本文整理自 IvorySQL 2025 生态大会暨 PostgreSQL 高峰论坛的演讲分享,演讲嘉宾:张晨,公众号《ZhangChen-PDU》主理人。
前言
在数据库运维中,灾难恢复始终是保障业务连续性和系统可靠性的核心环节。随着数据库规模和复杂性的增加,传统工具在极端场景下的局限性愈发明显,因此需要更专业、高效的解决方案来应对数据损坏或不可启动的情况。
PDU 的快速介绍
在数据库运维场景中,灾难恢复一直是考验系统可靠性与底层机制理解的重要环节。对于 Oracle 等商业数据库来说,已有成熟的内部工具如 DUL 可用于在数据库无法启动时直接从数据文件中提取数据。而在 PostgreSQL 生态中,长期缺乏类似的工具,这也正是 PDU 诞生的初衷。
PDU 是什么
PDU(PostgreSQL Data Unloader)是专门用于 PostgreSQL 系数据库的灾难恢复工具,旨在解决数据库无法正常启动、单表文件损坏或归档丢失等极端情况下的数据恢复问题。其核心功能主要包括:
-
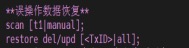
从 wal 中恢复 delete/update 的原数据。
![图片1.jpg]()
-
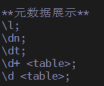
