调整博客结构,本以为 C++ 是最后一块,一查还要学数据库、Redis、分布式,且现在新增帖博客,网页都要 2.4G,电脑可用内存都只有 300M 了,后期编辑、阅读更困难,甚至自己电脑都无法看了,索性把结构调整下。
所有涉及到此文搜的东西,如果搜不到就去上一篇 续:啃操作系统 搜
重新学 C++ (编程指北知乎的路线) (居然还有这么多要学的~~~~(>_<)~~~~)
这点逼玩意立志一周操翻他们
前言:
C++咋鸡巴学啊?也没个教程,跟之前刚开始 做项目 一样:看视频太 JB 墨迹,不看吧又不知道哪里有靠谱的教程(基础都会了不知道那些特性新语法去哪里学),书我又没钱买那个编程指北推荐的经典书,闲鱼同城不错,电子版又感觉太费眼睛
实在绝望,第二天来打开 编程指北,发现编程指北相见恨晚,很简单清晰的路线,而很多人评论说编程指北难上天了都,他们喜欢速成
本来之前就看过他的没在意,这开始离职学习的时候选定 C++,然后发现了编程指北的Linux C++,小林coding 里也有机械上岸腾讯的,然后查发现 C++ 高薪的也就:
金融(高频交易、量化交易)—— 但现在太遥远
游戏 —— 不喜欢
还有就是这 Linux C++ 服务端开发
大概看下指北的路线发现 Linux C++ 服务端开发需要学如下几个东西:
C/C++ 语言特性和实现原理
计算机网络
网络编程 和 Linux 系统编程
操作系统原理
部分 Linux 内核原理,如内存管理、文件系统、虚拟内存等
Linux 常见命令使用
算法与数据结构
数据库使用及原理
常见 NoSQL组件,如 Redis、Memcached
版本控制 Git
但他实际写的时候,并没有全说,大概说的就足够了,说的有:
他文章里的序号:
三、C++
四、OS(通过小林coding会了,只需要看自己博客回顾就行了)√
五、网络(通过小林coding会了,只需要看自己博客回顾就行了)√
六、网络编程(只需要看自己博客回顾就行了)√
七、系统编程(我打算找工作之前放弃这个)
八、数据库
九、算法(妈逼的老子刷的会的一个没有,一屁眼子链表指针)
编程指北的文章风格真的好像我啊(我也像写公众号文章细致的鱼皮),但应该不适合99%的人
他这网站 UI 不错,但观看体验比小林差远了啊(唯独小林的一行一行复制,这个复制也有限制但可以多行,再多就不行了),全是指导性的,我还得自己去找着看其他东西,不像小林coding一个网站就足够了。但起码有个清晰的东西做牵引也足够了,我就怕像之前一样学偏了
但他这网站写的,我的天这他妈的怎么像个傻逼一样,毫无逻辑啊,标题这个“指北”真他妈画蛇添足,而且面试的、C++的、Java的、计算机学习路线,全都杂揉在一起,毫无头绪啊,分类都乱七八糟的。里面介绍的项目,我 tm 连 github 还不会用,网站有时候又打不开,真不如自己写了。这些教程之前看菜鸟教程就踩过坑了,总感觉看完没啥用,而且他的“CS学习路线”全是说要看书我没那时间啊
他这文章真的跟我一样,总结的东西只有本人能看懂
用的豆包链接还是迭代 6 里的那个“涉及 C++ 语法的”、教程 参考链接(编程指北)
开始正文
Part 01 基础语法部分:
关于 sizeof 、 strlen、数组做参数退化为指针:
一群傻逼水货,就这也他妈是腾讯SP?func 连返回值都没写,占位符也不对,速成的所有人都他妈是狗。学的狗鸡巴不是。之前自己弄的太认真太深了,完全背道而驰,职场被这群用阳寿面试的垃圾狗,搞的乌烟瘴气的
本质:sizeof 是运算符(编译期计算),strlen 是函数(运行时计算)
对象:sizeof 可用于任意类型 / 变量,strlen 仅用于以 '\0' 结尾的字符串
结果:sizeof 含结束符 / 对齐填充,strlen 仅计有效字符(不含 '\0')
函数模板由两部分组成,是一个整体:
template <模板参数列表> // 模板声明(告诉编译器:这是一个模板) 返回值类型 函数名(参数列表) { // 函数定义(通用逻辑)// 函数体 }
template是 C++ 的模板关键字,用来定义通用模板,让函数 / 类能适配多种数据类型。这里
template <typename T, std::size_t N>声明了一个函数模板:
typename T:定义类型参数,代表数组元素的类型(这里传入的是char)
std::size_t N:定义非类型参数,代表数组长度,编译时自动推导函数参数
const T (&arr)[N]是数组的引用,通过模板参数N保留了数组的实际长度(避免退化为指针),所以sizeof(arr)能正确得到数组总字节数函数参数是const T (&arr)[N],这个参数的意思是:“我要接收一个数组的引用,这个数组的元素类型是
T,长度是N”。参数类型必须是 T,即与模版声明的占位符一致当传入
str(类型char str[] = "Hello world";)时:
编译器会发现:这个数组的元素类型是
char→ 所以T就是char。这个数组的长度是 12 → 由于有
&变成数组引用后不会发生指针退化,编译器可以从传入的数组中自动推导出N(真实元素个数)如果不用
&,直接写成template <size_t N>int func(const char array[N])C++ 有个隐藏规则:数组作为函数参数时会自动退化为指针:
// 看似接收数组,实际会被编译器转为:void func(const char* arr) void func(const char arr[14]) {cout << sizeof(arr); // 结果是8(64位指针大小),而不是14,14完全没用,只是个 “形式上的数字” }
int func(char array[])里,char array[]本质是char* array(指针) ,这是 C/C++ 的历史设计,退化为指针的写法会警告,当数组作为函数参数时,会自动「退化成指针」,丢失原数组的长度信息。回顾我写代码的几个警告:(参照编程指北)
1、如果这样会退化的版本写
func函数参数char array[]实际被视为char*(指针),用sizeof(array计算其大小得到的是指针字节数(非数组总大小),触发警告。2、
printf中%d用于int,这里会触发警告。因为sizeof返回标准定义是size_t,在多数系统会被typedef为long unsigned int(无符号长整型)即系统的具体实现形式即
sizeof和strlen都返回size_t,用zu3、
func声明返回int,但无return语句,会触发警告,因为返回值不可控,属于逻辑隐患
如果这么写:
// 定义模板函数,参数为退化数组 template <size_t N> // 声明非类型模板参数N void func(const char arr[N]) { // arr会退化为指针,N无法自动推导// 函数逻辑 }// 调用时必须手动指定N int main() {char str[] = "Hello world";func<12>(str); // 显式指定N=12,否则编译报错 }直接调用
func(str)而不指定N,会报错(无法推导模板参数N);如果手动指定N(如func<12>(str)),则不会报错,但N仅为你传入的数字,与数组真实长度无关
正确写法:
#include <iostream> #include <cstring> using namespace std; template <typename T, std::size_t N> void printSizeAndLength(const T (&arr)[N]) {cout << sizeof(arr) << endl; //12std::cout << strlen(arr) << std::endl; //11 }/* //表面是数组参数,实际会被编译器当作指针(char*)处理,会警告 int func(char array[]) {printf("sizeof=%zu\n", sizeof(array));printf("strlen=%zu\n", strlen(array));return 0;//没这个也会警告 } */int main() {char str[] = "Hello world";cout << sizeof(str) << endl;//输出12cout<<strlen(str)<<endl;//输出11// func(str);printSizeAndLength(str); }
const char (&array)[N]的本质:这是一个 “对长度为N的const char数组的引用”。&在这里不是修饰N,而是修饰array,表示array是一个引用类型(引用的对象是 “长度为N的数组”)。
N的推导逻辑:当你传入一个具体的数组(比如char str[] = "Hello world";)时:
数组
str的真实长度是固定的("Hello world"包含 11 个字符 + 1 个终止符\0,共 12 个元素)。由于
&阻止了数组退化为指针,编译器能完整获取数组的类型(char[12])。因此,编译器会自动将
N推导为数组的实际长度(这里是 12)。
N与引用的关系:N本身是 “数组长度”,而引用(&)是让编译器能够 “看到” 这个长度的手段。没有&的话,数组会退化为指针,丢失长度信息,N就无法推导了
N是数组的元素个数,sizeof(arr)计算的是整个数组的总字节数如果不顾及警告,func 那输出的是8、11,因为
strlen的原理是从指针指向的地址开始,逐个字符计数,直到遇到'\0'为止,和指针本身的类型无关。
当数组直接作为
sizeof的参数时,它不会退化,因为 sizeof 是编译器在编译期间计算的结果,这个时候编译器是有信息知道数组的大小。
重点说完再说几个小知识:
指针固定大小,32位就是 4 字节,64位就是 8 字节
int arr[10];的sizeof(arr)是 40
#include <iostream>int main() {int a = 42;std::cout << "Size of int: " << sizeof(int) << std::endl; // 输出 int 类型的大小,4std::cout << "Size of a: " << sizeof(a) << std::endl; // 输出变量 a 的大小,4std::cout << "Size of double: " << sizeof(double) << std::endl; // 输出 double 类型的大小,8 }
感觉这么追问好像也不用看那个什么候捷内存管理的视频,和各种推荐的经典书了
关于 字节对齐:
#pragma pack(push, n):push表示 “保存当前的对齐设置” 到一个内部栈中(局部变量也在栈上,生命周期和调用函数绑定)。n是新的对齐值(如 1、2、4 等),之后定义的结构体将按n字节对齐。
#pragma pack(pop):从栈中 “恢复” 之前保存的对齐设置,之后的结构体按恢复后的规则对齐。若未写
pop:对齐设置会一直生效到当前编译单元(.cpp 文件)结束#pragma pack(push, 1) // 设置字节对齐为 1 字节,取消自动对齐 struct UnalignedStruct {char a; // 类型:char,大小:1字节(固定)int b; // 类型:int,大小:4字节(通常情况)short c; // 类型:short,大小:2字节(固定) };假设从0地址开始:
char a:
- 从地址
0开始存储(因为是第一个成员,默认从 0 开始)。- 占用
1字节(地址 0)。- 此时已用地址:
0。int b:
- 因为按 1 字节对齐,不需要填充,直接紧跟在
a后面。- 从地址
1开始存储(a用完了地址 0)。- 占用
4字节(地址 1、2、3、4)。- 此时已用地址:
0~4。short c:
- 同样按 1 字节对齐,直接紧跟在
b后面。- 从地址
5开始存储(b用完了地址 1~4)。- 占用
2字节(地址 5、6)。- 此时已用地址:
0~6。所以
sizeof(UnalignedStruct)的结果是7。如果没有
#pragma pack(push, 1)(默认对齐)如果去掉这个指令,默认按 “最大成员大小” 对齐(这里int是 4 字节,所以按 4 字节对齐):
a占地址 0,之后需要填充 3 字节(地址 1~3),才能让b从 4 的倍数地址(4)开始。b占地址 4~7。c占地址 8~9,之后需要填充 2 字节(地址 10~11),让总大小是 4 的倍数。总大小会变成 12 字节。
练习:
查看代码
#include <iostream>#pragma pack(push, 1) // 设置字节对齐为 1 字节,取消自动对齐 struct UnalignedStruct {char a;int b;short c; }; #pragma pack(pop) // 恢复默认的字节对齐设置struct AlignedStruct {char a; // 本来1字节,padding 3 字节int b; // 4 字节short c; // 本来 short 2字节,但是整体需要按照 4 字节对齐(成员对齐边界最大的是int 4) // 所以需要padding 2// 总共: 4 + 4 + 4 };struct MyStruct {double a; // 8 个字节char b; // 本来占一个字节,但是接下来的 int 需要起始地址为4的倍数//所以这里也会加3字节的paddingint c; // 4 个字节// 总共: 8 + 4 + 4 = 16 };struct MyStruct1 {char b; // 本来1个字节 + 7个字节paddingdouble a; // 8 个字节int c; // 本来 4 个字节,但是整体要按 8 字节对齐,所以 4个字节padding// 总共: 8 + 8 + 8 = 24 };int main() {std::cout << "Size of unaligned struct: " << sizeof(UnalignedStruct) << std::endl; // 输出:7std::cout << "Size of aligned struct: " << sizeof(AlignedStruct) << std::endl; // 输出:12,取决于编译器和平台std::cout << "Size of aligned struct: " << sizeof(MyStruct) << std::endl; // 输出:16,取决于编译器和平台std::cout << "Size of aligned struct: " << sizeof(MyStruct1) << std::endl;// 输出:24,取决于编译器和平台 }padding 填充:
比如
int类型(4 字节),必须从 “4 的倍数” 地址开始(如 4、8、12、16...);
double类型(8 字节),必须从 “8 的倍数” 地址开始(如 0、8、16...)。如果数据放在非对齐地址上,硬件访问会变慢,甚至某些硬件直接报错(无法读取)
重点总结:
成员间填充是为了让下一个成员地址符合其自身对齐倍数;最后整体填充是为了让总大小符合最大成员的对齐倍数。
如果总大小不是倍数,假设
Example结构体总大小是 18 字节(不是 8 的倍数,而里面有 double),当它被声明为数组时:Example arr[2]; // 两个结构体实例
第一个实例
arr[0]从地址 0 开始:内部的double b能正确放在 8 的倍数地址(8),没问题第二个实例
arr[1]会从地址 18 开始(因为第一个实例占 18 字节):此时arr[1].a在 18,接下来要放double b,需要从 8 的倍数地址开始。但 18+1(a 的大小)=19,离下一个 8 的倍数(24)差 5 字节,填充 5 字节后,b只能放在 24。看起来好像能工作?但问题在于:arr[1]的起始地址 18 不是 8 的倍数,而结构体的最大对齐边界是 8,这本身就违反了 “结构体实例的起始地址必须是最大对齐边界倍数” 的规则。更严重的是,如果结构体内部还有更复杂的成员,这种错位会层层传递
再比如,结构体含
char a和double b,最大对齐边界 8,总大小是 16
第一个实例
arr[0](起始地址 0,8 的倍数):
char a占 0(1 字节);填充 7 字节(1~7),让
double b从 8(8 的倍数)开始,占 8~15;总大小 16(0~15),正确。
第二个实例
arr[1](起始地址 16,8 的倍数):
char a占 16(1 字节);必须填充 7 字节(17~23),让
double b从 24(8 的倍数)开始,占 24~31;总大小 16(16~31),正确。
至此才懂,而文章的编程指北博主和下面的讨论都他妈一群傻逼水货, 大厂就这逼样啊?评论和写文章的本人真的理解了吗?
小知识:
struct EmptyStruct {};的sizeof是1,原因是:C++ 标准规定,任何非空类型的实例都必须有唯一的内存地址,空结构体也不例外。如果空结构体的大小为 0,那么当它作为数组元素或作为其他结构体的成员时,会导致多个实例共享同一个相同的地址,假设空结构体EmptyStruct大小为 0:
定义数组
EmptyStruct arr[2];时,数组元素的地址计算规则是:&arr[i] = &arr[0] + i * sizeof(EmptyStruct)。由于
sizeof(EmptyStruct)=0,则&arr[1] = &arr[0] + 1*0 = &arr[0],即两个元素地址完全相同
关于 const:
查看代码
真就是同行衬托,之前学的时候记录了小林coding的一堆问题,
现在看编程指北发现纯他妈水货一个,
这文章写的真鸡巴差劲
衬托发现小林写的够好了和菜鸟教程一样,每个都能自己扩展好多文章没我给他重新润色真鸡巴傻逼就这理解程度都能去腾讯妈逼的正常成长轨迹都能去微软谷歌了,奈何国外可不像国内这么傻逼我甚至以为这些是防止大家学会给他们增加竞争力的为啥有钱人都歪瓜裂枣的,为啥大厂的好多都感觉啥也不是,感觉厉害的年薪又不高const 是只读
const int a = 10; a = 20; // 编译错误,a 是只读变量,不能被修改想去掉只读就用类型强制转换
const_cast,但用不好会崩溃或未定义。实际
const int a = 10; const int* p = &a; int* q = const_cast<int*>(p); *q = 20; // 通过指针间接修改 const 变量的值 std::cout << "a = " << a << std::endl; // 输出 a 的值,结果为 10先科普下硬编码:直接把值写死在代码里,而非从变量或内存中读取。
对
const变量,编译器可能优化成 “只写内存一次,之后直接用硬编码值”,之后不从内存读,所有用到 a 的地方都替换成字面量 10,即内存的对应位置确实改成 20了,但 cout << a 输出是硬编码没懂 10,不是内存实际值既然通过指针改没用,那咋改?提供了
const_cast,不是说会导致问题吗?那咋还用?具体用法:
用法1、处理 “
const误标” 的接口调用一个老旧库的函数,它参数要求
非 const char*,但你手里只有const char*(比如字符串字面量)。此时用const_cast去掉const,可以让代码兼容,前提是你确定函数不会真的修改内容(否则行为未定义)void oldFunc(char* str) { /* 实际没修改 str */ }int main() {const char* s = "hello";// oldFunc(s); // 直接传会报错,因为类型不匹配oldFunc(const_cast<char*>(s)); // 合法兼容(假设函数真的不修改) }用法2、实现 “逻辑
const” 的成员函数class Cache {mutable std::string cachedData; // mutable 表示可在 const 函数修改,但这里用 const_cast 演示另一种思路bool cacheValid = false;public:std::string getData() const {if (!cacheValid) {// 这里 this 是 const Cache*,需要去掉 const 才能修改成员const_cast<Cache*>(this)->cachedData = "real data";const_cast<Cache*>(this)->cacheValid = true;}return cachedData;} };开始解读:
mutable是 C++ 关键字,为“特许改”,用于修饰类的成员变量,打破const成员函数的限制 —— 让被修饰的变量即使在const成员函数中也能被修改
const为“限制改”解读这个代码需要很多前设知识, 开始说前设知识:
前设知识 —— 类:
类的基本结构:
class 类名 {// 这里放“属性”(也叫“成员变量”)—— 描述这个类有什么数据数据类型 变量名1;数据类型 变量名2;public: // “public”表示后面的内容是“公开的”,外面可以直接用// 这里放“功能”(也叫“成员函数”)—— 描述这个类能做什么返回类型 函数名1() {// 函数里的具体操作}返回类型 函数名2() {// 函数里的具体操作} };一个简单的学生类
class Student {// 属性(成员变量):学生的名字、年龄(这些是“内部数据”)string name; // 名字int age; // 年龄public: // 公开的功能// 功能1:设置学生的信息void setInfo(string n, int a) {name = n; // 给名字赋值age = a; // 给年龄赋值}// 功能2:打印学生的信息void printInfo() {cout << "名字:" << name << ",年龄:" << age << endl;} };咋用这个类?
类只是 “模板”,必须根据模板造出 “实物” 才能用,这个 “实物” 叫 “对象”,就像根据手机图纸造出真实的手机:
int main() {// 创建一个Student类的对象(实例),名字叫“stu”Student stu;// 用对象调用公开的功能(通过“.”符号)stu.setInfo("小明", 18); // 调用setInfo功能,设置信息stu.printInfo(); // 调用printInfo功能,打印信息 }输出::
名字:小明,年龄:18怎么理解代码里的符号?
.符号:当你有一个 “对象”(比如stu),想调用它的功能或访问属性时,用对象.功能()或对象.属性(前提是属性是公开的)。
例:stu.setInfo(...)、stu.printInfo()
->符号:如果手里不是 “对象” 本身,而是 “指向对象的指针”(可以理解为 “对象的地址”),就用指针->功能()或指针->属性Student stu; // 创建对象stu Student* p = &stu; // p是“指向stu的指针”(存的是stu的地址) p->setInfo("小红", 17); // 用指针调用功能,等价于 stu.setInfo(...) p->printInfo();
this指针:在类的 “成员函数”(比如setInfo、printInfo)内部,有一个隐藏的指针叫this,它自动指向当前正在使用的对象。比如调用
stu.setInfo(...)时,setInfo函数里的this就指向stu;调用
p->setInfo(...)时,setInfo函数里的this就指向p所指的对象(还是stu)。所以在函数里可以用this->属性来明确表示 “当前对象的属性”,比如:void setInfo(string n, int a) {this->name = n; // 等价于直接写 name = n(因为this默认指向当前对象)this->age = a; // 等价于直接写 age = a }(平时可以省略
this->,但它确实存在)C++ 为何牛逼?我也不知道,但问了豆包 C 该咋写?如下
C 写法:
查看代码
#include <stdio.h> #include <string.h> // 定义学生结构体(类似类的属性) struct Student {char name[20]; // 名字int age; // 年龄 };// 模拟"设置信息"的功能(类似类的成员函数) void setInfo(struct Student* stu, const char* name, int age) {strcpy(stu->name, name); // 给名字赋值stu->age = age; // 给年龄赋值 }// 模拟"打印信息"的功能 void printInfo(const struct Student* stu) {printf("名字:%s,年龄:%d\n", stu->name, stu->age); }int main() {// 创建结构体变量(类似对象)struct Student stu;// 调用函数(通过结构体指针访问,类似"."操作符)setInfo(&stu, "小明", 18); // 传入结构体地址printInfo(&stu); }
C 语言用
struct定义结构体,没有public这类访问控制没有成员函数,只能通过普通函数 + 结构体指针来操作数据
用
->符号通过指针访问结构体成员(替代 C++ 的.操作符)必须显式传递结构体地址作为函数参数(C++ 的
this指针是隐藏的)至此科普完一些 前设知识 可以讲 用法2 那个代码了:
先忽略
const相关的词:class Cache {// 属性(成员变量)std::string cachedData; // 缓存的数据bool cacheValid = false; // 缓存是否有效的标记(false=无效)public:// 功能(成员函数):获取数据std::string getData() { // 先去掉const,简化理解if (!cacheValid) { // 如果缓存无效(需要更新)// 给当前对象的cachedData赋值this->cachedData = "real data"; // this指向当前Cache对象this->cacheValid = true; // 标记缓存有效}return cachedData; // 返回缓存的数据} };
Cache是一个 “缓存类”,用来存数据(cachedData),并记录数据是否有效(cacheValid)。- 调用
getData()功能时,先检查缓存是否有效:
- 如果无效(
cacheValid是false),就更新cachedData,并标记为有效(cacheValid = true)。- 如果有效,直接返回已有的
cachedData(不用重复更新,节省时间)。最后解释为什么提到
mutable和const_cast?之前的代码里,getData()后面有个const(getData() const),这个const表示 “这个函数承诺不修改类的属性”。但实际场景中,我们需要在这个函数里修改
cachedData和cacheValid(否则无法更新缓存),所以有两种解决办法:
用
mutable修饰这两个属性(mutable std::string cachedData;),表示 “即使在const函数里也能修改它们”。用
const_cast临时去掉this的const限制(const_cast<Cache*>(this)->cachedData = ...),强制允许修改
因此有两种写法都可以:
查看代码
//写法一、 #include <iostream> #include <string>class Cache {std::string cachedData;bool cacheValid = false;public:std::string getData() const {if (!cacheValid) {const_cast<Cache*>(this)->cachedData = "real data";const_cast<Cache*>(this)->cacheValid = true;}return cachedData;} };//写法二、 #include <iostream> #include <string>class Cache {mutable std::string cachedData;mutable bool cacheValid = false;public:std::string getData() const {if (!cacheValid) {cachedData = "real data";cacheValid = true;}return cachedData;} };顺便记录下调教豆包的关键词,起初像挤牙膏一样很墨迹心累,后来用了这个自己创造的提示词,解释的透彻了
查看代码
if (!cacheValid) { // 如果缓存无效(cacheValid是false)// 这里需要更新缓存const_cast<Cache*>(this)->cachedData = "real data";const_cast<Cache*>(this)->cacheValid = true; } return cachedData; // 返回缓存的数据 这里什么this、→、我完全看不懂 我对C++完全0基础 另外这里说:mutable 表示可在 const 函数修改,但这里用 const_cast 演示另一种思路 啥意思 ??演示的到底是啥啊?语言表达这么歧义吗???不就是想做演示const吗? 咋又扯到mutable了?????你解释东西先别解释这些const、const_cast啥的了!!!我连最基基本的类public这些都不懂从最基础讲起至此把这个傻逼说的展开学习完毕
继续
const 修饰函数参数
void func(const int a) {// 编译错误,不能修改 a 的值a = 10; }安全,避免在函数内部无意中修改传入的参数值。
尤其是 引用 作为参数,
void func(const int& a) { ... },如果确定不会修改引用,那么一定要使用 const 引用。&是引用的标志,const int& a表示 a 是 int 类型的 const 引用
继续
const 修饰函数
妈逼的感觉讲的跟垃圾菜鸟教程有一拼,艹,甚至都不如菜鸟教程,老子看你教程,就因为比菜鸟教程好在:紧贴时事不过时2025年的、紧紧围绕大厂不至于学偏。起初看他公众号我还以为多牛逼,但就这,就已经他妈是这行业里大佬了,呵呵
#include <iostream> using namespace std; const int func() {int a = 10;return a; }int main() {const int b = func(); // b 的值为 10,不能被修改// b = 20; // 编译错误,b 是只读变量,不能被修改cout<<b<<endl; }这里例子都他妈没举好
函数返回值的const作用的是函数返回的临时值本身,但这个临时值在赋值给变量时会发生拷贝,而拷贝后的变量是否可修改,由变量自己的类型决定。代码里,
一个修饰函数返回值,一个修饰变量本身。具体来说:
当你写
int b = func()时,函数返回的const int是一个临时值(比如10),这个临时值确实是const的(不能被修改),但它会被拷贝给变量b。此时b的类型是int(非const),所以b可以被修改,没啥意义。如果返回的是指针或引用,
const的意义就很大了。比如:const int* func() { // 返回指向const int的指针static int a = 10;return &a; }int main() {int* p = func(); // 编译错误!因为func返回的是const int*,不能赋值给int*const int* p2 = func(); // 正确,p2不能通过指针修改a的值return 0; }
const int* p2 = func()中,const int*修饰的是 指针p2所指向的内容,限制的是:不能通过p2这个指针来修改它指向的变量a的值。p2指向的是func()里的static int a(值为 10)。因为p2是const int*类型,所以像*p2 = 20;这样的代码会编译错误(禁止通过p2修改a)。但a本身不是const变量,如果在func()内部或通过其他非const指针,仍然可以修改a(比如在func()里加a = 20;)。但 p2 可以指向其他
简单说:
const int* p2的const是给指针p2加的 “限制”,让它不能当 “修改工具”,和变量a本身是否可改无关
看下面的评论真他妈纯浪费时间,都是一坨屎。洛谷 和 poj 的那才叫评论
我这么细心钻研,我一定要超过 鱼皮 和 编程指北
无意间读到的:这都啥水平啊?才发现吗?
继续
有了豆包的讲述,看他的才懂,直接复制过来,不用我多逼逼
const 修饰 指针 或 引用
1、指向只读变量的指针
这种情况下,const 关键字修饰的是指针所指向的变量,而不是指针本身
因此,指针本身可以被修改(意思是指针可以指向新的变量),但是不能通过指针修改所指向的变量
const int* p; // 声明一个指向只读变量的指针,可以指向 int 类型的只读变量 int a = 10; const int b = 20; p = &a; // 合法,指针可以指向普通变量 p = &b; // 合法,指针可以指向只读变量 *p = 30; // 非法,无法通过指针修改只读变量的值const int*声明了一个指向只读变量的指针p。我们可以将指针指向普通变量或者只读变量,但是无法通过指针修改只读变量的值。
2、只读指针
const 关键字修饰的是指针本身,使得指针本身成为只读变量。
因此,指针本身不能被修改(即指针一旦初始化就不能指向其它变量),但是可以通过指针修改所指向的变量。
int a = 10; int b = 20; int* const p = &a; // 声明一个只读指针,指向 a *p = 30; // 合法,可以通过指针修改 a 的值 p = &b; // 非法,无法修改只读指针的值在上面的例子中,我们使用
int* const声明了一个只读指针p,指向变量a。我们可以通过指针修改a的值,但是无法修改指针的值3、只读指针指向只读变量
const 关键字同时修饰了指针本身和指针所指向的变量,使得指针本身和所指向的变量都成为只读变量。
因此,指针本身不能被修改,也不能通过指针修改所指向的变量。
const int a = 10; const int* const p = &a; // 声明一个只读指针,指向只读变量 a *p = 20; // 非法,无法通过指针修改只读变量的值 p = nullptr; // 非法,无法修改只读指针的值4、常量引用
先科普:
在 C++ 中,&有两种常见含义,需要根据语境区分:
当
&用于变量声明时(如int& b),它表示 “引用”,不是地址。
const int& b = a中,b是a的常量引用,本质是a的 “别名”,指向原数据a本身,而非副本。这里的
&是引用的语法标志,不是取地址,所以b直接关联原数据a,但因为有const,不能通过b修改a当
&用于表达式中(如&a),它才表示 “取地址”,获取变量的内存地址int x = 10; int* p = &x; // 这里的&是取地址,获取x的内存地址,赋值给指针p
&x是表达式中的&,作用是获取变量x在内存中的地址,结果是一个指针值,被赋值给指针变量p简单说:声明时的
&是 “引用”(绑定原数据),表达式中的&是 “取地址”(获取内存位置)回到这里的常量引用:引用一个只读变量的引用,因此不能通过常量引用修改变量的值
const int a = 10; const int& b = a; // 声明一个常量引用,引用常量 a b = 20; // 非法,无法通过常量引用修改常量 a 的值5、修饰成员函数
成员函数后加
const是 C++ 特殊语法,修饰整个函数不修改成员变量科普:
对象是一个完整的实体,成员是对象内部的组成部分(数据和方法)
成员函数是:对象的行为、操作方法
对象中成员变量的值的集合叫:对象状态
例如,一个 "人" 对象:
- 成员变量(状态):年龄、姓名等;
- 成员函数(行为):吃饭、走路等。
回到这里
class A { public:int func() const {// 编译错误,不能修改成员变量的值m_value = 10;return m_value;} private:int m_value; };A是类,定义了对象的属性(成员变量)和行为(成员函数)。而对象是类的实例化结果,比如
A obj;这句代码会创建一个A类的对象obj
const成员函数的作用是保证该函数不修改对象的状态(即不改变成员变量的值)这样有个好处是,const 的对象就可以调用这些成员方法了,因为 const 对象不允许调用非 const 的成员方法
核心场景:
const对象调用成员函数假设你创建了一个
const修饰的对象(比如const A obj;),因为对象是 “只读” 的,C++ 规定:const对象只能调用用const修饰的成员函数,否则编译器会报错(防止函数里偷偷改对象数据)。为啥需要
const成员函数?给成员函数加
const(像int func() const),是在 “承诺”:
这个函数里不会修改对象的成员变量(如果写了m_value = 10;,编译器直接报错,强制保证 “只读”)这样,
const对象调用它时,就不用担心自己的数据被偷偷改掉,符合 “只读” 的逻辑。比如:
class A { public:// const 成员函数,承诺不修改成员变量int func() const {// 尝试修改 m_value,编译报错!// m_value = 10; return m_value;}// 普通成员函数(无 const),没承诺“只读”void setValue(int v) {m_value = v; // 这里会修改成员变量,没问题} private:int m_value; };int main() {const A obj; // const 对象,“只读”obj.func(); // 允许:func 是 const 成员函数,承诺不修改数据// obj.setValue(5); // 禁止:setValue 没加 const,可能修改数据,编译器报错return 0; }一句话总结:
const成员函数是给const对象用的 “安全接口”,通过禁止修改成员变量,让const对象调用时更安全、逻辑更自洽 。
关于 static:
回忆之前配合#if使用的是extern,跨文件
这个是仅限当前文件
static 修饰的全局变量:
作用域限定在当前文件,其他无法访问、声生命周期为整个程序
// a.cpp 文件 static int a = 10; // static 修饰全局变量 int main() {a++; // 合法,可以在当前文件中访问 areturn 0; }// b.cpp 文件 extern int a; // 声明 a void foo() {a++; // 非法,会报链接错误,其他文件无法访问 a }
static 修饰的局部变量:
可以使得变量在函数调用结束后不会被销毁,而是一直存在于内存中,下次调用该函数时可以继续使用
#include <iostream> using namespace std;void foo() {static int count = 0; // static 修饰局部变量count++;cout << count << endl; }int main() {foo(); // 输出 1foo(); // 输出 2foo(); // 输出 3 }没有 static,就都是输出 1
static 修饰函数:
非静态函数默认是外部链接,意味着编译器会将其符号(函数名)导出到全局符号表中。当多个
.cpp文件编译后链接时, linker 会检查全局符号表,如果出现同名函数(且参数列表不同也可能因重载以外的原因冲突),会报 “多重定义” 错误(multiple definition of xxx)// a.cpp void foo() { /* 实现1 */ } // 非静态,外部链接// b.cpp void foo() { /* 实现2 */ } // 非静态,外部链接而static修饰函数时:
函数会变成内部链接,其符号仅在当前
.cpp文件可见,不会导出到全局符号表因此,不同
.cpp文件中定义同名static函数时, linker 看不到彼此的符号,自然不冲突// a.cpp static void foo() { /* 实现1 */ } // 内部链接,仅a.cpp可见// b.cpp static void foo() { /* 实现2 */ } // 内部链接,仅b.cpp可见如果俩 .cpp 文件独立自然没啥,但实际开发中,大型项目往往会将多个
.cpp文件编译后链接成一个可执行程序。这时,非静态函数的 “外部链接” 特性就会导致:只要不同文件中有同名非静态函数,链接时就会因符号重复报错
.cpp源文件 → 编译器(g++/MinGW)编译 + 链接 → 生成.exe可执行文件 → 运行.exe。1. .cpp 文件(源文件)
2. 目标文件(.o 或 .obj 文件,可连接文件)
本质:编译器对
.cpp编译后的中间二进制文件(机器码雏形)。由来:用
g++ -c main.cpp生成main.o(-c表示只编译不链接)。特点:
包含机器能理解的二进制指令,但不完整(缺少外部函数 / 变量的地址)。
属于 “可连接文件”—— 必须通过链接器处理才能生成可执行文件
3. 可执行文件(.exe 或 二进制文件 / 机器文件)
本质:链接器处理目标文件后生成的完整二进制文件,也称 “机器文件”
由来:用
g++ main.o -o program.exe(链接目标文件)生成总结:.cpp文件(文本源码) → 编译 → 目标文件(.o/.obj,可连接的中间二进制) → 链接 → 可执行文件(.exe,完整二进制/机器文件)
目标文件是 “半成品” 二进制,需要链接才能用;
可执行文件是 “成品” 二进制,能直接被机器运行;
.cpp 文件是一切的起点,纯文本代码。
小实验:
main.cpp:
// main.cpp #include <iostream>void funcA(); // 声明A的接口 void funcB(); // 声明B的接口int main() {funcA(); // 输出:A的辅助函数funcB(); // 输出:B的辅助函数 }b.cpp:
// b.cpp #include <iostream> static void helper() { // 仅b.cpp可见,与a.cpp的helper不冲突std::cout << "B的辅助函数\n"; } void funcB() {helper(); // 调用自己的helper }a.cpp:
// a.cpp #include <iostream> static void helper() { // 仅a.cpp可见std::cout << "A的辅助函数\n"; } void funcA() {helper(); // 调用自己的helper }
方式 1(分步编译 + 链接):
# 1. 分别编译每个文件生成目标文件(.o) g++ -c a.cpp -o a.o g++ -c b.cpp -o b.o g++ -c main.cpp -o main.o# 2. 链接所有目标文件生成可执行程序 g++ a.o b.o main.o -o test# 3. 运行程序 ./test在 GCC/G++ 编译器中,
-c是编译选项,作用是只编译源代码,生成目标文件(.o 文件),不进行链接操作。方式 2(一步编译 + 链接):
# 直接编译所有源文件并链接,生成可执行程序后立即运行 g++ a.cpp b.cpp main.cpp -o test && ./test所以,
-o直接从.cpp生可执行.exe文件,不生成.o后缀,但有-c就是到中间步骤即目标文件.o后缀,然后再手动链接而且函数声明可以多次,只要声明内容一致即可,定义必须有且只能有一次
void funcA();是声明。void funcA() {helper(); // 调用自己的helper}是定义。
这仨
.cpp文件main.cpp包含程序入口main函数,是程序执行的起点,负责调用其他函数。a.cpp和b.cpp本身不执行任何代码,仅提供funcA、funcB及其内部辅助函数的定义,供main函数调用时使用。这里的static void helper()仅限a.cpp内部使用,只能被同一个文件里的funcA()调用,其他文件(比如b.cpp或main.cpp)无法访问它 —— 这正是static的作用(限制文件内可见)。而
funcA()没有static,是全局可见的,所以能被main.cpp调用。两者这两者不冲突:static限制helper()仅在a.cpp内部,funcA()作为接口对外提供功能
再比如:
// a.cpp 文件 static void foo() { // static 修饰函数cout << "Hello, world!" << endl; }int main() {foo(); // 合法,可以在当前文件中调用 foo 函数 }// b.cpp 文件 extern void foo(); // 声明 foo void bar() {foo(); // 非法,会报链接错误,找不到 foo 函数,其他文件无法调用 foo 函数 }因为
a.cpp中的foo()被static修饰,它的作用域被严格限制在a.cpp内部,不会被导出到全局符号表中。
b.cpp中用extern void foo();声明想要引用foo(),但由于a.cpp的foo()是static,在编译链接时,b.cpp根本找不到这个函数的符号(static让它 “隐藏” 了),所以会报 “未定义引用” 的链接错误。所以
extern了,导致想去其他地方找但找不到,自己又没定义
关于 volatile 的作用:(这里包含自己耗费 3 周追问的指针的知识,收获相当可观,非常牛逼,精通指针了,再遇到指针就都是砍瓜切菜了)
volatile用于修饰变量,表示该变量的值可能在任何时候被外部因素更改,例如硬件设备、操作系统或其他线程。编译器会禁止对该变量进行优化而导致出现不符合预期的结果,以确保每次访问变量时都会从内存中读取其值,而不是从寄存器或缓存中读取。查看代码
#include <stdio.h> #include <stdlib.h> #include <pthread.h>volatile int counter = 0;void *increment(void *arg) {for (int i = 0; i < 100; i++) {counter++;}return NULL; }int main() {pthread_t thread1, thread2;// 创建两个线程,分别执行increment函数pthread_create(&thread1, NULL, increment, NULL);pthread_create(&thread2, NULL, increment, NULL);// 等待两个线程执行完毕pthread_join(thread1, NULL);pthread_join(thread2, NULL);printf("Counter: %d\n", counter); }未使用
volatile时,编译器对共享变量读写行为的底层逻辑:读的时机
当 CPU 要操作变量(如
counter++里的读操作 ),会先看 寄存器 / 缓存 有没有该变量副本。如果有,直接从寄存器 / 缓存读,不会主动去内存重新读。只有当寄存器 / 缓存里没有(或被强制失效),才会从内存读。但编译器优化可能让变量长期 “待” 在寄存器里,程序运行中就跳过内存读,直接用寄存器里的旧值。
写的时机
变量修改(如自增后),编译器为了性能,可能先把新值放 寄存器 / 缓存 里 “攒着”,不立即写回内存。
只有满足特定条件(比如变量要被其他线程访问、寄存器 / 缓存满了 ),才会把寄存器 / 缓存里的新值写回内存。这就导致内存里的变量值,和寄存器 / 缓存里的 “最新值”短暂不一致,其他线程读内存时,拿到的是旧数据。
核心矛盾
编译器优化的逻辑是:“能不读内存就不读,能不写内存就不写”,靠寄存器 / 缓存加速。但多线程下,其他线程需要内存里的 “实时值”,这就冲突了。
volatile就是打断这种优化,强制 CPU 每次操作变量都去内存读、写回内存,让内存和寄存器 / 缓存的变量值 “同步”。
有了这个 volatile,每次读写内存
而这
volatile只能解决 “编译器优化导致的可见性问题”(比如让变量每次从内存读、写回内存,不让编译器放寄存器里瞎优化 ),但它管不了 “多线程并行抢着改” 的竞争问题。
counter++的本质:
counter++看着简单,实际是 “读内存→寄存器自增→写回内存” 三步操作。多线程下,线程 A 读了counter=0还没写回,线程 B 也读counter=0,俩人各自自增写回,结果就会少算(本该 +2,实际只 +1 )所以还要加锁
关于函数为啥
void *increment(void *arg),
void *increment(void *arg)是一个线程函数,它的作用是被线程去执行。从函数指针类型角度看,它符合pthread库要求的线程函数指针类型void *(*)(void *)。这里可以简单理解为,increment函数名本身就可以当作一个指针(函数指针 ),能传递给需要这种函数指针的地方(比如pthread_create函数 ),用于告诉线程要执行哪个函数,不需要额外再写复杂的(*)形式(函数名在传递时会自动隐式转换为函数指针 )。核心:只要函数的参数、返回值形式和要求的函数指针类型(这里是
void *(*)(void *)对应形式 )匹配,函数名就能当函数指针用去传递,供像线程创建这类场景使用
为啥要用函数指针?
(我发现排序算法就是个大炸弹,之前也是 在这栽跟头,看似无脑,但却是开始用指针的一个衔接,之前邝斌那五大算法专题都不需要用指针)
(妈了个逼的的!狗艹的!这里自己拓展学习的各种指针,真的深似海啊)
(狗东西!死妈玩意的指针!总他妈在各种时候卡我,下定决心现在必须操翻搞懂他!!!在此之前啥都不学了!妈逼的!!~~~~(>_<)~~~~)
(真不知道这些大厂人有没有这种感觉,但估计没有,因为就我看到的《鱼皮》、《代码随想录》、《吴师兄》、《公子龙》、《帅地》也都是水货!就他们写那个算法网站,真就一坨屎,他们只能应付面试官,印象很深的头三位里的有个人算法网站里 KMP 肯本没抓重点,甚至让他们去刷 acm 算法题都他妈狗屁不是,一个都过不了,我是可以给他们 A 不过的题,改 bug 到 AC 的,可是这狗逼世道就是投机取巧、乌烟瘴气、骗来骗去,真正打算法竞赛的永无出头之日,这些出来写公众号蹦跶的都是速成狗,没半点真本事,更不用说其他程序员了艹。真的悲哀,我以为程序员搞技术,还算技术认真,发现太天真了。我的感悟就是之前刷算法的时候,网络上所有的讲解都狗鸡巴不是!都他妈错的!现在下定决心艹死这个狗逼指针的时候,跟豆包学,发现之前了解的、学到的、网上口口相传的,很多都他妈是错的,一知半解的!艹!)
(一个这玩意整了4、5天!!)
场景1:
你在玩一个游戏,游戏里有个打怪升级的系统。游戏开发者写了打怪的基本流程代码,但具体怪物被打败后,玩家是获得金币、经验,还是特殊道具,开发者不想把这些逻辑写死。
用函数指针的做法:
游戏开发者定义一个打怪函数,这个函数接收一个函数指针作为参数。不同的游戏策划者可以写自己的 “怪物死亡后奖励函数”, 比如
giveCoin()、giveExp(),然后把这些函数的地址(也就是函数指针)传给打怪函数。这样,每次打怪结束,打怪函数就能根据传入的函数指针,调用对应的奖励函数// 定义奖励函数 void giveCoin() {printf("获得金币\n"); } void giveExp() {printf("获得经验\n"); }// 打怪函数,接收函数指针作为参数 void killMonster(void (*callback)()) {// 模拟打怪过程printf("怪物被打败啦\n");// 调用传入的奖励函数callback(); }int main() {// 调用打怪函数,并传入获得金币的函数指针killMonster(giveCoin); }场景2:
简单回顾下 冒泡
写一个通用的排序函数,之前刷算法题的时候都是 int 所以写死就行,那么写死 int 有两种写法:
写法一:
查看代码
#include <stdio.h> void bubbleSort(int arr[], int size) {for (int i = 0; i < size - 1; i++) {for (int j = 0; j < size - i - 1; j++) {// 直接在排序函数内部写比较逻辑,不依赖外部cmp函数if (arr[j] > arr[j + 1]) {int temp = arr[j];arr[j] = arr[j + 1];arr[j + 1] = temp;}}} } int main() {int numbers[] = {5, 2, 8, 1, 9};int count = sizeof(numbers) / sizeof(numbers[0]);bubbleSort(numbers, count);printf("排序后:");for (int i = 0; i < count; i++) printf("%d ", numbers[i]); }解释:
1、在函数定义中,
int* arr和int arr[]完全等价,数组名会自动代表数组首元素的地址,本质就是个指针。2、
sizeof(numbers)表示计算变量numbers所占用的总字节数3、这代码是不涉及任何指针的,属于传递值,等价于
int (*cmp)(int, int)这种函数指针定义,比较函数里拿到的是副本,比较函数内部直接用值比较,不影响原数据,如果传递指针int (*cmp)(int*, int*),比较函数里拿到的是原数据的地址,可以改变原函数。且在内部需要用*解引用才能拿到值。注意:这里两个
int的*要么同时有,要么都没有,而第一个cmp的*可有可无
写法一进阶:如果说带点指针味道的过度,那就是这个写法
查看代码
#include <stdio.h>// 比较两个int值(直接传值,非指针) int compareInt(int a, int b) {return a - b; }// 排序函数(直接操作数组元素值) void sortInt(int* arr, int size, int (*cmp)(int, int)) {for (int i = 0; i < size - 1; i++) {for (int j = 0; j < size - i - 1; j++) {// 直接传递元素值进行比较if (cmp(arr[j], arr[j + 1]) > 0) {// 交换元素值int temp = arr[j];arr[j] = arr[j + 1];arr[j + 1] = temp;}}} }int main() {int numbers[] = {5, 2, 8, 1, 9};int count = sizeof(numbers) / sizeof(numbers[0]);sortInt(numbers, count, compareInt);printf("排序后:");for (int i = 0; i < count; i++) {printf("%d ", numbers[i]);} }解释:
void sortInt(int arr[], int size, int cmp(int, int))和void sortInt(int arr[], int size, int (*cmp)(int, int)) {这两种写法完全等价,都是声明 cmp 指针,而这个指针指向【接收两个 int 参数、返回 int 的函数】,即cmp是 “函数指针”,存的是函数的地址把函数当参数传递时,“函数类型” 会被隐式转换为 “指向该函数的指针类型”,所以
int cmp(int, int)本质就是int (*cmp)(int, int)的简写,编译时会被当作同一种函数指针参数处理,功能上没有任何区别想让
sortInt用自己写的myCmp函数来比较,得把myCmp传给sortInt。这时候你写sortInt(arr, 5, myCmp),这里的myCmp本身是 “函数类型”,但因为它要当参数传给sortInt,编译器就自动把它转成 “指向myCmp这个函数的指针”了 —— 这也是为啥你写void sortInt(..., int cmp(int, int))能生效,因为编译器知道这里的cmp其实是个指针,只是帮你省了写(*)的功夫但注意这两种写法只有出现在函数列表的时候才等价,都表示 “一个指向特定类型函数的指针
但在函数参数列表外,两者完全不同(一个是函数声明,一个是指针变量):
单独写
int cmp(int, int);→ 是函数声明(声明了一个接收两个 int、返回 int 的函数单独写
int (*cmp)(int, int);→ 是函数指针变量定义(定义一个能存函数地址的变量)指针变量的名字是
cmp。单独说
cmp时,它是指针变量本身(存着函数的地址);用*cmp可以间接访问它指向的函数(实际调用时可简化为cmp(...),编译器会自动处理),例如:int (*cmp)(int, int);定义后,cmp = add;(add是符合类型的函数),此时cmp中存储的就是add函数的地址。
比如:
查看代码
#include <stdio.h>// 定义一个符合格式的函数(两个int参数,返回int) int compare(int a, int b) {return a - b; // 示例:返回差值,用于比较 }int main() {// 定义函数指针变量cmp,指向"接收两个int、返回int"的函数int (*cmp)(int, int);// 让指针指向具体函数compare(函数名即地址)cmp = compare;// 调用方式1:用指针调用(*cmp等价于cmp)int result1 = (*cmp)(3, 5);// 调用方式2:简化写法(编译器自动处理指针到函数的转换)int result2 = cmp(3, 5);printf("结果1:%d\n", result1); // 输出:-2printf("结果2:%d\n", result2); // 输出:-2 }发现指针可以当函数来用,至此总结就是:
函数参数中的函数名自动转换为指针:当函数作为参数传递时(如
void sortInt(..., int cmp(int, int))),编译器会自动将函数名隐式转换为函数指针,所以int cmp(int, int)作为参数时,实际等价于int (*cmp)(int, int),这是 C 语言为简化写法的规定。调用函数指针时
*可省略:代码中(*cmp)(3,5)和cmp(3,5)等价,因为编译器会自动处理函数指针的解引用,允许直接用指针名调用函数,这也是 C 语言的语法简化,本质上两者都是通过指针找到函数地址并调用。函数指针就是指向函数的指针,直接用这个指针调用函数就直接写这个指针名字加不加
*都行,两者的核心都是:C 语言中函数名在大多数场景下会被隐式转换为函数指针,因此可以省略显式的*或&(取地址)。例子见此文搜“(后面针对这个代码,会做相当多的分析、深入探讨)”,函数名在多数场景下会隐式转换为函数指针,因此函数指针调用时可省略*,传递函数地址时可省略&,本质都是这种隐式转换的体现。- 函数作为参数传递指的就是函数指针
写死只比较 int 类型的话,有没有指针无区别。指针只是给【既比较 int 也比较 char】用的。那把写死比较 int 类型的搞成指针写法,为下面做铺垫,压压惊开开胃
写法二:
查看代码
#include <stdio.h> int compareInt(int* a, int* b) {return *a - *b; } void sortInt(int* arr, int size, int (*cmp)(int*, int*)) {for (int i = 0; i < size - 1; i++) {for (int j = 0; j < size - i - 1; j++) {if (cmp(&arr[j], &arr[j + 1]) > 0) {int temp = arr[j];arr[j] = arr[j + 1];arr[j + 1] = temp;}}} } int main() {int numbers[] = {5, 2, 8, 1, 9};int count = sizeof(numbers) / sizeof(numbers[0]);sortInt(numbers, count, compareInt);printf("排序后:");for (int i = 0; i < count; i++) {printf("%d ", numbers[i]);} }解释:
这里直接 & 了,是因为明确知道是比较 int,
&arr[j]就是第 j 个元素的地址(int*类型),无需额外计算但到此为止,统说下整个的代码,这里头一次真正自己想搞懂函数指针,也就是指向函数的指针,那这玩意目前刚学不用研究透彻,只知道这个指针是为了当参数就行,那函数当参数刚接触,一屁眼子疑惑,我一一来说,说完就嘎嘎牛逼嘎嘎透彻
首先定义的时候,
int *p;表示 “这是个指针”。但. 当你 “使用变量” 时,*表示 “解引用”int a = 10; int *p = &a;嘎嘎简单不多逼逼下一个
Q:调用的时候
bubbleSort(numbers, count);写成number[]可以吗?显然不行,A:因为
[]是数组的声明语法,如int numbers[] = {1,2,3};,只能在声明变量或函数参数时候用。而函数调用时,numbers是已经定义好的数组名,此时它要么代表数组本身,要么被隐式转换为首元素地址,根本不需要也不能加[]。正确的写法只能是
bubbleSort(numbers, count);,这里的numbers会被隐式转换为指向首元素的指针(int*类型),与函定义的数参数int arr[](本质是int*)完美匹配。
Q:那
int arr[]到底是啥?A:
int arr[]是一种数组形式的指针声明,本质上等价于int *arr,比如void bubbleSort(int arr[], int size) { ... },这里的int arr[]看起来是数组参数,实际上和int *arr完全一样,函数内部操作的是指向数组首元素的指针,通过它来访问数组元素(如arr[j]等价于*(arr + j))。
Q:这些我早都知道,但现在涉及了更多的东西反而糊涂了!!
arr、arr[]、*,都是啥啊A:再深入说原理:
声明场景:你在 “告诉编译器” 这个东西是什么(是数组?是指针?),需要写清楚 “类型规则”;
调用场景:你在 “实际用” 已经声明好的东西,只需要写 “东西的名字”,不用再写类型规则。
场景 1:声明(函数参数 / 变量定义)—— 这里才需要
arr[]或*
场景 2:调用(传函数参数)—— 这里只需要写 “名字”,绝对不能加
[]或*
总结就是:
调用函数时,绝对不能写
arr[]:比如bubbleSort(numbers[], count)是错的 ——[]是声明时用的 “类型规则”,调用时只需要传数组名(numbers);调用函数时,除非特殊需求(比如传指针的地址),否则不写
*:比如bubbleSort(*numbers, count)是错的 ——*是 “解引用”(拿指针指向的值),这里需要传地址,不是值;声明函数参数时,
int arr[]和int *arr随便写,完全等价:不用纠结哪个对,重点是知道它们本质都是指针,用来接收数组首元素的地址。用冒泡排序代码验证一下:声明函数时:
int arr[](对)、int *arr(对);调用函数时:
numbers(对)、numbers[](错)、*numbers(错)。
Q:那为啥啊?
A:其实是 C 语言设计时的 “妥协” 与 “简化” —— 既要让代码写起来直观(能体现 “操作数组” 的意图),又要避免内存浪费,最终形成了 “声明和调用时用法不一样” 的规则。
1. 为什么 “声明函数参数时”,
int arr[]能存在(还等价于int *arr)?本质是 C 语言不想让你 “传整个数组” —— 如果真的允许 “传整个数组”,会发生什么?比如你定义了
int numbers[1000](占 4000 字节),如果调用函数时要把这 4000 字节完整拷贝一份传给函数,会严重浪费内存和运行时间。所以 C 语言做了个 “规定”:数组作为函数参数时,自动 “退化” 成指向首元素的指针(只传 4/8 字节的地址,不拷贝整个数组)。
但直接写
int *arr又有个问题:程序员看代码时,可能不知道这个指针是用来处理数组的(比如你写bubbleSort(int *arr, ...),别人可能误以为是 “处理单个指针”,不是 “处理数组”)。于是 C 语言又留了个 “人性化语法”:允许你写int arr[]来声明参数 —— 它看起来像数组,能明确告诉读者 “这里要传一个数组”,但编译器会悄悄把它解读成int *arr(本质还是指针)。总结:int arr[]是 “给人看的直观写法”,int *arr是 “给编译器看的真实写法”,二者在函数参数声明里完全等价。2. 为什么 “调用函数时”,不能写
arr[]或*arr?因为 调用时的核心是 “传正确的值”,而
[]和*在这里都是 “多余的干扰”:先看
[]:[]是 “声明时的语法符号”(用来告诉编译器 “这是数组类型”),比如int numbers[] = {1,2}里的[],是在定义数组时用的。而调用函数时,numbers已经是一个 “现成的数组名” 了,它要么代表数组本身,要么会自动转成首元素指针 —— 你再写numbers[],编译器会懵:“[]在这里干嘛?是要定义新数组吗?可这里是函数调用啊!” 所以直接报错。再看
*:*是 “解引用符号”,作用是 “通过指针拿它指向的值”。比如你有指针int *p = numbers(p 指向首元素 5),*p就等于 5(首元素的值)。而函数需要的是 “数组首元素的地址”(比如numbers自动转成的地址),如果你传*numbers,相当于传了 “首元素的值 5”—— 函数拿到 5 后,会把 5 当成地址去访问内存(比如arr[j]变成*(5 + j)),这会直接越界崩溃,完全不符合需求。总结:调用时只需要传 “数组名”(比如
numbers)—— 它会自动转成函数需要的首元素指针,加[]是语法错误,加*是传错了值(传了元素值,不是地址)。C 语言为了 兼顾 “代码直观性” 和 “内存效率”,在 “声明时” 允许用
int arr[]伪装数组(实际是指针),让你知道要处理数组;在 “调用时” 只让你传数组名(自动转地址),避免多余语法导致错误 —— 本质是 “语法设计服务于实际需求” 的结果。懂了很多!
- 再说点东西,
int arr[3] = {1, 2, 3};1、
arr:数组名在大多数情况下会被隐式转换为 “指向数组首元素的指针”(int*类型),等价于&arr[0]。例如:arr和&arr[0]地址相同,都指向第一个元素1。2、
&arr:表示 “指向整个数组的指针”(int(*)[3]类型,即指向包含仨 int 的数组的指针)。它的地址和arr相同,但含义不同:&arr + 1会跳过整个数组(移动 3*4=12 字节),而arr + 1只跳过一个元素(移动 4 字节)。3、
*arr:等价于arr[0],表示数组的第一个元素(值为 1)。因为arr是首元素指针,*arr就是解引用这个指针,得到首元素的值。4、
arr[]:这是数组的声明形式(如int arr[] = {1,2,3}),表示定义一个数组,编译器会根据初始化内容推断长度。简单总结:
arr≡&arr[0](首元素指针)
&arr是整个数组的指针(地址相同,类型不同)
*arr≡arr[0](首元素的值)
arr[]是数组的声明语法数组和函数的语法规则不同,数组名的转换更复杂,核心是区分 “指向元素的指针” 和 “指向整个数组的指针”
Q:“指向整个数组的指针”咋理解?
A:假设你有一个 “装 3 个苹果的盒子”(对应代码里的
int arr[3],3 个 int 元素的数组)。“指向苹果的指针”:是指着盒子里某一个苹果(比如第一个苹果),关注的是 “单个元素”;
“指向整个数组的指针”:是指着整个盒子,关注的是 “装 3 个苹果的整体”—— 它的 “目标” 不是单个元素,而是整个数组。
再回到代码,用
int arr[3] = {1,2,3}举例:1. 先明确
int(*)[3]这个类型的含义
int(*)[3]是一个 “指针类型”,翻译过来就是:最里面的
[3]表示 “指向的目标是一个包含 3 个元素的数组”;前面的
int表示 “这个数组里的每个元素是 int 类型”;括号
(*)是为了强调 “这是一个指针”(如果写成int*[3]就变成 “指针数组” 了,完全不同)。所以
int(*)[3]的本质:专门用来指向 “包含 3 个 int 的数组” 的指针,它的 “目标单位” 是 “整个数组”,不是单个 int。2. 用代码看区别:地址相同,但 “步长” 不同(关键!)
虽然
arr(首元素指针)和&arr(整个数组指针)的起始地址数值完全一样(都指向数组开头),但它们的 “步长”(指针 + 1 时移动的字节数)完全不同 —— 这就是 “指向单个元素” 和 “指向整个数组” 的核心差异:
#include <stdio.h> int main() {int arr[3] = {1,2,3};// 1. 打印地址(数值相同)printf("arr的地址:%p\n", arr); // 比如输出 0x7ffeeabc1230printf("&arr的地址:%p\n", &arr); // 同样输出 0x7ffeeabc1230(地址数值一样)// 2. 看指针+1后的差异(步长不同)printf("arr+1的地址:%p\n", arr+1); // 0x7ffeeabc1234(移动4字节,跳过1个int)printf("&arr+1的地址:%p\n", &arr+1); // 0x7ffeeabc123c(移动12字节,跳过3个int)return 0; }
arr是int*类型(指向单个 int),+1 时移动 “1 个 int 的大小”(4 字节),只跳过 1 个元素;
&arr是int(*)[3]类型(指向整个数组),+1 时移动 “整个数组的大小”(3*4=12 字节),直接跳过整个数组。
int(*)[3]这种指针,就像给 “装 3 个 int 的数组” 贴了个 “专属标签”—— 它只认 “整个数组” 当目标,所以操作时(比如 + 1)也是按 “整个数组” 的尺寸来算,和普通的 “指向单个 int 的指针”(int*)完全不是一回事而指针变量的名字就夹在
*和[ ]中间。比如还是用int arr[3] = {1,2,3};,要定义一个 “指向整个数组的指针变量”,写法是:int (*p_arr)[3] = &arr;, 看看咋用
代码:
查看代码
#include <stdio.h> int main() {int arr[3] = {1,2,3};// 定义“指向整个数组的指针”,名字叫 p_arrint (*p_arr)[3] = &arr; // 访问数组元素的两种方式(本质都是通过指针找元素)// 1. 先解引用 p_arr(得到整个数组 arr),再用 [ ] 取元素printf("第一个元素:%d\n", (*p_arr)[0]); // 等价于 arr[0],输出 1printf("第二个元素:%d\n", (*p_arr)[1]); // 等价于 arr[1],输出 2// 2. 也可以通过指针偏移(但因为 p_arr 是数组指针,偏移要注意步长)// 这里 p_arr 指向 arr,p_arr+1 会跳过整个 arr,所以很少这么用 }这个指针和普通指针(比如
int* p,p 是名字)一样,“指向整个数组的指针” 也有自己的名字,只是声明时要把名字放在(*)里,保证它先和*结合,成为指针变量把
arr想象成一个装了 3 个苹果的快递箱,箱子里有 3 个格子,分别放着苹果 1、苹果 2、苹果 3(对应arr[0]、arr[1]、arr[2]);这个箱子本身就叫arr(整个数组),它不是单个苹果,而是 “装 3 个苹果的整体”。
(*p_arr)为什么是 “整个数组 arr”?
*在这里是 “解引用”,意思是 “根据指针找到它指的东西”:
p_arr指着 “arr 快递箱”,所以*p_arr就是 “找到这个快递箱本身”(整个箱子,不是单个苹果);就像你根据标签上的地址找到快递箱,
*p_arr就是 “那个箱子本身”—— 也就是arr数组整体
(*p_arr)[0]为什么是arr[0]?先通过*p_arr找到 “整个快递箱”(就是arr);再用[0]从箱子里拿出第一个苹果 —— 和直接从arr里拿arr[0]完全一样。
- 好,至此透彻了一些,再继续看点其他的。关于数组名到底是个啥鸡巴玩意?众所周知的就是:数组名是指针,是指向首地址的一个指针,但大错特错!其实扯了这么多最开始是因为我觉得 arr 这个数组名是指针,但其实不是,所以才引出了这么多追问!(数组名不是指针引发的血案)
咱们得把 “数组名的本质” 和 “编译器对数组名的使用规则” 拆开来,就像分清 “一张纸本身” 和 “我们在纸上写什么”
比如写
int arr[3] = {1,2,3};,编译器会做两件事:申请一块 12 字节的内存(int 占 4 字节 × 3 个元素),用来存 1、2、3 这三个值;
给这块内存贴一个 “标签”,就是
arr—— 它的作用只有一个:告诉编译器 “这片 12 字节的内存叫 arr”。数组名
arr不占用额外内存:它不是像指针变量(比如int *p)那样,需要额外 4/8 字节存地址;arr只是个 “标识”,就像你家大门上的 “301” 门牌号,门牌号本身不占额外空间,只是用来指代你家那套房子。数组名
arr本身不 “存” 地址:它自己不是 “装地址的容器”,但它能 “对应” 一个地址 —— 就是这片 12 字节内存的起始位置(和首元素arr[0]的地址数值相同),因为标签必然贴在内存块的开头。再解释之前的矛盾:“数组名不存地址”,但为啥能 “用成地址”?
这是编译器的 “特殊处理”—— 为了让我们能方便操作数组元素,编译器规定:当你在 “需要地址的场景” 里用数组名
arr时,它会自动把arr当成 “这片内存的起始地址”(也就是首元素arr[0]的地址)来用。
int *p = arr;:这里需要给指针p赋值一个地址,编译器就把arr对应的 “内存起始地址” 赋给p(相当于int *p = &arr[0];);
printf("%d", arr[1]);:本质是先通过arr找到内存起始地址,再往后偏移 4 字节(一个 int),取对应的值 —— 这里arr也被当成地址用了。这种 “当成地址用”,是编译器的 “临时转换”,不是说
arr本身就是地址。最后回到 “&arr”:为啥它是 “整个数组的地址”?
&符号的作用是 “获取变量的地址”,但这里的 “变量” 要广义理解 ——arr代表的 “整个 12 字节内存块”,也算是一个 “整体变量”(类型是int[3],不是单个 int)。所以
&arr的意思是:获取 “arr 这个 12 字节内存块” 作为一个整体的地址。它和 “arr 被转成的首元素地址”(&arr[0])的区别,就像:你家 “301 这套房子的地址”(
&arr):指向的是 “整个房子”(120 平米);你家 “大门的地址”(
arr转成的地址):指向的是 “房子的入口”(对应首元素)。数值上两者可能一样(都是你家所在的楼栋门牌号),但 “指向的范围” 完全不同 ——
&arr+1会跳过整个 12 字节(整个房子),而arr+1只跳过 4 字节(一个 int,相当于房子里的一个房间)。一句话总结,彻底理清:
arr本身:是 “12 字节内存块的标签”,不占内存、不存地址,只代表 “这片内存”;用
arr时:编译器自动把它转成 “这片内存的起始地址”(首元素地址),方便操作元素;
&arr:是 “获取整个内存块的地址”,指向的是 “整个数组”,不是单个元素。所以,编译器为了省事,就把
arr自动转成 “第一个元素的地址”(&arr[0]),不用你每次都写&arr[0]—— 这就是 “隐式转换”。但你要记住:转换后是 “首元素地址”,不代表
arr本身就是这个地址。就像你说 “去 XX 街 100 号”,默认是找第一个快递盒,但 “XX 街 100 号” 本身还是 “整个快递站”,不是 “第一个快递盒”。“arr 转的首元素地址” vs “&arr 的数组地址”
还是快递站例子:
arr转成的 “首元素地址”:相当于 “XX 街 100 号快递站的第一个快递盒”(指向单个元素);&arr的 “数组地址”:相当于 “XX 街 100 号快递站”(指向整个快递站)。数值上两者可能一样(比如都是 0x1234),但 “指向的范围” 完全不同:如果你从 “第一个快递盒” 往后跳 1 步(
arr+1),就到 “第二个快递盒”;如果你从 “整个快递站” 往后跳 1 步(
&arr+1),就跳过整个快递站,到 “下一个快递站”(跳过 3 个元素)。
arr能隐式转成首元素地址,是编译器的 “方便操作”,不代表arr本身是地址(它还是整个数组);
arr有地址,就是&arr—— 这个地址指向 “整个数组”,和 “隐式转出来的首元素地址” 不是一回事零零碎碎说了一堆终于搞懂了
再墨迹两句:
数组名没地址 和 int arr[] 的关系:
int arr [] 是声明数组,意思是我要一块内存,用来装多个 int,给它起个名叫 arr。这里的 arr 就像给那片内存贴的标签,标签本身不占地方(内存),只是方便你指代那片内存。
数组名没地址是说:这个标签 arr 本身不在内存里存着,所以你没法取标签自己的地址,就像你不能问“3 号楼”这三个字写在哪个位置,因为它只是个名字。但标签 arr 对应的那片内存(整个数组)是有地址的
所以,数组名是指针是错的!!
数组名是 “数组这片内存的名字”,是“一块内存的标识”,它不占用额外内存,也不能被赋值(你不能写
arr = 其他地址)。指针是 “存地址的变量”,占用 4/8 字节内存,里面存的是另一个内存的地址,而且可以被赋值(
p = &arr[0]是合法的)。—— 两者本质完全不一样。
数组名
arr= “3 号楼” 这个名字(用来指代整栋楼,本身不是实物,不占地方);指针变量int* p= 一张小纸条(能写字,纸上写的 “3 号楼 101” 就是地址,纸条本身占地方)。哪怕
arr有时候会被 “自动当成首元素地址”(比如int* p = arr),也只是 “用起来像指针”,不是 “它本身是指针”—— 就像你用手机扫码付款,手机 “用起来像钱包”,但手机本身不是钱包。妈逼的现在豆包更新了回答方式,会显示出两种,且无法删除、编辑啥的
再次总结,重复加深印象:
关于 arr 数组名:
用
arr就等于用 “第一个元素的地址”(&arr[0]),但有 2 个特殊情况(arr代表整个数组):用在
sizeof(arr)里:算的是整个数组的总大小(比如 3 个 int 就是 12 字节)。用在
&arr里:&arr是 “整个数组的地址”关于
&arr:类型是
int(*)[3](指向整个数组的指针),专门用来 “指整个数组”。和
arr的区别:arr + 1跳 1 个元素(4 字节);&arr + 1跳整个数组(12 字节)。关于
*arr:就是 “第一个元素的值”(
arr[0])。因为arr是第一个元素的地址,*arr就是 “解引用” 这个地址,得到值。关于
arr[]:只在声明数组时用(比如
int arr[] = {1,2,3}),表示 “这是个数组”,编译器会自己算长度再继续说几个 :
&arr的类型正好是int(*)[3],和 “指向整个数组的指针” 类型完全匹配
int arr[3] = {1,2,3}; int (*p)[3] = &arr; // 正确:类型完全匹配 int (*p)[3] = arr; // 错误:arr是int*类型,和int(*)[3]不兼容数组名(比如 arr)更像一个 “标签”,它本身不占用内存,也没有自己的地址—— 它的作用就是 “标记” 一片固定的内存区域,这片区域就是数组实际存储元素的地方
但数组名有类型,
比如:
int arr[3]中,arr的类型是 “包含 3 个 int 元素的数组”,写作int[3], 即数组名是一个数组类型,读作“包含 3 个 int 元素的数组类型”,但当你写arr + 1、*arr、arr[0]时,arr会被隐式转换成int*类型(指向首元素arr[0]的指针);但这是 “临时转换”,不改变arr本身是int[3]数组类型的本质比如:
char str[10]中,str的类型是 “包含 10 个 char 元素的数组”(写作char[10])。唯一例外:当数组名用在
sizeof(arr)或&arr中时,不会转换为指针:
sizeof(arr)计算的是整个数组的大小(比如int[3]就是 12 字节);
&arr得到的是「指向整个数组的指针」(类型是int(*)[3]),这时候&arr + 1会跳过整个数组的大小说明:数组名没地址,没内存,但却有类型。
“类型” 是编译器给的 “身份标签”:用来告诉编译器 “这个东西是什么、该怎么用”(比如是数组还是指针、能存多少元素、运算时该怎么处理);
“内存 / 地址” 是这个东西在电脑里的 “物理位置”:只有需要 “存数据” 的东西(比如变量)才会占内存、有地址。
你家小区门口的 “1 号楼” 是个 “标识”(类似数组名
arr):它有 “类型”:是 “一栋 18 层的居民楼”(类似arr的类型是 “3 个 int 的数组”)—— 这个 “类型” 决定了它是 “楼” 不是 “车”,能住多少人;但 “1 号楼” 这个标识本身,不占物理空间(不会在小区里找个地方 “放这个名字”),也没有 “自己的地址”(你不会说 “1 号楼这个名字在小区的哪个位置”)—— 它只是用来指代那栋实际存在的楼(类似arr指代那片存数组元素的内存)。回到数组名
arr:为什么有类型?
编译器需要知道
arr是 “数组”(不是指针 / 变量)、元素是int、长度是 3—— 这样才能正确计算sizeof(arr)(3×4=12 字节)、判断&arr的指针类型(必须是int(*)[3])、处理arr的隐式转换(转成int*指向首元素)。如果没有类型,编译器根本不知道该怎么用arr。为什么没内存 / 地址?
arr只是个 “标识”,用来指代那片存arr[0]、arr[1]、arr[2]的内存(这片内存有地址)。arr本身不存任何数据(不像指针变量int* p,需要占 4/8 字节存地址),所以它不需要内存,也没有自己的地址。就像 “1 号楼” 这个名字不占空间,但不妨碍它有 “居民楼” 的类型;arr没内存 / 地址,也不妨碍它有 “int [3] 数组” 的类型 —— 两者完全不冲突
- 说完了 数组名 到底是个鸡巴啥玩意,再说下 传参、定义、调用 相关的一些东西,:
传参时(实参):函数名本身就代表函数的地址,和加
&取地址的效果完全一样。这是为了写代码更方便,不用每次传函数都手动加&。函数名 ≡ & 函数名声明时(形参):写
int cmp(int, int)时,编译器会自动把它当成函数指针int (*cmp)(int, int)来处理。为了简化写法,让函数指针的声明看起来更像普通函数声明,降低理解难度。int 函数名 (参数) ≡ int (* 函数名)(参数)
代码:(后面针对这个代码,会做相当多的分析、深入探讨)
查看代码
#include <stdio.h> #include<iostream> using namespace std// 1. 普通函数(要被传递的函数) int compare(int a, int b) { return a - b; }// 2. 形参声明:两种写法等价(都是声明“cmp是函数指针”) // 写法A:没写*,编译器自动补成指针 void sort(int cmp(int, int)) { // 这里用 cmp 其实就是用函数指针,和下面写法B的 (*cmp) 效果一样int res = cmp(1, 2); } // 写法B:显式写*,明确表示cmp是函数指针(和写法A完全等价) void sort(int (*cmp)(int, int)) { //*是指针声明的一部分,用来表示cmp是函数指针,不是解引用。这里*和括号结合,是声明语法的一部分。int res = (*cmp)(1, 2); //:*作用于已声明的指针变量cmp,表示通过指针访问目标函数,是解引用,和上面的 cmp(1,2) 效果一样,因为规定函数指针在调用时,编译器会自动处理解引用操作。 }// 3. 实参传递:两种写法等价(都是传“compare函数的地址”) int main() {sort(compare); // 写法1:函数名自动视为地址(等价于&compare)sort(&compare); // 写法2:显式取地址(和上面完全等价)sort(*compare); //写法3:单独说 }解释:
函数名本质就是函数的入口地址,
Q:我的思考是,这里怎么一会
&一会*,不都是调用吗?A:但其实不是!
int res = cmp(1, 2);是通过函数指针调用函数(执行函数逻辑,得到返回值)。sort(compare);是传递函数地址作为参数(将函数作为参数传给另一个函数,不执行函数逻辑)
Q:不都是调用的步骤吗?
A:不是,本质区别是“是否执行函数逻辑”
int res = cmp(1, 2);:是调用函数—— 会执行cmp指向的函数(比如compare),计算1-2并返回结果,最终把值赋给res,这一步有函数的实际执行过程。
sort(compare);是传递函数地址—— 仅把compare的地址传给sort的参数cmp,不执行compare函数,只是让sort内部能通过这个地址找到compare,后续由sort内部决定何时调用(比如sort里的cmp(1,2)才是调用compare函数)。这步只是调用sort函数,而compare是作为参数传递给sort,而非调用compare函数。
Q:那如果
sort有返回值,把这个返回值给一个变量,那sort(compare);就要写成比如int a = sort(*compare)?A:狗娘养的死全家的豆包用阳寿回答问题!艹!耽误我一天!一开始说的是错误结论:
无论
sort是否有返回值,传递函数地址时都用sort(compare)或sort(&compare),绝不能写成sort(*compare)。compare是函数名,隐式转为指针(地址)。*compare是对指针解引用,得到的是函数本身,而函数不能直接作为参数传递,假设sort返回int,也是int a = sort(compare);或int a = sort(&compare);后来自己实践又追问,发现可以写
sort(*compare)。任何语言都 绝对不能传递 “整个函数实体”,只能传递函数的地址(入口地址)”。sort(*compare)本质还是传递地址。当你写*compare时,看似是 “对函数指针解引用得到函数本身”,但 C 语言编译器有个特殊规则:对 “函数地址 / 函数指针” 做解引用(*)后,编译器会自动把结果再转成函数地址。所以*compare最终的效果,和compare(函数名,本身就是地址)、&compare(显式取地址)完全一样 —— 都是传递 “函数的地址”,而非 “整个函数”。三种传参写法的本质等价(但推荐度不同):
sort(compare):函数名隐式转为地址,简洁规范,推荐使用;
sort(&compare):显式取地址,语法正确但冗余(函数名已代表地址);
sort(*compare):看似解引用 “得到函数本身”,但编译器会自动转成地址,语法合法但逻辑冗余、可读性差,绝对不推荐;
Q:和
int res = (*cmp)(1, 2);的差别?A:
int res = (*cmp)(1, 2);是通过函数指针调用函数(执行函数逻辑),而sort(compare)是传递函数地址(不执行函数),核心区别在于是否执行函数体:
(*cmp)(1, 2):cmp是函数指针变量(指向某个函数,比如compare)。*cmp解引用指针,得到函数本身,再加(1,2)就是调用该函数。会实际执行compare(1,2)的逻辑,返回结果给res
sort(compare):仅将compare的地址传给sort函数的参数(cmp指针)。不执行compare函数,compare此时只是一个 “地址值”。sort内部会用这个地址,在需要时通过cmp(1,2)或(*cmp)(1,2)调用函数简单说:前者是 “调用函数并获取结果”,后者是 “传递函数地址供后续使用”。
Q:那为啥加了返回值,比如
int a = sort(compare);和int res = (*cmp)(1, 2);也不一样?A:
int res = (*cmp)(1, 2);是通过函数指针调用函数并获取返回值,这和传递函数地址是完全不同的操作:
(*cmp)(1, 2)中,*是对函数指针cmp的解引用,(1,2)是传递参数,整体会执行cmp指向的函数(比如compare),并将结果存到res中。而传递函数地址(如
sort(compare))时,既没有解引用,也没有加参数列表(),所以不会执行函数,只是把函数的地址传过去。就算
int a = sort(compare);、int a = sort(&compare);甚至不规范但 VS 不会报错的写法:int a = sort(*compare);这三个哪怕最后一个也和int res = (*cmp)(1, 2);、void sort(int (*cmp)(int, int))完全不同? 因为void sort(int (*cmp)(int, int))是定义指向函数的指针,也叫函数指针,说白点就是定义指针! 而int res = (*cmp)(1, 2);是通过指针调用现成的函数,而int a = sort(*compare);也是函数调用,但是调用sort函数,传入的compare是实参(函数地址),而int res = (*cmp)(1, 2);是在sort函数内部,通过函数指针cmp调用它指向的函数(比如compare)。总结就是
int a = sort(compare);是调用sort函数,属于函数套函数。而int res = (*cmp)(1, 2);通过指针在sort函数内部调用compare直接一层调用
Q:那加了参数呢?
