合集 - AI应用合集(8)
1.Stable_diffusion入门学习2023-12-232.ControlNet学习实战1--字体海报2024-01-293.ControNet基础学习2024-02-204.Ollama初识03-235.Ollama进阶参数学习04-136.RAG 知识库数据结构化04-13
7.Vllm部署大模型05-31
8.Docker结合Python构建服务器容器06-22前言
之前虽然介绍过 Ollama 部署大模型,虽然 Ollama 对于大模型管理非常方便,但是在于企业多并发或用户访问量大的场景下,Ollama 就有些力不从心了,所以就需要更有效的模型部署方式。
网上有许多部署大模型的工具,这里主要介绍使用 Vllm 来部署,用 Vllm 部署的大模型可以兼容 OpenAI 的接口,这也是让其非常通用的原因之一。
环境创建
Python 虚拟环境
Vllm 主要是通过 Python 来安装,所以我们先建立一个 Python 的虚拟环境,拥有管理其服务。
创建 Python 我这里选择使用 Miniconda 使用 conda 命令。Miniconda 安装方式这里就不再过多说明了,这里主要介绍一下 conda 相关的命令。
shell
conda env list ## 查看conda创建的所以虚拟环境 conda create -n name python=3.10 ## 创建特定版本python conda activate name ## 进入某个虚拟环境 conda env remove -n name ## 删除某个虚拟环境
Python 相关安装包
创建一个用于部署的虚拟环境,使用命令,安装 Vllm。
shell
pip install vllm
过程很长,等待安装完成即可。
这时我们可以去魔搭社区,找一下需要部署的模型。这里可以选择 Qwen ,Deepseek 等国产开源大模型。
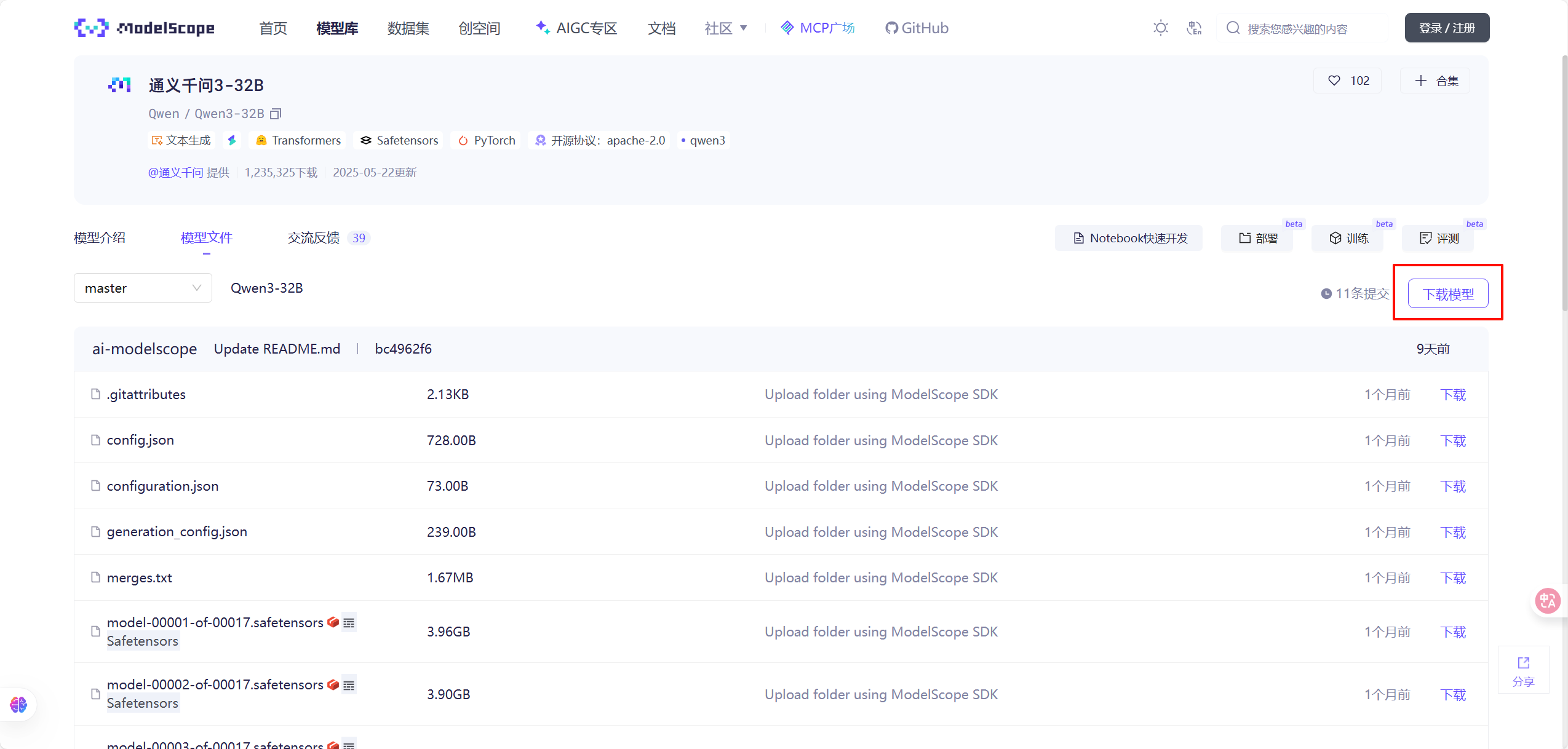
找到这里的下载模型,官方推荐使用 ModelScope 进行下载具体使用方式可以参考官方的说明。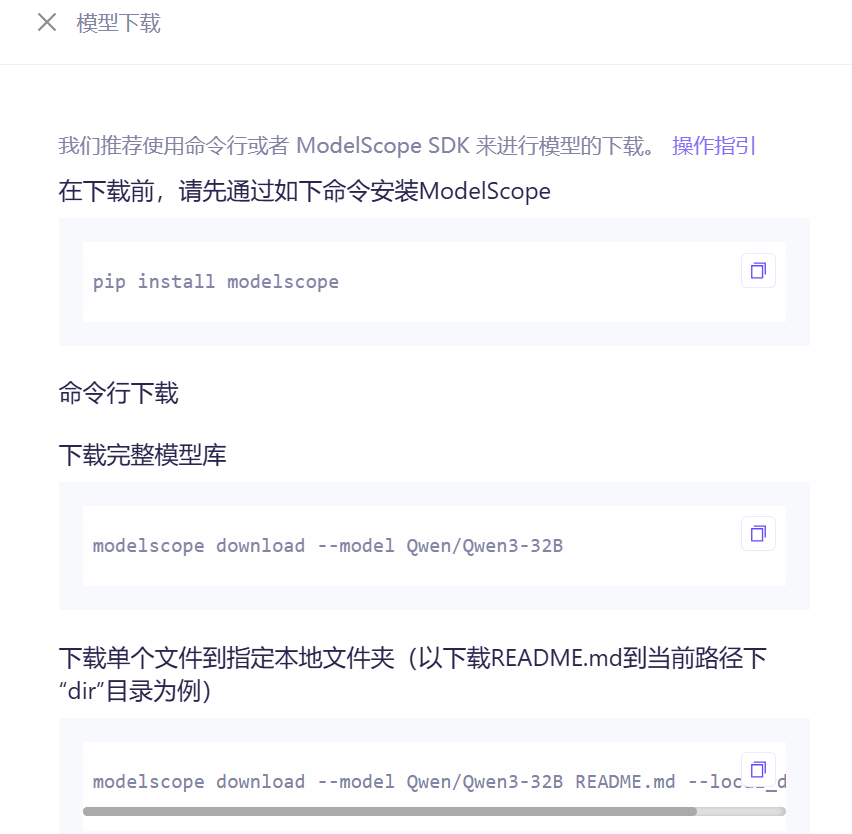
shell
## 安装下载环境
pip install modelscope
## 下载模型
modelscope download --model Qwen/Qwen3-32B
## 下载指定目录下
modelscope download --model Qwen/Qwen3-32B --local_dir ./dir
Vllm 服务启动
在部署模型的使用,由于满血版模型过于庞大,不可以避免的需要对模型进行量化,量化方式有很多种 GPTQ 、AWQ 和 Bitsandbytes,至于这几种的量化方式的的区别,我这里对这些了解也不是特别清楚,这里就不过多说明,可以自行去了解一下。