数据库无法启动时直接从数据文件中提取数据。
![图片2.png]()
-
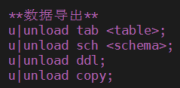
支持单表/整库/自定义数据文件级别的恢复。
![图片3.png]()
-
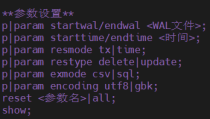
提供事务级/时间区间级数据恢复。
![图片4.png]()
为什么需要 PDU
在灾难恢复场景下,主流数据库的能力存在明显差异。
- Oracle 拥有成熟工具体系,如官方 DUL 与国内 ODU,可在数据库无法启动时直接从数据文件中恢复数据并生成可导入的 dump 文件。
- PostgreSQL 的 pg_filedump 工具功能有限,仅能导出已知表结构的单个数据文件,缺乏定制化能力,遇到复杂问题难以应对,且对生产环境适配不足,例如仅通过 xmax != 0 判定元组状态,准确性有限。
- PG 系国产数据库 在灾备工具方面几乎空白,多数数据库修改了底层数据文件结构,pg_filedump 无法兼容,且缺乏专业恢复工具,在灾难场景下常束手无策。
基于这一现状,PDU 的开发旨在填补 PG 系数据库在灾难恢复中的空白。
关于 pg_filedump 更详细的技术解析可参考👉作者往期文章
PDU 如何使用