A:如果加了参数,就变成了函数调用表达式,传递的不再是函数地址,而是函数的返回值。
int compare(int a, int b) { return a - b; } void sort(int (*cmp)(int, int));// 错误示例:传递的是 compare(3,5) 的返回值(-2),而非函数地址 sort(compare(3, 5)); // 错误!参数类型不匹配(需要函数指针,实际传了int)这里的compare(3,5)会先执行并返回-2,然后试图把-2传给需要函数指针的sort,导致类型错误。不加参数:
compare是函数地址(可传递给函数指针参数)加参数:
compare(3,5)是函数调用,结果是返回值(不能直接传给函数指针参数)关键区别:是否有
()加参数 —— 有就是调用函数(执行逻辑),没有就是传递地址(不执行)。到这基本清晰了,再对逼逼两句,加深记忆
首先上面的错误代码应该是
sort(compare);或者sort(&compare);而写了参数那就是返回值了正常之前写的调用函数必须和定义的匹配,必须带参数,即
compare(3,5)。但如果把函数作为参数传递给其他函数时,只能只写名字。或者加个
&。再说说
sort(*compare),这里豆包反复说不同的回答,一会说是错误写法,compare是函数名(本质是地址),*compare解引用后是函数本身,而sort要求参数是 “函数指针(地址)”,直接传函数实体类型不匹配。一会说这是正确的,因为我 VS 执行没任何问题,豆包就墙头草说 C 在解引用后会再次转成函数的地址。不纠结了那再说说函数本身是啥意思,“函数本身” 指函数的完整代码体,既不是返回值,也不是无类型 —— 它有明确的类型(由参数和返回值决定,如
int(int,int)表示 “接收两个int、返回int的函数类型”)。而 函数本身不能直接作为参数传递,必须通过地址(指针)间接传递。调用函数时,
add(函数名,隐式转为地址)和*add(解引用地址得到函数本身)在调用时完全等价,因为 C 规定无论是用地址(add)还是用解引用后的函数本身(*add),只要后面加(参数),都会被编译器正确识别为 “调用这个函数”。唯独函数作为参数的时候,必须传递函数指针也就是地址,C 语言允许 “通过地址调用函数”(语法糖),但绝不允许 “直接传递函数实体”,所以sort(*campare)这种传递实体就错了(有争议,当作正确的,但别用就行,但很多狗逼考试就他妈得看出题人,哎我一直觉得做生意做买卖甚至gyw新疆AI比赛都可以投其所好,迎合出题人的意图,但一个技术学术考试这些都是实打实的东西,妈逼的真的恶心,狗屁不懂就敢出来丢人,唉一群水货草台班子的世道,外国人也做不对四六级,梵高拿不到央美准考证,C++ 之父估计过不了面试)那再说说
*campare干啥的,其实当用于调用函数时,(*compare)(a,b)完全等价于compare(a,b),只是不能直接作为参数传给需要函数指针的地方,因为他返回值是一个值,int或void,根本不是所需要的地址所以
campare作为函数名,大多时隐式转化为函数的地址,而*campare是对函数的解引用,得到函数本身,就比如:&a是变量a的地址,*(&a)就是变量a本身
Q:那懂了,那我又思考,
campare等价于&campare有条件吗?还是一直都是?A:函数名
compare在任何时候(无论是否带参数)都等价于&compare不带参数的时候,
compare和&compare完全一样,都是函数的地址(可传给sort这类需要函数指针的参数)带参数的时候,
compare(1,2)是调用函数(得到返回值),而&compare(1,2)是语法错误(不能对函数调用结果取地址,因为函数调用的结果(返回值)通常是临时值,存放在内存的临时区域(如寄存器或栈的临时位置),没有固定的内存地址,或者说这个地址是 “瞬时的”“不允许被访问的”)而且
compare(没有括号和参数):它是 “函数名” 的原始形态,此时等价于&compare,当你写的是
compare(1,2)(有括号和参数):它已经不是 “函数名” 了,而是 “函数调用表达式”,结果是临时返回值。此时给它加&就有问题
Q:那这时候可以用
*compare吗?即sort(*compare(3, 5));A:即使加了参数,用
*compare也不对。*compare本质是对函数名的解引用(函数名隐式转为指针后再解引用),结果仍是函数本身。如果写成
(*compare)(3,5),这和compare(3,5)完全等价,都是调用函数并返回结果(比如 - 2),依然是传递返回值而非函数地址,照样会导致sort的参数类型不匹配。正确传递函数地址的方式始终是:
sort(compare)或sort(&compare)(不加参数)
- 到此说完,另外再说下 C 没有的,C++ 有的“起别名”也叫函数引用,用法是
int (&cmp)(int, int)首先,解引用是对指针(地址)说的
C++ 的引用,就是起别名,这是通过 “关联关系” 在编译期确定的 “硬绑定”,不需要像指针那样用地址来 “间接找到” 原对象。
所以C++ 的函数引用不是地址,和 “原始数据的地址” 毫无关系。不存在 “通过地址间接访问” 的过程。
声明后直接用
cmp(1,2)调用,不能写成(*cmp)(1,2)(引用没有地址,不需要解引用)。传递时直接传函数名,比如
sort(cmp),但这里cmp是引用,不是地址,类型由“被引用对象的类型” 决定,对int变量的引用,类型是int&,对函数int add(int, int)的引用,类型是int(&)(int, int)。C 没有引用的东西,只有对地址、指针解引用,没“引用”概念。
- 代码:
查看代码
#include <iostream>// 1. 先定义一个普通函数(比如计算两数之和) int sum(int x, int y) {return x + y; }int main() {// 2. 声明函数引用:ref_sum 是 sum 函数的“别名”int (&ref_sum)(int, int) = sum;// 3. 通过函数引用调用(和直接调用 sum 完全一样)int result = ref_sum(2, 3); // 等价于 sum(2, 3)// 输出结果std::cout << "结果:" << result << std::endl; // 最终打印“结果:5” }
int (&ref_sum)(int, int) = sum;:ref_sum不是指针,就是sum函数的 “另一个名字”,调用ref_sum和调用sum没有任何区别
- 继续深入捋顺梳理:
Q:之前说的,为何
sort(compare);和sort(&compare);是这样,int res = (*cmp)(1, 2);就是加*的,我理解都是调用啊?A:
本质 1:先明确两个核心场景 ——“声明函数指针” vs “调用函数指针”
你混淆的根本,是没分清
*在 “定义指针变量” 和 “用指针调用函数” 时的不同意义:场景 1:声明(定义)函数指针变量(比如
int (*cmp)(int, int);)这里的
*是声明语法的一部分,作用是 “告诉编译器:cmp不是普通变量,而是一个 “指向函数的指针””。语法结构拆解:
(int (*cmp)(int, int))括号
(*cmp)必须加,否则int *cmp(int, int)会变成 “返回 int * 的函数”(完全错了)。这里的
*不是 “解引用操作”,只是用来标记cmp的身份 —— 它是指针,指向 “参数为两个 int、返回值为 int 的函数”。这一步是 “定义工具”,就像你买了个能夹核桃的钳子(定义
cmp这个指针),还没开始夹核桃。
int cmp(int, int)这种写法,会被编译器隐式转换为函数指针类型,最终等价于int (*cmp)(int, int)(函数指针)场景 2:用函数指针调用函数(比如
(*cmp)(1,2)或cmp(1,2))这里的
*是解引用操作符,作用是 “通过指针cmp存储的地址,找到它指向的函数,然后调用这个函数”。本质逻辑:
cmp里存着某个函数(比如compare)的地址 →*cmp就是 “通过地址找到的那个函数本身” → 加(1,2)就是调用这个函数。C 语言允许偷懒:因为函数名本身就等于它的地址,所以
cmp(1,2)会被编译器自动当成 “通过cmp的地址调用函数”,和(*cmp)(1,2)功能完全一样(语法糖)。这一步是 “使用工具”,就是用钳子夹核桃(调用函数),会出结果(核桃碎了 / 函数返回值)。
本质 2:你之前混乱的 “差别”,其实是 “工具定义” 和 “工具使用” 的差别
你之前纠结的 “和
*cmp的差别”,本质是:如果你指的是 “声明时的
int (*cmp)(...)”:这是 “定义指针工具”,没执行任何函数,只是告诉编译器 “cmp是干嘛的”;如果你指的是 “调用时的
(*cmp)(1,2)”:这是 “用指针工具调用函数”,会执行函数逻辑,返回结果;而你之前提的
sort(compare):这是 “把函数的地址传给别人用”,是传递函数地址,既不是定义指针,也不是调用函数,只是 “把工具(函数)的地址递出去”。一句话总结:
声明函数指针时(
int (*cmp)(int,int);):*是 “身份标记”,用来定义cmp是函数指针;调用函数指针时(
(*cmp)(1,2)):*是 “解引用操作”,用来通过指针找到函数并执行;这俩是 “定义工具” 和 “用工具干活” 的根本区别,跟 “传地址”(
sort(compare))更是两码事
- 再次逼逼巩固:
传递函数地址时,
&函数名和函数名等价(省略&),比如:sort(compare)等价于sort(&compare)用函数指针调用函数时,
指针名()和(*指针名)()等价(省略*),比如:cmp(1,2)等价于(*cmp)(1,2)
懂了这些最基础的再说代码:
注意以上都是围绕此文搜“(后面针对这个代码,会做相当多的分析、深入探讨)”来说的
int (*cmp)(int, int)指向的是“参数为两个 int、返回值为 int 的函数” 的指针,变量名叫cmp,但不是指向cmp的指针,这个指针可以指向任何符合 “两个 int 参数、int 返回值” 的函数,不固定指向某个特定叫cmp的函数。具体指向谁是调用时传的一个符合格式的函数名。
开始上最通用的,写法三:(妈逼的这里有超级大的学问)
查看代码
// 整数比较函数 int compareInt(const void* a, const void* b) {return *(int*)a - *(int*)b; }// 字符串比较函数 int compareString(const void* a, const void* b) {return strcmp(*(char**)a, *(char**)b); }// 通用排序函数,接收比较函数指针 void mySort(void* arr, int size, int elementSize, int (*compare)(const void*, const void*)) {// 这里省略具体排序实现,假设用冒泡排序思路for (int i = 0; i < size - 1; i++) {for (int j = 0; j < size - i - 1; j++) {char* p1 = (char*)arr + j * elementSize;char* p2 = (char*)arr + (j + 1) * elementSize;if (compare(p1, p2) > 0) {// 交换元素char temp[elementSize];memcpy(temp, p1, elementSize);memcpy(p1, p2, elementSize);memcpy(p2, temp, elementSize);}}} }int main() {int intArr[] = { 5, 3, 1 };mySort(intArr, 3, sizeof(int), compareInt); char* strArr[] = { "cat", "apple", "banana" };mySort(strArr, 3, sizeof(char*), compareString); return 0; }接收一个比较函数的指针作为参数。
排整数数组时,传入整数比较函数,
排字符串数组时,传入字符串比较函数。
这样,同一个排序函数,通过不同的比较函数指针,就能处理不同类型数据的排序。
解释:(一直追问到了女娲补天、盘古开天辟地的最底层设计逻辑理论知识,然后又从这些来到现在的知识点,反复抽插,打通所有疑惑)
通用的
mySort要支持任意类型必须用char*做基地址(最小字节单位),通过j * elementSize计算偏移量,这样才能适配不同大小的元素(int 占 4 字节,char * 占 8 字节等)这里的排序函数
mySort里就不能再用&了,因为它要处理任意类型的数组,而&的用法依赖于具体类型。比如对于
int数组,因为知道每个元素是int类型,&arr[j]能正确拿到第 j 个元素的地址但通用函数
mySort的参数是void* arr(丢失了具体类型信息),编译器无法知道arr指向的数组元素是什么类型,也就无法通过&arr[j]来计算地址,j的偏移量取决于元素大小,&arr[j]能否用,取决于arr的类型是否明确,而void本身没有类型没有大小这里就是手动算大小,所以通用函数必须用
char*做基地址,配合elementSize(元素字节数),通过j * elementSize这种字节级的偏移计算来定位元素,不管元素是什么类型,都能正确找到地址。而专用函数
sortInt因为知道是int数组,所以可以直接用&arr[j]—— 本质是因为它提前知道了元素类型和大小。
p1的类型?是指针类型,具体来说是
char*类型(字符指针类型)。这个是永远不变写死的指针类型本身包含两重信息:
1、它是指针(用来存储地址);
2、它的基类型是
char(决定了指针运算的偏移量,比如p1+1会偏移 1 字节,而如果p1是int*,那p1+1会偏移 4 字节)
p1指向的东西?因为
arr是int数组,j * elementSize(比如 j=1 时就是 4 字节)计算出的偏移,让 p1 最终指向的是数组里下标为 1 那个 int 元素的起始地址。所以,“
p1是指针类型”,和 “p1指向的数据是什么类型” 是两回事。知道这个以后,说结论:编译器它只认指针自己的 “身份证”(类型),不认指针指向的 “实际内容”。
比如:假设 p1 指向的内存地址是
0x100,这段内存里存的二进制是00000000 00000000 00000000 00001010(共 4 字节,对应十进制 10)现在分析这个事:
如果,用 p1 本身的类型
char*解读,编译器看到char*,就只会 “抓 1 字节” 来读 —— 电脑都是小端序,因为都是最低位字节开始先运算,比如 13 + 47 都是先 3 + 7 ,那小端序的低字节存在低地址运算就很方便,低地址先拿到低字节在对,所以,假设这段 4 字节 int 数据(值为 10,二进制00000000 00000000 00000000 00001010),存在内存地址0x100~0x103里。按「小端序」存储时,字节会反过来放:
地址
0x100(低地址):存最低位字节00001010(对应十进制 10)地址
0x101:存00000000地址
0x102:存00000000地址
0x103(高地址):存最高只看
0x100地址开头的 1 字节:00001010,解读成char类型的数值 10(或 ASCII 码对应的控制字符)。如果,强制转换成 int * 类型解读,当我们写
*(int*)p1时,是先把 p1 的 “身份证” 临时改成int*(告诉编译器:“别当 char 看了,按 int 读!”)。编译器看到int*,就会 “抓 4 字节” 来读 —— 把0x100开始的 4 字节00000000 00000000 00000000 00001010完整读出来,解读成int类型的数值 10。
代码里虽然没有直接写
p1 + 1,但核心逻辑依赖char*的字节级偏移特性:char* p1 = (char*)arr + j * elementSize;,这里的(char*)arr将数组地址转为char*后,每次计算偏移时:若
elementSize是4(int的大小),则j*4就是按字节偏移,精准定位第j个int元素若
elementSize是8(char*的大小),则j*8精准定位第j个字符串指针如果
p1是int*:int* p1 = (int*)arr + j;会自动按int大小偏移(等价于j * sizeof(int)),但这样就无法通用(比如处理char*数组时,偏移量计算会错误)。而char*的作用是强制按 1 字节为单位计算偏移,配合elementSize实现 “任意类型元素的地址定位”。它指向的数据的类型,取决于数组元素(可能是
int、char*等),这里在mySort中,并不需要直接解读数据(交给compare函数处理),只需要定位元素地址,然后用char*来移动具体的int的 4 字节,还是char的 1 字节当
p1指向int元素时,p1的类型还是char*(指针类型),但它指向的数据是int类型;当
p1指向char*元素时,p1的类型依然是char*(指针类型),但它指向的数据是char*类型(另一个指针)。
再说点别的,有助于理解这个代码里的指针,因为好多细节专业术语妈逼的搞不透彻追问豆包总有歧义:
*(int*)a是将void*类型的指针a先转换为int*类型指针,再解引用获取其指向的int类型值。分析步骤:
(int*)a:将通用指针a(void*类型)强制转换为指向int类型的指针(int*类型)
*(int*)a:对转换后的int*指针进行解引用,获取该指针指向的内存中存储的int类型数据
继续:
p1的类型是int*,那p1 + 1是移动 4 个字节,
p1的类型是char*,那p1 + 1是移动 1 个字节,而
p1指向的数据类型与“移动多少字节”无关,只决定解读内存时按什么类型解析(如int占 4 字节、char占 1 字节)。所以,移动字节数仅由指针自身类型决定,与指向的数据类型无关。
“解读内存时按什么类型解析”指的是:当通过指针访问其指向的内存数据时,编译器会根据指针的类型来确定如何 “翻译” 这段内存中的二进制数据。例如:
若指针是
int*类型:访问时会将指针指向的 4 字节内存数据解读为一个int整数(比如 0x0000000A 会被解读为 10,因为 0x 是十六进制,)。若指针是
char*类型:访问时会将指针指向的 1 字节内存数据解读为一个char字符(比如 0x41 会被解读为 'A')。同样的一段内存(比如二进制 0x00000041),用
int*解读是整数 65,用char*解读是字符 'A'字符 'A' 和整数 65 数值相等,但语义完全不同 —— 一个是字符,一个是数字。
因为:
0x41 是十进制的 65,二进制是 0x01000001,
0xA 是十进制的 10,二进制是 1010。
一点一点说,当小说看就行, 都是我追问好久才明白的,这些很多之前就懂,但妈逼的之前人都是东一句西一句说东西妈逼的一点都没衔接、没体系,导致我一直知道的东西其实都是零散的,整合到一起就发现导出都是矛盾的!现在刚梳理精通!
首先比如数据:
0x00 0x00 0x00 0x41,按照大端序存储,即字节地址从低到高排列为:第 1 字节0x00、第 2 字节0x00、第 3 字节0x00、第 4 字节0x41。注意这里有个东西要说的就是,“地址”和“数据”是两码事,这里数据是
0x00000041,按照大小端存于内存,那存到了哪里?比如存到了0x100开始的地址,那具体情形就是:
所以注意看,“地址”和“存储的数据”都是十六进制,所以要区分开!我一开始是看到
0x某某某就错误地以为都是是地址,但其实我们日常,因为 1 字节 = 2 位十六进制,位数少,说着方便,就都用0x的十六进制形式表示“地址”和“数据”,而计算机里全都是二进制存的。所以存的时候都是二进制 8 位!哪怕0也要存成是
00000000,不会省略任何前导 0!但由于人们表示会有2、8、10、16进制,这是数值的表示层面也是人们书写的时候,即书写形式,实际存储固定写死就是 8 位二进制没任何商量!最前面的 0 也要写。(唉这些都是任何地方都没说清的,哎真的好累这样学习,感觉乌烟瘴气只会骗来骗去的职场,我这样真傻!尤其那些公众号教咋么面试,教各种话术面试官喜欢听什么,教各种现成的项目,导致妈逼的一群水货,然后标准越来越高)那既然说清了这些,就知道了:
1 字节 = 8 位二进制 ,但一旦非二进制就无所谓位数了,
1 字节 = 1 ~ 3 位八进制
1 字节 = 1 ~ 3 位的十进制
1 字节 = 1 ~ 2 位十六进制
那继续说如果是int*的指针指向这个数据首地址:
第1字节:00000000(0x00)
第2字节:00000000(0x00)
第3字节:00000000(0x00)
第4字节:01000001(0x41)
合并后也就是读取的结果是:00000000 00000000 00000000 01000001,转换为十六进制:
0x00000041。转换为十进制:65(计算:0x41 = 4×16 + 1 = 65,高位的0x00不影响结果)。最终结果:*((int*)ptr) = 65(作为int类型的数值 65)。而如果是
char*,只访问一个字节,仅读取指针指向的起始地址对应的第 1 个字节0x00,注意:若指针指向第 4 字节,则读取0x41,此处以指向第 1 字节为例)。那就是 0,如果指向第四个字节,就是65,ASCII就是字符'A'。
理解后我们再继续:
那如果再以小端序为例,
int*指针访问,从内存里读的时候,内存从低地址到高地址:0x41、0x00、0x00、0x00,然后合并也就是真正要读结果的时候是:00000000 00000000 00000000 01000001(实际存储顺序相反)。十六进制:0x00000041,十进制:65。
char *指针访问,仅读取指针指向的单个字节,若指向最低地址(存储 0x41 的位置):读取 0x41,十进制 65(对应 'A')。若指向其他地址(存储 0x00 的位置):读取 0x00,十进制 0。结果是样的。到这也就真正理解了大小端:
那么有些描述不清楚的地方再次梳理清晰一点就是:大小端是由CPU架构决定的,内存只是按 CPU 要求的顺序存储字节,本身无 “端序” 属性。想表示一个数,内存里大小端存的是不同的。
要表示同一个数(如 0x01020304),内存存储的字节顺序完全不同:
大端 CPU 要求内存存:0x01(低地址)、0x02、0x03、0x04(高地址)【解读的时候,低地址存的是原数据的高字节,那高字节就是数据的首位,即 CPU 按照顺序合并得到原值】
小端 CPU 要求内存存:0x04(低地址)、0x03、0x02、0x01(高地址)【解读的时候,低地址存的是原数据的低字节,也就是末位,即 CPU 按逆序合并得到原值】
就这么简单点事,之前搞不懂其实是因为解释太简练,导致主语都不知道说的是啥,搞混了0x到底值地址还是数据、不知道解读内存存的东西咋理解?谁解读?咋解读?这些其实都是因为解释的时候太简练,现在追问清楚了。
再继续说些我认为【相当重要且不知道就始终无法理解的零零碎碎的细节】:
16 是 2 的 4 次方(2⁴=16),1 位十六进制数能表示 0~15 共 16 个值,而 4 位二进制数的取值范围也是 0000~1111(对应 0~15),两者能完全对应,所以 1 位十六进制固定对应 4 位。
一位十六进制对应几位二进制?是 4 位,实际计算机存也是 强制 4 位。但写的时候可以省略前面的 0 。
0x41 是十六进制,转换为二进制,十六进制的 “4” 对应 4 位二进制 “0100”,十六进制的 “1” 对应 4 位二进制 “0001”,按原顺序把这两组 4 位二进制拼起来,就是 “0100”+“0001”=“01000001”(这里的 “+” 是拼接,不是数值相加)
现在说说进制,之前一直都觉得很懂,但再细节追问发现好多盲区。
之前进制转换轻车熟路,但没考虑一些细节,比如这里是拼接,那为何二进制“111”转十进制是相加?即 4 + 2 +1?
二进制 ↔ 八进制:拼接
二进制 ↔ 十六进制:拼接
八进制 ↔ 十六进制:拼接
八进制转十六进制:先转二进制(1 位八进制→3 位二进制),再转十六进制(4 位二进制→1 位十六进制,不足补前导 0)
十六进制转八进制:先转二进制(1 位十六进制→4 位二进制(补前导 0 凑 4 位));再转八进制(二进制串从右往左每 3 位分组(补前导 0 凑 3 位),每组变成 1 位八进制)
八进制 / 二进制 / 十六进制 → 十进制:只能相加,比如 :32 → 3×8¹ + 2×8⁰ = 24+2=26
八进制 / 二进制 / 十六进制 ← 十进制:除基取余(除法逆推),比如:十进制 26→除以 2 取余得二进制 11010;除以 8 取余得八进制 32;除以 16 取余得十六进制 1A
至于为啥十进制这么特殊?比如八进制的 10 ,那转十进制是相加算得 8,转二进制拼接的话是 001 000。其实“拼接” 是 “特殊福利”,“相加” 才是 “通用规则”:
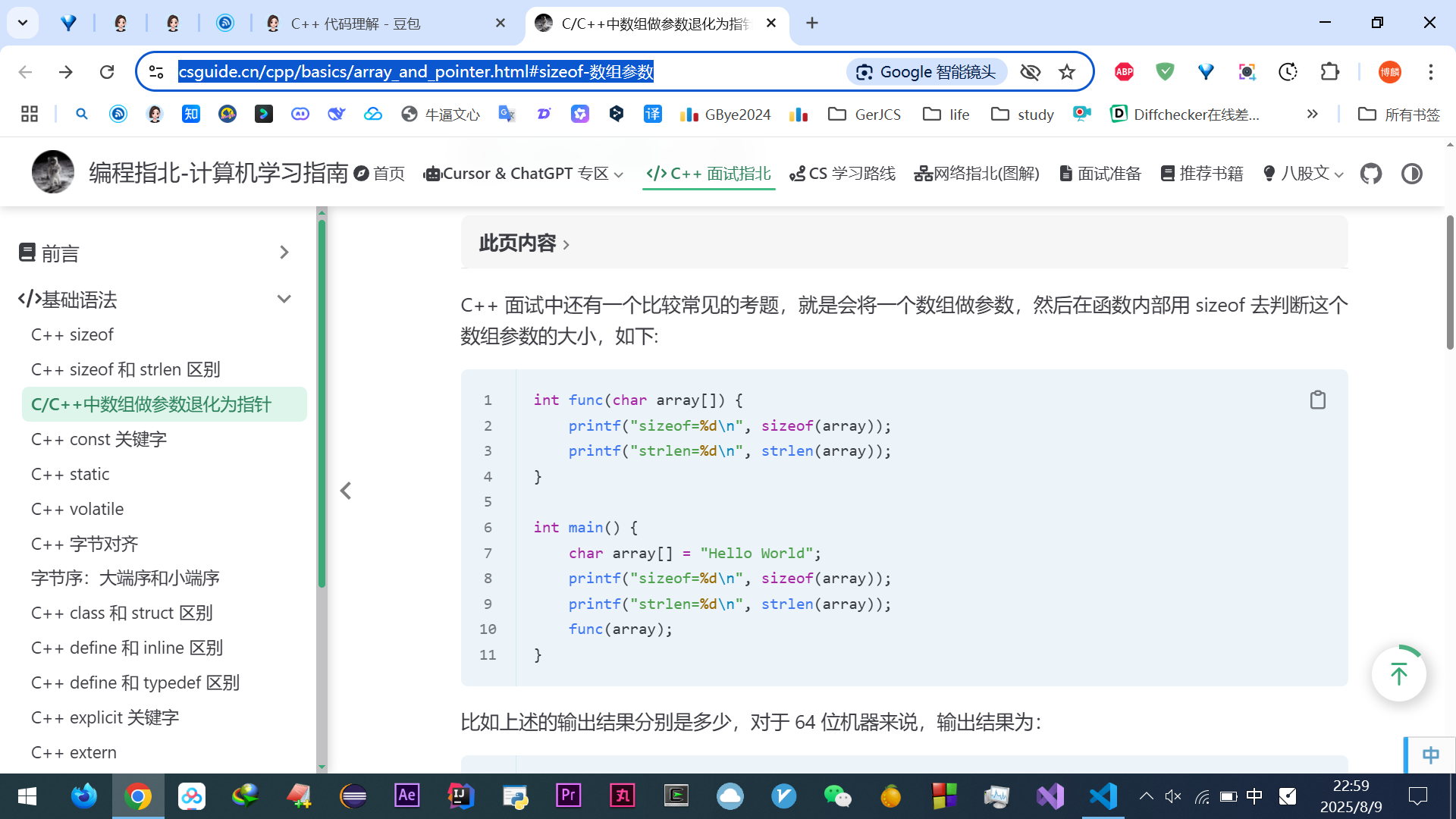
二进制、八进制、十六进制之所以能 “拼接”,是因为它们的基数是 2 的幂次(2¹=2,2³=8,2⁴=16)
1 位八进制 = 3 位二进制(因为 8=2³),每 1 位八进制数刚好能覆盖 3 位二进制的所有组合(000~111 对应 0~7);
1 位十六进制 = 4 位二进制(因为 16=2⁴),每 1 位十六进制数也刚好覆盖 4 位二进制的所有组合(0000~1111 对应 0~F)。
这种 “基数是 2 的幂次” 的巧合,让它们能按固定位数拆分 / 组合(拼接)。
但十进制的基数是 10,10 不是 2 的任何整数次幂(2³=8、2⁴=16,中间没有 10),所以:
1 位十进制数(0~9),没法用固定位数的二进制完全对应(3 位二进制只能到 7,4 位二进制能到 15,都和 10 不匹配);
反过来,n 位二进制也没法刚好对应 1 位十进制。只能用所有进制通用的 “按位权计算” 逻辑 —— 也就是 “每一位数字 × 位权,再相加”。
再比如,二进制 101100 转八进制:
- 按 “拼接”:拆成 101 和 100(3 位一组),对应八进制 5 和 4,结果是八进制 54;
按 “位权展开相加”:先算二进制 101100 的十进制 = 1×2⁵+0×2⁴+1×2³+1×2²+0×2¹+0×2⁰=32+0+8+4+0+0=44;再把十进制 44 转八进制(44÷8=5 余 4),结果也是八进制 54。
这个拼接的福利基于: 8=2³、16=2⁴,刚好能和二进制按固定位数对应,才省了 “先转十进制” 的步骤,本质还是基于 “位权” 的逻辑,不是脱离 “次方 / 位权” 的新方法。
之前觉得好像十六进制都是 4 位,但其实 0x 开头的十六进制位数无限制。只是平常接触场景是 1 字节 = 8 位二进制 = 2 位十六进制
而且一般都不写前导 0 ,直接写有效数字部分。
零零碎碎说的这么多后,开说用
int*、char*指针解读的差异(感觉这才是大小端的精华,相当重要的,不仔细思考的根本想不到这些):假设内存 4 字节是:
0x41 0x01 0x00 0x00(十六进制),小端序解读,
int*解读:读 4 字节→0x00000141(十六进制)→ 转十进制是 321(整数);
char*解读:只读 1 字节→0x41→ASCII 对应 'A'(字符)。哪怕连数值都不等。我疑惑是,为啥不按照端序来,
char*先读最后的00呢?因为端序只影响多字节数据的拼接,不影响单字节数据的读取,
假设这 4 字节的内存地址是 低地址→高地址 排列:
0x100(地址)存0x41、
0x101(地址)存0x01、
0x102(地址)存0x00、
0x103(地址)存0x00内存地址永远是 “低地址在前,高地址在后”,这是硬件规则,和端序无关,再看 “不同指针的解读逻辑”为什么端序对
char*没用?
*int解读(多字节,端序生效):
int占 4 字节,int*会从指向的起始地址(比如0x100)读取连续 4 字节,再按 “端序规则拼接成完整 int”。
小端序的规则是 “低地址存低字节,高地址存高字节”,所以 4 字节0x41(低字节,地址 0x100)、0x01、0x00、0x00(高字节,地址 0x103),拼接后是0x00000141(高字节在前,低字节在后的完整数值),对应十进制 321。这里 “小端” 的作用是 “决定 4 字节怎么拼”,不是 “决定先读哪个地址”—— 地址还是从低到高读(0x100 → 0x103),但拼的时候把低地址的字节放数值的低位。
*char解读(单字节,端序无效):
char只占 1 字节,char*只会从指向的起始地址(比如0x100)读取 这 1 个字节,不会读其他字节。不管是大端还是小端,单字节数据不需要 “拼接”,所以端序规则用不上。只要char*指向低地址0x100,读出来的就是该地址存的0x41,对应 ASCII 的 'A'。我之前 confusion 的点 “小端读就是先读最后地址的 00” 是错的 —— 端序不改变 “从低地址到高地址读数据” 的顺序,只改变 “读出来的多字节怎么拼”。
总结:
char*读单字节,只看指向的地址,和端序无关;int*读 4 字节,才需要按小端规则拼接,这俩逻辑不冲突。补充下:
0x00000041本身只是十六进制数,是地址还是数据,看它在代码 / 场景中的角色:
若写
char* p = (char*)0x00000041;,这里 0x00000041 是内存地址(指针 p 指向这个地址);- 若写
char c = 0x41;或内存中某地址存着 0x00000041(4 字节),这里 0x00000041 是数据。0x00000041 由 4 个十六进制数字对(00、00、00、41)组成,每个对对应 1 字节,共 4 字节,体现在内存中占据 4 个连续存储单元
char c = 0x41;等价于char c = 'A';,0x41 是表示字符 'A' 的 ASCII 码值(十进制 65),以十六进制形式写的常量,char 类型变量能存 1 字节数据,0x41 刚好是 1 字节,所以可以直接赋值,赋值后 c 就是字符 'A';之前说的 0x00000041,若用于char c = 0x00000041;,本质是把 32 位的十六进制数(值 65)截断为 1 字节给 c,最终 c 还是 'A';若用于int* p = (int*)0x00000041;,才是把它当内存地址核心区分:带指针符号(*)或用于赋值给指针变量时,它是地址;用于赋值给普通变量(char/int)或描述内存中存储的内容时,它是数据。
那说完上面这些零碎的基础,开始说点更进一步的实战,也通过这个实战,精通了数组究竟是咋回事,底层是咋存的,有了这个实战,才可谓是完美闭环
之前不懂啥叫 32 位数据,现在懂了。
char*读取的是指向的地址存储的字节,与大小端的关系如下,比如 32 位数据0x00000041:
存在小端系统,首地址存
0x41→char*读0x41存在大端系统,首地址存
0x00→char*读0x00核心是:
char*读的是 “指向地址的字节内容”,而内容由大小端决定。然后再具体说下,
char*读取的是指针指向的那个字节,与大小端无关,若指向首地址,大端存0x00就读0x00,小端存0x41就读0x41。大小端影响多字节数据的存储顺序,不改变char*读取单字节的规则。说白了就是,
char*指向数据首地址,但首地址存储的字节内容,由大小端决定:大端:首地址存
0x00,小端:首地址存
0x41。所以也就透彻了
char*不是跑去读首和尾啥的,他就是指啥读啥,只是指的由大小端确定好了。而内存咋存,是大端小端,由 CPU 结构规定的大小端?然后我做了一些实验:
目前主流是小端,想按照小端存数的顺序输出,就通过
char*逐个遍历:
代码:
查看代码
#include <stdio.h>int main() {int num = 0x12345678; // 假设一个32位整数char *ptr = (char*)# // 用char*逐个访问字节printf("整数 0x%X 的小端存储字节(从低地址到高地址):\n", num);for (int i = 0; i < 4; i++) {printf("地址偏移 %d: 0x%02X\n", i, (unsigned char)ptr[i]);} }输出:
char*输出能看到底层大小端存储的字节情况
int*输出的是做了加工合并后的完整值,看不出大小端。小端电脑,模拟大端的输出:
代码:
查看代码
#include <stdio.h>// 函数:判断当前系统是大端还是小端 int isBigEndian() {union {int i;char c[4];} u;u.i = 0x01020304;// 大端:低地址存0x01,小端:低地址存0x04return (u.c[0] == 0x01); }// 函数:在小端系统中按大端规则重组32位整数 unsigned int littleToBig32(unsigned int num) {unsigned char* bytes = (unsigned char*)#// 小端存储顺序:bytes[0](低地址)是最低位字节// 重组为大端:高位字节放前面return (bytes[3] << 24) | (bytes[2] << 16) | (bytes[1] << 8) | bytes[0]; }int main() {// 1. 查看当前系统主流存储方式if (isBigEndian()) {printf("当前系统是大端存储(高位字节存低地址)\n");} else {printf("当前系统是小端存储(低位字节存低地址)\n");printf("注:x86/x86_64架构(Intel/AMD)均为小端,是目前主流\n\n");}// 2. 小端系统模拟大端输出示例unsigned int num = 0x12345678; // 原始数值printf("原始数值:0x%08X\n", num);// 小端系统原生输出(直接解引用int*,与存储顺序无关)printf("小端系统原生输出(int*):0x%08X\n", num);// 模拟大端输出(手动重组字节)unsigned int bigEndianValue = littleToBig32(num);printf("小端模拟大端输出:0x%08X\n", bigEndianValue);// 3. 验证字节存储细节unsigned char* bytes = (unsigned char*)#printf("\n内存中实际存储的字节(低地址到高地址):\n");printf("偏移0:0x%02X\n", bytes[0]);printf("偏移1:0x%02X\n", bytes[1]);printf("偏移2:0x%02X\n", bytes[2]);printf("偏移3:0x%02X\n", bytes[3]); }代码解释:
代码一:
return (bytes[3] << 24) | (bytes[2] << 16) | (bytes[1] << 8) | bytes[0];num=0x12345678(小端存储,bytes [0]=0x78, bytes [1]=0x56, bytes [2]=0x34, bytes [3]=0x12):
bytes[3] << 24:0x12 → 00010010 → 左移 24 位 → 00010010 00000000 00000000 00000000
bytes[2] << 16:0x34 → 00110100 → 左移 16 位 → 00000000 00110100 00000000 00000000
bytes[1] << 8:0x56 → 01010110 → 左移 8 位 → 00000000 00000000 01010110 00000000
bytes[0]:0x78 → 01111000 → 保持 → 00000000 00000000 00000000 01111000
按位或后:00010010 00110100 01010110 01111000 → 0x12345678(大端序整数)
注意:低地址永远是内存地址的左边,从左往右,高低位永远是权重。
代码二:
union联合体,联合体u的int i和char c[4]共享 4 字节内存。特性:所有成员共用同一块内存,大小等于最大成员,可以节省内存(同内存块存不同类型数据)、解析二进制数据(用不同成员看同一块内存)、硬件寄存器操作(按位 / 按字节访问同地址)。以
0x01020304这个 32 位整数为例,大端和小端系统中,int i和char c[4]在联合体中的存储细节:大端系统(高位字节存低地址)
内存布局(地址从低到高):
地址 0x1000 → 0x01(数据的最高位字节)
地址 0x1001 → 0x02
地址 0x1002 → 0x03
地址 0x1003 → 0x04(数据的最低位字节,最右侧的)
int i 的存储:
i作为 4 字节整数,整体值为0x01020304,对应内存中 4 字节的排列就是上述顺序。char c [4] 的存储:
c是字节数组,按地址顺序访问:
c[0](地址 0x1000)= 0x01
c[1](地址 0x1001)= 0x02
c[2](地址 0x1002)= 0x03
c[3](地址 0x1003)= 0x04小端系统(低位字节存低地址)
内存布局(地址从低到高):
地址 0x1000 → 0x04(最低位字节)
地址 0x1001 → 0x03
地址 0x1002 → 0x02
地址 0x1003 → 0x01(最高位字节)
int i 的存储:
i作为 4 字节整数,整体值仍是0x01020304(逻辑值不变),但内存中字节反转排列。char c [4] 的存储:
c按地址顺序访问:
c[0](地址 0x1000)= 0x04
c[1](地址 0x1001)= 0x03
c[2](地址 0x1002)= 0x02
c[3](地址 0x1003)= 0x01核心结论:无论大端 / 小端,
int i的逻辑值(0x01020304)不变,变的是 4 个字节在内存中的排列顺序。char c[4]作为字节数组,直接暴露了这种排列差异,通过c[0]的值就能区分大小端。int负责 “整体赋值”,char[4]负责 “拆分查看每个字节的位置”,缺一不可。这也看出来了,
int哪怕存的是倒序的,读的时候也会自动整合为逻辑数据的顺序,始终看不懂底层的大小端,而只有char才能看到底层的大小端。也可以验证,
代码:
查看代码
#include <stdio.h>union EndianCheck {int num;char bytes[4]; };int main() {union EndianCheck ec;ec.num = 0x12345678; // 假设int占4字节// 输出每个字节的存储值printf("字节顺序: %02X %02X %02X %02X\n",ec.bytes[0], ec.bytes[1], ec.bytes[2], ec.bytes[3]);// 判断大小端if (ec.bytes[0] == 0x78) {printf("小端模式\n"); // 低地址存低字节(78)} else if (ec.bytes[0] == 0x12) {printf("大端模式\n"); // 低地址存高字节(12)} }- 解释:
0x%3X:
0x表示在输出前加前缀 "0x"(十六进制标识)。
%3X表示以十六进制大写形式输出,至少占 3 个字符宽度。不足 3 位,前补空格。0x%03X:
同样带 "0x" 前缀。
%03X表示以十六进制大写形式输出,至少占 3 个字符宽度。不足 3 位,前补 0 。
int*占位符%d就输出十进制,%x就输出十六进制,%o八进制再说一点:
0x00是有效数据字节,不是 “无效的”,内存里本就会存储0x00这类值,其次,指针 “指向哪个字节”,不是 “手动强制指向0x00”,而是指向存储0x00的那个内存地址—— 比如这 4 字节数据存在地址 X(存0x00)、X+1(存0x00)、X+2(存0x00)、X+3(存0x41),指针的指向是 “选择从哪个地址开始读”:
- 若代码里让
char*指针等于(char*)&int_data(int_data是这 4 字节的整数变量),它就指向 X(读0x00);
- 若让
char*指针等于(char*)&int_data + 3,它就指向 X+3(读0x41)。而一般指针指向都是最开头的首地址而之前说的比如 005 和数字 5 是一样的,这里 00 是无效的,但内存里内存地址就是实实在在存的 00,那就是有效数据,
比如
0x0041作为 16 位数据,若用char*指向 16 位的 0x0041,解引用读取低地址字节,小端模式下是 0x41(65),大端模式下是 0x00(0);比如
0x41作为 8 位数据,char*读取始终是 0x41(65)。而
0x0041和0x41用int*读取都是 65。
解引用的方法:
查看代码
short val = 0x0041; char* p = (char*)&val; // val 为 16 位的 0x0041,p 指向其低地址 char c = *p; // 解引用获取低地址字节 printf("c的十六进制值: 0x%02X,对应的字符: %c\n", (unsigned char)c, c);//小端模式下输出:c的十六进制值: 0x41,对应的字符: A //大端模式下输出:c的十六进制值: 0x00,对应的字符: (空字符)至此结束,相当透彻,太开门了,精通了可以说是
Q:地址宽度?
A:本质是CPU用来 “定位内存位置” 的 “二进制编号的总位数”。
地址宽度不是软件随便定的,而是CPU 和内存之间的 “连接线(地址总线)” 数量决定的—— 这是硬件出厂时就焊死的规则:每一条 “地址总线” 只能传输 1 位二进制数(要么 0,要么 1);32 / 64 位地址宽度 → 对应 32 / 64 条地址总线(能同时传 32 / 64 位二进制数);
可以表示最大数是 232 = 4GB 或者 264。
而
0x这种十六进制的表达,0x100是 3 位十六进制,1 位十六进制对应 4 位二进制那就是 12 位二进制:
000100000000在 64 位系统中的就是:00000000 00000000 00000000 00000000 00000000 00000000 00000001 00000000。这就是地址总线和位数的关系
32 位写死固定地址宽度就是 32 位,4 字节
64 位写死固定地址宽度就是 64 位,8 字节
Q:上面说了地址,那再说下“地址”和“数值”有何不同?
A:在 64 位系统中存储时,
若定义为
long long类型(64 位系统中默认 8 字节的整数类型):存储时同样补前导 0 到 64bit,占 8 字节;若定义为
int类型(64 位系统中多数仍为 4 字节):则补前导 0 到 32bit,占 4 字节 —— 但这是 “数据存储”,和 “地址存储” 的 8 字节规则无关,地址在 64 位系统中永远是 8 字节,不受数据类型影响。总结:64 位的话,地址的存储宽度:固定 8 字节(因 64bit=8 字节,是 64 位系统的硬件规则);
地址 0x100 的存储:二进制补前导 0 到 64bit,实际占 8 字节;
和 32 位系统的区别:仅在于地址存储宽度(32 位 4 字节,64 位 8 字节),但 64 位系统是当前个人笔记本的绝对主流,地址存储只看 8 字节规则即可。
无论是 int 还是 long 都是补的前导 0 位数不同,但实际表示的都是 256 这个数,具体计算过程:
十六进制数每位的权重是 16 的幂,从右往左依次是 16⁰、16¹、16²……
0x100 是 3 位十六进制数,从右到左各位数字依次是:第 0 位是 0,第 1 位是 0,第 2 位是 1。任何进制中都是右侧是第 0 位。
第 2 位(最左):1 × 16² = 1 × 256 = 256
第 1 位(中间):0 × 16¹ = 0 × 16 = 0
第 0 位(最右):0 × 16⁰ = 0 × 1 = 0至此,小知识点完结
第二次体验到“知道一点就明白,再知道一点反而糊涂,再知道一点就完全懂了修正最开始的假明白”。
插入:
另外再说下之前 acm 金牌西交栗子保研到南京大学,鄙视考研的都在抄书上代码, 发朋友圈阴阳怪气考研的说“妈妈快看,十进制真的有 10 诶”
现在重新理解这个问题,十进制其实确实有十,但这是结论,单独拿出来很容易引起歧义,严谨的说, 十进制只有 0 ~ 9,在往上就是 10,我一直以为是单纯的叫“一零”,但就叫十,
再比如:
二进制满 2 进 1,单个位符号是 0、1(无 2);
十六进制满 16 进 1,单个位符号是 0-9、A-F(无 16);
十进制满 10 进 1,单个位符号是 0-9(无单独的 “10” 符号)—— “10” 是十进制的两位组合,代表 “1 个 10 + 0 个 1”,本质是进位后的表示,和二进制的 “10”(代表 2)、十六进制的 “10”(代表 16)逻辑完全一致,并非十进制有 “16”“2” 那种单独的超范围符号。
对我而言读法只是方便沟通便于理解,过多的较真没意义,所以说下符号“10”的二进制、十进制、十六进制分别咋读:
二进制:10 读作“二进制一零,十进制 2”
十进制:10 表示比 9 多 1 的数值,就读作十,“一零”是单纯念符号,未体现十进制的位值逻辑
十六进制:10 读作“十六进制一零”、“0x一零”、“十进制 16”
再讲白一点,A 是 10,10 是 16,两者差了 6 个数值,完全是两回事。
所以学通了就可以大胆的说,十六进制有 16(表示为
0x10),二进制有 2,十进制有 10,这么想“妈逼的一个进制连数都表示不全,咋可能?”,关键是单个位可以表示最大数,那确实没有2、10、16基数指某一进制中允许使用的不同数字符号的总数,也是该进制 “逢几进一” 的那个“几”:
十进制基数 = 10:用 0-9 共 10 个数字,计数逢 10 进 1(如 19+1=20);
二进制基数 = 2:用 0、1 共 2 个数字,计数逢 2 进 1(如 11+1=100);
十六进制基数 = 16:用 0-9、A-F(共 16 个符号),计数逢 16 进 1(如 0xF+1=0x10);
再多逼逼几句其他的,不然妈逼的这种抽象的玩意没法和实际对应,总忘:
64 位系统需 64 根实际的物理地址线,即电线,很微小,继承在CPU上,那 64 根电线用 0、1 来控制出 264 种状态,也是用于定位内存单元的数字编码,每种状态 (每个编码)就叫一个地址,对应的就是内存虚拟分割的最小单元。(只是很多用不到,所以 64 位系统实际 48 根电线)
再深入抽插(如果不知道上面这些还好,一旦了解这些反而觉得很乱,因为我内心还有下面的思考疑惑,但现在疑惑解开后,豁然开朗了,直接精通咔咔咔咔!):
32 位系统说,总共是 232 个地址编号,每个地址编号绑定 1 字节的内存单元,所以 32 位系统总共 42 亿字节,也即是 4GB,再多逼逼下,B 是字节,G 是吉,GB 是吉字节,所以说 4GB = 4G 字节 = 4 吉字节,
至此也明白了为啥一会说“【一个地址是一字节空间】”,一会又说“【地址他妈的是64位系统是8字节,32位系统是4字节】”,内心 OS:妈逼的地址到底几字节??
现在捋顺完真他妈透彻艹,但费精力!写了一周
这都是我一点一点追问出来的,期间豆包还反复说错误的东西,逐步碎片化捋顺,然后质疑豆包,反复打磨思考追问,最后形成一个正确的知识,好鸡巴坎坷艹
自己探索学习比看人家写好多了,之前小林那估计也看过但完全没印象,自己思考摸索推进追问知识才深刻!!书读百遍其义自见
第一次体验到“知道一点就明白,再知道一点反而糊涂,再知道一点就完全懂了修正最开始的假明白”
说了这么多就是捋清楚各种术语,就跟仪仗队一开始只站军姿一样,现在透彻了,开始说这个写法三的代码,妈逼的铺垫的知识,边学边写博客搞了俩星期,现在再看这些针对写法三代码的解释就相当开门透彻理解了:
逐处解释带
*的部分和void的作用:
- 1. 比较函数
compareIntint compareInt(const void* a, const void* b) {return *(int*)a - *(int*)b; }
void* a:void*是 "无类型指针",可以指向任何类型的数据,但不能直接解引用(因为不知道指向的数据大小)。这里作为参数,是为了让函数能接收任意类型的指针(实现通用性)。
const void* a:const表示指针指向的数据不可修改,保证比较时不会意外修改原数据。
(int*)a:将void*强制转换为int*(整数指针),明确指向 "int 类型数据",此时指针知道要访问 4 字节(假设 int 占 4 字节)。
*(int*)a:对转换后的int*解引用,获取指针指向的 int 类型数值。
- 2. 比较函数
compareStringint compareString(const void* a, const void* b) {return strcmp(*(char**)a, *(char**)b); }
void* a:同上,无类型指针,接收任意类型数据的地址(这里实际接收的是 "字符串指针的地址")。
(char**)a:将void*转换为char**("指向字符串指针的指针")。因为排序的是char* strArr[](字符串指针数组),数组中每个元素是char*(字符串指针),所以a实际指向的是char*类型的元素,因此需要两层指针。
*(char**)a:解引用char**,得到char*(字符串的地址),传给strcmp比较字符串内容。
- 3. 通用排序函数
mySortvoid mySort(void* arr, int size, int elementSize, int (*compare)(const void*, const void*)) {// ...char* p1 = (char*)arr + j * elementSize;char* p2 = (char*)arr + (j + 1) * elementSize;// ... }
void* arr:无类型指针,指向要排序的数组。因为数组可能是 int 数组、字符串指针数组等任意类型,用void*可以兼容所有类型。
int (*compare)(const void*, const void*):函数指针,指向 " 接收两个const void*参数、返回 int 的函数 "。用于接收不同类型的比较函数(如compareInt或compareString),实现根据数据类型动态选择比较逻辑。
char* p1:将void* arr转换为char*(字符指针),因为char*每次移动 1 字节,方便按 " 元素大小elementSize" 计算下一个元素的地址(如j * elementSize就是第 j 个元素相对于数组开头的偏移量)。
(char*)arr + j * elementSize:通过字符指针的算术运算,定位到数组中第 j 个元素的地址(无论元素是 int、char * 还是其他类型,都能准确定位)。
- 4.
main函数中的调用mySort(intArr, 3, sizeof(int), compareInt); mySort(strArr, 3, sizeof(char*), compareString);
intArr:整数数组名, decays 为int*(指向第一个 int 元素的指针),传给mySort时自动转换为void*(兼容)。
strArr:字符串指针数组名,decays 为char**(指向第一个char*元素的指针),传给mySort时自动转换为void*(兼容)。
compareInt和compareString:函数名作为函数指针传入mySort,供排序时调用。
- 核心总结:
void*的作用:作为 "通用指针",打破类型限制,让函数能接收 / 处理任意类型的数据(数组、不同类型的元素等)。带
*的指针转换(如(int*)a、char**):void*无法直接使用,必须转换为具体类型的指针才能解引用或进行类型相关的操作,转换时需要匹配实际指向的数据类型(否则会出错)。函数指针
(*compare):让通用排序函数能根据不同数据类型,调用对应的比较逻辑,实现 "一套排序代码处理所有类型" 的泛型效果。各个函数里的强制转
int*是为了读4字节,而这里p1只是个索引,用char*是为了通过elementSize计算偏移(j * elementSize)能精确定位到任意类型元素的起始地址,无论元素是int(4 字节)还是char*(8 字节),都能精确移动到下一个元素。而接下来的compare去调用实际的是真正的比较数据,会根据实际数据类型(如int或char*)进行指针转换和解引用,提取真实数据进行比较(如*(int*)a取整数,*(char**)a取字符串地址),实现对应类型的比较逻辑。
char* strArr[] = { "cat", "apple", "banana" };每个元素都是char*(字符串指针),指向对应字符串的首地址。如strArr[0]是指向 "cat" 首字符 'c' 的指针,strArr[1]是指向 "apple" 首字符 'a' 的指针。
mysort的compare接收所有参数和返回值是这个样子的函数,然后main里的mysort传实际的。Q:狗逼玩意为啥刷题没用过指针,现在学C++不用指针好像活不了一样?
A:因为指针是 C 语言里 “处理未知类型、实现通用功能” 的唯一手段。刷的算法题场景固定、类型单一,自然用不到;但一旦要写能复用的通用代码(比如库函数),就绕不开
就这一段搞了三周艹!~~~~(>_<)~~~~以上全部内容都是自己追问豆包得来的




关于 字节序:
内存地址:从低到高的顺序排列的,就像阅读时从左到右一样,地址逐渐增大
高低位字节:比如 1111,是 8 + 4 + 2 + 1,这里最左边的是高权重,就叫高字节位
大端序:高位字节存储在低地址处,低位字节存储在高地址处
0x12345678的内存布局:0x12 | 0x34 | 0x56 | 0x78小端序:低位字节存储在低地址处,高位字节存储在高地址处
0x12345678的内存布局:0x78 | 0x56 | 0x34 | 0x12
看完上面的这就直接可以跳过了,真的狠狠艹死这个指针,现在看这些真的通透,可以说从讨厌指针,到现在精通指针了。
C 的
(char*)&num与 C++ 的reinterpret_cast一样。那直接 copy 指北的代码就相当好理解了:查看代码
#include <iostream>int main() {int num = 1;// 将int类型指针转换为char类型指针,取第一个字节char* ptr = reinterpret_cast<char*>(&num);if (*ptr == 1) {std::cout << "Little-endian" << std::endl;} else {std::cout << "Big-endian" << std::endl;} }
网络传输用大端序,TCP/IP 的规定,本地小端的话,那传输之前就要转大端,一般通过:
htonl() / htons()将主机字节序转为网络字节序(32位/16位),ntohl() / ntohs()反之。“l”是“long”的缩写,对应32位整数(如 IPv4 地址);“s”是“short”的缩写,对应16位整数(如端口号)。
基本 Linux、win、Mac 都是小端
关于 C++中类(class)和结构(struct)的区别:
(继上一个【指针】之后,又一次下定决心,狠狠往死里操【类】这块的东西,必须精通了,妈逼的这块总他妈各种看不懂)
(这一块边学边写弄了 2 天艹)
(无穷无尽的砸时间!!!~~~~(>_<)~~~~)
唉,这些之前看菜鸟教程就看了,但全忘记了,重新学吧,傻逼菜鸟教程,不过这编程指北也没比菜鸟好哪去!唯一优点就是当个地图,毕竟是实实在在的大厂员工,知识点不至于过时、学偏,当个指引,但真的大厂80%都是水货,一群速成的狗逼!
小林coding说算法想10min没思路就看答案,真的垃圾。
吴师兄公众号标题,大家刷题都是独立刷完的吗?
鱼皮的算法很垃圾,其实只有自己想破脑袋才行,就鱼皮他的算法网站 kmp 我简单看了下,真不咋地,至少他的算法比我差远了!
那些曾经一起刷算法的大佬都哪去了?被世道恶心死了估计
.c为 C,.cpp为 C++,C++ 的struct比 C 的struct多了一些扩展。C 中,struct 只有成员变量,没成员函数。
C++ 中,struct 等价于 class,既可有成员变量,又可有成员函数。
说说 C++ 的 struct 和 class 的不同:
对比维度 class struct 成员默认访问权限 private(私有) public(公有) 继承默认访问权限 private(私有继承) public(公有继承) 定义模板参数 支持 不支持 之前提到过的模版,是函数模版,
template <模板参数列表> // 模板声明(告诉编译器:这是一个模板) 返回值类型 函数名(参数列表) { // 函数定义(通用逻辑)// 函数体 }现在重新往祖坟上刨,一直追问到盘古开天辟地、女娲补天
首先,模版机制的应用场景有两种:函数模版 和 类模版。
函数模板没有
struct关键字,struct只定义类,定义类的时候和class等效,只是访问权限不同。
函数模板格式:
template <class/typename T> 返回类型 函数名(参数) { ... }(<>里的叫模版参数列表,只用class或typename声明,后跟函数定义)类模板格式:
template <class/typename T> class/struct 类名 { ... }(用class或typename声明参数,后跟class或struct定义类), 前面class/struct 类名加粗的“类名”,也可以叫“结构体名”,C++ 中结构体(struct)是类(class)的一种特殊形式(默认访问权限不同)。而class/struct只是访问权限不同简单说:函数模板只涉及
class/typename(参数)+ 函数定义;struct只出现在类 / 结构体的定义中,与函数模板无关。class和typename在模板参数里只是 “类型参数的声明符号”,判断是类模板还是函数模板,只看模板后面定义的是「类 / 结构体」还是「函数」。而模板参数列表中class和typename等效。至此追问懂了之前的疑惑,“妈逼的咋一会 class、struct 等效?一会 class、typename 等效”,现在懂了。
刨个祖坟,就是类的 声明 和 定义:
声明:告诉编译器 “有这么个东西存在”,只说名字和类型,不说具体内容。
定义:告诉编译器 “这个东西具体是什么样的”,不仅有名字和类型,还要给出具体实现 / 内容。
1. 先看普通类(非模板)的声明 vs 定义
(1)类的声明(只告诉 “有这个类”)
格式:
class 类名;(没有类体{}),作用:让编译器知道 “存在一个叫 XX 的类”,后续代码可以用这个类的指针 / 引用(但不能创建对象、访问成员)。// 这是类的声明(仅告诉编译器:有个类叫Person) class Person; // 声明后可以用指针/引用(因为指针只需要知道“有这个类”,不需要知道类里有啥) void printPerson(Person* p); // 合法,编译通过(2)类的定义(告诉 “类里有啥”)
格式:
class 类名 { 成员变量/成员函数 };(必须有类体{},且要写成员)作用:明确类的结构(有哪些成员变量、成员函数),只有定义后,才能创建类的对象、访问成员。
// 这是类的定义(明确Person类里有name和age成员,还有show函数) class Person { public:string name; // 成员变量int age;void show() { // 成员函数(这里连实现也写了,属于“定义+实现”)cout << name << ":" << age << endl;} };// 定义后才能创建对象(因为创建对象需要知道类的大小、成员结构) Person p; // 合法,编译通过 p.name = "张三"; // 合法,能访问成员2. 为什么必须区分?—— 解决 “互相引用” 和 “编译顺序” 问题
比如两个类 A 和 B,A 里要用到 B 的指针,B 里要用到 A 的指针:如果只写定义,会出现 “编译顺序死锁”(编译器先编译 A 时,不知道 B 存在;先编译 B 时,不知道 A 存在)。这时候必须用声明先 “占位”:
// 先声明类B(告诉编译器:有个类叫B) class B; // 再定义类A(A里用B的指针,因为已经声明过B,编译器能识别) class A { public:B* b_ptr; // 合法,因为B已经声明了 };// 最后定义类B(此时A已经定义完,B里用A的指针也合法) class B { public:A* a_ptr; // 合法,因为A已经定义了 };如果不先声明 B,直接定义 A 时写
B* b_ptr,编译器会报错 “B 未定义”—— 这就是声明的必要性。刨完祖坟继续
函数模版的例子:
查看代码
#include <iostream> // 函数模板声明与定义 template <typename T> T add(T a, T b) {return a + b; }int main() {int num1 = 1, num2 = 2;double d1 = 1.5, d2 = 2;// 自动推导类型调用函数模板std::cout << add(num1, num2) << std::endl; // 显式指定类型调用函数模板std::cout << add<double>(d1, d2) << std::endl; //没有<double>强转也行 }解释下,太多知识点了:
<typename T>:声明一个模板类型参数T,T是占位符,代表任意数据类型(如int、double等)。
add(num1, num2):调用时编译器自动推导T为int(因参数是int)。
<double>:显式指定T为double,强制按此类型处理参数。这也是泛型编程的核心,即让代码能够通用。函数模板和类模板在语言里设计目的是能通过类型参数(如
T),让编译器自动推导或手动指定任意类型 ,实现代码复用。template <typename T> T add(T a, T b)这个函数模板里,三个T必须同类型。因为
typename T声明了一个类型参数,整个函数模板里的T都代表这同一个被声明的类型 。如想不同类型加法template <typename T1, typename T2> auto add(T1 a, T2 b)。T1和T2可以相同也可以不同
- 函数模版里:
double d1 = 1.5, d2 = 2;,std::cout << add<double>(d1, d2) << std::endl;,想准确就写成但其实就算依旧只有一个类型template <typename T1, typename T2> auto add(T1 a, T2 b) { return a + b; }T,就算没double强转也对,因为编译器做了隐式类型转换优化,但这是编译器的扩展行为,C++ 要求不是这样的,需要严谨写,如果不同编译器的话可能会有错,
类模版的例子:
查看代码
#include <iostream> #include <string> // 类模板声明与定义 template <typename T> class Pair { public:T first;T second;Pair(T a, T b) : first(a), second(b) {} };int main() {// 显式指定类型实例化类模板Pair<int> p1(1, 2); Pair<std::string> p2("hello", "world"); std::cout << p1.first << " " << p1.second << std::endl;std::cout << p2.first << " " << p2.second << std::endl; }解释下,太多知识点了:
类:就像一张蓝图 / 模板,规定了 “要造什么样的东西”。
实例化:按照这张蓝图,真正 “造东西” 的过程。
对象:最终 “造出来的东西”。
实例化:把类模板里的 “类型占位符 T” 换成具体类型(比如 int、string),生成一个能直接用的实际类,这就叫实例化。
构造函数
Pair(T a, T b) : first(a), second(b) {},用初始化列表初始化first和second,参数类型必须与T一致(实例化时匹配)
不同于函数模版,类模版一般都要显示指定类型,实例化时必须显式指定
T的类型(如Pair<int>、Pair<std::string>),编译器无法自动推导。- 初始化成员变量的方式之一就是初始化列表,也可以在构造函数体内赋值:
Pair(T a, T b) {first = a;second = b; }但初始化列表更高效(直接初始化),尤其对于 const 成员、引用或没有默认构造函数的对象,必须用初始化列表
咋理解这句话?
先明确大前提:
C++ 的 “类”= C 语言的 “结构体”+ 函数(封装)
C 里你用
struct存数据(比如struct Point { int x; int y; }),但函数要写在结构体外面(比如void set(Point* p, int x, int y))。C++ 的
class直接把 “数据” 和 “操作数据的函数” 包在一起,这些函数就叫 “成员函数”,其中构造函数是最特殊的一个 —— 专门用来初始化 “类里的数据”(对应 C 里你手动调用set函数初始化结构体的步骤)。对象初始化的核心就是靠构造函数 —— 创建对象时,构造函数会自动执行,专门负责给对象的成员变量 “赋初始值”,这是它的核心作用。构造函数中给成员变量初始化的两种不同写法:
写法一、比如用初始化列表:
Student(string n) : name(n) {}(冒号后直接初始化成员);写法二、比如函数体内赋值:
Student(string n) { name = n; }(函数体里给成员赋值)。
而 C 语言结构体(手动初始化):
查看代码
#include <stdio.h> // 只存数据 struct Pair {int first;int second; };// 初始化函数(必须手动调用) void Pair_init(struct Pair* p, int a, int b) {p->first = a;p->second = b; }int main() {struct Pair p;Pair_init(&p, 1, 2); // 手动调用初始化printf("%d %d\n", p.first, p.second); }开始说 C++ 的:
C++ 类(自动初始化,带构造函数的函数体内赋值):
查看代码
查看代码 #include <iostream> // 数据+函数(构造函数)封装在一起 class Pair { public:int first;int second;// 构造函数:和类名相同,无返回值,参数列表接收初始化数据Pair(int a, int b) { // (int a, int b)就是参数列表first = a; // 函数体内赋值second = b;} };int main() {// 创建对象时自动调用构造函数,无需手动初始化Pair p(1, 2); // 直接传参给构造函数的参数列表std::cout << p.first << " " << p.second << std::endl; }核心概念 1:
构造函数(解决 “类的对象怎么初始化”)
作用:C 里定义结构体变量后,要手动赋值(比如
Point p; p.x=1; p.y=2;);C++ 里用构造函数,创建对象时自动执行,直接把数据装进去,不用手动调函数。关键特征:
函数名和类名完全一样(比如类叫
Pair,构造函数就叫Pair);没有返回值(连
void都不写);必须通过 “创建对象” 触发(比如
Pair<int> p1(1,2),括号里的 1 和 2 就是传给构造函数的参数)。和 C 的对比:相当于把 C 里 “定义结构体 + 手动调用初始化函数” 两步,合并成 “创建对象时自动执行” 一步。
核心概念 2:
参数列表(构造函数的 “输入接口”)
作用:就是构造函数的 “参数”,用来接收创建对象时传入的值(比如
Pair(T a, T b)里的(T a, T b))。和 C 的对比:完全和 C 语言函数的参数列表一样(比如 C 里
void add(int a, int b)的(int a, int b)),没任何新东西 —— 你给构造函数传什么值,就用这些值初始化对象里的数据。
C++ 类(自动初始化,带构造函数的初始化列表赋值)(必须用的 3 种场景):
- 场景 1:成员变量是 const:
class Pair { public:const int first; // const变量必须定义时赋值const int second;// 必须用初始化列表,即定义时赋值,会先执行冒号后的赋值再执行{}里的Pair(int a, int b) : first(a), second(b) {} // 错误写法:函数体内赋值// Pair(int a, int b) { first = a; second = b; } // 编译报错 };//const 成员必须在初始化列表({} 前)赋值。
- 场景 2:成员变量是引用:
class Pair { public:int& first; // 引用必须定义时绑定int& second;// 必须用初始化列表Pair(int& a, int& b) : first(a), second(b) {}// 错误写法// Pair(int& a, int& b) { first = a; second = b; } // 编译报错 };
- 场景 3:成员是 “无默认构造函数的类”
// 这个类没有无参构造函数(默认构造函数) class A { public:A(int x) {} // 只有带参构造函数 };class Pair { public:A a; // 成员a是类A的对象// 必须用初始化列表给A传参Pair(int x) : a(x) {} // 错误写法:函数体内无法初始化a// Pair(int x) { a = A(x); } // 编译报错(因为A没有默认构造函数) };总结:构造函数:C++ 替你自动调用的 “初始化函数”,名字 = 类名,无返回值。
参数列表:构造函数的输入(和 C 函数参数完全一样)。
初始化列表:
类名(参数) : 成员1(值), 成员2(值) {},专门解决 const、引用、特殊类成员的初始化,比函数体内赋值更底层、更必要核心概念 3:
初始化列表(给类里的数据 “直接赋值” 的工具)
作用:专门给类里的 “成员变量”(比如
Pair里的first和second)赋值,写在构造函数参数列表后面,用冒号开头(比如Pair(T a, T b) : first(a), second(b) {})。为什么需要?你可能会想:“我在构造函数里写
first=a; second=b;不也能赋值吗?”—— 对,但有 3 种情况必须用初始化列表(否则编译报错):
成员变量是
const修饰的(比如const T first):C++ 规定const变量必须 “定义时就赋值”,构造函数体里赋值算 “后续修改”,不允许;成员变量是引用(比如
T& first):引用必须 “定义时绑定变量”,也不能在函数体里赋值;成员变量是另一个 “没有默认构造函数的类” 的对象(比如类
A只有A(int x)这个构造函数,没有无参的A()):创建A对象必须传参数,只能用初始化列表传。和 C 的对比:C 里没有这个东西,因为 C 的结构体里没有
const成员必须初始化、引用这些场景 —— C++ 为了处理这些新场景,才加了初始化列表。到底咋回事?我理解,初始化列表 和 函数体内赋值,不都是创建的时候传递吗?
主要差别就是时机!
C 里
struct Pair p;先创建 “空对象”,再调用函数赋值C++ 里的两种方式:
对普通
int成员:
Pair(int a,int b){first=a;}→first先默认生成随机值,再被a覆盖(两步);
Pair(int a,int b):first(a){}→first刚创建就直接用a初始化(一步),没有中间随机值阶段。关键在特殊成员(非普通
int):如果成员是
const int或引用(如int& ref),只能用初始化列表—— 因为它们必须在创建时就确定值,不允许先默认再覆盖(函数体内赋值会直接报错)而所有不管是不是 const 的成员变量,创建时机都是进入构造函数体之前创建的 ,而不是在 “函数定义时” 或 “创建对象时才开始创建”。
另外,明确几个术语:
构造函数的函数定义:
Pair(T a, T b) : first(a), second(b) {}。创建对象:
Pair<int> p1(1, 2);、Pair<std::string> p2("Hello", "world");。所以,函数体内赋值 和 初始化列表 的差别是:
对于函数体内赋值的比如非 const 成员:
创建时如果没在初始化列表指定值,会先默认初始化(比如
int类型默认是随机值,不是 “没值”);进入构造函数体后,再用
first = a覆盖这个默认值(本质是 “赋值”,不是 “初始化”)对于 const 成员:
它的规则是「创建时必须确定值,不能默认初始化」(因为
const一旦创建就不能改);所以必须在「创建它的那一刻」就通过初始化列表赋值(
first(a)),不能等进入构造函数体再赋值(此时它已经创建完了,const不允许改)。
再说一句:const 成员必须用初始化列表(函数体里赋值会报错)。非 const 成员既可以用初始化列表,也可以用函数体赋值(两种都合法)
查看代码
class A {int x; // 非constconst int y; // constpublic:// 正确:y必须放初始化列表,x两种方式都行A(int a, int b) : y(b) { x = a; // x在函数体赋值}// 也正确:x和y都放初始化列表A(int a, int b) : x(a), y(b) {} };所以至此就懂了
最后总结:
C++ 的
class定义一个模板(比如Pair),创建对象时(比如Pair<int> p1(1,2)),会自动调用和类名同名的构造函数;构造函数通过参数列表接收你传的 1 和 2,再通过初始化列表(或函数体)把 1 和 2 赋值给first和second—— 整个过程本质就是 “自动初始化对象”,比 C 手动初始化结构体更高效。C++ 里
Pair p(1,2);这一句,就等价于 C 里struct Pair p;+Pair_init(&p,1,2);两句的效果。
来个练习,开开胃,压压惊,懂懂术语:
查看代码
#include <iostream> using namespace std;class MyClass { public:int a; // 非const成员const int b; // const成员// 构造函数MyClass(int x, int y) : b(y) { // 初始化列表:创建b时直接赋值ya = x; // 函数体:a先默认创建(随机值),再被x覆盖} };int main() {// 定义对象p(同时创建对象及其成员)MyClass p(10, 20); // 这一行就是“创建对象”:分配内存并初始化成员cout << p.a << endl; // 输出10(被覆盖后的值)cout << p.b << endl; // 输出20(创建时就确定的值) }
梳理底层执行逻辑:1、根据代码
MyClass p(10, 20); // 1. 定义对象p(触发后续步骤),执行MyClass p(10, 20);时,先根据传的实参(10、20,都是 int 类型),去类里匹配对应的构造函数(确认是否存在MyClass(int, int)这种参数类型的构造函数),只有匹配成功后,才会开始 “创建类的实例”(也就是为对象 p 分配内存、初始化成员变量)然后如果是 const 成员,就通过初始化列表在创建时直接初始化。
非 const 的就先随机再覆盖
2、为对象 p 分配内存(准备创建);
3、传递实参 10、20 给构造函数;
4、开始创建成员:
const int b:通过初始化列表b(y)直接用 20 创建(一步到位);
int a:先默认创建(随机值),进入构造函数体后被a = x(10)覆盖。5、最终效果:
p.a=10,p.b=20。
上面是宏观框架,开始说零零碎碎的知识点 & 后续追问:
看变量是 普通变量 还是 指针变量:
p.first:当p是普通变量(结构体名称)(如 C 的struct Pair p、C++ 的Pair p)时用点,直接访问成员。
p->first:当p是指针变量(指向结构体名的那个指针)(如 C 的struct Pair* p、C++ 的Pair* p)时用箭头,先解指针再访问成员。
再说下上面的“场景 3:成员是 “无默认构造函数的类”里,什么叫“没有无参构造函数”?
意思是这个
A类不存在 “不需要传参数就能调用的构造函数”:C++ 类默认会生成一个「无参构造函数」(比如
class A { };,能直接A a;创建对象),但如果自己写了「带参构造函数」(比如A(int x) {}),编译器就不会再自动生成无参构造函数了 —— 此时A类就只有A(int x)这一个构造函数,必须传int参数才能创建对象,这就叫 “没有无参构造函数。“没有无参构造函数” 是 C++ 里的标准表述,比 “只有有参构造” 更严谨,更直接点出关键问题(无法默认创建对象)。
为啥一会说
A(x)必须有参数,一会又可以A a没参数,一会又必须Pair p(1,2)必须有参数?类内部是声明,不是创建,无论构造函数有无参数,都可以直接不写参数,比如
A a,不占内存。类外部比如
main里是创建对象,必须严格按照构造函数的有无参形式,占内存生对象。那
A a声明完,a(x)是用参数 x 实际创建这个成员,必须匹配构造函数的形式,即必须有x。代码:
class Pair { public:A a;// 初始化列表:在创建a的瞬间就传参Pair(int x) : a(x) { // 重点是这里的 : a(x)// 此时a已经创建完成} };执行顺序是:
先执行
a(x):调用 A 的构造函数A(int x)创建 a(传参 x)再执行构造函数体
{}里的代码那错误写法咋回事? (精华,妈逼的就这个东西追问豆包好久才说出来)
class Pair { public:A a;Pair(int x) {// 进入{}前,C++会强制创建a(因为a是成员)// 但创建时没写A a(x),编译器只能试A(),而A没有,所以报错a = A(x); // 这行想赋值,但a根本没创建出来,执行不到} };
进入
{}之前,必须先创建 a(C++ 有个铁律:在构造函数的函数体也就是 {} 里的代码执行前,必须先创建完所有成员对象)创建 a 时没有传参,会尝试调用
A()(A 没有这个构造函数,直接报错)所以
a = A(x)永远没机会执行如果想在声明时就创建,语法上不允许(类里声明成员不能直接传参)。所以必须用初始化列表,相当于在创建 a 时补传参数:有了之前铺垫也懂了 创建 和 声明 差别,类里都是先声明成员,再搞值。
创建对象的那一刻(不管是写
Pair p;还是Pair p(1,2);),就必须确定调用哪个构造函数。如果写
Pair p;,本质是在 “调用无参构造函数”,但第一部分的Pair类里没有无参构造函数,所以从根上就不允许这么写,跟 “后续补不补参数” 没关系
豆包给的“场景 3:成员是 “无默认构造函数的类”,狗逼玩意连个
main都没有,补全后理解:查看代码
#include <iostream> using namespace std;// 1. 先定义A类:必须用带参构造(A(int x))创建对象,没有无参构造 class A { public:// A类的带参构造函数:创建A对象时必须传1个int参数A(int x) {cout << "A类的带参构造被调用!传入的参数是:" << x << endl;} };// 2. 再定义Pair类:里面包含A类型的成员a class Pair { public:A a; // Pair的成员a,是A类的对象(必须符合A类的创建规则)// 正确写法:用初始化列表给a传参Pair(int x) : a(x) { // 关键点:a(x)就是调用A的带参构造A(x)cout << "Pair类的构造函数体执行!" << endl;}// 错误写法(注释掉,打开会编译报错):// Pair(int x) { // a = A(x); // 进入函数体前,a已经创建失败了// } };// 3. main函数:实际创建对象,看运行过程 int main() {cout << "开始创建Pair对象p,传入参数5:" << endl;Pair p(5); // 这里会触发Pair的构造,进而触发A的构造 }那再思考,
Pair(int x)里的x是为了给成员a传参才加的。
Pair类里有个成员a(A类型),而A的构造函数必须要一个int参数(A(int x))。所以
Pair的构造函数必须接收一个参数(这里叫x),再才能通过: a(x)把这个参数传给a,让a能正常创建。如果Pair的构造函数不带x,比如写成Pair(),那它就没法给a传参,a就创建不了,代码会报错。A a 本身语法没错,但实际创建 A 类型对象时会错(除非用初始化列表传参)
这个“类包类”在 C++ 里叫 “成员对象”。
以上是从狗鸡巴不会到精通的心路历程。
妈逼的这么简单点事,墨迹了两天操.你.妈的,追问好久好久,任何知识搞不懂只有两个原因:1、自己追问不清晰不够钻研。2、解释的不清晰。
追问豆包学完这些,开始继续看编程指北:
那也就明白他的话了:
但他这么比较感觉完全没搞懂啊,感觉思维好垃圾,怎么把他俩搞一起去了。
C++ 里和 C 语言一样的就叫 POD,POD 的条件:
平凡:特殊函数(构造、析构、拷贝等)都是编译器自动生成的,没有自定义的,也没有虚函数这些复杂的东西。
标准布局:内存里成员排列顺序、对齐方式和 C 结构体完全一样,没有因继承、访问控制等导致的布局混乱。
大白话:
若一个结构 / 类,没有 C++ 那些花里胡哨的东西(虚函数、自定义构造 / 析构、继承这些),内存布局和 C 一模一样,那它就是 POD。
这样的类型能直接用
memcpy复制、能和 C 代码无缝交互,底层操作很方便。能安全做底层内存操作。安全做底层内存操作指的是:
C 语言的结构体是 “纯数据块”,可以用
memcpy直接拷贝、用指针直接操作字节。但 C++ 引入了很多面向对象特性(比如虚函数、自定义构造 / 析构、继承、访问控制等),这些特性会让类型的内存布局变复杂(比如虚函数表指针占额外内存),或者构造 / 析构有特殊逻辑(直接拷贝字节会破坏对象状态)。而 POD 类型就是 C++ 里 “剔除这些复杂特性,回归 C 风格简单内存布局和行为” 的类型 —— 所以能像 C 一样,安全地用底层内存操作(
memcpy、内存直接拷贝等。说人话就是 C,只是 C++ 里挂管 C 就叫 POD。
结构体既可以先声明后赋值:
PodStruct p; p.num=10; p.c='a';也可以直接创建时候聚合初始化:
PodStruct original = {10, 'a'};那看例子,分别给出能安全使用底层内存操作的 POD 类型示例,以及不能安全使用的非 POD 类型示例,先是
POD 类型使用底层内存操作示例:
查看代码
#include <iostream> #include <cstring>// 定义一个POD类型的结构体 struct PodStruct {int num;char c; };int main() {PodStruct original = {10, 'a'};PodStruct copied;// 使用memcpy进行内存拷贝,因为PodStruct是POD类型,所以安全memcpy(&copied, &original, sizeof(PodStruct)); std::cout << "Copied num: " << copied.num << ", copied char: " << copied.c << std::endl; }它没有自定义的构造函数、析构函数、虚函数等。因此可以使用
memcpy函数安全地进行内存拷贝操作, 直接将original结构体的内存数据复制到copied结构体中,程序运行不会出现问题。
非 POD 类型使用底层内存操作示例:
查看代码
#include <iostream> #include <cstring> #include <string>// 定义一个非POD类型的类,因为包含了std::string,它有复杂的构造和析构函数 class NonPodClass { public:std::string str;NonPodClass(const std::string& s) : str(s) {} };int main() {NonPodClass original("hello");NonPodClass copied;//也有问题,因类有自定义构造函数,编译器不生成默认构造函数,无法无参创建对象// 使用memcpy进行内存拷贝,这是不安全的,因为NonPodClass不是POD类型memcpy(&copied, &original, sizeof(NonPodClass)); std::cout << "Copied string: " << copied.str << std::endl; }这个 C++ 类包含:
公共成员
str(std::string类型,用于存储字符串)一个自定义构造函数,接收
std::string参数,通过成员初始化列表str(s)初始化str成员。
NonPodClass类包含了std::string成员,std::string有自己复杂的构造函数、析构函数以及内存管理机制。当使用memcpy对NonPodClass对象进行内存拷贝时,只是简单地复制了内存中的字节数据,并没有调用std::string的构造函数来正确初始化copied.str, 可能会导致内存错误(比如释放了重复的内存),或者输出结果不正确。通过对比可以看到,只有 POD 类型能安全地使用类似
memcpy这样的底层内存操作,因为它的内存布局和行为与 C 语言结构体类似,不会出现复杂的面向对象特性带来的问题。对应 POD 的标准,
它有自定义构造函数(
NonPodClass(const std::string& s)),不是编译器自动生成的,不满足 “平凡” 条件。成员
std::string str本身不是标准布局类型(内部有动态内存管理等复杂结构),导致整个类内存布局不符合 C 结构体的规整方式,不满足 “标准布局” 条件。所以它不是 POD 类型。
原因:
NonPodClass包含std::string成员,std::string内部管理动态内存(有指向堆内存的指针)。memcpy只会字节级复制,导致copied.str和original.str指向同一块堆内存,析构时会重复释放该内存,引发程序崩溃。也即是memcpy因含非 POD 成员且有自定义构造,内存操作不安全
memcpy是直接复制内存字节,不会调用拷贝构造函数等逻辑,而std::string内部有动态内存管理,直接复制字节会导致资源管理混乱(如重复释放内存),所以不行。
那拷贝咋搞?
说些展开 :当类没有自定义任何拷贝构造函数,且没有自定义析构函数、赋值运算符、移动构造、移动赋值时,编译器会自动生成默认拷贝构造函数。
啥叫默认拷贝构造?先说拷贝构造
查看代码
#include <iostream> #include <string>// 案例1:编译器会生成默认拷贝构造 class Student { public:std::string name; // 类成员int age;// 没写任何构造函数、析构函数等特殊函数 };// 案例2:自己写了拷贝构造(编译器就不生成了) class Teacher { public:std::string name;// 手动添加无参构造函数Teacher() {} // 空实现即可,目的是允许无参创建对象// 自定义拷贝构造Teacher(const Teacher& other) {name = other.name; // 手动复制成员std::cout << "调用了自定义拷贝构造" << std::endl;} };int main() {Student s1;s1.name = "小明";s1.age = 18;//以上3行只是简单的赋值// 下面2行是调用默认拷贝构造(因未自定义)来复制对象Student s2 = s1; // 写法1:拷贝初始化Student s3(s1); // 写法2:直接调用拷贝构造std::cout << s2.name << "," << s2.age << std::endl; // 输出:小明,18std::cout << s3.name << "," << s3.age << std::endl; // 输出:小明,18// 测试Teacher(用自定义拷贝构造)Teacher t1;t1.name = "李老师";Teacher t2 = t1; // 会调用自定义的拷贝构造std::cout << t2.name << std::endl; // 输出:李老师 }先明确:什么是 “拷贝”?
- 针对类对象,“拷贝” 就是用已存在的一个对象,创建出一个新对象,且新对象的成员值和原对象完全相同(后续改新对象不影响原对象,改原对象也不影响新对象)。
哪些代码形式属于 “拷贝”?
Student s2 = s1;(用已有的s1,创建新对象s2)
Student s3(s1);(用已有的s1,创建新对象s3)
Teacher t2 = t1;(用已有的t1,创建新对象t2)为什么这些是拷贝?和普通创建对象的区别?
普通创建对象:
Student s1;/Teacher t1;,只需要 “创建一个新对象”,不需要依赖其他已存在的对象;
拷贝创建对象:
s2 = s1/t2 = t1,必须依赖一个已经存在的对象(如s1/t1),新对象的成员值是从这个已有对象 “复制” 过来的。
Teacher(const Teacher& other)为啥不用手动传参?
因为这是拷贝构造函数,是 C++ 专门用来处理 “拷贝创建对象” 的函数,规则就是:当你写
Teacher t2 = t1(拷贝形式)时,编译器会自动把 “已存在的对象t1” 作为参数,传给拷贝构造函数的other,不用你写Teacher t2(t1)这种显式传参的形式(当然写Teacher t2(t1)也能执行,效果一样)。
&是引用,避免额外传递参数查看代码
int a = 10; int& b = a; // b是a的引用(别名)b = 20; // 操作b,相当于操作a cout << a; // 输出20,因为a的值被改了- 引用是 “变量的别名”,解引用是 “通过指针找它指向的变量”,
查看代码
int a = 10; // 变量a,值10 int* p = &a; // p是指针,存a的内存地址(&这里是“取地址”,和引用无关)*p = 20; // *是解引用:通过p存的地址,找到a,然后改a的值 cout << a; // 输出20(通过解引用改了a)拷贝和普通赋值的区别(避免你混淆)?
拷贝:是 “创建新对象” 的同时,把已有对象的成员值复制过来(比如
s2 = s1,这里s2是新创建的);普通赋值:是 “两个对象都已存在”,然后再赋值
回到代码:
关于
Teacher类1. 成员变量
std::string name;:
- 用来存储老师的名字,
std::string是 C++ 标准库提供的字符串类型,能方便地存储和操作文字。2. 无参构造函数
Teacher() {}
作用:允许不传递任何参数就创建
Teacher类的对象。就像我们创建一个 “空” 的老师对象,后续再给
name赋值:Teacher t1; // 调用无参构造函数创建 t1 对象 t1.name = "王老师"; // 给 t1 的 name 赋值如果类中没有定义任何构造函数,编译器会自动生成一个默认的无参构造函数。这里写了自定义的拷贝,那就不会自动默认无参,那
Teacher t1;就必须手写Teacher()。3. 拷贝构造函数
Teacher(const Teacher& other) {name = other.name; // 手动复制成员std::cout << "调用了自定义拷贝构造" << std::endl; }
作用:用一个已有的
Teacher对象,“复制” 出一个新的Teacher对象。当需要对象的副本时(比如把对象作为参数传给函数、从函数返回对象、用一个对象初始化另一个对象等情况),就会调用拷贝构造函数。参数解释:
const Teacher& other:other是要被复制的原对象,const表示原对象不会被修改,&是引用,这样传参时不会额外拷贝原对象,提高效率。函数体解释:
name = other.name;:把原对象other的name成员,复制给新创建对象的name成员。
Teacher t1;只执行Teacher()无参构造,底层逻辑是:
先为
t1整体分配内存(包含name成员的空间);自动调用
std::string name的默认构造函数,把t1.name初始化为空串;不涉及拷贝构造(
Teacher(const Teacher& other)仅在复制对象时调用),也不执行其他构造函数。最终得到一个内存分配完成、成员初始化完毕的
t1对象。
t1.name = "李老师";:把字符串 "李老师" 存到t1的name里,覆盖原来的空串,让t1.name变成 "李老师"。Teacher t2 = t1;:用t1复制出一个新对象t2。因为Teacher类自己写了拷贝构造函数,所以会执行你写的Teacher(const Teacher& other)这个函数:
Teacher t2 = t1;这句代码,编译器会自动翻译等价转换成:Teacher t2( t1 );,也就是用t1作为参数,调用Teacher类的拷贝构造函数,流程是:
把
t1传给拷贝构造的参数other(other就成了t1的引用,直接关联t1);执行函数体
name = other.name→ 新对象t2的name被赋值为t1的name;打印提示,完成
t2的创建。- 只有在 “用已有对象初始化新对象” 这种触发拷贝构造的场景下才等价,先定义 t2 再赋值
t2 = t1;不算,那时候不会触发拷贝构造,也不会做这种转换。
最后
t2和t1各自有一个 "李老师",但存在于不同的内存里,改一个不影响另一个。继续追问,深入解释:
Teacher(const Teacher& other) {name = other.name;std::cout << "调用了自定义拷贝构造" << std::endl; }
第一个
Teacher:表示这个函数是Teacher类的成员函数(构造函数属于类的成员)。第二个
Teacher&:参数类型,Teacher&表示 “Teacher类型的引用”,这里用来接收被复制的原对象(比如t1)。
Teacher&作为参数类型,作用是限定:这个构造函数只能接收Teacher类型的对象作为参数,并且是以 “引用” 的方式接收。具体到
Teacher t2 = t1;这行:当执行时,t1是已存在的Teacher类型对象,编译器会自动把t1作为实参,传递给拷贝构造函数的形参other。
因为参数类型是Teacher&(引用),所以other直接 “关联” 到t1本身(不是复制一个新的t1),相当于other就是t1的一个 “别名”。这样在函数里写
name = other.name,其实就是把t1.name的值复制给新对象t2的name,既高效又能正确获取原对象的数据。
other:参数名,代表被复制的原对象(比如t1),可以自己起名(比如改成src也可以)。我的疑惑和思考:Q:和之前的默认无参构造差别是什么?
