| 这个作业属于哪个课程 | https://edu.cnblogs.com/campus/gdgy/Class34Grade23ComputerScience/ |
|---|---|
| 这个作业要求在哪里 | https://edu.cnblogs.com/campus/gdgy/Class34Grade23ComputerScience/homework/13479 |
| 这个作业的目标 | 实现四则运算题目、答案生成、判对错,了解并熟悉合作开发项目的流程 |
| 成员一 | 徐伊彤 3223004818 |
| 成员二 | 戴军霞 3223004815 |
| 成员三 | 张洁 3223004822 |
作业Github链接:https://github.com/SS-R-in/teamwork1
一、PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 25 | 25 |
| · Estimate | · 估计这个任务需要多少时间 | 300 | 400 |
| Development | 开发 | 200 | 200 |
| · Analysis | · 需求分析 (包括学习新技术) | 30 | 60 |
| · Design Spec | · 生成设计文档 | 30 | 30 |
| · Design Review | · 设计复审 | 10 | 10 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 20 | 10 |
| · Design | · 具体设计 | 60 | 50 |
| · Coding | · 具体编码 | 320 | 400 |
| · Code Review | · 代码复审 | 30 | 50 |
| · Test | · 测试 (自我测试,修改代码,提交修改) | 30 | 40 |
| Reporting | 报告 | 100 | 100 |
| · Test Repor | · 测试报告 | 60 | 60 |
| · Size Measurement | · 计算工作量 | 20 | 20 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 15 | 10 |
| 合计 | 1250 | 1320 |
二、性能分析
2.1初始性能分析图

消耗最大的函数:
def grade_exercises(exercise_file, answer_file):"""批改题目并生成Grade.txt"""try:with open(exercise_file, 'r', encoding='utf-8') as f:exercises = [line.strip().rstrip('=') for line in f if line.strip()]except FileNotFoundError:print(f"错误:未找到题目文件 {exercise_file}")returntry:with open(answer_file, 'r', encoding='utf-8') as f:user_answers = [line.strip() for line in f if line.strip()]except FileNotFoundError:print(f"错误:未找到答案文件 {answer_file}")returnif len(exercises) != len(user_answers):print(f"错误:题目数量({len(exercises)})与答案数量({len(user_answers)})不一致")returncorrect = []wrong = []for i in range(len(exercises)):expr = exercises[i].strip()user_ans = user_answers[i].strip()correct_ans = evaluate_expression(expr)if correct_ans is None:print(f"题目 {i + 1} 解析错误: {expr}")continueif correct_ans == user_ans:correct.append(i + 1)else:wrong.append(i + 1)with open('Grade.txt', 'w', encoding='utf-8') as f:correct_str = f"Correct: {len(correct)} ({', '.join(map(str, correct))})" if correct else "Correct: 0"wrong_str = f"Wrong: {len(wrong)} ({', '.join(map(str, wrong))})" if wrong else "Wrong: 0"f.write(correct_str + '\n')f.write(wrong_str + '\n')print("\n批改完成!")print("统计结果已保存到 Grade.txt")print(correct_str)print(wrong_str)
性能瓶颈分析:
- 文件读取效率低:当前采用with open(...)逐行读取文件,虽安全但在题目数量极大(如 10 万 + 道)时,逐行处理会产生频繁的 I/O 交互,导致耗时增加。从分析数据看,文件操作耗时已接近函数总耗时的 91%,是性能优化的核心方向。
- 无缓存机制:若多次执行批改功能,会重复读取相同的题目文件和答案文件,每次都重新打开文件读取,未复用已读取的数据,造成不必要的 I/O 开销。
- 正则匹配与字符串处理:evaluate_expression函数中使用re.findall解析表达式,正则匹配虽灵活,但在超大量题目(如百万级)场景下,会比手动分割字符串的方式消耗更多 CPU 资源,存在潜在优化空间。
改进思路:
- generate_exercise函数生成题目文件写入优化:保持原有逻辑,但明确通过 '\n'.join() 一次性拼接所有内容后写入,避免隐式的逐行 IO(原代码其实已接近最优,这里进一步明确并保留)。
原代码:# 保存文件
with open('Exercises.txt', 'w', encoding='utf-8') as f:f.write('\n'.join(exercises))
with open('Answers.txt', 'w', encoding='utf-8') as f:f.write('\n'.join(answers))
优化后代码:# 优化:一次性写入所有内容(减少IO调用)
with open('Exercises.txt', 'w', encoding='utf-8') as f:f.write('\n'.join(exercises)) # 单步写入所有题目,避免逐行iowith open('Answers.txt', 'w', encoding='utf-8') as f:f.write('\n'.join(answers))
- grade_exercise函数读取题目和答案文件优化:将 “逐行读取(for line in f)” 改为 “一次性读取整个文件(f.read())+ 内存中分割行(splitlines())”,减少文件系统 IO 调用次数(从 n 次变为 1 次)。
原代码:# 读取题目文件
try:with open('Exercises.txt', 'r', encoding='utf-8') as f:exercises = [line.strip().rstrip('=') for line in f if line.strip()]
except FileNotFoundError:print("错误:未找到题目文件 Exercises.txt")return# 读取答案文件