PDU 的使用非常简便,其软件组成仅包含两个部分:可执行文件与配置文件。使用步骤如下:
第一步:填入数据目录与归档目录

第二步:进入 pdu 可执行文件
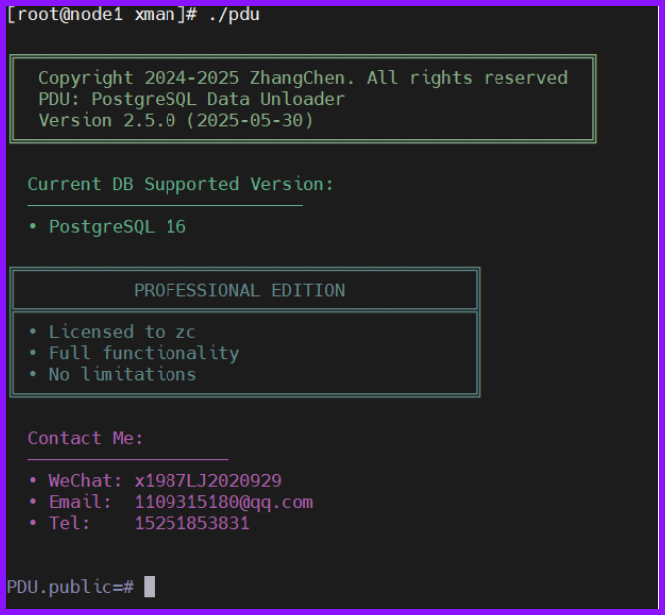
第三步:通过简化命令 b 执行自动初始化
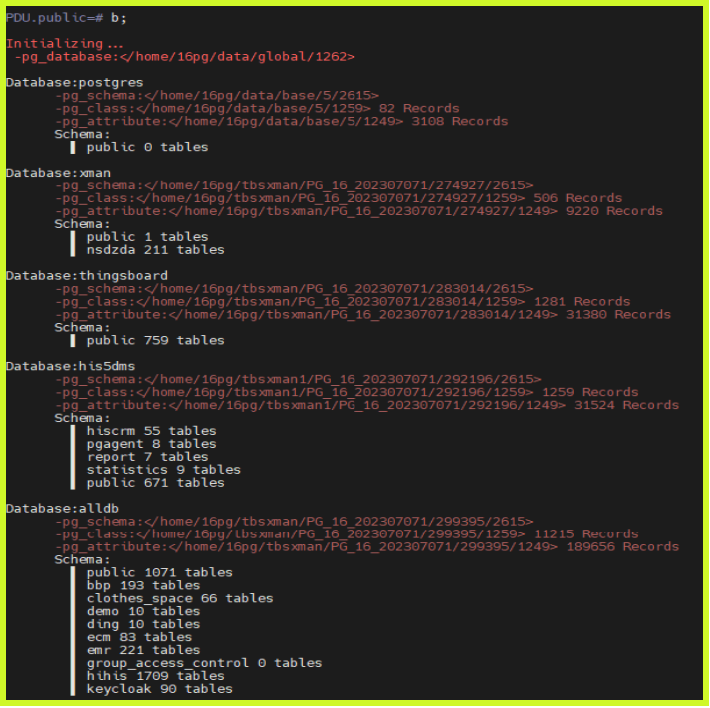
第四步:自由操作
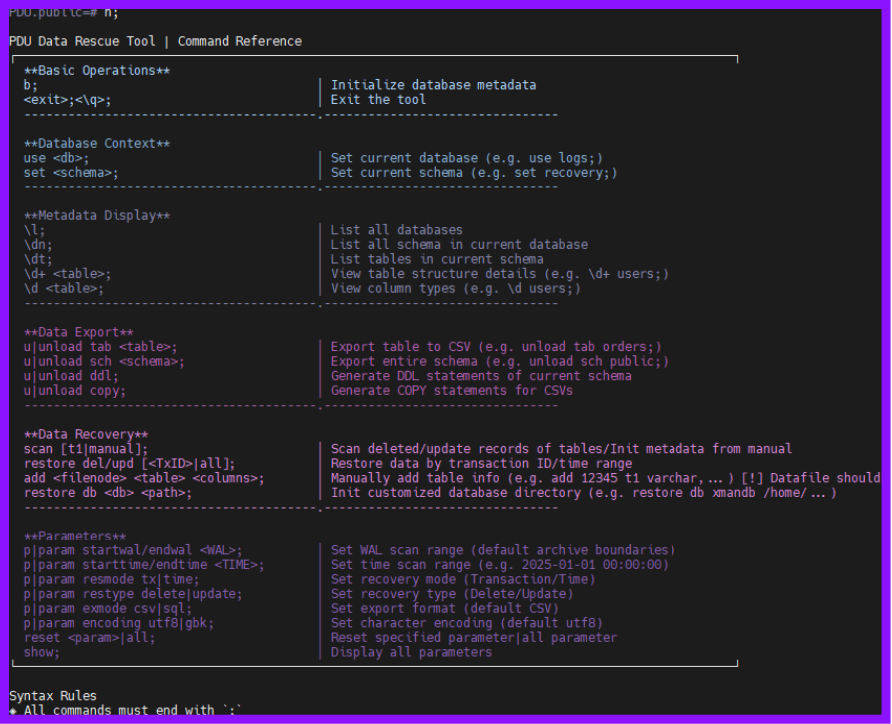
以下为演示图片:

PDU 程序崩溃了如何反馈
PDU 采用 C 语言开发,能够直接复用 PostgreSQL 内核的数据结构与函数,从而提高数据解析的效率与兼容性。在程序运行过程中,如果出现核心转储或者崩溃(core dumped),用户可通过操作系统配置生成 core 文件 ulimit -c unlimited,将 core 文件提供给开发者以复现问题并进行排查。
数据字典的快速初始化
tuple 数据读取基本原理
在数据库无法启动的情况下,PDU 仍能完成数据字典的初始化,这一过程基于对 tuple 数据读取方式的分析与实现。