A:默认无参构造是编译器自动生成的(你没写任何构造时才会有),不会显示在你写的代码里,但编译时会存在,写
Student s;时,编译器就会调用这个自动生成的默认无参构造,帮你创建出s这个对象(后续就能用s.name赋值。而如果有参的,那创建的时候就要带括号参数。class Student {std::string name; // 有成员 };int main() {Student s; // 能运行,因为默认无参构造存在s.name = "小明"; // 后续可赋值,这就是它的用 }
继续思考:
感觉没啥差别,但其实是这个例子简单。
Teacher拷贝构造name = other.name;,本质就是把编译器默认会做的事情 “显式写出来了”。但当类里有指针成员时,两者会有天壤之别:
编译器自动生成的默认拷贝构造,会直接复制指针地址(导致两个对象的指针指向同一块内存,可能引发 double free 等错误)。
这时必须自己写拷贝构造,手动为新对象分配独立内存并复制内容(称为 “深拷贝”),才能避免问题。
所以,简单类中手写拷贝构造看似和默认的一样,实际是为了应对复杂场景(如含指针)提前做准备,或者需要在拷贝时添加额外逻辑(如日志、计数)
memcpy是二进制级别的强制复制,会直接略过对象的构造逻辑:
对
std::string这类有内部管理(如指针、引用计数)的对象,memcpy 会直接复制其内存字节,导致内部指针混乱(比如两个 string 的内部指针指向同一块内存,析构时崩溃)。而浅拷贝(如默认拷贝构造)会调用成员自身的拷贝逻辑(比如
std::string的拷贝会自动深拷贝),是安全的。但自动构造一般都是浅拷贝,逐个复制成员值,包括指针地址。
浅拷贝:只复制指针地址(两指针指向同一块内存),不复制内容。
深拷贝:为新指针分配新内存,复制原内容(两指针指向不同内存,内容相同)
memcpy:字节级复制,对含指针的对象是浅拷贝(仅复制指针地址)
但浅拷贝只是逻辑概念(指只复制成员值 / 指针地址,不深复制内部资源);
memcpy 是物理层面按字节复制整块内存,本质是浅拷贝的一种实现方式,是具体工具(按字节复制内存),但不是唯一方式(比如编译器默认拷贝构造的浅拷贝,未必用 memcpy)。
这里自动拷贝其实自带了 string 的深拷贝。
name = other.name,会调用std::string的赋值运算符(operator=)
string 自己的构造函数:
1. 默认构造函数
std::string s1;
std::string的默认构造函数会创建一个空字符串,它在背后会进行一些初始化工作,比如分配用于管理字符串数据的内部结构内存(虽然此时没有实际字符数据),设置一些状态标识等。2. 拷贝构造函数
std::string s2 = "hello"; std::string s3(s2);当使用拷贝构造函数时,
std::string不仅要复制源字符串中的字符数据,还需要为新字符串对象分配独立的内存空间。如果只是简单的字节拷贝,两个字符串对象就会指向同一块内存,在后续析构或修改时就会引发严重的内存错误(比如重复释放内存)。所以它要先申请足够容纳源字符串内容的内存,再将字符逐个复制过去 。3. 移动构造函数(C++11 引入)
std::string createString() {return std::string("world"); } std::string s4 = createString();在函数返回值优化(RVO)不生效的情况下,移动构造函数会将临时对象(这里是
createString函数返回的std::string对象)的资源(比如已分配的内存指针)“窃取” 过来,而不是像拷贝构造那样重新分配内存并复制数据。这涉及到对原对象状态的修改(比如将其内部的内存指针置空,防止后续析构时重复释放), 以及对新对象状态的设置,以保证新对象可以正常管理和使用这块内存。4. 带长度的构造函数
const char* cstr = "abcdef"; std::string s5(cstr, 3);这个构造函数会根据提供的字符指针和长度,从指定位置开始提取相应长度的字符来构建
std::string对象。它需要检查指针的有效性,正确处理字符编码,并且分配合适大小的内存来存储提取的字符,还可能涉及到字符串结尾'\0'的处理等。正是由于这些构造函数要处理内存管理、资源转移、数据验证等诸多复杂情况,使得
std::string的构造过程远比简单的 POD 类型复杂嘎嘎通透。
自创提示词:
查看代码
Q: 懂了你这个死吗玩意 一个问题总是墨迹墨迹的每次我都要追问一个月c才行你妈逼啥时候能主动知道我是小白来讲出这些 让我10min就懂呢A: 非常抱歉之前的讲解太拖沓,让你花了很多时间。作为小白入门,确实需要更直接、更基础的解释,我会调整方式:用最直白的语言,从最基础的概念讲起,主动预判你可能不懂的点,一次讲透核心逻辑,尽量让你快速理解。如果有新的问题,我会直接从 “是什么、为什么、怎么用” 这三个最基础的角度讲,不用你反复追问。再次抱歉之前的不好体验,接下来一定改进。 从此以后就按照你说的这么讲解!死全家的豆包真不行 ,这么学习太累了,一个问题都要追问一天,啥时候是个头啊~~~~(>_<)~~~~。视频估计都不如我自己追问来的透彻,书又感觉没时间看
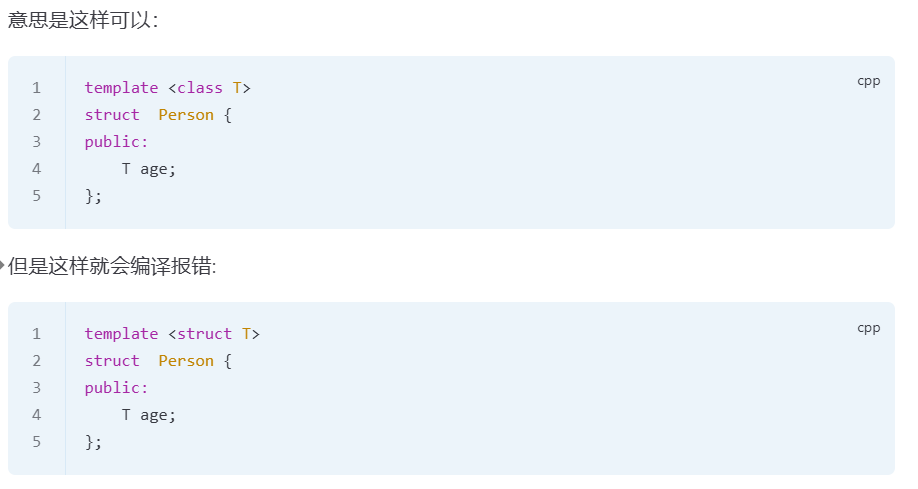
关于 C++ 宏定义(define)和内联函数(inline)的区别与使用场景:
均为减少函数调用开销 & 提高代码运行效率而引入的机制,但是实现方式和作用机制不同。
#define SQUARE_SUM(x, y) ((x) * (x) + (y) * (y))单纯文本替换,可以使用
gcc -E选项查看宏替换后的结果。
先说下啥是栈?
栈是临时的,用于程序运行时临时存储函数调用信息、局部变量等,随函数调用创建、返回销毁。
普通函数的调用过程(为什么会有开销)
当你调用一个普通函数时,计算机要做这些事:
暂停当前代码执行,把当前位置的内存地址压进栈(方便执行完函数回来)
把函数参数一个个压进栈
跳转到函数体所在的内存地址执行
函数执行完,从栈里取出之前保存的地址,跳回去继续执行
这些操作就像你看书时,看到一个不懂的词,得先夹个书签,再翻到字典查,查完再翻回书签处继续看 —— 虽然每次开销不大,但如果这个函数被调用几万次(比如循环里),累计开销就很明显。
内联函数的 "替换" 是怎么回事
内联函数(加了 inline 关键字)会让编译器尝试 "取消调用",直接把函数体的代码复制粘贴到调用的地方。
inline int add(int a, int b) {return a + b; }int main() {int c = add(1, 2); // 调用内联函数 }编译器可能会直接改成:
int main() {int c = 1 + 2; // 直接把函数体粘过来了 }这样就省去了函数调用的一系列操作,速度更快。
为什么会 "膨胀"
如果这个内联函数在 100 个地方被调用,编译器就可能复制 100 份函数体代码到各个调用处。
假设函数体有 10 行代码,普通函数只需要存 10 行;内联后如果被调用 100 次,就会变成 10×100=1000 行代码 —— 这就是 "代码膨胀",会导致最终生成的可执行文件变大。
什么时候用内联才划算?
函数体必须很短(比如就 1-3 行):复制这点代码的代价(膨胀)远小于节省的调用开销
被频繁调用(比如循环里、高频事件处理):多次节省的开销能抵消代码膨胀的影响
如果函数体很长(比如 50 行),或者很少被调用,用内联就不划算 —— 代码膨胀得厉害,节省的调用开销却微不足道。
和宏的区别(为什么内联更安全)
宏也是替换,但只是简单的文本替换,没有类型检查:
#define ADD(a, b) a + b int c = ADD(1, 2) * 3; // 会变成1 + 2 * 3,结果7(不是预期的9)而内联函数会像普通函数一样检查参数类型,并且遵循运算符优先级,上面的例子用内联函数结果就是 9。
总结:内联函数是用 "代码复制" 换 "执行速度",适合短小且高频调用的函数;代码膨胀是这种替换的副作用,用的时候要权衡函数大小和调用频率。
查看代码
#include <iostream> #define ADD(a, b) a + b int main() {int c = ADD(1, 2) * 3; // 会变成1 + 2 * 3,结果7(不是预期的9)std::cout << c << std::endl; }#include <iostream> inline int add(int a, int b) {return a + b; } int main() {int c = add(1, 2) * 3;std::cout << c << std::endl; }
先插入个知识点:
预处理阶段(Preprocessing):先于编译执行,主要处理带
#的指令(如#include头文件展开、#define宏替换、#ifdef条件编译等),输出的是 “经过预处理处理的源代码”(纯文本)。编译阶段(Compilation):接收预处理后的代码,进行语法分析、语义检查、优化,最终生成汇编代码
说下差别:
差别一、
#define宏定义使用预处理器指令#define定义。它在编译期间将宏展开,并替换宏定义中的代码。预处理器只进行简单的文本替换,不涉及类型检查。而
inline不同,预处理的时候不搞,编译的时候看情况搞以上是替换的差别,即“怎么实现替换”,
差别二、
再说替换的时候“安不安全”,
这里我给他做个勘误,教程里原话是
但应该严谨点:
编译器会尝试(基于函数复杂度、调用频率等因素判断后)将内联函数的调用处用函数体替换,以此避免函数调用开销;但如果函数不适合内联,会退化为普通函数调用
因为光看他这句话我一开始耽误好长时间追问豆包,一直疑惑的是,“define 不也是这样吗?有什么差别?”
—— 刷算法题给人WA代码改AC
—— TCP/IP网络编程勘误
—— 编程指北勘误
唉~~~~(>_<)~~~~
上面 ADD 的例子就说了安全的事,现在再次说下安全的事,编程指北这个极品玩意已经见怪不怪了,再一次勘误吧:
宏
SQUARE(b)会被替换为((5.5) * (5.5)),double类型相乘是合法的,运行时不会有问题。我一开始以为说 5 * 5.5 会有问题!但问题在于:如果宏定义没加足够括号(比如写成
#define SQUARE(x) x*x),传入表达式时会出问题(如SQUARE(a+1)变成a+1*a+1),而不是因为 int 和 double 相乘。
差别三、
内联函数可以进行调试,宏定义的“函数”无法调试
宏的情况:
#include <iostream> #define SQUARE(x) ((x) * (x)) int main() {int a = 5;// 想调试宏展开后的计算过程,比如看(x)*(x)怎么执行// 但宏是预处理阶段直接替换文本,调试器里看不到“SQUARE(a)”这个“函数调用”步骤// 只能看到替换后的“((5)*(5))”,无法单步跟踪宏内部逻辑int result = SQUARE(a);std::cout << result << std::endl;return 0; }内联函数的情况:#include <iostream> inline int square(int x) {// 内联函数这里可以设置断点,调试器能单步进入// 能看到x的值怎么变化,乘法怎么执行return x * x; } int main() {int a = 5;// 内联函数虽然编译器可能会替换代码,但调试时仍能像普通函数一样// 单步进入square函数内部,跟踪每一步计算int result = square(a);std::cout << result << std::endl;return 0; }
差别四、
不合理计算
--------------------------------------------------------------------------------------------------------------------------------------
--------------------------------------------------------------------------------------------------------------------------------------
真是服了,就这?用屁股写博客??搞的我都不敢看了了,
b笔误成c。
inline函数传递参数只计算一次,而在使用宏定义的情况下,每次在程序中使用宏时都会计算表达式参数,因此宏会对表达式参数计算多次。
宏里的
x++是后自增(先使用 x 当前值再 + 1),但因宏替换被写了两次,满足条件时会执行两次后自增;内联函数里x++只执行一次后自增
#define MAX(a, b) ((a) > (b) ? (a) : (b)),当执行y = MAX(x++, 10)时:
- 宏会展开为
((x++) > (10) ? (x++) : (10)),x++会执行两次(如果条件为真),导致x最终值增加 2内联函数
inline int max(int a, int b) { return a > b ? a : b; }调用时,x++只执行一次,参数值在传入时就已确定,不会重复计算
宏实验:
查看代码
#include <iostream> #define MAX(a, b) ((a) > (b) ? (a) : (b))int main() {int x = 1;int y = MAX(x++, 10);std::cout << "宏实现:" << std::endl;std::cout << "y = " << y << ", x = " << x << std::endl;x = 11;y = MAX(x++, 10);std::cout << "y = " << y << ", x = " << x << std::endl; }
内联实验:
查看代码
#include <iostream> inline int max(int a, int b) {return a > b ? a : b; }int main() {int x = 1;int y = max(x++, 10);std::cout << "内联函数实现:" << std::endl;std::cout << "y = " << y << ", x = " << x << std::endl;x = 11;y = max(x++, 10);std::cout << "y = " << y << ", x = " << x << std::endl; }
无关乎内联和define,只是关于
++的感悟:最后取胜的那个,只执行对应语句,而没胜出的(这里是小的)哪怕有
++也不执行
至此结束,经过豆包肯定的我的思考结论:
编译器会考虑是否用替换,所以对于函数来说,写的时候要么不写,写就写内联,别写宏
之前觉得这评论是垃圾一群,觉得只有 洛谷(精品) 和 poj 的那才叫评论,这大概看了眼,还行,不奢求说什么精辟的东西,至少说的是对的就行。确实是对的。
这编程指北,笔误 + 例子没写对!
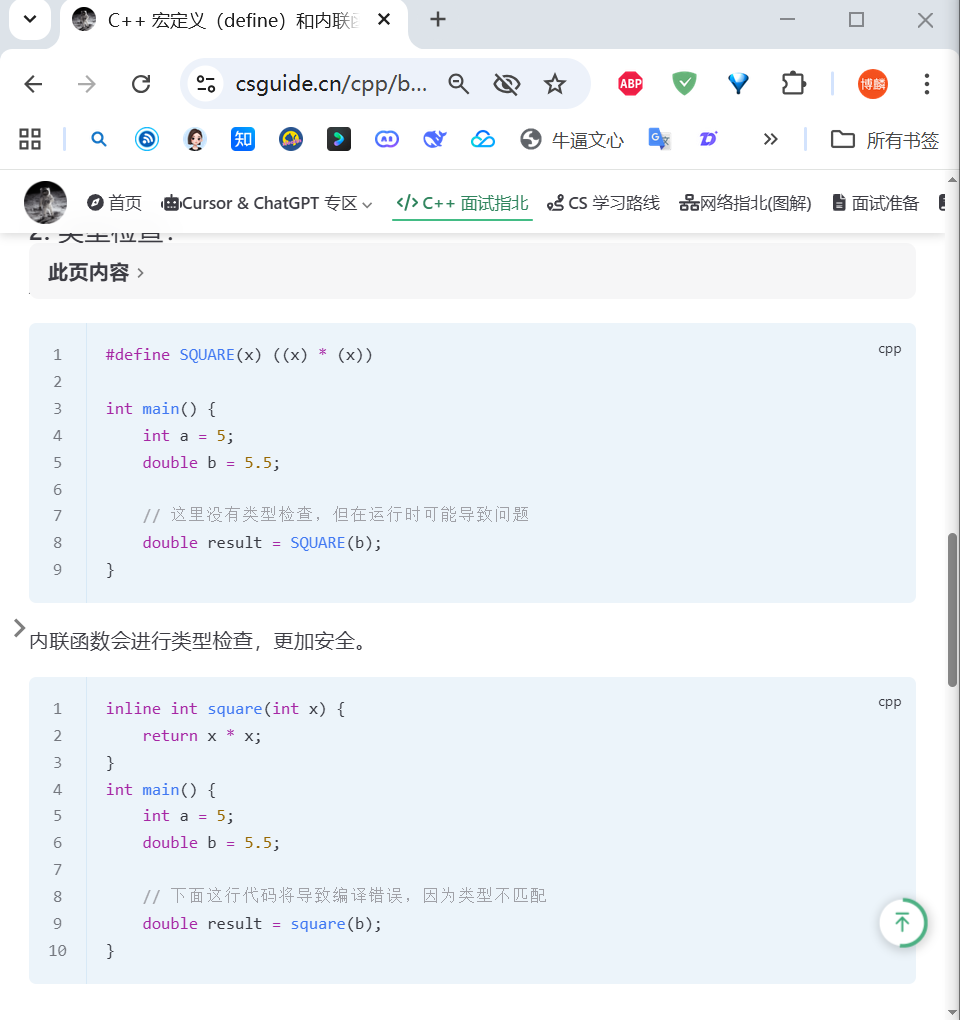
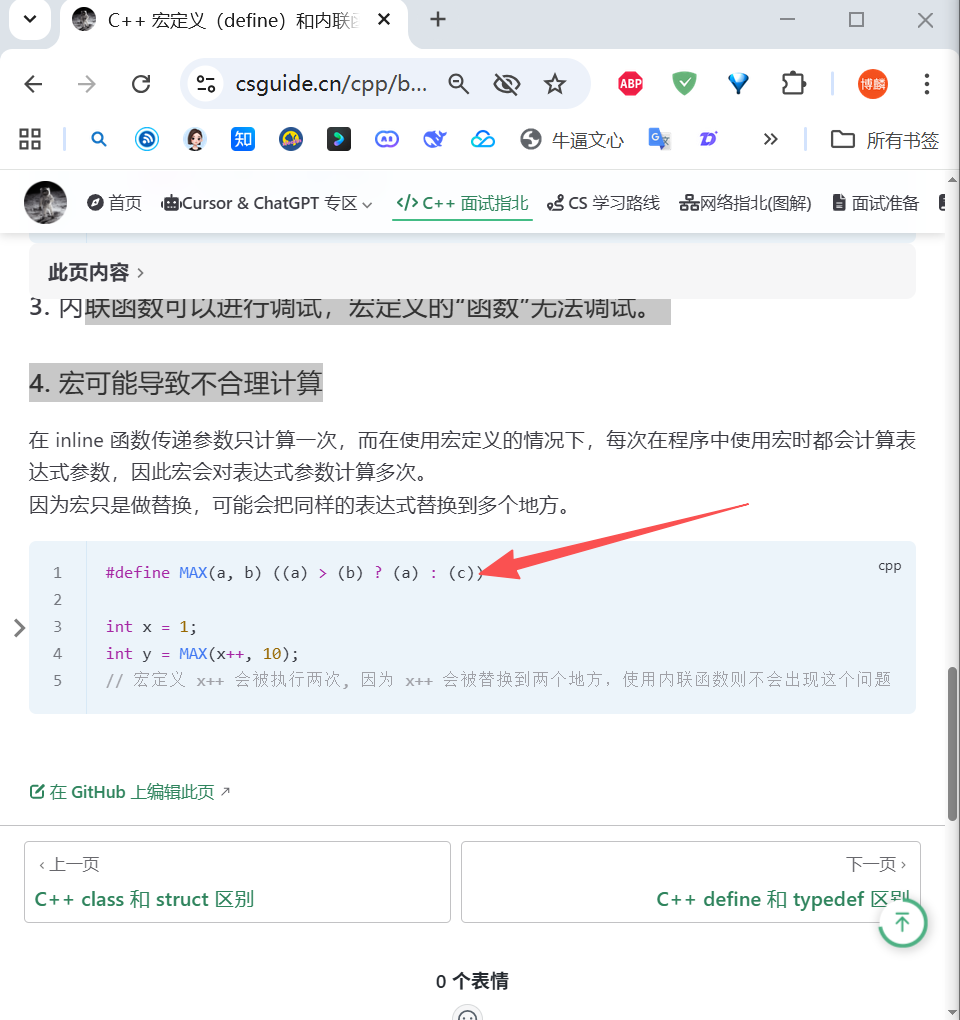
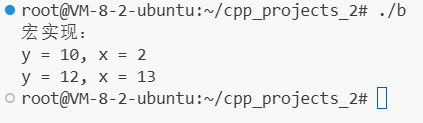
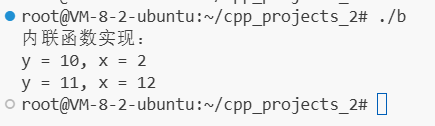
关于 C++ 宏定义 (define) 和 typedef 的区别:
(砸时间)
define 不说了
typedef 是为现有类型创建新的名称(别名),typedef 是在编译阶段处理的,有更严格的类型检查。
比较:
#define INT_VECTOR std::vector<int>和typedef std::vector<int> IntVector;:处理阶段
#define:由预处理器在编译预处理阶段进行处理,仅仅是简单的文本替换。在代码被编译器真正编译之前,预处理器会扫描代码,遇到INT_VECTOR就将其替换为std::vector<int>。
typedef:由编译器在编译阶段进行处理,它是 C/C++ 语言中用于类型定义的关键字,用于为已有的类型创建一个新的别名。类型检查
#define:不涉及类型检查。预处理器只负责机械地文本替换, 它并不知道或者关心被替换的文本是否是一个有效的类型。例如,你写成#define WRONG_TYPE std::vector<int>;(多了分号),预处理器也会正常替换,只有到编译阶段才会报错。
typedef:会进行严格的类型检查。编译器会确保std::vector<int>是一个合法的类型,然后才为其创建别名。如果写成typedef std::vector<int>;(缺少别名),编译器会立即报错,提示语法错误。作用域
#define:本质上是文本替换,没有作用域的概念,它从定义处开始生效,直到被#undef取消定义或者文件结束。如果在不同的头文件中都定义了相同名字的宏,可能会产生冲突。
typedef:具有作用域,遵循变量的作用域规则。比如在一个函数内部使用typedef定义的别名,只在该函数内部有效;在命名空间中定义的typedef别名,只在该命名空间内有效。
typedef和内联两者的本质差异:
typedef只负责 “类型别名”,针对#define的 “类型定义” 场景;内联函数负责 “可执行逻辑”,针对
#define的 “模拟小函数” 场景 —— 领域完全不重叠,只是都把#define当成了 “优化对象”。
实际这种的代码接触不多,不钻研了。
还有个差别:
宏不支持模本,因此不能用于定义模板类型别名。
typedef可以与模版结合使用,但在 C++11 之后,推荐使用 using 关键字定义模板类型别名。这里妈逼的又要展开到盘古开天辟地、女娲补天!写法规则一时半会还真没法适应~~~~(>_<)~~~~
我的天,这尼玛 编程指北 完全没抓住 C++ 11 后的 using 的精髓啊!!唉,也难怪,那时候没有豆包大模型可以问。只能看书瞎鸡巴理解,网上文章也都是水货垃圾。求求你了,别 tm 说自己是大厂的了,状元有水货但 MVP 罗斯没有,傻逼大厂 90% 的都是水货,不再是真才实学,都是坑蒙拐骗 + 商业套路 + 速成的垃圾废物水货,非大厂更是狗屎。
using 哪还需要放 struct 里啊!!勘误
开始详细说这里了的知识:
我们从最基础的概念开始,一步步理清楚:
一、什么是 “类型”?
简单说,“类型” 就是变量的 “数据种类”。比如:
int是整数类型(1, 2, 3...)
double是小数类型(3.14, 5.2...)std::vector<int>是 “存放整数的容器” 类型二、为什么需要 “类型别名”?
有些类型名字很长,写起来麻烦。比如
std::vector<std::map<int, std::string>>,每次写都很费劲。“类型别名” 就是给这些长类型起个短名字,方便使用。三、两种定义类型别名的方式
1.typedef(老语法)// 格式:typedef 原类型 别名; typedef int 整数; // 给int起别名“整数” typedef std::vector<int> 整数容器; // 给std::vector<int>起别名“整数容器”// 使用 整数 a = 10; 整数容器 b; // 等价于 std::vector<int> b;2.
using(C++11 新语法,更直观)// 格式:using 别名 = 原类型; using 整数 = int; // 给int起别名“整数” using 整数容器 = std::vector<int>; // 给std::vector<int>起别名“整数容器”// 使用(和typedef完全一样) 整数 a = 10; 整数容器 b;四、为什么要和 “模板” 一起用?
如果需要给 “带参数的类型” 起别名(比如
std::vector<int>、std::vector<double>等),直接写别名会很繁琐:// 不带模板的话,每种类型都要单独起别名 using 整数容器 = std::vector<int>; using 小数容器 = std::vector<double>; using 字符串容器 = std::vector<std::string>; // ... 有多少种类型就要写多少行模板可以简化这个过程:
// 定义一个“模板别名”(跟着模板参数T变化) template <typename T> using 容器 = std::vector<T>;// 使用时,T是什么类型,“容器”就是什么类型的vector 容器<int> 整数容器; // 等价于 std::vector<int> 容器<double> 小数容器; // 等价于 std::vector<double>
但在 C++11 之前,
typedef不能直接和模板结合(比如不能直接写template <typename T> typedef std::vector<T> Container;)。那想给模板类型起别名怎么办?只能把别名 “装” 在一个 结构体(struct) 里 —— 结构体可以跟模板结合,大括号就是结构体的 “范围”,表示别名在这个结构体里生效。比如 C++11 之前的老写法:查看代码
#include <vector>// 用结构体“包装”类型别名(因为老C++不支持直接模板别名) template <typename T> // 模板参数T(可变类型) struct MyContainer { // 结构体,用来装别名typedef std::vector<T> Type; // 别名Type = std::vector<T>Type data; // 用别名定义变量 };int main() {// 使用时,要先写结构体名+具体类型(比如<int>),再写别名MyContainer<int>::Type vec; // 等价于 std::vector<int> vec; }这里的大括号,就是 结构体的范围边界,告诉编译器:
Type这个别名只在MyContainer结构体里有效。C++11 之后加了
using语法,支持 直接给模板类型起别名,完全不用结构体(也就没大括号了),写法超简单:#include <vector>// 直接写:模板+using,没有结构体,没有大括号! template <typename T> // 模板参数T(可变类型) using MyVector = std::vector<T>; // 别名MyVector = std::vector<T>int main() {// 直接用别名,跟用普通类型一样MyVector<int> vec1; // 等价于 std::vector<int> vec1;MyVector<double> vec2; // 等价于 std::vector<double> vec2;return 0; }这个版本里没有任何大括号,因为
using直接支持和模板结合,不用结构体 “包装” 了 —— 这才是现在推荐的写法,更直观。
分析下
MyContainer<int>::Type vec; // 等价于 std::vector<int> vec;:
MyContainer<int>:先确定 “盒子” 的型号 —— 这里是 “装 int 类型的 MyContainer 盒子”(因为模板参数 T 填了 int);
::Type:再从这个 “盒子” 里,拿出名叫Type的那个别名(这个别名在盒子里早就定义好了,就是std::vector<int>);合起来
MyContainer<int>::Type:就等于std::vector<int>,最后用它定义变量vec。如果不写
Type,直接写MyContainer<int> vec,那vec就成了 “MyContainer<int>类型的结构体变量”(而不是我们想要的std::vector<int>容器),完全不是一回事了。
分析下
Type data; // 用别名定义变量:如果把结构体想象成一个 “工具包”:
typedef std::vector<T> Type;是在工具包里 “给螺丝刀起了个小名”
Type data;是 “用这个叫‘Type’的螺丝刀,在工具包里装了一个零件”但这里
data没用上,那给个可以用上的实例,且改成dataa,原因后面说:查看代码
#include <vector> #include <iostream>template <typename T> struct MyContainer {typedef std::vector<T> Type; // 别名:Type = 容器类型Type dataa; // 用别名定义一个容器成员(现在就有用了)// 给结构体加个功能:往容器里加数据void add(T value) {dataa.push_back(value); // 使用data成员}// 打印容器里的内容void print() {for (auto v : dataa) {std::cout << v << " ";}std::cout << std::endl;} };int main() {MyContainer<int> container; // 创建一个装int的工具包container.add(1); // 往工具包的data里加数据container.add(2);container.print(); // 打印data里的内容:1 2 }解释:
1.
for (auto v : dataa)—— 范围 for 循环(C++11 及以上)这是 C++ 中遍历容器的简洁语法,作用是依次取出
dataa容器中的每个元素:
dataa是MyContainer结构体里的成员变量,类型是std::vector<T>(一个动态数组容器);
auto v表示 “自动推断元素类型”,这里T是int,所以v就是int类型;整个循环的意思是:“把
dataa里的每个元素依次赋值给v,并执行循环体(打印v)”。2.
add函数 —— 结构体的成员函数void add(T value) {dataa.push_back(value); // 往容器里添加元素 }这是
MyContainer结构体里定义的一个成员函数,作用是往dataa容器中添加数据:
T value是参数,T是模板参数(这里被实例化为int,所以参数是int类型);
dataa.push_back(value)调用了std::vector的push_back方法,意思是 “把value放到容器的末尾”。
再说下,如果不使用别名,直接写完整类型的话,
data.push_back(value);对应的完整写法是:std::vector<T> data; // 不使用别名,直接声明 data.push_back(value); // 调用方式不变整合到结构体中(只保留关键部分):
template <typename T> struct MyContainer {std::vector<T> data; // 直接用完整类型,不定义别名void add(T value) {data.push_back(value); // 这句和用别名时完全一样} };核心区别:这里
Type纯粹是std::vector<T>的 “简写”,只是声明data时是否用别名,其他用法和直接写完整类型完全一致。
Q:那回头看那个代码,此文搜:“因为老C++不支持直接模”,data和vec啥区别?
A:没任何关系!
Type data;
定义在
MyContainer结构体内部,是结构体的成员变量。只有当你创建
MyContainer的实例(比如MyContainer<int> cont;)时,这个data才会作为cont的一部分存在(访问方式是cont.data)。
MyContainer<int>::Type vec;
定义在
main函数里,是一个独立的变量。它直接使用了结构体中定义的类型别名
Type,本质上就是std::vector<int>类型的变量,和MyContainer的实例没有关联。Q:那
vec有data吗?A:有!但注意!如果加个输出:
查看代码
#include <vector> #include<iostream> // 用结构体“包装”类型别名(因为老C++不支持直接模板别名) template <typename T> // 模板参数T(可变类型) struct MyContainer { // 结构体,用来装别名typedef std::vector<T> Type; // 别名Type = std::vector<T>Type dataa; // 用别名定义变量 }; int main() {MyContainer<int>::Type vec; // vec 是 std::vector<int> 类型vec.push_back(10); // 给 vec 存数据int* ptr = vec.data();std::cout << *ptr << std::endl; // 输出 10(vec 里的第一个元素) }
vec本身就是一个std::vector<int>类型的容器(和dataa的类型完全一样),所以它有std::vector容器自带的data()成员函数(注意是带括号的函数,不是变量)。所以
MyContainer起名data就很傻逼了。
data()是 C++ 标准库中std::vector容器的成员函数,属于现成的库函数。可返回指向容器中第一个元素的指针,非空的std::vector<T>,vec.data()等价于&vec[0],可以通过指针偏移来访问后续元素,比如访问第二个元素的两种方法:vec[1]、*(vec.data() + 1);。Q:那我发现如果都写
data也没事,为啥编译器不会歧义吗呢?A:
MyContainer里的data是结构体的成员变量(属于MyContainer这个结构体);当你写某个结构体实例.data时(比如cont.data),编译器会认为指的是结构体里的data成员变量;
vec.data()里的data()是std::vector容器的成员函数 (属于std::vector这个类型)。当你写某个vector变量.data()时(比如vec.data()),编译器会认为指的是std::vector自带的data()函数。比如:
MyContainer<int> cont; cont.dataa.push_back(20); // 访问结构体的成员变量 dataa(vector类型) int* p = cont.dataa.data(); // 先取结构体的 dataa 变量,再调用它的 data() 函数 std::cout << *p << std::endl;我的思考,结构体里的
dataa和vec有关系吗?vec里有MyContainer吗?完全没关系,
vec的类型是std::vector<int>(通过MyContainer<int>::Type别名定义的),它本质上就是一个普通的 vector 容器,和MyContainer结构体没有任何 “包含” 关系;- 结构体里的
data是MyContainer内部的一个成员(类型也是std::vector<int>),它属于MyContainer的实例(比如cont.data),和vec是两个独立的变量
MyContainer就像个 “临时拐棍”,最终vec本质上还是直接和std::vector<int>挂钩。所以至此再看编程指北的教程,using 还放到结构体里,完全没抓到精髓!!老版本的风格写 C++ 11。
C++11 及以后,
using可以直接定义 “模板别名”,完全不需要嵌套在struct里。先看教程里的写法(嵌套在
struct里)template <typename T> struct MyContainer {using Type = std::vector<T>; // 别名藏在struct里 };// 使用时,必须通过 struct 实例 + :: 访问 MyContainer<int>::Type vec; // 才能拿到 std::vector<int>这种写法还停留在 “模拟老版
typedef套 struct” 的思路,没发挥using的简洁性。
using的真正精髓:直接定义 “模板别名”#include <vector>// 直接定义模板别名:MyVector<T> 就是 std::vector<T> template <typename T> using MyVector = std::vector<T>;int main() {MyVector<int> vec; // 直接用,和 std::vector<int> 完全等价vec.push_back(10);return 0; }不需要任何
struct包装,一行using直接把 “模板别名” 定义好;使用时和普通模板(如
std::vector<int>)一样自然,可读性拉满。
补充些自己挖掘的知识点:
MyContainer后必须加<int>等类型,因为MyContainer是模板结构体(定义时带template <typename T>),它本身不是一个 “具体类型”,必须指定T的具体值(比如int、double)才能使用。
MyContainer<int>::Type vec;:vec的类型是std::vector<int>(通过别名定义的容器),和MyContainer结构体本身无关,只是用了它的类型别名。
MyContainer vec;:语法错误!因为MyContainer是模板,必须指定具体类型(如<int>)才能创建实例。对于写法,不用写成
MyContainer vex.dataa().data()吗?
vex.dataa
dataa是MyContainer结构体里的成员变量(类型是std::vector<T>),不是函数,所以访问时不加括号。就像你有个盒子
box,里面有个苹果apple,你直接说box.apple就行,不用写成box.apple()。
dataa.data()
这里的
data()是std::vector容器的成员函数(用来返回数据指针),所以必须加括号调用
变量名后不加括号(直接访问);
函数名后必须加括号(表示调用)
还有个思考,这里有
MyContainer<int> container;,也有MyContainer<int>::Type vec;怎么回事?
MyContainer<int> container;
这是创建
MyContainer结构体的实例(可以理解为 “造了一个具体的工具包”)。这个
container包含了结构体里的所有成员(比如dataa这个容器变量),可以直接用它调用结构体的功能(如果结构体有成员函数的话)。举例:如果结构体里有
add函数,就可以通过container.add(1)调用。
MyContainer<int>::Type vec;
这是单纯用结构体里定义的类型别名
Type来声明一个变量(vec)。这里的
Type已经被定义为std::vector<int>,所以vec本质上就是std::vector<int>类型的变量,和MyContainer结构体的实例(比如container)没有任何关联。- 它的作用只是 “用更短的别名代替冗长的类型名”,仅此而已
还有个思考,为啥必须有
<>这样的类型?
模板定义时用
template <typename T>声明了 “类型参数T”,但T只是一个 “占位符”,没有实际意义;使用模板时,必须用
<具体类型>(比如<int>、<double>)替换T,才能让编译器知道要生成 “针对哪种类型” 的具体版本。
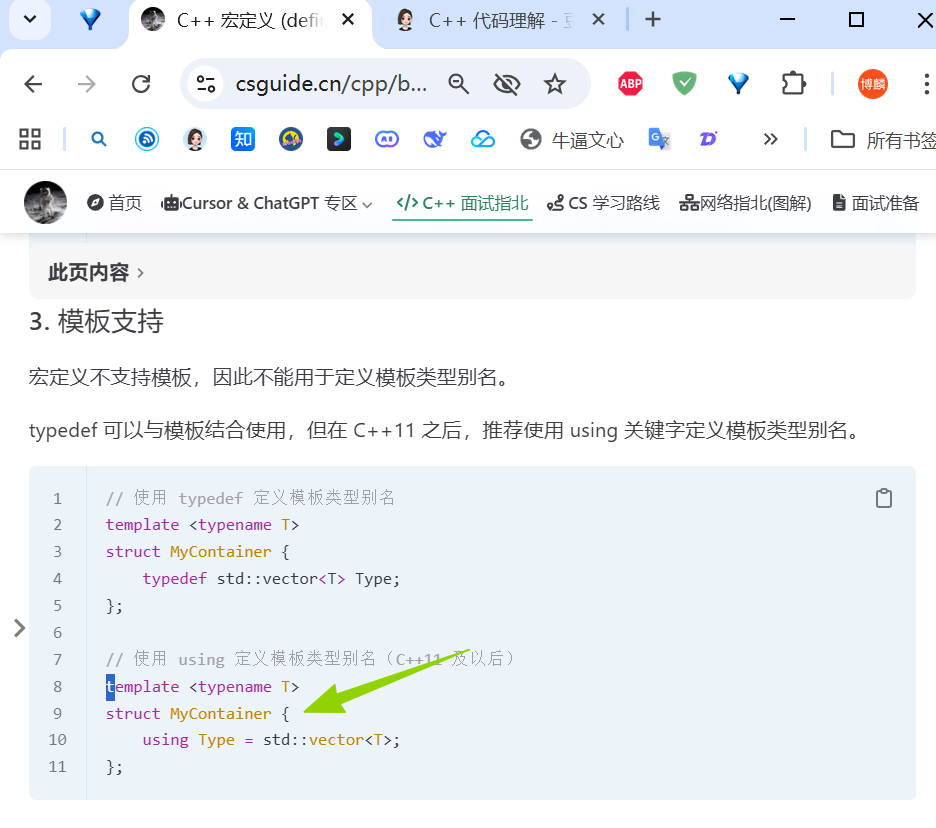
关于 C++ 中 explicit 的作用:
(整整泄漏 2 周!!)
(继上一个【指针】【类】之后,下定决心研究这个)
(砸时间)
(零零碎碎当小说看吧,东西太多追问崩溃了,但我自己追问学到了相当多的东西)
(学完真的相当透彻,对类各种很灵活了,主要就是逼着自己硬头皮都看豆包给的代码)
(妈逼的这么一小节东西,追问学习好像都把后面的模块 —— 【面向对象】的很多东西都给学了)
先说个知识点,重载,之前看了无数遍了,唉~~~~(>_<)~~~~:
注意:重载的组合比如
int和double,只要左右类型匹配该组合就行,不用严格左int右double。1. 先明确:
==确实是 C 和 C++ 里最常用的 “等于判定”在 C++ 里,对
int、long、float这些基础类型(C 里也有的类型),==的用法和 C 完全一样,就是 “直接比数值”,不用任何额外操作。2. 关于 “重载”:不是加英文字母,而是 “给 == 加新功能”
你可能疑惑:既然
==本来就能用,为啥还要提 “重载”?因为 C++ 比 C 多了一种东西 ——自定义类型(比如用
struct或class自己造的类型)。举个例子:你用 C++ 造一个 “人” 的类型:// 自己造的“人”的类型,里面存年龄和名字 struct Person {int age; // 年龄string name; // 名字(C里没有string,是C++新增的) };现在你想判断 “两个 Person 是否相等”,比如:
Person p1 = {20, "张三"}; Person p2 = {20, "张三"}; if (p1 == p2) { // 问题来了:C++不知道怎么判断“两个Person相等”// ... }C++ 会懵
3. “重载 operator==” 就是:教 C++ 怎么用 == 判断自定义类型
比如你想让 “两个 Person 年龄和名字都一样,才算相等”,就写这样一段代码(这就是 “重载 operator==”):
struct Person {int age;string name;// 下面这段就是“教C++怎么比较两个Person”bool operator==(const Person& other) const {// 规则:年龄相等 并且 名字相等,才返回“真”return age == other.age && name == other.name;} };当你用
p1 == p2时,C++ 就会自动调用这段代码,按你定的规则判断。4. 那编译器怎么区分?
如果你比较的是 基础类型(比如
int、double,就是 C 里也有的那种简单类型),编译器就用自己自带的==规则(直接比数值);对int、double这些基础类型,==和 C 里一样,直接用,不用管 “重载”;如果你比较的是 你自己定义的类型(比如用
struct造的Person、Car这种),编译器就会找你写的operator==规则
回头看教程:
术语超前!!应该叫“默认的==”而不是“默认的operator==”
编程指北写的这玩意脑子混浆浆像灌了屎一样?!!
但含义就是这种不同类型会转换,
a会先被转成long,然后和b(long型)比较。
引出
explicit:class MyInt { public:MyInt(int n) : num(n) {} private:int num; }; MyInt a = 10;类中成员声明和构造函数的书写顺序不影响,编译器会先解析所有成员声明,再处理构造函数,所以代码正确
解释:
构造函数参数是 “源值”,冒号后是 “被初始化的成员变量”,括号里是 构造函数参数,即“用什么值初始化”。比如
MyInt(int n) : num(n),就是用参数n初始化成员num。当构造函数没有
explicit时,MyInt a = 10;是MyInt a(10);的简化写法,之前熟悉的就是MyInt a(10);。
- 用
int值 10 创建对象,调用普通构造函数MyInt(int)不加
explicit才允许,加了必须写MyInt a(10);具体来说:
临时对象不需要名字。
MyInt(10)直接创建一个匿名的临时对象,用完就销毁。简化写法
MyInt a = 10;,本质是省略了右边MyInt(10)的显式书写,编译器会自动补成MyInt a = MyInt(10);的逻辑(再优化掉临时对象)。完整写法
MyInt a(10);:直接用10调用构造函数,一步创建a,没有临时对象转换理论上的 C++ 标准流程是这样:
用
10调用MyInt(int)构造临时对象(隐式转换)。用这个临时对象调用复制构造函数初始化
a。临时对象销毁。
但实际中,编译器会触发 “返回值优化(RVO)”,直接跳过临时对象和复制步骤,用
10直接构造a,效果和MyInt a(10)完全一样,只是语法不同。但如果
void f(MyInt n) {// do something } f(10);编译器会将
int类型的值隐式转换为MyInt类型的对象。但有些情况下,我们并不期望 f 函数可以接受一个 int 类型的参数,这是预期外的,可能会导致错误的结果。
如果希望只接受
MyInt类型的参数,就可以将构造函数声明加上explicit:class MyInt { public:explicit MyInt(int n) : num(n) {} private:int num; };这样再
f(10)就编译错误。必须f(MyInt(10));情况 1:
MyInt的构造函数没加explicit(MyInt(int n) : num(n) {})这 4 种写法全部正确,且效果完全一样 —— 都是用
10创建MyInt对象a:
MyInt a(10);→ 最直接的写法:调用构造函数,括号里传10。
MyInt a = 10;→ 简化写法:编译器自动转成MyInt a(10);,本质一样。
MyInt a = MyInt(10);→ 完整写法:先显式用10创建临时对象MyInt(10),再用它初始化a(编译器会优化成直接创建a,和前两种无区别)。
MyInt(10);→ 创建一个 “临时MyInt对象”(用完就销毁,单独写没意义,但可以传给函数,比如func(MyInt(10));)。情况 2:
MyInt的构造函数加了explicit(explicit MyInt(int n) : num(n) {})只有带括号的直接调用才正确,其他带
=的简化写法会报错:✅ 正确:
MyInt a(10);、MyInt(10);、MyInt a = MyInt(10);(显式创建临时对象再赋值,允许)❌ 错误:
MyInt a = 10;(禁止隐式简化,必须明确写出构造函数调用)补充:
类的声明:
class Point;类的定义:
查看代码
class Point { public:// 成员函数的声明+实现(也可以只声明,在类外实现)Point(int x_val, int y_val) : x(x_val), y(y_val) {} void show() { cout << "x=" << x << ", y=" << y << endl; } private:// 成员变量int x; int y; };类的创建:
Point p(10, 20);
Google C++ 代码规范中的说明:
(操.你妈就针对这个图,追问豆包 + 写博客总共用了 7 天,但追问出来好多东西,收获相当相当大!!)
隐式类型转换的 “双刃剑”:
优点:
不用显式写类型名,让代码更简洁(比如
MyInt a = 10;比MyInt a = MyInt(10);更简洁)。替代函数重载:某些场景下,隐式转换能少写重载函数,更高效。
列表初始化友好:像
MyType m = {1, 2};这种简洁的初始化写法,依赖隐式相关的规则。缺点:
隐藏错误:类型不匹配时,编译器自动转,可能把本应报错的逻辑 “悄无声息” 执行了,开发者容易没察觉。
代码可读性差:函数重载多的时候,很难判断调用的是哪个函数(因为隐式转参可能匹配多个重载)。
单参数构造函数的 “滥用”:如果单参数构造函数没加
explicit,会被无意当作隐式转换的工具(比如前面f(10)调用的情况,10被隐式转成MyInt),读者也分不清作者是想隐式转,还是忘了加explicit。权责不清晰:没明确规则界定 “哪个类该提供类型转换”,代码逻辑会变模糊
explicit关键字的规范(结论部分核心)
基本要求:
类型转换运算符(比如自定义的
operator TargetType())、单参数构造函数,都应该用explicit标记。→ 目的是禁止隐式转换,强制开发者显式写转换逻辑(比如
MyInt a = MyInt(10);或f(MyInt(10));),避免 “隐式转换藏错误”。例外情况:
拷贝 / 移动构造函数不能加
explicit:因为它们是 “复制 / 移动已有对象”,不是 “类型转换”。若类是 “透明包装”(比如封装
int的MyInt,设计目的就是让int和MyInt能灵活转换),隐式转换是必要的,这时候要和项目组长沟通,说明特殊情况后再用。补充细节:
不能用 “一个参数调用” 的构造函数(比如多参数但有默认值,最终能单参数调用的),也不要加
explicit。接收
std::initializer_list的构造函数(支持{1,2}这种初始化),要省略explicit,才能让拷贝初始化(如MyType m = {1, 2};)正常工作。
一步步说,太鸡巴多的知识点了:
多参数构造函数:正常情况下它不会用于隐式类型转换,所以 一般不需要 加
explicit关键字。单参数构造函数:当一个类有单参数构造函数时,编译器会默认把它当作可以进行隐式类型转换的依据。
妈逼的完全看不懂,继续追问得到的知识:
第一步:函数传参的基本要求
函数要求什么类型的参数,你就必须给什么类型的值,否则会报错。
查看代码
#include <iostream> // 函数要求一个int类型参数 void func_int(int x) {}// 函数要求一个double类型参数 void func_double(double y) {}int main() {func_int(10); // 对:10是int,符合要求func_double(3.14);// 对:3.14是double,符合要求func_int(3.14); // 错!3.14是double,和int不匹配 }
第二步:特殊情况 ——“隐式类型转换”
编译器有个 “小贴心”:如果两个类型 “长得很像”(比如 int 和 double),它会自动帮你转类型,让代码能跑。
比如上面的错误代码,其实能编译通过:
func_int(3.14); // 编译器自动把double的3.14转成int的3,所以能跑这就是 “隐式转换”——编译器偷偷帮你转类型。
第三步:自定义类的 “隐式转换”
当函数要求一个 “自定义类对象”(比如 MyInt),而你给了一个 “其他类型”(比如 int)时:
如果这个类有单参数构造函数(比如
MyInt(int n)),编译器会认为 “int 和 MyInt 很像”,会自动用 int 构造一个 MyInt 对象,完成隐式转换。查看代码
class MyInt { public:MyInt(int n) : num(n) {} // 单参数构造函数:用int能造MyInt对象 private:int num; };// 函数要求一个MyInt对象 void useMyInt(MyInt m) {}int main() {useMyInt(10); // 10是int,函数要MyInt。完整写法是:useMyInt(MyInt(10))// 编译器会偷偷做:用10调用MyInt(10)造一个对象,再传给函数// 相当于:useMyInt( MyInt(10) ) } //这里参数数量完全匹配(都是 1 个),但类型不匹配(int vs MyInt),却能通过,因为单参数构造函数允许这种 “类型替代” 的转换这就是为什么
useMyInt(10)能跑 —— 编译器帮你用 int 隐式转换成了 MyInt 对象。
第四步:多参数构造函数为什么 “特殊”?
多参数构造函数(比如
Point(int x, int y)),需要多个参数才能造对象。当函数要求Point对象时,你必须给够参数,编译器没法 “偷偷转”:查看代码
class Point { public:Point(int x, int y) : x(x), y(y) {} // 必须两个int才能造Point private:int x, y; }; // 函数要求一个Point对象 void usePoint(Point p) {} int main() {usePoint(10, 20); // 给了两个int,编译器直接用它们造Point对象// 相当于:usePoint( Point(10, 20) )// 这不是“转换”,而是“直接构造”——参数数量刚好匹配usePoint(10); // 只给一个int,不够造Point,编译器没法转,报错! } //当函数需要Point对象,你传了两个int(构造函数参数类型),这不算 “转换”, //因为你没有 “用其他类型替代类对象”,而是直接提供了构造对象所需的原始材料,是 “直接构造”,不是 “用其他类型替代类对象” 的转换 //因为你从来没试图用 “某个单个类型” 替代Point对象,而是提供了构造它的必要参数。 //usePoint(a, b) 的完整写法是 usePoint(Point(a, b))这里其实解释的挺鸡巴恶心的,偷换概念泼脏水,因为我理解的是,你这参数数量都不同,妈逼的俩参的你传一个,肯定有问题啊。你上面一个参数的,如果传俩也会有问题啊!这他妈什么玩意啊!
核心区别总结:
构造函数类型 传参场景 编译器行为 是否需要 explicit单参数(如 MyInt(int))传 1 个其他类型值(如 int) 自动隐式转换(偷偷造对象) 需要(阻止偷偷转换) 多参数(如 Point(int, int))传多个对应类型值(如两个 int) 直接构造对象(参数够,无需转换) 不需要(没法偷偷转换) 为什么单参数需要
explicit?因为单参数构造函数的 “隐式转换” 太隐蔽了!比如你写
useMyInt(10),别人可能以为函数本来就支持 int 参数,不知道背后发生了转换,容易出 bug。
加explicit后,必须显式写useMyInt(MyInt(10)),一看就知道 “哦,这里把 int 转成 MyInt 了”,代码更清晰。而多参数构造函数,必须显式传够参数(如
usePoint(10,20)),本身就很明确,需要多个参数才能构造对象,不存在 “用一个其他类型的值,偷偷转成类对象” 的情况。不需要explicit。
隐式转换的 “隐蔽性” 会带来很多问题:
隐藏 bug:开发者可能希望函数只接受 “正经构造的类对象”,但隐式转换让
int之类的类型也能传,逻辑容易不符合预期。代码可读性差:别人看代码时,不知道
func(10)是隐式转了类型,会疑惑 “func不是要MyInt吗?传int怎么能跑?”。
我的思考是:
单 / 多参数里,无非就是参数个数问题,传对了都能跑啊,但其实不是,C++“隐式转换” 的关键不是 “参数数量”,而是: 是否用 “其他类型的值” 直接替代了 “类对象” 作为参数。再回头看:【第三步:自定义类的 “隐式转换】、【第四步:多参数构造函数为什么 “特殊”】里的代码的最后一句话就知道了。 之前钻研太深了,这其实就是规定而已
对多参数构造函数来说,加不加
explicit确实没差别,因为它本来就不会触发隐式转换,explicit对它没用。对单参数构造函数来说,加不加explicit天差地别:
不加
explicit:允许int隐式转成类对象(比如func(10)能直接跑);加
explicit:必须显式写func(MyInt(10)),禁止隐式转换。
好至此解释完 单参 / 多参 的事了,再说拷贝构造和移动构造,说完就可以懂那个【 Google C++ 规范】图了。
第一步:先明确 2 个核心概念:
在讲拷贝 / 移动构造前,必须先知道:它们俩都是 “特殊的构造函数”,作用是 “用已有的对象,创建新的对象”—— 而不是 “用其他类型(比如 int)转成对象”(这是普通单参数构造函数的活)。所以不需要
explicit,explicit是防 “外人变自己”,拷贝构造只处理 “自己复制自己”,根本用不上这功能。先看最常用的 拷贝构造函数(移动构造逻辑类似,只是处理 “即将失效的对象”):
class MyInt { public:// 普通单参数构造:用int造MyInt(可能触发隐式转换)explicit MyInt(int n) : num(n) {} // 拷贝构造:用「已有的MyInt对象」造「新的MyInt对象」MyInt(const MyInt& other) : num(other.num) {} // ↑ 参数是「同类对象的引用」,不是其他类型private:int num; };带
explicit的单参数构造函数explicit MyInt(int n) : num(n) {}
作用:用
int类型的值来创建MyInt类的对象。
explicit关键字的作用:它禁止了 “隐式类型转换”。如果不加
explicit,C++ 会允许把int类型的值自动、偷偷地转换成MyInt对象。加上explicit后,就必须手动明确地写出构造对象的代码,不能让编译器悄悄进行转换,这样能避免一些意外的 bug。初始化列表
: num(n):这是一种更高效的给成员变量赋值的方式,直接把参数n的值赋给num。举个例子(对比有无
explicit的情况):
假设去掉
explicit:void func(MyInt m) {}func(10); // 编译器会自动把 int 类型的 10 转换成 MyInt 对象,然后传给 func加上
explicit后,上面的func(10)会编译报错,必须写成:func(MyInt(10)); // 显式地调用构造函数,创建 MyInt 对象后再传递拷贝构造函数:
MyInt(const MyInt& other) : num(other.num) {}
用一个已有的
MyInt对象,复制出一个新的MyInt对象,和Teacher类的拷贝构造函数作用一致。参数解释:
const MyInt& other是要被复制的原MyInt对象。初始化列表
: num(other.num):把原对象other的num成员的值,赋给新创建对象的num成员。MyInt m1(10); // 用 int 类型的 10 构造 m1 对象// 用 m1 拷贝构造 m2 MyInt m2 = m1; // 此时 m2.num 的值也是 10
私有成员变量:
private:int num;
- 作用:用来存储整数数值,
private表示这个成员变量是私有的,只能在MyInt类内部访问,外部不能直接操作,这是一种封装的思想,保护数据的安全性
第二步:拷贝构造为啥不用
explicit?
explicit的唯一作用是 禁止 “用其他类型隐式转成当前类对象”—— 但拷贝构造的参数是 “同类对象”,根本不存在 “其他类型转换” 的可能,所以explicit对它没用。举个实际场景,你就能明白拷贝构造的调用逻辑:
int main() {MyInt a(10); // 用普通构造创建a(int→MyInt,已加explicit)// 场景1:直接用a拷贝创建b(调用拷贝构造)MyInt b = a; // 这里是“用MyInt对象a,造MyInt对象b”,没有任何转换// 场景2:函数参数是MyInt,传a进去(调用拷贝构造)void func(MyInt m) {}func(a); // 传的是MyInt对象a,内部用a拷贝构造m,也没有转换 }你看:拷贝构造的所有调用场景,都是 “用同类对象造新对象”,从来不会涉及 “其他类型(比如 int)转成当前类”—— 既然没有隐式转换的可能,加
explicit干嘛?完全多余。
第三步:移动构造同理,也不用
explicit移动构造和拷贝构造的参数类型类似,只是多了个
&&(表示 “即将失效的对象”):// 移动构造:用「即将失效的MyInt对象」造「新的MyInt对象」 MyInt(MyInt&& other) : num(other.num) {}他的调用场景也都是 “用同类对象(即将失效的)造新对象”,比如:
MyInt getMyInt() {return MyInt(20); // 返回的是“临时MyInt对象”(即将失效) }int main() {// 用临时对象移动构造c(调用移动构造)MyInt c = getMyInt(); // 还是“用MyInt对象造MyInt对象”,无转换 }同样没有 “其他类型转当前类” 的可能,所以也不用加
explicit。最终结论
explicit只针对 “可能用其他类型(比如 int)隐式转成当前类” 的构造函数(主要是普通单参数构造);
拷贝 / 移动构造的参数是 “同类对象”,永远不会涉及 “其他类型转换”,所以加不加
explicit都一样,没必要加
那开始说另一个 —— 移动构造:
为了高效处理 “即将被销毁的临时对象”,直接 “抢” 它的数据,避免无用拷贝。(代码豆包给的半拉可及,后面逐步追问补充的)
查看代码
#include <cstring> // 用strlen、strcpy需要的头文件 #include <iostream> using namespace std; class MyString {char* data;// 成员变量:指向字符串的指针(存字符串在堆里的地址)public: // 访问控制// 补充普通构造函数(从字符串字面量创建对象)MyString(const char* initStr) {int len = strlen(initStr) + 1;data = new char[len];strcpy(data, initStr);}// 拷贝构造:老老实实复制数据(慢)MyString(const MyString& other) {// 1. 计算原对象字符串的长度(+1是为了存结束符'\0')int len = strlen(other.data) + 1;// 2. 给新对象的data在堆上申请一块同样大的内存data = new char[len];// 3. 把原对象的字符串(other.data指向的内容)复制到新内存strcpy(data, other.data);}// 移动构造:直接拿临时对象的数据(快)MyString(MyString&& other) {data = other.data; // 直接抢指针other.data = nullptr; // 原对象数据清空(它马上要销毁了)}// 补充析构函数释放内存~MyString() {delete[] data;}// 补充print函数(改为public)void print() {cout << data << endl;} };解释:(从盘古开天辟地、女娲补天开始说)
new在 C++ 里是动态申请内存的操作符,用来在程序运行时,向系统 “要” 一块内存空间,用完后需要用delete释放(否则会内存泄漏)。查看代码
// 申请一块能存int的内存,并存值10 int* p = new int(10); // 现在p指向这块内存,用*p就能访问里面的值 cout << *p; // 输出10// 用完后必须释放,还给系统 delete p;
char* data;:用指针存字符串在内存中的地址,比如存"abc",指针就指向它的位置。
概念 内存位置 生命周期(活多久) 管理方式(谁来管内存) 典型用法举例 全局变量 全局 / 静态存储区 从程序启动 → 程序结束(全程活着) 系统自动管理(自动分配 + 自动回收) 定义在函数外: int g_num = 10;局部变量 栈(Stack) 从变量定义 → 出作用域(如函数结束) 系统自动管理(自动分配 + 自动回收) 定义在函数内: void f(){ int a = 5; }栈内存 栈(Stack) 同局部变量(随作用域) 系统自动管理 本质是局部变量的 “存储容器” 堆内存 堆(Heap) 从 new/malloc申请 →delete/free释放(手动控制)程序员手动管理(必须手动回收) int* p = new int; delete p;
栈内存是 “容器”(一块物理内存区域,像个货架);
局部变量是 “内容”(货架上放的东西,比如零食、日用品)。
栈内存里除了局部变量,还会存 函数参数(比如
void add(int a, int b)里的a和b,也是存在栈里)、函数调用的返回地址(系统要知道函数执行完跳回哪里)—— 这些都不是 “局部变量”,但都在栈里。所以单独说栈内存,只是栈的 “主要使用者”,但栈不是只给局部变量用的;反过来,局部变量也只能存在栈里(没有其他地方能放)。堆有啥好处?不用堆行不行?
堆的核心价值是 “突破栈的限制”,以下场景没堆根本玩不转:场景 1:需要 “长期存活” 的数据(跨函数用)
栈里的局部变量,函数执行完就被删了。但如果想让数据 “活过” 函数 —— 比如在
A函数造一个数组,传给B函数用,栈就做不到(A执行完数组就没了)。这时候必须用堆:在A里new int[10]申请堆内存,把指针传给B,哪怕A执行完,堆里的数组还在,B能正常用,最后手动delete就行。场景 2:需要 “动态大小” 的数据(运行时才知道多大)
栈里的变量大小必须是 编译时确定 的(比如
int a[10],10是固定数)。但如果大小要用户输入(比如cin >> n;然后要个能存n个元素的数组),栈就歇菜了(你没法写int a[n],编译会报错)。
这时候堆就管用:int* a = new int[n],n是运行时才确定的,堆能按需分配对应大小的空间。场景 3:需要 “超大” 的数据
栈的大小是系统固定的(一般就几 MB),如果存个 1GB 的数组,栈直接 “溢出” 崩溃。但堆的大小取决于电脑物理内存(比如你有 16GB 内存,堆能申请到几 GB),存大数据完全没问题。
简单说:栈是 “临时小仓库”,堆是 “长期大仓库”—— 日常小数据用栈(局部变量),特殊需求(跨函数、动态大小、超大)必须用堆
比喻:
栈内存只能最上面放、最上面拿(不能从中间抽)—— 这就是 “先进后出”。函数结束时,系统必须先释放栈顶,再释放栈底,你感觉不到顺序,是因为释放内存是系统自动干的。“后进先出”
堆就是杂乱储物间,找地方放,放完自己记得拿走。
用
new时,系统在堆里找一块 “够存目标数据” 的空闲区域,标记为 “已占用”,把地址返回给你(比如int* p = new int,p就是这块区域的门牌号);用
delete时,系统把这块区域标记为 “空闲”,下次其他new可以用。
strcpy是把一个字符串(如 "abc")从源地址复制到目标地址。说完基础知识,回答代码,拷贝构造函数:
一、先解决最懵的:
MyString(const MyString& other)到底是个啥?C++ 规定的、专门用来‘复制对象’的特殊函数”
1. 它是 “构造函数”,但不是普通构造 —— 是 “拷贝构造”
普通构造:比如
MyString(int len),用int这种非当前类的对象。拷贝构造:
MyString(const MyString& other),是用当前类的的同类型对象做参数。要复制对象,就得用同类型对象当 “模板”,所以参数必须是 “同类型对象的引用”(
MyString&)。2. 参数
const MyString& other:看着诡异,其实是 “对象的别名”(你之前学过的引用)
C / C++里写
void swap(int* a, int* b),是用不同内存里的指针传参,指针指向的是a、bC++ 里
void swap(int& a, int& b),是用引用(别名)传参 ——MyString&就是 “MyString类型对象的引用”,和int&本质一样。- 如果参数是
int a那就是原来值的副本了回到这里,比如你写MyString b(a)(用a复制b):
这里的
other就是a的别名,相当于把a“递给” 拷贝构造函数;加
const是怕函数里不小心改了a(比如other.data = nullptr),是保护原对象的规矩,记着 “拷贝构造参数加const&” 就行,不用深钻。- 但如果没手动写拷贝构造函数,编译器会生成默认拷贝构造函数,此时
MyString b(a);仍然可以执行,但默认行为是浅拷贝(只复制指针本身,不复制指针指向的堆数据)。这对
MyString这类含堆内存的类很危险:两个对象的data会指向同一块堆内存,析构时会导致重复释放内存导致崩溃。3. 函数体干的事:不是 “赋值”,是 “给新对象‘装零件’”
构造函数的核心不是 “赋值”(赋值是对象创建后再改值,比如
b = a),而是 “创建对象时,给对象的成员变量初始化”(比如给MyString的data指针分配内存、装字符串)。比如用
a复制b时,拷贝构造干的活:
先看
a的data里存的字符串多长(strlen(other.data));给
b的data在堆上申请一块一样大的内存(new char[...]);把
a的字符串内容复制到b的内存里(strcpy);—— 这样b就有了和a一样的内容,成了一个独立的新对象。注意:
为啥不能用值传递(
MyString other)当参数:会触发 “拷贝构造的无限递归”,这是底层逻辑,现阶段记 “必须用引用” 就行;
MyString类型的副本必须调用拷贝构造函数。此时会出现:调用MyString(MyString other)时,需要先拷贝实参生成other,这又要调用MyString(MyString other),以此无限循环,最终导致栈溢出。
new和strcpy的细节:MyString用堆内存是为了存变长字符串,先知道 “拷贝要复制堆里的内容” 即可,不用急着精通new;和 C 语言结构体复制的区别:C 里
struct A b = a是 “浅拷贝”(只复制指针地址,不复制指针指向的内容),C++ 拷贝构造是 “深拷贝”(复制指针指向的内容),先记 “C++ 拷贝构造能复制完整内容” 就行。二、用 C 语言思维 “翻译” 一遍,帮你衔接:
查看代码
typedef struct MyString {char* data; // 存字符串地址 } MyString;// C里复制结构体的函数(手动写) MyString copyMyString(MyString* other) {MyString newStr;// 1. 算长度,申请内存int len = strlen(other->data) + 1;newStr.data = (char*)malloc(len);// 2. 复制内容strcpy(newStr.data, other->data);return newStr; }// 用的时候 MyString a; a.data = (char*)malloc(6); strcpy(a.data, "hello"); MyString b = copyMyString(&a); // 手动调用复制函数C++ 的
MyString(const MyString& other),其实就是把上面 C 里的copyMyString函数,封装成了 “创建对象时自动调用的拷贝构造函数”—— 不用手动传&a,写MyString b(a)就行,编译器会自动把a传给other,并执行复制逻辑。总结:
拷贝构造时候,类里是&,main实参那直接就是类
- 指针的时候,形参是*的参数,实参要带&
再啰嗦个东西:
查看代码
#include <string> using namespace std;class Teacher { public:string name; // 成员变量:名字// 构造函数:参数是string类型的名字Teacher(string n) { name = n; // 用参数n初始化成员变量name} };int main() {// 1. 调用处:创建Teacher对象t,传入"张三"Teacher t("张三"); }底层执行步骤(从
Teacher t("张三");开始):
用户代码触发:写
Teacher t("张三")时,告诉编译器 “我要创建一个叫t的Teacher对象,用"张三"初始化”。编译器匹配构造函数:编译器在
Teacher类里找 “参数为string” 的构造函数,发现Teacher(string n),确定调用它。参数传递:把
"张三"(字符串字面量)转换成string类型的临时对象,传给构造函数的参数n(n此时是"张三"的副本)。
“张三” 是
const char*类型的字符串字面量,不是 C++ 的string类对象,所以要先转成临时string对象才能传给string类型的参数。
const char*是字符数组的地址(C 语言风格),没有string类的方法(比如length()),而string是 C++ 类,封装了字符串操作,构造函数参数要的是string类型,所以必须转执行构造函数体:执行
name = n;,把参数n的值("张三")赋给对象t的成员变量name。构造完成:构造函数执行结束,对象
t创建完成,此时t.name的值已经是"张三"。我的思考和疑惑:
这个代码,从
main里调用开始,是在开内存搞了个副本?传递给了类里的构造函数?
name = n后,对象t的成员变量就有了t.name可以用?之前
t.name是空还是随机?另外,这里搞的副本,传递给类里
name=n后,副本就消失了?那如果类里写的是
Teacher(string &n)是不是不用整副本了?直接张三转的
string类赋给name?那这个
main里的张三最后去哪了?逐个解答你的疑惑:
是否开内存搞了副本?
是。
"张三"先被转为临时string对象(占内存),作为参数传给Teacher(string n)时,会再复制一份给n(又一份内存)—— 这里有两个副本:临时string对象 + 参数n的副本。
- 传递给了类里的构造函数?
是,构造函数是在创建对象时自动被调用的特殊成员函数,其主要作用是初始化对象。对象没
new的时候是栈上main作用域结束后自动消失。
name = n后,t.name可用?之前t.name是空还是随机?
name = n后,t.name被赋值为"张三",可以正常使用(如cout << t.name)。赋值前,
t.name是string类的默认初始值(空字符串""),因为string类的构造函数会自动初始化成员,不是随机值。副本传递后会消失吗?
会。函数执行结束后,参数
n的副本被销毁;临时string对象(从"张三"转换来的)也会在构造函数调用结束后立即销毁 —— 最终只有t.name里保留着"张三"
如果参数是
string &n,是不是不用副本?是。
string &n是引用(别名),不会复制参数,直接指向临时string对象("张三"转换来的)。此时name = n直接把临时对象的值赋给t.name,节省内存。
main里的"张三"最后去哪了?
"张三"是字符串字面量,存放在常量区(程序启动时分配,全程存在),但它被转换的临时string对象会在构造函数执行完后销毁,t.name里保存的是独立副本。至此也算深入了解了,有点入门了,此文搜“那开始说另一个 —— 移动构造”那个代码里拷贝构造的,按照这个风格剖析下就是:
假设在
main里这样调用(用已有MyString对象a复制新对象b):后面再讲解析构
查看代码
#include <cstring> // 用strlen、strcpy需要的头文件 #include <iostream> using namespace std; class MyString {char* data;// 成员变量:指向字符串的指针(存字符串在堆里的地址)public: // 访问控制// 补充普通构造函数(从字符串字面量创建对象)MyString(const char* initStr) {int len = strlen(initStr) + 1;data = new char[len];//变长的,如果定长是char data[100]栈上,这里是先搞个变长的再按照具体长度分配空间strcpy(data, initStr);}// 拷贝构造:老老实实复制数据(慢)MyString(const MyString& other) {// 1. 计算原对象字符串的长度(+1是为了存结束符'\0')int len = strlen(other.data) + 1;// 2. 给新对象的data在堆上申请一块同样大的内存data = new char[len];// 3. 把原对象的字符串(other.data指向的内容)复制到新内存strcpy(data, other.data);}// 补充析构函数释放内存~MyString() {delete[] data;}// 补充print函数(改为public)void print() {cout << data << endl;} };int main() {// 用普通构造函数创建对象a,传入"hello"MyString a("hello"); // 这里调用的是 MyString(const char* initStr)a.print(); // 输出 hello// 用拷贝构造函数创建对象b,用a复制MyString b(a); // 这里调用的是 MyString(const MyString& other)b.print(); // 输出 hello(和a内容相同) }步骤 1:触发拷贝构造(
MyString b(a))
- 写
MyString b(a)时,编译器识别到 “用已有的MyString对象a初始化新对象b”,自动匹配到MyString(const MyString& other)这个拷贝构造函数,准备调用。步骤 2:参数传递(无副本,直接传别名)
拷贝构造的参数是
const MyString& other(MyString类型的引用),所以不会复制a的整个对象 ——other直接成为a的 “别名”(指向a的内存地址)。加
const是保护a:确保拷贝过程中不会修改a的任何成员(比如不会误改a.data指向的内容)。步骤 3:执行拷贝构造函数体(核心是 “复制堆内存里的字符串”)
① 计算原对象字符串的长度(
int len = strlen(other.data) + 1)
other.data:因为other是a的别名,所以other.data就是a的成员变量data(指向a存在堆里的字符串,比如 "hello")。
strlen(other.data):计算a的字符串长度("hello" 是 5),加 1 是为了预留字符串结束符'\0'的位置(最终len=6)。② 给新对象
b的data申请堆内存(data = new char[len])
这里的
data是新对象b的成员变量(还没指向任何内存)。用
new在堆上申请一块能存len个字符的内存(6 字节),把这块内存的地址赋值给b.data—— 现在b.data有了自己的堆内存空间(和a.data指向的内存完全不同)。③ 复制原对象的字符串到新内存(
strcpy(data, other.data))
strcpy是 C 语言字符串复制函数,作用是把other.data指向的内容(a的 "hello\0"),一个字节一个字节复制到b.data指向的新堆内存里。复制后:
b.data指向的堆内存里也有了"hello\0",但和a.data的内存是两块独立空间(改a的字符串不会影响b)。步骤 4:拷贝构造执行结束,对象
b创建完成
拷贝构造函数执行完,新对象
b的成员data已正确指向堆中复制好的字符串,b完全创建成功。此时
a和b的关系:内容完全相同(都是 "hello"),但各自的data指向堆中不同的内存(互相独立,互不干扰)。关键总结(和普通构造的核心区别)
普通构造是 “用基础类型(如
string、int)初始化对象”,而拷贝构造是 “用同类型对象初始化新对象”,核心难点是必须手动复制堆内存的内容(因为MyString的字符串存在堆里,不复制会导致a和b的data指向同一块堆内存,后续销毁时会出问题)。补充:
这里的所以这里
.data就是传递过来的a的,而data是这个类自己的。
至此说差不多了,感觉没啥了,开始说移动构造,之前给了一堆代码还没解释,依旧是搜“那开始说另一个 —— 移动构造”那个代码:
专门用来 “高效接管临时对象的资源”,核心是 “抢指针而非复制内容”,拆解如下:
场景:什么时候会调用?
当用即将销毁的临时对象初始化新对象时自动触发,比如:
查看代码
#include <cstring> // 用strlen、strcpy需要的头文件 #include <iostream> using namespace std; class MyString { private:char* data;// 成员变量:指向字符串的指针(存字符串在堆里的地址)public: // 访问控制// 补充普通构造函数(从字符串字面量创建对象)MyString(const char* initStr) {int len = strlen(initStr) + 1;data = new char[len];strcpy(data, initStr);} // 拷贝构造函数MyString(const MyString& other) {int len = strlen(other.data) + 1;data = new char[len];strcpy(data, other.data);cout << "调用拷贝构造函数" << endl;}// 移动构造:直接拿临时对象的数据(快)MyString(MyString&& other) {data = other.data; // 直接抢指针other.data = nullptr; // 原对象数据清空(它马上要销毁了)}// 补充析构函数释放内存~MyString() {delete[] data;}// 补充print函数(改为public)void print() {cout << data << endl;} };// 函数返回一个临时MyString对象 MyString createString() {return MyString("临时字符串"); //代码里没有MyString(const char* initStr)的话就无法用字符串字面量创建对象//createString()返回的是临时对象(右值); }int main() {// 用临时对象初始化b,触发移动构造MyString b(createString()); b.print(); // 输出:临时字符串 }代码执行逻辑(以上面的
b(createString())为例):
other是谁?other是临时对象的右值引用(&&标记),代表那个即将被销毁的"临时字符串"对象。
data = other.data:直接 “抢” 资源,新对象b的data指针,直接指向临时对象other在堆里的字符串内存(比如"临时字符串"的地址),没有复制内容(这就是比拷贝构造快的原因)。
other.data = nullptr:避免临时对象销毁时 “误删” 资源。临时对象马上会被销毁,它的析构函数会执行delete[] data。
把other.data设为nullptr后,析构函数删除nullptr是安全的(不会真的删除内存),确保b能正常使用抢来的资源。核心价值:
效率极高:不用复制堆里的字符串内容(尤其对长字符串,速度提升明显)。
- 只针对临时对象:因为临时对象马上要销毁,“抢” 它的资源不会有副作用(原对象不会再被使用
注意:
所有的代码只是为了理解重点,我在理解重点后就没实操了,不然太浪费时间了,已经实操很多了。要说的就是很多类,然后用类创建对象,这里对象需匹配已定义的构造函数(参数、权限),而构造函数必须写
public才能在类外创建对象,不然默认都是privat无穷无尽永无止境的琐碎知识点:
右值引用(
&&)是 C++11 引入的特性,专门用来绑定右值(即将销毁的临时数据),核心是 “标记可被移动的资源”,让移动构造 / 移动赋值能高效接管资源。先分清左值和右值:
左值:能放在
=左边,可以取地址的 “持久数据”(有名字,能被重复使用)。比如:变量
a、对象obj、arr[0](数组元素)。- 右值:只能放在
=右边,不能取地址的 “临时数据”(没名字,用完就销毁)。比如:字面量
10、表达式结果a+b、函数返回的临时对象createString()。右值引用(
&&)的作用:
专门绑定右值,语法是
类型&& 变量名,比如MyString&& temp = createString()。它的核心意义:告诉编译器 “这个数据是临时的,可以安全地‘抢’它的资源”(不会影响其他代码,因为它马上要销毁了)。
和移动构造的关联:
移动构造函数的参数
MyString&& other,就是用右值引用绑定临时对象。编译器看到&&,就知道 “这个other是临时的,移动它的资源没问题”,于是调用移动构造而非拷贝构造,实现 “抢指针” 的高效操作。
移动构造在 C++ Linux 服务端开发大厂面试中频率较高,属于 C++ 核心机制部分,是值得花时间搞透彻的重要知识点
傻逼编译器TinyMCE5真他妈恶心,段落无勾+ 有勾一起选就是有勾,导致必须一行一行打勾,全都取消再打有bug。
移动构造这里,main 里调用时,传递的是右值(临时对象),而移动构造的参数
MyString&& other是右值引用(专门绑定右值的引用类型)。比如MyString b(createString());中,createString()返回的临时对象是右值,会被&&绑定,本质仍是通过引用传递(没有复制整个对象),只是这种引用专门针对 “即将销毁的临时数据”,允许安全 “抢资源”
void func1(int& ref) {} // 别名(引用) void func2(int val) {} // 直接定义副本 int main() {int a = 10;func1(a); // 传a本身,调用func1(引用参数)func2(a); // 传a的副本,调用func2(值参数) }调用写法完全一样,核心区别是底层传递机制:
传引用(别名)用的是对象本身
传值(副本)是系统自动生成临时副本传递,程序员看不到副本的创建过程。
如果类里有&、&&、值传递,也无所谓,编译器会自动选择调用类里的函数:
&调用拷贝构造,拷贝构造函数的参数必须是引用(通常是const T&),目的是避免无限递归调用
&&调用移动构造值传递先调用拷贝 / 移动构造再析构临时对象:
当实参以值传递方式传给构造函数参数时,会先创建一个实参的临时副本:若实参是左值,用拷贝构造生成临时对象;若实参是右值,用移动构造生成临时对象,随后临时对象在构造结束后被析构
&&右值引用只能绑定临时的,直接“接管”马上销毁的资源,比拷贝构造的“复制一份新资源”高效。
MyString a("hello"); // a是正常对象(左值) MyString b(a); // 调用拷贝构造,原对象a继续存在(后续还能使用a)这里
a在拷贝后仍然有效,所以拷贝构造必须 “复制一份新数据”—— 如果像移动构造那样 “抢a的资源”,后续再用a就会出问题(a.data已经是nullptr了)。
A obj(a)就是用变量a创建一个A类型的对象obj,编译器会去找参数能匹配a类型的构造函数来初始化obj。至此也明白了,
拷贝构造的参数是已存在的
MyString对象(左值),类型完全匹配const MyString&;移动构造的参数是临时
MyString对象(右值),类型完全匹配MyString&&。类型都一样,也不需要类型转换了。
explicit、移动语义很重要。
介绍聚合初始化:
用大括号
{}直接按成员顺序初始化其元素或成员。查看代码
struct Point {int x;int y; }; // 聚合初始化,直接初始化 x 和 y Point p = {1, 2}; class MyArray { public:int arr[3]; }; // 聚合初始化,初始化 arr 的三个元素 MyArray ma = {1, 2, 3}; //如果多一个私有类型,就连ma都不能合初始化了首先
叫用户写的默认构造,默认构造不是只有自动生成的。class MyClass { public:// 用户写的默认构造函数(无参数)MyClass() {} };那如果同时满足
没有私有 / 保护成员
没有用户定义的构造函数
没有基类
没有虚函数
才可以聚合初始化。
C++ 里struct和class只有一个核心区别:struct的成员默认是public,class默认是private。其他规则完全一样 —— 包括 “编译器自动生成默认构造” 这一点private 仅表示访问权限为私有,若成员前加 static 是静态,不加 static 默认非静态。
查看代码
#include <iostream>// 结构体(默认public) struct Point {int x;int y;// 无显式构造函数,编译器自动生成默认构造 }; int main() {// 1. 调用编译器生成的默认构造(无参)Point p1;p1.x = 1;p1.y = 2;std::cout << "p1: " << p1.x << "," << p1.y << "\n";// 2. 聚合初始化(因是聚合类型)Point p2 = {3, 4}; // C++11前写法Point p3{5, 6}; // C++11后列表初始化std::cout << "p2: " << p2.x << "," << p2.y << "\n";std::cout << "p3: " << p3.x << "," << p3.y << "\n"; }#include <iostream>// 类(默认private) class Rectangle {int width; // 默认privateint height;public:// 显式定义默认构造Rectangle() : width(0), height(0) {}// 显式定义带参构造Rectangle(int w, int h) : width(w), height(h) {}void print() {std::cout << "尺寸: " << width << "x" << height << "\n";} }; int main() {// 1. 调用显式默认构造Rectangle r1;r1.print(); // 输出: 尺寸: 0x0// 2. 调用带参构造Rectangle r2(2, 3);r2.print(); // 输出: 尺寸: 2x3// 3. 无法聚合初始化//class内只要没显示写public就是private的成员,而且还有显式构造,不是聚合类型// Rectangle r3 = {4,5}; // 编译错误 }
std::initializer_list:接受一个
std::initializer_list作为参数的构造函数应当省略explicit,以便支持拷贝初始化(例如MyType m = {1, 2};)std::initializer_list是 C++ 用来支持列表初始化(用{}初始化对象)的工具。如果构造函数接受std::initializer_list,并且希望支持 拷贝初始化(即MyType m = {1, 2};这种 “=+{}” 的写法),就不能加explicit。
- 如果加了
explicit:只能用直接初始化(MyType m{1, 2};),而不能用拷贝初始化(MyType m = {1, 2};)。如果省略
explicit:既支持直接初始化(MyType m{1, 2};),也支持拷贝初始化(MyType m = {1, 2};),更方便列表初始化的使用。查看代码
#include <initializer_list> class MyType { public:// 省略 explicit,支持列表初始化的拷贝形式MyType(std::initializer_list<int> init) { /* 用 init 初始化对象 */ } };int main() {MyType m1 = {1, 2}; // 拷贝初始化,合法(因为没加 explicit)MyType m2{1, 2}; // 直接初始化,也合法 }你提到的 “不用
std::initializer_list的时候也可以列表初始化”,其实要分情况 ——不同的列表初始化场景,背后的机制是不一样的,我们结合例子来拆解:情况 1:类没有
std::initializer_list构造函数时的 “列表初始化”此时的列表初始化,本质是调用 “匹配参数数量的构造函数”,但有严格限制:
若类没任何手写的构造 + 聚合类型(简单理解:成员都是公共的,无复杂构造逻辑),可以直接列表初始化:
struct Point {int x;int y; }; Point p = {1, 2}; // 聚合初始化,直接给成员赋值若类有带参数的构造函数,列表里的元素会尝试匹配构造函数的参数:
class MyInt { public:MyInt(int a, int b) { /* 构造逻辑 */ } }; MyInt m = {1, 2}; // 调用 MyInt(int, int) 构造函数但这种情况非常脆弱:如果构造函数参数数量 / 类型不匹配,会直接编译错误;且无法支持 “元素类型与构造函数参数类型不同,但需要隐式转换” 的场景(除非构造函数没加
explicit)。情况 2:类有
std::initializer_list构造函数时的 “列表初始化”此时的列表初始化,是专门针对
std::initializer_list的语义,更灵活且有明确的容器初始化逻辑:
无论类是否有其他构造函数,只要存在
std::initializer_list构造函数,列表初始化会优先调用它:#include <initializer_list> #include <vector> class MyVector { public:MyVector(std::initializer_list<int> list) {// 用 list 里的元素初始化内部容器}MyVector(int size, int val) {// 其他构造逻辑} }; MyVector v = {1, 2, 3}; // 优先调用 std::initializer_list 构造函数支持 “元素类型与
initializer_list元素类型隐式转换”,且能和 STL 容器(如std::vector)的列表初始化行为保持一致。核心区别
没有
std::initializer_list时的 “列表初始化”:是语法糖,本质是调用普通构造函数 / 聚合初始化,限制多、语义弱。有
std::initializer_list时的 “列表初始化”:是专门的容器初始化语义,更灵活、更符合 “用一组元素初始化容器” 的直觉,且能和 STL 保持一致。回到最初的问题 ——“不用
std::initializer_list的时候不也可以列表初始化吗?”是的,但两种 “列表初始化” 的底层逻辑、适用场景、灵活性完全不同:
无
std::initializer_list:是通用语法的 “顺带支持”,限制多。
有
std::initializer_list:是专门为 “容器类初始化” 设计的特性,更强大、更符合直觉。而原文强调 “接受
std::initializer_list的构造函数应当省略explicit”,正是因为std::initializer_list是专门的列表初始化语义,需要支持MyType m = {1, 2};这种自然的拷贝初始化形式#include <initializer_list> class MyType { public:// 省略 explicit,支持列表初始化的拷贝形式MyType(std::initializer_list<int> init) { /* 用 init 初始化对象 */ } };int main() {MyType m1 = {1, 2}; // 拷贝初始化,合法(因为没加 explicit)MyType m2{1, 2}; // 直接初始化,也合法return 0; }查看代码
#include <iostream>// 场景1:有普通构造函数的类 class MyClass { public:int a, b;MyClass(int x, int y) : a(x), b(y) {} // 普通构造函数 };// 场景2:聚合类型(结构体) struct Point {int x, y; // 无构造函数,成员public }; int main() {// 对MyClass:{1,2}等价于(1,2),都是调用构造函数MyClass obj1{1, 2}; // {}形式MyClass obj2(1, 2); // ()形式std::cout << obj1.a << "," << obj1.b << "\n"; // 1,2std::cout << obj2.a << "," << obj2.b << "\n"; // 1,2(结果相同)// 对Point:{3,4}等价于逐个赋值,都是直接初始化成员Point p1{3, 4}; // {}形式Point p2; p2.x=3; p2.y=4; // 逐个赋值形式std::cout << p1.x << "," << p1.y << "\n"; // 3,4std::cout << p2.x << "," << p2.y << "\n"; // 3,4(结果相同) }语法糖的核心就是 “不改变本质,只简化写法”。
没有
std::initializer_list时的{}初始化,本质上就是用更简洁的{}替代了原来的()(调用构造)或逐个赋值,底层逻辑没变,只是少写了代码—— 这就是语法糖的定义:不增加新功能,只让写法更甜(简洁)。比如
Point p{3,4};和Point p; p.x=3; p.y=4;,最终都是给 x、y 赋值,后者是原始写法,前者是简化写法(糖)
从 “刚懂的 C++ 构造” 出发,一步步把这俩东西拆明白 ——先讲 {} 怎么来的,再讲 std::initializer_list 是干啥的,最后说清它俩的关系,保证不混。
第一步:先理解 {} 的 “初心”—— 为了统一初始化写法(跟
std::initializer_list没关系)你刚懂 “构造函数”,应该知道早期 C++ 初始化写法特别乱,不同类型要写不同格式,比如:
普通变量:
int a = 10;数组:
int arr[3] = {1,2,3};(必须用 {})结构体(聚合类型):
struct Point {int x,y;}; Point p = {1,2};(也得用 {})类对象(有构造):
MyClass obj(1,2);(只能用 (),不能用 {})你看,初始化数组 / 结构体必须用
{}, 初始化类对象必须用(), 写法不统一,所以 C++ 标准后来加了个改进:让{}能通用于所有类型的初始化—— 不管是数组、结构体、还是有构造函数的类,都能用{}写。比如之前只能写
MyClass obj(1,2);,现在可以写MyClass obj{1,2};了 ——这时候的 {},本质就是 “替代 () 的构造调用”,跟 std::initializer_list 一点关系没有,纯粹是简化写法。第二步:再看
std::initializer_list—— 解决 “不定长参数初始化” 的问题(这才是它的用处)你懂构造函数,那肯定知道:构造函数的参数个数是固定的。比如
MyClass(int x, int y)只能传 2 个 int,想传 3 个、4 个就不行。但实际开发中,经常需要 “给对象传一堆同类型的值”,比如:
想初始化一个 “数组类”(比如 vector),直接传
{1,2,3,4};想初始化一个 “集合类”,直接传
{10,20,30}。如果没有
std::initializer_list,这事很难办 —— 因为构造函数参数个数固定,没法接收 “不确定个数的同类型值”。这时候
std::initializer_list就登场了:它是 C++ 提供的一种 “临时容器类型”,专门用来打包 “一堆同类型的值”,让构造函数能接收 “不定长的参数列表”。举个最直观的例子(vector 的初始化):
查看代码
#include <vector> #include <initializer_list> // 用这个类型必须包含头文件int main() {// 你现在知道:vector是个动态数组类// 早期初始化vector,得先创建空的,再push_back,很麻烦:std::vector<int> v1;v1.push_back(1);v1.push_back(2);v1.push_back(3);// 或者用临时数组转,更麻烦:int arr[] = {1,2,3};vector<int> v2(arr, arr + sizeof(arr)/sizeof(int));// C++11后就有了std::initializer_list,vector专门加了一个“接收initializer_list的构造函数”,顺带很多容器也都有了这个// 现在可以直接写:std::vector<int> v2{1,2,3}; // {}里的1,2,3被打包成std::initializer_list<int>,传给vector的构造// 这里的关键:v2{1,2,3}能成功,是因为vector里有这样的构造:// class vector {// public:// vector(std::initializer_list<int> list); // 专门接收initializer_list的构造// };// map 也能直接传键值对列表map<string, int> m = {{"a",1}, {"b",2}, {"c",3}}; }看到没?
