature map 尺⼨会变⼩,如何应⽤ Residual Learning?
为了确保快捷路径上的数据与主路径输出能够进行逐元素相加,需要对其维度和尺寸进行匹配。具体通过三种方式实现:
- 采用1x1卷积来调整通道数,使其与主路径输出的通道维度一致;
- 其次,在卷积操作中应用填充(Padding),以避免特征图尺寸在卷积过程中被缩小;
- 最后,通过步长(Stride)设置为1的池化层来逐步降低特征图的空间尺寸(如高和宽),从而完成尺寸对齐。
有什么⽅法可以进⼀步提升准确率?
- 在模型结构方面,通过增加网络的深度来增强其表征复杂模式的能力。
- 延长了训练周期(Epoch数)
- 采用了更先进的优化器
- 应用了更多样化的数据增强技术,通过增加训练数据的多样性来有效提升模型的泛化能力。
体会
遇到的问题及解决方法
在做实验5:使用VGG对CIFAR10分类的时候,在全连接层的前向传播过程中,我发现出现了一个矩阵形状不匹配的错误。如下图所示:
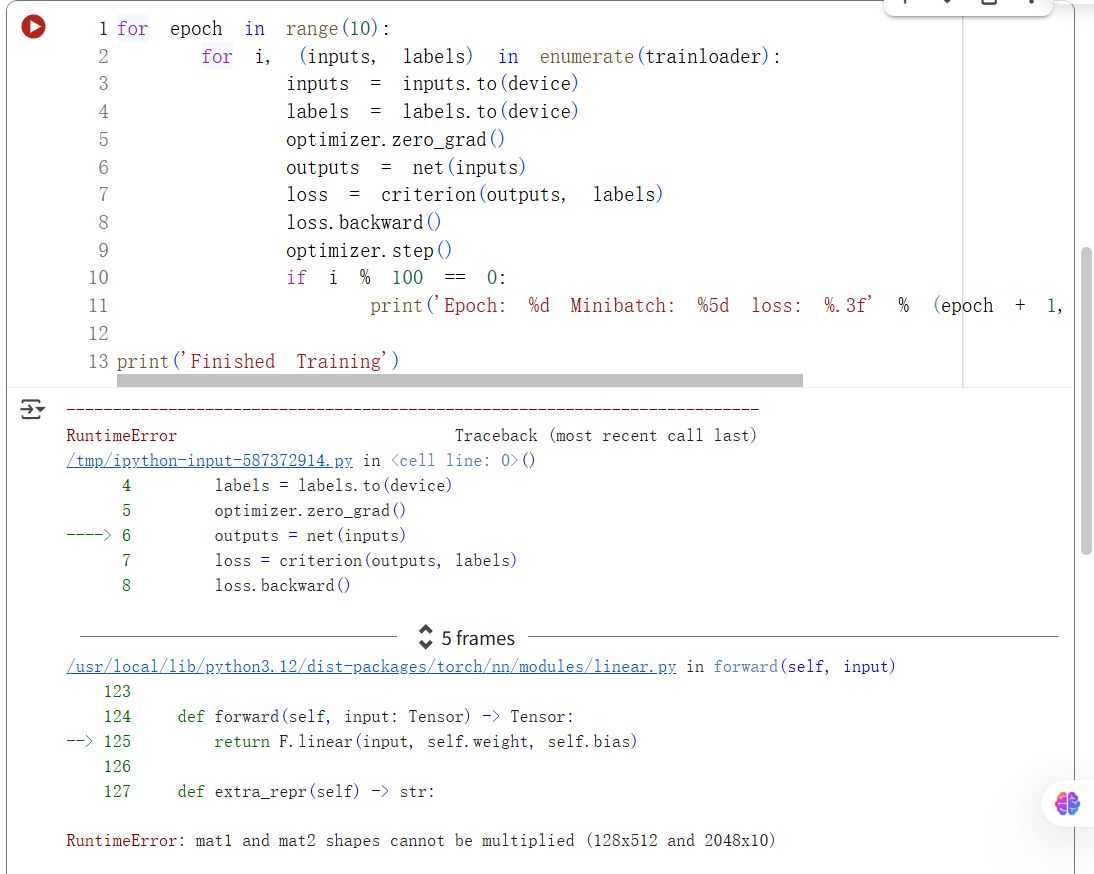
我发现是矩阵形状不匹配的问题。
所以我将VGG网络中欧冠的全连接层修改为``self.classifier = nn.Linear(512, 10)`,这样特征图经过卷积和池化层后的输出形状是512,与全连接层的输入尺寸匹配,就可以正常训练了。
心得体会
在本次实验中我体会到了理论与实践结合的重要性,我们需要通过实际编码和调试才能理解深度学习框架的使用技巧和建立对模型性能的直观感受。