在 PostgreSQL 中,每个数据页(Page)开头的页头(Page Header)存储了页的基本信息。页头中各字段都有固定的字节长度与偏移量,例如 pd_lower 占 2 个字节,表示空闲空间的起始位置,即最后一个行指针(Line Pointer)的结束地址。在数据文件中,每行显示 8 个字节,通过偏移量即可确定各结构的具体位置。
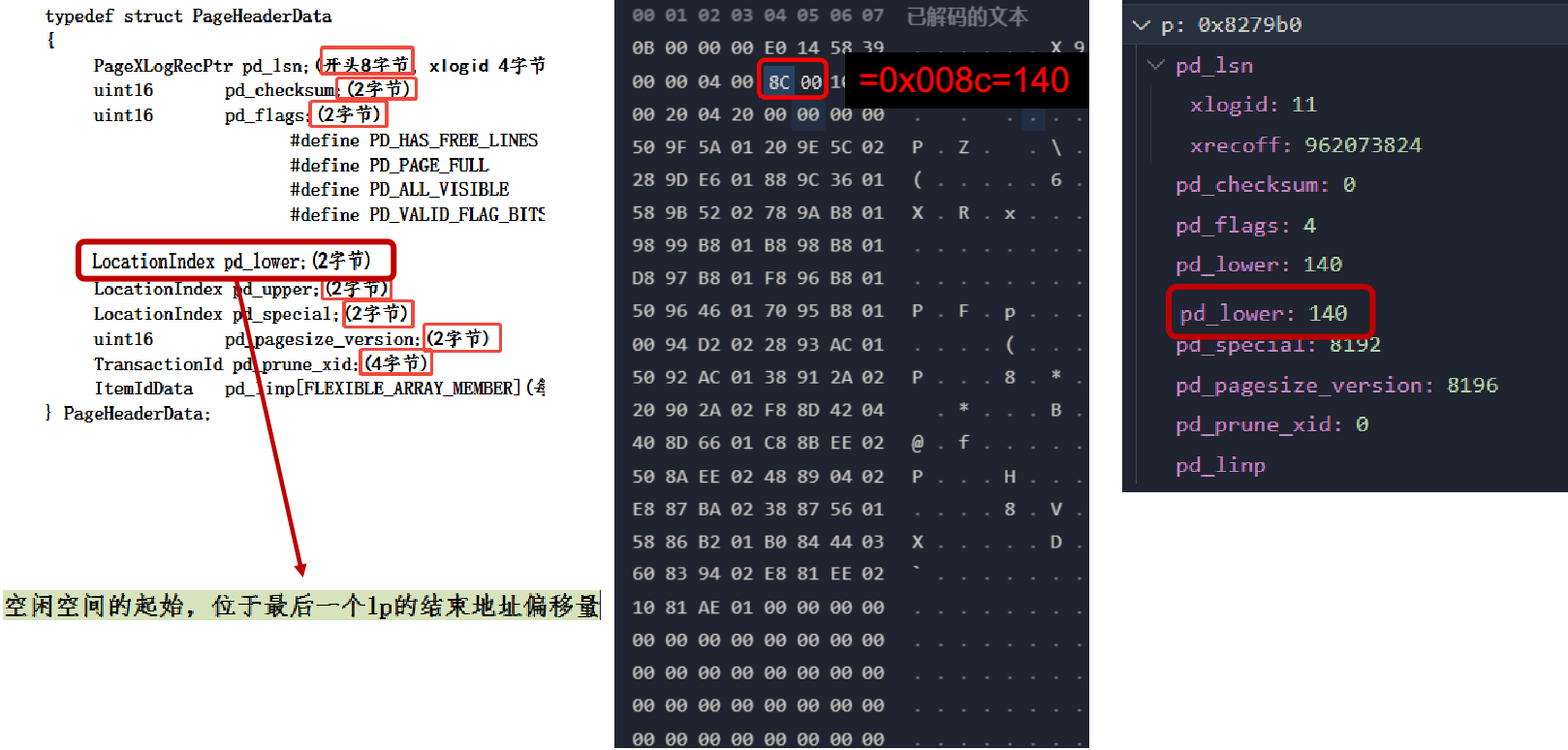
数据页的核心构成
数据页主要由两部分组成:目录(Line Pointer 数组) 和 数据区域(Tuple Data)。目录用于记录每条元组在页内的偏移量、标志位及长度信息,每个行指针占 4 个字节,用于定位对应的数据记录。
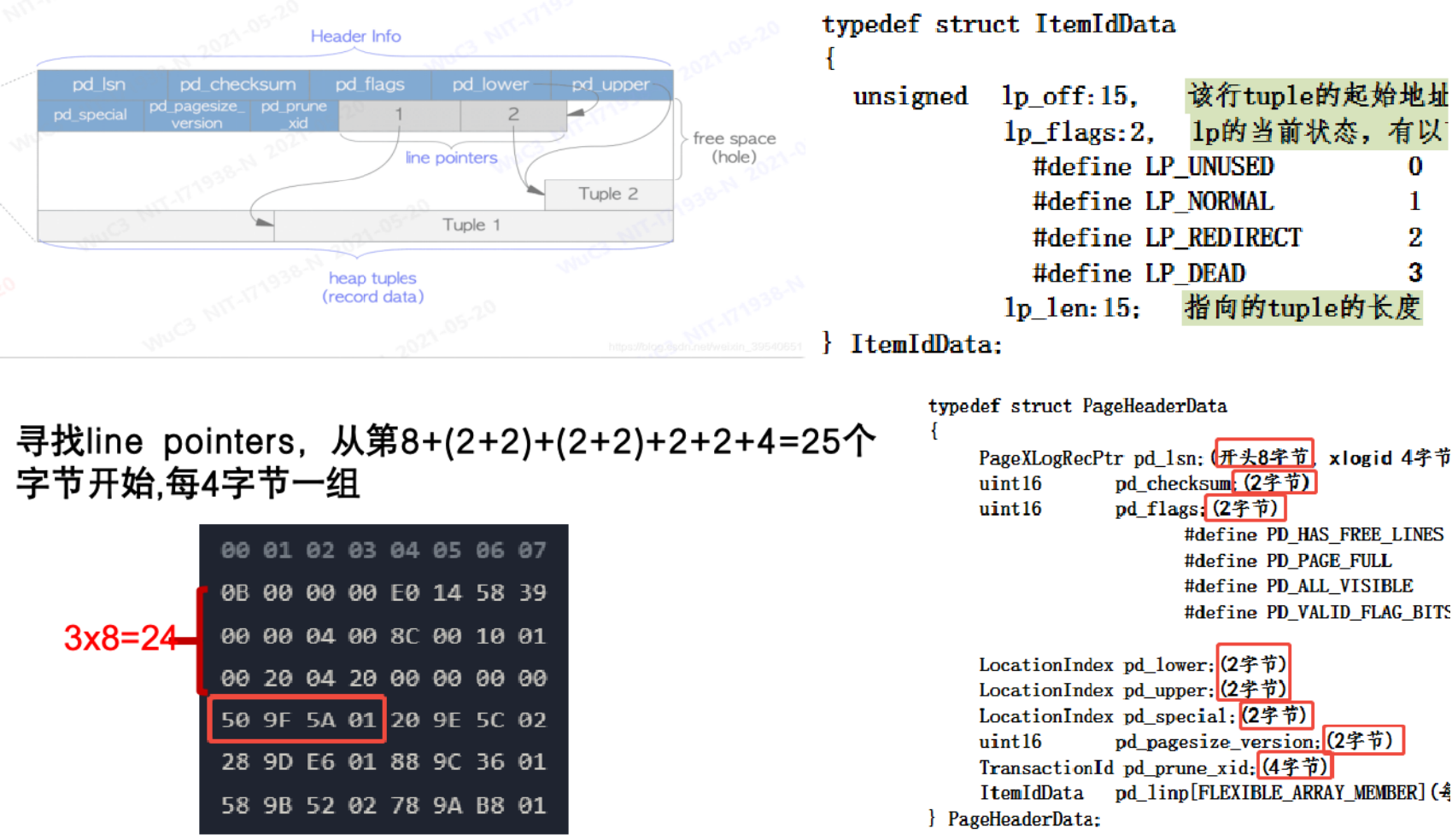
获取到单条 ltemld 之后,在偏移量 lp_off 获取 tuple。
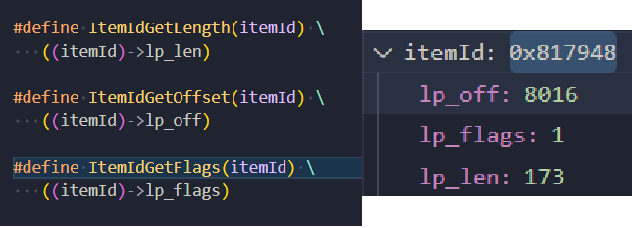
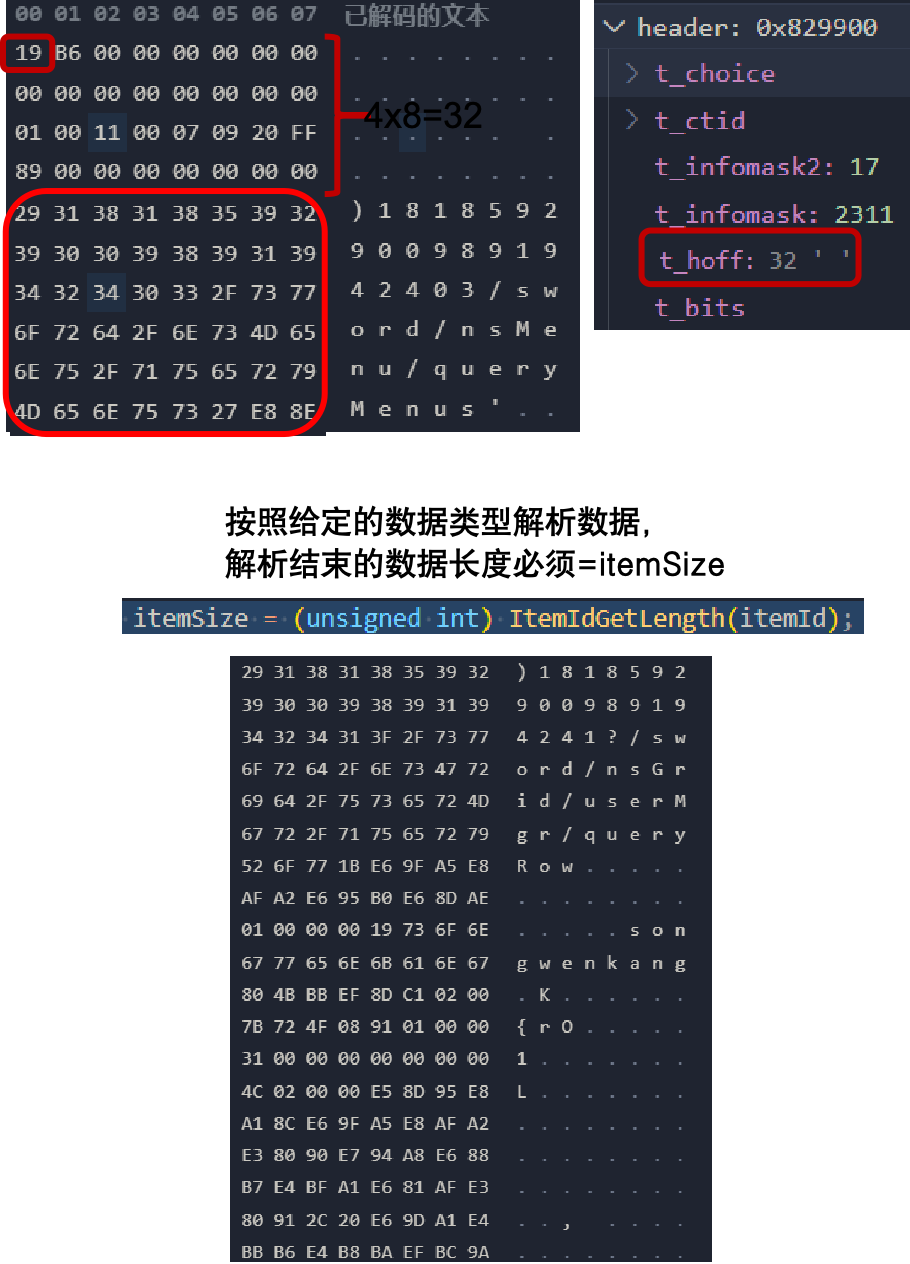
从 tuple 中定位数据区域
当定位到具体元组后,可通过行指针获取其头部信息(Tuple Header)。其中,t_hoff 表示元组头长度,用于计算实际数据的起始位置;lp_len 表示元组总长度。由于 PostgreSQL 的数据存储中列与列之间不存在分隔符,因此在解析时必须严格按照数据类型定义逐字节读取,确保解析出的长度与目录记录一致,才能确认数据读取正确。