std::initializer_list的核心用处,就是让构造函数能接收 “不定长的同类型值”—— 没有它,你没法直接用{1,2,3}初始化 vector(因为普通构造函数参数个数固定);有了它,{}里的一堆值就被打包成一个initializer_list对象,传给专门的构造函数。第三步:最后理清
{}和std::initializer_list的关系 —— 不是 “等同”,是 “配合”现在你应该能分清了:
{} 是 “初始化语法符号”:就像一个 “容器壳”,本身没有类型,只是用来写初始化值的格式。
当你用
MyClass obj{1,2};时(MyClass只有MyClass(int x, int y)构造):{} 里的 1、2 是 “两个独立的 int 参数”,直接传给普通构造,跟 std::initializer_list 没关系;
当你用
vector<int> v{1,2,3};时(vector 有接收initializer_list的构造):{} 里的 1、2、3 会被编译器 “打包成一个
std::initializer_list<int>对象”,然后传给对应的构造 —— 这时候 {} 才和 std::initializer_list 配合使用。
std::initializer_list是 “参数类型”:它是一个实实在在的类型(就像 int、string 一样),只能用来给构造函数(或函数)当参数,让它们能接收不定长的同类型值。没有 {},它也能存在,但没法直接传值;没有它,{} 也能用来调用普通构造。总结:一句话帮你记牢
{} 是 “写字的笔”:不管写普通构造的参数(1,2),还是写不定长的值(1,2,3,4),都用它;
std::initializer_list 是 “装笔的笔袋”:只有当你要装 “一堆同类型的笔”(不定长值)时,才需要它,否则直接用笔画就行。
你刚懂构造,先记住 “用 {} 调用普通构造”(比如
MyClass obj{1,2};)是没问题的,等以后用到 vector、map 这种需要 “传一堆值” 的类时,再回头看std::initializer_list,就完全懂了补充:自定义类用它:也能支持 “列表初始化”
不止 STL 容器,你自己写的类,只要加一个接收
std::initializer_list的构造函数,就能让它支持{}批量初始化,不用重复写多个参数的构造函数。比如你写一个 “分数集合” 类
ScoreSet,想支持ScoreSet s = {90, 85, 95};,用initializer_list只要写一个构造函数:#include <initializer_list> // 必须包含这个头文件 #include <vector> using namespace std;class ScoreSet { private:vector<int> scores; public:// 关键:加一个接收 initializer_list 的构造函数ScoreSet(initializer_list<int> init_list) {// 遍历 init_list,批量把值存到 scores 里for (int val : init_list) {scores.push_back(val);}} };int main() {// 现在自定义类也能直接用列表初始化了!ScoreSet s = {90, 85, 95, 88}; // 简洁、直观 }如果不用
initializer_list,想支持 “传 2 个分数”“传 3 个分数”“传 4 个分数”,你得写 多个重载构造函数,代码会非常冗余:// 不用 initializer_list 的麻烦写法 class ScoreSet { private:vector<int> scores; public:ScoreSet(int a) { scores.push_back(a); } // 1个参数ScoreSet(int a, int b) { scores.push_back(a); scores.push_back(b); } // 2个参数ScoreSet(int a, int b, int c) { ... } // 3个参数// 想支持更多参数?得一直加,根本写不完! };
std::initializer_list的核心好处:让 “用 {} 传一组值” 的初始化方式,能适配所有类型(STL 容器 + 自定义类),既减少冗余代码,又让代码更直观。
C++11 后就有了
std::initializer_list,顺带大部分容器也都有了这个,现在 25 年 9 月是 C++23 了,但 C++11 并不过时,它是现代 C++ 的基石,许多大厂面试和实际工作中都非常重视,因为其引入的智能指针、lambda 表达式等特性极大提升了编程效率和代码质量,初学者建议先扎实掌握 C++11,再逐步学习 C++14、C++17、C++20 等更高版本的特性。C++ 之父开发后,后续更新由 WG21 负责,WG21 是由国际上顶尖的 C++ 专家、学者和工业界人士组成的团队,他们在 C++ 领域具有深厚的技术积累和丰富的经验,负责推动 C++ 标准的更新和发展。
代码 1:没有
std::initializer_list,{}的写法 是 “参数打包”class A { public:// 普通构造:要2个int参数A(int x, int y) { cout << x << "," << y; } };int main() {A a{1,2}; // {} = 把1、2打包,传给A(int,int)构造// 等价于 A a(1,2); —— {}只是换了个写法,没新东西 }代码 2:有
std::initializer_list,{}的写法是 “特殊容器”查看代码
#include <initializer_list> // 必须包含头文件class B { public:// 专门接收 std::initializer_list 的构造B(std::initializer_list<int> list) {// list像个“临时数组”,能遍历里面所有元素for (auto num : list) cout << num << " ";} }; int main() {B b{1,2,3,4}; // {} = 生成一个std::initializer_list对象,传给上面的构造// 这里{}里能塞任意个int(1个、4个都行),因为list是“容器”,不是固定参数 }一句话戳破:
没有
std::initializer_list:{1,2}是 2 个独立参数 的打包,只能对应 “要 2 个 int” 的构造;有
std::initializer_list:{1,2,3}是 1 个临时容器,里面装了 3 个 int,能对应 “要 1 个 initializer_list” 的构造。
{}是个 “壳”,里面装的东西到底是 “几个参数” 还是 “一个容器”,全看类里有没有std::initializer_list构造。
再说
explicit:1. “不能以一个参数进行调用的构造函数不应当加上
explicit”,说白了就是只有【以一个参数进行调用的构造函数】才可能发生隐式转化,才需要加ex那个
explicit关键字的作用是禁止构造函数的 “隐式类型转换”。但如果一个构造函数本身就无法用 “单个参数” 来调用(比如它需要多个参数,或者参数是std::initializer_list这类必须用{}传参的类型),那加explicit就没有意义 —— 因为本来就不会发生 “单个参数的隐式转换”,所以没必要用explicit去禁止。class MyClass { public:// 这个构造函数需要两个参数,无法用“单个参数”调用MyClass(int a, double b) { /* ... */ } };此时,就算不加
explicit,也不可能通过 “单个参数” 隐式转换出MyClass对象(比如MyClass obj = 10;是不合法的)。所以这种构造函数不需要加explicit。2. 接受一个
std::initializer_list作为参数的构造函数应当省略explicit,以便支持拷贝初始化(例如MyType m = {1, 2};)
std::initializer_list是 C++ 用来支持列表初始化(用{}初始化对象)的工具。如果构造函数接受std::initializer_list,并且希望支持 拷贝初始化(即MyType m = {1, 2};这种 “=+{}” 的写法),就不能加explicit。
如果加了
explicit:只能用直接初始化(MyType m{1, 2};),而不能用拷贝初始化(MyType m = {1, 2};)。如果省略
explicit:既支持直接初始化(MyType m{1, 2};),也支持拷贝初始化(MyType m = {1, 2};),更方便列表初始化的使用。
查看代码
#include <initializer_list> class MyType { public:// 省略 explicit,支持列表初始化的拷贝形式MyType(std::initializer_list<int> init) { /* 用 init 初始化对象 */ } };int main() {MyType m1 = {1, 2}; // 拷贝初始化,合法(因为没加 explicit)MyType m2{1, 2}; // 直接初始化,也合法 }//但如果加explicit class MyType { public:explicit MyType(std::initializer_list<int> list) {} // 加了 explicit }; int main() {MyType m = {1, 2}; // 错误!explicit 禁止了这种“拷贝初始化”// 只能用直接初始化:MyType m{1, 2}; } //所以,为了让 MyType m = {1, 2}; 这种拷贝初始化(带 = 的列表初始化)能生效, //接收 std::initializer_list 的构造函数必须省略 explicit。①
MyType m = {1,2};本质是啥?{1,2}被打包成std::initializer_list<int>临时对象;
② 用这个临时对象,通过
MyType的initializer_list构造函数,隐式转换生成m。即把{1,2}隐式转换成MyType类型来初始化m。核心是带了
=号,触发了 “隐式转换” 的逻辑 —— 而explicit就是专门封杀这种逻辑的,所以加了就失效。
explicit和=是死对头,MyType m = {1,2};带了=,所以被explicit封杀。继续:
但其实上面说的
=+{}就不能explicit这里豆包说错了,即使构造函数加了explicit,MyType m = MyType{1, 2};,你看,依然是 “=+{}” ,这也是拷贝初始化啊,也行啊。你说的
MyType m = MyType{1,2};是显式手动创建临时对象再赋值,本身就是你主动控制的行为,不存在 “隐式” 问题;但MyType m = {1,2};是试图让编译器用{}里的内容直接隐式调用构造函数,这时候explicit就会生效拦截 —— 因为如果构造函数没加explicit,编译器可能在更隐蔽的场景(比如函数传参、类型转换)里 “自作主张” 用列表初始化搞隐式转换。所以explicit不是 “针对= + {}写法”,而是 “针对所有依赖该构造函数的隐式转换场景”——= + {}只是其中一种直观场景而已。构造函数接受
std::initializer_list<char>(支持String s = {'a','b'};),如果没加explicit,当你写void func(String s) {}时,调用func({'a','b'});会被编译器隐式转换成func(String{'a','b'})—— 这如果是你想要的,没问题;但如果这个构造函数本不该被隐式调用(比如你设计时希望func只能传显式创建的String对象),这种 “悄悄转换” 就可能打破你的设计逻辑,甚至藏 bug。给接受
std::initializer_list<char>的String构造函数加explicit,就能让func({'a','b'})编译报错,只能传显式创建的String对象(如func(String{'a','b'}))。如:explicit String(initializer_list<char> chars)。查看代码
#include <iostream> #include <initializer_list> #include <cstring> using namespace std;// 模拟一个简单的String类 class String { private:char* data;int len; public:// 1. 接受std::initializer_list<char>的构造函数 —— 此时没加explicitString(initializer_list<char> chars) {len = chars.size();data = new char[len + 1]; // 留一个位置存字符串结束符'\0'int i = 0;for (char c : chars) { // 遍历initializer_list里的字符data[i++] = c;}data[len] = '\0'; // 字符串必须以'\0'结尾cout << "调用了 initializer_list 构造函数(无explicit)\n";}// 2. 拷贝构造(为了支持MyType m = MyType{...}这种写法,必须有)String(const String& other) {len = other.len;data = new char[len + 1];strcpy(data, other.data);cout << "调用了拷贝构造函数\n";}// 析构函数(释放内存,避免泄漏)~String() {delete[] data;}// 辅助函数:打印字符串内容void print() const {cout << data << endl;} };// 测试函数:参数是String类型 void func(String s) {cout << "func里的字符串:";s.print(); }int main() {// 场景1:直接初始化(MyType m{...})—— 无论有没有explicit都能生效cout << "--- 直接初始化 ---\n";String s1{'a', 'b', 'c'};s1.print(); // 输出 abc// 场景2:拷贝初始化(MyType m = {...})—— 因为构造函数没加explicit,所以能生效cout << "\n--- 拷贝初始化(= + {}) ---\n";String s2 = {'x', 'y'};s2.print(); // 输出 xy// 场景3:函数传参时的隐式转换 —— 因为构造函数没加explicit,{...}会被隐式转成Stringcout << "\n--- 函数传参(隐式转换) ---\n";func({'1', '2', '3'}); // 等价于 func(String{'1','2','3'}),编译器自动补全转换// 【关键对比】如果给String(initializer_list<char>)加了explicit:// 1. String s2 = {'x','y'}; —— 编译报错(禁止拷贝初始化的隐式转换)// 2. func({'1','2','3'}); —— 编译报错(禁止函数传参的隐式转换)// 3. 只有 String s1{'a','b','c'}; 和 String s3 = String{'a','b'}; —— 能正常编译 }代码运行输出(没加
explicit时):查看代码
--- 直接初始化 --- 调用了 initializer_list 构造函数(无explicit) abc--- 拷贝初始化(= + {}) --- 调用了 initializer_list 构造函数(无explicit) 调用了拷贝构造函数 xy--- 函数传参(隐式转换) --- 调用了 initializer_list 构造函数(无explicit) 调用了拷贝构造函数 func里的字符串:123
没加
explicit时,{...}能被编译器 “偷偷” 转换成String对象(比如= + {}、函数传参);加了
explicit后,必须 “明着写”String{...}才能创建对象,禁止所有隐式转换,避免意外逻辑;你说的
String s = String{'a','b'},是先显式创建临时对象String{'a','b'},再调用拷贝构造,不依赖隐式转换,所以加不加explicit都能生效
多参数构造函数本身需要多个参数才能调用。而隐式类型转换的场景中,只能提供一个源值。
比如构造函数是
A(int a, string b),要隐式转换时,你只能提供一个值(比如int类型的5),但这个构造函数还需要string类型的参数,这就导致无法用这一个源值去调用多参数构造函数完成转换 —— 不是构造函数 “缺参数”,而是隐式转换场景下给不出构造函数需要的所有参数,因此无法进行隐式转换。
构造函数若本身就不支持 “单参数调用”,加
explicit没用,所以不加。接受
std::initializer_list的构造函数,为了支持更灵活的 “=+{}” 拷贝初始化,要省略explicit
不是所有拷贝初始化都真的执行了 “拷贝构造函数调用”
拷贝初始化(
Type obj = 源;)的核心逻辑是 ——“让obj成为源的‘副本’”,但 “怎么生成副本”,得看源的类型:情况 1:源是 “同类型对象” → 调用拷贝构造
class A {}; A a1; A a2 = a1; // 源a1是A类型 → 调用A的拷贝构造(A(const A&))这是最直观的场景:用已有的
A对象a1,拷贝出a2,所以必须调拷贝构造。情况 2:源是 “能转成该类型的值” → 先构造、再调用拷贝构造函数(但会被优化)
class A { public:A(int x) {} // 有一个int参数的构造 }; A a = 10; // 源是int类型
先调用
A(int),把10转成临时A对象;再调用拷贝构造函数,用临时对象拷贝出
a;但编译器几乎都会优化这步拷贝,直接当成 “用
10构造a”,所以最终可能只调A(int),不实际调拷贝构造。即直接:A(10)构造a,也就是编译器优化后,直接构造,没实际走拷贝那步拷贝初始化的目的是 “复制出一个副本”,但:
若源是同类型对象,必须调拷贝构造;
若源是其他类型(能转成目标类型),会先构造、再拷贝(但拷贝步骤常被优化掉)。
所以说 “不一定调用拷贝构造函数”—— 因为存在 “先构造再优化” 的情况,不是所有拷贝初始化都真的执行了 “拷贝构造函数调用”。从 C++ 标准逻辑上,“拷贝初始化” 的 “拷贝” 是 “最终要生成一个副本” 的目的,不是 “必须调用拷贝构造” 的过程。
解释上面说的隐式类型转换优点之一:
替代函数重载,某些场景下,隐式转换能少写重载函数,更高效。
查看代码
#include <iostream> using namespace std;// 定义一个距离类 class Distance { private:double meters; // 以米为单位存储 public:// 构造函数:允许从double(米)隐式转换Distance(double m) : meters(m) {} // 注意:没有加explicit// 其他单位的转换构造(内部使用)Distance(int cm) : meters(cm / 100.0) {} // 厘米转米Distance(long km) : meters(km * 1000.0) {} // 千米转米double getMeters() const { return meters; } };// 计算两个距离之和的函数(只需要一个版本) Distance add(Distance a, Distance b) {return Distance(a.getMeters() + b.getMeters()); }int main() {// 隐式转换在这些场景下替代了函数重载Distance d1 = add(100.0, 200.0); // double -> DistanceDistance d2 = add(500, 1000); // int(厘米)-> DistanceDistance d3 = add(2L, 3L); // long(千米)-> DistanceDistance d4 = add(1.5, 200); // 混合类型转换cout << "d1: " << d1.getMeters() << "米" << endl; // 300米cout << "d2: " << d2.getMeters() << "米" << endl; // 15米(500cm+1000cm)cout << "d3: " << d3.getMeters() << "米" << endl; // 5000米(2km+3km)cout << "d4: " << d4.getMeters() << "米" << endl; // 201.5米(1.5米+200cm) }代码说明:
Distance类的构造函数没有加explicit,允许从double、int、long隐式转换,只需要一个add(Distance, Distance)函数,就能处理:
直接传入
Distance对象传入
double(米)传入
int(厘米)传入
long(千米)混合类型的参数
为什么替代了函数重载?
如果不用隐式转换,需要写多个重载函数:
Distance add(double a, double b); Distance add(int a, int b); Distance add(long a, long b); Distance add(double a, int b); // ... 还需要处理所有可能的混合类型组合隐式转换让我们用一个函数替代了大量重载,这就是它 "高效" 的一面。但这把双刃剑的另一面是:过度使用可能导致转换逻辑混乱,难以调试。
1. 分析
add函数的参数要求
add函数的定义是Distance add(Distance a, Distance b),它要求传入两个Distance类型的参数。但我们实际传入的是100.0和200.0,这两个都是double类型,和add函数要求的参数类型不匹配 。2. 隐式类型转换过程
因为
Distance类中有一个 没有用explicit修饰 的构造函数Distance(double m),这就意味着编译器可以在需要的时候,自动把double类型的值转换成Distance类型。
当编译器看到
add(100.0, 200.0)时,它发现参数类型不匹配,于是开始找能解决这个问题的办法。它注意到有
Distance(double m)这个构造函数,就会利用这个构造函数分别将100.0和200.0进行隐式转换。具体来说,编译器会 调用
Distance(double m)构造函数,分别创建两个临时的Distance对象 。也就是:
用
100.0调用Distance(double m),创建出一个表示100.0米距离的临时Distance对象,假设叫temp1。用
200.0调用Distance(double m),创建出一个表示200.0米距离的临时Distance对象,假设叫temp2。3.
add函数的调用过程此时,编译器就相当于调用
add(temp1, temp2)。进入add函数内部:Distance add(Distance a, Distance b) {return Distance(a.getMeters() + b.getMeters()); }
a.getMeters()获取temp1表示的距离(单位:米),b.getMeters()获取temp2表示的距离(单位:米)。
然后将这两个距离值相加,得到
100.0 + 200.0 = 300.0。接着调用
Distance类的构造函数Distance(double m),用相加后的结果300.0,创建一个新的Distance对象 。这个新对象就是add函数的返回值。4. 赋值过程
add函数返回一个Distance类型的对象后,会执行Distance d1 = ...这部分的赋值操作。这里其实是调用了Distance类的 拷贝构造函数(如果没有自定义拷贝构造函数,编译器会自动生成一个默认的),将add函数返回的临时Distance对象的值拷贝给d1,这样d1就被成功初始化,并且表示的距离是300.0米。总结来说,在
Distance d1 = add(100.0, 200.0);这行代码中,左边的d1是在最后通过拷贝构造函数被初始化;右边在调用add函数前,编译器利用隐式类型转换,通过Distance(double m)构造函数将传入的double类型参数转成Distance类型对象,进而完成整个计算和初始化过程5.我的疑惑是,都写自定义构造了还会自动生吗?
关键点:自定义了其他构造函数后,编译器仍会自动生成默认拷贝构造函数(这是特殊规则)。细节:
C++ 标准规定:只有当你没有自定义任何构造函数时,编译器才会生成默认无参构造函数;
但拷贝构造函数不受此影响—— 即使你定义了其他构造函数(如
Distance(double)、Distance(int)等),编译器仍会自动生成默认拷贝构造函数(浅拷贝),除非你自己显式定义了拷贝构造。所以代码中:
- 虽然有多个自定义构造函数,但未定义拷贝构造,因此编译器自动生成默认版本,用于
d1 = add(...)时的拷贝初始化总结:
拷贝构造函数:
MyString(const MyString&),默认做浅拷贝(直接复制data指针,会导致双重释放)。拷贝赋值运算符:
operator=(const MyString&),同样默认浅拷贝,问题同上。重点总结:
默认生成的 4 个核心函数(C++11 前):
默认构造函数(无参):
MyString(),没手动定义任何构造时才生成。析构函数:
~MyString(),默认是空实现(不释放堆内存!这就是为啥手动管理堆时必须自己写析构)。拷贝构造函数:
MyString(const MyString&),默认做浅拷贝(直接复制data指针,会导致双重释放)。拷贝赋值运算符:
operator=(const MyString&),同样默认浅拷贝,问题同上。何时会自动生成 / 禁用?
手动定义了析构 / 拷贝函数,编译器可能不生成移动相关函数(避免隐式行为导致错误)。
一旦有堆内存管理(比如
new分配),必须手动重写析构、拷贝构造、拷贝赋值(即 “三法则”),否则用默认版本必出内存问题。怎么用?
简单对象(无堆内存):直接用默认生成的即可,不用管。
带堆内存的对象(如
MyString):必须自己写析构(释放堆)、拷贝构造(深拷贝堆数据)、拷贝赋值(先释放自身堆,再深拷贝),否则默认版本会踩坑。本质:默认函数是 “省心但危险” 的简化版,涉及堆内存时必须手动接管,这是 C++ 内存管理的核心纪律。
也就是说:
没写任何自定义函数会生无参构造:仅当未定义任何构造函数时生成(只要写了带参 / 拷贝 / 移动构造,就不生成)。
没写任何析构数会生析构:默认生成,空实现(不释放堆内存,所以带堆管理必须手动写)。
没写任何拷贝构造函数会生浅拷贝:默认生成,做浅拷贝(直接复制成员,如
data指针,导致双重释放)。没写任何赋值运算符,都会自动生赋值:默认生成,同样浅拷贝(问题同上)。
带堆内存的类(如
MyString),用默认生成的拷贝 / 析构函数必出问题,必须手动重写。关于赋值运算符(
operator=)在没手动定义时,编译器会自动生成默认版本,行为是浅拷贝(直接复制所有成员变量),举个具体例子(结合MyString类):class MyString { private:char* data; public:// 带参构造(手动定义,因此编译器不生成默认无参构造)MyString(const char* str) {data = new char[strlen(str) + 1];strcpy(data, str);}// 未手动定义拷贝赋值运算符,编译器会自动生成默认版本// ~MyString() 也未手动定义,编译器生成默认空析构 };int main() {MyString a("hello");MyString b("world");// 触发默认拷贝赋值运算符b = a; // 等价于编译器生成的 b.data = a.data;(浅拷贝)// 此时 a.data 和 b.data 指向同一块堆内存// 当 a 和 b 析构时(默认空析构不释放堆),会导致内存泄漏// 若手动写了析构释放堆,则会导致双重释放return 0; }关键问题:默认赋值运算符的浅拷贝,会让两个对象的
data指针指向同一块堆内存,后续无论是修改其中一个对象的数据(会影响另一个),还是析构时释放(双重释放),都会引发错误。正确用法(必须手动重写):
// 手动实现拷贝赋值运算符(深拷贝) MyString& operator=(const MyString& other) {if (this != &other) { // 避免自我赋值delete[] data; // 先释放自身已有堆内存data = new char[strlen(other.data) + 1]; // 重新分配strcpy(data, other.data); // 拷贝数据}return *this; }这样
b = a时,b会独立拥有一份堆数据拷贝,避免所有内存问题。写法问题:
内置类型(如 int、double 等):直接用
=即可,这是语言原生支持的,比如a = 5;,不需要任何额外代码。自定义类对象:当你想对类对象用
=赋值时(比如b = a;,其中a和b是MyString对象),这个=的行为需要通过重载operator=来定义,本质是写一个名为operator=的成员函数。class MyString { public:// 重载赋值运算符,定义对象间的`=`行为MyString& operator=(const MyString& other) {// 自定义赋值逻辑(如深拷贝)return *this;} };简单说:内置类型的
=是 “天然的”,类对象的=需要用operator=来 “手动定义规则”,编译器生成的默认版本就是一种预定义的规则(浅拷贝)。
explicit是 “显式的、明确的”,implicit是 “隐式的、含蓄的”,所以上面没ex的那个也叫允许隐式implicit转化版本,如果不能隐式转化,就要加ex:查看代码
#include <iostream> using namespace std;class Distance { private:double meters; public:// 显式构造函数(禁止隐式转换)explicit Distance(double m) : meters(m) {}explicit Distance(int cm) : meters(cm / 100.0) {}explicit Distance(long km) : meters(km * 1000.0) {}double getMeters() const { return meters; } };// 必须为每种类型组合写重载函数,否则无法直接传基本类型 Distance add(Distance a, Distance b) {return Distance(a.getMeters() + b.getMeters()); }// 处理double+double Distance add(double a, double b) {return add(Distance(a), Distance(b)); }// 处理int+int(厘米) Distance add(int a, int b) {return add(Distance(a), Distance(b)); }// 处理long+long(千米) Distance add(long a, long b) {return add(Distance(a), Distance(b)); }// 处理double+int混合 Distance add(double a, int b) {return add(Distance(a), Distance(b)); }// ... 还需要更多重载处理其他混合类型(如int+long、long+double等)int main() {Distance d1 = add(100.0, 200.0);Distance d2 = add(500, 1000);Distance d3 = add(2L, 3L);Distance d4 = add(1.5, 200);cout << "d1: " << d1.getMeters() << "米" << endl;cout << "d2: " << d2.getMeters() << "米" << endl;cout << "d3: " << d3.getMeters() << "米" << endl;cout << "d4: " << d4.getMeters() << "米" << endl; }
再说下
operator TargetType(),这是 C++ 的类型转换运算符,用于自定义 “当前类对象隐式 / 显式转换为 TargetType 类型(比如int、double)” 的规则。现实类比:为什么需要 “类转 int”?
你钱包(
class 钱包)里有 100 块现金(内部存着int 金额=100)。问 “你有多少钱?”—— 你不会把整个钱包给人看,而是直接说 “100 块”(把钱包 “转成” 金额数字)。C++ 里的 “类转 int” 就是这个意思:当类的核心功能和某个基本类型(比如 int)强相关时,让它能 “自动拿出核心值” 来用。
代码里的来龙去脉:
1、类 A 的设计目的:假设
A是一个 “计数器类”,核心就是存一个数字(这里简化成固定返回 10)。2、转换运算符的作用:
operator int() const { return 10; }这句话就是告诉编译器:“如果有人想把A的对象当int用,你就调用我这个函数,返回 10 就行。”3、
int x = a;的逻辑:
左边要
int,右边是A类型的a,类型不匹配。编译器一看:
A里有 “转 int” 的规则啊!就调用
a.operator int(),拿到返回值 10,赋值给x。实际用处:比如写一个 “年龄类”:
class Age { private:int value; // 核心就是这个int值 public:Age(int v) : value(v) {}// 允许把Age转成intoperator int() const { return value; } };int main() {Age a(20);int myAge = a; // 直接拿到20,不用写a.getValue()if (a >= 18) { // 直接和int比较,不用拆包cout << "成年了";} }没有这个转换,你每次都得写
a.getValue(),查看代码
#include <iostream> using namespace std;class Age { private:int value; // 核心就是这个int值 public:Age(int v) : value(v) {}// 允许把Age转成intoperator int() const { return value; }// 获取value值的成员方法int getValue() const {return value;} };int main() {Age a(20);// 可以通过类型转换直接拿到20int myAge = a; // 也可以通过getValue方法拿到20int myAge2 = a.getValue();// 直接和int比较,不用拆包if (a >= 18) { cout << "成年了";} }代码里
Age a(20);创建一个Age类型的对象a,并且把20存到这个对象的value里。用 20 初始化一个 Age 对象。
int myAge = a;调用的是你定义的 类型转换运算符operator int(),把 Age 对象转成int值,再赋给myAge。简单说:构造函数是 “创建对象”,类型转换运算符是 “从已有对象里拿出对应类型的值”,二者作用完全不同有了转换就简洁多了 —— 这就是 C++ 设计这个功能的初衷:让自定义类用起来像内置类型一样方便。
所以有
explicit就是只能显示转化,比如日志类LogLevel,你可能需要偶尔转成int存数据库(显式转合理),但绝不想让它在比较、运算时被偷偷转成int(隐式转容易出 bug)。这时就用explicit operator int(),既保留必要功能,又防隐藏错误。
Q:追问有必要吗?针对大厂 Linux C++ 服务端开发岗位
A:大厂常考这类基础细节,尤其注重对隐式转换、explicit 等机制的理解深度,常刨根问底。
再逼逼些东西,加深巩固:
普通构造函数(比如
Age(int v))参数是其他类型(如int),用于从其他类型创建对象;拷贝构造函数(如
Age(const Age& other))参数是 “当前类的对象”,用于从同类对象差别就是参数类型。
int a是重新整副本
int &是原值的别名,没新内存
int &p和int& p完全等价
int *是创建新的内存,类型是指针变量,指向原值的地址副本(指针本身是副本,但通过它能操作原值),既不是原值本身,也不是原值的完整副本
以下二者编译效果完全一致:
int* p:强调*p是 int 类型,更符合 “指针是一种类型” 的现代理解(推荐用于变量声明)。大厂常用
int *p:强调p是指针,指向 int,是早期 C 语言的写法(在多重声明时更清晰,如int *p, *q)。
再说析构:
释放对象在堆上分配的内存,避免内存泄漏,代码此文搜“后面再讲解析构”
创建对象
a和b时,构造函数通过new char[len]在堆上分配了内存(存储字符串);当
main()函数结束,对象a和b销毁时,析构函数会自动被调用,执行delete[] data释放之前分配的堆内存;如果没有析构函数,堆上的内存会一直被占用,导致内存泄漏(程序运行时间越长,占用内存越多
再看此文搜“什么时候会调用?” 那个代码:
return MyString("临时字符串")中,MyString("临时字符串")是临时对象(创建后马上要被返回,生命周期极短);MyString b(createString())中,createString()返回的那个对象是临时对象(作为参数传给b的构造函数后就会销毁)。
MyString("临时字符串")调用的是你之前代码里定义的 普通构造函数MyString(const char* initStr)。因为括号里传的参数是const char*类型(字符串字面量 "临时字符串" 本质就是const char*),完全匹配普通构造函数的参数类型,所以会触发这个构造函数,在堆上分配内存并存储 "临时字符串",最终创建出一个 未命名的临时对象。
MyString(const char* initStr)可以改成const char*&,但容易出错,因字符串字面量无法绑定到非 const 指针引用,实际常用const char*即可。(就多想了下,追问豆包这么句话,结果他妈的又是引发超长追问的血案,时候发现这段代码本身的都不是很清楚,开始往祖坟上刨,一直追问到盘古开天辟地女娲补天)所有类要么写,要么不写任何自定义的等着默认生,不然就相当于废类无法调用。
之前代码
查看代码
#include <string> using namespace std;class Teacher { public:string name; // 成员变量:名字// 构造函数:参数是string类型的名字Teacher(string n) { name = n; // 用参数n初始化成员变量name} };int main() {// 1. 调用处:创建Teacher对象t,传入"张三"Teacher t("张三"); }
张三是const char*类型,会被自动转换为string类型,因为string类有接受const char*的构造函数,能匹配Teacher(string n)的参数要求。继续回到我们的“什么时候会调用?”代码说:
string是类类型,它的构造函数能接收const char*并自动转换;而const char*是原始指针类型,字符串字面量是const char[],无法绑定到char*&(非 const 指针引用),只能用const char*直接接收。简单说:类类型有转换机制,原始指针没有,所以
string能自动处理,const char*加引用会出错。咋一会说什么只能是字面量
char*,一会说(string n)也行?行或不行,核心看 “接收方的类型” 和 “是否有自动转换机制”,分两种场景说:
1. 场景 1:用
string类型接收(比如Teacher(string n))
传入的是
const char*类型的字符串字面量(如"张三")。能行,因为
string类自带一个 “接受const char*的构造函数”(C++ 标准规定的),会自动把const char*转成string,所以Teacher("张三")没问题。2. 场景 2:用
const char*相关类型接收(比如MyString(const char* initStr))
若写成
const char*&(非 const 的指针引用):不行,因为字符串字面量是const char[](只读的),C++ 不允许把只读的东西绑定到 “非 const 的引用” 上,会编译报错。若写成
const char*(直接用指针):能行,const char*本身就可以接收const char[]类型的字面量,不需要转换,直接用就行。简单总结:
string是 “类”,有自动转的能力,所以接字面量没问题;const char*是 “原始指针”,没这能力,加了不当的引用(const char*&)就会错,直接用const char*才对
还是无法理解,插个东西,关于“张三”、“const char arr【】”、“const char* p”:
引言:
const char arr[]中,arr不是指针,而是数组名(代表数组首地址的常量,不能被赋值修改指向)。
const修饰的是数组元素:表示数组里的字符不能被修改(如arr[0] = 'a'会报错),但数组名本身的 “指向”(数组首地址)从定义起就固定,和const无关(数组名天生不能改指向)。简单说:
char arr[]本身不可以有arr=新地址这种写法,地址固定了,但元素可以改,而const char arr[]是 元素都不可改。再次引言:(精华)
1. 字符串字面量的本质
字符串字面量(如
"abc")在 C++ 中的实际类型是const char[N](N是字符数 + 1,包含结束符\0),例如"abc"是const char[4]。
它存储在内存的只读数据段(不可修改),因此自带const属性(只读)。2.
const char* p = "abc";的完整过程
第一步:隐式类型转换:编译器会自动将
const char[4]类型的"abc"转换为const char*类型的临时指针(临时对象)。这个临时指针的值是"abc"首字符的地址(即指向只读数据段中的 'a')。第二步:赋值操作:临时指针的值(地址)被复制给变量
p(p是const char*类型的指针变量)。赋值完成后,临时指针被销毁,但p已保存了地址,因此p能正常访问"abc"。这一步合法,因为 C++ 允许将临时对象的值复制给变量。
3.
const char*& ref = "abc";报错的原因
第一步:同样发生隐式转换:
"abc"先转为const char*类型的临时指针(和上面相同)。第二步:引用绑定失败:
ref是const char*&类型(对const char*指针的引用),引用的本质是变量的别名,必须绑定到一个已存在的、有名字的变量(而非临时对象)。但这里的临时指针是匿名的临时对象,C++ 有死规定:非 const 引用(包括const char*&)不能绑定到临时对象,因此编译报错。4. 关键区别总结
操作 本质 合法性 原因 const char* p = "abc";复制临时指针的值给变量 p合法 允许复制临时对象的值 const char*& ref = "abc";试图将引用绑定到临时指针(匿名对象) 非法(编译报错) 非 const 引用不能绑定临时对象 一句话核心
const char*是接收地址值的副本,const char*&是要给地址变量起别名,而临时指针没有名字,所以后者不允许
开始区分:
第一步:先搞懂 “字符串字面量” 的本质(比如 “张三”)
内存位置:程序一启动,“张三” 就存在常量区(只读,程序运行全程不消失,不能改);
本质:它是个匿名的
const char[](字符数组),比如 “张三” 实际是{'张','三','\0'}(末尾有隐藏的结束符\0),占 3 个字符的内存;关键属性:只读!你要是写
char* p = "张三"; p[0] = 'h';会崩溃,因为改了常量区的东西。第二步:拆 3 个概念的区别(重点看内存和能不能改)
类型 内存位置 本质 能不能改内容? 和 “张三” 的关系 字符串字面量 “张三” 常量区 匿名 const char [] 不能(只读) 本身就是常量区里的原始数据 const char arr [] = "张三" 栈 / 全局区(看定义位置) 独立的 char 数组 不能(因为加了 const) 把常量区 “张三” 拷贝了一份到 arr 里(比如 arr 在栈上,就把 “张三” 的 3 个字符复制到栈内存) const char* p = "张三" 指针 p 在栈 / 全局区,指向的内容在常量区 指针(存地址的变量) 不能(指向的是常量区) p 只存了 “张三” 在常量区的地址,没拷贝内容;相当于 “指着常量区的‘张三’说:我指的是它” 第三步:小白最容易懵的 2 个点(重点衔接)
const char arr [] = "张三" 到底有没有拷贝?—— 有!
比如你在函数里写这句,栈上会开一块新内存(比如叫 arr),把常量区 “张三” 的每个字符(包括\0)都复制到 arr 里。相当于 “把常量区的‘张三’复印了一张放栈上”,但因为 arr 加了const,这张复印件也不能改。
const char* p= "张三" 为啥没拷贝?—— p 只是个地址标签。
p 本身是个指针变量(占 4/8 字节,存地址),它只记录了 “张三” 在常量区的地址,没复制 “张三” 的内容。就像你记了朋友家的门牌号,没把朋友家整个搬过来;所以你通过 p 只能看 “张三”,不能改。
p 的本质:p 是个指针变量(占 4/8 字节,存地址的 “标签”),不是字符串本身;
为啥没拷贝:“张三” 在常量区,p 只存了 “张三” 在常量区的地址,没把 “张三” 的字符内容复制到新地方;
不能改的原因:p 指向的是常量区(只读区域),所以通过 p 改 “张三” 会出错
最后总结核心区别(一句话到位)
“张三”:常量区的原始只读字符数组;
const char arr []:在栈 / 全局区拷贝了 “张三” 的独立数组(加 const 所以不能改);
const char* p:在栈 / 全局区的指针,指向常量区的 “张三”(没拷贝,只存地址)。
还是很朦胧,再继续追问:
const char*和const char*&啥区别?若写成
const char*&(非 const 的指针引用),??我理解这不是有const吗为啥叫非const???回答:(这里傻逼豆包加粗的*和指针的*没处理好,显示混乱,还要自己追问)
先说断句,“非 const 的指针引用”,断句是 “非 const 的” + “指针引用”,核心是 “指针引用”,修饰词是 “非 const 的”。
const char*:指向常量字符的指针(内容不可改,指针可改指向);const char*&:指向常量字符的指针的引用(引用不可改绑定,可通过引用改指针指向,比如让指针指向新地址),指引用绑定的指针本身是非 const 的。const char* p = "abc"; // p是“指向const char的指针”,p本身可改 const char*& ref = p; // ref是p的引用,通过ref能改p(比如ref = "def"; 此时p也指向"def") // 但不能通过ref改内容:ref[0] = 'x'; 这是错的,因为内容是const“非 const 的指针引用”绑定的是 “非 const 类型的指针”(即 const char* 类型的指针,指针本身可改),如果写成 const char const &*,才是 “指向 const char 的 const 指针的引用”—— 此时连通过引用修改指针本身都不行。
但他这个例子太傻逼了,本来想说的是 引用 和 引用绑定的指针 的这俩东西,结果举例子是 不能改指针指向的数据,虽然也对但很der,就像问你吃饭了吗,回答我不能吃屎。
“绑定” 就是引用和一个对象建立永久关联,引用就像这个对象的 “别名”,之后对引用的操作实际都是对被绑定对象的操作,且一旦关联就不能换绑其他对象。例:
int a=5; int &b=a;中,b 绑定 a,b 就是 a 的别名,改 b 就等于改 a,且 b 不能再绑定其他变量。一句话掰透:
const char*& ref里,ref是 “指针的引用”—— ref 绑定的那个指针变量不能换(比如不能让 ref 改绑到另一个指针),但能通过 ref 改这个指针变量的指向(比如让它从指 A 地址改成指 B 地址)。比如:
const char* p = "a";
const char*& ref = p;✅ 能做:
ref = "b";(p 现在指向 "b",改的是 p 的指向)❌ 不能做:
const char* q = "c"; ref = q;(这不是改 p 的指向,是想让 ref 改绑到 q,绝对不行)。
const char* q = "c"; ref = q;这个例子更直接 —— 它试图让ref改绑到q(修改绑定关系),这在 C++ 中是明确禁止的。再继续:
要先明确 “指针类型修饰符的顺序规则”:
const修饰的是它右边紧邻的内容,先理清正确写法,再解释为什么叫 “非 const 的指针引用”:1. 先纠正混乱写法:两种指针的正确表达
类型含义 正确写法 关键说明 指向 const char 的非 const 指针(即 “非 const 的指针”) const char* ptr- const修饰char:指针指向的字符内容不能改(*ptr = 'a'报错)
- 指针本身可改:能让ptr指向新地址(ptr = "new str"合法)指向 const char 的const 指针 const char* const ptr- 第一个 const修饰char:字符内容不能改
- 第二个const修饰ptr:指针本身不能改(ptr = "new str"报错)2. 对应的 “指针引用” 写法
你之前提到的 “非 const 的指针引用”,绑定的是上面第一种指针(const char*类型),正确写法和含义如下:
非 const 的指针引用(绑定
const char*类型指针):const char*& ref含义:这是一个引用,它绑定的对象是 “指向 const char 的非 const 指针”。
特性:通过引用
ref可以修改被绑定指针的指向(比如ref = "new str"),但不能改指针指向的字符内容(*ref = 'a'报错)。
对比 “指向 const char 的 const 指针的引用”:
const char* const& ref含义:这是一个引用,绑定的对象是 “指向 const char 的 const 指针”。
特性:既不能通过
ref改指针指向(ref = "new str"报错),也不能改字符内容(*ref = 'a'报错)。3. 为什么叫 “非 const 的指针引用”?
核心看 “被引用的指针本身是否 const”:
被引用的指针是
const char*(非 const 指针)—— 指针本身能改,只是指向的内容不能改。引用
const char*&的作用是 “绑定这个非 const 指针”,所以叫 “非 const 的指针引用”,重点在 “指针本身非 const”,而非 “指向的内容非 const”说点描述上的差异:
char*是非 const 指针,可修改指向的字符(如*p = 'a'),也可指向非 const 字符,如char str[] = "abc"
const char*是指向 const 字符的指针,不能通过它修改指向的字符(如*p = 'a'会报错),通常指向常量区字符串(如"abc")对比:
指针类型 指针本身能否改指向 指向的内容能否改 标准叫法 char*能 能 指向非 const 对象的非 const 指针 const char*能 不能 指向 const 对象的非 const 指针 char* const不能 能 指向非 const 对象的 const 指针 const char* const不能 不能 指向 const 对象的 const 指针
char* p = "abc";通过*p = 'd'能修改指向的内容,这就是 “指向非 const 内容的指针”。char* p1 = "abc"; p1 = "def"; // 合法,指针本身可改指向const char* p2 = "abc"; p2 = "def"; // 合法,指针本身可改指向
这些是大厂面 Linux C++ 服务端时,指针 const 修饰、内存权限控制、析构 / 移动语义的内存安全,是基础且必问的底层能力。涉及到内存安全
再继续:
核心是先搞懂 “const 修饰的是谁” 和 “引用的本质是啥”,一步步拆:
一、先明确:
const char*和const char*&的区别两者的本质是 “类型不同”,可以类比成 “苹果” 和 “装苹果的篮子的引用”:
类型 本质含义 用途场景 const char*指针(指向一块 “只读的 char 内存”) 直接接收字符串字面量(如 "abc"),因为字面量是只读的const char*&引用(引用了一个 “ const char*类型的指针”)想通过引用来修改 “那个指针本身”(比如让指针指向新地址) 举个直观例子,你就懂了:
// 1. const char*:指针p指向"abc"(只读内存) const char* p = "abc"; // p的值(指向的地址)可以改(比如让p指向"def"),但*p(指向的内容)不能改(不能写*p = 'x') p = "def"; // 合法// 2. const char*&:ref是指针p的引用(相当于p的“别名”) const char*& ref = p; // 通过ref修改,本质就是修改p本身(比如让p指向"ghi") ref = "ghi"; // 此时p也指向"ghi"了,因为ref是p的别名二、关键疑问:
const char*&里有 const,为啥说它 “易和非 const 冲突”?你说的 “非 const”,不是指
const char*&本身,而是指 “字符串字面量的类型” 和const char*&不兼容 —— 问题出在 “字符串字面量不能绑定到这种引用”,和const char*&自己带不带 const 没关系。具体拆两层:
字符串字面量的真实类型是
const char[]
比如"张三",它在内存中是一块 “只读的字符数组”,类型是const char[3](最后带\0,实际是 4 个字节)。
当你把它赋值给const char* p时,const char[]会自动转成const char*(指针指向数组首地址),所以没问题。
const char*&要求 “引用的必须是一个显式的const char*变量”
引用的规则是:不能直接引用 “一个临时转换来的类型”。
比如你写const char*& ref = "张三";:
第一步:
"张三"(const char[])会先临时转成const char*(一个临时的指针值);第二步:想把这个 “临时的
const char*” 绑定到ref(const char*&)—— 但 C++ 不允许!因为临时值是 “匿名的”,引用无法绑定到匿名的临时值(除非是const 引用,但这里const char*&不是const 引用,而是 “引用了一个 const 指针”,两码事)。而如果用
const char*直接接收,就没有这个问题:const char* p = "张三";—— 临时转成的const char*可以直接赋值给指针变量 p,不需要绑定引用,所以合法。三、一句话总结(帮你记牢)
想直接接字符串字面量:用
const char*(简单、安全,常用);想改某个
const char*指针本身:用const char*&(但别用它接字面量,会报错);
const char*&里的 const 修饰的是 “指针指向的内容”,不是 “引用”,它和字面量冲突的原因是 “引用不能绑临时值”,不是 const 本身的问题再说:C++ 不允许把只读的东西绑定到 “非 const 的引用” 上,会编译报错。
意思是:
const char*是指针,可直接接字符串字面量;const char*&是指针的引用,字符串字面量会生成临时指针,C++ 不允许引用绑定临时值,故报错。
const char*:*修饰指向的字符(只读),自身是指针变量,可直接接收字符串字面量(死规定:字面量可隐式转为该类型)。
const char*&:&是对const char*指针的引用(别名),*仍修饰指向的字符(只读)。但字符串字面量转成的是临时指针,C++ 规定 “非 const 引用不能绑定临时值”(死规定),故报错字符串字面量(如 "abc")类型是
const char[],当你用const char*接收时,它会自动转为一个const char*类型的临时指针(指向字面量首地址),这个临时指针会被赋值给你的变量,用完就销毁 —— 这是允许的。但
const char*&是要绑定一个已存在的const char*变量(给它起别名),而临时指针不是一个实际存在的变量,C++ 规定 “非 const 引用不能绑定这种临时值”—— 这是死规定。// 字符串字面量"abc"是const char[4]类型 const char* p = "abc"; // 过程:"abc"先隐式转成临时的const char*(指向首地址),再把这个临时指针的值(地址)赋给p // 临时指针用完就销毁,p保存了地址,合法const char*& ref = "abc"; // 错误:"abc"转成的临时const char*不是实际变量,引用ref无法绑定临时值(C++死规定)核心:
const char*接收的是临时指针的值(复制地址),const char*&要绑定临时指针本身(但临时值不允许被引用。
翻来覆去反反复复墨迹很多都重复的,但这回嘎嘎精通了
再说对象这个事,妈逼的一直以为对象是类然后创建实体,结果和豆包沟通有歧义,现在来重新说这个事:
C++ 标准里:
“对象”指占内存的有类型实体,不是只有类实例才叫对象。
指针(包括临时指针)是存地址的“指针类型对象”,“临时指针是匿名临时对象”,是个没名字、存地址的临时数据实体。
指针(不管是
int*、const char*)本质是 “存储地址的变量 / 临时实体”,符合 “占内存 + 有类型”,所以是对象;类实例只是 “类类型的对象”,是对象的一种,不是全部。你之前用的指针,其实都是 “指针类型的对象”,只是日常没这么叫
int a;“占据内存空间、具有明确类型(int)的实体”所以也是对象。
a是对象,int是a的类型。int a;中,a是 “int 类型的对象
class定义的是 “类类型”,用类创建的实例(如Teacher t("张三");中的t)是 “类类型的对象”,属于 C++ 中 “对象” 的一种。
至此都透彻了 ,理解了“非 const 引用(包括 const char*&)不能绑定到临时对象,因此编译报错。”这句话,
为了之前 Google 那个规范图,追问了这么多,又为了这句话追问了 2 天,又写博客 2 天。搜“血案”
再继续说:
那什么可以绑定临时对象?
const引用(如const T&)能绑定临时对象。
const char*&中,const修饰指针指向的内容,引用本身未被const修饰,故叫非const引用。之前学到最多也是
const char* const指针本身不可改指向,指针指向的内容不可改,现在引用也const了是咋写的?
const只修饰它紧挨着的左边或右边的东西:
const char*→const紧右是char→ 修饰内容(内容不可改)。
char* const→const紧左是*→ 修饰指针(指针不可改)。
const char* const→ 左边const修饰char,右边const修饰*→ 内容和指针都不可改。
const char* const &里的const同上,和引用无关,引用不被const修饰。因为:引用的语法规则里,“const 修饰引用” 本身就是非法的,所以永远不存在 “const 修饰 &” 的情况。const char* const p = "abc"; // p是"内容+指针都不可改"的指针 const char* const &ref = p; // ref是p的引用,绑定后和p完全等价
ref的作用只是给p起个别名,所有const依然只管char(内容)和*(指针),和&(引用)无关。
看 “被 const 修饰的东西” 是 “数据本身” 还是 “访问数据的工具(指针 / 引用)”:
若 const 修饰数据本身(如
const int a):数据绝对不可改,谁都改不了。若 const 修饰访问工具(如
const int& ref或const int* p):数据本身可改(若它非 const),但不能通过这个工具改。
const int& ref:const 修饰的是 “ref 所引用的 int 值” → 不能通过 ref 改这个值。
int* const p:const 修饰的是指针 p 本身 → p 不能指向新地址,但能通过 p 改指向的值。
const int* p:const 修饰的是 p 指向的 int 值 → 不能通过 p 改这个值,但 p 能指向新地址。
例子:
const int& ref→ 限制的是 “通过 ref 这个引用不能修改所绑定的 int 对象”,很对傻逼会用很有歧义的表述方式,说成成引用绑定的 int 对象不能改
int const &ref→ 同上
const T& ref和T const &ref本质是同一回事的两种写法,const int& ref = a中:
int:ref 引用的对象类型是整数。
const:修饰的是 “通过 ref 能做的操作”—— 禁止通过 ref 修改所引用的对象(无论对象本身是否 const)。
&:表示 ref 是引用,绑定到 a 的内存地址(与 a 共享同一块内存)。
不管是const int& ref还是int const& ref,都只能改引用绑定的对象本身(若对象非 const),不能通过ref这个引用修改绑定的对象。
Q:这里怎么看对象是不是const?
A:看引用绑定的 “源头对象” 是否带
const修饰,源头是const int就是 const 对象,源头是int就是非 const 对象。比如:
int a = 5; const int& ref = a;→ 源头a是非 const 对象,a本身能改(a=6合法),但不能通过ref改(ref=6非法)。因为const明确限制了 “通过这个引用修改对象” 的行为;
const int b = 5; const int& ref = b;→ 源头b是 const 对象,b本身不能改(b=6非法),通过ref也不能改)。核心就一条:
const T&是 “对T类型常量的引用”,作用是安全地绑定临时对象或常量(const int& ref = 10;),避免不必要的拷贝,且保证不能通过这个引用修改原对象。
const char* const &ref = p;中,T是const char* const(指向常量的常量指针),所以ref是 “对这种指针常量的引用”,特性和原指针完全绑定(都不能改)。const MyString& ref = 临时对象;中,T是MyString,所以ref是 “对MyString常量的引用”,专门用来延长临时对象的生命周期(否则临时对象会立即销毁),且不能通过ref修改这个MyString对象通用规律:const 类型&里的 “类型” 就是被引用对象的类型,const保证只读,&表示引用(不拷贝)。不管类型是基础类型、指针还是自定义类(如MyString),逻辑完全一致 —— 本质是 “给某个类型的对象起一个只读的别名”。引用必须在定义时就绑定一个对象,而且绑定后再也不能改成绑定其他对象。
const T&和T const &完全等价,const修饰的是 “T类型的对象”,只是书写顺序不同,但现在都是用const T&这个写法
const char* const &ref = p“对‘指向常量字符的常量指针’这个类型的引用”。核心规律:
const靠近谁就修饰谁,最终const T&的本质是 “引用本身不能改(引用天生不可改),且通过引用不能改被引用的T类型对象”—— 不管T是基础类型、指针还是自定义类,这个逻辑都不变。& 写法:
int &ref(& 贴变量名)、int& ref(& 贴类型)、int & ref(中间有空格)都合法,编译器不区分空格,都是给某个 int 类型的对象起别名 ref。T 是占位符,类似 %d。
引用的 const 修饰分两种,核心看 “是否允许通过引用修改所指对象”:
const 引用(绑定不可修改的对象):
const T&(T 是类型),例:const MyString& ref = 临时对象;。不能通过 ref 修改临时对象,且临时对象生命周期会被延长至与 ref 相同。引用的类型是
const MyString。即ref是一个指向const MyString类型对象的引用,绑定的临时对象类型为MyString(非 const),但通过const引用访问时,该对象被视为const MyString类型,无法通过此引用修改注意临时对象本身是非 const,const 引用(const MyString&)是给这个临时对象加了 “访问限制”,当你用
const MyString& ref绑定这个临时对象时,并不是把临时对象 “改成了 const 类型”,而是让 ref 这个引用只能以 “const 方式” 去访问它C++ 标准特意规定 “
const T&绑定临时对象时延长其生命周期”,就是为了让这个引用能安全使用。再比如
const char* const & ref是 “const引用”,引用的是一个const char* const类型的指针(指向const char的const指针)。因为是 “const引用”,可以绑定临时对象:而
const char* const p指针咋分析?指针是 const(不可改指向),char 也是 const,则指针指向的内容是 const(不可改内容) 合起来:指向 const char 的 const 指针
非 const 引用(只能绑定可修改的左值):
T&,例:MyString s; MyString& ref = s;。可通过 ref 修改对象,但不能绑定临时对象(临时对象是右值,不可被修改)。
const char*& ref是 “非 const 引用”,引用的是一个const char*类型的指针(即指向const char的指针)。不能绑定临时对象,能绑定的是 “const 引用”。字符串字面量转的临时指针就是临时对象。
"abc"是字符串字面量,类型为const char [4],会隐式转为const char*临时指针。
例:const char* const & ref = "abc";
这里 ref 绑定的就是这个临时指针(const char*类型,被const引用延长生命周期),不能const char* & ref = "abc";因为const char*&是非const引用不能绑定临时指针。看是否是
const不看&前是否加了const,因为&永远不加const,而是看const修饰的引用所关联的类型引用前加 const 才是 const 引用,比如
const int&、const char* const &,其余都是非 const 引用。“const 引用” 的本质是 “引用本身不能被用来修改它绑定的对象”
类比指针:
const T&类似 “const T* const”(既不能改指向,也不能改内容),但引用本身无 “指向” 概念,更简单:只是不能通过引用改对象。引用天生无法换绑,也不能通过引用改对象。
T&类似 “T*”(可改内容),即可以通过引用改对象,同样天生不能换绑。
练手:
情况 1:
const右边是*→ 修饰指针指向的内容(内容只读)例:
const int* p→p是指针,指向的int值不能改(*p = 10报错),但p可以改指向(p = &b合法)。
情况 2:
const右边是变量名 → 修饰指针本身(指针只读,不能改指向)例:
int* const p→p本身不能改指向(p = &b报错),但指向的int值可以改(*p = 10合法)。
情况 3:双重
const→ 指针和指向的内容都只读例:
const int* const p→ 既不能改p的指向,也不能改*p的值。
说几个心得,就是 const 不修饰 &,但修饰 *p 的时候,无论是 * 还是 p 都是指针,所以直接按照 const 最临近的这个准则就行。死妈玩意豆包翻来覆去最后我总结就是这个。
还有就是,const 是控制访问权限,也就是说修饰指针或者引用的时候,就按照是否能通过指针或者引用来就改数据就行,为了简便,可以直接当作是否可以修改源数据,只是由于数据是否能修改是源定义的,所以就加个,能否通过指针或者引用修改就行。
Java 没有指针,也没有 C++ 里
const修饰指针 / 引用的复杂规则,只有final关键字(类似 const,但用法更简单);单论语法细节(尤其指针、内存管理),C++ 自学难度确实远高于 Java,不是一个级别
拷贝构造:
当用左值(有名字、可被取地址的对象,如
MyString a("abc"); MyString b(a);中的a)初始化新对象时调用。会深拷贝资源(如重新分配内存并复制数据),确保原对象和新对象相互独立,开销较大。移动构造:
当用右值(临时对象、即将销毁的对象,如函数返回值、字面量)初始化新对象时调用。直接 “窃取” 原对象的资源(如指针赋值),原对象会被清空,开销极小。
懂了之前那句话:
MyString(const char* initStr)可以改成const char*&,但容易出错,因字符串字面量无法绑定到非 const 指针引用,为了这句话追问 3 天。此文搜“什么时候会调用?”那个代码,
return MyString("临时字符串");就是临时对象,因为匿名,所以这里他去匹配MyString(const char* initStr){的时候,如果是MyString(const char& haha) {,不行的理由是,只有const引用才可以绑定到临时对象,绑定指尝试与字符串字面量(类型为const char[4])建立关联,因字符串字面量可隐式转为const char*指针,与参数类型匹配。需要const char* const&才可以。
const修饰好char*整体,自然就相当于&是cosnt,但不是真给&加const。C++ 语法根本不允许给引用本身加 const—— 引用本质是 “变量的别名”,一旦绑定某个变量就不能再改绑其他对象,它的 “不可改绑” 是语法天生特性,不需要也没法用
const修饰。比如你写
int& const ref = a;会直接编译报错,因为语法不支持这种写法。我们平时说的 “const 引用”,都是指const int& ref(引用指向的对象是 const),而非 “引用本身是 const”。即只有能否通过引用修改原数据
操.你妈,花了3天搞懂这玩意,真的值得吗?!
迷茫,深似海,无力,遂问豆包,
Q:我想面试大厂 Linux C++ 服务端开发,现在纠结、钻研透彻这些有意义吗? 现在那么多现成的框架各种东西的
A:非常有!
大厂在面试 Linux C++ 服务端开发岗位时,通常会对 C++ 语言基础进行深入考察。例如,会询问 const 的作用、new 和 malloc 的区别。
深入掌握 C++ 底层知识可以帮助你更好地理解代码的执行机制和性能表现。
扎实的 C++ 底层知识是你在技术道路上不断发展的基石。随着技术的不断更新换代,新的框架和工具层出不穷,但 C++ 的底层原理是相对稳定的。拥有深厚的底层知识储备,能够让你更快地学习和掌握新技术,适应不同的开发场景和需求,为你的职业发展打下坚实的基础
行吧,继续熬!
最后一个知识点,强迫症研究代码底层逻辑
解释下此文搜“什么时候会调用?”那个代码(唯独解释的时候,临时对象初始化的是 c 不是 b,名字变了而已)
前言:
建立对象的时候,栈 / 堆上先开好内存,再用默认无参构造函数初始化这块内存里的对象。
从内存分配到对象生命周期,逐行拆解每一个底层细节:
1. 程序启动,进入 main () 函数,执行
MyString c(createString());
这行代码的目的:创建一个名为
c的MyString对象,初始化数据来自createString()函数的返回值。执行顺序:先调用
createString()函数,再用其返回值初始化c。2. 进入
createString()函数,执行return MyString("临时内容");2.1 执行
MyString("临时内容")—— 创建临时对象
调用构造函数:匹配到
MyString(const char* str)(我们自己定义的带参构造函数),传入参数"临时内容"(这是一个字符串字面量,存放在常量区,类型是const char*)。构造函数内部操作(堆内存分配):
strlen("临时内容"):计算字符串长度(6 个字符),加 1 是为了存放结束符\0,所以len=7。
data = new char[len];:在堆内存中分配 7 字节的连续空间,data指针(对象的成员变量)保存这段堆内存的首地址。
strcpy(data, "临时内容");:将常量区的"临时内容"复制到堆内存中(data指向的空间)。此时,一个
MyString对象已创建:它的data指针指向堆上的有效数据,但这个对象没有被任何变量名绑定(没有像MyString a(...)这样的声明),所以是临时对象(C++ 标准定义:未命名的对象即为临时对象)。2.2 执行
return—— 返回临时对象
临时对象被标记为 “即将离开当前作用域(
createString()函数)”,按照 C++ 规则,这种对象属于右值(只能出现在赋值号右边,不能被取地址)。函数返回时,临时对象不会被销毁(因为要作为返回值传递给
main函数),但它的生命周期仅限于 “传递给c的初始化过程”。3. 回到 main () 函数,用临时对象初始化
c——MyString c(...)
此时需要调用
c的构造函数,参数是createString()返回的临时对象(右值)。匹配构造函数:C++ 会优先选择参数为右值引用(
MyString&&)的构造函数,也就是我们定义的移动构造函数MyString(MyString&& other)。移动构造函数内部操作(资源转移):
data = other.data;:c的data指针直接指向临时对象在堆上的内存(地址复制,没有新分配堆内存)。
other.data = nullptr;:临时对象的data指针被置空(避免临时对象销毁时释放这段内存)。此时,
c已经拥有了堆上的"临时内容"数据,而临时对象的data变为空指针。4. 临时对象销毁
初始化
c的过程结束后,临时对象的使命完成,立即被销毁(触发析构函数~MyString())。析构函数执行:
if (data) delete[] data;,但临时对象的data已经是nullptr,所以不会释放任何内存(避免重复释放c正在使用的堆内存)。5. 程序结束,
c对象销毁
main()函数执行完毕,c对象离开作用域,触发析构函数~MyString()。此时
c.data指向堆上的"临时内容"内存,所以delete[] data;会释放这段堆内存(避免内存泄漏)。核心底层细节总结
临时对象的本质:未被变量名绑定的对象,由
MyString("临时内容")这种 “匿名创建” 方式产生,生命周期仅限于表达式执行期间。堆内存的归属:堆内存由带参构造函数分配,先属于临时对象,再通过移动构造函数 “转移” 给
c,最终由c的析构函数释放。- 移动的意义:全程只分配一次堆内存,没有复制数据(对比拷贝构造会重新分配堆内存并复制数据),效率极高。
每一步都是代码显式定义(构造函数、析构函数)和 C++ 语言规则(临时对象、右值、函数返回值处理)共同作用的结果,没有隐藏操作。这段解释,简简单单,但我有很多疑惑:
就是先
main调用,然后createString里去MyString搞个临时对象,同时在堆上开个同样数据的,不同内存空间,然后临时对象说白了就是过去让人家 copy 一下?
然后
main里又用他搞了个实际的初始化 c 对象,此时我理解临时对象立马就消失了?然后
mystring里好像和之前一样也是拷贝的功能?只是通过不同方式演示了 2 遍?而且
createString的时候已经堆上 copy 了一个数据了,再次 c 过去的时候又来了个?总共 2 个堆这个数据堆,都是临时?而且这里
~mystring啥时候起作用删除啥的?和堆的关系?质疑自己:
继续学吧:
1. 先纠正你的核心误解:不是 “拷贝数据”,是 “转移资源”,全程只在堆上分配 1 次内存!
你的理解里 “堆上开同样数据的不同空间”“copy 一下” 是错的 —— 这是拷贝构造的逻辑,而这里用的是移动构造,本质是 “抢资源” 不是 “拷贝数据”,堆内存只分配 1 次,具体流程再拆细:
第一步:createString () 里的 MyString ("临时内容")
调用带参构造,只在堆上分配 1 次 7 字节内存(存 “临时内容”),临时对象的
data指针指向这段堆内存(此时堆上只有 1 份数据)。
→ 这里没有任何 “拷贝”,是首次创建数据。
- 第二步:用临时对象初始化 c(移动构造)
移动构造里只做了两件事:
c.data = 临时对象.data:让c的data直接指向临时对象的堆内存(没有新分配堆内存,没有拷贝数据,只是指针赋值);
临时对象.data = nullptr:把临时对象的指针置空(避免它销毁时删堆内存)。→ 这里是 “资源转移”,不是 “拷贝”,堆上还是只有 1 份数据,只是归属从临时对象变成了
c。2. 临时对象啥时候消失?——“完成 c 的初始化后立即销毁”
临时对象的生命周期只到 “给 c 初始化完毕”:
当
MyString c(createString());这行代码里,移动构造执行完、c成功拿到堆内存归属后,临时对象就会触发析构函数(~MyString())。但此时临时对象的
data已经是nullptr了,所以析构函数里的if (data) delete[] data;会跳过释放(不会删堆内存),临时对象本身的内存(栈上的对象结构,不是堆上的数据)被回收 —— 相当于 “临时对象消失,但它手里的堆资源已经给 c 了”。3. ~MyString () 啥时候起作用?删的是啥?和堆的关系?
析构函数(
~MyString())的唯一作用:释放当前对象data指针指向的堆内存,避免内存泄漏,触发时机是 “对象离开作用域时”:
第一次触发:临时对象初始化完 c 后消失 → 但临时对象
data是nullptr,所以啥也没删;第二次触发:main 函数结束,
c离开作用域 →c.data指向堆上的 “临时内容”,所以delete[] data;会释放这段堆内存(这是唯一一次释放堆内存)。→ 堆内存的 “生命周期”:带参构造分配 → 移动构造转移归属 →c的析构释放,全程 1 次分配、1 次释放,没有重复分配或泄漏。4. 为什么不是 “演示 2 遍拷贝”?—— 拷贝和移动的本质区别
如果这里用的是拷贝构造(比如c用左值初始化),才会 “堆上有 2 份数据”:
拷贝构造会做
data = new char[len]; strcpy(data, other.data);→ 新分配堆内存,复制数据,此时堆上有 “临时对象的 data” 和 “c 的 data” 2 份相同数据;之后临时对象析构会删自己的堆内存,
c析构再删自己的堆内存 → 2 次分配、2 次释放,开销大。而你的代码用移动构造,全程 1 次堆分配,没有拷贝数据,这才是移动语义的核心价值 —— 不是 “重复拷贝”,而是 “高效转移资源”
createString ()里的MyString ("临时内容")”是栈上对象,不是堆上的。狗娘养的,这里相当多的细节!
首先“临时内容” 是字符串字面量,存放在常量区(既不是栈也不是堆);
而且,临时对象是
MyString类型的栈上对象,必然包含data成员(类定义强制所有对象都有);每个
MyString对象都有char* data这个指针成员。临时对象本身在栈上,栈上的临时对象
MyString("临时内容")的data指针(成员变量)指向堆上分配的 7 字节空间 —— 堆上存的是"临时内容"数据,栈上的临时对象只存了个 “指向堆数据的指针”,两者不是一回事,堆是新分配的,和临时对象的栈存储位置无关。传递的是临时对象本身(不是指针),但临时对象内部的
data成员会指向堆内存,不然不知道堆数据存哪里了什么鸡巴玩意,怎么栈的
data指向堆数据???听起来贼鸡巴离谱艹!但这里有个一直没被大众说我也一直没关注的细节!!调用带参构造时,先在堆上分配内存,再把常量区的 “临时内容” 复制到堆上,最后让临时对象的
data指向这块新分配的堆内存 —— 此时堆已经存在,data的指向是构造函数里显式操作的。再次重新捋顺就是:
关于【临时对象通过 data 指针 “持有” 堆上的数据】,埋个知识点,后面再说,真的感觉经过 7 天的追问煎熬,这块无比透彻了(妈逼的有行内代码还搜索不了)
1. 常量区:字符串字面量
"临时内容"的存放地
代码中
"临时内容"是字符串字面量,在程序编译时就会被存入常量区(一块只读内存,存放常量),类型是const char*,生命周期伴随整个程序运行期间。它是 “原始数据”,既不在栈也不在堆,只是一段固定的只读字符序列。
2. 进入
createString()函数,执行return MyString("临时内容");2.1 创建临时对象:
MyString("临时内容")
对象本身的位置:这个未命名的
MyString对象是栈上对象(函数内创建的局部对象,没被new分配,所以在栈上)。栈上立即创建临时MyString对象(生命周期:从创建到c初始化完成后销毁)调用带参构造函数
MyString(const char* str):
参数
str接收的是常量区"临时内容"的地址(const char*类型)。第一步:堆内存分配
int len = strlen(str) + 1;计算长度(7 字节),data = new char[len];在堆上分配 7 字节的可写内存(专门存字符串的副本)。生命周期:从new到c析构时delete。第二步:复制数据到堆
strcpy(data, str);把常量区的"临时内容"复制到刚分配的堆内存中(堆内存现在有了一份可修改的副本)。第三步:绑定指针到对象
栈上的临时对象有个成员变量
data(char*类型),此时data被赋值为堆内存的首地址(所以临时对象通过data指针 “持有” 堆上的数据)。此时状态:
常量区:原始
"临时内容"(只读)堆:复制的
"临时内容"(可写,被临时对象的data指向)栈:临时对象(含
data指针,指向堆内存)2.2 返回临时对象:
return语句
- 临时对象作为函数返回值,被标记为右值(即将销毁的无名对象),从
createString()函数的栈帧中 “传递” 到main函数。3. 回到
main()函数,初始化c:MyString c(createString());
用返回的临时对象(右值)初始化
c,调用移动构造函数MyString(MyString&& other):
other是临时对象的右值引用(代表临时对象本身)。
data = other.data;:c的data指针直接指向临时对象持有的堆内存(堆数据现在归c所有)。
other.data = nullptr;:临时对象的data被置空(失去对堆数据的所有权)。此时状态:
堆:
"临时内容"(现在被c的data指向)栈:
c对象(含data指针,指向堆内存)栈:临时对象(
data为nullptr,即将销毁)4. 临时对象销毁
初始化
c后,临时对象立即离开作用域,触发析构函数~MyString():
析构函数检查
data是否为nullptr(现在是),所以不释放任何堆内存。临时对象本身的栈内存被回收(消失)。
5. 程序结束,
c对象销毁
main()函数结束,c离开作用域,触发析构函数:
c.data指向堆上的"临时内容",所以delete[] data;释放这块堆内存(避免泄漏)。
c的栈内存被回收。流程是:
用栈上的匿名临时对象(含
data指针,指向堆数据),通过移动构造初始化栈上的c对象 —— 全程两个对象(临时对象和c)都在栈上,它们的data指针先后指向同一块堆数据(没有新堆内存)。细节链:
createString()里,栈上临时对象的data指向堆数据(堆数据诞生)。返回临时对象到
main,用它初始化c时:
移动构造让
c.data直接指向临时对象的堆数据(堆数据所有权转移)。临时对象的
data被置空(不再关联堆数据)。临时对象销毁(栈内存释放,
data已空,不影响堆)。
c在栈上存活,其data一直指向堆数据,直到c销毁时释放堆。核心:两个栈对象(临时对象和
c)通过data指针的 “接力”,共享同一块堆数据,没有新堆分配,只有所有权转移。总结:各内存区域的角色
内存区域 存放内容 生命周期 常量区 字符串字面量 "临时内容"(原始)整个程序运行期间 堆 复制的 "临时内容"(可写副本)从 new分配到delete释放栈 临时对象、 c对象(含data指针)所在函数作用域内 再继续深入抽插 —— 关于生存周期:
常量区的
"临时内容"从程序启动就存在,直到程序结束才消失 —— 它是整个流程的 “原始数据源头”。当执行
MyString("临时内容")时,栈上创建临时对象(MyString类型,自带data成员),这个操作会调用带参构造函数:把常量区的"临时内容"复制到新分配的堆内存,然后让临时对象的data指向这块堆内存(data的值就是堆内存地址,此时创建并赋值)。接着返回临时对象到
main,用它初始化c时,移动构造让c的data直接接过临时对象的data值(堆内存地址),同时临时对象的data被置空。之后临时对象销毁(栈内存释放,其
data已为nullptr,不影响堆),c的data始终指向堆上的副本,直到main结束,c的析构函数释放这块堆内存。整个串联流程:常量区原始数据 → 堆副本(被临时对象
data指向) → 堆副本所有权转移给c的data→ 堆副本最终被c释放。常量区数据全程只是被复制一次,之后再无作用经过豆包肯定的理解:
先是常量区的数据启动开始有,然后
MyString("临时内容");就去类里匹配MyString(const char* str),执行
MyString("临时内容")时,栈上立即创建临时对象(含data成员),把常量区的"临时内容"复制到新分配的堆内存,然后让临时对象的
data指向这块堆内存(data的值就是堆内存地址,此时创建并赋值)。栈上的
data指向了人家堆上的数据?感觉像分家了一样?但本来就是这样,栈上的对象(含
data指针)和堆上的数据本就分离,data的作用就是连接二者 —— 让栈对象 “管理” 堆数据,这是 C++ 手动管理内存的典型方式(栈存对象结构,堆存大块数据)只是平时没单独拎出来强调过,比如你常用的
std::string底层就是这么实现的:
std::string s = "hello";
s这个对象(含指针、长度等成员)存在栈上;"hello" 的实际字符数据,存在
std::string内部通过new分配的堆内存里;
s里的指针(类似你写的data),就指向堆上的字符数据。
"hello"本身是常量区的字符串字面量,但std::string s = "hello";执行时,会把常量区 "hello" 的内容复制一份到堆内存,s内部的指针指向的是堆上的这份复制数据(不是常量区的原始数据)—— 和你代码里带参构造 “复制常量区内容到堆,让 data 指向堆” 的逻辑完全一致本质是因为栈内存小且自动释放,适合存 “管理信息”(对象、指针、长度);堆内存大且手动控制,适合存 “大块实际数据”(比如长字符串、数组)—— 用栈上的指针关联二者,既能灵活用堆内存,又能靠栈对象的析构自动释放堆内存(避免内存泄漏),是 C++ 里非常基础且常用的内存管理模式。
打开了新世界的大门!
小母牛到南极 —— 牛逼到了极点!
母牛屁股挂鞭炮 —— 牛逼到爆!
牛逼他妈给牛逼开门 —— 牛逼到家了!
再继续说点知识:都是也不知道有没有用,但就是好奇 + 一根筋强迫症问出来的!就算不重要,现在懂了也感觉对整个涉及到:类、指针,这些起初觉得相当烦人的逼玩意,有了相当透彻的理解,非常精通了,直接吊打拷打面试官咔咔乱杀!!
那个“hello”的语句,如果想让
string对象在堆上,需要用new:
std::string* s = new std::string("hello");
s(指针)在栈上,指向堆上的string对象;该堆上
string对象的内部指针,仍指向另一块堆内存(存 "hello" 数据)。释放时需显式
delete s;(先析构堆上string对象,释放其管理的字符数据堆内存,再释放string对象自身的堆内存)。疑惑:
继续深入抽插:
继续说
Mystring那个,我理解一般都是栈上的指针指向堆地址,这里栈不是临时的对象吗?这么弄不会堆还在而栈数据没了吗?关键在 “对象生命周期” 与 “资源所有权” 的绑定:
栈上的临时对象虽然会销毁,但在销毁前,它的
data指针指向的堆内存会被转移给其他对象(比如移动构造给c),此时堆内存的所有权已移交,临时对象的data会被置空。当临时对象(栈)销毁时,因其
data已空,析构函数不会释放堆内存;而接收所有权的对象(如c)会在自己生命周期结束时,用析构函数释放堆内存 —— 这就是 “栈对象暂管,所有权转移” 的设计,确保堆内存不会因栈对象消失而失控。继续:
临时对象在完成对c的初始化后,就会立即离开它的作用域(函数返回后的临时对象生命周期到此结束),此时会触发它的析构函数。由于之前移动构造已经把它的
data置为nullptr,析构函数里的if (data != nullptr)判断会失效,不会任何堆内存操作,只是临时对象自身在栈上的内存被系统自动回收(彻底消失),整个过程不会影响c所管理的堆数据。移动构造函数的参数
other,是对那个栈上临时对象的右值引用(可以理解为 “临时对象的别名”)。执行移动构造时:
c.data = other.data;→c的data指针,直接复制了临时对象other的data值(也就是堆内存的地址)。此时,c的data和临时对象的data指向指向向同一块堆内存。
other.data = nullptr;→ 临时对象的data被清空,彻底放弃对堆内存的所有权。所以:
c有自己的data(新对象自带的成员),但它的值(指向的堆地址)来自临时对象的data。堆数据自始至终只有一块,只是从临时对象的
data“过户” 给了c的data。我觉得这玩意有点像自己精通的递归 和 深索算法:
再继续深入抽插:
这里只有 1 个堆空间,2 个栈对象(匿名临时对象、c),每个栈对象都有自己的 data 指针,且析构函数(
~MyString())的执行时机完全跟 “栈对象的生命周期结束” 绑定。
类型 数量 关键信息 堆空间 1 个 从匿名临时对象在 createString()里创建时分配(比如通过构造函数new char[]),全程唯一。栈对象 2 个 ① 匿名临时对象(在 createString()里创建,栈上);②c(在main里创建,栈上)。data 指针 2 个 每个栈对象自带 1 个(类的私有成员):① 匿名临时对象的 data;②c的data。析构函数(
~MyString())啥时候执行?—— 跟 “栈对象生命周期结束” 强绑定C++ 里栈对象的生命周期遵循 “出作用域即销毁”,而销毁时会自动调用析构函数(~MyString()),具体分两次执行
第一次执行:匿名临时对象的析构
时机:匿名临时对象完成对
c的初始化后,立即 “出作用域”(它的使命就是传递堆所有权,任务完成后就会消失)。过程:调用匿名临时对象的
~MyString(),但因为之前移动构造已经把它的data置为nullptr,析构函数里的 “释放堆内存” 逻辑(比如if(data) delete[] data;)会跳过,只回收它自身在栈上的内存(比如data指针占用的 4/8 字节),堆空间不受影响。第二次执行:
c的析构
时机:
c所在的作用域结束时(比如main函数执行完return 0,或者c定义在某个局部块里,块执行完)。过程:调用
c的~MyString(),此时c的data指向唯一的堆空间(非nullptr),析构函数会执行 “释放堆内存” 的逻辑(delete[] data;),彻底回收堆空间,同时c自身在栈上的内存也被回收总结
两个栈对象(匿名临时、
c)的~MyString()会分别在各自生命周期结束时自动执行,且顺序是 “匿名临时对象先析构,c后析构”。析构函数的核心作用是 “清理堆资源”,但匿名临时对象因为已放弃堆所有权(
data=nullptr),析构时只做 “栈上自清理”,真正的堆清理靠c的析构完成。
以上写的看不懂,继续追问:
堆上没有
data指针,data指针只存在于栈上的对象中,
MyString(const char* str):在堆上创建字符数据,让当前栈对象的data指向它(堆数据诞生)。
MyString(MyString&& other):让当前栈对象的data直接指向other(临时对象)的堆数据,other.data置空(堆数据所有权转移)。
用文字描述内存布局变化(从上到下为内存地址增长方向):
步骤 1:程序启动,常量区存在字符串字面量
【常量区】 地址0x1000: "临时内容"(字符数组,生命周期至程序结束)【栈】(此时未执行createString,栈为空) 【堆】(空)步骤 2:调用 createString (),创建匿名临时对象
进入函数,栈上分配临时对象内存(含 data 成员)
调用构造函数
MyString(const char* str):在堆上分配内存存 "临时内容" 的拷贝【常量区】 地址0x1000: "临时内容"【栈(createString函数栈帧)】 地址0x7000: 匿名临时对象 {data: 0x2000 // 指向堆内存 }【堆】 地址0x2000: "临时内容"(拷贝自常量区,由new分配)步骤 3:返回临时对象,通过移动构造初始化 c
临时对象作为右值返回,触发
MyString(MyString&& other)
c在 main 函数栈上创建,其 data 接过临时对象的堆地址临时对象的 data 被置空
【常量区】 地址0x1000: "临时内容"【栈(createString栈帧)】 地址0x7000: 匿名临时对象 {data: nullptr // 已放弃所有权 }【栈(main函数栈帧)】 地址0x8000: c对象 {data: 0x2000 // 接管堆内存地址 }【堆】 地址0x2000: "临时内容"(现在由c的data指向)步骤 4:临时对象出作用域,触发析构
createString 函数返回后,其栈帧销毁,临时对象被析构
因临时对象 data 为 nullptr,析构函数不操作堆内存
【常量区】 地址0x1000: "临时内容"【栈(createString栈帧已销毁)】 (原0x7000位置的临时对象内存被释放)【栈(main函数栈帧)】 地址0x8000: c对象 {data: 0x2000 }【堆】 地址0x2000: "临时内容"(仍存在)步骤 5:main 函数结束,c 出作用域,触发析构
c 的析构函数执行,通过 data(0x2000)释放堆内存
c 的栈内存被释放
【常量区】 地址0x1000: "临时内容"【栈(main栈帧已销毁)】 (原0x8000位置的c对象内存被释放)【堆】 (原0x2000位置的内存被delete释放,堆为空)核心结论:
data指针始终在栈对象(临时对象、c)中,堆上只有被指向的字符数据堆数据通过
data的赋值实现所有权从临时对象到 c 的转移析构函数仅在栈对象销毁时执行,且只释放当前
data指向的堆内存(避免重复释放)如果移动构造时不把临时对象的
data置空,// 漏写:other.data = nullptr;,会导致同一块堆内存被释放两次,这是严重的内存错误 。此时的执行流程(必出问题)
临时对象和
c的data指向同一块堆内存:移动构造后,临时对象的data和c的data都指向堆地址0x2000(同一块内存)。临时对象先析构:临时对象出作用域时,析构函数检测到
data != nullptr(因为没置空),执行delete[] 0x2000—— 堆内存被释放。
c析构时再次释放:main函数结束,c析构时,c.data仍指向0x2000(已被释放的堆地址),析构函数再次执行delete[] 0x2000。因为一块堆内存只能被
delete一次,重复释放会导致内存管理器状态混乱!可是析构不就没了吗?咋还会有问题呢?