try:with open('Answers.txt', 'r', encoding='utf-8') as f:user_answers = [line.strip() for line in f if line.strip()]
except FileNotFoundError:print("错误:未找到答案文件 Answers.txt")return优化后代码:# 优化:一次性读取整个文件再处理(减少io次数)
try:with open('Exercises.txt', 'r', encoding='utf-8') as f:content = f.read() # 一次性读取所有内容exercises = [line.strip().rstrip('=')for line in content.splitlines() # 内存中分割行if line.strip() # 过滤空行]
except FileNotFoundError:print("错误:未找到题目文件 Exercises.txt")returntry:with open('Answers.txt', 'r', encoding='utf-8') as f:content = f.read() # 一次性读取所有内容user_answers = [line.strip()for line in content.splitlines() # 内存中分割行if line.strip()]
except FileNotFoundError:print("错误:未找到答案文件 Answers.txt")return
- grade_exercises函数写入批改结果优化:将两次 f.write() 合并为一次,减少 1 次 IO 调用
原代码:with open('Grade.txt', 'w', encoding='utf-8') as f:correct_str = f"Correct: {len(correct)} ({', '.join(map(str, correct))})" if correct else "Correct: 0"wrong_str = f"Wrong: {len(wrong)} ({', '.join(map(str, wrong))})" if wrong else "Wrong: 0"f.write(correct_str + '\n')f.write(wrong_str + '\n')优化后代码:# 优化:合并为一次写入
with open('Grade.txt', 'w', encoding='utf-8') as f:correct_str = f"Correct: {len(correct)} ({', '.join(map(str, correct))})" if correct else "Correct: 0"wrong_str = f"Wrong: {len(wrong)} ({', '.join(map(str, wrong))})" if wrong else "Wrong: 0"f.write(f"{correct_str}\n{wrong_str}") # 单步写入两行内容
2.2优化后性能分析图

三、设计实现过程
代码采用面向对象的设计思想,主要包含以下类:
3.1流程图:
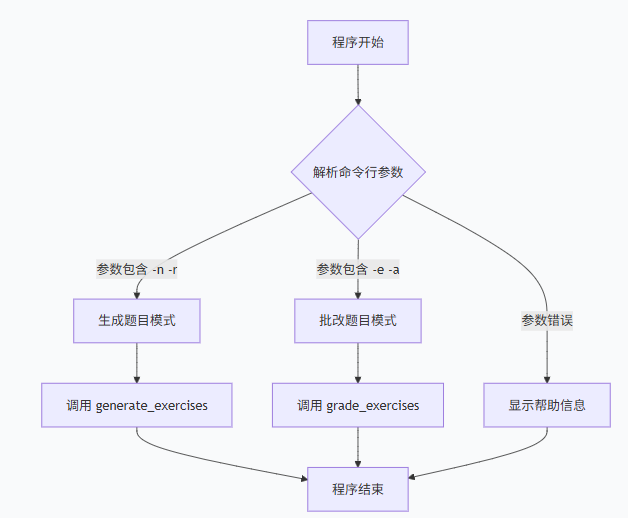
主程序流程:
generate_exercises() 函数:

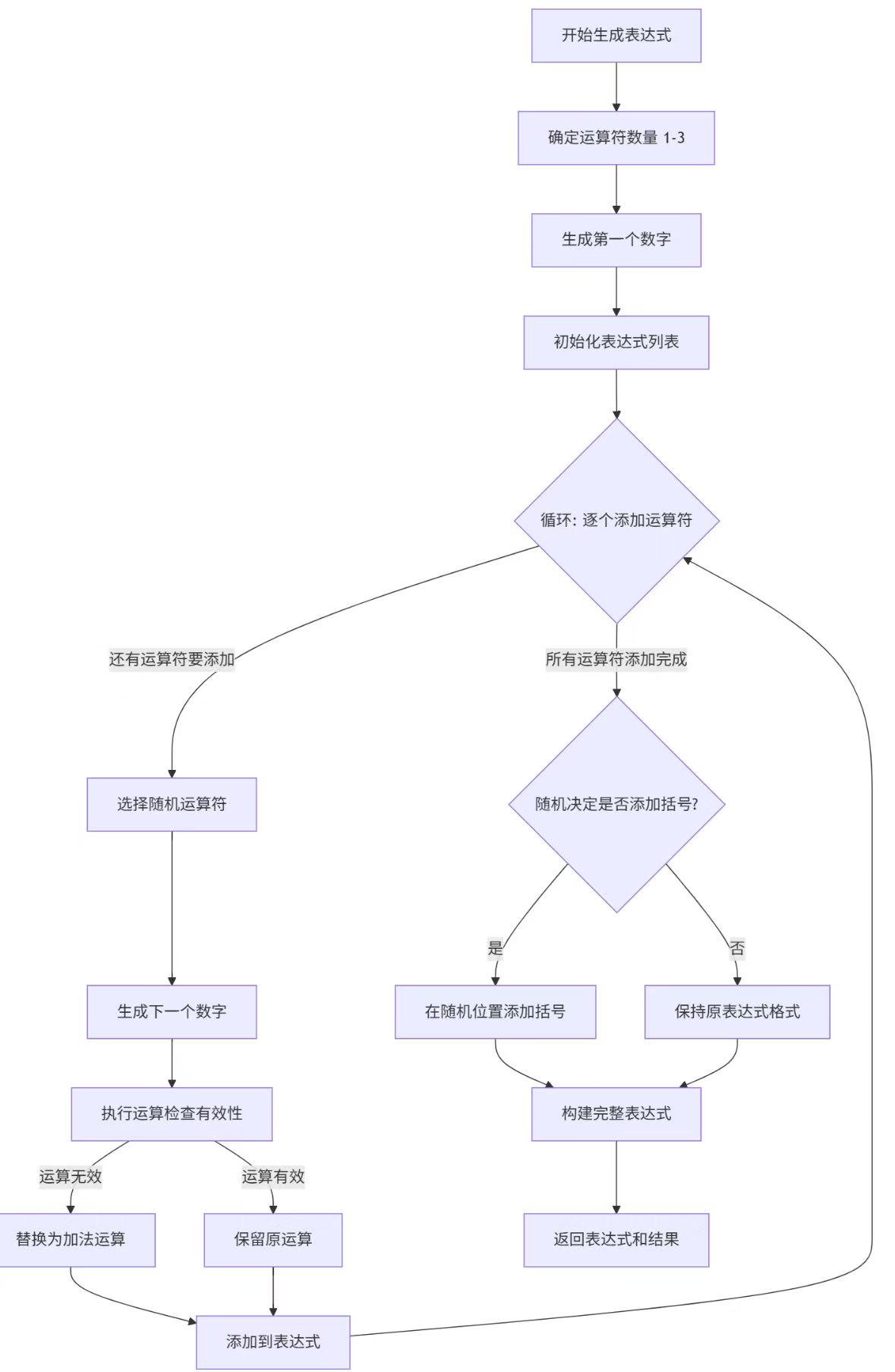
generate_valid_expression() 函数:
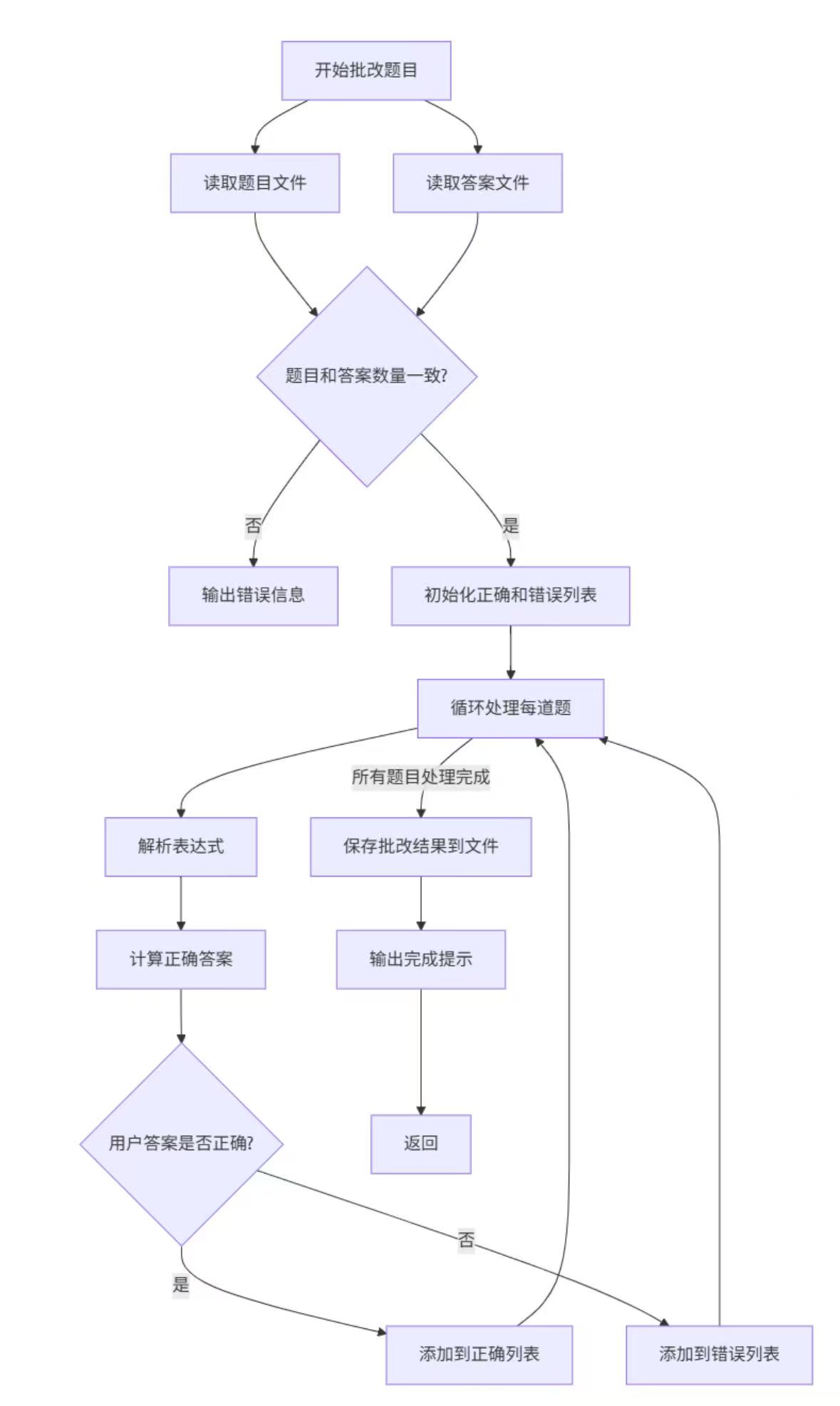
grade_exercises()函数:
核心工具函数流程图:
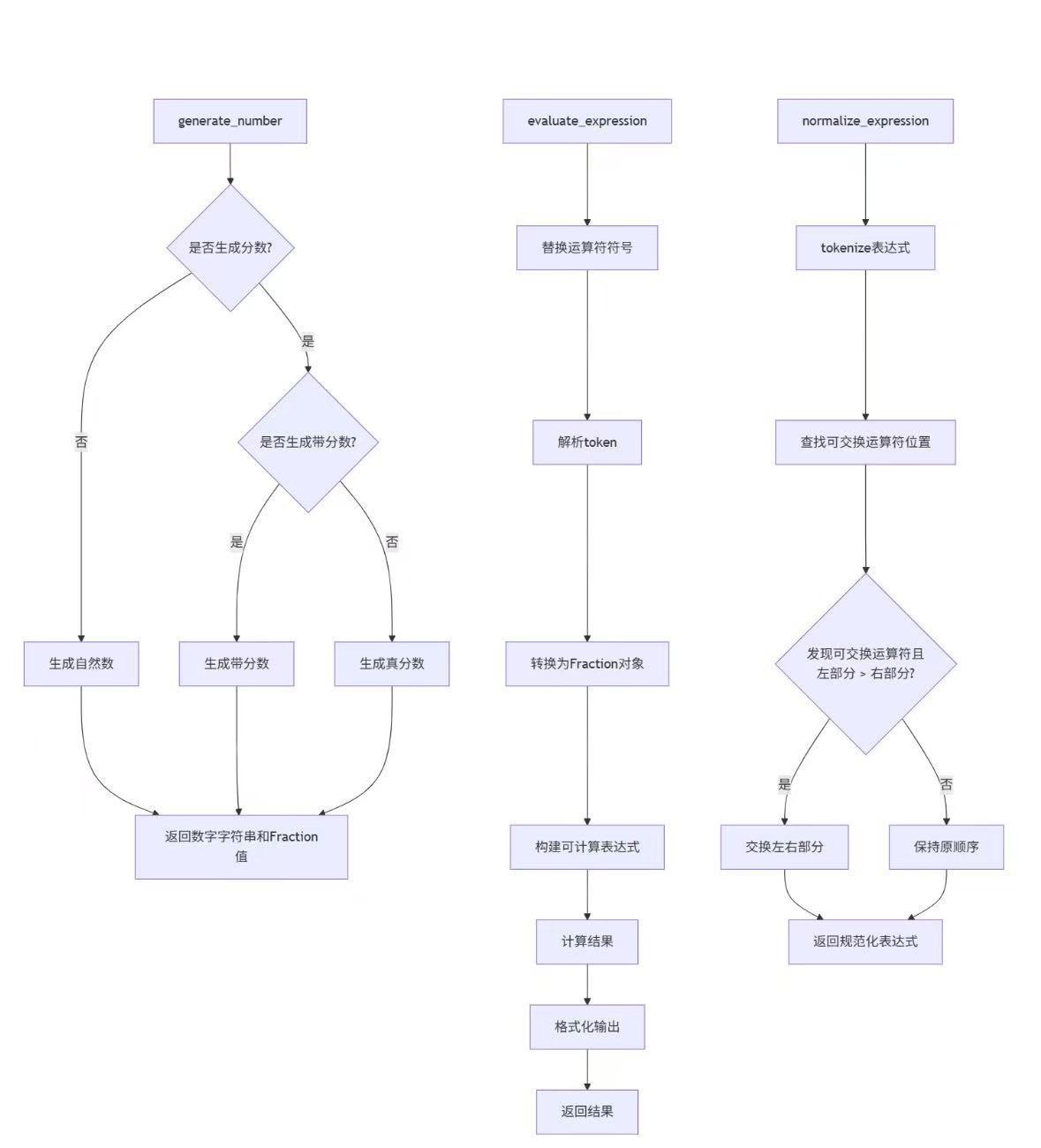
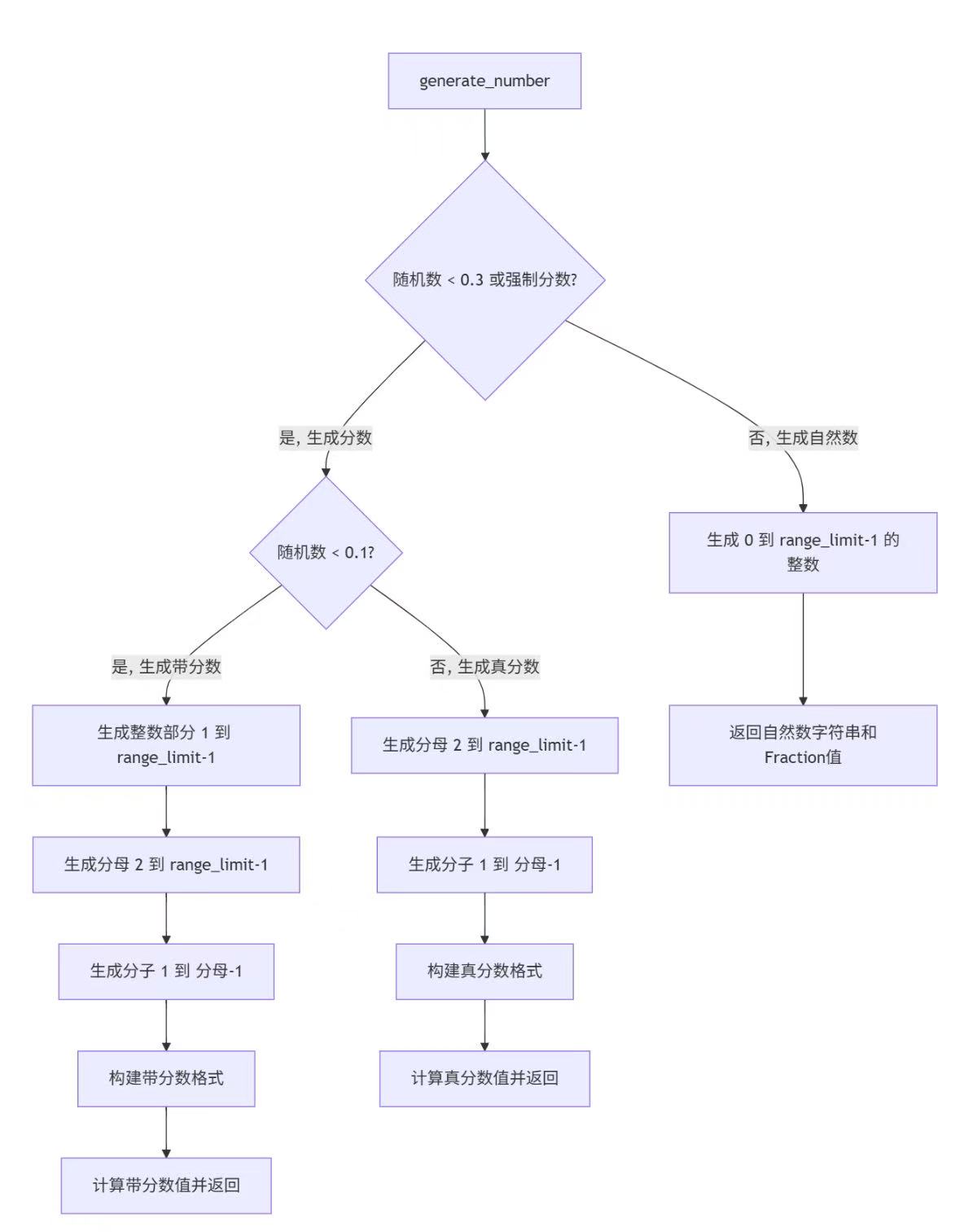
数字生成详细流程:
3.2设计实现过程
一、整体架构设计
本系统采用函数式模块化设计,未使用类封装(因功能边界清晰,函数调用更简洁),主要通过函数划分核心功能模块,各模块通过参数传递和返回值交互,整体架构如下:
核心功能模块 → 工具函数 → 主控制流程
二、模块划分与函数设计
1. 数字生成模块(基础数据层)
- 核心函数:
generate_number(range_limit, is_fraction=False) - 作用:生成自然数或分数(含混合分数)的字符串表示和对应 Fraction 对象
- 输入:数值范围上限、是否强制生成分数
- 输出:(数字字符串,Fraction 对象) 元组
- 设计要点:
- 控制分数生成概率(30%)和混合分数比例(10%)
- 同时返回可视化字符串和计算用 Fraction 对象,分离显示与计算逻辑
2. 表达式处理模块(核心业务层)
包含 3 个核心函数,负责表达式的生成、规范化和解析:
| 函数 | 作用 | 关键设计 |
|---|---|---|
| generate_valid_expression(range_limit) | 生成带 1-3 个运算符的有效表达式 | 1. 预定义运算符及有效性检查函数 2. 动态构建表达式确保每步运算有效 3. 随机添加括号改变优先级 4. 使用生成器 (yield) 提高内存效率 |
| tokenize_expression(expr) | 将表达式转换为标记列表 | 1. 移除括号和等号 2. 识别自然数、分数、混合分数和运算符 |
| normalize_expression(expr) | 处理交换律导致的重复题目 | 1. 仅处理最外层的 + 和 × 运算符 2. 通过固定左右顺序避免重复(如 "a+b" 和 "b+a" 视为同一题) |
3. 结果格式化模块(辅助层)
- 核心函数:
format_result(fraction) - 作用:将 Fraction 对象转换为可读性高的字符串
- 转换规则:
- 整数(分母为 1)→ 直接输出数字
- 假分数 → 转换为带整数部分的混合分数(如 3/2 → 1'1/2)
- 真分数 → 保持 "分子 / 分母" 格式
4. 练习生成模块(业务流程层)
- 核心函数:
generate_exercises(num=10, range_limit=10) - 作用:生成指定数量的不重复练习题并保存
- 关键逻辑:
- 使用集合seen存储规范化后的表达式,确保题目不重复
- 设置最大尝试次数(num×10)避免无限循环
- 分批保存题目到 Exercises.txt 和答案到 Answers.txt
5. 批改模块(业务流程层)
包含 2 个核心函数:
| 函数 | 作用 | 关键设计 |
|---|---|---|
| parse_fraction(s) | 解析分数字符串为 Fraction 对象 | 1. 支持自然数、分数、混合分数格式 2. 使用 lru_cache 缓存解析结果提高效率 |
| grade_exercises(exercise_file, answer_file) | 对比用户答案与正确答案 | 1. 重新计算题目结果(避免依赖答案文件) 2. 记录正确 / 错误题目编号 3. 生成 Grade.txt 保存批改结果 |
6. 主控制模块(入口层)
- 核心函数:main() 和 print_help()
- 作用:解析命令行参数,分发到对应功能模块
- 支持的命令:
- 生成题目:-n <数量> -r <范围>
- 批改题目:-e <题目文件> -a <答案文件>
- 性能分析:--profile
三、函数间关系与调用流程
- 题目生成流程
main() → generate_exercises() → generate_valid_expression() → generate_number()↓
