作业1
核心代码与运行结果
url='http://www.shanghairanking.cn/rankings/bcur/2020'response = urllib.request.urlopen(url)
if response.getcode() == 200:html = response.read().decode('utf-8')#解析网页soup = BeautifulSoup(html, 'lxml')#找到排名表tables = soup.find_all('div', attrs={'class':'rk-table-box'})#找到行标签rows=tables[0].find_all('tr')print('排名\t学校名称\t省市\t学校类型\t总分')for row in rows[1:]:#找到行内对应的块,获取排名print(row.find('div', attrs={'class':'ranking'}).text.strip(),end='\t')#找到行内对应的块,获取名称print(row.find('span',attrs={'class':'name-cn'}).text.strip(),end='\t')for attr in row.find_all("td")[-4:-1]:print(attr.text.strip(),end='\t')print()
这里打开链接发现第一页没做什么处理,直接request+bs4,通过浏览器调试快速找到排名对应的块和表格位置用bs4提取即可。
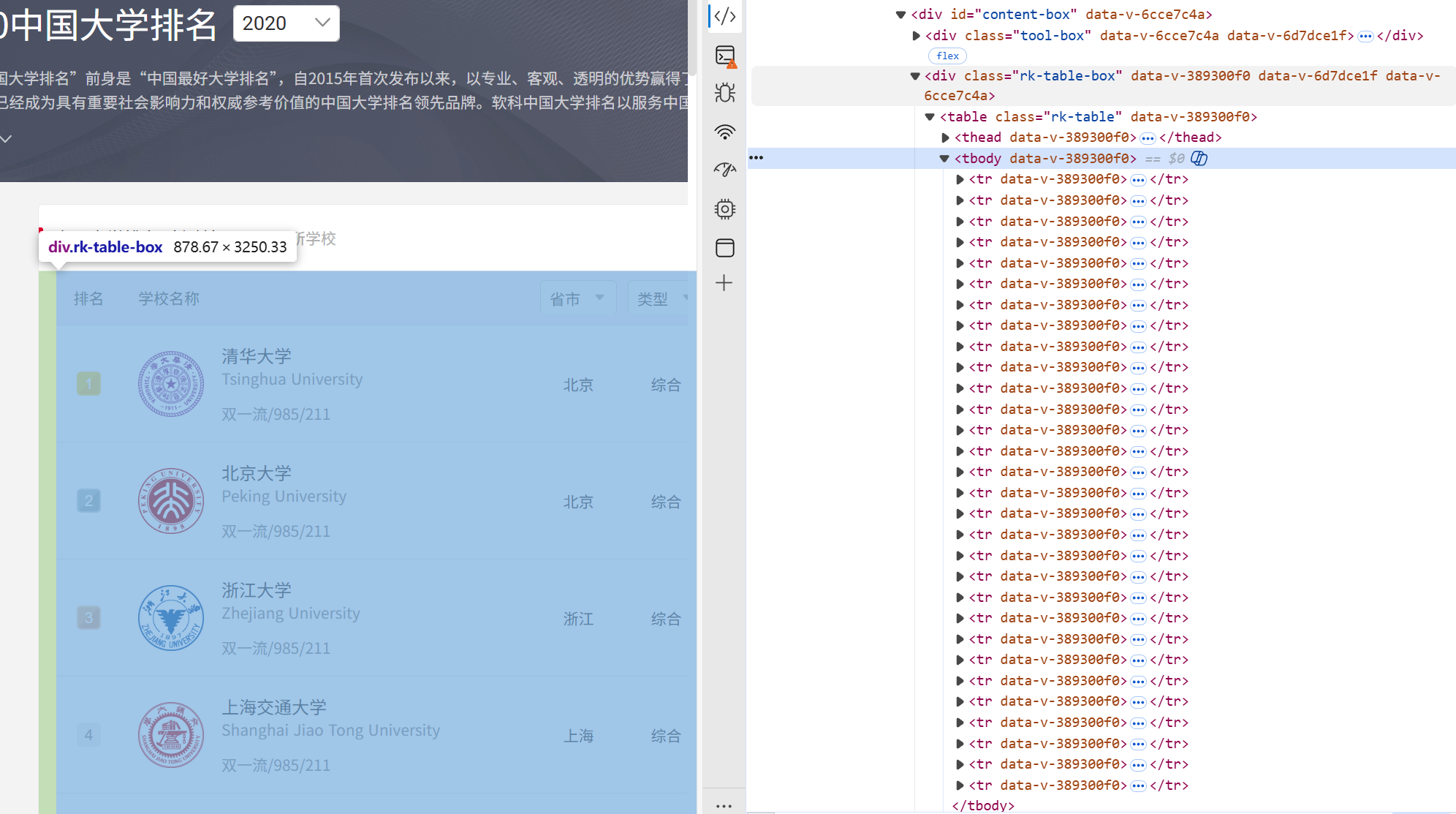
心得
这里发现用浏览器定位目标位置十分方便,不过这里翻页是用js实现的,request就无能为力了。大概流程就是先requset拿到静态网页,用re或bs4解析一下。然后找一下目标所在的块,一般相同内容对应的class都一样,后续处理也方便。
作业2
核心代码与运行结果
#用requests和re库方法设计某个商城(自已选择)商品比价定向爬虫,爬取该商城,以关键词“书包”搜索页面的数据,爬取商品名称和价格。import requests
import re
url='https://search.bl.com/k-%25E4%25B9%25A6%25E5%258C%2585.html?bl_ad=P668822_-_%u4E66%u5305_-_5'headers={'user-agent':"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/141.0.0.0 Safari/537.36 Edg/141.0.0.0"}
response = requests.get(url,headers=headers)
response.encoding='utf-8'
html = response.text
#print(html)
#缓存到本地
with open('index.html','w',encoding='utf-8') as f:f.write(html)# with open('index.html','r',encoding='utf-8') as f:
# html = f.read()
#正则表达式模板
#找到li标签
li_pattern = re.compile(r'(<li class="on-show" \b[^>]*>.*?</li>)', re.DOTALL)
#找到价格对应的块
money_pattern=re.compile(r'<div class="money-fl">¥([0-9.]+)</div>')
#找到名称,这里多个标签包含了名称信息,选了a标签
title_pattern=re.compile(r'<a target="_blank" title=(".*") href=')
for a in li_pattern.findall(html):# print(a)print(title_pattern.findall(a)[0],end='\t')print(money_pattern.findall(a)[0])

心得
步骤大差不差,主要是网站不好找,这里找了个小网站爬,不过也只能能获取部分信息,找了几个购物网站都是动态网页,可以用Selenium等自动化包爬。
作业3
核心代码与运行结果
import requests
from bs4 import BeautifulSoupurl='https://news.fzu.edu.cn/yxfd.htm'
res = requests.get(url)
res.encoding='utf-8'
html = res.text
links=[]
soup = BeautifulSoup(html, 'lxml')
#去img标签里找图片地址并拼接
for img in soup.find_all('img'):link=img.get('src')print(link)links.append('https://news.fzu.edu.cn/'+link)#下载
for i, url in enumerate(links):print(f"\n进度: {i + 1}/{len(links)} - 正在下载: {url}")response = requests.get(url, stream=True, timeout=30)response.raise_for_status() # 检查请求是否成功try:with open('./pics/'+url.split('/')[-1], 'wb') as f:for chunk in response.iter_content(chunk_size=8192):if chunk:f.write(chunk)print(f"✅ 下载成功 ")except Exception as e:print(e)

心得
福大的网站还是友好,流程也差不多。翻页也设计在url里,就没什么问题了。这里找图片比较方便直接去img标签里找。拼接的话这里通过浏览器发现图片的链接为:'https://news.fzu.edu.cn/'+link,基本没什么问题了。
gitee地址
https://gitee.com/wsxxs233/data-collection