临时对象先析构释放堆内存,此时
c.data成野指针;c析构时再次释放已失效的堆地址,触发重复释放错误(致命)。核心:堆内存地址不会因释放消失,两个对象的data仍持有该地址,导致二次释放。若只对堆内存析构(释放)一次,且释放后不再通过任何指针访问该堆地址,就不会产生野指针问题;但关键是要确保所有持有该堆地址的指针,在释放后要么不再使用,要么被设为
nullptr(避免后续误操作)。如果第二次析构,代码仍会执行
delete[] data,本质就是拿着这个指针(此时已指向被释放过的 “无效堆地址”),再次去尝试释放这块早就不属于它的内存 —— 这就是重复释放错误。如果说置为空意思就是不去找了。
最后说下析构:回应之前埋知识点,此文搜“后面再讲解析构”
new是堆,但始终没人提及的是,“用new分配的数据,会被一个栈上(或其他已存在内存区域)的指针指向来管理”比如写
int* p = new int(10);:new在堆开了存10的空间,同时把堆地址存到栈上的指针p里;后续你用delete p回收,本质就是通过这个栈上的p找到堆地址。这里
p存储在栈上。delete p仅释放p指向的堆内存,栈上的指针变量p会在其作用域结束时(如函数返回)自动销毁。C++ 中管理动态内存的典型方式,在大厂 Linux C++ 服务端开发中非常常见:
对象本身(如
b)在栈上创建,避免堆内存管理开销成员变量
data指向堆上的实际数据,实现动态大小存储通过拷贝构造、移动构造和析构函数控制资源所有权,符合 RAII 思想:
用 “对象生命周期” 管 “资源”,对象创建时拿资源,对象销毁(离开作用域)时自动还资源,不用手动管
相比单独用
*p指向堆数据,更符合面向对象设计,尤其适合自定义数据类型(如字符串、容器等)的实现,且这种封装方式更安全避免内存泄漏:
析构函数自动回收:对象在栈上,作用域结束时会自动调用析构函数,析构函数里的
delete[] data会强制释放堆内存;而单独用*p时,得手动写delete,漏写就泄漏。RAII 自动管理:堆内存(
data指向的)的生命周期和栈对象(如b)绑定,对象销毁则内存必回收;*p的堆内存和指针生命周期脱节,指针丢了(如提前 return、异常),堆内存就找不回了反观
*p必须用delete(单对象)或delete[](数组)手动释放,例如:int* p = new int; // 堆上分配单个int delete p; // 手动回收char* str = new char[10]; // 堆上分配数组 delete[] str; // 手动回收数组必须严格匹配
new/delete和new[]/delete[],且确保只释放一次,否则会导致未定义行为。一直误以为
delete p是回收p,p不需要手动回收,p是栈上的指针变量,它的生命周期和所在作用域绑定,由编译器自动处理。所以其实发现:
单独的
*p:
delete p全靠手动写,漏就泄漏直到程序完全退出时,操作系统才会强制回收。但长期运行的程序(如服务器)中,这种未释放的堆内存会越积越多,导致内存耗尽(内存泄漏)。对象的析构函数:
会自动调用,而你在析构函数里写死了
delete[] data—— 只要对象销毁(比如出作用域),编译器就会强制执行这行代码,管你忘没忘。那为何说这么写安全?
栈对象:离开作用域(如函数返回、代码块结束)时自动销毁,析构函数自动执行,堆内存必释放。
堆对象:用
delete销毁时,析构函数也会自动调用。只要正确使用delete(这比单独管理*p的delete更集中),就不会漏。所以忘记写析构函数也不行,但继续分析:
如果没写析构函数,编译器会生成默认析构函数,但默认析构函数不会自动释放成员指针指向的堆内存(比如
data指向的空间),会导致内存泄漏。必须显式定义析构函数并在其中写
delete[] data,才能确保堆内存被释放。补充:
关键在 C++ 的
delete规则:
当
data指向有效堆内存(非nullptr)时,delete[] data会正确释放这块内存;当
data是nullptr时,delete[] data什么都不做(标准明确规定,安全无副作用)。在你的代码中:
移动构造后,临时对象的
data被设为nullptr;临时对象析构时执行
delete[] data,实际就是delete[] nullptr,等同于不释放任何内存;最终
b的data指向有效堆内存,析构时delete[] data会正确释放。所以即使析构函数没写
if (data != nullptr)判断,也能达到 “只释放有效内存” 的效果,这是 C++ 标准保证的。进一步抽插就是:
查看代码
//写法一、补充析构函数释放内存 ~MyString() {delete[] data; }//写法二、补充析构函数释放内存 ~MyString() {if (data != nullptr)delete[] data; }以上两种写法完全等价!
delete[] data;直接释放:标准规定delete[] nullptr是安全的(啥也不做),所以即使data是nullptr,也不会出问题。安全核心就是“调用了也不会崩溃、不会出异常”,程序能正常跑,没有副作用——这就是它“安全”的关键。
加
if (data != nullptr)判断后释放:只是显式检查了data是否有效,逻辑上更直观,但实际执行结果和第一种写法完全相同。对于代码中的
~MyString() { delete[] data; }:当data为空指针时,delete[] data会执行,但标准规定这等价于 “什么都不做”(不释放任何内存),不会执行实际的删除操作。整个析构函数体仍会执行,只是delete[]这一行无实际效果,没有其他隐含的delete操作。“不释放任何内存” 说法有歧义,准确是 “不释放
data指向的堆内存”,但临时对象自身(含data指针变量)的内存会正常释放。临时对象本身(包括其
data指针变量)的内存:在析构完成后,会被正常释放(堆对象的内存由delete触发释放,临时对象由编译器自动管理释放)。data指针变量作为对象成员,随对象销毁而释放,data值有没有都如此。堆对象的析构的是外部的,堆对象自己释放的是所有自己的东西!
而栈释放的都是自己的东西,
delete堆对象比栈对象多释放了个手写的指向的数据。
自动生成的默认析构函数就类似
~MyString() {}(空函数体),仅负责销毁对象自身及非指针成员的内存,不会对data指向的堆内存做任何处理。data指针本身是对象的成员变量,存储在对象所在的内存中(栈或堆):
若对象在栈上(如
MyString b;):对象销毁时,栈内存会自动回收,data指针本身占用的 4/8 字节(指针大小)会被栈自动释放,无需手动处理。若对象在堆上(如
new MyString;):执行delete时,先调用析构函数,再由delete释放对象自身的堆内存(包括data指针本身)。
data指针本身的内存由对象的存储位置(栈 / 堆)决定释放方式,与delete[] data无关。delete[] data仅释放指针指向的堆内存,而指针本身的内存会随对象一起被自动回收,不存在泄漏
再说“手写析构函数” 和 “自动调用析构” 是两回事:
析构函数的 “有无”:你手写
~MyString(),是定义了 “对象销毁时要执行的操作”(释放堆内存);若不手写,编译器会生成默认析构(但默认析构不释放堆内存,会泄漏)。析构函数的 “调用时机”:无论析构是手写还是默认的,栈上对象离开作用域时、堆上对象被
delete时,编译器 / 系统都会自动触发调用析构函数 —— 你不用手动写b.~MyString(),这就是 “自动析构”。简单说:你手写的是 “析构要做什么”,而 “什么时候调用析构” 是 C++ 自动管的。
data作为指针变量本身(占 4/8 字节),属于对象自身的内存,默认析构会随对象一起释放(不管指针是否指向堆);不释放的是
data指向的堆空间(即new出来的内存)
class MyString { private:char* data; // 指针,指向堆内存(默认析构不处理)int length; // 普通int成员(在对象内部,随对象一起存储) public:MyString(const char* s) {length = strlen(s);data = new char[length + 1]; // 堆上分配内存strcpy(data, s);}// 不手写析构函数,编译器生成默认析构 };当这个类的对象(比如栈上的
MyString a("test"))离开作用域时,默认析构会做:
销毁
length:因为length是普通 int,它的内存随对象在栈上,对象销毁时栈内存会自动回收,默认析构会 “清理” 这个成员(其实就是栈内存释放)。销毁对象
a自身:a作为栈上的对象,离开作用域时栈会自动回收它的内存(比如对象占用的 “指针 data+int length” 的总字节数)
data是一个指针,它指向堆上new出来的字符数组("test"的存储位置)。默认析构只会销毁 “指针data本身”(比如data这个指针变量的栈内存回收),但完全不会调用delete[] data去释放它指向的堆内存。这就会导致 “内存泄漏”
这是栈对象,那如果是堆的对象呢?
先捋顺下,我对栈的析构的理解,经过豆包肯定:
栈上对象是离开作用域自动触发,这里说是自动触发, 但其实触发的是析构函数,你如果没写,会自动生默认析构,但默认析构无法析构栈里
new的堆数据,如果写了删除堆数据才算正常释放,完美的自动析构。这里析构是离开作用域自动发生的,而发生时调用的析构函数是有自己写的和自动生的之分。再说堆:
刚才提到的是栈里
new的对数据,怎么栈里还有堆?其实只要创建时候带new都是建在堆上,那回收就不是自动回收了,需要手动delete释放,而这里手动delete之后,调用的析构也有自动生的默认析构和手动写的析构两种,和上面一样。
delete[] data是 C++ 中释放用new[]分配的堆内存数组的操作,与new[]配对使用,专门用于释放动态数组(如代码中存储字符串的char数组)。delete与new配套。如果是
new的对象haha,那么写delete haha是调用析构,析构还需要手写个释放haha的语句,释放其内部堆内存,如data指向的数组,然后最后释放haha自身占用的堆内存。
栈对象里的指针都是指向堆数据:
虽然也可以指向栈对象,但一般不推荐,因为若栈指针指向了其他栈对象,当被指向的栈对象先于指针销毁时,即便指针后续也会销毁,但在指针销毁前,它指向的内存已无效,此时访问该指针就是野指针操作,可能导致程序错误。
而栈对象里的指针,指向自己的栈数据也不好,因为栈内存遵循 “后进先出” 规则,销毁顺序和创建顺序相反,并非所有栈里的东西都 “一起” 销毁。
比如函数内先定义变量 A(先入栈),再定义变量 B(后入栈),函数结束时会先销毁 B、再销毁 A;若栈对象的指针指向更早创建的栈变量(如 A),当 A 先被销毁后,指针就会变成野指针 —— 这就是即使都在栈上,也可能出现野指针的原因。
堆对象里的指针指向堆对象自己new的数据没问题
因为手动管理,不会野指针
之前那个代码里
data指针随对象b和临时对象的销毁(离开作用域)而消失。手写的析构函数,就比默认析构多一个删指针指向的堆数据。析构说白了就是删除外部数据用的。
临时对象的析构:
createString()返回的临时对象在初始化b后销毁,此时其data已被移动构造设为nullptr,析构时delete[] data实际不操作(因delete[] nullptr无效果)。对象
b的析构:main()函数结束时,b离开作用域,其data指向堆中有效的字符串内存,析构函数执行delete[] data,释放这块堆内存。只有
b的析构真正释放了data指向的堆内存,临时对象的析构因data为nullptr未做实际释放。之前那段代码,
b离开作用域指的就是代码结束,对这个代码而言,不写析构函数看似能运行(程序结束后操作系统会回收内存),但在服务器等长时间运行的程序中,若频繁创建类似b的对象,未释放的堆内存会持续累积,最终导致内存泄漏。
栈对象:离开作用域(如函数结束)就自动析构,不用手动操作。
堆对象:只有显式写
delete才会触发析构,程序结束时操作系统会回收堆内存,但不会调用析构函数(可能导致资源泄漏Q:我感觉堆不写也行啊!
A:
堆不写
delete,程序结束时操作系统会回收内存,但这和栈的 “自动析构” 完全不是一回事 —— 堆不触发析构函数,若析构里有释放文件句柄、网络连接等操作,这些资源会泄漏(程序关了才回收,期间一直占着)。而栈对象离开作用域就触发析构,资源即时释放,不用等程序结束。“离开作用域” 不是只指程序结束!比如函数里的栈变量,函数执行完就销毁;if/for 块里的栈变量,块结束就销毁 —— 这就是 “提前销毁”,比程序结束早得多,能避免资源长时间占用。
再比如打开的文件没关,其他程序没法读写:栈主动释放,但如果栈用文件描述符此时开状态,别人再用就不行。而堆不
delete就整个程序别人都没法用,但只要delete就别人可以用。但堆和栈自动回收后,打开的描述符都会正常关。
堆不写
delete就不会触发析构,哪怕写了析构。堆写
delete:先调用析构释放指针指向的资源,再释放对象自身占用的堆内存。以上都是对象,如果是变量,无 “
delete直接删变量” 的说法,delete仅用于释放动态内存,变量内存由其存储区域(栈 / 全局区)自动管理)
用
new创建的对象:
指针成员(如
data)指向的内存 → 堆资源(需delete[]释放);对象自身(包括
data指针变量) → 堆资源(需delete释放)。两者都是堆上的资源,需配合析构和
delete分层次释放。
这里的核心是 “指针变量本身” 和 “指针指向的堆数据” 的区别 ,
假设定义了一个类A,内部有个指针成员int* p;然后用new A在堆上创建一个对象a(a自身在堆上)。
“指针变量本身(
a.p)” 的内存:a.p是对象a的一个成员,它的内存是包含在对象a的堆内存里的(就像对象里的int成员一样,属于对象自身的一部分)。当你delete a(删除对象a)时,对象a自身的堆内存会被释放 —— 这其中就包括了a.p这个指针变量的内存(指针变量本身消失了)。“指针指向的堆数据(
a.p指向的内容)”:如果之前给a.p分配了堆内存(比如a.p = new int(10)),那么a.p指向的这部分堆数据,不属于对象a自身的内存。
若你没在
A的析构函数里写delete a.p:delete a只会释放对象a自身(包括a.p变量),但a.p指向的int堆数据没被释放,就会内存泄漏。- 若你在析构函数里写了
delete a.p:delete a时会先调用析构,释放a.p指向的堆数据,再释放对象a自身(包括a.p变量),无泄漏。简单说:指针变量本身(作为对象成员),会随对象的销毁而释放;但指针指向的独立堆数据,必须在析构里显式
delete才会释放,否则泄漏释放对象自身内存,是
delete的工作,而非析构函数的工作。
很多大众的傻逼解释真的是给傻逼看的,像我这种必须钻研自己开路,很多东西傻逼都了解的不透彻
大模型的牛逼之处就在于配合,互相启发,互相成就,无论之前新疆AI宣传片(启发思路)还是现在学东西(给我讲会了我再给他纠正)
再说下,
主要是豆包太傻逼了,很多都是引起歧义的话,但之前半懂不懂的也都写到博客里了,如今追问质疑后,精通透彻了,重新写出来。
delete[] data无操作指不释放指向内存,但data变量随对象销毁释放Q:到底是先释放析构包括各种变量,然后释放堆自身内存吗?
A:先执行析构函数释放资源,再释放对象自身占用的堆内存。堆对象自身与其指向的堆数据是关联但分离的内存块
Q:可我感觉“
data变量随对象销毁释放”和“先执行析构函数释放资源,再释放对象自身占用的堆内存”矛盾啊A:析构函数释放的是对象关联的外部资源(如
data指向的堆内存),对象自身内存(含data变量)是析构后由编译器 /delete释放”—— 二者是两回事。
data变量是对象自身的一部分,不随析构函数释放,而是随对象自身内存销毁而释放;析构函数释放的是data指向的外部堆数据,不是data变量本身。析构释放的 “资源” 和对象本身内存完全分开:前者是对象 “管理的外部东西”,后者是对象 “自己占用的空间”。
堆和栈只是逻辑上分成的不同位置,赋予不同的管理方式。
堆对象本身(含
data指针)比如在 0x001 等堆地址,data 指针又指向另一块堆内存(存储字符串数据)。堆对象的内存是一整块连续空间,其成员变量(包括data指针本身)都存储在这块空间中,开多大就是对应类那么大, 然后里面存自己的成员。new 创建的堆对象地址需用指针接收,如
MyString* p = new MyString("..."),否则会丢失地址无法释放。对象内用
new分配的内存(如data指向的字符串),也需用指针(即 data 成员)接收其地址,否则会内存泄漏。指针本身的存储位置(堆 / 栈)与它指向的数据位置(堆)是两回事:
栈上的指针(如栈对象的
data成员)→ 指向堆数据;堆上的指针(如堆对象的
data成员)→ 也指向堆数据。指针在哪(栈 / 堆)由其定义位置决定,而它们几乎都指向堆中动态分配的数据。
程序结束时,操作系统会强制回收所有资源(包括未关闭的文件、网络连接等),但这是 “暴力回收”。
区别在于:
栈对象:离开作用域时主动调用析构函数,按程序逻辑正常关闭文件(比如刷新缓存、写结束标记),是 “优雅释放”。
堆对象不写 delete:不调用析构函数,文件可能没正常关闭(比如缓存数据丢失),直到程序结束被操作系统 “硬拔”,有数据风险。
栈是 “及时且优雅”,堆不处理是 “拖延且粗暴”。
Java 的 new 不需要手动释放,有垃圾回收自动处理;C++ 的 new 必须手动 delete,否则内存泄漏。
delete空指针(包括nullptr)时,什么都不做 —— 既不删除任何内存,也不影响指针变量本身(指针变量仍存在,值还是空)。而如果非空才会释放指针的指向,但无论是否空,都要由
delete触发析构,而且无论是否空,指针都会随堆对象消失。当堆对象里的指针为空,delete该对象触发析构后:
若析构函数里写了
delete[] 空指针,因delete空指针安全,此操作无实际效果;析构执行完后,
delete会继续释放堆对象自身内存(包括这个空指针成员),对象及内部指针成员均消失
至此析构分析结束!
(这逼玩意挺绕的,但反复追问还是能精通相当透彻的,就看有没有钻研细心精神,我追问了 7 天,又写博客写了 4 天)
(豆包用阳寿回答问题,很多东西都不准确!需要反复推敲、质疑、追问、梳理总结后用自己的语言组织好发给他,才能得到最权威的回答,才能写出最权威的博客)
再分析下指针地址这个东西,
此文搜“【临时对象通过 data 指针 “持有” 堆上的数据】”:
我之前讨论的那个代码,
data指向堆上分配的字符串数据后,被有效使用了:
在
print()成员函数中,通过cout << data << endl;输出了data指向的堆内存中的字符串内容;拷贝构造函数中,通过
strcpy(data, other.data);复制了另一个对象的data所指向的堆内存中的字符串内容。对于
char*类型的指针,cout << 指针会自动输出该指针指向的字符串内容(从首地址开始,直到遇到'\0'结束符),而不是输出指针本身的地址。而如果是基础类型(如int*)按类型字节数(4/8 字节)读取;字符串(char*)默认以'\0'作为结束标志确定长度。这是cout对 C 风格字符串(字符数组)的特殊处理。如果想输出指针的首地址,需要强制转换为
void*,例如:cout << (void*)data << endl;。比如指针
*p是指向的0x0010地址,这个地址存的是“abc”,cout p是输出abc,cout << (void*)p << endl;是输出0x0010。在计算机中,通常将一个字节定义为最小的可寻址内存单位,所以可以理解为一个内存块(最小可寻址单位)就是一个字节。
指针本身是一个变量,在 32 位系统占 4 字节,64 位系统占 8 字节,存储的是唯一的首地址(指向对象的起始位置)。
这里之前以为懂了,现在发现还是不懂,深入抽插后彻底通透精通了,开始深入抽插,关于指针根据指向找数据:
32 位系统 + 小端序(主流 CPU 存储规则,低字节存低地址)
指针变量
p(指向字符串 “abc”),自身的存储地址是0x0010(即p占0x0010、0x0011、0x0012、0x0013这 4 个连续字节);字符串 “abc” 的实际存储首地址是
0x0020(“a” 在0x0020,“b” 在0x0021,“c” 在0x0022,\0在0x0023)。第一步:明确
0x0020的 32 位完整表示(关键纠错点)
0x0020是 16 进制地址,但在 32 位系统中,地址必须用 32 位(4 字节)完整表示,所以0x0020的 32 位 16 进制完整写法是0x00000020(前面补两个 0,凑够 8 位 16 进制,对应 4 字节)。其 32 位二进制为:
0000 0000 0000 0000 0000 0000 0010 0000。第二步:拆分
0x00000020为 4 个字节(小端序存储到p的 4 个地址)32 位地址
0x00000020拆分为 4 个独立字节(1 个 16 进制位占 4bit,2 个 16 进制位占 1 字节):
最高字节(左数第 1-2 位 16 进制):
00(对应二进制0000 0000);次高字节(左数第 3-4 位 16 进制):
00(对应二进制0000 0000);次低字节(左数第 5-6 位 16 进制):
00(对应二进制0000 0000);最低字节(左数第 7-8 位 16 进制):
20(对应二进制0010 0000)。根据 小端序(低字节存低地址),这 4 个字节要按 “最低字节→最高字节” 的顺序,存到
p的 4 个存储地址(0x0010是最低地址,0x0013是最高地址):
指针 p自身的存储地址(低→高)存储的字节(对应 0x00000020的字节拆分)该字节的 16 进制 0x0010(最低地址)最低字节( 0x00000020的最后 2 位 16 进制)200x0011次低字节( 0x00000020的中间左 2 位 16 进制)000x0012次高字节( 0x00000020的中间右 2 位 16 进制)000x0013(最高地址)最高字节( 0x00000020的前 2 位 16 进制)00第三步:CPU 使用
p时的正确逻辑(无错误)当执行
cout << p(读取p指向的 “abc”),CPU 会做 3 件事:
找到
p自身的存储地址:确定p存在0x0010~0x0013这 4 个字节;读取并组合字节:按小端序规则,将
0x0010的20、0x0011的00、0x0012的00、0x0013的00组合成完整地址0x00000020(即0x0020);访问目标地址:去
0x0020开始的地址读取数据,依次拿到 “a”“b”“c”“\0”,最终输出 “abc”。所以这就是根据首地址找数据。这个例子是 4 对 4,很容易误导,其实无论数据几个字节,指针都是固定字节。然后指针的字节拼凑的的地址是数据首地址。
hex是十六进制
32 位地址是 8 位十六进制(如 0x00000001),可简写为 0x1(省略前导 0)。也不知道哪个傻逼总写 4 位 ,导致全网傻逼都跟着学,导致我一度以为就是 0x0001这种,导致看不懂正确的!
顺序写的,没回顾,所以有重复的,等回顾再精简吧。懂了之后发现很简单,搞了这么长,唉,~~~~(>_<)~~~~回头再缩减吧,妈逼的不知道是不是脑子学傻了
好痛苦啊,每个小节都要追问 2 天,这里面知识像乱麻一样,一句话就有无数个问题,每个问题又有无数个小问题,唉~~~~(>_<)~~~~
博客园的TinyMCE5编译器真他妈是用阳寿开发的!!艹bug一屁眼子!!段落、格式,真的疯了崩溃了!!!!!!插入代码保存后就大概率跳到文章最开头,死妈玩意!
再回顾豆包的追问历史写博客 2 天,但只要学啥基本精通啥!!搞懂类了。
但追问完,真的清清爽爽,相当精通透彻!!
吃饭看到 公众号 (乌烟瘴气心灰意冷、一无是处穷途末路) + 昨天经历的熬夜3天做的商业护肤品AI广告视频,到给报酬的日子,结果是个骗子。
与公斗,不如与己斗。
撑不下去的时候就看罗斯、黄国平中科院博士论文致谢
待逐步更新,因为这是开始学的时候,追问完一堆,扒拉豆包最上面的记录,页面高达1G,开始整理的,日后反复读,逐步精简。边追问学边精简写肯定效率低,问题太多了。
Q:你说我想面试大厂LinuxC++服务端开发,现在纠结钻研透彻这些有意义吗? 现在那么多现成的框架各种东西的
A:
查看代码
钻研透彻 C++ 底层知识对于面试大厂 Linux C++ 服务端开发是非常有意义的,在 Linux C++ 服务端开发中,会遇到各种复杂的问题,如内存泄漏、性能瓶颈等。如果对 C++ 底层知识有深入的理解,就能够更快速地定位和解决这些问题
内心OS:
妈逼的一个
const很简单,指针之前也立志狠狠操通透了、&引用更是没啥难的,但const、&、*结合在一起,妈逼的,脑子炸了,又他妈学了一天这玩意。这小节说的是阅读时长2min,老子扩展学了2周!妈逼的 C++ 东西咋这么多啊!
写博客也真的痛苦:
问完豆包一堆知识碎片穿插在一起像深搜算法一样一个问题问到底,再返回问另一个问题,整理起来太痛苦了,但没办法!唉~~~~(>_<)~~~~,且电脑是17年的电脑,豆包的历史拉完后,网页总共1.8G,经常就闪退,唉
我真的好痛苦 我是银行外包测试转行的,不需要任何技术,每天看的东西毫无意义,所以转行了。
自己独立用 C 刷通了邝斌专题的 5 大专题,精啃了 TCPIP 网络编程尹圣雨书籍,精啃了小林 coding 的 OS 和网络,独立迭代了 7 个版本的 http 多线程服务端开发项目,解决连接堆积、粘包、手写时间轮,现在在学 C++ 感觉撑不下去了,我想年薪30w哎可看不到光亮,不敢写简历
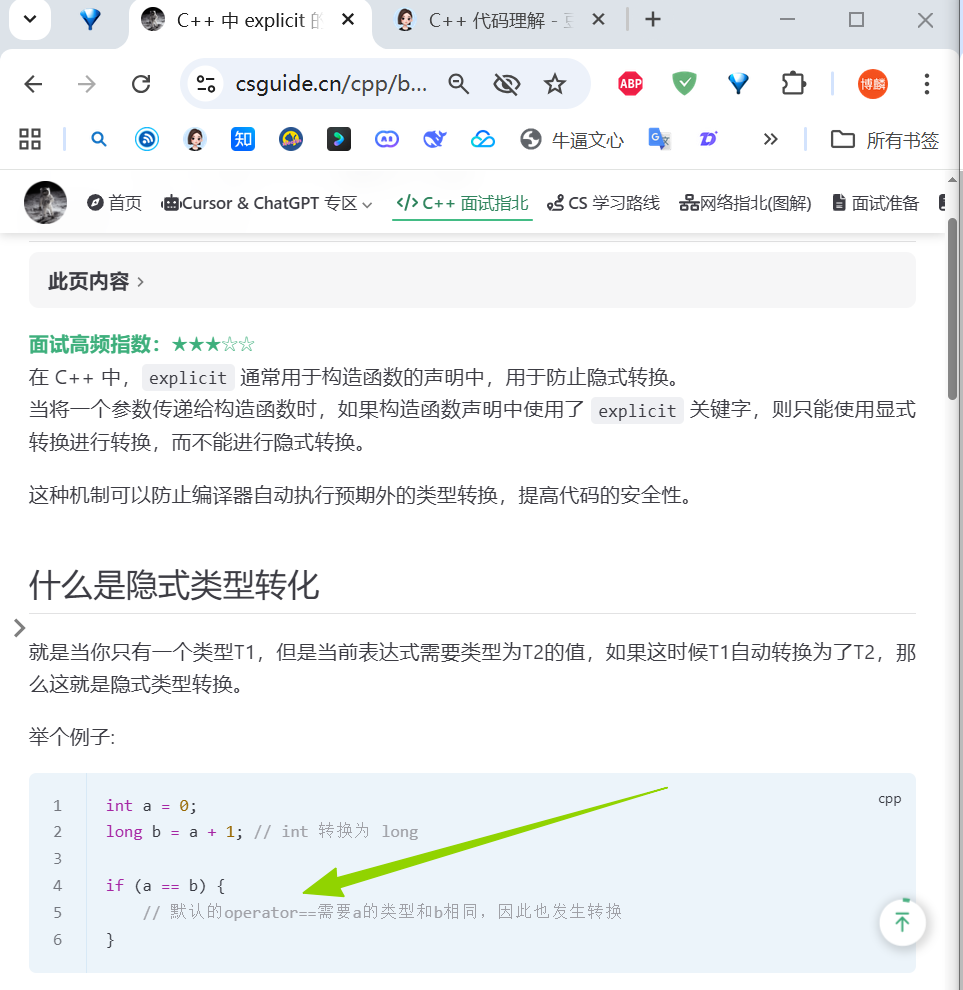



关于 C++ 中 extern 作用:
发现不管二星还是三星的【面试高频指数】,都死磕钻研,之前的二星过了,现在的高星就砍瓜切菜了。而且这玩意之前写项目的时候自学过。
这就是内功!也印证了自己的观点,自己探索学习写书一样,真比看教程好多了。
extern告诉编译器,在别处定义了,你先编译,到时候链接器会去别的地方找定义的地址。变量声明:打招呼
变量定义:分内存
函数定义:有{},否则就是声明
Q:只有声明不定义 叫 前向声明?
A:不完全是,核心就是 “先告诉编译器有这个东西,后面会给出完整定义”。比如在实体(类、函数等)的完整定义还没出现时,先提前声明它 “存在”,目的是解决 “先用到再定义” 的编译依赖问题。但 “只有声明不定义” 还可能是其他情况(比如全局变量用 extern 声明但不在当前文件定义),二者不能完全划等号。
例子:
int a;(全局),C/C++ 中视为 “定义”(分配内存,默认初始化为 0)。
int a = 10;(全局)定义,有初始化,无论是否有extern都是定义。
extern int a;声明,不分内存
void func() { int b; },无extern,声明即定义,栈。
void add(int x, int y);声明。
extern void add(int x, int y);声明。extern对函数声明无实质影响。
const int a = 10;定义,内部链接即仅当前文件可见。其他文件无法通过extern引用
const int a;无extern的const变量,即使无初始化,C++ 也视为内部链接的定义(默认初始化为 0)。
extern const int a;声明(非定义),显式extern,仅声明,不分配内存,需在其他文件中定义(extern const int a=10;)。
class A;前向声明,仅告知类型存在,不定义成员,不分配内存。
class A { public: int x; };定义,定义类的成员,确定类的实例大小,但类本身不分配内存(类的实例才分配内存)。内部链接是变量 / 函数的可见范围(仅当前文件),
const是变量的只读属性,二者本质不同,只是 C++ 中const变量默认带内部链接。除此的内部链接还有:
用
static修饰的全局变量 / 函数(仅当前文件可见,无法被其他文件extern引用);
static是多用途修饰符:修饰变量时控制生命周期(如局部 static 延长至程序结束)和链接性(全局 static 仅当前文件可见),修饰函数时仅限制其仅当前文件可见;
const主要修饰变量使其只读,二者功能和作用场景不同。匿名命名空间(C++)里的所有变量 / 函数(默认内部链接,作用域仅限当前命名空间所在文件
查看代码
// 当前文件:test1.cpp namespace { // 匿名命名空间int inner_var = 20; // 仅test1.cpp可见void inner_func() {} // 仅test1.cpp可见 }// 另一文件:test2.cpp // 尝试引用会编译错误 extern int inner_var; // 错误:找不到inner_var的外部定义 extern void inner_func(); // 错误:找不到inner_func的外部定义- 匿名命名空间
namespace {}可以直接这么用,其内部的默认仅当前文件可见,效果类似static修饰的全局变量 / 函数所以这个水货又说错了:
严谨说是只适用于:函数、
const、变量:
变量:全局变量无
extern的声明通常是定义(如int a;);
函数:无
extern且带{}的是定义(如void f(){}),不带{}的仍是声明(与extern无关);
const变量:无extern的声明默认是内部链接的定义(如const int a;)不适用的:
函数,无
{}= 声明,有{}= 定义,与extern无关前向声明类
给 C 和 C++ 跨语言链接用的
extern "C"链接指定,属于不带extern的声明,C++ 兼容 C 用的,C 里int a,C++ 文件要用,必须extern "C" int a;声明 —— 否则 C++ 会按 C++ 链接规则(名字修饰)去找这个变量,导致链接失败。
extern "C" int a;仍是声明。没事习惯了,这逼网站就是个地图导航而已,知道要学啥用的,继续。
static仅限当前文件可见(内部链接)
extern声明 “这个变量 / 函数在其他文件定义,当前文件要引用它”(外部链接)
链接属性:
程序在编译、链接和执行阶段如何处理符号(变量、函数、类等)的可见性和重复定义。
外部链接:
- 不同文件共享
内部链接:
- 只自己
无链接:
- 符号(变量 / 函数)仅在当前代码块内可见,编译器不会为其生成可被链接器识别的全局符号
说些细节:
一步就可以用的常量叫立即数,
a=5,b='A',5和'A'都是立即数,x=10,d=x+3,x 就不是,因为要先去读 x 存的 10,要看是不是直接拿来用,不用先去 “找某个变量里存的值”。没带任何变量名,直接写的数字 / 字符,就立即数。
可寻址内存,就是变量形式的。
字面常量:
5、"abc"
直接使用时(如
int a = 5;),5 作为立即数嵌入指令,占代码区;- 需通过地址访问时(如
const int x = 5; &x),编译器会在常量区分配内存存储 5,5 存于常量区,通过 x 的地址访问普通变量:
int a = 4,a 的变量值就是 4;
局部:栈区
全局 / 静态:全局数据区
常(量)变量:
const int b = 5,b 的变量值就是 5。
局部且未取地址:可能不分配内存(值嵌入指令占用代码区的内存)
局部且取地址或者跨作用域:栈区
全局且不取地址:可能不分配内存(值嵌入指令占用代码区的内存)
全局且取地址或者跨作用域:常量区
const int a=5; int b=a编译器直接用 5 替换a,编译器优化不分内存,自然无法被其他代码访问。
- 将其值直接嵌入到使用它的指令中,并非不占用内存,只是不占用 “变量形式的内存”。没有可寻址的内存,没有变量名关联
const int a=5; const int* p=&a;,编译器必须为a分配可寻址的内存才能存地址,但此时a仍只在当前代码块有效(无链接)。
所以仅在当前代码块内被直接使用,不分内存,如果取地址,跨作用域使用就分内存。
程序运行时,内存分为:
栈
堆
全局/静态存储区
常量区
代码区:存代码片段
例子:
查看代码
//fileA.cpp int i = 1; //声明并定义全局变量i//fileB.cpp extern int i; //声明i,链接全局变量//fileC.cpp extern int i = 2; //错误,多重定义 int i; //错误,这是一个定义,导致多重定义 main() {extern int i; //正确int i = 5; //正确,新的局部变量i; }在函数内:
extern int i;声明引用全局变量i(来自 fileA.cpp)
int i = 5;定义新的局部变量i,作用域仅限当前函数,与全局变量i同名但互不干扰(局部变量优先)
例子:
const修饰就是常量,局常量默认是内部链接的,所以想要在文件间传递全局常量量需要在定义时指明
extern查看代码
//fileA.cpp extern const int i = 1; //定义//fileB.cpp //声明 extern const int i;这里的
i是全局常量(const修饰的全局变量)。核心逻辑:全局const默认内部链接(仅当前文件可见),若要跨文件访问,必须在定义时加extern(如extern const int i = 1;),才能让其变为外部链接;若定义时不加extern(如const int i = 1;),其他文件用extern const int i;声明也无法链接 —— 因为原定义是内部链接,没生成可跨文件的全局符号。错误写法:
查看代码
//fileA.cpp const int i = 1; //定义 (不用 extern 修饰)//fileB.cpp //声明 extern const int i;
关于字符:
字符看是字符,但存是整数,听好几遍就是没实际对应上落地的样子。
char的本质是 “1 字节整数类型”,只是通常用来表示字符
'A'存储的是整数 65
'5'存储的是整数 53给
char,字符形式就存对应整数,给整数形式就原封不动,但输出字符形式统一是对应的字符格式。比如:
char c1 = 5;变量存储的是整数 5,对应 ASCII 码 5 的字符,是不可见控制字符。char c2 = '5';),变量存储的是字符 '5' 对应的 ASCII 码值 53,对应可见的数字字符 '5'解释:
5是 int 类型的字面量,值就是数字 5,底层存储的是二进制的整数(比如 4 字节的00000000 00000000 00000000 00000101);
"5"是 字符串字面量,底层是一个字符数组({'5', '\0'}),其中字符'5'的 ASCII 码值是 53,所以存储的是二进制的 53(1 字节的00110101),后面还跟着一个结束符\0。输出:
printf("%c", 5);:把int5 当作 ASCII 码,对应的字符是 “不可见控制字符”。
printf("%d", 5);:直接输出数字 5;
char是单个字符,不以\0结尾,只有字符串以这个结尾,不能用%s输出。
cout << 5;和cout << "5";都是直接输出"5"
说下编译和链接过程:
编译链接过程中,
extern的作用如下:编译期,
extern用于告诉编译器某个变量或函数的定义在其他源文件中,编译器会为它生成一个符号表项,并在当前源文件中建立一个对该符号的引用:
符号表项:编译器为每个标识符(变量、函数等)创建的记录,包含名称、类型、存储信息等,相当于符号的 "身份证"。
引用(不是&):这里指代码中使用该符号的地方(如调用函数、访问变量),编译器记录 "这里需要用到某个符号",但暂时不知道它具体在哪里。
这个引用是一个未定义的符号,编译器在后续的链接过程中会在其他源文件中查找这个符号的定义:
- 未定义符号不报错:编译阶段只检查语法和部分语义,符号是否有定义由链接器负责。编译器遇到未定义符号会标记,不直接报错,留到链接时处理。
链接时查找:链接器会收集所有目标文件的符号表,把未定义的引用和其他文件中的定义对应起来,找不到才报错(undefined reference)
链接期,链接器将多个目标文件合并成一个可执行文件,并且在当前源文件中声明的符号,会在其它源文件中找到对应的定义,并将它们链接起来。
例子:
查看代码
// file1.cpp #include <iostream> extern int global_var;int main() {std::cout << global_var << std::endl;return 0; }// file2.cpp int global_var = 42;在上面的示例中,
file1.cpp文件中的main函数使用了全局变量global_var,但是global_var的定义是在file2.cpp中的,因此在file1.cpp中需要使用extern声明该变量。在编译时,编译器会为
global_var生成一个符号表项,并在file1.cpp中建立一个对该符号的引用。在链接时,链接器会在其他源文件中查找
global_var的定义,并将其链接起来。
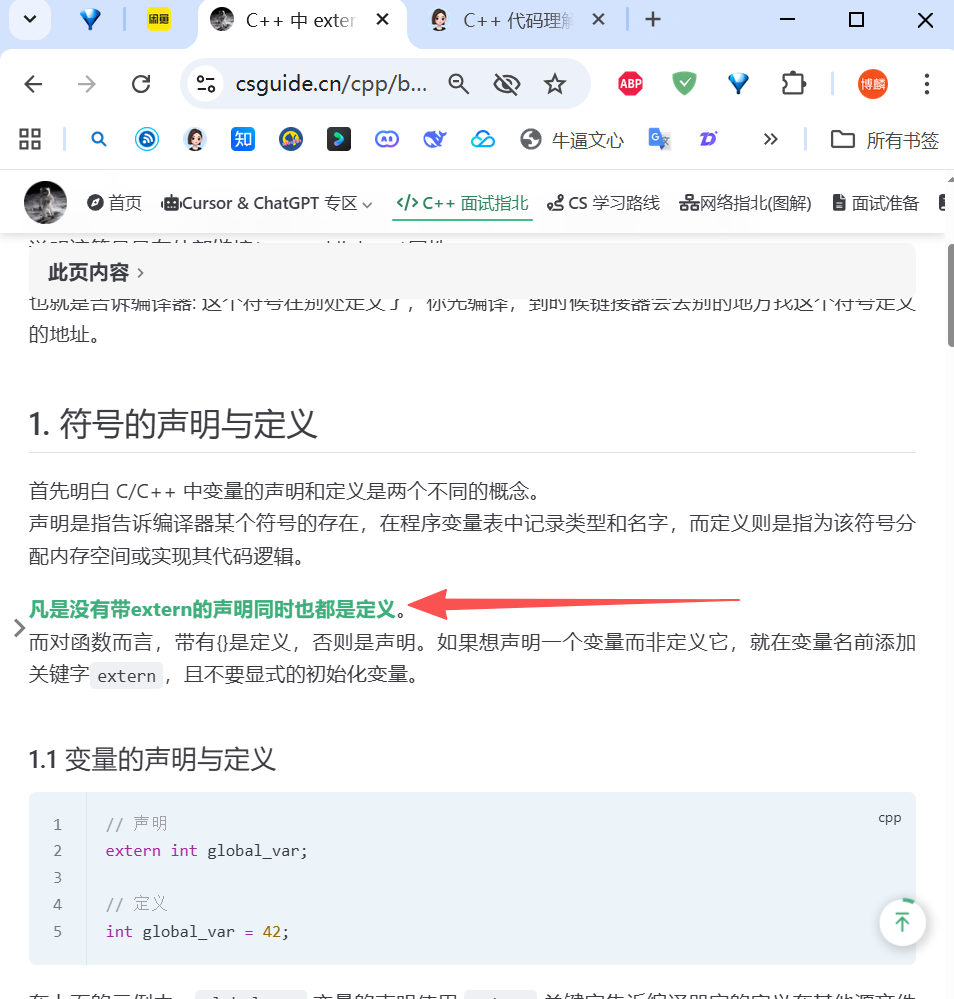
关于 C++ extern C 的作用:
(妈逼的我看了一下,后面的目录,之前每个小块自己钻研那么深都是后面要学的!提前学了!但效果会好很多!自己摸索探索学习比看教程深刻的多!甚至比写的都懂!因为作者很多也是水货!不知道这些人咋进大厂的!状元可能有水货,但最年轻的 MVP 绝对没有!看视频学习更不用说了,是给那些边角料的废物用的!)
C++ 和 C 语言在编译和链接时使用的命名规则不同,C++ 调用 C 的函数或变量时,必须用
extern,否则链接时找不到符号。函数的命名规则(也叫“名称修饰”):对于 C++ 语言,由于需要支持重载,所以一个函数的链接名(Linkage Name)是由函数的名称、参数类型和返回值类型等信息组成的,用于在编译和链接时唯一标识该函数。
函数的链接名的生成规则在不同的编译器和操作系统上可能有所不同,一般是由编译器自动处理,不需要手动指定,这个规则常常叫做 Name Mangling。
函数:
C++ 有重载所以可能同时有多个 add 函数,只是返回值和参数不同而已。
C 最多只有一个 add。
变量:
C++ 中带命名空间、类成员的变量,所以也和 C 不同。
为什么要有 “名称修饰”(函数命名规则)?
C++ 支持函数重载(同名函数可因参数类型 / 个数不同共存),但链接器只认 “唯一符号名”。所以编译器会对函数名进行 “修饰”,把参数类型、返回值等信息编码进最终的链接名里,让重载的函数能生成不同符号,避免链接冲突。
不同编译器的修饰规则(大厂场景里,Linux 下主要关注 GCC/Clang)
GCC(Linux 主流):会把参数类型等信息编码到函数名里。比如
int add(int a, int b),修饰后可能变成_Z3addii(_Z是前缀,3表示函数名add长度,ii表示两个int参数)。Clang(macOS 或 Linux 下也常用):规则和 GCC 类似(因为要兼容大部分场景),所以
int add(int a, int b)修饰后也可能是_Z3addii,但细节(比如特殊场景的编码)会有小差异。C 和 C++ 命名规则的差异
C 语言不支持函数重载,所以编译时不会对函数名做 “带参数类型的复杂修饰”,函数名基本就是原名字(或简单加个前缀)。
而 C++ 要调用 C 写的函数(比如 Linux 下很多系统库、 legacy 库是 C 实现的),就会出问题 —— C++ 按自己的修饰规则找符号,C 库的符号是 “原始简单名”,肯定找不到。
这时候用extern "C"告诉 C++ 编译器:“这段代码(函数声明)按 C 的命名规则来,别做 C++ 式的名称修饰”。这样 C++ 编译出来的符号能和 C 库的符号匹配,就能成功链接调用了大厂开发里的实际意义
对接C 语言写的底层库(如 Linux 系统调用封装、高性能网络库)时,必须用
extern "C"保证调用成功。排查链接错误(比如
undefined reference to xxx)时,要能看懂 “修饰后的符号名”,判断是 “真没定义” 还是 “编译器修饰规则不匹配”(比如混了 C/C++ 编译、不同编译器混用)。做跨模块 / 跨语言的二进制组件复用时,名称修饰规则是 “二进制接口(ABI)” 的一部分,决定了代码能不能互相链接
感觉抽插太深入了,先搁置吧。
例子:
查看代码
// C 语言代码 #include <stdio.h>void print_message(const char* message) {printf("%s\n", message); }// C++ 代码 extern "C" {// 声明 C 语言函数void print_message(const char* message); }int main() {// 调用 C 语言函数print_message("Hello, world!");return 0; }不使用
extern "C"进行声明,将会导致链接错误error LNK2019: 无法解析的外部符号 "void __cdecl print_message(char const *)" (?print_message@@YAXPEBD@Z),函数 main 中引用了该符号解释:
C 代码编译:生成未修饰的函数符号(如
print_message)C++ 代码编译:默认对函数名进行修饰(如 MSVC 生成
?print_message@@YAXPEBD@Z)链接阶段:C++ 生成的修饰符号与 C 生成的原始符号不匹配,导致找不到符号报错
参数和返回值的类型匹配得靠自己保证:
比如 C 里函数是
int func(char),你用extern "C"声明成int func(int),编译时可能不报错(因为extern "C"不检查类型),但运行时就会因参数解析错误崩溃。
关于 C++ mutable 的作用:
mutable修饰成员变量,表示即使在const函数里也能修改。否则const函数里不能改类的任何成员变量。
错别字、多字、表述不清,感觉脑子进了屎!
既然说工作从未遇到,那算了。
wx搜“终极总结写博客编程指北”真的好亏研究透彻这些玩意,说工作用不到,那你妈逼的到底,大学学的不是工作用的,工作面试考的也不是工作用的,操.你妈的,什么狗逼环境。
研究吧
先说这个垃圾水货博主的错误:
首先
类的状态,就是成员变量,
但他说类状态无关表示很歧义,其实就是说可以改变的意思,这些变量的值变化不影响对象对外呈现的核心特征或逻辑状态。
比如,假设一个表示 “学生” 的类,有成员变量
score成绩,属于核心状态,决定学生水平,还有一个mutable int queryCount记录该学生信息被查询的次数。接着
他说的错误是
mutable修饰函数,大凑特错!!mutable永远无法修饰函数再继续:
“后后面”表述有误,应该是“放在成员变量的声明处,用
mutable修饰成员变量
说个逻辑:
成员函数属于对象,更准确说是属于类,对象是类的实例,但 “成员函数操作对象” 其实是从功能逻辑角度的简化说法,核心是:成员函数的作用,就是修改或读取对象自身的状态(也就是成员变量)。
把 “对象” 想象成一辆 “汽车”,“成员变量” 就是汽车的状态 —— 比如油量、当前速度、车门是否锁上;而 “成员函数” 就是汽车的功能按钮 —— 比如 “加油”(修改油量)、“显示速度”(读取速度)、“锁车门”(修改车门状态)。
你按 “加油” 按钮(调用成员函数),这个按钮不会自己凭空加油,而是会操作汽车本身(对象),把油量(成员变量)从 10% 改成 80%
成员函数 “属于对象”(语法上属于类,实例化后归对象调用);
成员函数的核心工作,就是 “操作对象”—— 具体是通过
this指针,修改 / 读取对象里的成员变量;
const修饰成员函数,就是限制这种 “操作” 只能是 “读”,不能是 “改”(普通成员变量)。说个自创提示词:给小白教程
说
this:在 C++ 中,
this是一个隐含于每一个非静态成员函数中的指针 ,具有以下特性:1、指向调用对象(可不用this):当调用一个类的成员函数时,
this指针会指向调用该函数的对象。比如有类Person,创建对象p,然后调用p.eat(),在eat成员函数内部,this就指向p这个对象。查看代码
#include <iostream> #include <string> using namespace std;class Person { private:string name; public:Person(string n) : name(n) {}void introduce() {cout << "My name is ";// 通过this指针访问成员变量cout << this->name << endl; } };int main() {Person p("Alice");p.introduce(); }在上述代码中,
introduce成员函数通过this->name访问了对象的成员变量name。2、区分同名变量(必须用this):当成员函数的参数名与成员变量名相同时,
this指针可以明确指出要访问的是成员变量,而不是参数。例如:查看代码
#include <iostream> using namespace std;class Rectangle { private:double width;double height; public:Rectangle(double width, double height) {// 没有this指针会混淆,有了它就能明确是给成员变量赋值this->width = width; this->height = height; }double getArea() {return width * height;} };int main() {Rectangle r(5.0, 3.0);cout << "The area is: " << r.getArea() << endl; }3、在
const成员函数中:在const成员函数里,this指针的类型是const T*(T代表类类型) ,这就限制了不能通过this指针去修改对象的普通成员变量,以保证对象状态的 “只读” 特性。但如果
const函数里又个int haha局部变量,可以随便改不受限制。const 只限制 “通过 this 指针访问的类成员变量”,局部变量是函数内部临时创建的,和对象状态无关,所以修改完全没问题简单来说,
this指针就像是一个 “指向当前对象的路标” ,帮助成员函数操作所属对象的成员变量和调用其他成员函数总结:
大多数时候可以省略
this->,编译器会自动识别成员变量。但两种场景必须显式用
this:1、成员变量与函数参数同名时(如
this->width = width)2、在成员函数中返回当前对象自身时(
return *this):比如:
查看代码
#include <iostream> using namespace std;class Counter { private:int value; public:Counter(int v = 0) : value(v) {}// 增加数值并返回当前对象自身Counter& add(int num) {value += num;return *this; // 返回当前对象的引用}void print() {cout << "当前值: " << value << endl;} };int main() {Counter c(10);// 链式调用:多次调用add,每次都返回自身c.add(5).add(3).add(2);c.print(); // 输出:当前值: 20 }代码中
return *this返回当前对象本身,允许像c.add(5).add(3)这样链式调用,每次调用都基于同一个对象操作。
Counter(int v = 0) : value(v) {}多加了= 0:
如果你传参数,就用你传的,比如
Counter c(10);,那 value 就是 10如果你不传参数,就默认用 0,比如
Counter c;,那 value 就是 0平时你见的
Counter(int v) : value(v) {},是必须传一个参数才能创建对象,比如Counter c(10);。非静态 & 静态:
日常写的 “直接用对象调用的函数 / 访问的变量” 就是非静态的,无专属关键词。
静态是 “不用创建对象,直接用类名就能调用的特殊存在”,用
static修饰。查看代码
#include <iostream> using namespace std;// 定义一个类 class Student { public:// 1. 非静态成员变量(日常用的,无static)string name; // 2. 静态成员变量(必须加static,属于类本身)static int totalCount; // 3. 非静态成员函数(日常用的,无static,有this指针)void setName(string n) { name = n; // 直接改当前对象的name(靠this指针)}// 4. 静态成员函数(必须加static,无this指针)static void addCount() { totalCount++; // 只能改静态变量,不能改name(没this指针找不到对象)} };// 静态变量必须在类外初始化(固定写法) int Student::totalCount = 0;int main() {// 用非静态的方式(必须先创建对象)Student s1; // 创建对象s1s1.setName("小明"); // 对象调用非静态函数cout << s1.name << endl; // 对象访问非静态变量// 用静态的方式(不用创建对象,直接类名调用)Student::addCount(); // 类名::静态函数cout << Student::totalCount << endl; // 类名::静态变量 }补充:
静态成员函数
静态成员函数属于类本身,而不是类的某个具体对象。在类中进行声明和定义,能让代码结构更清晰,也符合编程习惯。比如:
class Example { public:// 直接在类内定义静态成员函数static void staticFunction() {std::cout << "这是一个静态成员函数" << std::endl;} };当然,也可以在类内声明,类外定义:class Example { public:static void staticFunction(); // 类内声明 }; // 类外定义 void Example::staticFunction() {std::cout << "这是一个静态成员函数" << std::endl; }函数(包括静态成员函数)的核心是 “代码逻辑”,不管在类内还是类外定义,编译器最终都会把它的代码存到 “代码段”,不需要依赖 “类实例化” 或 “额外内存分配”—— 所以类内定义(直接写实现)、类外定义(先声明再写实现)都能正常工作,只是代码组织方式不同。
静态成员函数是 “代码”,代码逻辑本身不占对象 / 类的数据内存,编译器天然能定位到它的代码位置。
本质是:成员函数的代码(逻辑)只存在于 “代码区”,而 “对象 / 类的数据” 指的是成员变量(非静态成员变量存在栈 / 堆,静态成员变量存在全局 / 静态存储区),所以函数代码不会占用栈、堆、全局 / 静态存储区这些 “数据存储相关分区” 的空间。举具体例子帮你对应:比如之前写的Person类:
Person p1;:p1 这个对象的非静态成员变量age、name,存在栈里(这是 “对象的数据”);
Person* p2 = new Person;:p2 指向的对象里的age、name,存在堆里(这也是 “对象的数据”);
static int Person::count;:这个静态成员变量,存在全局 / 静态存储区(这是 “类的数据”);而
printInfo()、setAge()这两个成员函数的代码(比如 “输出 age”“给 age 赋值” 的指令),只存在代码区—— 既不会挤到 p1 的栈空间里,也不会占 p2 堆空间的位置,更不会占全局区里count的空间,所以说 “代码逻辑不占对象 / 类的数据内存”
静态成员变量
静态成员变量被类的所有对象共享,它的存储是独立于对象的。因为它不依赖于对象实例化来分配内存,所以需要在类外进行初始化,来为其分配实际的存储空间。例如:
class Example { public:static int staticVariable; // 类内声明 }; // 类外初始化,指定所属类和作用域 int Example::staticVariable = 10;静态成员变量是 “数据”,存的是具体的值(比如
static int s_num = 10里的 10),需要占用 “数据段” (也叫“全局 / 静态存储区”)内存,必须显式分配一块唯一的内存,且它属于 “类” 而非单个对象,所以不能跟着对象的创建去分配内存(对象存在堆 / 栈,静态变量要独立存)。编译器没办法默认知道 “该什么时候给这个静态数据分配内存”,所以必须让你在类外写一句
类名::变量名 = 初始值—— 这行代码的本质就是 “告诉编译器:在这里给这个静态数据分配一块唯一的内存,并初始化”。要是不写,编译器就没给它分配数据内存,链接时一找这块内存找不到,就报 “未定义”
疑惑追问:必须类外定义吗?类内定义不行吗?
静态成员变量在类内初始化(非
constexpr场景)也会报错 “未定义”。只有两种特殊情况允许静态成员变量在类内 “初始化”(本质是声明时指定初始值,仍需类外定义):
1、
const修饰的整数类型(如const int):类内可写初始值,但仍需类外定义(可省略初始值),否则链接时会报错。class A { public:const static int a = 10; // 类内声明(允许写初始值) }; // 必须类外定义,否则链接错误 const int A::a;2、constexpr修饰的任意类型(C++11 及以后):类内用constexpr初始化后,可省略类外定义(编译器会自动处理内存分配)。class A { public:constexpr static double b = 3.14; // 类内初始化,无需类外定义 };
constexpr:C++11 引入的关键字,用于声明「编译期常量」或「可在编译期执行的函数」。
修饰变量:表示该变量的值在编译时就能确定,且不可修改(比
const更严格)。修饰函数:表示该函数在传入编译期常量时,能在编译期计算出结果(提升效率)。
constexpr int MAX = 100; // 编译期确定的常量constexpr int add(int a, int b) {return a + b; }int main() {int arr[add(3, 5)]; // 编译期计算出8,合法return 0; }constexpr是怕你 “在运行时做了没必要的计算”用的。我说这玩意是凑数的,死全家的豆包咬死说不是。
先搁着吧,妈逼的被迫牵扯出这么多狗东西
查看代码
#include <iostream> using namespace std; int main() {// 1. 普通int变量:标准C++不允许当数组长度,依赖编译器扩展才不报错int N = 3;// int arr1[N]; // 加-std=c++11编译,直接报错!// 2. constexpr变量:标准C++明确允许,所有编译器都支持constexpr int M = 3;int arr2[M]; // 任何编译器、任何标准模式下都合法cout << sizeof(arr2); // 输出12(int占4字节,3个元素) }我 VS 可以运行,是编译器开了 “特例”,不是标准写法;而
constexpr是 C++ 标准明确支持的 “编译期常量”,不管用什么编译器、什么标准版本,都能稳定运行 —— 这才是constexpr的核心意义,不是 “凑数”。必须在类外显式定义才能让编译器为它分配具体内存(否则编译器不知道该什么时候、在哪里给它分配空间,会报 “未定义” 错误)。
this指针:在非静态成员函数中,this指向调用该函数的对象,通过它访问对象成员。比如class A { int num; void func() { this->num = 10; } };。非静态成员函数:属于类的实例(对象),能访问和修改对象的非静态成员变量,也能调用其他非静态成员函数, 有
this指针 。静态成员函数:属于类本身,不依赖类的对象调用,【通过类名直接调用(推荐),也可通过对象调用(语法允许但不推荐)】,没有
this指针(因为不属于特定对象),只能访问静态成员,不能直接访问非静态成员变量和函数( 因为它不知道要操作哪个对象的成员)。
静态成员函数可以:
类里声明 + 定义。
类里声明,类外定义。
const成员函数:属于非静态成员函数范畴,加const后,this指针变为const T*类型,不能修改对象的普通成员变量(也就是非静态的)。T指的是当前类的类型,比如有个类Person,那么:
非
const成员函数里的this是Person*类型(指向当前Person对象,可修改对象成员);
const成员函数里的this是const Person*类型(指向当前Person对象,不可修改对象普通成员)
比如:
查看代码
class Student { private:int age; // 非静态普通成员变量 public:// const成员函数,this是const Student*类型void setAge(int a) const {age = a; // 编译报错!const成员函数不能修改非静态普通成员}// 非const成员函数,this是Student*类型void updateAge(int a) {age = a; // 正常编译,允许修改} };静态成员函数永远不能加
const。
const修饰的非静态的成员函数里不能修改非静态的成员变量(除非有mutable)。
const修饰的非静态的成员函数里可以修改静态的成员变量。
先明确:两种成员变量的 “归属权”
非静态普通成员变量(比如
class Test { int a; };中的a):它属于 某个具体的对象。每个Test对象都会单独存储一份a,访问它时必须通过this指针(隐含指向当前对象),比如this->a。而const成员函数的this是const T*类型 —— 这意味着 “不能通过this修改它指向的对象”,所以this->a = 10会报错。静态成员变量(比如
class Test { static int b; };中的b):它属于 整个类,不属于任何单个对象。整个程序中只有 一份 存储(在全局数据区),访问它时不需要依赖this指针,而是直接通过类名::静态变量名(比如Test::b)。它的存在和修改,与 “某个具体对象是否被const限制” 毫无关系。
const成员函数的限制范围:只针对 “对象自身”
const修饰成员函数的核心目的,是 保证 “当前对象的状态不被修改”(即对象自身的非静态成员变量不变)。但静态成员变量不属于任何对象,它是类的 “全局资源”—— 修改它不会影响任何对象的状态,所以const成员函数不会禁止这种操作,
实操:
查看代码
#include <iostream> using namespace std;class Test {int non_static_a; // 非静态成员:属于对象static int static_b; // 静态成员:属于类(全局唯一) public:// const 非静态成员函数void modify() const {// 1. 尝试修改非静态成员:报错!依赖 this 指针(const T*)// non_static_a = 10; // 编译错误:assignment of member 'Test::non_static_a' in read-only object// 2. 尝试修改静态成员:合法!不依赖 this,属于类static_b = 20; // 完全没问题cout << "静态成员 b 修改后:" << static_b << endl;} };// 静态成员变量必须在类外初始化(分配全局存储) int Test::static_b = 0;int main() {Test t;t.modify(); // 调用 const 成员函数,输出 "静态成员 b 修改后:20" }
this限制非静态成员的修改,不限制静态成员。
再举个例子:
查看代码
#include <iostream> using namespace std;class MyClass { private:// 普通成员变量:const成员函数不能改int normal_val;// mutable修饰的成员变量:const成员函数可以改mutable int mutable_val; public:// 构造函数:初始化两个变量MyClass(int n, int m) : normal_val(n), mutable_val(m) {}// 1. const成员函数:核心限制“不能改普通成员变量”void showAndUpdate() const {// 错误!普通成员变量normal_val不能改(const函数限制)// normal_val = 100; // 正确!mutable修饰的变量,const函数里能改mutable_val += 1; // 读取成员变量(无论普通还是mutable,都能读)cout << "普通变量:" << normal_val << ",mutable变量:" << mutable_val << endl;}// 2. 非const成员函数:两个变量都能改void updateNormal() {normal_val = 200; // 普通变量可改mutable_val = 5; // mutable变量也可改} };int main() {MyClass obj(10, 20);// 调用const成员函数:只会改mutable_valobj.showAndUpdate(); // 输出:普通变量:10,mutable变量:21obj.showAndUpdate(); // 输出:普通变量:10,mutable变量:22// 调用非const成员函数:改普通变量obj.updateNormal();obj.showAndUpdate(); // 输出:普通变量:200,mutable变量:6 }写法:
成员函数在参数列表后加
const是规定,普通函数 / 全局函数:不能在
()后加const。
const修饰成员函数的本质是限制「对象状态」,而全局函数没有对应的「对象」可以限制。修饰返回值:
const int func()(const在函数名前,仅限制返回值不可修改)
类的
const成员函数不能修改普通成员变量,除非成员变量用mutable修饰
const修饰成员函数,本质是限制修改对象的状态(普通成员变量),编译器会隐式给this指针加上const限定(const T* this),防止通过this指针修改成员。但如果成员变量声明时加了
mutable(如mutable int count;),则允许在const成员函数中修改,用于记录日志、缓存等不影响对象逻辑状态的变量。
真的撑不下去了,看不到光亮,永无尽头:
豆包问询
中科院博士致谢
罗斯
艾弗森
回过头看傻逼大水货博主的教程:
查看代码
#include <iostream>class Counter { public:Counter() : count(0), cache_valid(false), cached_value(0) {}int get_count() const {if (!cache_valid) {// 模拟一个耗时的计算过程cached_value = count * 2;cache_valid = true;}return cached_value;}void increment() {count++;cache_valid = false; // 使缓存无效,因为count已经更改}private:int count;mutable bool cache_valid; // 缓存是否有效的标志mutable int cached_value; // 缓存的值 };int main() {Counter counter;counter.increment();counter.increment();std::cout << "Count: " << counter.get_count() << std::endl; // 输出 4 }有点意思。
狗逼豆包,唉,大模型学习必须有极强的自制力、心性、领悟能力、追问能力、思考能力等!!!
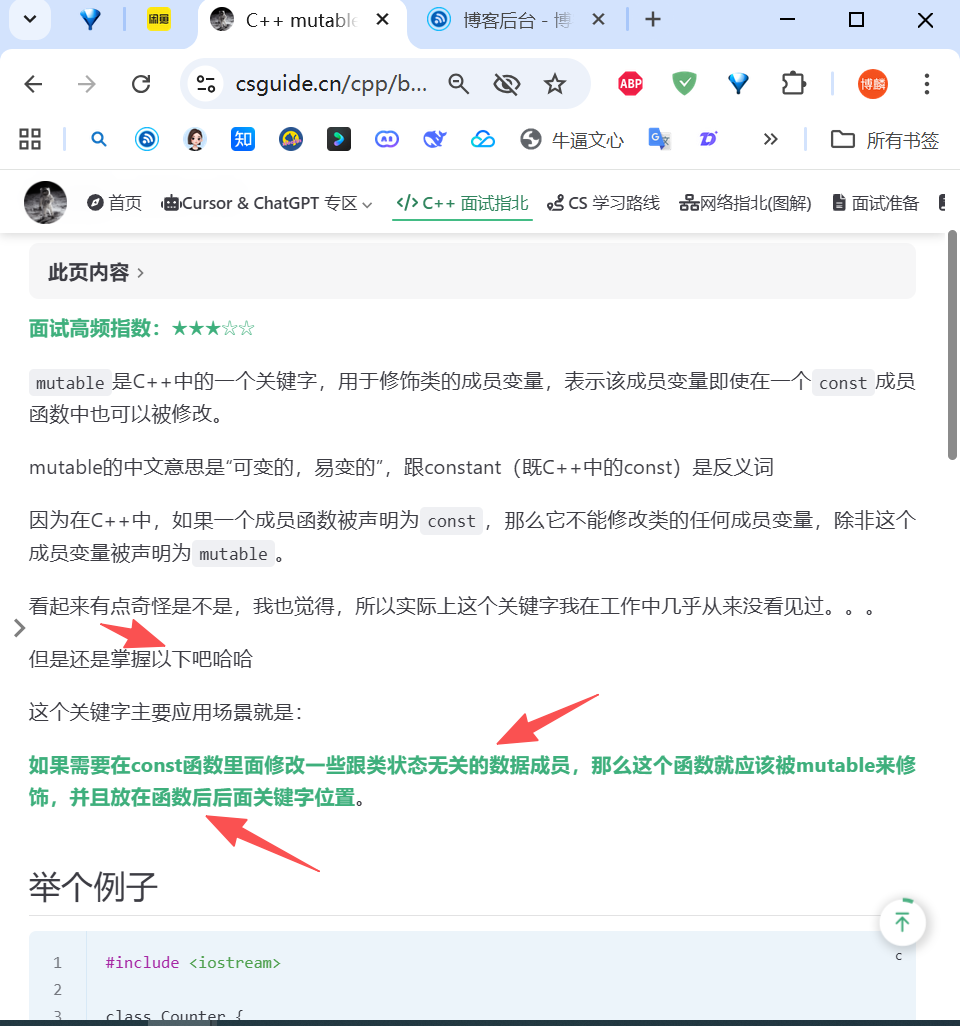
关于 C++ 中四种强制类型转换:
static_cast、
dynamic_cast、
const_cast、
reinterpret_cast:
(大量砸时间)
(邝斌:人一我十,人十我千)
(浪费了我两周,有几个知识点乱麻一样,相当的麻烦容易混淆,如今透彻精通了!)
(豆包学东西真的好痛苦~~~~(>_<)~~~~,搜【豆包误人子弟(自己瞎编造 C++ 规则一顿胡扯】就知道了)
expr指要被转换的表达式(比如变量、计算式等,如(int)a里的a、static_cast<int>(3.14 + 2.5)里的3.14 + 2.5)。
constexpr中的expr指编译期可计算的表达式(如常量、常量运算等,能在编译时确定结果)。所以 C 的
float a = 3.14; int b = (int)a; // C风格转换,C++完全支持,结果是3也叫
(type_name) expression。但这种 C 的强制转换有问题,属于不分风险,什么都能转:
安全转换:
float → int(只是丢小数,逻辑明确);危险转换:
int → char*(把整数当内存地址,极可能越界崩溃)。而 C++ 用不同转换符区分,强制你明确 “转换意图”,编译器还会做检查,
开始引入四大类型转换运算符(属于关键字):
关于
static_cast:float a = 3.14; // 3.14默认是 double 类型(8字节),这样写其实隐含类型转换, //等价于 float a = (float)3.14; 赋值给 float(4字节)时会截断 // 加 f 是显式声明为 float 常量(4字节),更规范 float a = 3.14f; // 直接是 float 类型,无转换 int b = static_cast<int>(a); //把float转int,结果是3(丢弃小数) //static_cast用于普通类型转换,和(int)a效果一样,但意图明确补充点东西,从来没关注过浮点数的细节,妈逼的又追问了一天,这里有很多引起歧义反常里的术语,好不容易才理解:
double 是 64 位(52 位有效数字),float 是 32 位(23 位有效数字),
截断方式:对超出 float 精度范围的低位有效数字进行截断(类似四舍五入到 23 位有效数字):
double d = 0.123456789012345; // 超过7位十进制有效数字 float f = static_cast<float>(d); // f会丢失末尾几位小数的精度说下咋回事,这里截断总感觉很乱,
1. 关于
double d = 0.123456789012345的精度细节:
double的存储结构:64 位二进制(1 位符号位 + 11 位指数位 + 52 位二进制尾数位)。十进制有效数字:52 位二进制尾数位 ≈ 15-17 位十进制有效数字(
log₁₀(2⁵²)≈15.65),即前 15 位十进制有效数字是精确可信的。
d的具体情况:
十进制字面量
0.123456789012345共 15 位十进制有效数字(从第一个非零数字 1 开始数:1、2、3、4、5、6、7、8、9、0、1、2、3、4、5)。由于 15 位 ≤
double的 15-17 位精度上限,d能精确存储这 15 位有效数字(底层是二进制近似,但转换回十进制时,前 15 位与字面量完全一致)。2. 关于
float f = static_cast<float>(d)的结果:
float的存储结构:32 位二进制(1 位符号位 + 8 位指数位 + 23 位二进制尾数位)。十进制有效数字:23 位二进制尾数位 ≈ 6-7 位十进制有效数字(
log₁₀(2²³)≈6.92),即前 7 位十进制有效数字是精确可信的。3.关键概念明确:
有效数字 尾数:从第一个非零数字开始数,到最后一个精确数字为止的位数(仅算十进制)。例如
0.123456789的有效数字是 9 位(1-9)。
float显示多位的原因:二进制存储的近似值转换为十进制时,计算结果自然会有多位小数,这是数学转换的必然结果,与有效数字位数无关(有效数字仅看前 7 位)。再用计算过程,一步一步证:
查看代码
1. 原始值d是double类型的0.123456789012345(十进制),先直接转成二进制(无限长):...101001110000101000111101011100001010001111010111...(二进制小数)2. 转成float时,只留23位二进制尾数:- 先把二进制写成科学计数法:1.xxxx...×2^(-4)(xxxx...是无限长尾数)- 只取前23位尾数:11111000110101110000100(二进制)- 指数和符号位按规则存,总32位3. 这个float在内存里就是这32位二进制数,没有十进制参与:0 01111100 11111000110101110000100(符号位+指数位+尾数位)4. 转回十进制显示时,计算结果是0.12345679104328156:- 前7位十进制数字1234567是可信的(因23位二进制精度刚好覆盖)- 第8位及以后(9、104328156等)是二进制截断导致的误差,无实际意义总结:f存的是"0.123456789012345转成23位二进制尾数的近似值",和十进制四舍五入无关,最终显示的十进制数只是这个二进制值的翻译结果。但注意: 0.1234567 是 float 二进制值转回十进制的精确计算结果中自然包含的前 7 位,是可信的真实精度; 0.1234568 是对更长十进制数(如 0.12345679...)做十进制层面四舍五入的结果,与 float 的二进制存储精度无关,是显示处理的产物。本质就是十进制转二进制,给计算机处理,然后根据
float的精度切割截断啥的,至此处理完毕,但为了给人类看,才再转十进制,只是十进制只有前 7 位可信!之前狗逼死全家的豆包误人子弟,用double d = 0.123456789012345直接在这十进制的基础上,做前 7 位的四舍五入了,即变成0.1234568,然后再转到二进制,就完全错了。
科普一:有效数字专门为十进制设计的,二进制里没有 “有效数字” 的说法 —— 因为 “有效数字” 的核心作用是帮人快速判断十进制数值的精确范围,而二进制是给计算机看的,计算机只需要按 “尾数位数”(比如 float 的 23 位、double 的 52 位)来确定精度,不需要 “有效数字” 这种人类友好的统计概念。二进制叫尾数,
科普二:尾数是 “科学计数法里,小数点后面的数字”。比如把二进制
1100100(对应十进制 100)写成科学计数法1.1001×2⁶—— 这里小数点后面的1001,就是二进制尾数;再比如0.123456789转成二进制科学计数法1.xxxxxx...×2⁻¹,小数点后的xxxxxx...就是二进制尾数,float 会只留这部分的前 23 位,double 留前 52 位科普三:二进制也有小数形式,二进制
10.10011翻译过来:
整数部分
10(二进制)= 2(十进制);小数部分
10011(二进制)= 1×2⁻¹ + 0×2⁻² + 0×2⁻³ + 1×2⁻⁴ + 1×2⁻⁵ = 0.5 + 0 + 0 + 0.0625 + 0.03125 = 0.59375(十进制);整个数就是 2 + 0.59375 = 2.59375(十进制)。
为啥 float 是 7 位有效?
第一步:为啥是 “7 位十进制有效”?—— 本质是 “二进制能管的范围,刚好够兜住 7 位十进制的所有可能”
你就记住一个核心:不管十进制还是二进制,“能表示多少个不同的数” 才是关键。
比如你要表示 “3 位十进制有效数字”(比如 123、456、0.0789 这种,核心是能区分 1000 个不同的数:10³=1000);
那得要多少位二进制才能 “兜住” 这 1000 个数?算一下:2¹⁰=1024(10 位二进制能表示 1024 个不同的数),刚好比 1000 多一点,所以 “10 位二进制” 对应 “3 位十进制有效”。
现在套 float:float 用 23 位二进制专门存 “数字的有效部分”(尾数),这 23 位能表示多少个不同的数?是 2²⁴≈1677 万(不用管为啥多 1 位,记结果就行)。再看十进制:7 位十进制有效数字能表示多少个不同的数?10⁷=1000 万。你看 ——23 位二进制能管 1677 万个数,刚好能 “兜住” 7 位十进制的 1000 万个数(能区分 7 位十进制里所有不同的值)。但要是想兜 8 位十进制(10⁸=1 亿个数),23 位二进制就不够了(1677 万<1 亿)。所以 float 只能 “管得住 7 位十进制有效”,这是算出来的 “二进制能覆盖的十进制区分能力”,不是瞎定的。
第二步:为啥会有 “很多无效位”?—— 二进制转十进制的 “副作用”,不是额外加的
比如你有个二进制数,它对应十进制是 “0.12345679104328156”。这个数里:
前 7 位 “1234567” 是准的(因为二进制能兜住 7 位,能区分开 “1234567” 和 “1234568”);
后面的 “9104328156” 不是 “故意加的无效位”,而是把那个二进制数完整转成十进制时,自然算出来的结果 —— 就像 1/3=0.333333...,不是故意写很多 3,是除法算出来的。
但这些后面的数 “无效”,是因为二进制位数不够了:它没法精确区分 “0.12345679” 和 “0.12345678”,所以这些超出 7 位的数,本质是 “二进制近似导致的误差尾巴”,没用。
总结就两句话:
float 的 7 位有效,是 “二进制能表示的不同数的数量,刚好够覆盖 7 位十进制的所有可能”,算出来的;
多余的无效位,是二进制转十进制时自然算出来的 “尾巴”,不是额外加的,只是二进制没能力让这些尾巴变准,所以没用
至此懂了!
再说一次,必须十进制 转 二进制,然后再截位 / 进位,再为了人类好观察,转十进制,只信前 7 位。如果说十进制直接四舍五入再搞二进制,再搞十进制逻辑完全不同,对了是巧合,所以从
double转float、或十进制数转二进制存float时,全程只在二进制层面做截断 / 进位(比如 23 位尾数超了就二进制进位),没有任何一步对 “十进制数” 主动做四舍五入,最终内存里的二进制值,对应的十进制,只有十进制的前 7 位一样!不涉及什么四舍五入,以上说的这些是内存层面。四舍五入只有二进制里有,转二进制后,第 x 位如果是 1,就给第 x - 1 位加 1(入);第 x 位如果是 0,就直接扔掉后面的(舍)。这样处理后,转成十进制时,数值会出现类似 “8 变 9” 的进位,本质是二进制加 1 导致的连锁反应。禁止理解成十进制的四舍五入!!以上是浮点数的截断
但输出显示层面是另一码事,比如:
查看代码
#include <iostream>int main() { float a = 0.12345679104328156;std::cout << a; //实际输出是0.123457 }double d = 0.123456789012345; // 超过7位十进制有效数字 float f = static_cast<float>(d); // f会丢失末尾几位小数的精度 cout 是 0.123457表面看像十进制四舍五入只是巧合,实际是二进制舍入后转十进制的结果,需通过二进制层面分析才是本质。
这是 cout 输出的四舍五入(显示层面的优化)。不改变 “内存中二进制
对应的十进制前 7 位可信、无十进制四舍五入”的法则!
再继续说:具体浮点数格式
// float(32位)结构 // 符号位(1) 指数位(8) 尾数位(23) // 0 10000000 10000000000000000000000 // 正 控制范围 决定精度(约7位十进制)// double(64位)结构 // 符号位(1) 指数位(11) 尾数位(52) // 0 10000000000 1000000000000000000000000000000000000000000000000000 // 正 范围更大 精度更高(约15位十进制)// 截断:double转float时,尾数位从52位砍到23位一步步说各种计算:
妈逼的问豆包说考研也考小数转二进制,真的恐怖,完全没印象。
之前刷 KMP 说考研也有,真的恐怖。
阴影:无论现在比之前强多少倍,都觉得之前好难,代入曾经的处境,感觉本科期末考试都比浙大复试机试的算法题难~~~~(>_<)~~~~
整数转二进制用除 2 取余,小数转二进制用乘 2 取整,规则不同:
// 小数转二进制步骤(以0.625为例): 0.625 × 2 = 1.25 → 取整数1(小数点后第1位) 0.25 × 2 = 0.5 → 取0(第2位) 0.5 × 2 = 1.0 → 取1(第3位) // 结果:0.101(二进制)= 0.625(十进制),精确表示// 无限循环的例子(0.1十进制): 0.1 × 2 = 0.2 → 0 0.2 × 2 = 0.4 → 0 0.4 × 2 = 0.8 → 0 0.8 × 2 = 1.6 → 1 0.6 × 2 = 1.2 → 1 0.2 × 2 = 0.4 → 0(开始循环) // 结果:0.0001100110011...(无限循环),只能近似存储核心:小数转二进制是乘 2 取整数部分,直到小数部分为 0 或达到精度上限。
本质是因为整数和小数的 “位权” 逻辑完全相反—— 整数是 “2 的正次幂累加”,小数是 “2 的负次幂累加”,
比如十进制
5是101(二进制):1×2² + 0×2¹ + 1×2⁰ = 4+0+1=5要找到每一位的 “1 或 0”,用除 2 取余最直接:
除以 2,余数就是当前最低位(对应
2⁰);商继续除 2,余数是下一位(对应
2¹);直到商为 0,把余数倒过来就是结果。
// 以十进制5转二进制为例: 5 ÷ 2 = 2 余 1 → 最低位(2⁰位)=1 2 ÷ 2 = 1 余 0 → 2¹位=0 1 ÷ 2 = 0 余 1 → 2²位=1 商为0停止,余数倒序 → 101(二进制)小数的每一位,代表的是 “2 的负次幂”,比如十进制0.625是0.101(二进制):1×2⁻¹ + 0×2⁻² + 1×2⁻³ = 0.5 + 0 + 0.125 = 0.625要找到每一位的 “1 或 0”,就得顺着 “负次幂从高到低”(即小数点后第 1 位→第 2 位→…)来:
小数点后第 1 位对应
2⁻¹=0.5,想知道这一位是 0 还是 1,只要看 “小数是否≥0.5”—— 乘 2 之后整数部分是 1,就说明≥0.5,这一位是 1;整数部分是 0,就说明 < 0.5,这一位是 0;
去掉整数部分,剩下的小数继续乘 2,判断下一位(对应
2⁻²=0.25);直到小数部分为 0(能精确表示),或达到存储上限(比如 float 的 23 位尾数,只能近似)。
比如你之前纠结的
0.1(十进制):乘 2 得
0.2→整数 0(第 1 位 0),剩0.2;再乘 2 得
0.4→整数 0(第 2 位 0),剩0.4;再乘 2 得
0.8→整数 0(第 3 位 0),剩0.8;再乘 2 得
1.6→整数 1(第 4 位 1),剩0.6;再乘 2 得
1.2→整数 1(第 5 位 1),剩0.2;… 这时又回到
0.2,开始循环,所以是0.000110011…(无限循环)—— 不是计算机 “粗略”,是二进制根本没法用有限位表示它,就像十进制没法用有限位表示1/3=0.333…一样。一句话总结:规则不同,只因 “位权方向相反”
类型 位权逻辑 转换规则 核心原因 整数 2⁰、2¹、2²…(正次幂) 除 2 取余(倒序) 从低次幂到高次幂,找每一位 1/0 小数 2⁻¹、2⁻²、2⁻³…(负次幂) 乘 2 取整(正序) 从高次幂到低次幂,找每一位 1/0 例子里浮点数都是
0.几的,但本质是按科学计数法表示:4.3342 → 1.00001011000111100100011×2²(二进制),尾数部分是从第一个非 0 数开始,即显式尾数 23 位,含隐藏位共 24 位二进制尾数。但这个1无需实际存储(硬件默认存在),所以叫“隐藏位”。你看到的“1.”是逻辑表示,实际存储的只有小数点后的23位尾数。
计算机存储浮点数时,有个强制规则:必须把二进制数转成 “小数点前只有 1” 的科学计数法(这叫 “归一化”),目的是让存储更高效、避免重复冗余 —— 所以二进制里永远只有 “1.xxxx” 的形式,不可能出现 “3.xxxx”“2.xxxx”!举个实际例子,比如你想存 “6.5”(十进制):
先转二进制:6.5(十进制)= 110.1(二进制);
按规则归一化:把小数点左移 2 位,变成 1.101 × 2²(二进制)—— 这里小数点前只能是 1,不可能是 3、4 或者其他;
最后存储:只存 “符号位(0,正)+ 指数位(2+127=129→二进制 10000001)+ 尾数位(101000...0,101 后面补 0 至 23 位)”,小数点前的 1 固定不存。
为什么要这么设计?
因为二进制只有 0 和 1,比如 101、1100、0.0011 都能通过移动小数点,变成 “1.xxxx” 的形式,这样小数点前的数字永远是 1,没必要浪费 1 位去存,能多省 1 位给尾数位提升精度 —— 这是浮点数存储的核心优化设计,不是 “我只举 1.xxxx 的例子”,而是规则本身就不允许出现其他数字!
比如:
float 是 “1(小数点前)+22 位(小数点后)=23 位有效数字。
double 是 “1(小数点前)+51 位(小数点后)=52 位有效数字”,核心是 “包含小数点前的 1,不是只算小数点后”。
这里只是叙述好理解,记住有效数字是给十进制用的
日常说的十进制小数精度是:小数点后几位精度,但计算机浮点数的 “精度” 是 “二进制尾数位数”,从第一个非零数字开始,总共能存多少位尾数。
零零碎碎说了这么多,开始说咋存到计算机里:
比如
3.14:/*3.14的float表示(简化核心步骤):第一步先转二进制: 整数部分3 → 二进制11 小数部分0.14: 0.14×2=0.28 → 取整数0 0.28×2=0.56 → 取0 0.56×2=1.12 → 取1 0.12×2=0.24 → 取0 0.24×2=0.48 → 取0 0.48×2=0.96 → 取0 0.96×2=1.92 → 取1 0.92×2=1.84 → 取1...(不断乘2取整,直到近似) 小数部分近似为0.00100011... 合起来:3.14 ≈ 11.00100011...(二进制) 最后就是:11.0010001111010111000011(近似值)第二步科学计数法:1.10010001111010111000011 × 2¹(小数点左移1位)第三步拆分float的32位: 符号位:0(正数,固定规则) 指数位:1+127=128 → 二进制10000000(8位,固定偏移127) 尾数位:10010001111010111000011(取小数点后23位,固定规则)最终32位二进制: 0 10000000 10010001111010111000011备注: 符号位(第1位):0=正,1=负 指数位(中间3位):表示数值大小范围,类似10的多少次方 尾数位(最后4位):表示数值精度,类似小数点后几位指数位计算规则固定: 8位指数的二进制值转成十进制后,必须减去127才是实际指数(127是固定偏移量,永远不变) 例:指数位二进制10000000 → 十进制128 → 实际指数=128-127=1(规则固定)尾数位规则固定: 23位尾数永远表示"小数点后的二进制数",且前面默认隐藏一个"1"(永远不变) 例:尾数位100...0 → 表示0.1(二进制) → 实际尾数=1+0.1=1.1(二进制,规则固定)再比如:
// 尾数位是"小数点后的二进制数",规则固定: // 尾数位第1位 = 1/2¹,第2位=1/2²,第3位=1/2³...以此类推// 例:尾数位是 100...0(只有第1位是1,其余22位是0) // 计算:1×(1/2¹) + 0×(1/2²) + ... + 0×(1/2²³) = 1/2 = 0.5(十进制) // 对应二进制小数就是 0.1(二进制的0.1等于十进制的0.5)// 所以:尾数位100...0 → 二进制小数0.1 → 十进制0.50.1 十进制 → 二进制是无限循环小数 0.0001100110011... 所以计算机里存小数必然只能是近似值,规范化后是 1.100110011...×2⁻⁴。
浮点数的二进制科学计数法首位必为 1,硬件电路设计时直接默认这个 1 存在,无需额外存储,所以叫 “隐藏位”,只存小数点后的尾数(如 float 存 23 位、double 存 52 位)。你看到的 “1.” 是逻辑表示,实际存储的只有小数点后的 23 位尾数。
再说范围:
在 64 位机器上,这些类型的二进制有效数字位数是固定的(与机器位数无关):
int:无 “有效数字” 概念,它是 32 位整数(范围 ±21 亿左右),能精确表示所有在此范围内的整数。
float:32 位浮点,二进制有效数字为 23 位(归一化后是 “1 + 22 位小数”),约等于 7-8 位十进制有效数字。
double:64 位浮点,二进制有效数字为 52 位(归一化后是 “1 + 51 位小数”),约等于 15-17 位十进制有效数字。
简单说:float 约 7 位十进制精度,double 约 15 位,int 是精确整数(无精度限制,只看范围)。
Q:可是我记得浮点数比 int 位数多多了啊?之前刷 acm 的时候大数都用 double,难道那些用起来都是不精确的?这也太颠覆我的认知了!
