Introduction
Context-sensitivity 会带来静态分析的精度提升,但是也会带来巨大的开销,这引出一个关键的问题:能否在某些对整体分析的精度有重要影响的函数上选择性的使用 context-sensitivity?这个问题的难点在于识别具有这种性质的函数。文章总结了在 context-insensitive 的指针分析中引入不精确性的 value flow 的三种普遍模式,在此基础上实现了 Zipper 来高效地识别这三种模式从而识别关键函数。
CAUSES OF IMPRECISION IN CONTEXT-INSENSITIVE POINTER ANALYSIS

函数 m 在 context-insensitive 的指针分析中会使得 x2 和 y2 都指向对象 A() 和 B(),即 pts(x2) = pts(y2) = {o4, o6}。如果对 m 进行 context-sensitive 的分析就不会引入这个问题,m 会被看作有两个拷贝 m5 和 m7。
定义 In and Out methods:Given a class \(C\) and a method \(M\) that is declared in \(C\) or inherited from \(C\)’s super-classes, if \(M\) contains one or more parameters then \(M\) is an In method of C, and if \(M\)’s return type is non-void then \(M\) is an Out method of \(C\).
定义 Object wrapping and unwrapping:If an object \(O\) is stored in a field of an object \(W\) (or in an array entry of \(W\) , in case \(W\) is an array), then \(O\) is wrapped into \(W\) . Conversely, if an object \(O\) is loaded from a field of an object \(W\) (or from an array entry of \(W\) in case \(W\) is an array), then \(O\) is unwrapped from \(W\) .
定义 value flow 的第一种模式 Direct flow:If, in some execution of the program, an object \(O\) is passed as a parameter to an In method \(M_1\) of class \(C\), and then flows (via a series of assignments, field load/store operations, method calls, or returns) to the return value of an Out method, \(M_2\), of the same class \(C\), then we say the program has direct flow from \(M_1\) to \(M_2\). (The example in Figure 1 is a simple instance of this pattern.)
从上面的定义,容易猜出 wrapped flow 和 unwrapped flow 的定义:
If, in some execution of the program, an object \(O\) is passed as a parameter to an In method \(M_1\) of class \(C\) and then flows to a store operation that wraps \(O\) into an object \(W\) , where \(W\) subsequently flows to the result of an Out method, \(M_2\), of the same class \(C\), then we say the program has wrapped flow from \(M_1\) to \(M_2\).
If, in some execution of the program, an object \(O\) is passed as a parameter to an In method \(M_1\) of class \(C\) and then flows to a load operation that unwraps an object \(U\) from \(O\), where \(U\) subsequently flows to the return value of an Out method, \(M_2\), of the same class \(C\), then we say the program has unwrapped flow from \(M_1\) to \(M_2\)
文章给出了这三种 value flow 的图解:

Direct flow
以一个 Java 程序中常见的 getter/setter 方法为例,图中展示了不同的对象是怎么通过这个 direct flow 被合并的。如果能够对 direct flow 路径上的函数使用 context-sensitive 的指针分析就可以规避这种精确性的损失。

Wrapped flow
Wrapped flow 的不精确性只有在 load 外部对象的 field 的时候会被引入分析,对应这个例子的 (28) 和 (34) 行。Wrapped flow 路径上的函数并不都需要 context-sensitivity 来解决不精确性,在这个例子中,只需要对 Collection 中的方法做 context-sensitive 的分析。

三种 value flow 都只相对于一个 class 来定义,In 和 Out 方法都位于一个 class 中。这种设计使得能够通过逐个考虑每个类的方法高效识别不精确性。
Unwrapped flow