5 张基表
聚焦于系统在解析存储文件中 5 张基表 时的处理机制。通过读取并解析这些基表中的 tuple,系统能够还原数据库对象的定义信息,包括表结构、字段属性以及对象间的依赖关系。该过程为数据字典的初始化提供了底层支撑,是数据库启动阶段恢复核心元数据的关键步骤。
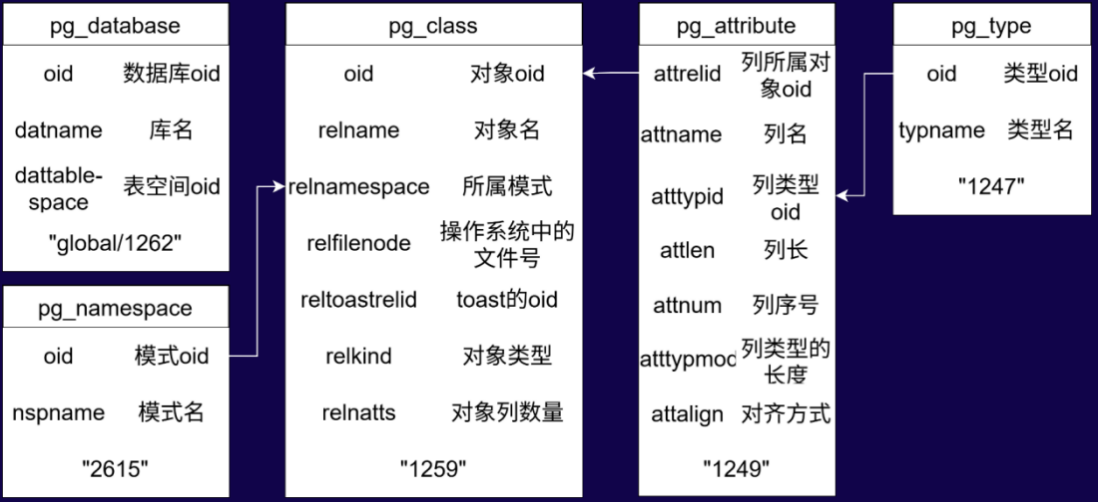
- 从 global/1262 中获取数据库的 oid 得到对应目录。
- 从“数据库 oid/2615”“数据库 oid/1259”“数据库 oid/1249”“数据库 oid/1247”5 张基表中获取整库的所有记录。
- 按照上图的对应关系拼凑出每张表的所有信息。
PDU 数据字典最终形态
PDU 在获取数据字典后,会将解析结果存储在可执行目录下的 meta 原数据目录中。系统会为每个数据库生成对应的 _tables.txt 文件,例如检测到数据库 alldb,则会在 meta 下生成 clothes_space_tables.txt 文件。
文件中每一行代表一张表,包含表 ID、文件号(默认一致)、TOAST ID 及文件号、模式 ID、表名、列名、列类型名、列数量与类型长度等。最后两列为列长度和类型对齐方式,其中列长度为 -1 表示变长类型(如 varchar、numeric),定长类型(如 int、float)则对应具体字节长度。对齐方式用于控制字节排列,以保障解析与计算的准确性。
