我一直觉得很神奇:大多数 AI 系统只要你一停止和它们对话,就会把一切都忘光。你喂给它们 facts、context、chat logs——会话一结束,噗的一下,全没了。这一直是“intelligent” agents 的最大瓶颈。
后来我发现了 Graphiti,感觉终于有人把 knowledge graphs 和 AI memory 连接到了一起。
如果这听起来有点高深,别担心,我们一步步来。

Graphiti 是什么
把 Graphiti 想象成一个创建并维护动态知识网络的工具。
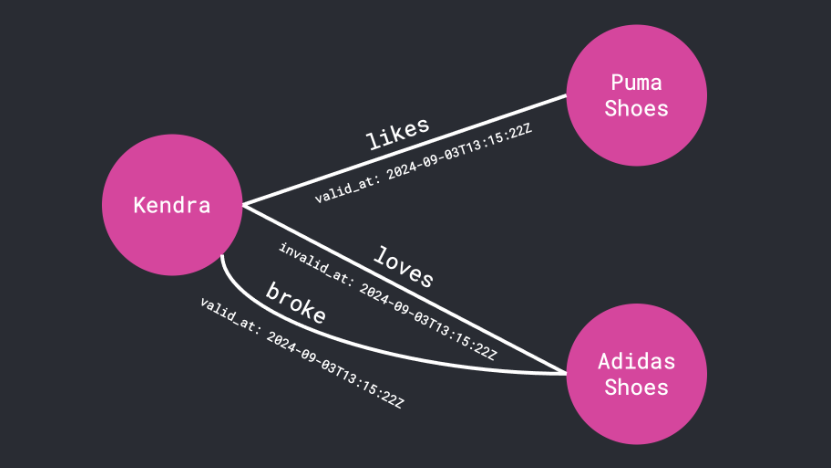
每一条小事实——比如“Kendra 喜欢 Adidas 鞋”——都会变成一个由信息相互连接构成的小三角(类似一个三元关系)。
Kendra -[loves]→ Adidas shoes
每个 node 代表一个“thing”(比如人或物品),每条 edge 表示一种 relationship(比如“loves”或“bought”)。这就是所谓的 knowledge graph。
和常见的 RAG(Retrieval-Augmented Generation)不同,Graphiti 不只是一次性把图构建出来然后就放着不管;它让图“活着”。随着新信息的进入(用户对话、数据库记录、外部更新等等),graph 会持续自我更新。
如果明天 Kendra 改爱 Nike,Graphiti 会自动更新那条 relationship,同时还会记得她曾经喜欢过 Adidas。这就像带上了 timeline 的 memory。
为什么这很重要
大多数 RAG 系统是静态的。它们批量处理数据、做 summarise,然后把信息“定格”。对 research bot 或 FAQ assistant 还行,但对任何快速变化的东西都很差——比如 CRM、real-time analytics dashboard,甚至是 personal AI companion。
Graphiti 颠覆了这个模式。
它带来:
- Instant updates:新数据进来就能即时更新
- Bi-temporal tracking:既知道事情发生的时间,也知道被记录的时间
- Hybrid retrieval:融合 semantic search(看语义)、keyword search(看精准关键词)和 graph traversal(看关系结构)
简而言之:更快、更贴心、更精准的响应——往往不到一秒。
设置 Graphiti
你需要 Python 3.10+,以及一个数据库(比如 Neo4j 或 FalkorDB)。为了简单起见,这里选 Neo4j。
安装依赖:
pip install graphiti-core
如果你用 uv(非常适合做依赖管理):
uv add graphiti-core
然后连接 Neo4j:
from graphiti_core import Graphiti
from graphiti_core.driver.neo4j_driver import Neo4jDriverdriver = Neo4jDriver(uri="bolt://localhost:7687",user="neo4j",password="password",database="graphiti_demo"
)
graphiti = Graphiti(graph_driver=driver)
现在,给它一条数据——Graphiti 把这种数据称为一个 “episode”:
episode = {"event": "purchase","user": "Kendra","item": "Adidas Ultraboost","timestamp": "2025-10-16T09:00:00Z"
}graphiti.add_episode(episode)
你可以这样查询:
results = graphiti.search("Who bought Adidas shoes?")
print(results)
就这么简单。不用 retraining,不用 recomputation。数据是“活的”,会不断演化。
幕后:一切如何串联起来
Graphiti 是 Zep 的核心组件,Zep 是一个很酷的 “context engineering platform”,为 AI agents 提供 long-term memory。
所以当你看到 Zep 在像变魔术一样处理动态数据、维持上下文时——其实是 Graphiti 在幕后默默干重活。
它也能很好地对接多家 AI providers:
- OpenAI(默认)
- Google Gemini
- Anthropic
- Groq
- 甚至 Ollama(如果你想把一切都本地化)
如果你在做 privacy-focused 的项目,Ollama 的集成非常香。你可以拉取像 deepseek-r1:7b(做 reasoning)和 nomic-embed-text(做 embeddings)这样的模型,全程不碰云端。
它与众不同的感觉
我用过不少号称 “real-time” 或 “context-aware” 的框架,但 Graphiti 确实做到了。你能直观看到 relationships 的发展变化;你可以让它回放某个时刻“世界”的样子。而且它使用 hybrid retrieval,而不是只靠 LLM summarisation,所以它很快——经常在一秒内返回。
如果你被传统 RAG 在应对动态数据时的捉襟见肘折磨过,Graphiti 会让人耳目一新。
使用前的小提醒
- Graphiti 使用 structured LLM output,因此像 OpenAI 或 Gemini 这样的模型效果最佳。
- 默认的 concurrency 比较低,以避免触发 API 限额;如果你的 API 允许更高吞吐,可以调高
SEMAPHORE_LIMIT。 - 需要为你使用的 LLM provider 设置 environment variables(如
OPENAI_API_KEY、ANTHROPIC_API_KEY等)。
最后的想法
Graphiti 像是 memory 与 reasoning 之间那块缺失的拼图。它不只是存 facts——更是去理解这些事实如何随时间演变。
如果你在打造需要记忆、推理、适应(而不是只检索静态信息)的 AI agents,这个框架值得一试。
说真的,那种查询数据像是在读一部自己不断续写的故事的感觉,太自然了。
如果觉得有用请关注微信公众号,获取更多资讯。
