这篇论文旨在解决,CLIP存在类间混淆问题。
CLIP通过对比学习在大规模图文对上进行预训练,而不是直接优化分类边界,因此在分类任务中区分类别能力不足,存在明显的类间混淆。
而且,下游数据与预训练数据之间存在显著域差异进一步加剧了类间混淆,特别是类别间相似度较高时。
我们可以通过一个可学习模块来建模类间混淆,然后通过残差结构消除这些混淆。
下面是方法:
传统CLIP:
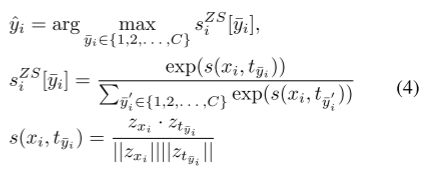
先计算每个图文对的余弦相似度(第3个),然后归一化这个值(第2个),然后最大值就是预测值(第1个)。
改进:
但是这时候是有类间混淆的,所以我们在最后比较最大值之前,应该用去除混淆的干净值来比较。所以要在归一化之后去除混淆,即:

混淆是怎么得到的呢?
将图像xi作为先验,然后通过归一化得到的值来学习类间混淆,即:
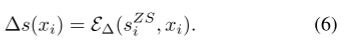
然后,我们方法中的参数通过最小化干净值(去了混淆的干净值)与标签值的交叉熵损失来优化:
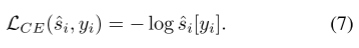
最后,为了防止过度去混淆,采用了L1正则化的相似损失,以确保干净值(预测值)与原始值(预测值)保持相似:
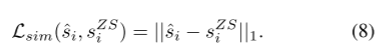
总损失(交叉熵损失 + λ × 相似损失):
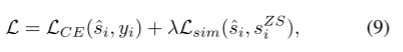
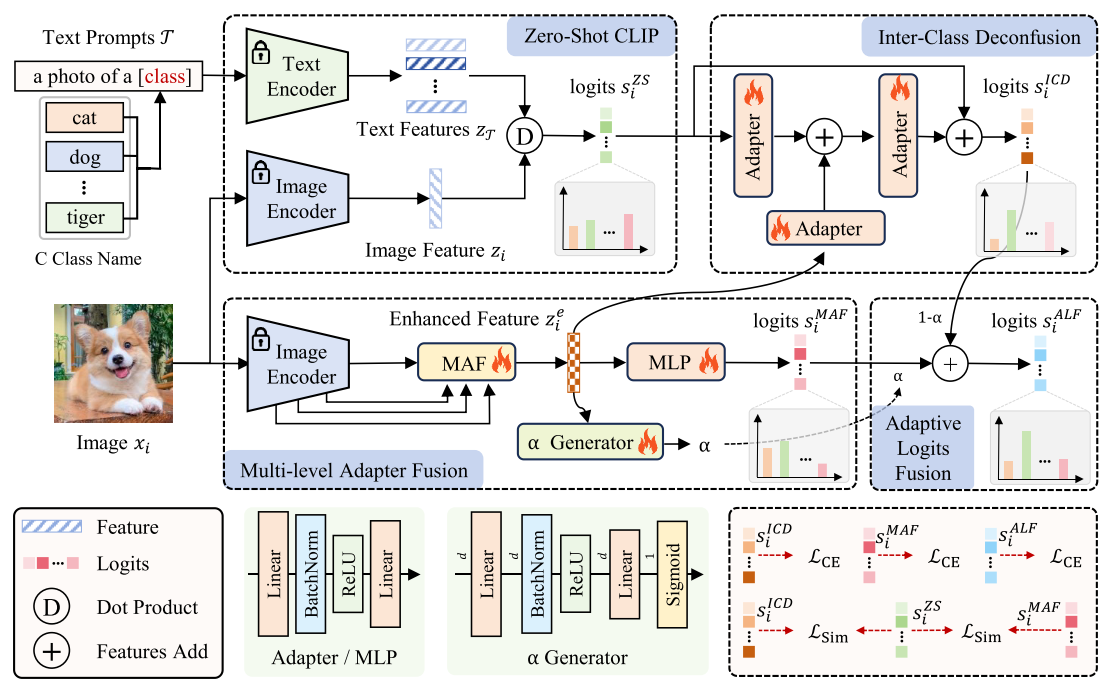
下面介绍一下模型及各个模块:
总体逻辑:
首先通过CLIP得到原始值。
下面的MAF会融合图像编码器的不同层的特征,以融合低层细节信息和高层语义信息,得到增强特征,
增强特征经过MLP得到 MAF的s值(特征值)。
ICD模块以增强特征为先验,通过残差结构从原始值来学习类间混淆得到 ICD的s值(类间混淆值)。
最后,ALF模块将 MAF的s值 与 ICD的s值 融合,其中 权重α 由 α Generator 得到。
MAF模块:
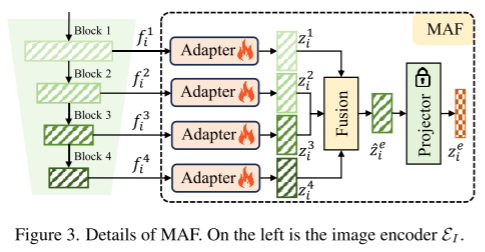
其中 Fusion 步骤有 WF 和 LF 两种方式:
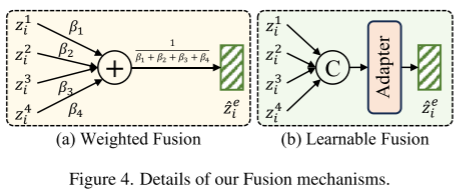