绿色箭头展示了这里例子中的 unwrapped flow。如果我们从 Box 类的角度考虑 In 和 Out 方法,则其构造函数 Box 仍将以 context-snesitive 的方式进行分析,因为它是 direct flow 的一部分。
有些不精确性不能仅通过一个 flow 来描述,而只能通过不同的 flow 组合来捕捉。
Zipper
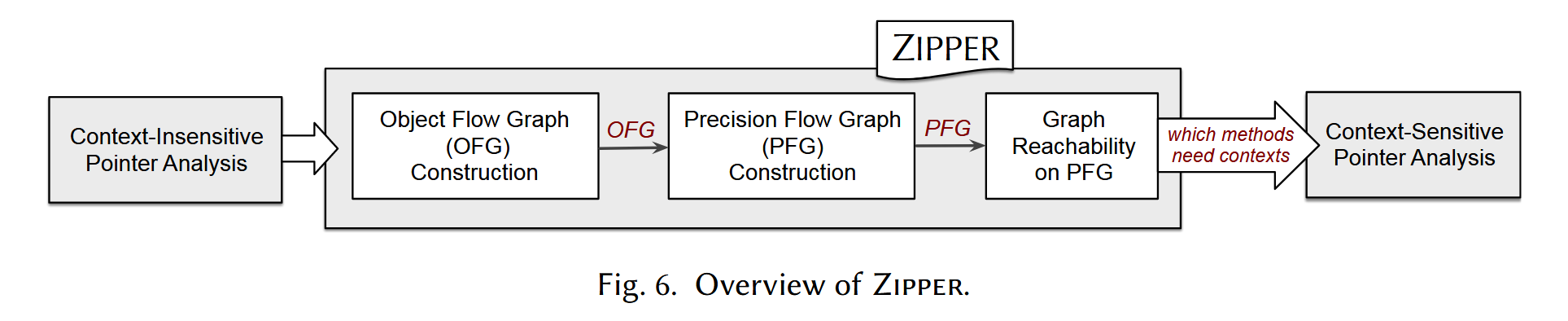
Object flow graph
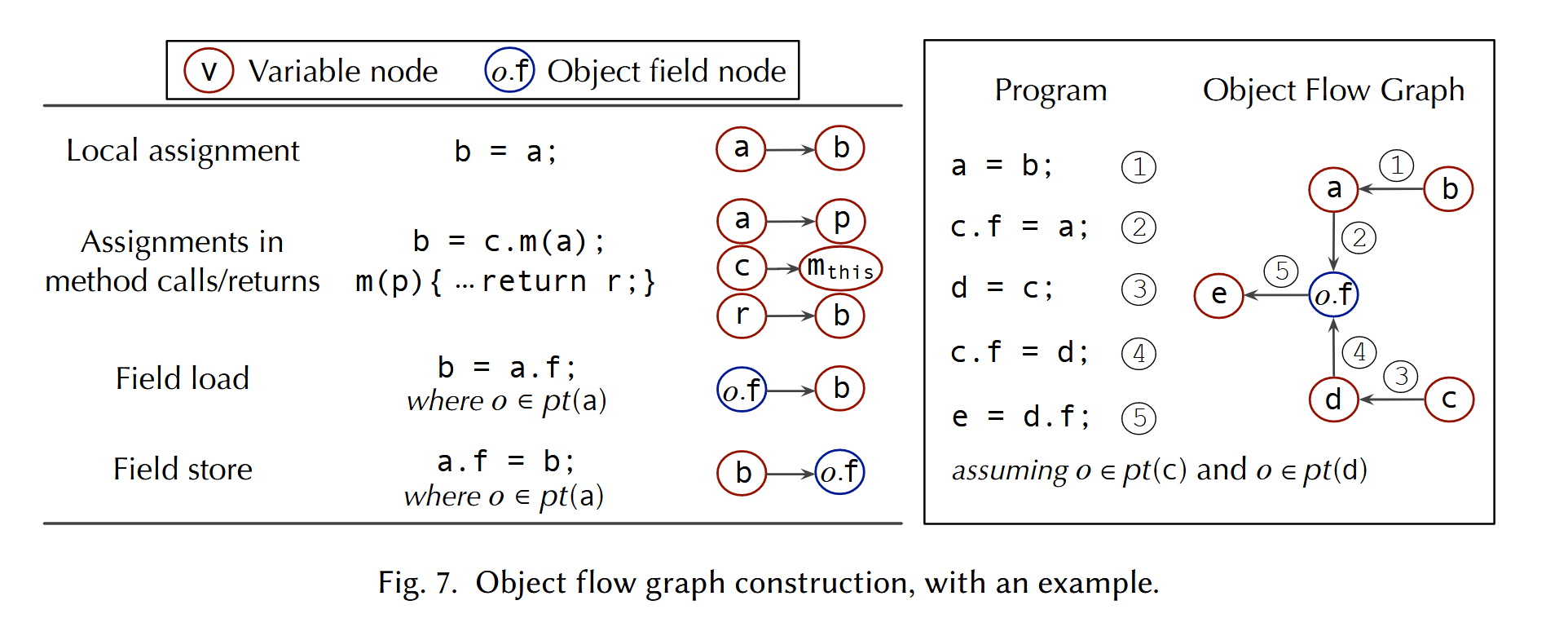
OFG 已经可以表达 direct flow,如果从结点 b 出发可以到达结点 e,那么说明 b 指向的对象可能流动到 e,也就说明 b 和 e 之间存在一个 direct flow;但是 OFG 并不容易表达 wrapped flow 和 unwrapped flow。Zipper 利用 OFG 的信息构建一个 precision flow graph。
Precision Flow Graphs and Graph Reachability
PFG 的构建算法如下:

对于某个 class \(c\),算法对 \(c\) 的每个方法 \(m\) 从每个参数 \(p\) 为起点深度遍历 OFG。依照 wrapped flow 和 unwrapped flow 的定义,对于 b = a.f,OFG 会在 b 和 a 指向的所有对象 o 的字段 o.f 上建立边关系,PFG 则会在 b 和 a 之间建立一个指向边来捕捉 unwrapped flow;b.f = a 也就是 wrapped flow 类似,不过需要在 a 和 b 可能指向的所有对象间建立边,否则可能会遗漏某些流。
这两种边的信息表示了不精确信息会如何被传递,试想,对于 b = a.f 假设 a 因为 context-insensitive 的分析变得不再精确,那么 b 的分析也不再精确;对于 b.f = a,如果 a 不精确,那么 b 指向的每个对象 o 也会变得不再精确。
下面的算法提取了所有 class 中的不精确方法:

对于 \(c\) 中的每个 Out 方法,PFG 上所有可达 Out 方法返回值的结点都可能因为其不精确性影响结果从而影响分析,收集这些结点所在的方法,并标记这些方法为 critical methods。