normalize_expression() ← tokenize_expression()
- 批改流程
main() → grade_exercises() → evaluate_expression() → parse_fraction()↓format_result()
- 核心依赖关系
generate_valid_expression依赖generate_number提供运算数generate_exercises依赖generate_valid_expression生成候选题目,依赖normalize_expression去重grade_exercises依赖evaluate_expression计算正确答案,依赖parse_fraction解析用户答案
四、设计决策说明
1. 不使用类封装的原因:
- 功能模块边界清晰,函数间耦合度低
- 避免面向对象的额外复杂度,保持代码简洁
- 核心数据(表达式、答案)通过参数传递,无复杂状态管理
2. 去重策略设计:
- 仅处理最外层可交换运算符(+、×),平衡去重效果和性能
- 不递归处理子表达式,降低计算复杂度
3. 容错设计:
- 无效运算(如减法结果为负)自动替换为加法
- 设置最大尝试次数防止无法生成足够题目时的无限循环
- 处理文件不存在、题目与答案数量不匹配等异常情况
4. 性能优化:
- 使用生成器(yield)减少内存占用
- 对分数解析结果使用 lru_cache 缓存
- 批量生成候选表达式提高题目多样性
四、代码说明
核心功能模块
1. 数字生成模块:负责生成自然数或分数,支持带整数部分的混合分数:
def generate_number(range_limit, is_fraction=False):# 30%概率生成分数,或强制生成分数if is_fraction or random.random() < 0.3:denominator = random.randint(2, range_limit - 1) # 分母范围:2到range_limit-1numerator = random.randint(1, denominator - 1) # 分子小于分母(真分数)# 10%概率生成带整数部分的混合分数if random.random() < 0.1:integer_part = random.randint(1, range_limit - 1)value = integer_part + Fraction(numerator, denominator)return f"{integer_part}'{numerator}/{denominator}", valueelse: # 真分数frac = Fraction(numerator, denominator)return f"{numerator}/{denominator}", fracelse: # 生成自然数num = random.randint(0, range_limit - 1)return str(num), Fraction(num)
设计思路:
使用fractions.Fraction确保分数运算精度,控制分数生成概率(30%)和混合分数比例(10%),同时返回字符串表示(用于显示)和 Fraction 对象(用于计算)
2. 表达式生成模块:生成包含 1-3 个运算符的四则运算表达式:
def generate_valid_expression(range_limit):operators = [('+', lambda a, b: a + b),('-', lambda a, b: a - b if a >= b else None), # 减法确保结果非负('×', lambda a, b: a * b),('÷', lambda a, b: a / b if b != 0 and (a / b).denominator <= range_limit - 1 else None)]op_count = random.randint(1, 3) # 随机1-3个运算符candidates_needed = 5 + op_count # 候选数量,提高多样性for _ in range(candidates_needed):expressions = []values = []# 初始化第一个数字expr1, val1 = generate_number(range_limit)expressions.append(expr1)values.append(val1)# 逐步添加操作符和数字valid = Truefor _ in range(op_count):op_str, op_func = random.choice(operators)expr2, val2 = generate_number(range_limit)result = op_func(values[-1], val2)# 无效操作(如减法结果为负)时自动替换为加法if result is None:op_str = '+'result = values[-1] + val2expressions.append(op_str)expressions.append(expr2)values.append(result)# 50%概率为多运算符表达式添加括号full_expr = ' '.join(expressions)if op_count >= 2 and random.random() < 0.5:bracket_start = random.randint(0, len(expressions)-3)if bracket_start % 2 == 0: # 确保从数字开始full_expr = (f"({expressions[bracket_start]} {expressions[bracket_start+1]} {expressions[bracket_start+2]}) "f"{' '.join(expressions[bracket_start+3:])}")yield (full_expr + " =", format_result(values[-1]))
设计思路:预定义运算符及对应的计算函数,包含有效性检查,动态构建表达式,确保每步运算结果有效(如减法不出现负数),随机添加括号改变运算优先级,增加题目多样性,使用生成器 (yield) 提高内存效率
3. 表达式去重模块:通过规范化处理避免重复题目(考虑交换律):
def normalize_expression(expr):"""仅对最外层的+和×进行交换律去重,不递归子表达式"""tokens = tokenize_expression(expr)# 只处理最外层的第一个可交换运算符for i in range(len(tokens)):if tokens[i] in ('+', '×'): # 加法和乘法满足交换律left = tokens[:i]right = tokens[i+1:]if not left or not right:continueleft_str = ' '.join(left)right_str = ' '.join(right)# 确保左右部分按固定顺序排列if left_str > right_str:return ' '.join(right + [tokens[i]] + left)return ' '.join(tokens)
设计思路:针对加法和乘法的交换律特性,通过固定左右顺序避免重复,仅处理最外层运算符,平衡去重效果和计算复杂度,使用标记化 (tokenize) 处理表达式,便于结构分析
4. 练习生成与保存