WF中的 β 是预置权重;LF首先通过跨特征通道维度进行特征串接,然后使用 Adapter 降维。
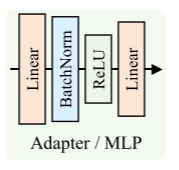
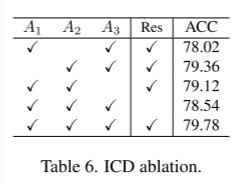
ICD模块:
首先,A1 Adapter 从原始值 学习类间混淆模式,
A2 Adapter从增强特征学习类间混淆的先验,
然后 A1 和 A2 的输出 一起输入到 A3 Adapter,联合学习 原始值 和 增强特征 的类间混淆模式。
最后,通过残差结构去除学习到的混淆模式,得到干净值。
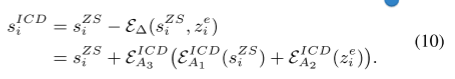
ALF模块:
将 MAF的s值(特征值) 和 ICD的s值(类间混淆值) 结合起来,权重α 由 α Generator 得到。
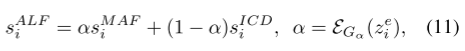
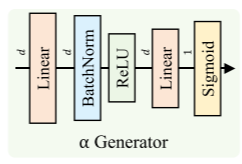
可以从公式注意到:α Generator的输入是增强特征。
优化:


最后,总损失:
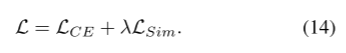
下面是实验部分:
图像分类数据集(11个):ImageNet、Caltech101、DTD、EuroSAT、FGVCAircraft、Flowers102、Food101、OxfordPets、StanfordCars、SUN397、UCF101
比较的SOTA(基于CLIP的FSL方法)(11个):CoOp、VT-CLIP、Tip-Adapter、SuS-X、FAR、CALIP-FS、SGVA-CLIP、Proto-CLIP-F、APE、DAC-V、LP++
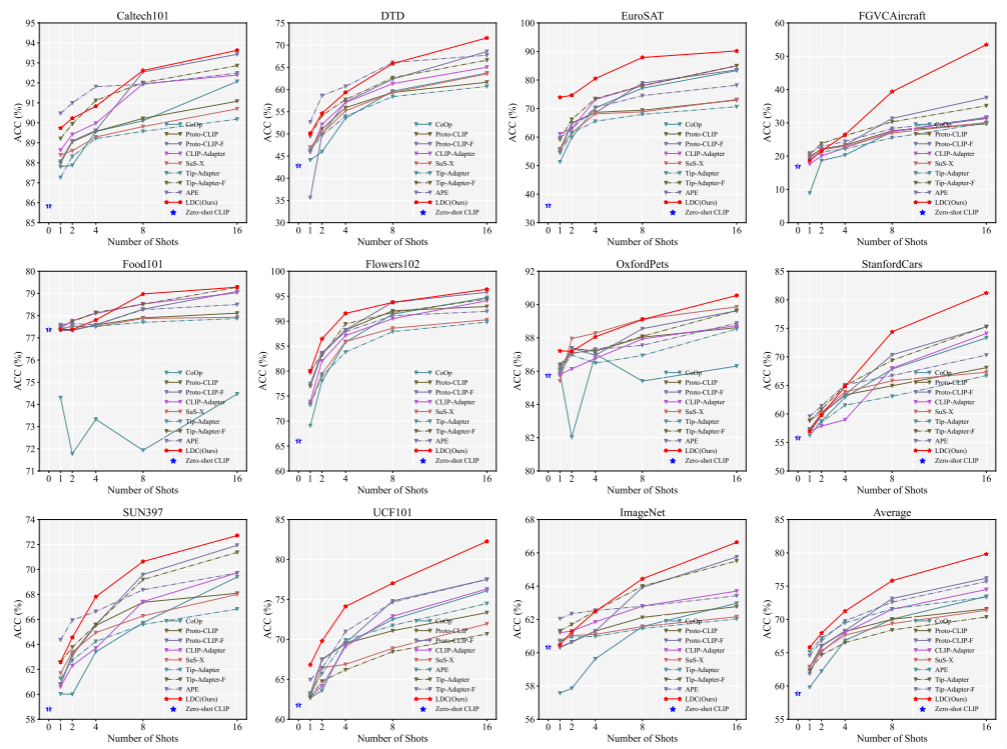
11个数据集和1个平均性能,红线是本文的LDC。
消融实验:
三个模块:
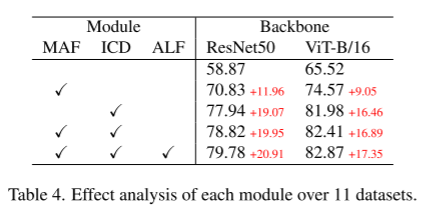
MAF中的四层特征、β取值、Projector:
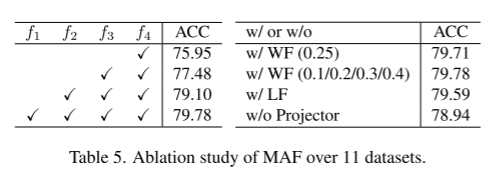
ICD中的三个Adapter:
ALF中的α取值(通过α Generator自适应取值最好):