量化级数为满血 FP16 ,FP8, INT8, INT4
这里主要强调一下 Bitsandbytes 这种量化方式,使用这种量化的模型,需要在 Python 环境下安装
shell
pip install bitsandbytes>=0.45.3
分享两个安装命令:
shell
vllm serve ModelSpace/Qwen2.5-VL-32B-bnb-4bit --port 8000 --host 0.0.0.0 --dtype half --max-model-len 16384 --max-num-batched-tokens 2048 --max-num-seqs 8 --gpu-memory-utilization 0.5 --cpu-offload-gb 32 --swap-space 32 --load_format bitsandbytes --quantization bitsandbytes --limit-mm-per-prompt image=5,video=5 --served-model-name qwen-vlvllm serve ModelSpace/Qwen3-30B-A3B-Base-bnb-4bit --port 8000 --host 0.0.0.0 --dtype half --max-model-len 32768 --max-num-seqs 8 --load_format bitsandbytes --quantization bitsandbytes --served-model-name qwen3-30b-a3b
分别介绍一下相关的命令用途。
- vllm serve :用于启动 vllm 服务,兼容 OpenAI 接口
- ModelSpace/Qwen2.5-VL-32B-bnb-4bit:模型的本地地址
- port host:服务器端口
- dtype:模型权重和激活的数据类型。可选值:auto, half, float16, bfloat16, float, float32。默认值:“auto”
- “auto” 将为 FP32 和 FP16 模型使用 FP16 精度,为 BF16 模型使用 BF16 精度。
- “half” 用于 FP16。推荐用于 AWQ 量化。
- “float16” 与 “half” 相同。
- “bfloat16” 用于精度和范围之间的平衡。
- “float” 是 FP32 精度的简写。
- “float32” 用于 FP32 精度。
- max-model-len:模型上下文长度。如果未指定,将从模型配置自动派生。支持可读格式的 k/m/g/K/M/G。示例:- 1k → 1000 - 1K → 1024
- max-num-batched-tokens:每次迭代的最大批处理令牌数。
- max-num-seqs:每次迭代的最大序列数。