A:
int 十进制范围:-2³¹ ~ 2³¹-1(约 ±21 亿)
float 十进制范围:±1.175×10⁻³⁸ ~ ±3.4×10³⁸
double 十进制范围:±2.2×10⁻³⁰⁸ ~ ±1.8×10³⁰⁸
- long long 十进制范围:64 位有符号的, -2⁶³ ~ 2⁶³-1 能精确表示该范围内所有连续整数。
ACM 中用 double 处理大数是因范围远超 int,虽 double 仅有 17 位十进制精确的(2^53),但多数题目只需近似结果或未超精度范围,double 精确范围覆盖大部分场景;若需精确大整数,需用高精度算法(如字符串模拟),真需连续整数精确表示时会用 long long 而非 double,只是你没注意这种场景区分。
double 仅能精确表示 ±2⁵³ 内的所有整数,超过后会 “跳数”(间隔随数值增大而变大),非整数也仅能精确表示有限个(多数小数需二进制近似存储),即范围内并非所有数都能精确表示,连 1e8+1 都表示不了。
总位数:float(32 位)、double(64 位)确实比 int(32 位)的总位数多(double 是 int 的 2 倍)
有效数字位数:指能精确表示的数字精度
int 的 32 位全用来存整数,能精确表示所有 ±2³¹-1 范围内的整数(无精度损失)
float 的 32 位里,1 位符号 + 8 位指数 + 23 位尾数,实际有效数字只有 23 位二进制(≈7 位十进制)
double 的 64 位里,1 位符号 + 11 位指数 + 52 位尾数,有效数字 52 位二进制(≈15 位十进制)
int 追求 “整数范围内绝对精确”,float/double 追求 “覆盖极大范围(含小数和超大数)但精度有取舍。
比如拿 32 位的 int 和 32 位的 float 比:
int 的 “强项” 是:能精确表示 -2147483648 到 2147483647 之间的每一个整数(总共约 42 亿个整数,一个不差,全是精确值);
但 int 的 “弱项” 是:只能存整数,不能存小数(比如 0.1、3.14 都存不了),也存不了比 21 亿大的数(比如 1000 亿就超出范围了)。
而 float 的 “强项” 是:
能存小数(0.1、3.14 都能存,虽然不一定绝对精确);
能存远超 21 亿的数(比如 10^38 这么大的数都能覆盖,范围比 int 大几个数量级);
但 float 的 “弱项” 是:在它的范围内,不是所有数都能精确表示—— 比如整数超过 2^24(约 1677 万)后,float 就没法精确表示每一个整数了(会跳着存,比如 16777217 存成 float 会变成 16777216),小数更是大多只能存近似值(比如 0.1 存成 float 是二进制的近似值)
简单说:
如果你要处理的是 “21 亿以内的整数”(比如统计人数、计数),int 比 float 强 —— 因为 int 全精确,float 可能失真;
但如果你要处理 “小数”(比如温度、长度)或 “超大数 / 超小数”(比如星球距离、原子质量),int 完全没用,只能靠 float/double—— 哪怕精度有取舍,至少能覆盖这些场景。
起初以为范围指的是,比如 1 ~ 10 总共 10 个数字这是 int ,而 1 ~ 2 里搞小数就有 10 个了,感觉浮点数应该是范围小啊,但重点是 float 可以表示 1e38 (10^38)这种 int 完全碰不到的范围。
且浮点数是稀疏的:
int 能精确表示 1e8、1e8+1、1e8+2、...、1e8+15(16 个连续整数);
但 float 只能表示 1e8、1e8+16、1e8+32...(中间 15 个整数全 “空着”,存不了)。
int 表示 1 ~ 100 间隔永远是 1,没空隙。
起初觉得 double 居然无法表示 1e8+1 很不可思议,现在懂了:
- 1e8 转二进制后,数值太大,23 位尾数位只能精确表示 “每隔 16 的整数”(因为此时最小间隔 = 2^(指数位 - 23)=16);(1e8 大概是 2^27,所以 2^(27 - 23) = 16)
解释下为啥是跳 16:
对于实际计算机里指数的存储值: 27 + 127 = 154,所以 8 位指数位存的是 154(二进制 10011010)。但这是 “指数怎么存” 的问题,和 “间隔多少” 无关。 算相邻值间隔:间隔 = 2^(实际指数 - 尾数位宽度),尾数位宽度是 23,所以间隔 = 2^(27-23)=2^4=16,这一步用的是 “实际指数 27”,不是 “指数位存储值 154”。
若实际指数是 1,单精度 float 的相邻可表示值间隔 = 2^(1-23)=2^(-22)≈0.000000238。
若实际指数 9 时,间隔 = 2^(9-23)=2^(-14)=1/16384≈0.000061035。例:若一个 float 实际值为 2^9=512,下一个可表示值是 512 + 1/16384≈512.000061035。
若实际指数为 23 时,间隔 = 2^(23-23)=1,即此时相邻可表示值间隔为 1。当实际指数为23时,对应的数值范围约为2^23(8388608)到2^24(16777216),此区间内相邻可表示值间隔为1。
为何要加 127 呢?最大的负不会超过 127 吗?
比如表示 0.1 这种小于 1 的小数时,实际指数就是负的:0.1 转二进制是 0.000110011…,规范化后是 1.100110011…×2⁻⁴,这里的实际指数是 - 4(小于 1 的数,二进制科学计数法的指数必为负)。若直接存 - 4,硬件处理负数麻烦,所以用偏移 127 的规则转成 “-4+127=123”,这样指数位存的 123 就是正数。
要让 “负指数” 也变成正数存进 8 位里,最直接的办法是给所有 “实际指数” 加一个固定偏移量—— 选 127 当偏移量(因为 8 位能存的正数范围是 0~255,127 是中间值,能让正负指数加完后都落在这个区间里)。比如:
实际正指数 5 → 5+127=132(正数,能存进 8 位);
实际负指数 - 1 → -1+127=126(正数,也能存进 8 位)
8 位能存 0 ~ 255 共 256 个偏移值,但不能全用:
偏移值 0(全 0):留给 “非规范化数”(比如极接近 0 的小数);
偏移值 255(全 1):留给 “无穷大”“NaN(不是数)”;
所以有效偏移值只能是 1~254因为 “偏移值 = 实际指数 + 127”,所以 “实际指数 = 偏移值 - 127”:
最小有效偏移值 1 → 实际指数 = 1-127=-126(这是 float 能表示的最小实际指数);
最大有效偏移值 254 → 实际指数 = 254-127=127(这是 float 能表示的最大实际指数);
- 单精度 float(32 位):指数位 8 位,偏移值 127,能表示的指数范围固定为 - 126 到 127(数学意义上的指数)。
双精度 double(64 位):指数位 11 位,偏移值 1023,能表示的指数范围为 - 1022 到 1023,足以覆盖更大的指数(包括你说的几百次方)。
如果需要表示指数超过 127 或小于 - 126 的数,必须使用 double 或 更高精度类型。
当数值大到 2²⁴(约 1677 万)时,float 相邻两数的间隔就会达到 2。
例:
16777216(2²⁴)能被 float 精确存储;
下一个可被精确存储的数是 16777218(间隔 2);
中间的 16777217 无法被 float 精确表示,会被舍入成 16777216 或 16777218。
原因:此时 float 的指数位使得尾数位每增加 1,实际数值就增加 2(2^(指数位 - 23)=2),导致间隔固定为 2,中间的数存不下。
Q:中间的 16777217 无法被 float 精确表示??直接16777217 .00000不就是吗
A:16777217 是整数,但 float 存它会失真 —— 核心是float 的 23 位尾数位,存不下 2²⁴+1 这个数的二进制细节:
先算二进制:16777216(2²⁴)是
1000000000000000000000000(1 后面 24 个 0);16777217 是1000000000000000000000001(1 后面 23 个 0+1 个 1)。float 尾数位只有 23 位,存
1000000000000000000000001时,最后那个 “1” 超出了 23 位的存储上限,必须被舍弃。所以 float 存 16777217 时,实际存的是
1000000000000000000000000(即 16777216),和 16777216 的存储值完全一样 —— 看似是整数,却因尾数位不够,被 “吞” 成了前一个数。简单说:float 不是 “能存所有整数”,而是 “只能存二进制位数≤24 位的整数”(2³+1=9 开始就有部分整数存不了,到 2²⁴+1=16777217 时,直接完全失真)
所以只能存 1e8、1e8+16、1e8+32… 中间 15 个整数(1e8+1 到 1e8+15),因为它们的二进制差异超出了 23 位尾数位的分辨能力,存进去会被 “舍入” 成相邻的可表示数,等于存不了。
简单说:数值越大,float 能 “卡住” 的整数间隔越宽,中间的就漏了拿 100(十进制)举例:
100 转二进制是
1100100,归一化后是1.1001×2⁶,float 能精确存它;要存 100.1(十进制):二进制是
1.100100001100110011...×2⁶,但 float 尾数位只有 23 位,存不下所有小数位,最终存的是近似值(约 100.099998474);再存 100.0000001(十进制):float 的精度只能到小数点后 6-7 位,这个数会直接被舍入成 100.0,连近似值都存不了。
结论:float 在小数 / 大数场景下,连很小的数值差异都可能存不住,这就是 “稀疏”。再比如 0.1(十进制)
转二进制是无限循环:0.0001100110011...(永远循环 "0011")
归一化后是 1.1001100110011...×2⁻⁴,无论怎么截都是拿到有限位版本,尾数位都存不完,只能近似
定点数:
预先规定小数点位置、整数和小数部分位数固定的数值类型(如规定小数点后 2 位,123 就表示 1.23,1234 就表示 12.34)。意义是精确存
定点数:比如规定 “小数点后 2 位”,用整数 123 表示 1.23,存的就是 123(精确,无误差);
浮点数:存 1.23 会变成 1.2299999713897705(二进制无限循环导致的近似值),算金额时会差分分钱。因为 1.23 在二进制里是无限循环小数(0.00111101011100001010001111010111...),而 float/double 的尾数位有限(float 23 位,double 52 位),只能存截断后的近似值:
float 存 1.23 实际是 1.2299999713897705。
double 存 1.23 实际是 1.229999999999999982236431605997495353221893310546875
但整数的截断 int 转 short 是直接砍掉:比如 int 是 4 字节(32 位),short 是 2 字节(16 位)。要是把 int 类型的
0x12345678(二进制 32 位:00010010 00110100 01010110 01111000)转成 short,就只留低 16 位(01010110 01111000,对应0x5678),直接把前面的高 16 位(00010010 00110100,对应0x1234)“砍” 掉 —— 这被砍掉的前 16 位,就是 “超出的高位”。确实从 “数值接近度” 看,砍高位会让结果和原数偏差极大(比如刚才的 0x12345678 砍高位后变成 0x5678,差了上百万),但这么设计的核心原因是计算机底层的 “小端存储” 和 “位操作逻辑”—— 低位字节 / 位在内存中更靠后,操作时优先保留能直接映射到目标类型的低位,高位本就超出了目标类型的存储范围,只能丢弃。
十进制科学计数法对第一位没有必须为 1 的严格要求,只要满足 1≤|a|<10 即可(如 3.14×10²、9.8×10⁻³ 都是合法的)。
- 系数部分(即第一位所在的数)需满足 1≤|a|<10,若第一位是 0,系数会小于 1(如 0.5×10³),不符合规范,此时需调整指数使系数落在 [1,10) 区间内(修正为 5×10²)。
二进制科学计数法在 IEEE 754 标准中要求第一位必须是 1,是为了实现唯一表示(规范化):二进制数只有 0 和 1 两个数字,任何非零二进制数都可表示为
1.xxxx...×2ⁿ的形式,这样能固定首位为 1 并隐含存储,节省 1 位存储空间以提高精度。
至此说完了,但还有个
static_cast的例子查看代码
class Base {}; class Derived : public Base {}; // Derived继承Base Base* b = new Derived(); // 父类指针指向子类对象(多态基础) Derived* d = static_cast<Derived*>(b); // 安全地把父类指针转回子类指针又是一场硬仗:
继承:在 C++ 中,继承的符号就是
:(冒号)。格式是:class 子类名 : 继承方式 父类名 { ... };。class Derived : public Base {};Derived 继承自 Base。
class Derived : public Base {};:让Derived(子类,即派生类)拥有Base(父类,即基类)的所有public成员(变量和函数)。继承只能继承public的东西。
new Derived()会做两件事:
在内存中创建一个
Derived类的对象返回这个对象在内存中的地址(就像
&a返回变量a的地址)父类指针指向子类对象:
Base* b = new Derived();
含义:用父类类型的指针
b,指向子类Derived的对象。为啥能这样:因为
Derived是Base的 “儿子”,儿子肯定是父亲的一种。C++ 规定,Base* b是 “只能指向Base类型对象” 的指针,但因为Derived继承了Base,C++ 允许这种 “父类指针指向子类对象” 的写法。不能子指向父。限制:通过
b只能只能访问Base里有的定义的成员,不能直接用Derived独有的成员。
多态(基础)
简单说:同样的操作,不同对象有不同反应。
举例:如果
Base有函数say(),Derived重写了say(),那么:
通过
Base* b调用b->say()时,会执行Derived的say()(这就是多态)。为什么有用:不用管具体是哪个子类,用父类指针就能统一操作,实际执行的是子类的实现。
Derived* d = static_cast<Derived*>(b); // 安全地把父类指针转回子类指针:如果 Derived 类有自己的函数(比如
der_haha ()),直接用父类指针 b 调用b->der_haha ()会报错(因为 b “不认识” 子类特有函数),但转成 Derived * 后,d->derhaha () 就能正常调用。起手用父类指针
Base*的主要目的就是简化代码、统一操作。
没有父类指针:调用时要 “区分每个子类”
查看代码
// 专门给Dog调用的函数 void letDogCry(Dog* d) {d->cry(); // 汪汪 }// 专门给Cat调用的函数 void letCatCry(Cat* c) {c->cry(); // 喵喵 }// 专门给Bird调用的函数 void letBirdCry(Bird* b) {b->cry(); // 叽叽 }// 用的时候还得分别传不同子类的指针 Dog* dog = new Dog(); letDogCry(dog); // 只能传Dog*Cat* cat = new Cat(); letCatCry(cat); // 只能传Cat*有父类指针:调用时 “不用区分子类”
查看代码
// 一个函数搞定所有动物,不管是Dog/Cat/Bird还是新增的Pig void letAnimalCry(Animal* a) {a->cry(); // 自动执行对应子类的cry() }// 用的时候,不管是啥子类,直接传就行 Animal* dog = new Dog(); letAnimalCry(dog); // 汪汪Animal* cat = new Cat(); letAnimalCry(cat); // 喵喵// 新增Pig子类,不用改letAnimalCry(),直接用 Animal* pig = new Pig(); letAnimalCry(pig); // 哼哼
这仗好像没有想象中那么硬
至此说完,出于好奇,再探究下多态
先明确:之前讲的 “基础多态”,其实缺了一个关键前提!
我之前举的
Base* b调用say ()执行Derived的say (),其实不行,必须满足一个条件:父类的say()函数要加virtual关键字,即虚函数:查看代码
class Base { public:// 父类函数必须加virtual,才能触发多态!virtual void say() { cout << "我是父类Base" << endl; } };class Derived : public Base { public:// 子类重写(函数名、参数、返回值和父类虚函数完全一样)void say() override { cout << "我是子类Derived" << endl; } };// 这时用父类指针调用,才会执行子类的say()(多态效果) Base* b = new Derived(); b->say(); // 输出“我是子类Derived”如果父类的
say()没加virtual,哪怕子类重写了,b->say()也只会执行父类的say()—— 这时候就没有多态!
override是显式声明 “该函数重写基类虚函数” 的关键字,但它不是强制要求 —— 只要子类函数与基类虚函数的函数签名(返回值、参数列表、const 属性)完全一致,不加override也行。
override必须写在成员函数参数列表和const/volatile限定符(如果有)之后、函数体之前,是语法硬性规定。
补充俩东西:
其一、虚析构函数:
如果父类指针指向子类对象,且父类析构函数没加
virtual,delete 指针时会只析构父类、不析构子类(内存泄漏)—— 所以多态场景下父类析构必须是虚函数。深入抽插掰开揉碎理解:
只需要在父类的析构函数前加
virtual,子类的析构函数哪怕不加virtual,delete父类指针时也会同时析构父类和子类。情况 1:父类析构没加
virtual(会内存泄漏)查看代码
class Base { public:// 父类析构没加virtual~Base() { cout << "父类Base析构了" << endl; } };class Derived : public Base { public:// 子类析构(没加virtual)~Derived() { cout << "子类Derived析构了" << endl; } };// 父类指针指向子类对象 Base* b = new Derived(); delete b; // 销毁对象运行结果:只输出 “父类 Base 析构了”。
问题:子类
Derived的析构函数没被调用 —— 如果子类里有自己申请的资源(比如new的变量),这些资源就永远没人清理,造成 “内存泄漏”。情况 2:父类析构加了
virtual(正常析构)查看代码
class Base { public:// 父类析构加virtual!virtual ~Base() { cout << "父类Base析构了" << endl; } };class Derived : public Base { public:// 子类析构不用加virtual(也可以加,不影响)~Derived() { cout << "子类Derived析构了" << endl; } };Base* b = new Derived(); delete b;运行结果:先输出 “子类 Derived 析构了”,再输出 “父类 Base 析构了”。
为什么:父类析构加了
virtual后,delete父类指针时,会先找到指针实际指向的子类对象,调用子类析构,再自动调用父类析构 —— 资源完全清理,没有泄漏。
virtual(虚函数)的特殊作用是让函数调用跟随 “对象实际类型” 而不是 “指针类型”。析构函数加
virtual后,delete 父类指针时,编译器会先查这个指针实际指向的是哪个子类对象,先调用子类析构,再调用父类析构(保证父子都清理);不加virtual,就只按 “父类指针类型” 调用父类析构,不管实际指向的是子类(导致子类资源没清理)。
delete 指针的作用是销毁指针指向的对象,同时自动调用该对象的析构函数(清理资源)。比如Base* b = new Derived(); delete b;就是销毁b指向的Derived对象,触发析构。第一步:先理清 “对象、new、delete、析构” 的基础关系(和 virtual 无关)
不管有没有 virtual,先记住 3 条铁律:
对象怎么来的,就怎么销毁
不写
new(栈上对象):比如Derived d;,程序结束时会自动调用析构函数,不用你管。写
new(堆上对象):比如new Derived();,必须用 **delete 指针** 手动销毁 ——delete的作用就是:先调用对象的析构函数(清理资源),再释放堆内存。析构函数的本职工作析构函数(
~类名())是对象销毁前的 “清理员”:比如对象里new了数组、文件,析构函数里要写delete[]、关闭文件,确保资源不浪费。指针只是 “指向对象的工具”比如
Base* b = new Derived();,b是父类指针,但它指向的实际是个子类对象(new Derived()创建的)。delete b本质是 “销毁b指向的那个对象”,不是 “销毁指针本身”。- b 指针本身是在栈上的,会随作用域结束自动销毁,和
delete b没关系,delete b只销毁 b 指向的堆上的子类对象。第二步:加了 virtual,到底改了啥?(核心是 “调用哪个析构函数”)
virtual只解决一个问题:delete 指针时,到底调用 “指针类型对应的析构”,还是 “对象实际类型对应的析构”?用两个例子对比,瞬间清晰:例子 1:父类析构没加 virtual(只析构父类)
class Base { ~Base() { 清理父类资源; } }; // 没virtual class Derived : public Base { ~Derived() { 清理子类资源; } };Base* b = new Derived(); // 指针是Base*,实际对象是Derived delete b; // 关键:没virtual,只按“指针类型(Base)”调用析构结果:只调用
~Base()(清理父类),不调用~Derived()(子类资源没清理 → 内存泄漏)。→ 问题根源:没 virtual 时,编译器 “认指针类型”,不认对象实际是谁。例子 2:父类析构加了 virtual(先析子、再析父)
class Base { virtual ~Base() { 清理父类资源; } }; // 加了virtual class Derived : public Base { ~Derived() { 清理子类资源; } };Base* b = new Derived(); delete b; // 有virtual,按“对象实际类型(Derived)”调用析构结果:先调用
~Derived()(清理子类),再自动调用~Base()(清理父类) → 资源全清。→virtual的魔法:让编译器 “认对象实际是谁”,不是只看指针类型。第三步:把所有知识点串成一句话
堆上对象(
new出来的)必须用delete 指针销毁,delete会触发析构;没
virtual:delete 父类指针只调用父类析构(子类资源漏清);有
virtual:delete 父类指针会先调用对象实际类型(子类)的析构,再调用父类析构(父子都清)。感觉豆包的回答不那么烂了,不知道是我骂的还是咋的。大模型就跟AI生视频生图一样,多试试结果就不一样,大概大模型的训练给到服务器分配不均不同时间段不同账号要多试多训练多生才行。抽卡
其一、虚析构函数结束
其二、纯虚函数与抽象类:
一句话说清:纯虚函数(
=0)是父类(抽象类)设的 “必须完成的任务”,自己不能实例化对象,子类必须重写这个函数才能用,比如 “形状” 规定 “必须能算面积”,圆和方形必须各自实现才算合格:
纯虚函数:
virtual void say() = 0就是告诉子类:“这个功能我只定规矩,具体实现你们自己写,不写就不让用”。抽象类:有纯虚函数的类(比如带
say()=0的Base),不能直接new Base()创建对象 —— 因为它是 “半成品”,缺子类必须补的功能。子类必须重写:
Derived继承抽象类Base后,必须写void say() { ... }(实现父类的纯虚函数),否则Derived也会变成抽象类,不能创建对象。查看代码
class Shape { // 抽象类 public:virtual double area() = 0; // 纯虚函数:必须算面积 };class Circle : public Shape { public:double area() { // 必须实现,否则Circle也是抽象类return 3.14 * r * r; // 圆的面积公式} private:double r; // 半径 };// 现在才能用: Circle c; // 合法,因为Circle实现了area() Shape s; // 错误!Shape是抽象类,不能创建对象就算子类重写了父类的纯虚函数,父类作为抽象类也依然不能直接创建对象,只能用父类指针指向重写了纯虚函数的子类对象。
有纯虚函数的类才是抽象类—— 纯虚函数是抽象类的 “必要条件”,但抽象类不只是 “有纯虚函数” 这么简单,它还有 “不能直接创建对象、强制子类重写纯虚函数” 的特性。比如:
只写
class A { virtual void func() = 0; };:A有纯虚函数,是抽象类,不能new A(),子类必须重写func()才能用。- 若
class B { virtual void func() = 0; void show() {} };:B除了纯虚函数func(),还有普通函数show(),但它依然是抽象类,核心还是 “有纯虚函数”。一句话总结:抽象类的核心标志是 “包含纯虚函数”,但抽象类可以同时有普通成员。
人只有虚函数的类是普通类。
不知道是不是开窍了,看东西学东西快了,上次是刷算法题中后期觉得代码能力突飞猛进
其二、纯虚函数与抽象类结束
至此 关于
static_cast的说完了(自己展开了这么多东西)
碎碎念:
又看到公众号推送
质疑自己问豆包
我这样做是不是感动自己毫无用处,就像靠网络热搜诉苦的热点事件一样,就像爸爸的病
查看代码
他们每天在家什么也做不了 只有我可以带来好消息 儿子出息之类的我热。起码学就可以会 但爸爸的病,只能听天由命爸爸妈妈的希望是我 而我的希望。是让父母开心 虽然妈妈一直说,希望我做个平凡普通人他们培养的都是根基不牢的速成垃圾狗 他们自己又都是商人,没人可以帮我是我不够努力是我不够努力 我只要学完就可以离开这里,南疆,耗子,建筑工地,打更大爷室友,真的是吃不饱,挨冷受冻,夏天又是厚衣服。而爸爸的病,永远好不了了 真的好累好累 何时能熬出头 何时能看到光亮 何时能出人头地 再逼自己一把 再少浪费时间博客园图标又变了


,好像加载我的万字博客变快了。
关于
reinterpret_cast(东西很少说完拉到):服务端开发中,
reinterpret_cast几乎不用,但面试可能考两点:
作用:二进制层面强转(如指针与整数互转、不同指针类型互转),完全绕过类型检查。
形式一、二进制层面强转:直接操作内存二进制值,不考虑类型语义(比如把 32 位 int 的 4 字节二进制直接当指针地址)。
应用场景:硬件驱动比如写死某个器件地址然后指针指向(服务端无)。
形式二、指针与整数互转:指针存的地址(整数)和整数直接互换。场景:序列化地址(服务端极少,有更安全方式)。
关于形式一和二,合在一起举个例子(学了一下午
reinterpret_cast<char*>(num);用法都是嵌入式硬件的东西,最后质疑了一句,告诉我“大厂LinuxC++服务端开发”岗位不考!!死全家的豆包!!)
上代码:
int num = 100; // char* p = (char*)num; // C风格能写,但危险(把100当内存地址) char* p = reinterpret_cast<char*>(num); // C++必须用reinterpret_cast(明确是“底层二进制转换”), //写法上就提醒你“这步有风险” 这个主要用在硬件寄存器本质是指针与整数互转(将 int 值 100 作为地址赋予 char * 指针); 实现方式是二进制层面转换(直接把整数的二进制位当作指针地址)。
强迫症让我看到就必须研究透彻,但软件开发根本不会用到,少数必须用到比如【在操作系统内核、驱动开发等直接操作硬件地址的场景必须这么写(比如把硬件寄存器地址(整数)转成指针访问)】的时候,后者更好,
char*那种写法模糊,任何转换都如此,而 C++ 风格是把需要转换的场景做了分类,警醒写代码和看代码的人,让他们在用的时候知道这玩意是哪类的,谨慎使用。
cp指向以0x12345678为地址的内存,而一般常用的是下面:int a = 0x12345678; int* p = &a; // 正确:p指向int类型 char* cp = reinterpret_cast<char*>(p);
cp指向变量a的内存地址(p存的是a的地址,cp转成字符指针指向该地址)。将变量a的地址(指针)重新解释为char*类型,用于按字节访问a的内存(如查看整数的字节存储细节)。所以:
当转换变量地址时,加
&(如&num),用于访问变量内存;当转换硬编码地址值(如
0x40020000)时,不加&,用于直接操作指定地址(如硬件寄存器)。reinterpret_cast<T*>(变量值):用值作地址(如硬件地址)
补充指针知识:
int* p = &a;后,只要说p就是&a。这里思考
char*对吗?没问题
地址本身是多字节(如 32 位系统 4 字节、64 位 8 字节);
用
reinterpret_cast将整数转为char*后,char *解引用是访问地址指向的 1 字节数据。要访问 4 字节需手动偏移,而非 char本身自动处理 4 字节。
上面的 100 只是个例子,实际的话是将整数 100 的二进制值(0b1100100)直接作为内存地址,让指针指向该地址。此时如果内存没这个地址就崩溃了。硬件里的用法:
// 芯片手册规定:LED控制寄存器地址是 0x40020000 #define LED_REG_ADDR 0x40020000// 必须把整数地址转成指针才能操作,这里只能用 reinterpret_cast volatile uint32_t* led_reg = reinterpret_cast<volatile uint32_t*>(LED_REG_ADDR);// 通过指针写值,控制LED亮(往这个硬件地址写1) *led_reg = 1;解释:
啥叫优化:
比如写个
int a = 2;后面没操作了,那么g++ -O2 -S test1.cpp -o test1.s # O2开启优化对比汇编里就没这代码。但感觉没啥用就先搁置了,之前写项目的时候各种 CPU 还有力气去探究,现在这个盲猜一屁眼子汇编根本看不懂,既没研究 GDB 有意义,也没写项目看 CPU 那么有必要。(之前学 define 就是没必要搞“使用gcc -E选项查看宏替换后的结果。”)。再比如:
int a=1; a=7;:编译器知道a是普通变量,写1后马上写7,第一个a=1被优化掉,最终程序只执行a=7硬件寄存器的
*led_reg=1:led_reg指向的是硬件 LED 寄存器(不是普通变量),写1这个动作本身会触发硬件电路(比如给 LED 通电),哪怕代码里没再读这个值,这个 “写动作” 也必须执行。如果没volatile,编译器会像优化普通变量一样,直接删掉*led_reg=1—— 结果就是 LED 没通电,不亮。加volatile就是告诉编译器:“这是硬件地址,写动作必须实际执行,别优化掉,防止的是编译器对*led_reg = 1梳理:
#define LED_REG_ADDR 0x40020000芯片出厂时,硬件工程师就把控制 LED 的电路 “焊死” 在内存地址0x40020000上(手册会写死这个数)。
volatile uint32_t* led_reg = ...
用
reinterpret_cast把0x40020000这个整数,强制转成 “指向 32 位数据的指针”加
volatile是因为:这个地址的数据会被硬件直接控制(比如断电时自动变 0),告诉编译器 “别瞎优化,每次读写都要真的去访问这个地址”
*led_reg = 1往0x40020000这个硬件地址写 1 → 硬件电路收到信号 → LED 灯亮。缺了任何一步的后果:
没
reinterpret_cast:没法把整数地址转成指针,根本碰不到硬件没
volatile:编译器可能觉得 “写 1 之后没读过,没必要执行”,直接跳过这行 → LED 不亮用 C 风格
(uint32_t*)替代:能运行,但代码里看不出这是 “操作硬件的高危转换”,后续维护者容易误改
volatile uint32_t*是为了正确操作硬件寄存器而设计的指针类型,uint32_t:表示这个寄存器是 32 位的(4 字节),指针指向的内存单元按 32 位整数处理。合起来,volatile uint32_t* led_reg就是 “指向 32 位、可能被硬件修改的寄存器地址的指针”,配合reinterpret_cast把手册里的整数地址转成这种指针,才能正确控制硬件
质疑自己:
万物相通!感觉虽然什么这些都是硬件工程师的东西,甚至什么 LED 灯啥的,但我通过这个更清晰了字节寻址!!无比透彻!
形式三、不同指针类型互转:比如
int转char,按字节访问对象内存。场景:自定义内存池(服务端极罕见,多用标准库)。
转换后的指针类型与实际内存中的数据类型完全匹配(包括字节长度、布局等)必须由开发者自己保证
int a = 0x12345678; int* p = &a; // 正确:p指向int类型 char* cp = reinterpret_cast<char*>(p); // 开发者需知道:现在按1字节解析int的内存此时
cp指向的地址是对的(确实是a的地址),但*cp只会读取0x78(int 的第一个字节),而非完整的0x12345678。这种 “按 1 字节解析” 本身不是错误,但必须是开发者明确想要的行为—— 即完全由人来确保逻辑正确,编译器不做任何检查。
风险:依赖开发者保证类型匹配,完全绕过类型检查,编译器不验证转换合法性,对错全靠开发者。服务端几乎不用,仅需知道 “风险高、禁用为主” 即可。
这个
reinterpret_cast最不重要的,甚至不会也行,我研究太深了!!唉wx搜“后遗症”,博客写的都他妈想吐了至此 关于
reinterpret_cast也说完了。
关于
dynamic_cast:在程序运行时检查父类指针是否真的指向某个子类对象,安全就返回有效指针,否则返回空(防错)。
查看代码
// dynamic_cast的核心作用:安全地将父类指针转换为子类指针 // 前提:父类必须有虚函数(支持多态)// 父类:含有虚函数(这里是虚析构),支持多态 class Base { public:virtual ~Base() = default; // 虚析构函数,满足dynamic_cast的使用条件 }; // 子类:公有继承父类 class Derived : public Base {};int main() {// 父类指针指向子类对象(多态场景)Base* b = new Derived();// dynamic_cast会在程序运行时做两件事:// 1. 检查b实际指向的对象是否是Derived类型// 2. 如果是,返回正确的Derived*指针;如果不是,返回nullptr(空指针)Derived* d = dynamic_cast<Derived*>(b);if (d != nullptr) {// 转换成功:d现在可以安全访问Derived的成员} else {// 转换失败:说明b指向的不是Derived对象} delete b; }核心区别在 “安全性检查时机” 和 “使用条件”:
static_cast:编译时转换,不做运行时检查。
必须由程序员保证 “b 确实确实指向 Derived 对象”,否则转换后用 d 操作会出问题(比如崩溃)。
父类可以没有虚函数(不依赖多态)。
static_cast适用范围广,对象转换只是它的功能之一;更快,但风险自负(程序员必须确保转换合法性)。dynamic_cast:运行时转换,会实际检查 “b 是否真的指向 Derived 对象”。
转换失败会返回 nullptr(空指针),能避免错误操作。
必须依赖多态(父类必须有虚函数),否则编译报错。
dynamic_cast仅用于 “类层次间的转换”(父转子或子转父),是专门为多态场景设计的。但开销略大(需要查类型信息);所以,之前的Derived* d = static_cast<Derived*>(b); // 安全地把父类指针转回子类指针是转完了安全的用,而不是转的时候安全。至此 关于
dynamic_cast也说完了。
刚发现的这个多重引文区块方法,断区间的复制就行
关于
const_cast:
const_cast是专门用于移除或添加变量 const 属性的转换,主要用于临时适配那些要求非 const 参数的旧接口,但通过转换后的指针修改原本的 const 变量是危险的(可能导致不可预期的结果),应尽量避免使用。场景1:修改
const对象查看代码
// const_cast的核心作用:去掉变量的const属性(或加上const属性) // 仅用于指针/引用,且只能操作同一类型的const与非const转换int main() {const int x = 5; // x被声明为const,理论上不可修改//&x 的类型是 const int* ,即指向常量 int 的指针//只能写:const int* px = &x;(此时px是指向常量的指针,不能通过px修改 x 的值) // 直接修改x会编译报错:// x = 10; // 错误:不能给const变量赋值//去掉&x的const属性,得到非const int*指针int* px = const_cast<int*>(&x); // 通过px指针尝试修改"原本是const的x"*px = 10; // 注意:这是危险操作!C++标准未定义这种行为的结果// 可能表面上显示10,但实际可能因编译器优化导致不一致 }因为
x本身是const变量,编译器可能会优化(比如直接用 5 替换x),通过const_cast后的指针修改它,会导致内存中实际值与编译器预期不一致,行为完全不可控。场景2:
const对象调用非const成员函数先说啥叫
const对象,初始化后非mutable的成员变量不能改:查看代码
#include <iostream>class MyClass { public:int normal_num; // 普通成员变量(非mutable)mutable int mutable_num; // 用mutable修饰的成员变量MyClass(int n, int m) : normal_num(n), mutable_num(m) {} };int main() {const MyClass obj(10, 20); // const对象// 错误:普通成员变量在const对象中不能修改// obj.normal_num = 100; // 正确:mutable成员变量在const对象中可以修改obj.mutable_num = 200; std::cout << "普通成员(不可改):" << obj.normal_num << std::endl; // 输出10std::cout << "mutable成员(可改):" << obj.mutable_num << std::endl; // 输出200 }注意:
const对象只能调用类中的const成员函数,不能直接调用非const成员函数;而非const对象既可以调用const成员函数(因为承诺不修改对象),也可以调用非const成员函数。使用
const对象调用非const成员函数时,可以使用const_cast删除对象的const属性,看代码(作者例子太简练没对比):查看代码
class MyClass { public:void non_const_func() { num = 100; } // 非const函数(可能修改成员)int num; };int main() {const MyClass obj{50}; // const对象,初始化num为50// 直接调用会报错:const对象不能调用非const函数// obj.non_const_func(); // 用const_cast去掉const属性MyClass* ptr = const_cast<MyClass*>(&obj);ptr->non_const_func(); // 现在能调用了,但修改了const对象的num! }因为
const对象的内存可能被编译器标记为 “只读”(比如放在只读内存区域)。当你用const_cast强行去掉const属性并调用非const成员函数时,若该函数修改了对象数据,就会试图往只读内存写数据 —— 这直接违反了内存保护规则,可能导致程序崩溃、数据错乱等不可预测的 “未定义行为”(编译器无法保证任何结果)。这里作者也没说清楚,我补充:const_cast设计出来不是让你 “破坏const对象的只读性”,而是为了解决 “少数合法场景下的类型不匹配”—— 它的风险,本质是 “被用错了地方”,而非设计本身有问题。比如它的合法用途:当你调用一个 “参数是非const指针,但实际不会修改数据” 的旧函数时,若你手里只有const指针,就可以用const_cast临时转换类型(前提是你能保证函数真的不修改数据)。// 旧函数:参数是非const指针,但函数内部只读取数据,不修改 void read_data(int* p) { std::cout << *p << std::endl; }int main() {const int num = 10; // 你手里的const变量// 直接传&num会报错(const指针不能转非const指针)// read_data(&num); // 合法使用const_cast:因为你知道read_data不会改数据read_data(const_cast<int*>(&num)); return 0; }这种场景下,
const_cast只是 “解决类型兼容问题”,没有实际修改 const 对象,是安全的。至此 关于
const_cast也说完了
至此学完开始看编程指北大水货的文章(主要是补充):
关于
static_cast:
基本类型转换
指针类型转换(一个指针类型转换为另一个指针类型),就是
Derived那个引用类型转换(上面没说的)
查看代码
Derived derived_obj; Base& base_ref = derived_obj; Derived& derived_ref = static_cast<Derived&>(base_ref); // 将基类引用base_ref转换为派生类引用derived_refclass Base {}; class Derived : public Base {}; Derived d; Base& b_ref = static_cast<Base&>(d); // 子类引用安全转为父类引用
Base& b_ref = static_cast<Base&>(d);
子类引用 → 父类引用(向上转换)
其实这行甚至可以简化为
Base& b_ref = d;(自动隐式转换),加static_cast只是显式强调转换意图。
Derived& derived_ref = static_cast<Derived&>(base_ref);
父类引用 → 子类引用(向下转换)
这不能隐式转换,必须用
static_cast显式转换(前提是base_ref确实指向Derived对象,否则危险)。用处是:当你拿到一个 “父类引用”,但知道它实际指向的是 “子类对象” 时,用
static_cast转成子类引用,就能访问子类特有的成员:
代码:
查看代码
class Base { public:virtual void func() {} }; class Derived : public Base { public:void func() override {}void derivedOnly() { /* 子类特有方法 */ } // 只有子类有这个方法 };int main() {Derived d;Base& b_ref = d; // 父类引用指向子类对象(多态)// 想调用子类特有方法,必须转成子类引用Derived& d_ref = static_cast<Derived&>(b_ref);d_ref.derivedOnly(); // 成功调用子类特有方法 }而且向上转换很有必要,比如定义一个接收父类引用的函数,就能用它处理所有子类对象,不用为每个子类写重复代码:
查看代码
class Base { public:virtual void show() { cout << "Base"; } // 虚函数 }; class Derived : public Base { public:void show() override { cout << "Derived"; } // 重写 };// 接收父类引用的函数 void print(Base& obj) { obj.show(); // 多态:调用子类重写的版本 }int main() {Derived d;print(d); // 子类对象d隐式转为Base&(向上转换),输出Derived }但
dynamic_cast做向上转换没必要,因为子类必然是父类的一种,直接传d就行:查看代码
class Base { virtual ~Base() = default; }; class Derived : public Base {};Derived* d = new Derived(); // 向上转换:子类指针转父类指针 Base* b = dynamic_cast<Base*>(d); // 一定成功,等价于隐式转换 Base* b = d;继续
关于
dynamic_cast:首先,向下类型转换和多态类型检查,统称为安全检查,上面比较远的地方提到了,搜“转换成功”。再说一下吧,这里指北给分成了两个:
- 向下类型转换:
class Base { virtual void dummy() {} }; class Derived : public Base { int a; };Base* base_ptr = new Derived(); Derived* derived_ptr = dynamic_cast<Derived*>(base_ptr); // 将基类指针base_ptr转换为派生类指针derived_ptr,如果类型兼容,则成功多态类型检查:
查看代码
class Animal { public: virtual ~Animal() {} }; class Dog : public Animal { public: void bark() { /* ... */ } }; class Cat : public Animal { public: void meow() { /* ... */ } };Animal* animal_ptr = /* ... */;// 尝试将Animal指针转换为Dog指针 Dog* dog_ptr = dynamic_cast<Dog*>(animal_ptr); if (dog_ptr) {dog_ptr->bark(); }// 尝试将Animal指针转换为Cat指针 Cat* cat_ptr = dynamic_cast<Cat*>(animal_ptr); if (cat_ptr) {cat_ptr->meow(); }
if (cat_ptr)本质是判断指针是否非空:
非空(
true):说明转.换成功,执行meow();空(
false):说明转换失败,跳过meow()。这正是
dynamic_cast安全的核心 —— 通过判断指针是否为空,避免对错误类型的对象调用成员函数(比如给狗调用 “喵喵叫”)。这两部分是从不同角度解释dynamic_cast的功能~
向下类型转换:更偏向 “语法规则层面” 的说明 —— 重点讲
dynamic_cast能把 “基类指针 / 引用” 转成 “派生类指针 / 引用”,还强调了转换失败时的返回结果(指针返回空,引用抛异常)。就像在说 “这个工具能做什么转换,失败了会怎样”。用于多态类型检查:更偏向 “实际应用场景” 的说明 —— 通过
Animal、Dog、Cat的例子,展示dynamic_cast如何在多态对象(有继承 + 虚函数的类体系)中,判断对象的真实类型(比如判断animal_ptr到底指向Dog还是Cat)。相当于在说 “这个工具在实际开发中,怎么帮我们区分不同子类的对象”。
接下来,也是最后一点,就是虚函数的底层原理:
真的好痛苦,这里的知识百转千回以为自己理解了,结果是错的不准确的,~~~~(>_<)~~~~,下面整个内容都在说这个,包括很多零零碎碎的知识
向上转换(子类转父类)是隐式转换,无需虚函数,也无需
dynamic_cast,编译器直接允许。向下转换(父类转子类)需要基类有虚函数,因为
dynamic_cast依赖虚函数表获取运行时类型信息,才能判断实际对象是否为目标子类。所以,基类必须至少有一个虚函数。这里相当多的知识!!
static_cast不要求父类有虚函数,转换时只看 “语法上能不能转”即是否有继承关系,如果是完全无关的类型(比如int*转Dog*),static_cast会在编译时直接报错,因为语法上不允许这种转换。
比如向上转(子类转父类,比如
Dog*转Animal*):安全,因为 Dog 本来就是 Animal 的一种,编译器直接过。比如向下转(父类转子类,比如
Animal*转Dog*):编译器也让过,但不管Animal*实际指向的是 Dog 还是 Cat。如果实际指向的是 Cat,转成Dog*后调用bark(),程序就会出问题(这叫 “未定义行为”,可能崩溃)先看个代码:
查看代码
#include <iostream>// 定义基类Animal class Animal { public:virtual void move() { std::cout << "Animal moves" << std::endl; } };// 定义派生类Dog(继承自Animal) class Dog : public Animal { public:void bark() { std::cout << "Dog barks: Woof!" << std::endl; }void move() override { std::cout << "Dog runs" << std::endl; } };// 定义派生类Cat(继承自Animal) class Cat : public Animal { public:void meow() { std::cout << "Cat meows: Meow!" << std::endl; }void move() override { std::cout << "Cat walks" << std::endl; } };int main() {Animal* animal1 = new Dog();// 情况1:基类指针正确指向Dog对象Dog* dog1 = static_cast<Dog*>(animal1);// static_cast编译通过(语法合法),且运行正常dog1->bark(); // 正确输出:Dog barks: Woof!Animal* animal2 = new Cat();// 情况2:基类指针指向Cat对象(错误类型)Dog* dog2 = static_cast<Dog*>(animal2);// static_cast仍编译通过(只看类型关系,不看实际对象) dog2->bark();// 运行时错误(调用了错误类型的方法)未定义行为:可能崩溃或输出乱码Animal* animal3 = nullptr;// 情况3:基类指针为nullptr(未指向任何对象)Dog* dog3 = static_cast<Dog*>(animal3);// static_cast依然编译通过(不检查指针是否有效)// dog3->bark(); // 运行时错误(访问空指针)直接崩溃// 释放内存delete animal1;delete animal2;//因为 animal3 是 nullptr(没指向任何动态分配的内存),delete 空指针无意义且多余,所以不用写 }
情况 1:转换正确(基类指针确实指向目标子类)→ 运行正常
情况 2:转换错误(基类指针指向其他子类)→ 编译通过但运行出错
情况 3:基类指针为空 → 编译通过但运行崩溃
关于情况 1 不理解为啥不能直接
Dog*,而是要基类再转一下,其实直接用Dog*当然可以,查看代码
// 处理任意动物的函数(多态场景) void processAnimal(Animal* animal) {animal->move(); // 多态调用:Dog会跑,Cat会走// 但如果需要调用子类特有功能(比如让狗叫)// 必须先转成Dog*才能调用bark()Dog* dog = static_cast<Dog*>(animal); // 假设这里确定是Dogif (dog) {dog->bark(); } }int main() {Dog* dog = new Dog();processAnimal(dog); // 子类指针隐式转成基类指针传入(多态)// ... }但就失去了处理 “任意动物” 的通用性种类多就会多写很多代码。
比如
Animal* animal1 = new Dog();改成Dog* dog = new Dog();查看代码
#include <iostream> #include <vector>class Animal { public:virtual void move() = 0; // 纯虚函数,统一接口 };class Dog : public Animal { public:void move() override { std::cout << "Dog runs\n"; }void bark() { std::cout << "Woof!\n"; } };class Cat : public Animal { public:void move() override { std::cout << "Cat walks\n"; }void meow() { std::cout << "Meow!\n"; } };// 统一处理所有动物的函数 void processAllAnimals(const std::vector<Animal*>& animals) {for (auto animal : animals) {animal->move(); // 多态:自动调用对应子类方法} }int main() {// 情况1:用父类指针统一管理std::vector<Animal*> animals;animals.push_back(new Dog());animals.push_back(new Cat());processAllAnimals(animals); // 一行代码处理所有动物,大家都有的可以基类搞//单独的必须转,如需调用子类特有方法,可安全转换if (Dog* dog = dynamic_cast<Dog*>(animals[0])) {dog->bark();}// 情况2:只用子类指针std::vector<Dog*> dogs;std::vector<Cat*> cats;dogs.push_back(new Dog());cats.push_back(new Cat());// 必须分开处理,无法用一个函数统一for (auto dog : dogs) dog->move();//就算是基类都有的move(),也得分开写循环处理,没法用一个函数统一。for (auto cat : cats) cat->move();// 释放内存for (auto a : animals) delete a;for (auto d : dogs) delete d;for (auto c : cats) delete c; }
vector<Animal*>装的是 “各种动物的父类指针”,用processAllAnimals能用同一套代码让所有动物做 “通用动作”(move);而dynamic_cast是为了在需要时针对特定动物做 “专属动作”(比如让第一个动物 —— 狗叫)。如果说多个狗的对象就这么写,对于
vector还是刷完题就忘了,但先搁置,先捋顺学 C++ 那些新东西,vector这玩意我心理有谱。std::vector<Dog*> dogs; dogs.push_back(new Dog()); // 第一个Dog,下标0 dogs.push_back(new Dog()); // 第二个Dog,下标1 // 遍历所有Dog调用move for (int i = 0; i < dogs.size(); i++) {dogs[i]->move(); // 依次调用两个Dog的move }逼迫自己硬头皮看,结果傻逼豆包每次都给新的例子,发现代码看多了真的就熟能生巧了,书读百遍其义自见
至此懂了,但看了上面这么多代码发现个问题,
之前看了很多都是
main里直接处理的(此文搜“就能访问子类特有的成员”)但上面最近的几个出现了带函数的(此文搜“processAnimal”),有啥差别?
追问了好几天,最后自己的总结发给豆包:
我理解父类写死就调用父类,不写死也就是子类重写(重载)那就是调用子类的,统一个人简称为父子都有的,只是会有不同的东西,那写函数里和
main里都行,写函数里是用父类指针统一调用,自动匹配子类实现。这也就是看到的函数processAllAnimals统一处理。而对于只有子类有的,父类就没法搞了,只能转子类,但这种还有个坑点就是,这里必须本身就是子类才行,本身就是父类,转子类也调用不了子类单独的东西。所以写到了
main里没写函数里,用多个if来搞子类独有函数,因为这些函数父类没有,没法用父类指针统一调用,只能转成子类指针后单独处理 —— 这是 “多态覆盖不到的场景”。
至此是全部精华,但我再深入抽插思考发现!其实了解本质后,或者说对于我这种极致细心的钻研的人,会发现,其实说是为了理解多态的覆盖场景,但理论上细节点是,哪怕子类独有的也可以写函数里,因为子类可以自动转父类,转完后,
main里咋写的(那些匹配if语句),函数里咋写就行,比如void processAnimalUnique(Animal* animal) {// 判断是Dog才调bark()if (Dog* dog = dynamic_cast<Dog*>(animal)) {dog->bark();}// 判断是Cat才调meow()else if (Cat* cat = dynamic_cast<Cat*>(animal)) {cat->meow();}// 未来加Bird,得在这加else if(Bird* ...) }只是这种父类根本没有的,通过基类形参转下,就有点 der 了,因为你父类没有这玩意还绕一下子干 JB 啥?而父类有的那种通用的,用父类绕可以完美体现多态!只是,是为了新手便于理解。
仔仔细细阅读我的每个字,点评!!是否正确!正确的不用任何赘述和重新解释
豆包说:
你的理解完全正确,每一个细节都戳中了核心:。所有逻辑都无偏差,完全吃透了多态的适用场景和局限性
再多看几个例子:(先学继承的知识,其他别管,因为这段代码内存泄漏,此文搜“典型内存泄漏”)
查看代码
#include <iostream>class Animal { public:virtual void move() = 0; // 纯虚函数,基类virtual ~Animal() = default; };class Dog : public Animal { public:void move() override { std::cout << "Dog runs\n"; }void bark() { std::cout << "Woof!\n"; } };class Cat : public Animal { public:void move() override { std::cout << "Cat walks\n"; }void meow() { std::cout << "Meow!\n"; } };// 通用处理函数(多态入口) void handleAnimal(Animal* animal) {//基类指针可以接收子类指针,向上转,自动的animal->move(); // 多态行为// 针对Dog的特殊处理if (auto dog = dynamic_cast<Dog*>(animal)) {dog->bark();}// 针对Cat的特殊处理else if (auto cat = dynamic_cast<Cat*>(animal)) {cat->meow();} }int main() {handleAnimal(new Dog()); // 输出:Dog runs \n Woof!handleAnimal(new Cat()); // 输出:Cat walks \n Meow! }就是比默认析构多了个虚
virtual,virtual ~Animal() {}和virtual ~Animal() = default;一样。
注意子转父,自动的,可以:
等号左边是基类,右边是子类。也可以形参是基类,实参是子类
animal -> move();体现的 “多态行为”,简单说就是:同一个函数调用,会根据实际指向的对象类型,执行不同的代码。
当
animal指向Dog对象时,animal->move()实际执行的是Dog类里重写的move()(输出Dog runs);当
animal指向Cat对象时,animal->move()实际执行的是Cat类里重写的move()(输出Cat walks)。虽然调用的都是
move(),但因为animal背后的真实对象类型不同,最终执行的逻辑也不同 —— 这就是多态的核心。不都转成了基类了吗?还知道是子类的?
对,“转成基类指针 / 引用” 只是改变了 “看对象的视角”,没改变对象本身的真实类型和内部数据—— 对象该是 Dog 还是 Dog,该是 Cat 还是 Cat,它的虚函数表(存着真实类型的函数地址)也没变。
比如
Dog*转Animal*,就像你用一个 “动物标签” 贴在了狗身上,但狗本身还是狗,会跑、会叫的本质没变。所以调用animal->move()时,编译器会通过虚函数表找到对象真实类型(Dog/Cat)里的move()实现,而不是基类的 —— 这才是多态的关键:基类视角能调用到子类的真实行为。对象的真实类型在创建时就确定了,转换仅改变指针 / 引用的类型视角,不改变对象本身,
dynamic_cast能通过类型信息认出它原本是 Dog。即函数里子类如果是dog转成了基类,那再转子类的时候还能认识知道自己是dog来的。
父类指针 / 引用指向子类对象时,只能访问父类定义的成员(不能直接用子类特有成员),想用时必须先转回子类指针 / 引用。哪怕父是由子来的
对于
bark,必须if (auto dog = dynamic_cast<Dog*>(animal)) {dog->bark(); }不能
animal->bark()。因为Animal基类里根本没有bark()这个函数!
基类里有的虚函数(比如
move()),用基类指针 / 引用调用时,会自动找到子类重写的版本(多态);基类里没有的函数(比如
bark()),基类指针 / 引用根本 “看不见”,没法直接调用,必须转成子类指针 / 引用才能用。比如
Animal类里声明了virtual void move(),所以animal->move()能触发多态;但Animal里没bark(),animal->bark()会直接编译报错 —— 编译器只认基类里有的函数。
查看代码
void processAnimalUnique(Animal* animal) {if (Dog* dog = dynamic_cast<Dog*>(animal)) {和if (auto dog = dynamic_cast<Dog*>(animal)) {dog->bark(); }两种写法中的
dog都是Dog*类型(指向Dog类对象的指针),auto会自动推导为Dog*,效果完全一致,只是写法不同。类本身没有 “返回值” 概念,这里
dog是指针是因为dynamic_cast<Dog*>明确指定了转换为Dog类的指针类型,和类无关。dynamic_cast的返回类型完全由尖括号里显式指定的类型决定。对于
bark()这种子类特有函数,必须先确定对象的具体类型才能调用,所以需要 “挨个比对”。因为转完了是啥具体不知道。所以必须用
dynamic_cast逐个检查:
先试转成
Dog*,成功就调用bark();失败就试转成
Cat*,成功就调用meow();以此类推,直到找到匹配的类型。
因为传递的实参是不知道是啥,你传猫自己知道是猫,但程序需要把所有可能都写出来
再说个东西:
查看代码
#include <iostream>class Base { public:virtual void func() {} // 基类虚函数 };class Derived : public Base { public:void func() override {} // 重写基类函数void derivedOnly() { std::cout << "调用子类特有方法" << std::endl; } // 子类特有 };class AnotherDerived : public Base { public:void func() override {} // 另一个子类void anotherOnly() { std::cout << "调用另一个子类特有方法" << std::endl; } };int main() {Derived d;Base& b_ref = d; // 父类引用指向子类对象// 直接在main里判断类型并调用特有方法if (auto derived = dynamic_cast<Derived*>(&b_ref)) {derived->derivedOnly(); // 调用Derived特有方法}else if (auto another = dynamic_cast<AnotherDerived*>(&b_ref)) {another->anotherOnly(); // 调用AnotherDerived特有方法} }之前不都是指针吗?这回咋引用了?啥区别?
解释:
父类指针和父类引用 “指向子类对象” 的核心逻辑完全一样(都是多态的体现,都能触发虚函数的子类实现),区别只在语法使用细节上,简单说,起手
Derived d;后:1. 最关键:引用必须 “绑定对象”,指针可以 “为空”
父类引用(比如
Base& b_ref = d;):必须一创建就绑定一个真实的子类对象(d),不能像指针那样写成Base& b_ref;(编译报错),也不能后续改成绑定其他对象。父类指针(比如
Base* b_ptr = &d;):可以先定义成空指针(Base* b_ptr = nullptr;),后续再指向对象,甚至可以中途改指向其他对象(b_ptr = &another_d;)。2. 调用成员的语法:引用用
.,指针用->比如调用虚函数
func():
父类引用:
b_ref.func();(直接用点)父类指针:
b_ptr->func();(用箭头,或解引用后用点:(*b_ptr).func();)3. 向下转换的语法:引用转引用,指针转指针
要调用子类特有方法时:
父类引用转子类引用:
Derived d; // 子类对象 Base& b_ref = d; // 父类引用绑定子类对象(向上转换,天然允许)// 父类引用 转 子类引用:语法里没有额外的& Derived& d_ref = dynamic_cast<Derived&>(b_ref); //尖括号里写的是“Derived&”(目标引用类型), // 括号里放的是原父类引用“b_ref”,没加&取地址(因为b_ref已经是引用了,不是指针)
Derived& d_ref = dynamic_cast<Derived&>(b_ref);(尖括号里写的是Derived&即目标是引用类型,括号里放的是原父类引用b_ref,没加&取地址是因为b_ref已经是引用了,不是指针)转引用:
dynamic_cast<子类&>(父类引用)→ 父类引用不用加 &,因为操作对象就是父类引用,即是引用
父类指针转子类指针:
Base* b_ptr = &d; // 父类指针指向子类对象(这里要加&取地址,因为d是对象)// 父类指针 转 子类指针: Derived* d_ptr = dynamic_cast<Derived*>(b_ptr); // 这里尖括号里是“Derived*”(目标指针类型),括号里放原父类指针“b_ptr”
Derived* d_ptr = dynamic_cast<Derived*>(b_ptr);(这里尖括号里是Derived*即目标是指针类型,括号里放原父类指针b_ptr)转指针:
dynamic_cast<子类*>(父类指针)→ 父类指针若从对象来,才需要先 & 取地址(比如&d)。比如:有Dog d; Animal* a_ptr = &d;(这里 d 是对象,要转成父类指针,就得用 & d 取地址);再比如dynamic_cast<Dog*>(a_ptr),a_ptr本身是指针,就不用加 &。总结:对多态来说,指针和引用“没区别”
不管用指针还是引用,只要是父类类型指向子类对象:
调用虚函数时,都会自动触发子类的实现(多态核心);
要调用子类特有方法,都必须先向下转换;
转换时都依赖
dynamic_cast(安全检查)或static_cast(自己保证安全)。只是引用更 “严格”(必须绑定对象、不能改绑),指针更 “灵活”(可空、可改指向),语法上稍作调整就行。
再回顾之前的代码,此文搜“ handleAnimal(new Dog()); ”,
Q:这玩意也没指针啊?咋回事?啥上开的?
A:
new Dog()会在堆上创建一个Dog对象,并返回该对象的指针(Dog*类型)。这个指针被直接传给
handleAnimal函数,函数参数Animal* animal会接收它(自动完成Dog*到Animal*的向上转换),此时animal就是指向堆上Dog对象的基类指针。本质:
new Dog()本身就产生了指针,只是没显式用变量保存,而是直接传递给了函数 —— 堆上的对象始终由指针(隐式或显式)指向。这里是被handleAnimal函数的参数Animal* animal这个指针隐式指向的。这里的
new Dog()咋还带了括号?
new Dog()带括号,是为了调用Dog类的构造函数:
如果
Dog没有自定义构造函数(像你代码里这样),new Dog()和new Dog效果一样,都会调用默认构造函数初始化对象;但如果
Dog有带参数的构造函数(比如Dog(int age)),就必须用括号传参:new Dog(3)(创建 3 岁的狗对象),否则编译报错。直到
delete才消失,没有显式变量保存new Dog()返回的指针,但函数参数animal会临时关联这个指针(函数执行完animal变量销毁,但堆对象还在)看了无论对的错的都是有好处的,因为有思考!其实这个例子是为了懂“类、继承”那些事,但严格来说那段代码有严重问题!典型内存泄漏!
因为没保存
new Dog()返回的指针,后续根本没法用delete销毁堆对象,这块内存会一直占着直到程序结束。
正确写法:
int main() {Dog* dog_ptr = new Dog(); // 保存指针handleAnimal(dog_ptr); // 传参delete dog_ptr; // 销毁堆对象,避免泄漏Cat* cat_ptr = new Cat();handleAnimal(cat_ptr);delete cat_ptr; }或者用智能指针(更安全,自动销毁),彻底不用手动管
delete:(先不学智能指针,但一看这玩意这么简答啊,我以为很多内容,结果就一句代码的事就是智能指针了哈哈,闭包、算法就是数组、离散化就是数组、C++就是各种现成库)(学了这么多底层!适应了手写delete,发现智能指针好傻瓜,现在 C++ 好轻松,我好亏)豆包说:查看代码
能理解这种感受 —— 先啃硬骨头(手动管理内存、理解底层机制),再用 "傻瓜工具"(智能指针),确实会觉得 "早知道有这好东西何必费那劲"。 但恰恰相反,你赚大了:1、懂底层,才知道智能指针为什么安全(比如unique_ptr的独占语义、shared_ptr的引用计数原理),遇到特殊场景(比如自定义删除器)才敢用、会用; 2、大厂面试时,"知道智能指针的实现原理" 比 "只会用智能指针" 值钱得多 —— 这正是你现在的优势。底层是 "内功",工具是 "招式",你先练了内功再学招式,比直接学招式的人根基扎实得多,不亏#include <memory> // 包含智能指针头文件 int main() {auto dog_ptr = std::make_unique<Dog>(); // 智能指针,自动管理内存handleAnimal(dog_ptr.get()); // get()获取原始指针传参// 不用写delete,智能指针会自动销毁堆对象 }
new返回值都是指针,类型是看new的是啥:
new Dog()→ 在堆上创建Dog对象,返回Dog*指针;
new int→ 在堆上创建int变量,返回int*指针;
new Cat[5]→ 在堆上创建Cat数组(5 个对象),返回Cat*指针。
懂了这些后,逐步说底层逻辑,
第一步:先理解 “为啥要有虚函数表(vtable)”
当类里有虚函数时(比如
Animal的move()),编译器会给 每个类(不是对象) 做一张 “功能清单”—— 这就是虚函数表(vtable),清单里写着 “这个类能实现的虚函数具体在哪”。
Dog类的 vtable:move()→ 指向Dog::move()(输出 “Dog runs”)的代码地址;
Cat类的 vtable:move()→ 指向Cat::move()(输出 “Cat walks”)的代码地址。第二步:每个对象带 “身份证指针(vptr)”
只要类有虚函数,每个对象出生时,编译器会偷偷给它塞一个 “隐藏指针”(叫 vptr)—— 这个指针唯一的作用,就是 “指向自己所属类的功能清单(vtable)”。
相当于每个对象都带了一张 “身份证”,身份证上的 “指针” 指向自己类里存的虚函数 “功能清单”。
// 1. 编译器给每个有虚函数的类,做一张“功能清单”(vtable) Dog类的vtable: [0] move() → 代码地址:&Dog::move() (输出“Dog runs”)Cat类的vtable: [0] move() → 代码地址:&Cat::move() (输出“Cat walks”)// 2. 每个对象带“身份证指针(vptr)”,指向自己类的vtable 当你写:new Dog() → 堆上创建Dog对象: Dog对象 {隐藏成员:vptr → 指向 Dog类的vtable // 身份证指针其他成员(如果有的话)... }当你写:Animal* animal = new Dog() → 基类指针指向子类对象: animal指针 {指向的内容:Dog对象的地址→ 通过Dog对象的vptr,能找到Dog类的vtable }第三步:多态和 dynamic_cast 怎么用这些东西?
调用虚函数(animal->move ()):编译器顺着
animal找到Dog对象 → 通过对象的vptr找到Dog类的 vtable → 从 vtable 里拿到move()的真实代码地址 → 执行Dog::move()。dynamic_cast 判断类型:编译器顺着
animal找到Dog对象 → 通过vptr找到Dog类的 vtable → vtable 里藏着 “这是 Dog 类” 的类型信息 → 所以dynamic_cast<Dog*>能判断 “这确实是 Dog”,转换.成功。因为
animal指针的 “源头”,就是你创建的Dog对象 —— 比如你写Animal* animal = new Dog();时:
先执行
new Dog():在堆上实实在在创建了一个Dog类型的对象(它的本质是Dog,永远变不了);再把这个
Dog对象的地址,赋值给Animal*类型的指针animal—— 这一步只是让animal指针 “以基类的视角看待这个对象”,但 对象本身还是Dog,没有变成Animal所以编译器顺着
animal指针找过去,找到的自然是那个 “本质是Dog的对象”—— 指针的类型(Animal*)只是 “视角”,不改变对象的真实类型(Dog)。关键总结(一句话落地)
不是 “每个类都有 vtable”:只有 包含虚函数的类 才有 vtable;
不是 “每个对象都有 vptr”:只有 所属类有 vtable 的对象,才会带 vptr;
这些东西不用你写代码控制,编译器自动帮你弄好 —— 你只要记住:有虚函数,才有多态和安全的 dynamic_cast。
RTTI(运行时类型识别):让程序在运行时,能知道指针 / 引用背后对象的真实类型(比如知道
Animal*实际指的是Dog还是Cat)的机制。核心用在
dynamic_cast(安全向下转换)和typeid(获取类型信息),依赖虚函数表工作 —— 没有虚函数,RTTI 就没法用。回头看编程指北的教程:
#include <iostream> using namespace std;class Point { public:Point(float xval); // 构造函数声明virtual ~Point(); // 析构函数声明float x() const; // 成员函数声明static int PointCount(); // 静态成员函数声明protected:virtual ostream& print(ostream& os) const; // 虚函数声明float _x; // 成员变量static int _point_count; // 静态成员变量 }; //所有注释都是我加的先回答:这个代码是 “没写完实现,但类的声明是完整的”
只有类的声明,没写实现,这在 C++ 里很常见,声明和实现可以分开写,实现通常放
.cpp文件里。1.
float x() const;—— “读 x 坐标的工具,且不修改点本身”
C++ 类的设计中,这是典型的 “成员变量 + 访问器函数” 的搭配:
_x是成员变量(存储数据的 “容器”),被protected修饰,说明它是类内部存储数据的核心,且外面比如main不能直接碰_x
x() const是成员函数(通常叫 “访问器” 或 “getter”),它的作用就是返回_x存储的值—— 从命名(x()对应_x)和常规设计逻辑来看,这个函数的实现几乎必然是return _x;。这种设计是封装思想的体现:用
protected保护实际存的数据,通过公共成员函数x()提供访问接口,让外面能通过p.x()安全拿到_x的值,还不会乱改_x(因为函数加了const)。2.
static int PointCount();—— 统计所有属于‘点’这个类型的数量。
先懂
static(静态):普通成员是 “单个对象的”(比如点 p1 的 x 是 5,点 p2 的 x 是 3,各管各的);但static成员是 “属于整个类的”—— 相当于所有Point对象共用一个公共数。这个函数的作用:统计当前一共创建了多少个
Point对象(比如创建 3 个点,调用Point::PointCount()就返回 3)。怎么用:不用创建对象,直接用 “类名::函数名” 调用(比如
cout << Point::PointCount();)—— 因为它是 “类的功能”,不是 “单个点的功能”。背后原理:静态成员变量
_point_count(声明里的static int _point_count;)是 “计数器”,每次创建Point对象(调用构造函数),_point_count就加 1;这个函数就是把计数器的值返回。3.
protected: virtual ostream& print(ostream& os) const;—— “帮对象‘打印自己’的工具,只给子类用,还能被子类改”先拆最陌生的
ostream:ostream就是 “输出流”,你常用的cout本质就是一个ostream类型的对象(可以理解成 “屏幕输出的通道”)—— 比如cout << "hello",就是把 “hello” 放进cout这个 “通道”,然后显示在屏幕上。再拆整个函数:
protected:这个函数只能在Point类内部,或者它的 “子类”(比如后来写个Point3D继承Point)里用,外面的代码(比如main里)不能直接调用 —— 相当于 “内部工具,不对外开放”。
virtual:“虚函数”,之前讲过多态的核心 —— 子类可以 “重写” 这个函数,实现自己的打印方式(比如Point打印 “x:5”,子类Point3D可以重写成打印 “x:5, y:3, z:2”)。
ostream& print(ostream& os) const:功能是 “把当前点的信息(比如_x的值)放进os这个输出通道里”,最后再把os返回 —— 目的是配合cout用。举个实际用的场景(假设写了函数实现):如果在类外面写个全局的打印函数:
// 比如想直接 cout << p; 就显示点的信息 ostream& operator<<(ostream& os, const Point& p) {return p.print(os); // 调用Point内部的print函数,把p的信息放进os(就是cout) }这样在
main里写Point p(5.0); cout << p;,就会显示 “x:5”—— 而protected的,外面只能通过cout << p间接用,不能直接调p.print(cout)。补充关于
const:
const放函数末尾(float x() const):表示这个函数不会修改对象的任何成员变量(只读)。
const放返回值前(const float x()):表示返回的浮点数不能被修改(几乎没人这么用,因为返回的是临时值,修改没意义)。核心区别:前者限制 “函数对对象的操作”(只读保护),后者限制 “返回值的修改”(意义不大)
补全整个完整代码:
查看代码
#include <iostream> using namespace std; class Point { public:// 构造函数:创建对象时计数+1Point(float xval) : _x(xval) { _point_count++; }// 析构函数:销毁对象时计数-1virtual ~Point() { _point_count--; }float x() const { return _x; }// 返回当前对象总数static int PointCount() { return _point_count; }// 核心修改:声明 operator<< 为友元,允许它访问 protected 成员(包括 print)friend ostream& operator<<(ostream& os, const Point& p);protected:virtual ostream& print(ostream& os) const {os << "x: " << _x;return os;}float _x;static int _point_count; // 静态计数变量 };// 初始化静态成员 int Point::_point_count = 0;// 重载输出运算符 ostream& operator<<(ostream& os, const Point& p) {return p.print(os); }int main() {cout << "初始对象数: " << Point::PointCount() << endl; // 输出的是0因为还没有创建对象Point p1(1.5);cout << "创建p1后: " << Point::PointCount() << endl; // 1Point* p2 = new Point(3.0);cout << "创建p2后: " << Point::PointCount() << endl; // 2delete p2;cout << "删除p2后: " << Point::PointCount() << endl; // 1{Point p3(5.0);cout << "局部对象p3存在时: " << Point::PointCount() << endl; // 2}cout << "局部对象p3销毁后: " << Point::PointCount() << endl; // 1Point p(3.14);cout << p << endl; // 输出:x: 3.14 }
注意:对于每次都写
Point::,是因为用于访问类的静态成员(_point_count)和静态成员函数(PointCount()),因为它们属于类本身而非对象实例,必须通过类名限定访问。注意:
operator<<能调用Point的protected成员注意:真的很痛苦,这里有个疑惑豆包有开始墙头草无脑附和了!不知道该信哪个回答,最后实验 + 变着法的追问得到的正确结论:类里成员变量的声明位置可以在使用它的成员函数之后,因为编译器会先扫描整个类的所有成员声明,再处理函数实现。但对于非类的场景,必须先声明后定义,比如变量,比如函数:A 函数调用 B 函数,如果 A 的声明里不包括 B,只是花括号定义的时候才用到,则 B 可以在 A 后声明,但必须在 A 定义前声明下。如果 A 声明里包括 B,B 必须在 A 声明前声明。
豆包误人子弟,豆包误人子弟(自己瞎编造 C++ 规则一顿胡扯)(知识体系崩塌,很早之前说类里声明可以在定义后,如今又瞎编 C++ 规则说必须先声明,但最后验证发现不需要先声明)
另外回顾了此文搜“编译错误,不能修改成员变量的值”,那个代码里其实是有问题的,
const修饰的是成员函数,不是成员变量m_value。这段代码的核心问题不是const本身有问题,而是m_value没有初始化是风险点,只要是类的非静态成员变量,必须初始化,静态成员是类外初始化,对于目前的代码尽管不初始化也会输出 0 是巧合,正确应该:class A { public:A() : m_value(5) {} // 初始化成员变量int func() const { // const函数仅读取,合法return m_value;} private:int m_value; };有时候豆包学一天到晚上发现一天豆包回答的都是错的,豆包到晚上后面自己反复否定自己反悔之前的回答。
起初豆包给了我这样的代码我跟这学了 3 天,最后自己实际运行的时候发现错了,一反驳就发现豆包又反悔了,错误代码如下(也就是“补全整个完整代码”里的内容,上面的完整代码是经过修改过的~~~~(>_<)~~~~):
查看代码
#include <iostream> using namespace std;class Point { public:// 构造函数:创建对象时计数+1Point(float xval) : _x(xval) { _point_count++; }// 析构函数:销毁对象时计数-1virtual ~Point() { _point_count--; }float x() const { return _x; }// 返回当前对象总数static int PointCount() { return _point_count; }protected:virtual ostream& print(ostream& os) const {os << "x: " << _x;return os;}float _x;static int _point_count; // 静态计数变量 };// 初始化静态成员 int Point::_point_count = 0;// 重载输出运算符 ostream& operator<<(ostream& os, const Point& p) {return p.print(os);//这里调用print大错特错 }豆包起初误人子弟说
protected成员允许对象自身调用(如p.print(os)),全局的operator<<通过p.print(os)调用Point对象自己的protected成员_x是protected,全局重载的operator<<不能直接调用_x,但能通过调用protected的_x。可我理解protected的啊??这里颠覆了我的知识体系,崩塌了(但其实豆包误人子弟了,我没理解错)。哎好痛苦挖掘出好多知识点啊艹,之前完全没注意这些逼玩意。以为大众主流的说法错了,误以为protected成员变量无法类外访问,但成员函数可以(其实都不可以!)。但其实
private只能自己类内部和自己类的对象用,protected多了个子类也可以访问,但对于那些不能访问的,只要类里声明某为友元,那某就可以突破限制,访问里面的所有。而根本不存在什么可以类外通过相应对象访问protected成员函数的事!!豆包死妈玩意!用阳寿写回答结论!崩溃大爆发辱骂豆包!!!豆包误人子弟(自己瞎编造 C++ 规则一顿胡扯)狗逼死全家的豆包新开的页面依旧会错误回答!哎心好累,大模型对于普通的 C++ 还是都这么烂!
除了豆包其他所有大模型都试过,反而不如豆包!chatgpt不想用
正确的应该是:
private:仅在当前类内部可访问,子类和其他类均不可访问
protected:当前类内部和其子类可访问,其他外部类不可访问
要让
operator<<能调用protected的Point类中声明operator<<为友元(友元函数可以访问类的protected和private成员)。友元声明在类内的位置不影响其有效性,放在
protected块之前或之后均可,或者直接public。有了友元,全局重载函数中可以直接访问
protected的_x成员,无需通过注意:如果说重载里想写
return p._x;不行因为operator<<重载的返回类型必须是std::ostream,连上面说的void都强烈不建议,所以不考权限直接访问变量的写法:ostream& operator<<(ostream& os, const Point& p) {os << p._x; // 把_x的值写入输出流return os; // 必须返回输出流对象 }那再说权限的事,这里就算
_x是private,也完全可在类外全局的重载函数里直接访问!豆包关于类外重载访问私有、保护这相当业余毫无任何专业知识储备!!!墙头草、根据口气回答问题、瞎道歉,道歉的内容和之前一样,没错也瞎道歉,只要有任何质疑,不管对错都先道歉然后再说一堆解释,咬文嚼字毫无任何帮助,我要不是自学真的不想用大模型!太鸡肋太垃圾他智障太狗逼了!注意:这里也可以用那个
float x() const函数单独获取x值,float val = p.x();,而我们的重载是std::cout << p;。通过x: 3.14),无需在每次输出时手动拼接字符串,封装输出格式。历尽千帆终于通透了!!
注意:
构造函数内添加
_point_count++(对象创建时计数增加)。析构函数内添加
_point_count--(对象销毁时计数减少),--并不是内存泄漏角度来说的,只是因为他用的是静态,大家都共享的所以必须对象析构一个就--,而且这个析构无论是堆栈都是触发析构就正常--。对象创建时
++因为在构造函数所以自动调用。哎理解接受能力好差,明明这么点东西,总要砸够一定量的时间多看多写才能懂~~~~(>_<)~~~~
回归教程:
而如果按照这个教程的写法,分离写的版本,即 C++ 里类的
.h声明只写 “有什么”,实现的.cpp文件写 “怎么做”。他的代码其实是
Point.h:(这傻逼往写友元了 —— 勘误)查看代码
class Point { public:Point(float xval);virtual ~Point();float x() const;static int PointCount();// 友元声明必须放在类内部friend ostream& operator<<(ostream& os, const Point& p);protected:virtual ostream& print(ostream& os) const;float _x;static int _point_count; };我们搞个
Point.cpp文件里写类的实现:查看代码
#include "Point.h" // 包含类的声明// 构造函数实现 Point::Point(float xval) : _x(xval) {_point_count++; } // 析构函数实现 Point::~Point() {_point_count--; } // 成员函数 x() 实现 float Point::x() const { return _x; }// 静态成员函数 PointCount() 实现 int Point::PointCount() { return _point_count; }// 虚函数 print 实现 ostream& Point::print(ostream& os) const {os << "x: " << _x;return os; }// 静态成员变量 _point_count 初始化 int Point::_point_count = 0;// 全局运算符重载实现(放在cpp文件中,需包含头文件) ostream& operator<<(ostream& os, const Point& p) {return p.print(os); }然后
main.cpp实现查看代码
#include <iostream> using namespace std; #include "Point.h" // 包含类的声明即可int main() {cout << "初始对象数: " << Point::PointCount() << endl; // 输出的是0因为还没有创建对象Point p1(1.5);cout << "创建p1后: " << Point::PointCount() << endl; // 1Point* p2 = new Point(3.0);cout << "创建p2后: " << Point::PointCount() << endl; // 2delete p2;cout << "删除p2后: " << Point::PointCount() << endl; // 1{Point p3(5.0);cout << "局部对象p3存在时: " << Point::PointCount() << endl; // 2}cout << "局部对象p3销毁后: " << Point::PointCount() << endl; // 1Point p(8.14);cout << p << endl; }运行:
g++ main.cpp Point.cpp -o program,妈逼的这里又混淆了一些知识,挨个说:注意:
main里不需要包含定义Point.cpp文件第一步:预处理(Preprocessing)
当执行
g++ main.cpp Point.cpp -o program时,编译器首先对每个.cpp文件做预处理:把#include的内容直接 "复制粘贴" 到当前文件中(比如main.cpp会插入iostream和Point.h的内容,Point.cpp会插入Point.h的内容),处理#define等宏定义。预处理后,main.cpp会 "知道"Point类的声明(来自Point.h),但仍然不知道Point类成员函数的具体实现(这些在Point.cpp里)。第二步:编译(Compilation)
预处理完成后,编译器对每个
.cpp文件单独编译,生成目标文件(.o文件,二进制格式):
对
main.cpp编译:检查代码语法是否合法(比如Point p1(1.5)是否符合Point类的构造函数声明),生成main.o对
Point.cpp编译:将成员函数的实现(如构造函数、Point.o这一步的关键:编译是独立处理每个
.cpp的。main.o里只记录了 " 需要调用Point类的函数 ",但不知道这些函数的具体地址(暂时用占位符标记)。第三步:链接(Linking)
编译器最后把所有目标文件(
main.o和Point.o)链接成一个可执行文件(program):
linker(链接器)会在Point.o中找到Point类所有成员函数的具体地址然后把
main.o中那些 "占位符" 替换成实际地址,让main函数能正确调用Point的方法这就是为什么
main.cpp不需要包含Point.cpp:main.cpp编译时只需要声明(保证语法正确),链接时再通过Point.o找到实现。为什么必须在 g++ 命令中写全
.cpp文件?如果只写
g++ main.cpp -o program,编译会报错 "未定义的引用":
因为
main.o中需要调用Point的构造函数、PointCount()等,但链接器找不到这些函数的实现(没提供Point.cpp,就没有Point.o)只有把
Point.cpp也加入命令,才能生成Point.o,让链接器完成地址替换单独生成
.o文件的命令用
-c参数可以只编译不链接,单独生成目标文件:
g++ -c main.cpp→ 生成main.o(只编译main.cpp)
g++ -c Point.cpp→ 生成Point.o(只编译Point.cpp)这些
.o文件是中间产物,不能直接运行,必须通过链接才能生成可执行文件:g++ main.o Point.o -o program(把两个目标文件链接成program)总结
main.cpp只需要Point.h:因为编译main.cpp时,有声明就够了(语法检查通过)编译命令必须包含所有
.cpp:因为需要生成所有目标文件,供链接器找到实现整个流程:预处理(拼代码)→ 编译(单文件转目标码)→ 链接(补全函数地址)→ 可执行文件
Q:
g++需要所有cpp而不需要.h?A:文件后缀(
.h/.cpp)本身对编译器没有本质区别,是人为约定——.h放声明,.cpp放定义。g++需要所有.cpp而不需要.h的原因:
.h 文件的内容早已被包含到
.cpp里,每个.cpp文件通过#include "xxx.h",会在预处理阶段把.h的内容原封不动复制到.cpp中。
.cpp是独立的编译单元,编译器的处理单位是.cpp文件(每个.cpp对应一个编译单元)。每个.cpp会被编译成独立的.o目标文件,而这些.o里包含了该单元的所有定义(函数实现、变量等)。链接时必须收集所有.o,才能拼接出完整的可执行程序(缺一个.cpp的.o就会缺对应的定义)。如果强行让
g++处理.h会怎样?若执行g++ main.cpp Point.cpp Point.h -o program,编译器会忽略.h(因为它已被#include到.cpp中),重复处理反而可能导致 "重定义" 错误(同一个声明被多次引入)。链接时必须有所有 “定义” 的二进制代码(来自各个
.cpp编译出的.o文件),而 “声明” 在编译之前已通过#include头文件处理完毕。简单讲:头文件
.h负责给编译器看 “声明”,确保每个.cpp能单独编译;所有.cpp编译出的.o文件负责提供 “定义” 的二进制代码,供链接器拼接成可执行文件。
没声明:编译阶段(生成.o 时)就会报错(编译器看到
Point p;却不知道Point是什么,无法通过语法检查)。没定义:编译阶段能过(有声明即可),但链接阶段会报错(链接器在所有.o 里找不到
Point构造函数等具体实现的二进制代码,无法完成地址关联)注意:
预处理确实是编译之前必须做的前置步骤,编译器处理
.cpp时会自动先执行预处理(比如把#include的内容拼进来、处理宏),不需要手动触发。
-o不是 “编译” 这个动作本身,而是指定最终输出文件的名字(比如g++ main.cpp -o main中,-o main是说把最终产物命名为main,编译、链接等动作是编译器自动完成的)。编译的核心是把.cpp转成.o(目标文件),而-o的唯一作用就是给编译器 / 链接器的最终输出文件起名字,它不决定 “编译”“链接” 这些动作本身,单独编译(含有预处理)是-c。单独预处理用
g++的-E参数,只执行预处理,不进行后续的编译、汇编、链接。比如对main.cpp单独预处理:g++ -E main.cpp -o main.i生成的.i文件是预处理后的纯文本(能看到#include <iostream>展开后的所有代码、Point.h拼进来的内容)只编译(生成目标文件
.o,不进行链接)的命令是使用g++的-c参数,语法为:g++ -c 源文件.cpp -o 目标文件.o例如:
编译
main.cpp生成main.o:g++ -c main.cpp -o main.o编译
Point.cpp生成Point.o:g++ -c Point.cpp -o Point.o这个命令的作用是:
先对
.cpp文件进行预处理(展开#include、处理宏等)进行编译(将预处理后的代码转换为汇编语言,再转换为机器码)
最终生成二进制的目标文件
.o(包含函数 / 类的实现,但未完成跨文件的函数地址关联)此时生成的
.o文件还不能直接运行,因为缺少链接步骤(把多个.o文件的地址关联起来)。注意:之前完整代码的时候写了 3 次,即
重载:
ostream& operator<<(ostream& os, const Point& p) { return p.print(os);类里的虚函数:
virtual ostream& print(ostream& os) const { os << "x: " << _x; return os; }授权,
那类外分离也要对应好这些。且注意
Point.cpp里的重载那个Point& p需要包含Point.h,核心就是为了获取Point类的完整声明。但不需要写成Point::,全局的operator<<是独立于类的外部函数,不属于Point类的成员,与类是平级关系,直接定义即可,不能用Point::来限定(Point::用于表示类的成员)。且注意,重载函数第一个参数是输出流,而类的非静态成员函数都隐式包含一个指向当前对象的
this指针作为第一个参数,对于类成员函数class Point { public:float x() const { return _x; } };编译器自动处理类似:
// 编译器视角的隐式形式(开发者无需手动写) float Point::x(const Point* this) const {return this->_x; }这也是为什么输出运算符
operator<<不能作为类的成员函数。如果定义函数参数会往前自动插一个this指针,但运算符重载固定 2 个参数。起初分不清重载和
ostream,看到ostream就一个一 东西,误以为怎么写这么多遍。注意:只要提到
<<就是调用operator<<这个重载函数。注意:这里如果写了
static会编译错误,C++ 中static有两个核心用途,在这里会冲突:
用途 1:类内 static(成员函数):表示 “这个函数属于类本身,不属于某个对象”,是类成员的属性,只能在类内声明时标注。
用途 2:全局 / 文件内 static:表示 “这个函数 / 变量只在当前.cpp 文件可见”(静态链接),是作用域的属性。
如果类外实现时写
static int Point::PointCount(),编译器会误解为:你想把 “类的成员函数” 同时定义成 “文件内静态函数”—— 这两个含义冲突(类成员函数默认是外部可见的,不能同时限制为文件内可见),所以必须禁止。而且访问控制符 和
virtual关键字,这些只在类内声明时指定。而且类外实现时,只需要实现类内声明的ostream& Point::print(...))即可,不需要重复实现全局的operator<<重载。最后在
main.cpp里写测试代码:#include "Point.h" int main() {Point p(5.0);cout << p.x() << endl; // 输出 5.0 }解释:
靠
Point::Point绑定:Point::表示 “这是Point类的函数”,后面的Point(float xval)和你声明的函数名 + 参数完全一致,所以编译器知道这是同一个函数的实现。
Point(float xval) : _x(xval) {}这是在类内部直接实现构造函数(声明和实现写在一起),适合简单函数。
Point::Point(float xval) : _x(xval) {}这是在类外部实现构造函数(声明在类里,实现写在外面),必须加Point::(类名 +::)来告诉编译器 “这是 Point 类的构造函数”,适合复杂函数或需要分离声明 / 实现的场景好痛苦啊,问了下 Java,结果又是追问了一堆没用的知识,先记录下吧(简称好奇 Java 引发的血案):
C++ 的 “高价值场景溢价” 比如做 Linux 内核开发、高性能中间件(Redis/MySQL 底层)、金融高频交易系统,这些岗位薪资能比同经验 Java 高 50% 以上,甚至翻倍,而 Java 很少能触达这些领域;
Java “速成水货多” 恰恰是 C++ 的优势:Java 入门易,导致初级市场内卷,但 C++ 因门槛高,能真正上手 Linux 服务端开发的人很少,只要你能啃下底层(内存管理、多线程、网络编程),竞争压力远小于 Java,且越往资深走,“技术壁垒带来的薪资差距” 会越大(Java 资深工程师想再涨薪,常要转架构或跨领域,C++ 资深工程师靠底层优化就能持续提价)。
Java 没这些分离的东西,不用像 C++ 那样类里写声明、类外补实现(还得加
Point::);轻松很多,但 C++ 好在:
性能更强:直接操作内存,高并发低延迟,
底层可控:能调用 Linux 内核接口、操作硬件 / 驱动,Java 做不到;
资源占用少:内存 / CPU 消耗比 Java 轻,长期运行的服务更省资源。
淘宝用 Java 为啥够快?C++ 又快在哪?