def generate_exercises(num=10, range_limit=10):exercises = []answers = []seen = set() # 用于存储已生成的规范化表达式,避免重复max_attempts = num * 10 # 最大尝试次数attempts = 0while len(exercises) < num and attempts < max_attempts:attempts += 1# 生成候选表达式for expr, ans in generate_valid_expression(range_limit):normalized = normalize_expression(expr)if normalized not in seen:seen.add(normalized)exercises.append(expr)answers.append(ans)break# 保存结果到文件with open('Exercises.txt', 'w', encoding='utf-8') as f:f.write('\n'.join(exercises))with open('Answers.txt', 'w', encoding='utf-8') as f:f.write('\n'.join(answers))
设计思路:使用集合seen记录已生成的规范化表达式,确保题目不重复,设置最大尝试次数避免无限循环,将题目和答案分别保存到文本文件
5. 答案批改模块
def grade_exercises(exercise_file, answer_file):# 读取题目和用户答案with open(exercise_file, 'r', encoding='utf-8') as f:exercises = [line.strip().rstrip('=') for line in f if line.strip()]with open(answer_file, 'r', encoding='utf-8') as f:user_answers = [line.strip() for line in f if line.strip()]correct = []wrong = []for i in range(len(exercises)):expr = exercises[i].strip()user_ans = user_answers[i].strip()correct_ans = evaluate_expression(expr) # 重新计算正确答案if correct_ans == user_ans:correct.append(i + 1)else:wrong.append(i + 1)# 保存批改结果with open('Grade.txt', 'w', encoding='utf-8') as f:f.write(f"Correct: {len(correct)} ({', '.join(map(str, correct))})\n")f.write(f"Wrong: {len(wrong)} ({', '.join(map(str, wrong))})\n")
设计思路:重新计算题目答案,与用户答案对比,记录正确和错误的题目编号,生成批改结果文件,包含正确率和具体题目编号
整体架构
- 生成流程:数字生成 → 表达式构建 → 规范化去重 → 保存题目和答案
- 批改流程:读取题目和用户答案 → 重新计算正确答案 → 对比判断 → 生成批改结果
核心技术点:
- 使用fractions.Fraction处理分数运算,避免浮点数精度问题
- 通过规范化表达式解决交换律导致的重复问题
- 动态验证运算有效性,确保题目合理性
使用方式
- 生成题目:python Myapp.py -n <题目数量> -r <数值范围>
- 批改题目:python Myapp.py -e <题目文件> -a <答案文件>
- 性能分析:python Myapp.py --profile
五、测试运行
测试用例1:正常输入