- gpu-memory-utilization:用于模型执行器的 GPU 内存比例,范围为 0 到 1。例如,值 0.5 表示 50% 的 GPU 内存利用率。如果未指定,将使用默认值 0.9。这是一个按实例限制,仅适用于当前的 vLLM 实例。如果您在同一 GPU 上运行另一个 vLLM 实例,则无关紧要。例如,如果您在同一 GPU 上运行两个 vLLM 实例,则可以将每个实例的 GPU 内存利用率设置为 0.5。默认值:0.9
- cpu-offload-gb:每个 GPU 要卸载到 CPU 的空间 (GiB)。默认值为 0,表示不卸载。直观地,此参数可以被视为增加 GPU 内存大小的虚拟方式。例如,如果您有一个 24 GB GPU 并将其设置为 10,则虚拟地您可以将其视为 34 GB GPU。然后,您可以加载一个 13B 模型(使用 BF16 权重),这至少需要 26GB GPU 内存。请注意,这需要快速的 CPU-GPU 互连,因为模型的一部分在每个模型前向传递中从 CPU 内存动态加载到 GPU 内存。默认值:0
- swap-space:每个 GPU 的 CPU 交换空间大小 (GiB)。默认值:4
- load_format:对应的模型加载器
- quantization:可选值:aqlm, awq, deepspeedfp, tpu_int8, fp8, ptpc_fp8, fbgemm_fp8, modelopt, nvfp4, marlin, gguf, gptq_marlin_24, gptq_marlin, awq_marlin, gptq, compressed-tensors, bitsandbytes, qqq, hqq, experts_int8, neuron_quant, ipex, quark, moe_wna16, torchao, None 用于量化权重的方法。如果为 None,我们首先检查模型配置文件中的 quantization_config 属性。如果为 None,我们假设模型权重未量化,并使用 dtype 确定权重的数据类型
- limit-mm-per-prompt:对于每个多模态插件,限制每个提示允许的输入实例数。期望一个逗号分隔的项目列表,例如:image=16,video=2 允许每个提示最多 16 个图像和 2 个视频。默认为每种模态 1 个。
- served-model-name:API 中使用的模型名称。如果提供了多个名称,则服务器将响应任何提供的名称。响应的模型字段中的模型名称将是列表中的第一个名称。如果未指定,则模型名称将与
--model参数相同。请注意,此名称也将用于 prometheus 指标的 model_name 标签内容中,如果提供多个名称,则指标标签将采用第一个名称。
正常启动后观察资源管理,可以看到模型正常导入到显存当中。
__EOF__