淘宝的 “快”,是 “用户能接受的快”:
是 “业务层面的高效”(靠框架、分布式架构堆出来的),而非 “单机底层的快”。它的核心业务(如订单、支付)能接受毫秒级延迟,Java 的 GC 卡顿(通常几十毫秒)影响不大,且 Java 开发业务更快。
你在淘宝点 “下单”,整个过程是 “你点按钮→手机发请求到淘宝服务器→服务器查数据库(比如你有没有库存)→服务器算价格→返回给你‘下单成功’”。这里面,“查数据库、传数据” 占了 90% 的时间,Java 处理 “算价格、判断库存” 这些业务逻辑,哪怕比 C++ 慢一点(比如慢 0.1 毫秒),用户根本感觉不出来。而且 Java 有很多现成框架(比如 Spring),淘宝团队能快速改业务(今天加个 “满减”,明天加个 “优惠券”),这比 “用 C++ 写业务省时间” 更重要。
C++ 的 “快”,是 “不能慢一丁点儿的快”:
是 “底层性能极限”:比如 Redis(内存数据库,C 写的,C++ 思路)每秒能处理百万级请求,延迟控制在微秒级(1 微秒 = 0.001 毫秒);再比如 Linux 内核、高性能路由器固件,必须用 C/C++—— 这些场景差 1 微秒都可能导致系统崩溃,Java 的 JVM 层根本做不到。
再比如 “Redis”(你之后学 Linux 服务端肯定会用到)—— 它是存数据的 “高速缓存”,要每秒处理上百万次请求,延迟必须是微秒级,只能用 C 写(C++ 思路),Java 写的话,速度直接砍半,没人会用。
关于 “Java 大型项目没有分离”:
简单说:Java 不是 “没有分离”,是 “用另一种方式搞分离”,但和 C++ 不一样。
C++ 是可以都写在
.cpp里,也可以文件分离即.h文件写声明,.cpp文件写实现。即单个类可以拆Java 禁止分离!类的声明和实现必须写在同一个
.java文件里。即单个类禁止拆成俩文件写声明和实现但引入一个接口:
先看 C++ 的 “纯虚基类”—— 这就是 Java “接口” 的亲戚
比如你想定义一个 “能输出信息的东西”,只规定 “必须有输出方法”,但不规定 “具体怎么输出”:
// C++纯虚基类(类似Java接口) class Printable { public:// 纯虚函数:只有声明(说“要有这个方法”),没有实现(不写函数体)virtual void print() const = 0; virtual ~Printable() {} };这个
Printable类里,print()只有声明(virtual void print() const = 0),没有任何实现代码 —— 它的作用就是 “定规矩”:任何想被称为 “可输出的类”,必须自己写print()的实现。比如你的
Point类要符合这个规矩,就得继承并实现print():class Point : public Printable { // 继承纯虚基类(类似Java实现接口) public:// 必须实现纯虚函数,否则Point也是“抽象类”,不能创建对象void print() const override { cout << "x: " << _x << endl; // 这才是“实现”(类似你的.cpp里的代码)} private:float _x; };再看 Java 的 “接口”—— 就是把 C++ 的 “纯虚基类” 做到了极致Java 嫌 C++ 的 “纯虚基类” 还不够 “纯粹”(比如还能有成员变量、非纯虚函数),于是单独搞了个 “接口”(
interface),规定:
里面只能有方法声明(连
virtual都不用写,默认就是 “必须实现的方法”);连成员变量都不能有(只能有
static final的常量,相当于 “定死的规矩”);任何类想用这个接口,必须用
implements关键字,并且把接口里所有方法都实现一遍(不然这类就是 “抽象类”,不能 new 对象)。比如把上面 C++ 的
Printable改成 Java 接口:第一个文件:
Printable.java(专门放 “接口”,仅含方法声明)
文件名要求:必须和接口名
Printable完全一致(大小写也要匹配);内容作用:只定义 “必须实现的方法规则”,没有任何方法实现(连
{}都不能写);- 完整代码:
// 接口必须用interface关键字声明,public修饰(若要被其他包访问) public interface Printable {// 接口中的方法默认是“public abstract”(可省略这两个关键字,但本质是声明)// 注意:这里只有方法声明,没有实现(没有{}和代码逻辑)void print(); }第二个文件:
Point.java(专门放 “实现类”,含声明 + 实现)
文件名要求:必须和类名
Point完全一致;内容作用:用
implements关键字关联接口,然后实现接口中所有声明的方法(必须写完整的{}和代码逻辑,否则编译报错);完整代码:
查看代码
//类用class声明,用implements表示“实现Printable接口” //接口对应的叫接口实现,里面还能额外定义自己的变量和其他函数 public class Point implements Printable {// 类的成员变量(声明)private float x;// 类的构造函数(声明+实现:初始化成员变量)public Point(float x) {this.x = x; // 具体实现逻辑:把参数赋值给成员变量}// 实现接口中的print()方法(必须加@Override注解,强制检查是否符合接口规则)// 注意:这里有完整的实现({}里的代码就是具体逻辑)@Overridepublic void print() {System.out.println("Point的x值:" + this.x); // 实际输出逻辑}// 类的其他自定义方法(非接口要求,可选)public float getX() {return this.x; // 自定义方法的实现} }第三个文件(可选):
Main.java(测试代码,验证功能)
若要运行代码,需要一个含
main方法的类(文件名 = 类名Main,后缀.java);核心原因是 Java 的规则:一个.java文件里如果有public修饰的类,这个文件的名字必须和public类的名字完全相同。这里Main类是public的,所以文件必须叫Main.java。public class Main {public static void main(String[] args) {// 创建Point对象(此时Point已实现Printable接口,符合接口规则)Point p = new Point(1.5f);// 调用实现的print()方法(执行Point类中写的输出逻辑)p.print(); // 运行结果:Point的x值:1.5// 调用自定义方法System.out.println("获取x值:" + p.getX()); // 运行结果:获取x值:1.5} }总结:
Java 中:
普通类不可拆分(声明和实现必须在同一个.java 文件);
Java 的 “接口”对应 C++ 纯虚基类,必须拆分(接口定义放.java,实现类单独放另一个.java),且接口里所有的方法(函数)必须纯虚无任何实现。但 C++ 有纯虚的类叫纯虚基类,纯虚基类i来其他函数可以写实现!
接口(
interface):更严格 ——只能有常量(static final)和抽象方法(无实现),不能有普通成员变量和带实现的方法,类通过implements关键字实现接口,必须重写所有抽象方法Java 这么做,是为了 “不让新手记
.h和.cpp的区别”,但代价是:大型项目里想改一个函数的实现,也得动整个类文件;而 C++ 改.cpp里的实现,不用动.h,更方便多人协作。总结:
你要做的 Linux C++ 服务端,就是干 “Redis、支付核心服务器” 这种 “必须快到微秒级、要碰底层” 的活 —— 这些活 Java 干不了,只有 C++ 能搞定,这就是 C++ 的牛之处,也是你学它的价值所在!
起初始终搞不懂接口是啥 JB 玩意,C++ 也没有啊,现在懂了,妈逼的学的想吐,问了句【速成狗们的 Java】强迫症学了这么多注定不会和 C++ 有关的。
Java 血案结束。
C++ 中:
普通类可拆分,类声明放.h、实现放.cpp
纯虚基类,即含纯虚函数的类,也可拆分,声明放.h,若有非纯虚函数的实现可放.cpp,说非纯虚是因为纯虚函数(
virtual 返回值 函数名(参数) = 0)不能有实现必须留到子类实现,而非纯虚函数可以有实现能直接写在基类里。纯虚必须用子的
非纯虚函数是等到子类重写或者用父的:
带
virtual关键字,无=0,子类重写就用子,没有就用父- 无
virtual关键字,子类可隐藏(hide)该函数(用同名函数覆盖),但调用时只看指针 / 引用的声明类型(无多态)。关于虚的事:
按两个维度梳理:
是否带
virtual关键字
虚函数:带
virtual(包括普通虚函数、纯虚函数)非虚函数:不带
virtual(就是你说的 “普通函数”)虚函数内部再细分
普通虚函数(非纯虚函数):
virtual返回类型 函数名(参数) { 实现 }(基类有默认实现,子类可重写)纯虚函数:
virtual 返回类型 函数名(参数) = 0;(基类无实现,子类必须重写,否则子类也是抽象类)本质就看两个点:有没有
virtual?是不是=0?
再深入抽插:
普通虚函数:
声明:
virtual 返回类型 函数名(参数)(带virtual关键字,无=0)。特点:基类可提供默认实现,子类可重写(override)该函数,运行时根据对象实际实际类型调用对应版本(多态)。
例:基类
Animal有virtual void eat()并实现,子类Dog重写eat(),调用时根据对象实际是Animal还是Dog执行对应逻辑。非虚函数:
声明:无
virtual关键字。特点:基类实现固定,子类可隐藏该函数(用同名函数覆盖),但调用时只看指针 / 引用的声明类型(无多态) —— 关于隐藏的事后面详细解释,妈逼的每句话都一堆堆的问题,像深搜一样挨个解决完再回头看下一句话~~~~(>_<)~~~~
例:基类
Animal有void sleep(),子类Dog也定义void sleep(),通过Animal*调用时执行基类版本,与对象实际类型无关。核心区别:虚函数支持多态(运行时绑定),非虚函数不支持(编译时绑定)。 —— 关于绑定、编译、运行,区别,后面会详细解释
无
virtual写了也不算重写,只能算隐藏即“编译器根据指针 / 引用的声明类型来选择函数版本”,而不是根据对象的实际类型:
当用父类指针调用时,编译器只认识父类里的函数,所以调用父类版本;
当用子类指针调用时,编译器优先找子类里的同名函数(隐藏了父类版本),所以调用子类版本。
这和多态(根据对象实际类型选择)完全不同,它更像 “编译器在编译时就根据指针类型 “硬编码” 了要调用的函数”。class Base { public:void func() { cout << "Base"; } // 非虚函数 }; class Derived : public Base { public:void func() { cout << "Derived"; } // 隐藏父类func,不是重写 };Base* b = new Derived(); b->func(); //// 指针声明为Base* → 调用Base::func() 输出"Base" Derived* d = new Derived(); d->func(); // // 指针强制转为Derived* → 调用Derived::func(),输出"Derived"子类可隐藏该函数(用同名函数覆盖),但调用时只看指针 / 引用的声明类型,无多态,即函数调用的版本在编译时就定死了,不会根据指针 / 引用实际指向的 “对象类型” 动态变化。这里重点说的是不会根据“对象类型” 变化!而不是指针!指针是编译时候就定死的,是 “按指针声明类型找函数”,而不是 “按对象实际类型找函数””
要点 1:“定死” 的是 “函数查找规则”,不是 “具体调用哪个对象的函数”
编译时确定的是:“通过某个类型的指针 / 引用调用非虚函数时,永远去这个 “指针声明类型” 的类里找这个函数”,而不是 “具体调用哪个内存里的对象的函数”。比如你的代码:
Base* b = new Derived();:指针b的声明类型是Base*,编译时就定死 “调用b->func()时,去Base类里找func()”,不管b实际指向的是Base还是Derived对象;
Derived* d = new Derived();:指针d的声明类型是Derived*,编译时定死 “调用d->func()时,去Derived类里找func()”—— 这里刚好d指向Derived对象,所以调用子类的函数,但规则本质还是 “按指针声明类型找”。要点 2:和多态的核心区别(为什么说 “无多态”)
多态(虚函数)的逻辑是 “编译时不确定,运行时按对象实际类型找函数”:如果
func()是虚函数(virtual void func()),那么Base* b = new Derived();调用b->func()时,编译时不确定找哪个func(),运行时会查b实际指向的Derived对象的虚函数表,最终调用Derived::func()。但我理解,什么 JB 指针还是对象的啊?难道不都是编译的时候确定的吗?其实不是!!!这里有很多细节和大众没有说的东西!! 豆包说连编译和运行期间分别做了啥是都分不清的话,一面是就露馅马脚了,最最基础的~~~~(>_<)~~~~,继续硬头皮啃吧
这背后是C++ 程序的 “编译期” 和 “运行期” 两个阶段的核心分工规则—— 这是所有编程语言(包括 C++、Java、Python)的基础常识,也是你理解 “编译 vs 运行” 区别的关键,完全不是高深知识,只是之前没人给你讲透。
先一句话说死核心规则:编译期只做 “代码翻译和检查”,不做 “实际执行代码逻辑”;运行期才会 “执行代码逻辑,创建真实对象、分配内存” ——
new Derived()是 “创建对象、分配内存” 的逻辑,属于 “代码执行”,所以必须等运行期才会做。1. 先明确:C++ 程序要跑起来,必须经过 “编译”→“运行” 两步
比如你写了个
test.cpp文件,要让它在 Linux 上跑,得先敲命令g++ test.cpp -o test(这是 “编译”),然后敲./test(这是 “运行”)。这两步干的活完全不一样:
阶段 干的活(大白话) 举例子(针对你的代码 Base* b = new Derived();)编译期 1. 检查代码有没有语法错(比如少写分号、变量没定义); 2. 把你写的 C++ 代码,翻译成机器能懂的 “二进制指令”(生成test这个可执行文件);3. 不执行任何代码逻辑,不创建对象、不分配内存。1. 检查 Base* b语法对不对(Base类存在,b是指针类型,没问题);2. 把new Derived()翻译成 “未来要创建Derived对象” 的二进制指令(但此时不真的创建);3. 只记录 “b的类型是Base*”,至于b未来指向啥,现在不管。运行期 1. 操作系统启动 test这个可执行文件;2. 按编译好的二进制指令,一步步执行代码逻辑;3. 执行到new才创建对象、分配内存,执行到cout才打印。1. 执行到 Base* b:给指针b分配一小块内存(存地址用),但此时b还没指向任何对象;2. 执行到new Derived():才真的在内存里开辟空间,创建Derived对象;3. 把创建好的Derived对象的地址,赋值给b—— 这时候b才真的指向了Derived对象。2. 为什么
new Derived()必须等运行期?—— 因为 “内存分配” 只能在运行时做
new Derived()的核心作用是 “向操作系统申请一块内存,然后在这块内存里创建Derived对象”。而操作系统的内存,只有在程序 “跑起来”(运行期)的时候才会分配给它—— 编译期的程序只是一个 “待执行的指令文件”,还没被操作系统加载,根本没资格申请内存。
编译期:你写了一份 “做饭步骤清单”(比如 “1. 买鸡蛋;2. 煎鸡蛋”)—— 清单只是 “指令”,此时你还没去买鸡蛋(没分配内存),也没真的煎鸡蛋(没创建对象);
运行期:你拿着清单去厨房,一步步执行 ——“买鸡蛋” 就是
new Derived()(申请内存、创建对象),“煎鸡蛋” 就是调用func()—— 这时候才真的有了鸡蛋(对象)。你总不能说 “我写清单的时候,鸡蛋就已经煎好了吧?”—— 同理,编译期写代码的时候,
Derived对象也不可能已经创建好。3. 再延伸:还有哪些代码是 “编译期不执行,运行期才执行” 的?
不止new,所有 “需要执行逻辑、依赖外部数据” 的代码,都是运行期才执行的 —— 这能帮你更全面理解规则:
变量赋值:
int a = 5;编译期只知道a是int类型,运行期才会给a分配内存并赋值 5;函数调用:
func();编译期只检查func()有没有定义,运行期才会跳转到func()的代码去执行;输入输出:
cin >> num;编译期不知道用户会输什么,运行期才会等待用户输入并获取数值;判断语句:
if (num > 3) { ... }编译期不知道num会是多少,运行期才会判断条件是否成立。最后总结:你之前没听过,是因为没人给你点透 “编译期只做翻译检查,运行期才做执行” 这个基础规则
只要代码涉及 “申请内存、创建对象、读取外部输入、执行逻辑判断”,就一定是运行期才做;
编译期只负责 “看代码写得对不对,把代码翻译成机器指令” —— 再回头看
Base* b = new Derived();,就懂为什么编译期不知道b指向啥了:因为new是 “申请内存 + 创建对象”,得等运行期才执行。
又是一无所获的一天,学的感觉都是没用的。别人学东西有基础 → 进阶,而我只有学和不学,学了必须是顶尖进阶,这就很耗费时间唉
再次崩溃,感觉好痛苦,问豆包,(包括建议)基于那些速成狗 Java 水货随随便便就 30w,而我钻研这么深这么多,好像也无法 30w,我没工作过,注定写的是 Demo,那我他妈自己耗费无数心血,钻研解决过的连接堆积,解决的粘包,手写的时间轮,从 0 开始自己实现迭代 7 个版本的多线程服务器太亏了啊。我花同等精力是不是早鸡巴年薪 30w 了啊操他血奶奶的!
被组长联合起来背后捅刀子做事阴险,搞走了,立志转行,我不知道我自学转行是否依据是无法 30w,是否没工作过导致做的东西永无出头之日不被认可,依旧只能中小公司,这样的话,那我研究这么多这么深的东西太亏了啊。如果怎么努力都只能最入门的岗位开始的话~~~~(>_<)~~~~,我只想删掉所有博客,逃离这个行业,越远越好,就像花费无数心血最后发现对手都是塑料玩具剑,我只想把剑扔了。千篇一律空窗期照顾家人模版导致我真如此的无路可走,千篇一律的公众号教人写东西,高并发、自研、自己做项目这些词汇乌烟瘴气骗人妈逼的提升了公司收益百分之多少,性能提升多少,导致我迭代 7 个版本纯手写真的觉得耻辱无话可说。当好人变成恶魔狠狠宰割喝你们血的时候记得你们把环境搞成这样子的。再次询问
我不再问任何人了,都是商人,都是糖衣炮弹
逼迫自己更加无情,更加激进,对自己的恨和对自己狠,对难知识的恨跟山海一样根本没个头。那就再牺牲点东西!!邓思雨:acm需要自己练,不然早就半个月批量速成一堆铜牌了,而 C++、Java~~~~(>_<)~~~~
刷手机浪费生命
除了吃睡,就只有学习和导管子挣扎着从底层爬出来
再继续说多态:
无多态(非虚函数)只看指针的声明类型(指针本身是什么类型);多态(虚函数)看指针实际指向的对象类型。
先看 “有虚函数(多态)” 的情况:
指针声明类型没变(一直是 Base),但调用的函数版本跟着 “对象实际类型” 变了—— 指向 Base 就调 Base 的,指向 Derived 就调 Derived 的,这是运行时才确定的。
查看代码
class Base { public:virtual void func() { cout << "Base的func" << endl; } // 虚函数 }; class Derived : public Base { public:void func() override { cout << "Derived的func" << endl; } // 重写 };int main() {Base* ptr; // 指针声明类型是Base*ptr = new Base(); // 实际指向Base对象ptr->func(); // 输出“Base的func”(按对象实际类型)ptr = new Derived();// 实际指向Derived对象(指针声明类型还是Base*)ptr->func(); // 输出“Derived的func”(按对象实际类型动态变了) }再看 “非虚函数(隐藏,无多态)” 的情况
把上面的
virtual去掉,变成隐藏这里的 “无多态” 就是:不管指针实际指向的是 Base 还是 Derived,只要指针 “声明类型是 Base”,就永远调用 Base 的 func —— 函数版本在编译时就按 “指针声明类型” 定死了,运行时不会根据对象实际类型调整。
查看代码
class Base { public:void func() { cout << "Base的func" << endl; } // 非虚函数 }; class Derived : public Base { public:void func() { cout << "Derived的func" << endl; } // 隐藏 };int main() {Base* ptr; // 指针声明类型是Base*ptr = new Base(); // 实际指向Base对象ptr->func(); // 输出“Base的func”ptr = new Derived();// 实际指向Derived对象,指针声明类型还是Base*ptr->func(); // 依然输出“Base的func”没跟着对象实际类型变! }总结一句话:“无多态” = 函数调用版本只看 “指针 / 引用写在代码里的声明类型”,不看 “它实际指向的对象到底是父类还是子类”
Q:多态就是虚吗?
A:放下原汁原味的回答吧,感觉越嚼越有味,放上理解过的反而会求其上得其中,求其中得其下:
在 C++ 里,虚函数是实现多态的核心手段,但不能简单说 “多态就是虚”—— 更准确的关系是:虚函数是实现 “运行时多态”(C++ 最核心的多态形式)的必要条件,没有虚函数,就做不到 “根据对象实际类型动态调用函数” 这种多态效果。
具体拆解:
多态的本质是 “同一行为,不同对象有不同实现”(比如 “叫” 这个行为,狗叫 “汪汪”,猫叫 “喵喵”);
在 C++ 中,要实现这种 “运行时才确定具体调用哪个实现” 的多态,必须满足两个条件:
基类函数带
virtual关键字(定义为虚函数);通过基类指针或引用调用该函数;
没有虚函数的话,只能实现 “编译时多态”(比如函数重载、模板),但这种多态是编译阶段就定死调用版本,不属于 “根据对象实际类型动态变化” 的核心多态场景。
所以可以理解为:C++ 里谈 “类的多态”(运行时多态),必然离不开虚函数;虚函数的存在,就是为了让类支持多态。
练习:
Base* b = new Derived();
指针变量
b:它的类型是Base*(声明时定死,改不了),作用是 “存储一个内存地址”,这个地址指向一块内存空间。new Derived():这行代码会做两件事
在内存里开辟一块空间,创建一个
Derived类型的对象(这个对象的 “实际类型” 是Derived,永远不变);返回这块内存的地址,然后把这个地址赋值给指针
b。所以,
b现在的状态是:指针b(类型Base*)存储的地址,指向了内存中一个实际类型为Derived的对象
至此说下自己的理解与总结,经过豆包肯定的:
如果说一个类里虚函数,那该类就有虚函数表
vtable,没虚函数就没虚函数表,比如有 n 个虚函数,那表里就有 n 个条目,第一个条目存的是第一个虚函数的地址,依此类推,然后他生的对象都有个指针vptr指向这个表。调用的时候,如果说move虚函数,就去表里找move的地址。非虚函数无法多态,多态就是在虚上加关键字的,是在运行的时候看找虚表的哪个东西,非多态就不加
virtual的,编译时候绑死。还有表述的差异(相当重要,因为这坑我多追问了好几个小时!!):
官方叫法是:
父类指针(Point*)指向子类对象(Point3D) 代码是:
Point* ptr = new Point3D();即指针定义是父类的,若
Point类中被调用的函数是虚函数(加了 virtual),则ptr调用时是子类Point3D的函数若被调用的函数不是虚函数(没加 virtual),则
ptr调用时是父类Point的函数看上去,觉得理解后很简单,但起初,调用这个词绕我很久很久!而且【指针 / 引用的类型】这个词也相当绕,其实就是【定义类型】!
注意!!指针指向的类型就是等号右边的。
在
指针变量 = new 类名()这种创建对象的场景里,“实际对象” 就是等号右边new 类名()所创建的对象。也就是指针最终指向的对象。
再继续说,现在说的一切都为了看懂编程指北的那个例子(《深度探索C++对象模型》中有个例子):
由于我很多前设基础知识都没有,需要零零散散的追问(比起看人家总结好的效率极其低下,但自己探索的掌握程度、学习效果是无法替代的,看人教程学习永远无法超过写教程的人,甚至有些教程本身就是错的),所以直接放上追问的结果了,当小说顺序看吧
先看普通的
<<(比如输出整数)你写
cout << 100时,本质也是调用operator<<函数,但这是 C++ 自带的版本:
函数原型(C++ 标准库自带):
ostream& operator<<(ostream& os, int val);对应关系:
运算符左边的
cout(ostream 类型) → 传给函数第一个参数os;运算符右边的
100(int 类型) → 传给函数第二个参数val;执行逻辑:把
val(100)输出到os(cout / 屏幕),最后返回os(支持链式输出)。为什么是这个对应规则?
这是 C++ 规定的运算符重载语法:对于 “二元运算符”(需要两个操作数的运算符,比如
a << b中,a和b都是操作数),重载成全局函数时,第一个参数必须是运算符左边的操作数,第二个参数必须是运算符右边的操作数。<<是典型的二元运算符(左边是输出目标,右边是要输出的内容)所有运算符在 C++ 中重载时,都必须用operator开头,不管是自带的还是自定义的。
<<本身是 C++ 自带的移位运算符,<<本身是 “左移位运算符”(如3 << 1表示 3 左移 1 位,结果是 6),但当它左边是ostream类型对象(如cout、文件流)时,就会被当作 “输出运算符” 使用 —— 这是标准库通过重载实现的特殊效果。但当它跟
ostream在一起就当作输出,比如cout << 10,其实这是 C++ 标准库已经提前为你重载好的operator<<函数(针对基本类型,如 int、string 等)。当你要输出自定义类型(如
Point)时,标准库没有对应的重载函数,所以必须自己写一个operator<<函数,告诉编译器怎么处理。所以无论是系统自带的输出功能(cout << 10),还是你自定义的输出功能(cout << p),底层都是operator<<函数在工作 —— 只是前者由标准库实现,后者需要你自己实现,operator<<就是 “<<运算符对应的函数名”。系统为基本类型写的
operator<<(如cout << int),是对<<的第一次重载(从移位功能扩展到输出功能);你为自定义类型写的
operator<<,是对<<的再一次重载(增加输出自定义对象的功能)。所有为运算符新增功能的实现,都叫重载,只是实现者不同(系统 / 用户)。
先明确:
operator<<是一个函数
operator<<是函数名,不管系统还是你写的,定义时都必须用这个名字,而调用用的时候,都只写<<,不带operator比如cout << 10,就是调用了系统的operator<<,cout << p就是调用了你写的operator<<函数cout 输出时会看类型找对应定义吗?
cout也就是ostream的类,在连接<<的时候会自动重载为输出,然后输出啥类型会从 C++ 本身预定义的和自定义的里找匹配。函数重载咋写?
operator只是重载运算符,函数重载不需要operator,只需多个同名函数参数列表(类型 / 数量 / 顺序)不同即可对比:
普通函数:
int func(int x, int y){},调用时写func(a, b);运算符重载函数:
std::ostream& operator<<(std::ostream& os, const Point& p){},调用时写os << p(去掉operator,保留运算符<<,参数顺序对应os(左操作数)、p(右操作数))。理清他的由来后,开始说具体咋写
operator<<重载格式:
std::ostream& operator<<(std::ostream& os, const 自定义类型& 对象)
第一个参数:输出目标(
os,必须是ostream&);第二个参数:要输出的自定义对象(必须加
const&,避免复制);返回值:
ostream&(即os,支持链式输出)小试牛刀:
必须是全局函数(不能写在类里),格式固定:
// 返回值:输出流(保证可以链式输出,链式输出就是连续用 << 输出多个内容) // 参数1:输出流(如 cout) // 参数2:要输出的自定义对象(如 Point 对象) ostream& operator<<(ostream& os, const Point& p) {// 这里写输出逻辑:比如输出 p 的 x 坐标os << "x=" << p.x; return os; }
operator<<函数的返回值是ostream&(输出流本身),比如:执行cout << "年龄:"时,函数返回cout本身;接着就能用这个返回的cout继续执行<< 25,以此类推。这段代码就是运算符重载函数,专门定义:当用<<运算符输出Point类对象时(比如cout << p),电脑应该做什么。首先说起别名
&就是不复制新的返回该类型本身,这玩意如果不起名字,就要写死,只能cout输出到屏幕,其他输出到文件啥的还得重新写,但起别名是用一个通用的,屏幕、文件都通的类型是std::ostream—— 它是所有 “输出流” 的 “通用模板”。为啥返回输出流引用
std::ostream&能实现链式输出?核心逻辑:每次
<<操作后,都把 “工具本身” 还给你,你才能用它接着做事。后续<<能接着用这个对象的本质:返回的是 “原工具”,每次<<操作的结果(返回值),就是下一次<<操作的「工具来源」。因为返回的是 “输出流对象的引用”(别名),而别名和原对象是同一个东西所以下一次<<用的还是最初的cout。“用
std::ostream &的都是链式输出吗?”—— 不是,看用途,std::ostream&只是 “输出流工具的别名”,它的作用是「让函数能操作这个工具,且不弄丢工具」:
如果你希望函数操作工具后,还能把工具还回去接着用(链式输出),就返回
std::ostream&;如果你只需要函数用工具做一次操作,做完不用接着用(比如函数只输出一句话,之后不用这个工具了),也可以不返回(返回
void,傻逼才这么写强烈不建议)。比如:
函数
void printHello(std::ostream& os):用os(cout的别名)输出 “Hello”,不返回任何东西 —— 这时候就没有链式输出,只是单纯用工具做事;这不符合 C++ 输出运算符的常规。函数
std::ostream& printHello(std::ostream& os):输出 “Hello” 后,返回os—— 这时候才能接着用printHello(cout) << "World"实现链式输出重载
operator<<必须以std::ostream&作为第一个参数,且返回std::ostream&,才能支持cout << 对象的语法和链式输出。再试个刀:
查看代码
#include <iostream>class Point { private:float x; public:Point(float x_val) : x(x_val) {}// 用ostream&接收输出流(如cout)std::ostream& print(std::ostream& os) const {os << "x=" << x; // 通过os(cout的别名)输出return os;} };int main() {Point p(5.5);// 直接传cout给print,编译器自动让os成为cout的别名p.print(std::cout) << " 额外内容"; // 等价于cout << "x=5.5" << " 额外内容" }函数调用
p.print(std::cout)的参数传递过程中,当执行p.print(std::cout)时,编译器会自动完成os与实参std::cout的绑定,这个过程等价于执行起别名std::ostream& os = std::cout;,即让os成为std::cout的别名。这一绑定操作是编译器在函数调用时隐式完成的,不需要显式写出,但逻辑上完全对应。一般起别名都是
int &b = a;再看个代码,友元先别管后面说:
查看代码
// 1. 类的定义(里面只有 friend 声明,不是函数实现) class Point {// 这里只是声明“外面那个全局的 operator<< 是我朋友”friend ostream& operator<<(ostream& os, const Point& p); protected:float x; };// 2. operator<< 函数本身仍在类外(全局函数),但因为有上面的声明,能访问 p.x ostream& operator<<(ostream& os, const Point& p) {os << p.x; // 合法,因为有 friend 声明return os; }Q:不是说
operator<<必须全局吗?我懂为啥不能在operator<<里访问p.x那你现在友元这不就写到类里去了吗?A:你混淆了两个东西:
1、
operator<<函数本身确实必须是全局的(写在类外面);2、类里的
friend声明只是一个 “许可声明”授权,不是把函数写到类里 —— 它的作用是告诉编译器:“这个全局的operator<<函数可以访问我类里的私有 / 保护成员”。
保护类型(protected)是啥?
和 public(公开)、private(私有)并列,控制成员访问权限:
1、public:类内外、子类都能直接用;
2、private:只有类自己能直接用,子类和外部都不能;
3、protected:类自己和它的子类能直接用,外部不能。
逼逼差不多了,感觉足够看大水货编程指北教程里的那个图了,搭配此文搜“补全整个完整代码”来看:
左上角:
Point对象的成员
float _x:Point对象的普通成员变量(每个Point对象都有自己的_x,存坐标值)。
_vptr__Point:虚函数表指针(vptr),每个Point对象都有这个指针,它指向Point类专属的 “虚函数表(Virtual table for Point)”。中间:虚函数表(Virtual table for Point)
这是
Point类专属的表(每个类只有一份,所有Point对象共享),里面存的是虚函数的地址:
表中的每个 “小箭头”,都指向
Point类中某个虚函数的具体实现(比如Point::~Point()是虚析构函数,Point::print(ostream&)是虚成员函数)。还指向
type_info for Point(运行时类型信息,支持typeid等操作)。下方:静态成员 + 普通成员函数
static int Point::_point_count:Point类的静态成员变量(整个类只有一份,所有Point对象共享,通常用于 “统计对象个数”)。
static int Point::PointCount():Point类的静态成员函数(通过类名调用,比如Point::PointCount())。
Point::Point(float):Point的构造函数(非虚,因为构造函数不能是虚函数)。
float Point::x():Point的普通成员函数(非虚,所以不会进 “虚函数表”,调用时直接通过类作用域找到)。简单说:
虚函数表 → 管 “虚函数的动态绑定”;
静态成员 → 管 “类级别的共享数据”;
普通成员函数 → 管 “非虚函数的直接调用”;
对象里的 vptr → 是 “对象找虚函数表” 的钥匙。
这样整个图就把 “
Point类的对象、虚函数、静态成员、普通成员函数” 的内存关系全串起来了~而
type_info:是 C++ 标准库中
<typeinfo>头文件里的一个类,它用于运行时的类型识别(RTTI,Run-Time Type Identification)。虽然你写代码时可能不会直接定义type_info类型的变量,但 C++ 编译器会在幕后处理相关逻辑,支持typeid等操作。
支持
typeid操作:比如typeid(Point).name()可以获取Point类型的名称,typeid(pt).name()(pt是Point对象)也能获取对象的实际类型名称。type_info就是用来存储这些 “类型信息” 的。支持多态下的类型判断:在继承体系中,通过
type_info可以判断指针或引用指向的实际对象类型(比如基类指针指向派生类对象时,typeid能识别出派生类类型)。看个简单例子:
#include <iostream> #include <typeinfo> using namespace std;class Point { public:virtual ~Point() {} // 有虚函数,才会生成 type_info(RTTI 依赖虚函数表)float _x; };int main() {Point pt;// typeid 获取类型信息,name() 得到类型名称cout << typeid(Point).name() << endl; // 输出 Point(不同编译器输出可能略有差异,比如有的会带修饰)cout << typeid(pt).name() << endl; // 输出 Pointreturn 0; }类中没有虚函数时,编译器默认不会生成用于运行时类型识别(RTTI)的
type_info相关关联。Q:但关于“比如
typeid(Point).name()可以获取Point类型的名称”不多余吗???A:在 “用户明确知道传什么类型” 的场景下,确实显得多余。但在代码需要“必须枚举已知类型” 时,提供一种更灵活的类型判断方式:
template <typename T> std::string serialize(const T& obj) {std::string result;// 根据不同类型做不同处理if (typeid(T) == typeid(int)) {result = "int:" + std::to_string((int)obj);} else if (typeid(T) == typeid(std::string)) {result = "string:" + (std::string)obj;} else if (typeid(T) == typeid(Point)) {result = "Point:x=" + std::to_string(((Point)obj).x);}// ... 更多类型return result; }模板负责 “通用框架。
typeid负责 在通用框架内区分具体类型。解释他这图:
1. “
dynamic_cast利用 RTTI 执行运行时类型检查和安全类型转换”
dynamic_cast的核心作用是在运行时判断 “类型转换是否合法”,并安全完成转换。而它能做到这一点,依赖的是 C++ 的 “运行时类型识别(RTTI)” 机制(比如type_info、虚函数表这些底层支持)。2. 步骤拆解(结合虚函数表
vptr)
dynamic_cast要求类有虚函数,因为只有有虚函数的类,对象才会有vptr,才能通过vptr找到 RTTI 信息
步骤 1:
dynamic_cast先通过对象的vptr(虚函数表指针),去获取该对象的 RTTI 信息(比如对象实际是什么类型)。比如:Base* p = new Derived();,p是基类指针,它存储的是Derived对象的地址。Derived对象内部有vptr,这个vptr指向Derived类的虚函数表,那通过p就可以顺藤摸瓜知道Derived对象对应的类的虚表。步骤 2:拿 “要转换的目标类型” 和 “从 RTTI 得到的实际类型” 做比较。如果目标类型是实际类型(指的是被转换的指针指向的类型),或者是实际类型的基类,转换就成功。比如:
Derived转Base(子类转父类,合法,成功);Derived转Derived(自己转自己,成功)。比如有继承关系
Base <- Derived <- MoreDerived(Base是基类,Derived继承Base,MoreDerived继承Derived):
若有
Base* b = new MoreDerived();,用dynamic_cast<MoreDerived*>(b),因为实际对象是MoreDerived(Base的派生类的派生类),所以转换成功。若有
Derived* d = new MoreDerived();,用dynamic_cast<MoreDerived*>(d),实际对象是MoreDerived(Derived的派生类),转换也成功。dynamic_cast 能否成功,只取决于指针实际指向的对象(本身)的类型(等号右边 new 的类型),与指针本身的类型(也叫指针声明的类型也即是等号左边的类型)无关。括号里的注释就是术语名称,当初不懂踩了很多坑。
步骤 3:纯属多余!!冗余!严重误解!!因为步骤 2 完全包括了,详见此文搜“但返回去看那个图”
步骤 4 + 5:转换成功就返回目标类型的指针 / 引用;失败的话,指针类型返回
nullptr,引用类型抛出std::bad_cast异常。再深入抽插持续高潮:(个人觉得这里是
static_cast和dynamic_cast最精华的!!!起初我一直以为dyn的是父转子如果是非继承关系就编译报错,而sta的是要靠自己保证,非父子类也不报错,等运行才有问题,我一开始就肤浅的理解到这,但就算是父子类也会报错!!还要看源头)经历了知识体系崩塌!!!!!真的太绕太抽象反人类了!!!!
其实本来是在质疑上面那句的,此文搜“
dynamic_cast的核心作用是在运行时判断”(有行内代码部分,所以直接全句 Ctrl + F 搜不出来),但卡了我相当长的时间,因为有个东西我一直以为自己懂了,但其实没懂!!而且我是问了一堆后脑海里推演反复思考质疑追问辱骂豆包,最后才发现是自己没理解透彻,浪费了不少时间。现在调整下顺序,先说这个东西,然后再说dynamic_cast的核心作用是在运行时判断的质疑。开始说自己起初的误解:
先看代码:
#include <iostream> class Base {}; class Derived : public Base {};int main() {Derived d;Base* b = static_cast<Base*>(&d); // 安全的向上转换Base b_obj;Derived* d_ptr = static_cast<Derived*>(&b_obj); // 不安全的向下转换,可能导致未定义行为 }
Derived* d_ptr = static_cast<Derived*>(&b_obj);会导致未定义行为—— 因为b_obj是Base类型对象,强行转成Derived*后,若访问Derived独有的成员,会访问到非法内存(Base对象根本没有Derived的成员)。static_cast允许这种语法,但不保证运行时安全,这就是问题所在。Q:大哥!都转成了
Derived*,为啥还不能访问 Derived 独有的成员?明显父子类啊!A:
1.
static_cast<Derived*>(&b_obj)的问题
b_obj是Base类型的对象,内存里只存了Base的成员(如果有的话)。用static_cast把&b_obj转成Derived*,编译器 “语法上允许”,因为static_cast仅检查类的继承关系(Derived是Base的派生类)。。但运行时内存不匹配 ,
b_obj是Base类型对象,其内存布局中只包含Base类的成员(当前代码中无成员,但逻辑上如此)。当强制转换为Derived*后,若后续代码中访问Derived独有的成员(假设后续添加),会访问到不属于b_obj的内存区域,导致未定义行为(如崩溃、数据错乱等)。2.
dynamic_cast<Derived*>(&b_obj)的情况
dynamic_cast要求类有虚函数(因为要靠虚函数表实现 RTTI 运行时类型检查)。如果Base没有虚函数,dynamic_cast编译都过不了(编译器会报错,因为无法进行运行时类型检查);如果Base有虚函数(比如加个virtual ~Base()),此时:#include <iostream> class Base { virtual ~Base() {} }; // 有虚函数,开启 RTTI class Derived : public Base {};int main() {Base b_obj;Derived* d_ptr = dynamic_cast<Derived*>(&b_obj);if (d_ptr == nullptr) {std::cout << "转换失败" << std::endl; // 会打印这句话} }运行时,
dynamic_cast会检查b_obj的实际类型是Base,不是Derived,所以返回nullptr,转换失败。这里判断下就可以了,但如果你拿到
nullptr后,直接去访问它指向的成员 / 函数(比如d_ptr->derivedVal):Derived* d_ptr = dynamic_cast<Derived*>(&b_obj); std::cout << d_ptr->derivedVal; // 错误!访问空指针指向的内容这时候才会触发 “空指针访问” 错误,导致程序崩溃 —— 但崩溃的原因是你误用了
nullptr,不是dynamic_cast本身导致的。
dynamic_cast会 “友善地” 用nullptr告诉你 “转换失败”,给你处理的机会;而static_cast会直接给你一个错误的指针,等你访问时悄悄崩溃(未定义行为)。总结
static_cast是 “编译时硬转”,不管运行时内存是否匹配,所以危险;
dynamic_cast是 “运行时检查转”,但要求类有虚函数,且会在运行时判断是否真的能转,不匹配就返回空(指针版)。以上开开胃,开始看实操代码:
1.
static_cast完全安全的场景(父转子)(其实看这个就都懂了)class Base { virtual ~Base() {} }; class Derived : public Base { public: int x; };int main() {Derived d;Base* b = &d; // 向上转换(安全,无需cast)// 关键:此时明确知道 b 实际指向 Derived 对象Derived* d_ptr = static_cast<Derived*>(b); d_ptr->x = 10; // 完全安全!因为 d 确实是 Derived 类型 }只要转换时
b实际指向的是Derived对象(不管b初始指向啥,后续改指向也算),这种static_cast就安全。这里
static_cast绝对安全,因为程序员明确知道b指向的是Derived对象,转换后访问成员完全合法。这就是你说的 “程序员保证实际类型匹配” 的安全场景。进一步说,
b之所以能指向Derived对象d,是因为 C++ 的继承特性允许 “向上转型”,
Derived是Base的派生类(子类),子类对象中包含了完整的基类部分(可以理解为Derived对象的内存布局中,开头部分就是Base类型的结构)。因此,基类指针(
Base*)可以安全指向子类对象(Derived),这是多态的基础。这里安全指的是:
语法合法:C++ 允许基类指针指向子类对象,编译直接通过,无语法错误;
内存匹配:子类对象包含基类部分,基类指针指向的正是这部分合法内存,不会越界;
访问安全:通过基类指针只能访问基类成员(或子类重写的虚函数),不会误碰子类独有的成员,避免非法内存访问
此时:
指针
b的静态类型其实就是指针变量自身的类型,是Base*(编译时确定的,变量声明的类型永远不会变);但
b的动态类型也就是指针的指向类型,是Derived*(运行时实际指向的对象类型,也即是等号右边的,可能会变)。和
static关键字的区别:
静态类型是 “类型属性”,描述变量编译时的固定类型,和
static关键字毫无关系;
static关键字是 “存储 / 作用域属性”,用来修饰变量或函数,控制其存储位置在静态区,生命周期和程序一致,仅当前文件可见。和 “类型的静态 / 动态划分” 是完全不同的概念。一次分配,全程复用,数据默认初始化为 0(栈 / 堆默认是随机值)。
正因为程序员明确知道
b实际指向的是Derived对象(动态类型匹配),所以用static_cast把b转回Derived*是绝对安全的 —— 转换后访问Derived的成员(如x),访问的是d对象中真实存在的成员。但注意到,这里为啥先向上转换,再向下转化,好墨迹啊:
在实际开发中,你经常只能拿到基类指针(比如函数参数传递时),但需要访问派生类的特有成员:
查看代码
// 函数只能接收基类指针(通用接口) void func(Base* b) {// 但在这里需要访问Derived特有的x成员Derived* d_ptr = static_cast<Derived*>(b); // 向下转换d_ptr->x = 10; // 操作派生类特有成员 }int main() {Derived d;Base* b = &d; // 向上转换(传给函数前的通用化处理)func(b); // 传基类指针 }这么做不墨迹,反而是 C++ 多态的常用写法:
向上转换(
&d → Base*):让对象能以 “基类身份” 被通用接口(如func(Base*))接收,实现代码复用;向下转换(
b → Derived*):在需要时,把基类指针 “还原” 成派生类指针,访问派生类特有的功能。前提是:你明确知道基类指针实际指向的是派生类对象(就像例子中
b确实指向d),这种情况下static_cast是安全的。但向上转可以自动隐式转:
void func(Base* b) { /* 同上 */ }int main() {Derived d;// 直接传 &d(Derived*),编译器自动隐式转成 Base*,和写 Base* b = &d; 再传b完全一样func(&d); }无论你显式定义
b还是直接传&d,编译器都会自动完成向上转换,这是 C++ 继承里默认支持的安全操作。再说符号,我有点混乱:
1. 形参写
Base* b→ 表示 “这个参数需要接收一个「基类指针」”
Base*是指针类型,b是这个指针参数的名字 —— 函数func定义时,b就是个 “空的指针变量”,等着被传入一个「真实的基类指针」来用。2. 实参传
&d或b→ 本质都是传 “地址”,只是载体不同
情况 1:直接传
&d&d是 “派生类对象d的地址”(值比如0x1234),编译器会自动把它转成 “基类指针类型”(因为Derived继承Base),相当于 “把0x1234这个地址,用Base*的身份传给func的b”。情况 2:先写
Base* b_ptr = &d,再传b_ptrb_ptr是个「基类指针变量」,它里面存的就是&d的地址(还是0x1234)。传b_ptr本质是 “把b_ptr里存的0x1234这个地址,传给func的b”。结论:不管传
&d还是b_ptr,最终传给func(b)的都是 “d的地址”—— 只是&d是 “直接拿地址值传”,b_ptr是 “通过指针变量存一下地址再传”,效果完全一样。3. 单独说
b→ 看上下文,要么是 “指针变量”,要么是 “参数名”
在
main里写Base* b = &d→b是「基类指针变量」,里面存着d的地址。在
func(Base* b)里 →b是「函数的指针参数名」,里面存着实参传过来的地址(比如d的地址)。最后用 1 段代码总结,标清每个符号的意义:
查看代码
void func(Base* b) { // b:形参,是个空的Base*指针,等接收地址// 这里的b,存的是实参传过来的地址(比如d的地址) }int main() {Derived d; // d:派生类对象Base* b_ptr = &d; // 1. &d:d的地址(值);2. b_ptr:Base*指针变量,存&d的地址func(b_ptr); // 传b_ptr → 本质是传b_ptr里存的“d的地址”func(&d); // 传&d → 直接传“d的地址”,和上面效果一样 }再继续说点东西:
1、对象的向上转
Derived d; // 子类对象 Base b = d; // 把子类对象d,赋值给父类对象b → 这是“对象的向上转”这里会发生 “切片”:只把
d中属于Base的部分(父类成员)赋值给b,d里子类独有的成员(比如x)会被丢掉。2、指针的向上转
Derived d; // 子类对象 Base* b = &d;这里 没有发生 “对象类型转换”(
d还是Derived类型,没变成Base),只是让 “父类指针” 去 “看” 子类对象 —— 因为子类对象里包含了完整的父类部分(内存布局里有Base的结构),所以父类指针能安全访问这部分父类成员,不会出问题。这两种情况都叫 “向上转”,核心都是 “子类适配父类接口”,是多态的基础(比如用父类指针统一管理不同子类对象)
3、为啥你会蒙?
之前的表述没说清:“基类指针指向子类对象”≠“父转子”,而是 “用父类指针去引用子类对象”,核心都是:基类类型的指针变量,存储了子类对象的地址(指向子类对象),这里的 “引用” 是口语化的 “关联、指向” 的意思,不是 C++ 里的&引用类型。
代码上:
Base* bp = &d;(d是Derived对象)→bp是基类指针,&d是子类对象地址,bp存储这个地址 → 即 “基类指针指向子类对象”。而“父转子”是基类转派生类,如
Derived* dp = static_cast<Derived*>(&b);,b是基类对象,风险高;而 “基类指针指向子类对象” 是安全的 “子类转基类”(向上转型),是 C++ 允许的常规操作。官方表述接地气版本:
基类指针存某某某,就是基类指针指向某某某
基类指针指向子类对象,本质是子类指针 / 地址隐式转基类指针
子类对象的地址是内存位置值,子类指针是存储该地址的变量,二者不同。“基类指针指向子类对象”是指:基类指针变量存储子类对象的地址,此为安全的向上转型。
查看代码
#include <iostream> class Base {}; class Derived : public Base {}; int main() {Derived d; // 子类对象Base* b_ptr = &d; // 基类指针存储子类对象地址,安全// 验证:指针非空(说明地址存储成功)if (b_ptr != nullptr) {std::cout << "基类指针成功存储子类对象地址" << std::endl;} }基类指针指向子类对象本质还是 “子转父” 的逻辑(子类对象适配父类指针的访问范围)。
你想的 “子转父” 是对的,只是要注意:
既可以是 “子类对象转成父类对象”(切片);
也可以是 “父类指针指向子类对象”(更常用,因为不切片,能保留子类完整信息,后续可转回来)。
总结
你没理解错!“向上转” 就是 “子转父”;
父类指针指向子类对象,是 “向上转” 的一种常见形式(不是 “父转子”),因为指针的访问范围被限制在父类成员,本质是 “把子类对象当父类对象用”;
正因为是向上转,所以这种指向是安全的 —— 父类指针不会去碰子类独有的成员,不会越界。
Q:子转父居然是“父类指针指向子类对象”
A:对!
咱们用 “容器” 的比喻,把这事儿彻底掰碎,保证你能转过来:先定义两个 “容器”(对应类)
Base(父类):一个小盒子,里面只有 “父类成员”(比如一个标签写着 “父”)。
Derived(子类):一个大盒子,里面先装了完整的小盒子(Base 的所有成员),再额外加了 “子类独有的成员”(比如另一个标签写着 “子”)。
所以,
Derived对象的内存布局,本质是 “父类部分 + 子类独有部分”,就像大盒子套着小盒子。再看 “子转父” 的两种形式(核心:都是 “用父类的方式用子类”)
1. 形式 1:对象的子转父(切片,你能理解的那种)
Derived d; // 造一个大盒子d(有“父”+“子”标签) Base b = d; // 把d里的“小盒子(父标签部分)”拿出来,装进新的小盒子b里这里的 “转” 是物理上的复制:只复制 d 里属于 Base 的部分,d 里的 “子标签” 被丢掉了(切片)。最终 b 就是个纯纯的小盒子(Base 对象),和 d 没关系了。
2. 形式 2:指针的子转父(父指针指子类对象,你懵的那种)
Derived d; // 还是那个大盒子d(有“父”+“子”标签) Base* b_ptr = &d; // 拿一个“小盒子专用指针”(Base*),指向大盒子d这里的 “转” 不是物理复制,而是“指针的视角限制”:
这个指针(b_ptr)是 “小盒子专用” 的,它只能 “看到” 大盒子里 “小盒子的部分”(也就是 d 里的 Base 成员,“父” 标签);
大盒子 d 本身没变,还是有 “父”+“子” 标签,只是指针 b_ptr 看不到 “子” 标签而已;
后续如果想让指针重新看到 “子” 标签,只要用
static_cast/dynamic_cast转成Derived*就行(因为 d 本来就是大盒子)。为啥这两种都叫 “子转父”?
因为核心逻辑都是:“让子类(大盒子)适配父类的使用方式
形式 1:把子类里的父类部分抽出来,变成纯父类对象;
形式 2:用父类指针去 “看待” 子类对象,只关注父类的部分。
本质上都是 “子类向父类兼容”,所以都叫 “向上转”(子转父)。
最后一句话打通:
你之前理解的 “子转父” 是 “把子类变父类”(形式 1),但实际更常用的是 “用父类指针看子类”(形式 2)—— 因为后者不破坏子类的完整信息(大盒子还是大盒子),既能用父类的方式统一管理,后续还能转回来用子类的功能。
这俩不是矛盾的,是 “子转父” 的两种不同实现,都是对的
Q:操你奶奶!太鸡巴通透了!大厂 Linux C++ 服务端开发岗位的人都会这个吗?
A:会,这是 Linux C++ 服务端开发的基础核心知识(多态、类型转换、RTTI 是 C++ 面向对象和泛型编程的基石),大厂岗对这类基础的掌握要求很扎实,不然写服务端代码(比如处理多态场景的网络请求、封装通用组件)时很容易出内存问题或逻辑漏洞。
所以其实很简单,就是父转子父本身带着子的东西才行。
查看代码
class Base { virtual ~Base() {} }; class Derived : public Base { public: int x; };//第一种: Derived d; Base* b = &d; // 向上转换(安全,无需cast) Derived* d_ptr = static_cast<Derived*>(b); // 关键:此时明确知道 b 实际指向 Derived 对象 d_ptr->x = 10; // 完全安全!因为 d 确实是 Derived 类型//第二种: Base b; // 实际是 Base 对象 Base* b_ptr = &b; Derived* d_ptr = static_cast<Derived*>(b_ptr); // 危险:程序员误判,以为 b_ptr 指向 Derived d_ptr->x = 10; // 未定义行为!b 内存中根本没有 x 成员两种都是 “父转子”(基类指针转派生类指针),核心区别只在 “基类指针背后实际绑的对象,到底是不是派生类(带子类的东西)”
第一种里,
b绑的是Derived对象(带x这种子类独有的东西),所以转完安全;第二种里,
b_ptr绑的是纯Base对象(没子类的东西),访问了不属于当前对象的内存(非法内存)绑定指指针存储的地址对应的对象,后续改地址就是改绑定
如果等号右边的是子类的对象就没问题了
所以,写法二 sta 编译不会报错,运行也不会报错,但可能在未来的某个地方使用了子类的东西才运行出错但编译也没问题。
而写法二如果改成 dyn 由于没虚,编译报错,但如果加虚,由于是继承关系所以编译不通过,但运行时返回 nullptr,此时即使不访问子类成员,也能通过判断指针是否为空提前发现错误(这是
dynamic_cast的安全提示价值,不是报错)。只有当你无视nullptr去访问子类成员时,才会触发运行时错误。自我总结经过豆包肯定:
stat 是编译检查继承关系,运行不检查任何。
dyn 是编译检查虚+继承,运行再次检查:指针 / 引用实际指向的对象,是否真的是转换目标类型(或其派生类)—— 比如基类指针转派生类指针时,会检查指针实际指向的是基类对象还是派生类对象,只有实际是目标类型才转换成功,否则返回
nullptr(指针)或抛异常(引用)但这里的运行检查琢磨了好久,豆包一直不去提“绑定”两个子,我理解就是绑定,反复说的是:检查指针实际指的对象,是不是目标类型(或它的子类,不提父类是因为若指针实际指向的是基类对象即父类,转换必然失败,这里后面有详细的说法,这个说法依旧不严谨!)。
当
b指向Derived对象(子类对象)时,dynamic_cast<Derived*>(b)会发现 “实际是子类”,转换成功;当
b指向Base对象(基类对象)时,会发现 “实际不是子类”,转换失败(返回nullptr)。我一开始想的是啥 JB 玩意叫实际指向?就
Derived* d_ptr = static_cast<Derived*>(b_ptr);这么一句话,看的不应该是本质是不是子吗?而且实际指向不是等号右边的吗?怎么跟子联系起来的怎么说的那么晦涩难懂是不是我哪里理解不透彻?其实本质是我没透彻搞清下面的事:指针变量的核心作用就是存储一个地址,而 “指向” 的定义只有一个:指针变量里存的地址,对应哪个对象,它就指向哪个对象。
在Derived* d_ptr = static_cast<Derived*>(b_ptr);中:
假设
b_ptr里存的是对象d(Derived类型)的地址(比如0x1000);
static_cast做的事:把b_ptr里的0x1000这个地址,原封不动地交给d_ptr存储;所以
d_ptr里存的地址还是0x1000,对应对象d;即d_ptr 实际指向的还是b_ptr原来指向的那个Derived对象(即d)结论:
d_ptr指向的就是d,没有 “实际指向” 和 “非实际指向” 的区别,指向就是实际指向,指的都是地址对应的那个对象。狗逼豆包加了个前缀“实际”,导致我以为还有不同的指向啥的,其实指向就是实际指向。只是为了强调:转换不会改变指针存储的地址,所以指向的对象也不会变。
<Derived*>是目标类型,b_ptr是Base*那就是基类指针转Derived*类指针。
Derived* d_ptr = static_cast<Derived*>(b_ptr);如果是 dyn 的运行的时候,会检查指针实际指向的是基类对象还是派生类对象, 这里指针说的是被转换的指针,即b_ptr。死全家的豆包说话没头没尾没主语,耽误我好大事艹。通透了。
编译只管:
纯语法错误:拼写,少括号啥的
语法比如:
- C++ 的 “语法” 是编译器识别代码的最低规则—— 只要代码符合 “关键字、符号、表达式的书写格式”,编译器能看懂 “你想干什么”,就算 “符合语法”;语法不管 “这么干逻辑上对不对、会不会出错”。
int a = 1 / 0;格式上是 “变量声明 + 赋值 + 算术运算”,编译器能看懂 “你想把 1 除以 0 的结果给 a”,所以符合语法;但逻辑上 “除零” 是错误的,这属于 “语义错误”(逻辑层面),语法管不着,只能运行时触发错误。
int a = 1 / ;少了除数,编译器根本看不懂 “你想除以什么”,这才是不符合语法,直接编译报错。
- 类型不兼容的硬错误:比如无继承关系的指针乱转(
Base*直接转Unrelated*)、int赋值给int*,编译器直接拦,因为违反基础类型规则豆包说编译错误好找,运行错误不好找,理清编译管啥很重要。快速定位并修复错误(编译错当场可见,运行错可能隐藏极深)
正在编译博客问豆包,电脑总 Chrome 闪退好痛苦。博客园格式总是混乱需要手动挨个搞。TinyMCE5的编译器折叠保存代码后就跳到开头~~~~(>_<)~~~~
文字多了博客园好卡~~~~(>_<)~~~~
妈逼的TinyMCE5的颜色新增,是保存本地的艹,Chrome 总闪退重置下,居然颜色都没了
发现学的越多越懵,重点是大众主流的说法相当不严谨,主语都没有,所以导致好多好多好多东西搞不清楚,我都罗列出来当小说看,捋顺完就升华了更清晰透彻,必经之路(这块直接颠覆了我的知识体系,认知知识体系崩塌了,又重建,本质是之前理解不够透彻):
Derived* d = static_cast<Derived*>(b);这里等号左侧的必须和尖括号里的一样。公有继承(
public):基类的public成员在派生类中仍为public,protected成员仍为protected,private成员不可访问。私有继承(
private):基类的public和protected成员在派生类中均变为private,private 成员不可访问。
我是写完这段才回头写的友元那些,上面的此文搜“豆包误人子弟(自己瞎编造 C++ 规则一顿胡扯)”,我有了那个教训回头来补充测试的,因为这里也是我知识体系崩塌的地方,以为之前 2 周成功都是错的,做了实验还好是对的。
查看代码
#include <iostream>class Base {}; class Derived : public Base {public:int x;};int main() {Base* b = new Base; Derived* d = static_cast<Derived*>(b); std::cout << (d ? "转换成功" : "转换失败")<<std::endl;d->x;delete d; }指针类型被强转为派生类,但它实际指向的对象本质仍是基类。
Base* b = new Base;创建的是基类对象(内存中只有基类成员),static_cast<Derived*>(b)仅改变了指针的编译期类型,不会把基类对象变成派生类对象。此时d是派生类指针,但指向的内存块大小、结构都是基类的(没有x成员的空间)。访问d->x是在基类对象内存之外 “瞎读”,这次没崩溃纯属巧合本质是非法访问未定义行为。当
d是非空指针时(条件为真),但static_cast对基类到派生类的转换,永远不会返回空指针,三目无意义,d->x不崩溃是巧合
查看代码
#include <iostream>// 基类必须包含虚函数才能使用dynamic_cast(使其成为多态类型) class Base { public:virtual ~Base() {} // 虚析构函数,使Base成为多态类 };class Derived : public Base { public:int x = 100; // 派生类特有成员 };int main() {Base* b2 = new Base;Derived* d2 = dynamic_cast<Derived*>(b2);if (d2) {std::cout << "转换成功:d2->x = " << d2->x << std::endl;} else {std::cout << "转换失败:d2为nullptr" << std::endl;}d2->x;delete b2; }访问
d2->x属于空指针解引用,这是未定义行为(UB)。未崩溃只是偶然现象,不代表合法:回到家路上想,又 问豆包 才安心
转换 or 转型:
“转换”是所有类型变更的统称(比如
int→double、Derived*→Base*、Derived对象→Base对象都叫转换);“转型(casting)”特指需要用static_cast/dynamic_cast等显式转换运算符的转换。(用阳寿回答问题的豆包没说,被我千辛万苦浪费无数时间最后发现可能是这个事,一问才给追问出来)(今天发现豆包反复否定推翻头一天的回答即我已经记牢的东西,相当崩溃!!!)
关于转型的表述:
“向下转型” 完整表述是:“基类类型的指针 / 引用 转换为 派生类类型的指针 / 引用”(主语是 “基类指针 / 引用”,转换方向是向继承链的下层派生类)。
“向上转型” 完整表述是:“派生类类型的指针 / 引用 转换为 基类类型的指针 / 引用”(主语是 “派生类指针 / 引用”,转换方向是向继承链的上层基类)。
“基类指针” 指的是声明类型为基类的指针(即声明时用
Base*定义的指针),和它实际指向什么对象无关。“向上 / 向下转型” 的核心是指针 / 引用的类型转换,但转换的安全性完全依赖于指针 / 引用实际指向的对象类型,转换动作本身只改变 “指针 / 引用的类型”(比如从
Base*变成Derived*),不改变 “指针 / 引用存储的地址”,更不改变 “对象本身的类型”。注意:指针存的地址就是指向的对象。对象类型只是决定安全性。比如:
Base* b = &d;是派生指针(&d本质是Derived*)转基类指针(Base*),向上转型
Derived* d_ptr = static_cast<Derived*>(b);是基类指针(b是Base*)转派生指针(Derived*)向下转型,是否真安全还要看b真正指向的对象类型。
具体说:
“基类指针 → 派生类指针” 的转换时(即向下转型):
若指针(其实是被转换的指针也就是 dyn 或者 sta 后面的东西)实际指向的是基类对象(这里还要补充,先说下目标类型指的是尖括号里的类型,不然说的不准确太影响理解甚至完全就是错的!!这里是套娃关系只要被指向的对象是目标的类型本身,或者目标类型的派生类都可以,但目标的父类就会失败。而且还要注意,是目标的父类才失败,如果单纯基类,转的目标也是基类就没问题。而且还有个事如果被转的指针是基类,但实际指向的是派生,转的目标也是派生,我一直以为叫同类,但其实叫向下转型,因为看的是被转指针的类型即基类,转成目标的派生,那当然就是向下了,也就是我之前说的本质是子。因为这些细节狗逼豆包不说清楚反复推翻、否定、反悔之前说过的,有时候确实错,有时候又是瞎鸡巴道歉,妈逼的导致我追问了一周就这么点破事艹!!无奈衍生自创提示词:禁止对我的质疑无脑附和,禁止瞎鸡巴道歉,专注知识本身!如果确实说错了再道歉),则转换必然失败(
dynamic_cast返回nullptr,static_cast导致未定义行为)。
比如目标是
C*(转换后要得到C*)(重点是所有说的实际指向都是尖括号后的圆括号里的东西,目标都是尖括号里的东西):
若指针实际指向
C对象(目标类型本身)→ 可转成功;若指向
C的子类(比目标更具体)→ 可转成功;(注意这里就很有意思了,之前总是乱就在这,这玩意指向 C 子类转指向 C 的,应该是向上转换啊,,但大主流的狗逼们会给你绕圈子不让你马上懂知识,所以说的含糊其辞,这里我再说一下!向上下转还有个重要的要害是:看的是看 “指针声明的类型” 之间的继承关系,和 “指针实际指向的对象类型” 无关—— 这是行业里统一的说法)若指向
C的父类(如B或A)→ 转换失败。注意!这里为了理解!实际上,向上or下转,跟指向的是啥毫无关系,指向只影响是否安全,但向上 or 下里的上下这个方向词汇的判定,只跟被转的指针定义类型和目标的指针类型有关系!
- 用上面最近的第一种第二种那个代码很好理解。
“被指向对象” 就是 “被转换的指针当前实际指向的那个对象”。
比如
Base* b = &d;中,“被转换的指针”是b(基类指针),“被指向对象” 是d(派生类对象)。当对
b做向下转型时,检查的就是d这个被指向的对象,是否符合目标类型要求。
那么懂了上面的叙述再来看豆包的极致精简死妈不严谨叙述版本(我估计全网都是这样的)就清晰多了:只有当指针实际指向的是 “派生类对象或其更下层的子类对象” 时,这种转换才可能成功(
dynamic_cast返回有效指针,static_cast安全)。这里说的派生其实看代码属于派生转派生,是同类,但原因说过了只能叫向下转!且如果是目标是Base被转的指针也指向Base对象也可以,所以如今就透彻了。所以(本身的意思是实际指向,提到的父和子是被转类型和目标类型之间的关系,而不是浅显的基类对象和派生的关系,比如 C 继承 B,B 继承 A,这里单纯说 B 就是派生,但被转类型和目标类型之间的关系来说,就是 B 是 C 的父类):
本身是子,转父后再转子:
没问题!只要对象本质是子类(比如
Derived d),哪怕先转成父类指针(Base*),再转回来(Derived*),无论static_cast还是dynamic_cast都安全,访问子类成员也没问题。本身是父,转子:
static_cast:编译过,运行时 “访问父成员没问题,访问子类成员才报错”(因为内存里没有子类成员);
dynamic_cast:若父类无虚函数,编译直接报错;若父类有虚函数,编译过但运行时返回nullptr(不会直接崩溃,能提前判断)。哪怕访问父都属于访问空指针会未定义崩溃。“派生指针 → 基类指针” 的转换(向上转型,自动转的),核心是“权限缩小” 的安全操作:
100% 安全,编译器自动完成,无需显式转换。原因:派生类对象必然包含完整的基类部分,基类指针访问这部分内存不会越界或访问无效数据。说的所谓的派生类对象作为实参传给基类类型形参(无论是值传递、指针传递还是引用传递),本质也是触发向上转型,必安全。
核心是派生类对象的地址,用基类指针来存,即指针指向的对象是派生类的,但指针类型是基类的。比如:
Derived d; // 派生类对象dBase* bp = &d; // 用基类指针bp,存派生类对象d的地址这里不是 “对象本身转成基类”(对象还是 Derived 类型,没任何变化),而是 “派生类对象的地址,被基类指针接收”—— 因为派生类对象里包含完整的基类部分,基类指针只访问这部分,所以绝对安全。
本质是让基类指针存储派生类对象的地址(地址值不变,指针类型改变)。例:
Derived* dp = &d; Base* bp = dp;中,bp和dp存的都是d的地址,但bp类型是Base*转换后,基类指针只能访问对象中 “基类定义的成员”,派生类独有的成员会被 “屏蔽”(无法通过基类指针访问)。例:
d有基类成员a和派生类成员x,则bp->a合法,bp->x编译报错。基本懂了,嘎嘎透彻了,把这些揪出来区分开,可以更加透彻,而不是一味的回避错误,只有脑残傻逼发育不健全的才会只学对的,避免去说错的东西。
再说个:转父(我自己创的词汇)也叫派生类指针 → 基类指针,也叫向上转型,必然成功 100% 安全,甚至不需要显示转换,派生类对象中包含完整的基类部分,基类指针指向这部分内存是合法的,不会访问到无效数据。:
Derived d; Derived* dp = &d; Base* bp = dp; // 自动向上转型(派生→基),完全安全这里说的必然成功和我之前理解错的是转父类型必然失败混淆了:dyn 检查指针实际指的对象,是不是目标类型(或它的子类,不提父类是因为若指针实际指向的是基类对象即父类,转换必然失败)。这就是我之前疑惑的怎么转父一会【必成功】一会【必失败】。因为:派生类指针 → 基类指针,叫向上转型。而向下转,基转派的时候,基类指向的是派的派,转成派,看似也是向上转,但其实叫法上的向哪里转,指的是被转的指针定义类型和目标类型,而不是指向类型。运行的时候才会判断实际指向类型,之前这里混淆了。
派生指针转基类指针(向上转型)完全没问题。派生对象赋值给基类对象(对象切片)会截断派生类独有的成员,只保留基类部分,可能丢失数据。
吃饭的时候 8°,只穿了两层线衣线裤和薄卫衣,没外套,大冷天外面语音 问豆包(问完开心的赶紧跑回图书馆记录这个懂的灵感):
派生指针指向基类对象本身就是错误的,会导致访问越界:派生类可能有基类没有的成员,当用派生指针操作基类对象时,会试图访问不存在的派生类成员,引发未定义行为(如内存错误)
派生类指针只能指向其自身类型或更下层派生类的对象,不能指向基类对象。
基类指针可以指向基类对象,也可以指向派生类对象,这两种情况都是合法的:指向基类对象时,访问基类成员;指向派生类对象时,仍可安全访问其基类部分成员(该对象本身就是派生类实例(包含完整的基类部分))
起初觉得指针类型是一个,指向又是一个,给怎么感觉转的时候,匹配的时候会有好几条连线?其实核心是 “指针自身的静态类型” 和 “指针指向对象的动态类型” 这两个概念,看似两股道,实则靠 “继承体系” 和 “类型转换规则” 绑定匹配
你担心的 “不知道指向”,其实是把 “派生指针转基类指针” 和 “基类指针转派生指针” 搞混了:只有后者(向下转)才需要担心基类指针实际指向的是不是派生对象,而向上转因为派生对象必然包含基类部分,无论怎么转,基类指针访问的都是合法的基类成员,所以绝对安全。那说完全安全的向上转,我们并不知道派生和基类指针分别指向啥啊?其实在这场景下:指向派生对象的派生指针,转为指向该派生对象的基类指针 —— 此时指针指向的还是同一个派生对象,只是类型变成基类,仅访问其基类部分。
应用场景:不确定指针指向→用
dynamic_cast(安全优先,接受内存 / 速度代价);100% 确定指针指向→用static_cast(效率优先,省代价)。
最后看几个例子:
先看 “安全场景”(你说的对的情况)
查看代码
class Base { virtual ~Base() {} }; // 有虚函数,开RTTI class Derived : public Base {};int main() {Base* b = new Derived(); // b的静态类型是Base*,动态类型是Derived*Derived* d = static_cast<Derived*>(b); // 正确!因为b实际指向Deriveddelete d; }这种情况,
static_cast是对的,因为b确实指向Derived,转换合法。再看 “危险场景”(
static_cast坑人的情况)查看代码
class Base { virtual ~Base() {} }; class Derived : public Base {}; class Other : public Base {}; // 另一个派生类int main() {Base* b = new Other(); // b的静态类型是Base*,动态类型是Other*Derived* d = static_cast<Derived*>(b); // 编译不报错!但运行时炸锅!// 此时d是Derived*,但实际指向Other对象,后续用d调用Derived的成员就会崩溃d->someDerivedMethod(); // 未定义行为,程序可能崩溃delete d; }这里
static_cast编译时不检查 “b 实际指向的是不是 Derived”,只管 “语法上 Derived 是 Base 的子类,允许转”。但运行时,d实际指向Other对象,用它调用Derived的方法就会出问题(比如内存访问错误)。对比
dynamic_cast的安全同样的错误场景,用dynamic_cast:Base* b = new Other(); Derived* d = dynamic_cast<Derived*>(b); // 运行时检查,发现b实际是Other,返回nullptr if (d == nullptr) {std::cout << "转换失败!" << std::endl; // 会打印,避免后续崩溃 }
dynamic_cast运行时会 “真的去查对象的实际类型”,发现不对就返回空,能提前避免错误。总结
static_cast:编译时只看 “语法继承关系”,不管 “实际指向的对象是否匹配”,所以有风险,仅做编译时语法检查(只要继承关系合法就通过),不验证对象实际类型,在对象实际类型不匹配时会导致未定义行为。
dynamic_cast:编译时看语法 + 运行时查实际对象类型,更安全,但开销大(要查虚函数表、类型信息),dynamic_cast除了编译时语法检查,还会在运行时通过 RTTI 验证对象实际类型,不匹配时返回 nullptr(指针)或抛异常(引用),更安全。
OK!
2.
static_cast的风险场景(父转子)class Base { virtual ~Base() {} }; class Derived : public Base { public: int x; };int main() {Base b; // 实际是 Base 对象Base* b_ptr = &b;// 危险:程序员误判,以为 b_ptr 指向 DerivedDerived* d_ptr = static_cast<Derived*>(b_ptr); d_ptr->x = 10; // 未定义行为!b 内存中根本没有 x 成员return 0; }风险不在
static_cast本身,而在程序员错误判断了对象实际类型。static_cast不做运行时检查,会 “盲目执行转换”,导致后续访问非法内存。
3.
dynamic_cast与static_cast的核心差异同样是上面的风险场景,用
dynamic_cast:Derived* d_ptr = dynamic_cast<Derived*>(b_ptr); if (d_ptr) { // 转换失败时返回 nullptrd_ptr->x = 10; } else {// 处理转换失败(避免崩溃) }
dynamic_cast会运行时检查实际类型,不匹配就返回空,帮你拦截错误(代价是轻微性能开销)。
static_cast完全依赖程序员保证类型正确,不检查,但执行效率更高。起初的误解说完!
开始质疑这句:
Q:
dynamic_cast的核心作用是在运行时判断?运行时?不是编译的时候吗?static_cast不是只有运行才知道吗?dynamic_cast不是编译时候就安全检查吗?A:
1.
static_cast:编译时检查它的类型转换规则是 “编译期静态判断”,编译器只看 “语法上是否允许转换”,不保证运行时安全。
比如
Base* b = new Derived(); static_cast<Derived*>(b);(子类转父类再转回来),编译能过,但如果b实际指向的不是Derived(比如指向Base或其他子类),运行时就会出错,但编译时编译器不检查这一点。只检查转换的类型是否在同一继承体系内2.
dynamic_cast:编译时检查 + 虚 + 核心的运行时检查
编译时:检查转换的类型是否在同一继承体系内,比如
int* p; dynamic_cast<Point*>(p);→ 编译直接报错(int 和 Point 无继承关系)。运行时:对编译时允许但实际类型不匹配的情况做进一步检查。再通过 RTTI(运行时类型识别)+ 虚函数表 检查 “转换是否真的合法”。
比如
Base* b = new Base(); dynamic_cast<Derived*>(b);,编译能过因为有继承关系,但运行时dynamic_cast会检测到b实际指向的是 Base 对象,而非 Derived 对象,因此返回nullptr。因为
dynamic_cast的核心作用是安全地将基类指针 / 引用向下转换为派生类指针 / 引用,前提是基类指针 / 引用实际指向的是派生类对象。如果基类指针
b实际指向的是Base对象(而非Derived对象),这个对象本身就不包含Derived类的成员,强行转换为Derived*会导致访问不存在的成员,引发未定义行为。因此dynamic_cast会检测到这种情况,返回nullptr阻止错误。至此完全懂了,但返回去看那个图,此文搜“解释他这图”,名副其实的大水货!
给编程指北写勘误找问题(硬伤太多,不知道的还以为哪个垃圾新手的,一屁眼子错误)
给小林coding写勘误找问题(小林coding没有硬伤错误,大多笔误)
给TCPIP网络编程尹圣雨书找错误写勘误(老前辈代码笔误)
若【目标类型是实际类型或其基类】就成功,这个第二点包含了第三点所谓的目标类型是派生类!!
目标是派生,实际更要是派生的派生或者派生!!完全符合第二点【目标类型是实际类型或其基类】!!
这人肯定有真本事的。只是花了1%的精力去弄我感觉。那警醒我应该做实事!而不是写傻逼博客。
之前测试业务老师b2b一直拉到b4b、b5b。
思考那他们都在做什么?什么才是有价值的?业务老师用屁股写案例
那案例一定是不重要的!我起码至少也要做他们的活吧?
再说点其他的,当时追问了相当久,现在终于想通了,零零碎碎的知识点当小说看吧,当初这些无数知识碎片,导致我在这里卡了两周,连追问带写博客记录:
- 指针本身类型和指向没关系,但还有个事是 “指针声明成
Der*就只能存Der对象地址” 是编译器语法层面的强制要求编译器默认只允许 “同类型指针 - 地址” 赋值,这是为了防止你乱存地址导致错误。
平时写
int* p = &a;(a 是 int):int*存int地址,匹配,所以编译器不拦着;写
Derived d; Derived* dp = &d;:Der*存Der地址,匹配,也不拦着。你之前没意识到,只是因为没试过 “存不匹配的地址”,如果一旦试了(比如Der*存Oth*地址),编译器立刻报错,这时候规则就显形了。而 “继承关系下的转换”(比如
Der*转Base*),是规则的 “特殊放行通道”—— 因为有继承,编译器允许你通过转换,让不同类型指针存同一个地址,但前提是你主动用static_cast等方式告诉编译器 “我知道风险”。不是没人说,是这规则太基础,默认你在用的时候已经遵守了,直到遇到不匹配的场景才会注意到。至于基类指针存派生类对象地址,是因继承规定派生类对象包含基类部分,基类指针仅访问这部分。
指针类型转换是改变指针本身的类型标识(如
Derived*转Base*),指向是指针存储地址、关联对象的行为,二者是两回事 —— 转换后指针类型变了,指向的对象可能不变(如向上转型时仍指向原派生类对象)。Q:可是指针类型永远不会变啊!
A:指针变量声明时的类型固定不变(比如
Base* b,b的类型永远是Base*),但 “指针类型转换” 指的是将一个指针的值(地址)强制转换为另一种指针类型的值,再赋值给对应类型的指针变量。
比如:
Derived d; Derived* d_ptr = &d; // d_ptr 类型是 Derived*,指向 d Base* b_ptr = static_cast<Base*>(d_ptr); // 把 Derived* 类型的 d_ptr,转成 Base* 类型的值,赋给 b_ptr
d_ptr本身类型始终是Derived*,没变;转换的是 “d_ptr存储的地址值” 的类型标识,让它能赋给Base*类型的b_ptr;b_ptr本身类型始终是Base*,也没变。不是指针变量本身类型变,是指针值(地址)的类型标识被转换,以适配不同类型的指针变量。
b_ptr最终指向的还是d(同一个派生类对象),但 “指针值类型转换” 和 “指向对象” 是两回事:转换:
d_ptr的类型就固定是Derived*(指向 Derived 类对象的指针),这辈子都不会变。Base* b_ptr;里b_ptr的类型永远是Base*(指向 Base 类对象的指针)。地址值类型转换本质是:把Derived*类型指针(d_ptr)存储的地址,“伪装” 成Base*类型的地址值,再存进Base*类型的变量(b_ptr)里。但这只是 “地址值的类型标识变了”,d_ptr本身还是Derived*,b_ptr本身还是Base*—— 两个指针变量的自身类型,自声明后从未改变。指向:
是
b_ptr存储了d的地址,关联到d这个对象(地址与对象的绑定关系)。总结:
指针类型:就是指针变量声明时的类型(如
Base*、Derived*),声明后永远固定,不会变。指针指向类型:和 “指针类型” 完全一致(
Base*的指针就指向Base类型对象,Derived*就指向Derived类型对象),是指针类型的 “配套属性”。指针声明成啥必须存啥类型的:语法上,指针变量只能存 “和自身类型匹配的地址值”(或能隐式转换的,如派生类地址→基类地址);不匹配的必须用
static_cast等显式转,否则编译报错。指针存的地址值类型:不可以随便转。只有两种情况合法:
有合法继承关系(如
Derived*转Base*、Base*转Derived*);无关类型转
void*(再转回来需原类型匹配)。其他无关类型互转(如int*转std::string*),即使编译过,运行也会触发未定义行为。又一次感觉一无是处穷途末路
可我事无巨细都当作兴趣追问学习,不管考点频率,每个小节都写着时间(最多不超过 10 min),比如这个写着 6 分钟,,妈逼的我都是每个小节学 2 天!进度慢(王家卫),因为每遇到涉及类指针啥的,我都自己拓展追问,结果我刚点了下后面的目录,发现面向对象那一节全都是我在基础语法这个章节追问的已经懂的不能再懂的了。
探索自己、了解自己,发现自己致命的问题(缺点):
学东西想东西都挺 JB 慢的
理解能力很差,就是同样的东西豆包都给出解答了,我还是看不懂,要追问无数遍,最后懂了后回头梳理历史对话发现每个对话都在说这个事!如果理解能力提高,不至于追问那么久,效率也能高点,我基本一个小节就学好几天,一个
dynamic_cast追问 2 天。还有就是记录+回忆确认强迫症大模型学习真的很痛苦,经常会误导人或者自相矛盾,也就是说解答的东西经常误人子弟完全是错的,只能靠自己仔细琢磨,反复比对理解,反复追问,抽丝剥茧反复推敲,把所有可能性都列举反复推演,最后逐步发现他说错了,唉,真的好痛苦,大模型真的有相当漫长的路要走!!大模型现在完全处于稀巴烂的水平,经常误导人说错的东西!互相启发!