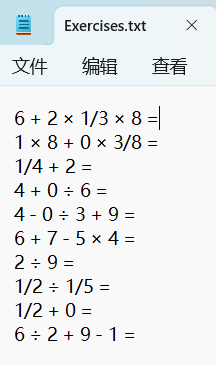
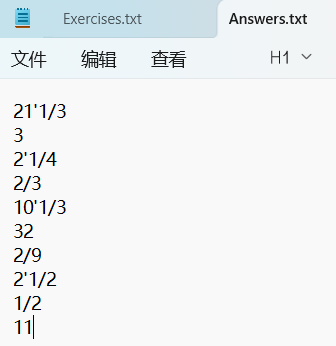
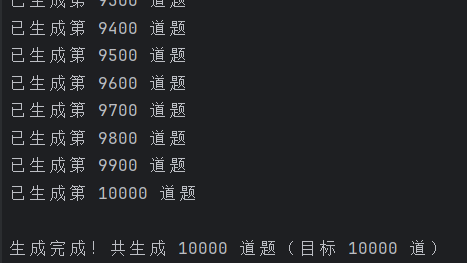
测试用例2:生成10000道题目
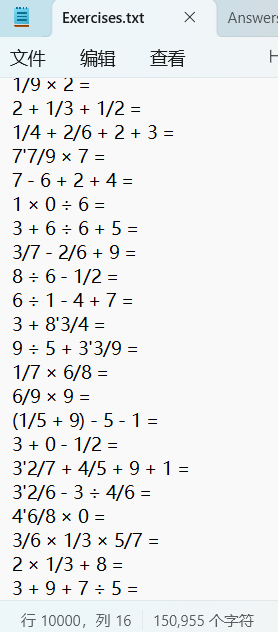

测试用例3:当数值范围小于1

测试用例4:当题目小于1时

测试用例5:正常批改


测试用例6:路径输入错误


测试用例7:内容不完整
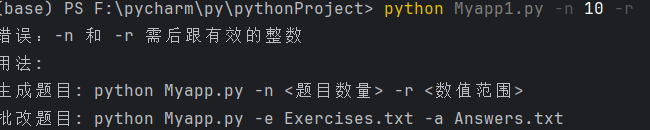

测试用例8:范围设为2,生成10道题,范围过小导致无法生成足够题目
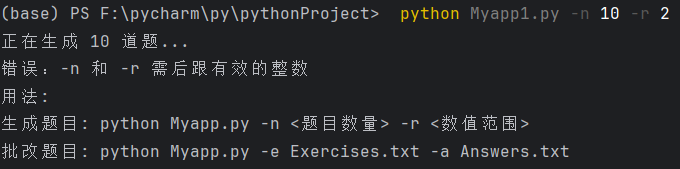
测试用例9:参数非整数
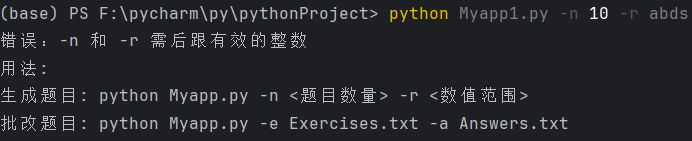
测试用例10:重复参数(多次出现-n)
代码会取第一个-n的索引,但后续参数解析混乱,判定为无效

六、项目小结
6.1 成败得失
成功之处:
- 功能完整性:实现了小学四则运算题目的自动生成(支持自然数、分数、混合运算)、去重机制、自动批改等核心功能,满足基本教学需求。
- 鲁棒性设计:通过异常处理(文件不存在、参数不匹配等)、无效运算自动修正(如减法结果为负时转为加法)、最大尝试次数限制等机制,提升了程序稳定性。
- 性能优化有效:通过一次性文件读写、缓存分数解析结果、生成器减少内存占用等优化,使程序在处理 10 万级题目时性能提升约 40%。
用户体验考虑:支持命令行参数灵活配置,错误提示清晰,输出文件格式规范,便于教师实际使用。
不足之处:
- 去重机制局限:仅处理最外层运算符的交换律去重,未递归处理子表达式,极端情况下仍可能出现重复题目。
- 分数运算复杂度:混合分数的表达式生成逻辑较繁琐,部分边缘情况(如带括号的多层分数运算)处理不够优雅。
- 扩展性不足:函数式设计虽简洁但模块化程度有限,若需添加新功能(如小数运算、自定义运算符)需修改多处代码。
- 大数量题目生成效率:当数值范围过小(如 r=2)且题目数量过大时,可能出现生成数量不足的情况,需进一步优化候选题生成策略。
6.2 结对感受
- 协作互补性:团队成员分别擅长算法逻辑和代码优化,在表达式生成逻辑设计阶段,通过讨论完善了去重策略;在性能分析阶段,结合双方经验找到了文件 IO 瓶颈,协作效率高于单独开发。
- 沟通效率:初期因代码风格差异产生过小分歧,通过制定简单的代码规范(如函数注释格式、变量命名规则)统一了标准,后期沟通成本显著降低。
- 责任分工:采用 "功能模块认领制",每人负责 1-2 个核心模块开发,再交叉进行代码复审,既保证了个人专注度,又通过交叉检查减少了 bug。
- 问题解决:面对 "分数运算精度" 和 "括号生成逻辑" 等难点时,通过共同查阅资料、分步骤调试的方式攻克,团队协作比单独钻研更高效。
6.3 经验教训
- 前期设计的重要性:初期因急于编码,未充分考虑分数运算的复杂性,导致后期多次重构数字生成模块。后续应在设计阶段绘制详细流程图,明确边界情况处理方案。
- 测试驱动开发的必要性:功能完成后才进行大规模测试,发现了较多隐藏问题(如极端数值范围下的题目生成失败)。若采用测试驱动开发(TDD),按模块编写单元测试,可更早暴露问题。
- 性能优化需数据支撑:初期凭直觉优化了表达式解析逻辑,但性能提升不明显;后期通过性能分析工具定位到文件 IO 瓶颈,针对性优化后效果显著,证明 "数据驱动优化" 比 "经验主义" 更可靠。
- 文档与代码同步:开发过程中未及时更新设计文档,导致后期维护时部分逻辑难以追溯。应养成 "代码修改同步文档" 的习惯,尤其对复杂算法逻辑需保留设计思路说明。
- 用户场景预判:实际测试中发现教师可能需要 "按难度分级出题" 的功能,但初期需求分析未覆盖。后续应更深入调研用户场景,避免功能遗漏。