下图为数据字典最终形态:

踩坑指南
在 PostgreSQL 数据文件和 TOAST 文件的脱离数据库读取过程中,有几类情况需要格外注意,以避免解析错误或数据丢失。
-
drop 列需在初始化与数据解析阶段进行特殊处理。
![图片16.png]()
-
reltoastrelid 不是 filenode,只是 oid。
![图片17.png]()
-
在脱离数据库环境读取 TOAST 数据时,需要格外谨慎。


默认情况下,toast oid 与 toast filenode 一致, external 结构体中保存的是 toast oid 。
vacuum full/truncate 之后,两者不再一致,但是 external 结构体中存的依然是 toast oid。

国产 PG 系数据库适配
在国产 PostgreSQL 系数据库的适配过程中,不同厂商对数据文件和 WAL 日志均有一定修改。
在数据文件页头方面,一些数据库增加了额外字节或填充零,使得原生读取函数无法直接解析。通过分析固定的字节模式,可以推断新增字段或填充值的位置,从而调整读取逻辑,使页头的 lower、upper 等关键字段正确解析。
在 WAL 日志适配方面,部分数据库增加了额外类型,改变了原有类型的编号顺序。为保证数据恢复功能,需要重新映射类型 ID,以正确识别 XLOG、HEAP、BTREE 等关键记录。
PDU 核心价值与性能优化
PDU 分为社区版和专业版,专业版的许可与服务器绑定。PDU 的核心价值在于数据恢复的速度——对于急需恢复生产环境的客户,解析数据的效率至关重要。
在实际使用中,TOAST 数据的解析是性能瓶颈所在。社区版存在限速,专业版全速解析时也会因 TOAST 数据量大而明显下降。为提升性能,开发者尝试了多线程,但发现瓶颈依然在 TOAST 解析上。针对这一问题,进行了结构优化:原本的全表扫描方式改为类似目录索引的解析方式。以一张 200MB、含 18,045 条数据的高密度 TOAST 表为例,优化前解析耗时约 800 秒,优化后降至 1.6 秒,同时解析结果与原数据完全一致。
这一优化显著提升了 PDU 的实际应用效率,也体现了其在灾难恢复场景下的核心价值。
结语
通过对 PostgreSQL 内核数据结构的深度解析和性能优化,PDU 显著提升了大规模数据恢复的效率与准确性,为数据库运维提供了可靠、可落地的灾难恢复能力,同时兼顾不同厂商版本的兼容性,实现了高效、安全的数据恢复实践。