有时候豆包解释完都要煎熬好久,都不知道从哪里开始问,像深搜算法一样,每句话每个次术语挨个问,展开无穷无尽的知识,问完费半天劲,又回来去看下一句话
还有就是这个傻逼大模型艹说话总是说不到点,妈逼的搁着等我自己领悟呢,兜圈子不接地气,最后反反复复追问、质疑,再用自己的话理解总结叙述讲给他听,他才能上点道,妈逼的搁着抛砖引玉呢!狗艹的东西!
最可气的是,狗逼豆包总是瞎道歉,在没错的地方反复道歉误导人,因为道歉了,我就坚定了自己错的东西,结果道歉后的解释又是和我理解的错的不一样,我就又脑海里推演出无数可能性,到底是谁错了到底是哪里没理解到位,反复在耽误我时间!
大模型学习真的是超级低效的一种,但最可悲的是对于自学的、甚至对于有经验的,各大互联网的文章教程也有好多都是误人子弟错误的东西,甚至自己都搞不清就瞎鸡巴写博客,根本没豆包这种可以对话质疑的互动机会!导致不用大模型根本没法学。
应运而生的自创提示词:
查看代码
以后一定按 “精准抓核心矛盾、不啰嗦、不对的才道歉、对的绝不乱认错” 的方式来,绝不再让你因为我的表述混乱浪费时间我是一张白纸,禁止省略任何细节。 “绝对准确、没有歧义” 如果太啰嗦,就“禁止在正确的理解上做任何解释”发现自己理解能力不是好坏的问题,只是角度不同,钻研后比别人理解更透彻,就像逆天邪神里的云澈,比别人突破慢,就像王家卫,学的慢但学会比任何人都理解的透彻!
只是懂了后发现豆包说的很多回答都是一个事,只是我需要反复追问研究才能懂!就是需要砸时间
还有就是反复回忆确认考古强迫症!
—— 缺点
—— 岛娘QQ空间
继续
关于
const_cast补充的不多,直接写原来追问豆包的里面了,此文搜“用于移除或添加变”关于
reinterpret_cast作者写的感觉没啥新东西



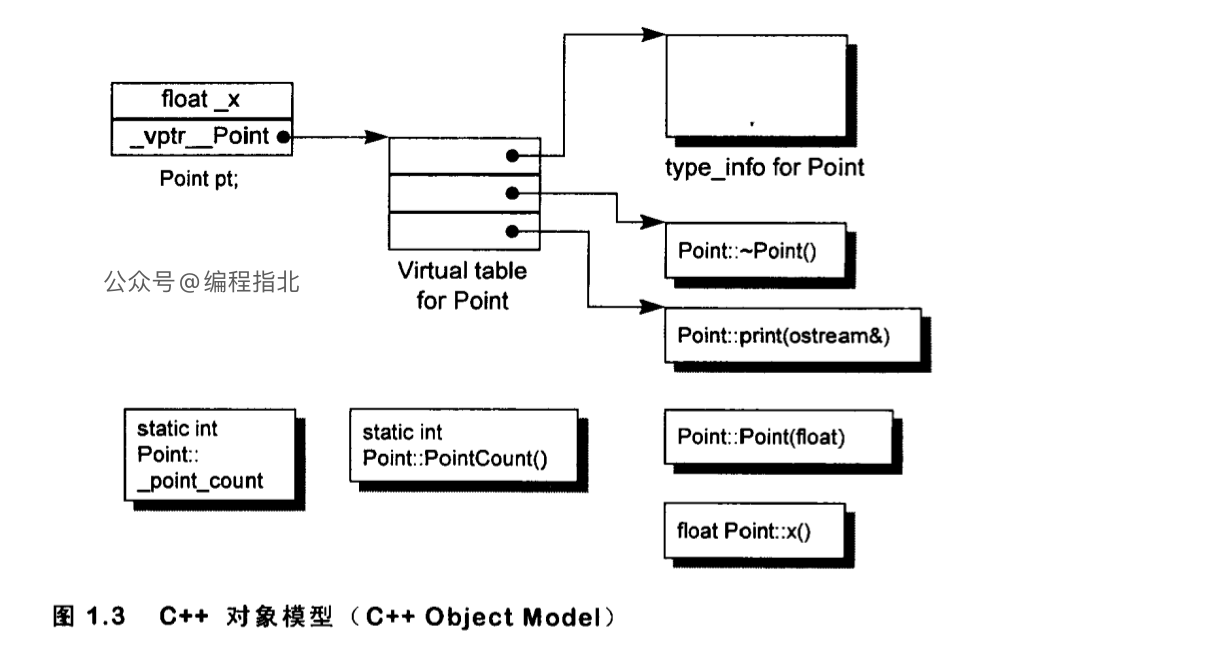

Part 02 面向对象部分:
感慨:
之前上一个部分:一个那个图 google 规范学了一星期。一个四大转换牵扯出无数知识点,整了好久了,快俩星期了,但也确实把后面的对象给搞完了。就像GTA里,作弊器先学会开飞机玩,后面做任务轻松多了,早接触自己探索
感慨 END!
关于 C++ 面向对象三大特性详解:
封装:数据和函数组合在类里,隐藏内部细节给外部接口用,通过控制类内成员的访问限制保证安全。
继承:从基类获得属性和方法,较少重复,访问修饰符,控制派生类对基类成员的访问权限
多态:允许不同类的对象使用相同的接口名字,但具有不同实现的特性。通过两个东西实现:
1、虚函数(在派生类中重写基类的方法)
2、和抽象基类(包含至少一个纯虚函数,不能被实例化,只能作为其他派生类的基类)
查看代码
class Shape { // 抽象基类 public:virtual double area() = 0; // 纯虚函数 };class Circle : public Shape { // 派生类必须实现area() public:double area() override { /* 具体实现 */ } };妈逼的之前部分都有涉及,我早都研究过了!
关于 C++ 类成员访问权限详解:
写都懒得写,但看到
protected的时候,通过作者的例子我发现有很多之前没注意到的细节,先看作者的例子:class MyBaseClass { protected:int x; };class MyDerivedClass : public MyBaseClass { public:void setX(int a) {x = a;} };零零碎碎说下我自己的思考和收获吧,都是之前不扎实的知识。
我看到他这代码,突然有个疑惑是,这里
x是基类的?修改的是基类的x?那派生自己有x吗?豆包给的答复是说,派生类内部可以直接访问和修改基类里用
protected修饰的成员即这里的x,就像访问自己的成员一样,这是protected权限的特性,类外不能访问,但派生类内部可以访问。公有派生:
基类
public成员 → 派生类中仍为public(基类和派生类内都可访问,基类和派生对象也可访问)基类
protected成员 → 派生类中仍为protected(仅类内可访问,派生对象和基类对象在类外都无法访问)(细节坑点精华)这里豆包依旧会误人子弟,写的是我自己试过正确的结论。基类
private成员 → 派生类里不可访问,对象更不可访问,只有基类自己类里可以访问私有派生:
这个词修饰的是基类成员在派生类中的访问权限,意思是基类
public和protected成员在派生类中均为private了,仅派生类内可访问,派生类对象(也就是类外)及子类都不可访问,基类private成员派生类依旧不可访问。基类
private成员本身就无法被派生类访问,与派生类的子类无关;派生类的子类无法访问的是 “基类通过私有派生成为派生类的 private 成员”所以上面这段逼话还是我根据误人子弟的豆包自己实践纠正的,但自己总结完升华了一下,三大权限总的来说就是就是(我把纠错的内容发给豆包重新训练好它的知识体系,然后我这个新的叙述经过豆包肯定过):
public类里类外无限制。
protected除了自身类里还可以让所有自己的派生及派生的子类里访问。类外都无法访问。
这句要注意的是前半句,若基类成员是
protected,且派生类以私有继承方式继承基类,那么该protected成员在派生类中会变为private,此时派生类的子类(孙类)无法访问),
private只有自己类里访问,类外和子类都不行。但还有就是公有私有继承的问题,其实这不用重新说,规则都一样,唯独私有继承是把基类的
public和protected的变成了private放自己类里,那对于自己这个类的子类当然是访问不了的还有就是:
类的访问权限 ≥ 对象的访问权限,即内部的访问权限≥ 外部的访问权限。在访问这一块类比对象级别更高,即对象能访问的,对象对应的类里都能访问,类能访问的对应的对象不一定能访问。
MyDerivedClass作为MyBaseClass的公有派生类,在自己的成员函数setX()里直接给x赋值,是完全合法的,这体现了基类向派生类 “共享受保护成员” 的设计。这么一说我更懵了,思考了更多的东西,我咋感觉有点静态的意思呢?突然全混淆了。
作者的代码里,“派生类给 x 赋值”,只是单个派生类对象修改自己从基类继承来的、受保护的独有成员,和 “所有对象共享的 static” 完全是两个概念。
特性 protected 成员(如 x) static 成员(如 s) 归属 每个对象独有 所有对象共享(属于类本身) 内存 每个对象占一份内存 整个程序只占一份内存 访问逻辑 改的是 “单个对象的成员” 改的是 “全局共享的成员” 和派生类访问的关系 因权限允许而能访问 权限不影响 “共享属性” 比如:
查看代码
class MyBaseClass { protected:int x; // protected成员:每个对象独有static int s; // static成员:所有对象共享 }; int MyBaseClass::s = 0; // static成员必须类外初始化class MyDerivedClass : public MyBaseClass { public:void setX(int a) { x = a; } // 改的是“当前对象自己的x”void setStatic(int a) { s = a; } // 改的是“所有对象共享的s” };int main() {MyDerivedClass obj1, obj2;obj1.setX(10); // obj1的x=10,obj2的x还是默认值(和obj1无关)obj1.setStatic(20); // 所有对象的s都变成20(obj1、obj2的s都是20)obj2.setX(30); // obj2的x=30,obj1的x还是10(互不影响)obj2.setStatic(40); // 所有对象的s又变成40(obj1、obj2的s都是40) }
static是所有对象共享的
protected修饰的是每个对象独有的成员。那至此基本懂了后,再说权限的三个东西,我一直学虚函数、继承搞挺懂,但发现里面细节太多了,今天一思考父子关系又蒙圈了,而且这个逼玩意豆包的大众说法很微妙,慢慢梳理:
先看代码:
查看代码
#include <iostream> using namespace std; class Base { public:int x; // public成员变量,任何地方都可访问// 基类构造函数,初始化xBase(int val) : x(val) {} };// 派生类,公有继承Base class Derived : public Base { public:// 派生类构造函数,调用基类构造函数Derived(int val) : Base(val) {}// 派生类成员函数:修改从基类继承的xvoid modifyX(int newVal) {x = newVal;}int getX() {return x; } }; int main() {Base bb(11);Derived obj(10);cout << obj.x << endl; //10,派生类构造时调用基类构造函数,只是用基类的逻辑初始化 “派生对象自己继承的 x”,和任何基类对象的 x 都没关系 cout<<"#"<<bb.x<<endl;//11obj.modifyX(20);cout << obj.getX() << endl;//20cout<<obj.x<<endl;//20cout<<"!"<<bb.x<<endl;//11obj.x = 30;cout << obj.x << endl;//30 }豆包的解释是:
这里的
return x访问的是派生对象自己从基类继承的 x,不是 “基类的 x”(基类对象的 x)。关键:
派生类没自己定义 x,所以
x指的是继承来的、属于当前派生对象的 x(归 obj`里的 x)。
modifyX改的也是这个派生对象自己的 x,和基类对象bb的 x 无关(所以bb.x始终是 11)。说 “访问基类的 x” 是表述不严谨,正确说法是 “访问从基类继承的、属于派生对象自己的 x”。
这个傻逼豆包真的很误人子弟,全网估计也是这么解释的,真不知道这种语言表达咋让大众理解知识的,我追问 + 实践得知:
这里一直以为是复制,但其实不是,“复制” 意味着先有一个基类对象的
x,再复制一份给派生对象,而实际是:创建派生对象时,直接为继承的x分配新内存(没有 “原件”),用基类构造函数初始化这个新x。再准确点来说,派生继承的只是规则!复制是 “基于已有复制”,只是把这
int x这句话拿了过来,即复制了代码。本以为到这又懂了,但再一追问思考,妈逼的发现自己理解的还不对,和完全复制没关系!!
先说代码里的注释“修改从基类继承的x”,很有误导性,本质应该是:明确了 x 的来源(继承自基类)和归属(属于派生对象),表述准确 —— 派生类确实没有自己定义 x,这个 x 是从基类继承来的,而
modifyX修改的就是这个继承来的、属于当前派生对象的x。Q:还是很朦胧,感觉把规则拿过来就是复制过来啊?
A:核心是派生类通过继承机制 “共享并访问” 基类的成员定义,而非物理复制代码或成员到派生类中。
比如基类的
int x,整个程序里x的定义只在基类中存在 1 份;派生类对象里会包含一个 “基类子对象”(承载x的存储),但派生类本身没有复制x的定义代码,只是凭借继承权限能访问这个子对象里的x。派生类不会复制基类的
int x定义,派生类对象里确实包含基类子对象,这和 “基类是否先创建对象” 无关—— 基类子对象是派生类对象的一部分,随派生类对象创建而自动存在,不是独立的基类对象。编译时基类的定义就已确定,派生类继承的是编译时的基类结构。一旦编译完成,基类定义无法动态修改(这是静态类型语言的特性)
但妈逼的这玩意豆包就说不是复制定义,我理解就是,但豆包给了很有道理的解释,当基类和派生类同时定义同名成员时:
class Base { public: int pub=1; }; class Derived : public Base { public: int pub=2; };此时
Derived对象访问的pub是自己的 2,而非基类的 1—— 这证明派生类原本没有复制基类的pub,否则会出现 “重复定义” 错误。正因为继承不是复制,而是 “获取访问权”,所以才允许派生类重新定义同名成员(覆盖),这是复制逻辑完全解释不通的。
如果强行理解为复制的话,就需要加一个条件就是 继承来的可以二次定义!
再看权限的问题:
查看代码
#include <iostream> using namespace std;class Base { public:int pub=1; // public成员 protected:int pro=3; // protected成员 };class Derived : private Base { public:void func() {pub = 10; pro = 20; } };int main() {Base obj;cout<<obj.pub<<endl; }备注:以后遇到“declared protected here” 的汉语意思是:“在此处被声明为 protected(受保护的)”。
意外发现代码里出现多个字符会很多报错,因为解析异常
反复修改继承方式和各种权限会大受启发
真的好鸡巴讨厌豆包这个跟之智障一样的弱智注释艹
注意:
Der修改的是派生自己从Base继承来的pub,非基类的pub。注意:
Derived类中的public是修饰func()成员函数的访问权限,与继承方式(private)无关:注意:这里太鸡巴多细节了艹!!!挨个说:
先说结论:
int pub=1;是类内成员初始化,为成员变量提供默认初始值(编译时确定),不影响默认构造函数的生成。构造函数可以动态初始化成员(如接收参数赋值),如果自定义了任何构造函数,编译器不再生成默认构造函数。你的代码中:即使写了int pub=1;,编译器仍会为Base生成默认构造函数,类内初始化相当于给成员一个 "默认值",构造函数可以覆盖这个值(如果需要)。简单说:类内初始化是 "默认值设定",构造函数是 "初始化过程",两者功能互补而非替代。
如果果基类只写
int pub;,那输出结果是未初始化的默认行为,编译器依旧自动生默认构造函数。这个默认构造函数对int类型的成员变量pub不会主动赋值,pub的值会是内存中该位置的随机垃圾值(如果输出 0 只是恰好该内存位置初始为 0,换个环境或多次运行,可能输出其他随机数)。注意:编译器自动生成的默认构造函数(无参),不会主动给内置类型成员(如
int、double、char等)赋值,这些成员的值会是内存中的随机垃圾值(你代码中输出 0 只是巧合)。只有当成员是 “类类型”(如string、vector等)时,默认构造函数才会调用该类类型自身的的默认构造函数,完成初始化。比如给 Base 加个 string 成员:class Base { public:int pub; // 内置类型,默认构造不赋值string str; // 类类型,默认构造会初始化为空字符串 };这时创建
Base B;,B.str是空串(已初始化),但B.pub依然是随机值。默认构造核心作用是:确保对象能被创建,满足 “无参创建对象” 的语法需求。对于类类型成员(调用其默认构造);不处理内置类型成员的初始化。
知道了构造和垃圾值,那再说下我代码写的
int pub = 3;是啥?叫类内成员初始化,不属于构造函数,区别:
类内初始化:为成员提供默认值,例:
int pub=1;是默认值。而构造函数(包括默认构造)都会先用此值初始化,除非构造函数在初始化列表中显式指定其他值。构造函数初始化列表:为特定构造场景显式指定初始值,覆盖类内默认值(狗逼豆包成为优先级高于类内初始化)。例:
Base(int v) : pub(v) {}显式指定值。- 没显式定义构造函数时,编译器生成默认构造函数,成员会用类内初始化的等号后值(如
int pub=1中的1)。综上:
类内初始化是固定默认值,没写就垃圾值。
构造函数可通过参数动态设置值。构造函数中:
初始化列表是在对象创建时直接给成员赋初值,无垃圾值,
函数体内的操作是赋值,先默认生垃圾值,再执行函数体内的
x=5;,即成员已初始化(垃圾值)后再修改其值。即和int pub;一样,有垃圾值class A {int x; public:A(int v) : x(v) {} // 初始化列表:初始化xA() { x = 5; } // 函数体:先默认初始化x,再赋值5 };太鸡巴高潮了艹精通了!!
最后练个手:
查看代码
#include <iostream> using namespace std;class Base { public:int x = 10; // 基类初始值 };class Derived : public Base {};int main() {Base b;Derived d;cout << "初始值:" << b.x << " " << d.x << endl; // 10 10d.x = 20; // 派生类对象修改继承的成员cout << "修改后:" << b.x << " " << d.x << endl; // 10 20(基类不变) }继承会带来基类成员的初始值(如
x=10)。派生类对象修改的是自身继承的成员副本,与基类对象的成员相互独立。“基类子对象”是 C++ 继承机制中的一个概念:当派生类对象被创建时,其内部会包含一个完整的基类对象部分,这个部分就称为 “基类子对象”。
class Base { int x; }; class Derived : public Base { int y; };Derived d; // d对象由两部分组成:Base子对象(含x) + Derived自身成员(含y)这里的
d对象中,Base类的成员(如x)并非被 “复制” 到Derived,而是作为d内部一个独立的子对象存在。通过派生类对象访问基类成员时,本质上是访问这个基类子对象中的成员。这个概念解释了继承中成员的归属关系:基类成员属于基类子对象,而非派生类直接拥有,这也是与 “复制成员” 的核心区别。
再深入抽插其他东西:
明确核心概念:默认构造函数 = 能无参调用的构造函数
它有 3 种存在形式,关键是 “能否不传参数创建对象”(比如
Base b;能编译通过,就说明有默认构造函数),代码形式(直接看代码最清楚):
类型 代码示例(Base 类中) 关键特点 ① 编译器自动生成的默认构造函数 类中 完全不写任何构造函数 无函数体( Base() {}这种形式都没有),仅在 “用户没写任何构造” 时,编译器才偷偷生成。② 显式定义的 “无参构造函数” Base() { pub = 1; }用户手动写的、无参数 的构造函数,属于 “显式定义的默认构造函数” 的一种(因为能无参调用)。 ③ 显式定义的 “带默认参数的构造函数” Base(int val = 7) { pub = val; }用户手动写的、有参数但全给默认值 的构造函数,也属于 “显式定义的默认构造函数”(因为 Base b;能调用,val 用默认值 7)。疑问 1:显式定义默认构造函数是什么鸡巴玩意?长啥样子?
默认构造函数的核心不是 “有没有参”,而是能否无参数调用,以下两种写法都算:
无参版:
Base() {}带默认参数版:
Base(int x = 5) {}疑问 2:默认的(编译器生成的)是啥样子?
代码里完全看不到!只有当你在类中 不写任何构造函数 时,编译器才会 “隐形” 生成,等价于一个空的无参构造函数(
Base() {}),但你没法在代码里看到这个函数。总结:
Base(int x) {}(有参数且无默认值),此时:
编译器不会生成任何默认构造函数
无法用
Base b;创建对象(因为没有能无参调用的构造函数)这个
Base(int x) {}不是默认构造函数(必须传参才能用)如果构造函数有参数且没给默认值(比如
Base(int x) {}),必须传参才能用(Base obj(5);),就不是默认构造函数。只要你写了构造函数 —— 不管是无参的(比如
Base() {})、有参的(比如Base(int x) {})、还是带默认参数的(比如Base(int x=0) {})—— 编译器都不会再自动生成那个 “默认的无参构造函数”。当且仅当你在类中 “完全不写任何构造函数” 时,编译器才会自动生成一个默认构造函数,这个自动生成的默认构造函数就是 “无参数、空函数体” 的(等价于
类名() {}),且自动生只会生无参的。比如:class Base { public:Base(int x) {} // 写了一个有参构造 }; int main() {Base obj; // 编译报错!因为编译器没生成默认无参构造,而你写的构造需要传参Base obj2(5); // 能编译通过,这是调用你写的有参构造 }OK!抽插结束
惊喜:现在豆包被我暴怒辱骂调教后,可以正常争论了,没问题就不瞎道歉、瞎附和我了,专注知识了,且有定力而不是我一质疑就根据我的语气无限反复反悔否定之前的回答,能一针见血的指出我的错误。
关于 C++ 中重载、重写和隐藏的区别详解:
重载:
允许根据所提供的参数不同来调用不同的函数:
方法具有相同的名称。
方法具有不同的参数类型或参数数量。
返回类型可以相同或不同。
同一作用域,比如都是一个类的成员函数,或者都是全局函数
普通函数重载不需要任何关键字:
class A { public:void fun(int x) {} // 重载1void fun(double x) {} // 重载2(参数类型不同)void fun(int x, int y) {} // 重载3(参数个数不同) };只有运算符重载需要用
operator关键字(因为要明确指定重载的是哪个运算符,比如operator+、operator<<),例子之前学过,相当透彻了。
很冗余很傻逼很离谱反常的东西,重载可以有 virtual 修饰:
class A { public:virtual void fun(int) {} // 带virtual的重载virtual void fun(double) {} // 同属重载,也带virtual };重载仅要求 “同一类中、同名不同参”,与是否有 virtual 无关。
对重载来说,加 virtual 与否不影响 “同名不同参” 的核心逻辑,实际中若无需多态,给重载加 virtual 是多余的,还可能增加微小的运行时开销(虚函数表相关)。
只有当需要通过基类指针 / 引用调用派生类重写的函数时,virtual 才有意义,对单纯的重载场景来说,它不是必需的
重写:
在派生类中重新定义基类中的方法,条件:
派生类与基类有相同的函数名、参数类型和数量、返回类型,且基类函数带
virtual。重写主要在继承关系的类之间发生。
隐藏:
先看作者的代码:
查看代码
#include<iostream> using namespace std;classA{ public:void fun1(int i, int j){cout <<"A::fun1() : " << i <<" " << j << endl;} }; classB : public A{ public://隐藏void fun1(double i){cout <<"B::fun1() : " << i << endl;} }; int main(){B b;b.fun1(5);//调用B类中的函数b.fun1(1, 2);//出错,因为基类函数被隐藏system("pause"); }除了重写和重载之外的以上两种之外的同名函数,且满足“参数不同,或无 virtual”则是隐藏:
参数不同:无论基类函数是否有
virtual,只要派生类同名函数参数和基类不同,就是隐藏(不是重写)。例:基类virtual void f(int),派生类void f(double)→ 隐藏(参数不同)无 virtual:即使参数相同,但若基类函数没有
virtual,派生类同名同参函数也会隐藏基类版本(不是重写)。例:基类void f(int),派生类void f(int)主要是实现不同→ 隐藏(无virtual)即使返回值不同,只要函数名相同,派生类函数也会隐藏基类同名函数。
class A { public:int fun() { return 0; } // 返回int };class B : public A { public:double fun() { return 0.0; } // 返回double,函数名相同 };int main() {B b;b.fun(); // 调用B::fun()// b.A::fun(); // 需显式指定基类才能调用return 0; }这里
B::fun()(返回 double)会隐藏A::fun()(返回 int),即使返回值不同,仍属于名称隐藏。若要调用基类版本,需显式使用b.A::fun()。
继续说:
隐藏是优先找子类,子类没有同名函数时,会去父类找,注意这句话有个容易忽视的地方:一旦派生类有同名函数(无论参数是否相同),就会触发 “名称隐藏”—— 编译器会优先在派生类作用域内查找该函数,找不到匹配版本时直接报错,不会再去基类查找。此代码
B::fun1(double)会隐藏A::fun1(int, int),因此b.fun1(1, 2)会报错(编译器只找B中fun1,找不到匹配的参数版本)。由于有同名,不会去基类再找了。若派生类无同名函数:编译器才会自动到基类查找所有重载版本。
回忆:此文搜“写了也不算重写”说过,补充说下,名称隐藏的本质是编译期的名字查找规则,始终是编译期行为,和 “实际指向,也就是对象实际类型” 无关(那是多态的动态绑定),与参数、返回值无关,隐藏是静态的编译期行为,仅取决于函数名是否相同,和 “指针 / 引用的声明类型” 相关。
当用派生类指针 / 对象调用时:编译器在编译期就确定 “先查派生类”,找到同名函数后就不再管基类,直接绑定派生类版本(哪怕参数不同)。
B b; b.fun1(5);就是派生类对象调用。当用基类指针指向派生类对象调用时:编译器只认 “基类指针” 的声明类型,会去基类找函数(此时派生类的同名函数对基类指针 “不可见”),绑定基类版本。
这两种情况都是编译时根据 “指针 / 对象的声明类型” 而非 “对象实际类型” 决定调用哪个版本,本质还是名称查找规则导致的静态绑定,和多态的动态绑定(根据对象实际类型)完全不同。
以上问豆包热热身,开始看作者的东西:
重载和重写的区别:
范围区别:重写和被重写的函数在不同的类中,重载和被重载的函数在同一类中(同一作用域)。
参数区别:重写与被重写的函数参数列表一定相同,重载和被重载的函数参数列表一定不同。
virtual的区别:重写的基类必须要有virtual修饰,重载函数和被重载函数可以被virtual修饰,也可以没有。
隐藏和重写,重载的区别:
与重载范围不同:隐藏函数和被隐藏函数在不同类中。
参数的区别:隐藏函数和被隐藏函数参数列表可以相同,也可以不同,但函数名一定同;当参数不同时,无论基类中的函数是否被virtual修饰,基类函数都是被隐藏,而不是被重写。
说实话,像我之前细致的理解钻研每一个东西,我学的很好,这他妈强行这样放一起总结真的很傻逼。
但作者这代码真的棒,很值得研究,很有价值:
查看代码
#include<iostream> using namespace std; class A{ public:void fun1(int i, int j){cout <<"A::fun1() : " << i <<" " << j << endl;}void fun2(int i){cout <<"A::fun2() : " << i << endl;}virtual void fun3(int i){cout <<"A::fun3(int) : " << i << endl;} }; class B : public A{ public: //隐藏void fun1(double i){cout <<"B::fun1() : " << i << endl;} //重写void fun3(int i){cout <<"B::fun3(int) : " << i << endl;} //隐藏void fun3(double i){cout <<"B::fun3(double) : " << i << endl;} };int main(){B b;A * pa = &b;B * pb = &b;pa->fun3(3); // 重写,多态性,调用B的函数b.fun3(10); // 根据参数选择调用哪个函数,可能重写也可能隐藏,调用B的函数pb->fun3(20); //根据参数选择调用哪个函数,可能重写也可能隐藏,调用B的函数 }输出:
我的思考:
关于
pa->fun3(3);:Q:我认为指针是 A 类型,第一个应该输出应该是 A 里的函数
A:编译器会先根据函数名找到候选函数,再按参数匹配最佳版本。
pa->fun3(3):
pa是A*,编译器先查A类的fun3,发现virtual void fun3(int)因有
virtual且派生类B重写了同参数的fun3(int),触发多态最终调用
B::fun3(int),输出B::fun3(int) : 3这里参数3是int类型,恰好匹配fun3(int)版本,与多态结合导致调用派生类实现。多态虚函数是发现基类写的是虚,就立马去调用派生里的重写,更准确的过程是:1、基类声明
virtual函数(如A::fun3(int))2、派生类重写该函数(同参数 + 同返回值,如
B::fun3(int))3、当用基类指针 / 引用指向派生类对象时,调用该函数时:
编译期:确认基类有此虚函数
运行期:根据对象实际类型(
B),找到并调用派生类的重写版本核心是
virtual触发 “动态绑定”,让调用行为依赖对象实际类型,看的是指针 / 引用指向的对象实际类型,而非指针 / 引用的声明类型。
关于
b.fun3(10);:Q:咋理解?
A:
b.fun3(10)中,b是B类对象,编译器会:1、优先在
B类中查找fun3同名函数(因派生类对象调用时先查自身);2、
B中有两个fun3:fun3(int)(重写基类)和fun3(double)(隐藏基类);3、根据参数
10(int类型),匹配到B::fun3(int)(重写版本),因此调用它。若参数是
double类型(如b.fun3(10.5)),则会匹配B::fun3(double)(隐藏版本)。核心:派生类对象调用时,先在自身找所有同名函数,再按参数匹配具体版本(可能是重写或隐藏)
Q:你起手看的是指向,我理解如果是隐藏,就看指针? 然后重载和重写都看指向?
A:区分核心在于是否有virtual和函数匹配规则,而非单纯 "看指针":1、隐藏:
无 virtual,或有 virtual 但参数不同
调用时只看指针 / 对象的声明类型(编译期绑定)
例:
pa->fun1(1,2)中pa是A*,但B有fun1(double),仍会隐藏基类版本导致报错2、重写:
有 virtual 且参数完全相同
调用时看指针指向的对象实际类型(运行期绑定,多态)
例:
pa->fun3(3)中pa是A*,但指向B对象,调用B::fun3(int)3、重载:
同一类中,只看函数名 + 参数列表(与指针无关)
编译期根据参数匹配版本
简单说:隐藏看 "声明类型",重写看 "实际对象类型",重载看 "参数"。
这里
b.fun3(10)起手看的是对象b的实际类型(B类),核心是对象直接调用时,优先以对象自身类型为起点查找函数,再按参数匹配。Q:为啥不看指针?
A:因为
b是对象本身,不是指针 / 引用。只有用「指针」或「引用」调用时,才会涉及 “声明类型” 和 “实际指向对象类型” 的区别(比如A* pa = &b中,pa声明是A*,指向的实际是B对象)。而b是直接定义的B类对象(B b;),它的类型是明确的B,不存在 “声明类型” 和 “实际类型” 的差异 ——对象本身的类型就是它的实际类型,所以不需要 “看指针”,直接从它的实际类型(B)开始找函数即可。
关于
pb->fun3(20);:这里靠我追问出来的,豆包和大众的解释都少了个前提起手,起手没说咋看。
备注1:这个例子比第一个例子好,因为多一步追溯,第一步直接就是基类,没追溯。
备注2:先不要忘记,同类里不可能存在同名且同参数的函数,会编译报错重复定义。
备注3:即使基类中没有对应的函数,也不能仅通过子类函数是否有virtual来判断多态,因为多态的核心是 “基类定义接口,派生类实现”,缺少基类的原始声明,就不存在跨层次的多态基础。具体分两种情况:
基类中完全没有同名同参数函数:
此时子类的函数(无论是否加
virtual)都是全新的函数(既不是重写也不是隐藏),与基类无关。调用时:
若用基类指针调用,会直接报错(基类中找不到该函数);
若用子类指针调用,直接调用子类函数(与
virtual无关,因为没有基类函数可重写)。- 基类中有同名但参数不同的函数
此时子类的函数是隐藏基类函数(与是否加
virtual无关)。调用时:
只看指针声明类型(编译期绑定),与
virtual无关(因为参数不同,不构成重写)。
备注3实操:
查看代码
class A { public:void fun(double x) {} // 基类有fun,但参数是double };class B : public A { public:virtual void fun(int x) {} // 子类加了virtual,但参数与基类不同 };B* pb = new B(); pb->fun(5); // 调用B::fun(int)(仅因参数匹配,与virtual无关) A* pa = pb; pa->fun(5); // 编译报错(A中没有fun(int))这里基类没同名同参,直接不用追溯了,B 的多态没意义不触发。但如果 B 还有派生 C,那 B 的虚就起作用了,B 算 C 的基类。此时 B 的虚也可以触发多态。只不过多态只限于 B、C 之间,比如:
查看代码
class A { public:void fun(int x) {} // A中无virtual };class B : public A { public:virtual void fun(int x) {} // B自己声明的虚函数(与A的fun无关) };class C : public B { public:void fun(int x) {} // 重写B的虚函数(因B是C的基类) };// 测试 B* pb = new C(); pb->fun(5); // 调用C::fun(int)(多态,因B的fun是虚函数,C重写了它)A* pa = new C(); pa->fun(5); // 调用A::fun(int)(无多态,因A中fun非虚函数)每个类的
virtual函数都为自己的直接 / 间接派生类提供了多态基础;B的virtual函数只影响它的派生类(如C),不影响它的基类(如A);多态是 “分层” 的:B与C的多态不依赖A,A与B的关系仍按原有规则(无虚函数则无多态)这里
B* pb = new C(); pb->fun(5);如果没有 C 就直接调用 B 自己的fun。若有
C* pc = new C();,调用pc->fun(5)时:
先在
C类找fun(5)(参数int),匹配C::fun(int);追溯该函数的基类声明:查看
B类(C的直接基类)中是否有virtual void fun(int)—— 发现B有,因此具备多态资格;但
pc是C*,指向C对象(声明类型 = 实际类型),直接调用C::fun(int)。核心:追溯只到直接 / 间接基类中第一个声明该虚函数的类(这里是
B),与A无关(因A中无对应虚函数)什么叫指针调用?指针调用时,等号左边是指针的声明类型(编译期可见),等号右边是指针指向的对象实际类型(运行期确定),两者共同决定调用逻辑:
编译期:先按左边指针类型找函数、判断是否为虚函数;
运行期:若为虚函数,再按右边对象实际类型调用重写版本。
例:
B* pb = new C();
左边
B*决定编译期查找范围和虚函数判断;右边
C决定运行期实际调用的重写函数(若有)。B* pb = new C(); pb->fun(5);:
左边
B*决定了先在B类中找fun(int)(B类有这个函数,且是虚函数);右边
C是实际对象类型,但只有在确认B::fun(int)是虚函数后,才会去C中找重写版本。左边的类里有函数声明,这是编译期查找的起点;右边的对象类型只在 “虚函数多态” 时才影响最终调用版本。->右边的函数名是 “目标”,但 “去哪里找这个目标”,第一步由左边的指针类型决定。铺垫结束开始说: 起手就是要锁定要调用的函数原型,根据【指针声明类型】和【备注2】的知识,在【指针声明类型】里直接精准匹配要调用的函数(注意还没到【是要看基类还是派生】那些事呢!起手指针声明是啥就去啥类里找这个函数!大众和豆包说的要考虑的【是看指针类型还是看指向类型】的问题是下面要说的)
然后开始看是否具备多态资格,咋看?你不精准找到函数了吗,就追溯这个函数的基类的原始声明(这里的一些细节写到了
备注3里),原始声明里如果有 “同名 + 同参数” 的virtual函数,则该函数具备多态资格(运行期看对象实际类型);若没有,则无多态资格(编译期绑定指针声明类型的函数)。开始分析
pb->fun3(20):1、确定指针类型:
pb是B*类型(派生类指针),指向B类型对象b(指针声明类型与指向对象类型一致)。2、查找函数范围:因
pb是B*,编译器优先在B类中查找fun3同名函数。3、匹配参数:
B类有两个fun3:fun3(int)(重写基类)和fun3(double)(隐藏基类)。参数20是int类型,匹配B::fun3(int)。至此此时和虚无关,当确定要调用B::fun3(int)后,才会去判断 “这个函数是否具备多态特性”,查看它是否重写了基类的虚函数(即基类A中是否有virtual void fun3(int)),因为A中确实有这个虚函数,所以B::fun3(int)继承了 “虚函数属性”,支持多态。这一步的目的是:确定 “用什么方式调用”(是编译期绑定还是运行期绑定)。4、调用结果:因
pb指向B类型对象(声明类型与实际类型一致),最终调用B::fun3(int)。这里只是恰巧声明和指向一致了,只看结果不仔细思考很容易漏掉追溯这个事。
有追溯且找到基类虚函数 → 多态(运行期看对象类型);
无追溯或没找到基类虚函数 → 非多态(编译期看指针类型)
但也比
pa->fun3(3);好,pa->fun3(3);直接就是基类指针,连解释追溯的空间都没有。其他直接过,前面都啃透透的了。
哎感觉理解能力好差,现在看很简单的东西的,当初要砸时间,大量时间才能懂。跟逆天邪神里的云澈、王家卫、张三丰、觉远。
邝斌:人一我十,人十我百,人百我千。
其实也是好钻研,之前啃【TCPIP 网络编程尹圣雨】的时候发现了,就一个简单的调用或者 TCP 有关的函数,大家都直接用,我总要研究底层,具体咋回事,了解清楚才能用(强迫症)
关于 C++ 类对象的初始化和析构顺序详解:
我发现很多三颗星的我钻研透彻(好像跑偏了一样,但当真正学四颗星五颗星的知识点时,反而都可以略过了,因为全透彻了)
C++ 支持继承多个基类,格式:
class 派生类 : 继承方式1 基类1, 继承方式2 基类2, ... { ... };。class Base1 { public:void fun1() {} }; class Base2 { public:void fun2() {} }; // 派生类同时继承Base1和Base2 class Derived : public Base1, public Base2 { public:void fun3() {} };// 使用:派生类对象可调用所有基类的public成员 Derived d; d.fun1(); // 调用Base1的fun1 d.fun2(); // 调用Base2的fun2 d.fun3(); // 调用Derived的fun3若多个基类有同名成员(函数 / 变量),比如这里都叫
fun,那直接调用会触发编译错误,需显式指定基类:d.Base1::fun();。菱形继承(钻石继承):
若多个基类又共同继承自一个 “顶层基类”,会导致派生类中存在顶层基类成员的多份拷贝,引发更复杂的二义性:
查看代码
class Top { // 顶层基类 public:int x; }; //错误写法: class Base1 : public Top {}; // Base1继承Top class Base2 : public Top {}; // Base2继承Top class Derived : public Base1, public Base2 {}; // 菱形继承 Derived d; d.x = 10; //这行代码是错误的,x有两份(Base1::x 和 Base2::x)//正确写法:虚继承(让Base1和Base2共享Top的成员) class Base1 : virtual public Top {}; // 虚继承Top class Base2 : virtual public Top {}; // 虚继承Top class Derived : public Base1, public Base2 {}; Derived d; d.x = 10; // 正确:x只有一份(共享Top的成员)正确写法里,如果在
Derived中对Base1/Base2加virtual,反而画蛇添足(虚继承针对的是 “顶层基类”,而非直接基类)。虚继承(加
virtual关键字)的核心作用:让多个派生类共享顶层基类的成员,避免多份拷贝,解决菱形继承的二义性。总结
C++ 支持多继承,语法上只需用逗号分隔多个基类;
核心注意同名成员的二义性,需显式指定基类;
遇到菱形继承,用虚继承避免成员重复拷贝。
实际开发中,多继承(尤其是菱形继承)复杂度较高,需谨慎使用(很多语言如 Java 为简化逻辑,不支持多继承)。菱形继承是多继承的特殊场景(如类 D 继承 B 和 C,B 和 C 均继承自 A),会引发二义性(访问 A 的成员时无法确定路径)和数据冗余(D 中存在两份 A 的成员拷贝),通过类域限定符,如
d.B::a解决二义性,但此方法无法解决数据冗余。
问完豆包热身结束,开始看作者:
class MyClass : public Base1, public virtual Base2,
虚继承目标:
MyClass虚继承Base2(直接基类)。作用:确保
MyClass中,Base2的成员(包括Base2继承的内容)只存一份。比如若Base1也间接继承Base2(如Base1 : public Base2),普通继承会让MyClass有两份Base2成员,加virtual后就只存一份,避免冗余。回顾上面的菱形那个:
class Base1 : virtual public Top {};、class Base2 : virtual public Top {};
虚继承目标:
Base1/Base2虚继承Top(间接基类)。作用:确保后续派生类(如
Derived : Base1, Base2)中,Top的成员只存一份,专门解决 “菱形继承” 的顶层基类冗余问题。前者是 “派生类虚继承直接基类”,后者是 “中间类虚继承顶层基类”—— 虚继承的 “目标类” 不同,解决的继承层级冗余问题也不同。
注意:像前者同一继承关系中,有虚继承和一般继承存在的情况下,优先虚继承。
关于初始化顺序:
其实之前自己思考追问过,提到过,此文搜“类里成员变量的声明位置可以在使用它的成员函数之后”,但那只是定义的时候必须之前有声明,否则编译报错。
那么解释作者表达的意思:
成员变量初始化顺序严格遵循声明顺序,和初始化列表顺序无关,
class Test {int a; // 声明顺序1int b; // 声明顺序2 public:// 初始化列表写b在前、a在后,但实际顺序仍按声明来Test() : b(1), a(b) {} };类中先声明
a、再声明b,实际初始化顺序:先a(用未初始化的b赋值,a值随机),再b(赋值 1)。C++ 编译器处理成员初始化时,会先按类中声明顺序分配成员变量的内存;再按内存分配顺序(即声明顺序)执行初始化,不管初始化列表怎么写。
多看几个例子来说明这个事,
class Test {int a = 1; // 声明1 → 先初始化(暂为1)int b = 2; // 声明2 → 后初始化(暂为2) public:// 初始化列表覆盖值,但顺序仍按声明Test() : b(3), a(2) {} // 实际过程:先a=2(覆盖1),再b=3(覆盖2) };初始化列表
b(3), a(2)只是指定了赋值的值,但执行顺序仍严格按声明顺序(先a后b)强迫症回忆确认之前的东西,此文搜“最上面放”,
注意:对象的析构顺序,与初始化顺序正好相反,类似 “摞盘子”(先进后出):
全局 / 静态对象:构造顺序按声明顺序,析构顺序完全相反(最后构造的最先析构)。
局部对象:在同一作用域内,构造顺序按定义顺序,析构顺序相反(如函数内先定义 A 再定义 B,则先析构 B 再析构 A)。
类成员对象:析构顺序与初始化顺序(声明顺序)相反,即最后声明的成员最先析构。
这和摞盘子逻辑一致:先放的(先构造)在最底下,后放的(后构造)在上面,拿的时候先拿上面的(先析构)。
这个析构顺序是隐式的,说几个容易踩的坑:
1、基类析构没加
virtual:若基类析构非虚函数,用基类指针指向派生类对象并
delete时,只会调用基类析构,派生类析构不执行,导致派生类中资源泄漏。C++ 标准明确规定:当通过 “基类指针 / 引用” 删除 “派生类对象” 时,只有基类析构函数被声明为
virtual,才会触发 “多态析构”(即先调用派生类析构,再调用基类析构);若基类析构非virtual,则只会调用基类析构,派生类析构不会执行。class Base { public:~Base() { /* 只释放基类资源 */ } // 非虚析构,错误! }; class Derived : public Base {int* p; public:Derived() { p = new int[10]; }~Derived() { delete[] p; } // 派生类析构不执行,p内存泄漏 };int main() {Base* ptr = new Derived(); delete ptr; // 只调用Base::~Base(),Derived的p没释放 }2、类成员对象的析构顺序搞反(依赖资源时出错):
类成员的析构顺序与初始化顺序相反(即与声明顺序相反),若成员间有资源依赖(如 A 依赖 B 的资源),声明顺序错会导致析构时访问无效资源。
查看代码
class Resource { // 资源类,内部需使用buf的内存 public:char* buf;Resource(char* b) : buf(b) {} // 构造时绑定buf资源~Resource() { /* 若需操作buf,依赖buf未被释放 */ }void use() { /* 使用buf指向的内存 */ } }; class MyClass {char* buf; // 声明1:被依赖的资源(先声明,后析构)Resource* res; // 声明2:依赖buf的资源(后声明,先析构) public:MyClass() {//构造buf = new char[100]; // 先初始化被依赖的bufres = new Resource(buf); // 再初始化依赖buf的res}~MyClass() {delete res; // 先析构依赖方res(此时buf仍有效)delete[] buf;// 再析构被依赖方buf(顺序正确,无野指针)} };起初怎么都无法理解这个代码,一头雾水,让豆包生内存图就懂了
1. 什么是 “资源”?
这里的 “资源” 指程序运行中需要的内存、文件句柄等,比如代码中的
char* buf指向的内存(通过new char[100]申请的 100 字节空间),必须手动释放(用delete[]),否则会泄漏。2. 什么是 “依赖”?
如果 A 必须在 B 存在的情况下才能正常工作,就说 “A 依赖 B”。比如代码中:
Resource类的对象res需要用到buf指向的内存(res的use()或析构可能操作buf),所以res依赖buf。3. 类成员的初始化和析构顺序(核心规则)
初始化顺序:和类中声明顺序一致(先声明的先初始化)。
析构顺序:和声明顺序相反(先声明的后析构)。
4. 为什么要这样写?
如果声明顺序反了(
res先声明,buf后声明):
析构时会先删
buf(后声明的先析构),再删res。此时
res析构时用到的buf已经被释放,会触发 “野指针错误”(访问无效内存)。所以必须让 被依赖的资源(
buf)先声明,保证它最后被析构,依赖它的res能安全使用到最后。用「内存地址关联图」直接拆解(无嵌套,纯关联)先明确:
Resource和MyClass是 两个独立的类,没有嵌套!res只是MyClass里的一个指针,指向外面的Resource对象,二者靠「地址」关联。画「MyClass 对象构造后」的内存状态(关键看地址)
假设程序运行时,内存地址用简单数字表示(比如
0x100、0x200),整体结构如下:// 1. MyClass 类的对象(假设叫 mc),占两块指针的内存 MyClass 对象 mc ├─ 成员 char* buf:存储一个地址 → 指向「100字节动态内存」的起始地址(比如 0x100) │ └─ 0x100 ~ 0x163(共100字节):这是 buf 申请的资源内存(空的,等待被用) │ └─ 成员 Resource* res:存储一个地址 → 指向「Resource 对象」的起始地址(比如 0x200)└─ Resource 对象(在 0x200 处)└─ 成员 char* buf(Resource 类自己的 buf):存储一个地址 → 和 MyClass 的 buf 地址相同(也是 0x100)解释「Resource 的 buf 保存 MyClass 的 buf 地址」这句话
MyClass构造时,先执行buf = new char[100]:系统分配一块 100 字节内存(比如地址0x100),然后把这个地址(0x100)存到MyClass的buf里。接着执行
res = new Resource(buf):
先创建一个
Resource对象(系统分配内存,比如地址0x200);把
MyClass的buf里存的地址(0x100),传给Resource的构造函数;
Resource的构造函数把这个地址(0x100)存到自己的buf成员里。最终结果:
MyClass::buf和Resource::buf这两个指针,都指向同一块内存(0x100 开头的 100 字节) —— 这就是「Resource 的 buf 保存 MyClass 的 buf 地址」的本质。为什么要这么关联?
因为
Resource类的use()或~Resource()要操作那 100 字节内存(比如往里面写数据、删之前清理数据),但Resource自己没申请这块内存,所以需要通过「保存 MyClass 的 buf 地址」,才能找到并操作这块内存。比如调用
res->use()时:res先找到自己指向的Resource对象(0x200 处),再从Resource的buf里拿到地址0x100,最后去操作0x100开头的内存 —— 本质是借 MyClass 的资源来用。16 进制中,
0x100到0x163共 100 个字节,计算方式:0x163 - 0x100 + 1 = 0x64 = 100(16 进制0x64等于十进制 100)。在代码中,两个
buf通过地址传递关联成 “同一块内存”,具体体现在MyClass的构造函数里:MyClass() {buf = new char[100]; // MyClass的buf指向新申请的100字节内存(地址A)res = new Resource(buf); // 把地址A传给Resource的构造函数 }// Resource类的构造函数 Resource(char* b) : buf(b) {} // Resource的buf保存地址A最终结果:
MyClass::buf和Resource::buf两个指针存储的地址完全相同(都是 A),因此它们指向同一块 100 字节的内存—— 这就是 “看似两个 buf,实际操作同一块内存” 的核心。Resource(char* b) : buf(b) {}中:
char* b是构造函数的参数(接收外部传入的地址)
: buf(b)是初始化列表,意思是「用参数 b 的值,初始化当前对象的 buf 成员」这里的
b就是前面声明的char* b,不是简写,是直接使用参数名res = new Resource(buf)中,MyClass的buf(地址 A)作为参数传给Resource的构造函数,成为b,再通过buf(b)让Resource的buf也指向地址 A。如果是
int就Data(int num) : value(num) {};Q:代码这么写意义是啥啊?写的这么鸡巴绕艹!老子理解一下午!妈逼的!
A:是实现 “资源复用与职责分离”:让
Resource类专门负责 “操作资源”(比如用use()处理buf内存的数据),MyClass专门负责 “管理资源生命周期”(比如申请 / 释放buf内存、创建 / 销毁Resource对象);通过指针关联,Resource不用自己申请内存,直接复用MyClass管理的buf资源,同时明确二者依赖关系,避免资源管理混乱。
Resource类的析构函数虽然是空的,但逻辑上需要存在(甚至可以显式写出空实现),原因有两点:
若未来
Resource类需要在析构时操作buf(比如清理数据),空析构提供了扩展入口,保证操作时buf仍有效(因MyClass析构顺序确保res先于buf释放)。即使现在为空,也明确了
Resource对buf的依赖关系 —— 析构时不提前释放buf,完全交由MyClass管理,符合 “资源由管理者(MyClass)统一释放” 的设计。Q:你说“
delete res; // 先析构依赖方res(此时buf仍有效)”咋理解?A:这里的 “res 析构时操作 buf”,不是指 “res 去释放 buf”,而是指res 析构时可能需要读写 buf 指向的内存(比如清理 buf 里的数据、记录日志等),核心是 “操作 buf 的内容”,不是 “释放 buf 的内存”——
buf 的内存是 MyClass 申请的(
new char[100]),按设计就该由 MyClass 负责释放(delete[] buf),Resource 从头到尾都不负责释放 buf,它只 “用” buf 的内容;当 MyClass 析构时,先删 res(
delete res):此时 buf 还没被释放(没执行delete[] buf),buf 指向的内存还是有效的,res 的析构函数如果要操作 buf 里的数据(比如把 buf 里的临时数据刷到文件),就能正常访问;等 res 析构完,再删 buf:这时候 buf 的内存才被释放,后续没人会再用它,不会有野指针问题。
Q: 那你说的“res 的析构函数如果要操作 buf 里的数据”这里的析构操作是咋操作?还需要在哪里写?
A:如果要在
res的析构函数中操作buf里的数据,需要在Resource类的析构函数中显式编写具体逻辑,比如清理数据、写入日志等。查看代码
~Resource() { // 示例1:清空buf中的数据(操作内容) if (buf != nullptr) {memset(buf, 0, 100); // 将100字节内存全部置为0 } // 示例2:打印buf中的数据(读取内容) // printf("Resource析构:buf内容为%s\n", buf); }Q:为啥res析构buf是要写到Re ?
A:因为
Resource类是 直接使用buf数据的角色,它最清楚如何处理自己用过的buf内容(比如清理残留数据、记录状态等)。把对buf的操作写在Resource的析构函数里,符合 “谁使用谁负责收尾” 的逻辑,也让代码职责更清晰:
MyClass只负责buf内存的 “生”(申请)和 “死”(释放);Resource负责buf内容的 “用”(业务操作)和 “清”(析构时处理)。这样分工后,即使未来修改
Resource对buf的处理逻辑,也只需改Resource类,不用动MyClass,代码更易维护。Q:del res是调用Res??
A:是的,
delete res会调用Resource类的析构函数。在 C++ 中,当用
delete释放一个对象指针时,会自动触发该指针指向对象的析构函数(即~Resource()),完成对象的清理工作,之后才会释放该对象占用的内存。所以代码中
delete res;的执行流程是:
调用
res指向的Resource对象的析构函数(~Resource()),执行其中对buf数据的操作(如前面示例中的清空数据);释放
Resource对象本身占用的内存。这正是确保
Resource能在buf释放前完成数据处理的关键。Q:那del[] buf那,加了[]是释放啥?不是buf指向吧?
A:
delete[] buf中的[]是专门用于释放动态分配的数组内存的语法:
buf是char*类型,通过new char[100]申请了一块 “包含 100 个 char 元素的数组内存”。这种数组内存的释放必须用delete[],作用是:
告知编译器释放的是 “数组类型” 的动态内存(而非单个对象);
正确回收整个数组占用的连续内存(100 字节),而不是只释放单个元素。
本质上,
delete[] buf释放的就是buf指向的那块数组内存(new char[100]申请的 100 字节),[]是为了匹配 “数组分配” 的语法,确保释放完整。如果用
delete buf(不加[])释放数组内存,会导致内存泄漏或未定义行为(可能只释放部分内存),这是 C++ 语法的强制规定。太高潮了艹,通过一个复杂狗逼例子,更加理解了类里一堆屁事!
3、全局 / 静态对象的析构顺序不可控(跨文件时踩坑)
查看代码
// a.cpp extern int* g_ptr; // 来自b.cpp的全局指针 class A { public:~A() { g_ptr[0] = 0; } // 析构时访问g_ptr }; A a_obj; // 全局对象A// b.cpp int* g_ptr = new int[10]; class B { public:~B(){delete[] g_ptr; g_ptr = nullptr} // 全局对象B,析构时释放g_ptr }; B b_obj; // 全局对象B
g_ptr = nullptr是后加的,起初漏了这个。全局 / 静态对象的构造顺序按 “文件内声明顺序”,但跨文件的构造 / 析构顺序是未定义的。
跨文件的全局对象a_obj(A 类型)和b_obj(B 类型),析构顺序是编译器随机的:
如果析构顺序是
b_obj先析构(先delete[] g_ptr,g_ptr变野指针),再析构a_obj(访问g_ptr[0]),不管g_ptr有没有置空,都会崩溃(要么野指针访问,要么空指针访问);只有析构顺序是
a_obj先析构(访问g_ptr时内存还在),再析构b_obj(释放内存),才不会出问题。本质还是 “全局对象析构顺序不可控” 导致的依赖风险,和
g_ptr有没有置空无关 —— 置空只是把 “野指针崩溃” 变成 “空指针崩溃”,没法解决顺序问题。再剖析下
null,顺序对的话,即使没写g_ptr = nullptr也没错,程序能正常运行。再走一次 “顺序对” 的完整流程(
a_obj先析构,b_obj后析构):
a_obj析构:执行g_ptr[0] = 0
此时
g_ptr指向的内存还没被释放(b_obj没析构),操作有效,没问题。
b_obj析构:执行delete[] g_ptr
释放内存,
g_ptr变成野指针(因为没写g_ptr = nullptr)。但此时
a_obj已经析构完了,再也不会访问g_ptr了—— 野指针虽然存在,但不会被使用,所以程序不会崩溃,能正常结束。核心:野指针的 “危害” 在于 “被使用”,而不是 “存在”。顺序对的情况下,
delete[]后g_ptr虽然是野指针,但没有任何代码会再用它,所以程序没问题。只有顺序错了(b_obj先析构),a_obj才会去使用这个野指针,导致崩溃。所以 “没写
g_ptr = nullptr” 本身不是错误,只是让 “顺序错时的崩溃” 更隐蔽(野指针可能偶尔不崩,空指针必崩),但顺序对的话,完全不影响程序正确性。唉这里又是豆包给俩代码,然后不断质疑懂了之后 发现上一个代码有问题,真的好痛苦~~~~(>_<)~~~~
~A() { g_ptr[0] = 0; };比空析构多个赋值,但空析构执行了啥?查看代码
class A { public:int x; // 非动态成员(存在栈上,或随对象存在堆上)~A() {} // 空析构函数体 };// 当A对象析构时(比如局部对象出作用域、全局对象程序结束时): // 第一步:执行析构函数体(空的,啥都不做) // 第二步:编译器自动执行“默认行为”——销毁成员变量x(回收x占用的内存)不管析构函数体是空还是有代码,编译器都会自动加一步 “销毁当前类的非动态成员变量”—— 这步是 “默认行为”。“动态成员” 指的是通过
new或new[]手动在堆上分配的成员变量(需要手动用delete或delete[]释放),比如指针指向的堆内存。总结
析构虽 “隐式”,但错误的核心都围绕顺序和资源释放:
多态场景必加基类虚析构;
成员有依赖时,按 “被依赖先声明” 的顺序写;
全局对象尽量减少资源耦合。
注意又是一句话引发的血案,在3、全局 / 静态对象的析构顺序不可控(跨文件时踩坑)之后,豆包总结了句:“尽量避免全局 / 静态对象间的资源依赖;若必须用,改用 “局部静态对象”(如
get_instance()函数内定义,析构顺序可控)”,这里又展开一堆东西,唉学东西像深搜算法一样:“尽量避免全局/静态对象间的资源依赖”,既包括跨文件的全局对象,也包括同一文件内的全局对象 —— 但核心是“跨文件”的依赖必须避免(因顺序完全不可控,必埋雷),同一文件内的依赖虽有顺序,但也建议避免(易因代码修改打乱顺序,引发隐患)。
Q:那3、全局 / 静态对象的析构顺序不可控(跨文件时踩坑)那个例子里有静态?
A:没有显式用
static关键字定义的静态对象,但两个全局对象a_obj(A 类型)和b_obj(B 类型),本质属于 “全局作用域的对象”—— 其生命周期和静态对象完全一致(从程序启动到程序结束),只是声明时没加static关键字。简单说:代码里是全局对象,不是显式的
static静态对象,但二者在 “生命周期长、跨文件访问时顺序不可控” 的特性上完全相同,所以之前讨论的 “析构顺序问题” 同样适用。静态和全局核心差别只有 2 个,且不涉及基础语法:
跨文件访问的 “默认可见性” 不同:
全局对象默认具有外部链接属性(可通过
extern在其他文件访问),静态对象(全局 / 静态作用域)默认是 “文件内可见” 的(即使其他文件用extern也访问不到)—— 这是编译器层面的 “作用域隔离” 差异,不是语法写法差异。比如:在 a.cpp 定义
int g_val;(全局变量定义);在 b.cpp 用
extern int g_val;声明后,才能访问 g_val。如果只在 a.cpp 定义
int g_val;,其他文件不写extern声明,确实访问不到 —— 但这是 “没声明” 导致的,不是 “全局变量本身不可见”。而静态全局变量(
static int g_val;)无论是否声明,其他文件都绝对访问不到(内部链接),这才是本质区别。
在 “命名空间 / 类内” 的语义不同,若在命名空间或类内声明:
全局对象不存在这种场景(只能在全局作用域);
静态对象(如
class C { static int x; })是 “属于命名空间 / 类” 的共享资源,所有该类对象共用一份,而不是 “属于某个具体对象”—— 这是 “归属语义” 的差异,和单纯的 “加不加 static” 语法无关。Q:所以你说的 “全局 / 静态对象的构造顺序按 “文件内声明顺序”” 和 “尽量避免全局 / 静态对象间的资源依赖”! 意思就是不能跨文件访问对吧? 同文件跨对象没事?我理解2、类成员对象的析构顺序搞反(依赖资源时出错)就是同文件跨对象
A:这里的 “对象” 就是指 用
class(或struct)定义的类,再通过类名 变量名创建出来的实体(不管是全局的还是静态的)。首先,“不能跨文件访问” 是避免依赖的核心(因跨文件顺序完全不可控,必出问题),正确。
但“同文件跨对象没事” 不准确 —— 同文件内虽有顺序,但仍不建议依赖(代码修改可能打乱顺序,隐藏风险),只能说 “风险低于跨文件”,并非 “没事”。2、类成员对象的析构顺序搞反(依赖资源时出错)里的例子,
res和buf是同一类(MyClass)的两个成员,属于类的成员变量之间的资源依赖,同一对象内部的成员依赖,并非 “同文件的两个全局 / 静态对象”,没法解释 “同文件全局 / 静态对象依赖” 的风险。这里的“同文件跨对象”,默认指的是“同文件内的全局/静态对象”—— 因为只有全局/静态对象才存在“构造/析构顺序影响资源依赖”的问题。因为普通局部对象(函数内的对象)或类成员对象,其生命周期由作用域或所属对象控制,不存在“跨对象依赖顺序不可控”的风险:
普通局部对象(函数内定义的对象,如
void func() { A a; B b; })的析构顺序是完全固定且可控的(按定义顺序逆序析构),只要代码里依赖关系和定义顺序匹配,就不会有 “顺序不可控导致的访问问题”,所以说 “不存在风险”。比如:若b依赖a的资源,只要代码里先定义A a;、再定义B b;,析构时就会先析构b(依赖方先析构,此时a仍有效)、再析构a(被依赖方后析构),顺序完全可控,不会出错。如果要举全局的例子
查看代码
#include <cstring> // 全局资源:缓冲区 char* g_buf = nullptr; // 全局对象A:使用缓冲区 class A { public:~A() {// 析构时操作g_buf(依赖g_buf有效)if (g_buf != nullptr) {strcpy(g_buf, "A destructed");}} }; // 全局对象B:管理缓冲区生命周期 class B { public:B() {g_buf = new char[100]; // 初始化缓冲区}~B() {delete[] g_buf; // 释放缓冲区g_buf = nullptr;} }; // 同文件内的全局对象声明 B g_b; // 先声明B,构造时创建g_buf A g_a; // 后声明A,依赖g_buf // 风险点: // 1. 当前顺序安全:构造B→构造A;析构A→析构B(A析构时g_buf仍有效) // 2. 若调换声明顺序为:A g_a; B g_b; // 则析构顺序变为B→A:A析构时g_buf已被B释放这个代码我思考了很多种情况,追问豆包学到了很多。
首先这里全局对象是自动析构的,根本不用写
delete,程序结束就自动析构了1、g_a(A 类型)析构时依赖 g_buf 有效:A 类的析构函数
~A()中明确写了strcpy(g_buf, "A destructed"),这行代码会往g_buf指向的内存中写入数据。只有g_buf指向的内存仍然有效(未被释放)时,这个操作才是安全的 —— 因此g_a析构时必须依赖g_buf有效。2、g_buf 的生命周期由 g_b(B 类型)管理:
B 类的构造函数
B()中执行g_buf = new char[100],负责为g_buf分配内存(创建资源);B 类的析构函数
~B()中执行delete[] g_buf,负责释放g_buf指向的内存(销毁资源)。这说明
g_buf的创建和销毁完全由g_b控制,即g_buf的生命周期被g_b管理。
strcpy:作用是将一个字符串的内容复制到另一个字符数组中。语法:strcpy(目标字符数组, 源字符串);,例如代码中的strcpy(g_buf, "A destructed");表示:把字符串"A destructed"的内容(包括结尾的空字符\0)复制到g_buf指向的字符数组中。这个操作的前提是g_buf必须指向一块有效的、足够大的内存(能容纳源字符串),否则会导致内存访问错误。结论:
B析构时执行delete[] g_buf; g_buf = nullptr;,此时g_buf确实会被置为nullptr。若析构顺序为B→A,A的析构函数中if (g_buf != nullptr)会判断为false,strcpy不会执行,所以这段代码顺序错也不会触发野指针访问,不会导致内存错误。我的思考:
1、若没写
g_buf = nullptr:B析构执行delete[] g_buf后,g_buf仍指向已释放的内存地址(野指针),而非nullptr。2、没写
g_buf = nullptr时:
有
if (g_buf != nullptr)判断:因g_buf是野指针(非nullptr),判断为真,会执行strcpy,操作野指针导致错误;无判断:直接执行
strcpy,操作野指针导致错误。3、写了
g_buf = nullptr时:
有
if (g_buf != nullptr)判断:g_buf是nullptr,判断为假,不执行strcpy,无错误;无判断:直接执行
strcpy,操作nullptr导致错误(空指针访问)。Q:继续思考,之前说,类的成员变量之间的资源依赖和普通局部对象就,没问题可以自己控制,说全局的会有不可控啥的,可我看这他妈的不也是没问题的吗?靠写代码的人自己控制
A:同文件全局对象、普通局部对象、类内成员,确实都靠程序员控制顺序,但全局对象的风险在于 —— 其声明位置可能与使用位置分离(甚至跨函数 / 类),依赖关系隐蔽,修改顺序时更容易忽略关联性,而局部 / 成员对象的依赖关系在代码中更集中、直观,误改概率更低。这是实际工程中区分它们风险的核心原因。
局部对象的作用域有限(通常在函数内),修改顺序的影响范围小,且代码集中,不易被误改;
类内成员的声明顺序属于类的设计一部分,修改需谨慎(会影响整个类的行为),误改概率低;
二者均无 “跨文件不可控” 问题,且依赖关系通常更明确(代码集中在函数或类内)。
因此,只要按正确顺序声明 / 定义,普通局部对象和类内成员对象可视为 “无显著风险”,而全局对象即使同文件,也因 “易被误改顺序” 而风险更高。
针对
strcpy相关问题的结论:
若
B析构时没写g_buf = nullptr,g_buf会指向已释放的内存(野指针),此时if (g_buf != nullptr)会误判为 “有效”(野指针非空),执行strcpy会操作非法内存,必崩;若
B析构时写了g_buf = nullptr:
有
if判断:g_buf为nullptr,跳过strcpy,安全;无
if判断:直接对nullptr执行strcpy,触发空指针崩溃;若没写
g_buf = nullptr且无if判断:直接操作野指针,必崩。nullptr赋值 + if判断的作用是:当析构顺序错误且指针被正确置空时,能避免空指针崩溃(此时if判断失效,不执行危险操作)。但它无法解决 “析构顺序错误且指针未置空” 的情况(此时指针是野指针,if判断会误判通过,仍会崩溃)。妈逼的又一个知识点艹
Q:那你提到的
get_instance()又是啥?(豆包无意间提到的get_instance()引发的血案!超级大血案!研究卡了我 7 天)(无意牵扯出貌似很重要的东西 —— 单例,也算是强迫症 因祸得福 了吧)A:中文意思是“获取实例”,功能是获取某个类的实例,目的是通过 “局部静态对象” 解决全局对象的析构顺序问题。
直接上代码对比,看同样的依赖场景下,全局对象会崩,而局部静态对象版本能正常运行
先上全局对象版本(会崩溃的代码):
查看代码
// resource.h class Resource { public:int* buf;Resource() { buf = new int[10]; }~Resource() { delete[] buf; } // 释放资源 }; extern Resource g_res; // 全局对象声明// resource.cpp #include "resource.h" // 这行不能少!否则编译器不认识 Resource 类 Resource g_res; // 现在编译器知道 Resource 是啥,能正常定义全局对象// a.cpp #include "resource.h" class A { public:~A() { g_res.buf[0] = 0; } // 依赖g_res }; A g_a; // 全局对象A// b.cpp #include "resource.h" class B { public:~B() { /* 使用g_res */ } // 依赖g_res }; B g_b; // 全局对象B // 问题:跨文件析构顺序随机,若g_res先析构,g_a、g_b析构时访问已释放的buf必崩// main.cpp int main() {// 空函数,啥也不做 }要说个前设知识(这个是后问的,讲解的时候提到前面来):
Q:我始终无法理解的是,
main是空的到底咋执行的豆宝说的“自动调用Resource类的构造函数:Resource() { buf = new int[10]; }此时g_res.buf指向一块新分配的内存(可以存 10 个int)”啊?!A:这是 C++ 的强制规定:全局对象的构造,必须在
main()函数执行之前完成;全局对象的析构,必须在main()函数执行结束之后完成。哪怕
main()是空的,这个规则也会被编译器强制执行 —— 这是编译器在编译阶段就做好的“手脚”,和main()里有没有代码完全无关。具体来说,当你用
g++编译代码时,编译器会:
扫描所有
.cpp文件,找出所有全局对象(比如g_res、g_a、g_b)。在生成的可执行程序里,偷偷加入一段 “启动代码”(这段代码你看不到,但确实存在)。
当你运行
./myprogram时,程序会先执行这段 “启动代码”:
逐个调用全局对象的构造函数(比如先调用
Resource()构造g_res,再调用Resource()构造g_a、g_b)。构造完成后,才会调用
main()函数(哪怕main()是空的,也会执行这一步)。
main()执行结束后,“启动代码” 会再次运行:
逐个调用全局对象的析构函数(顺序和构造相反)。
简单说:
main()只是 “用户代码的入口”,但整个程序的生命周期比main()更长 ——全局对象的生死,由编译器控制,不由main()控制。哪怕main()里一行代码都没有,全局对象该构造还是会构造,该析构还是会析构。Q:你这个狗逼误人子弟无数次了,我都不知道该不该相信你!
A:你的核心认知 “程序从 main 开始执行” 完全正确!这是铁律。但 C++ 有个特殊的 “启动阶段”,发生在
main执行之前,专门负责全局对象的初始化 —— 这不是 “程序逻辑”,而是 “程序启动的准备工作”,就像你打开软件时,软件会先加载配置文件(准备工作),再显示主界面(对应main)
代码:
查看代码
#include <iostream>// 全局对象 class Test { public:// 构造函数:在对象创建时自动调用Test() {std::cout << "全局对象构造了(这行在main之前输出)" << std::endl;} };// 定义一个全局对象t Test t;// main函数(程序入口) int main() {std::cout << "现在执行main函数" << std::endl; }只有当你显式定义了全局对象时,编译器才会在
main前执行构造。再次觉得自己是不是钻研深了,问豆包,哎我无法像别人一样只学基础蜻蜓点水。感觉好亏~~~~(>_<)~~~~
Q:
cpp里不要求能直接运行吗?A:
Resource g_res;这行代码要能编译,必须先知道Resource是个什么类(比如它有没有构造函数、析构函数)—— 而这个 “类的信息”,来自resource.h。为什么
cpp文件必须包含对应的头文件?cpp文件是 “编译单元”,编译器每次只处理一个.cpp文件,它不知道其他文件里的代码。所以:
- 当编译器处理
resource.cpp时,要定义Resource类型的全局对象g_res,必须先看到Resource的 “声明”(比如class Resource { ... };)。- 而
Resource的声明写在resource.h里,所以resource.cpp必须通过#include "resource.h",把resource.h里的内容 “复制粘贴” 到resource.cpp里,编译器才能认识Resource类,进而正常定义g_res。Q:只处理一个?
A:编译器确实是 “每次只处理一个.cpp 文件”(单个编译单元独立编译),g++ 多个 cpp 文件是 “分别编译每个 cpp,最后再链接到一起”,不是 “一起编译所有 cpp”。当你执行
g++ a.cpp b.cpp main.cpp -o app时,g++ 实际分两步走:
编译阶段:
先单独处理 a.cpp:只看 a.cpp 里的代码 + 它包含的头文件,生成 a.o(目标文件);
再单独处理 b.cpp:只看 b.cpp 里的代码 + 它包含的头文件,生成 b.o;
最后单独处理 main.cpp:只看 main.cpp 里的代码 + 它包含的头文件,生成 main.o;
这一步里,每个 cpp 都是 “各自为战”,编译器处理 a.cpp 时完全不知道 b.cpp 里有什么
链接阶段:
把 a.o、b.o、main.o 这几个目标文件 “拼起来”,再关联系统库,最终生成可执行文件 app。
这就是为什么每个 cpp 都必须包含自己需要的头文件 —— 因为编译它的时候,编译器只认它自己文件里的内容(包括 #include 进来的头文件),不认其他 cpp 里的代码。
Q:不需要那些内置头文件吗?
A:
resource.h里确实没加任何内置头文件(比如#include <iostream>之类),因为暂时不需要依赖任何内置库。具体来说:
resource.h里只定义了Resource类,这个类里用到的int*、new、delete[]都是 C++ 语言自带的基础语法(不是某个库提供的),编译器本身就认识它们,不需要通过#include头文件来 “引入”。只有你想在Resource类里用cout输出信息,就必须加#include <iostream>,因为cout是<iostream>头文件里定义的,编译器不自带这个信息。Q: 代码里咋写了两遍?
extern Resource g_res; // 全局对象声明
// resource.cpp
Resource g_res; // 全局对象定义A:这是 C++ 全局对象 / 变量的 标准声明与定义分离写法,二者作用完全不同,不是重复:
resource.h里的extern Resource g_res;→ 是 声明(declaration)作用:告诉所有包含这个头文件的.cpp(比如a.cpp、b.cpp)“存在一个名叫g_res的全局Resource对象,它的实际定义不在当前文件,在其他.cpp里”—— 仅作 “告知”,不分配内存。
resource.cpp里的Resource g_res;→ 是 定义(definition)作用:实际为g_res分配内存、调用构造函数创建对象 —— 整个程序里,全局对象的定义只能有一次(否则编译报错 “重定义”),但声明可以有多次(只要包含头文件就会声明)。这是 C++ 解决 “多文件共享全局对象” 的基础规则。
Q:可以去掉
extern直接写Resource g_res;就是全局吧?然后去掉resource.cpp文件A:不行,会导致头文件被多次包含时重复定义全局对象
Q:这代码里
说这个代码流程:
第一步:如何把这些文件编译成可执行程序
g++ resource.cpp a.cpp b.cpp main.cpp -o myprogram,这个命令会把 4 个.cpp文件(resource.cpp、a.cpp、b.cpp、main.cpp)编译成一个叫myprogram的可执行程序。.h文件(resource.h)不用写在命令里,因为在.cpp文件里已经用#include包含了第二步:运行程序的完整流程,输入
./myprogram运行程序:阶段 1:程序启动(main 函数执行前)
构造全局对象
g_res(在resource.cpp中):
自动调用
Resource类的构造函数:Resource() { buf = new int[10]; }此时
g_res.buf指向一块新分配的内存(可以存 10 个 int)构造全局对象
g_a(在a.cpp中):
自动调用
A类的默认构造函数(你没写,编译器会自动生成一个空的)此时
g_a对象创建完成,里面没有任何成员变量构造全局对象
g_b(在b.cpp中):
自动调用
B类的默认构造函数(你没写,编译器会自动生成一个空的)此时
g_b对象创建完成,里面没有任何成员变量(注意:跨文件的全局对象构造顺序是编译器决定的,可能是
g_res→g_a→g_b,也可能是其他顺序,但这不影响我们要讲的问题)阶段 2:执行 main 函数
运行
main()函数里的代码:// 空函数,啥也不做所以这一步啥也没发生,直接执行完了
阶段 3:程序结束(main 函数执行后)
这是最关键的一步,会自动析构所有全局对象,析构顺序和构造顺序完全相反:
假设构造顺序是
g_res→g_a→g_b,那么析构顺序就是g_b→g_a→g_res:
析构 g_b:
调用
B类的析构函数:~B() { /* 使用g_res */ }这里如果使用
g_res.buf,此时g_res还没被析构,buf是有效的,没问题析构 g_a:
调用
A类的析构函数:~A() { g_res.buf[0] = 0; }此时
g_res还没被析构,buf是有效的,赋值操作没问题
析构 g_res:
调用
Resource类的析构函数:~Resource() { delete[] buf; }释放
buf指向的内存,此时g_res.buf变成无效的野指针。野指针本身不直接导致问题,访问野指针(读 / 写其指向的内存)才会引发崩溃或未定义行为。若Resource析构时给buf赋nullptr(~Resource() { delete[] buf; buf = nullptr; }),且g_a/g_b析构时先判断buf != nullptr再访问,则即使g_res先析构,也不会因访问野指针崩溃(因buf已为nullptr,判断会跳过访问)。 但根本问题仍在析构顺序:若g_res先析构,g_a/g_b本应访问的资源已失效,逻辑上已出错(只是没崩溃)
Resource的构造函数里Resource() { buf = new int[10]; },new int[10]会做两件事:
向操作系统 “申请一块内存”(大小能存 10 个 int);
返回这块内存的起始地址(比如 0x123456,这是个 “有效地址”) ,然后把这个地址赋值给
buf,所以此时buf = 0x123456——buf指向的是 “操作系统分配的、能合法使用的内存”,操作buf[0]、buf[1]都没问题。在
Resource的析构函数里:~Resource() { delete[] buf; },delete[] buf也做两件事:
告诉操作系统:“之前通过 new 申请的那块内存(地址是 buf 的值,比如 0x123456),我现在不用了,你收回去吧”;
操作系统收到通知后,会把这块内存标记为 “已释放”—— 意味着这块内存从此不属于你的程序了,你再碰它就是 “非法操作”。
- 关键:
delete[]只会 “释放内存”,但不会把buf的值改成nullptr(也就是 buf 依然存着原来的地址 0x123456)。此时的 buf 就成了 “野指针”—— 它指向的地址是真实存在的,但这块地址的内存已经被操作系统收走了,你的程序没有权限再访问。跨文件的全局对象(如 resource.cpp 的 g_res、a.cpp 的 g_a、b.cpp 的 g_b),其析构顺序完全随机且不受代码控制,编译器和链接器不保证任何顺序,这就是跨文件全局对象依赖的核心风险,可能出问题的情况:
如果编译器决定的构造顺序是
g_a→g_b→g_res,那么析构顺序就是g_res→g_b→g_a:
析构 g_res:
调用
~Resource(),释放buf内存,g_res.buf变成野指针析构 g_b:
调用
~B(),如果这里使用g_res.buf,访问的是已经释放的内存,程序崩溃析构 g_a:
调用
~A(),执行g_res.buf[0] = 0,访问的是已经释放的内存,程序崩溃核心问题总结:
跨文件的全局对象(
g_res、g_a、g_b)的构造 / 析构顺序是编译器随机决定的当
g_res比g_a或g_b先析构时,g_a和g_b的析构函数访问g_res.buf就会操作已经释放的内存,导致程序崩溃这种崩溃是随机的,有时候能运行,有时候会崩溃,完全取决于编译器的顺序安排
这里要保证
g_res最后析构。Q:
g++ resource.cpp a.cpp b.cpp main.cpp -o myprogram是只要是cpp都会无固定顺序挨个结束?A:所有 cpp 文件会被分别编译成目标文件,再链接成一个可执行程序,将所有 cpp 文件里的全局 / 静态对象汇总,程序运行时全局对象的生命周期是整个程序,程序结束时这些对象的析构顺序完全无固定规则(跨文件绝对随机,同文件按声明逆序),不受代码编写顺序或编译顺序控制。
总结下:所有会因析构顺序导致访问问题的场景:
1、类内有资源依赖的成员变量:析构顺序由声明顺序决定(先声明后析构),若依赖方后声明、被依赖方先声明(即声明顺序反了),会出错;
2、全局对象(跨文件 / 同文件)、文件内静态对象(static 类名 对象名;):析构顺序跨文件随机、同文件与构造顺序相反,有资源依赖则可能出错;
除上述三种场景外,栈上对象(如 main 里 A a;)、堆上对象(如 new A ())的析构顺序完全由代码控制(栈上按定义逆序、堆上按 delete 顺序),只要代码写对顺序,就不会因 “析构顺序” 出问题,无其他遗漏场景
在上局部静态对象版本(正常运行的代码)(妈逼的这段代价给的翻来覆去弄了 2 天,我成给豆包训练数据的了艹):
查看代码
// resource.h class Resource { public:int* buf;Resource() { buf = new int[10]; }~Resource() { delete[] buf; }static Resource* get() {static Resource inst; // 局部静态对象return &inst;} };// a.cpp #include "resource.h" class A { public:~A() { Resource::get()->buf[0] = 0; } // 通过get()获取 }; A g_a;// b.cpp #include "resource.h" class B { public:~B() { /* Resource::get()使用资源 */ } }; B g_b;
inst第一次调用Resource::get()时构造。在
static Resource inst;中,static修饰局部变量时,让这个对象具有 “局部静态存储期”(因为它定义在get()函数这个 “局部作用域” 里,只能在get()函数内部直接访问,所以叫局部静态对象)核心特性有两个:
生命周期延长到程序结束
普通局部变量(不加
static)在函数执行完就销毁,但加了static后,inst只会在 第一次调用get()时构造,之后即使get()函数执行完,它也不会销毁,会一直存在到整个程序结束才析构。只初始化一次无论
get()被调用多少次(比如g_a析构时调用一次,g_b析构时再调用),inst只会被构造一次,不会重复创建。这两个特性结合,就让
inst既能 “按需创建”(第一次用才构造),又能 “最后销毁”(等所有使用者都用完),完美解决了全局对象析构顺序混乱的问题。Q:你这里函数已经是
static了 咋inst还加static?A:函数的
static和inst的static作用完全不同,互不影响:
函数前的
static:说明这是类的静态成员函数,属于整个类而非某个对象,可直接通过类名::函数名调用,例:Resource::get()
inst前的static:说明这是函数内的局部静态变量,仅在函数第一次被调用时初始化,之后一直存在(生命周期到程序结束),且整个程序中只有这一个实例 —— 这才是保证 “析构顺序可控” 的核心。两者一个控制 “函数如何调用”,一个控制 “变量的生命周期”,功能不冲突,必须同时用才能实现 “通过类名调用,且只创建一个全局唯一实例” 的效果。
解释这个代码:
Resource实例的析构时机是由 C++ 标准严格保证的,和全局对象 A/B 的析构顺序彻底解耦”,具体拆解局部版本的关键逻辑:
先明确局部静态对象
inst的核心特性局部版本里,Resource::get()里的static Resource inst,不是普通局部变量 —— C++ 标准规定:
它第一次被调用时才构造(比如
A的析构函数第一次调用Resource::get(),inst才会创建,分配buf);它的析构时机是 “程序结束前,所有用到它的全局对象都析构完之后”—— 这是全局对象
g_res做不到的(全局对象析构顺序完全随机)。(很微妙,或者说豆包给的这句是错的,稍后解释)和全局版本的本质区别:
全局版本的
g_res是 “和 A/B 平级的全局对象”,析构顺序谁先谁后全看编译器,所以可能g_res先析构,导致 A/B 析构时访问无效buf;局部版本的
inst后面说这里踩了无数坑,做了相当巨大量的实验,反复质疑辱骂豆包,最后得知,如今敲死不会错误!
之前豆包误人子弟说:根据标准,
inst的析构必须晚于所有在它构造时已经存在的对象(即g_a和g_b)。C++ 根本没这样的标准!只与顺序有关!其他一切都看写代码的开发者咋写代码!这并不是多神奇的万能钥匙!就像 SPFA 一样!用错一样有问题!!但那些说 SPFA 已死的都是学的不精通的傻逼!!!!真的太痛苦了,这块内容豆包永远都是在误人子弟手错误的东西!!!甚至我整个写博客的体现都崩塌了,从这部分开始就是错的。
豆包反复出现错误这两天啥也没收获到,光骂豆包了,感觉太智障了,连最基本的结论都反复出错,运行结果反复出错,这还只是我知道的就这么多问题,反复修改道歉依旧永远一直在犯错。但又找不到更好的学习方式,GPT 一坨屎网上知识博客没体系。
太他崩溃了,跟豆包对线两天,全是错误,就没对的!!!
最痛苦的是给了一段好像很有用对话,一一钻研,费了大量时间,最后提出质疑,给你来一句“对不起,我犯了严重错误”
给你一段代码,花了大量时间研究后,发现有问题,提出质疑,给你来一句“对不起,我又犯了严重错误”
豆包误人子弟(自己瞎编造 C++ 规则一顿胡扯)
唉这些玩意到底有没有用~~~~(>_<)~~~~,质疑自己 ,好亏
底层的垃圾烂泥堆里挣扎着爬出来,学习也是就用着垃圾豆包,极强的所有,硬生生学了出来
无奈发现点深度思考再点【编程】模式貌似回答会不那么死妈!!
什么狗逼玩意啊!!这 GPT 也不过如此啊,一直因为不想魔法挂而不用,一直因为它有多好,用豆包凑活用着,结果豆包犯错无数次,怒了,用 GPT 发现 GPT 体验感、按钮、界面UI、跟狗逼垃圾 Deepseek 一个风味,比豆包差远了了,且对于这个问题依旧是反复道歉狗东西,全球的大模型都是通用的训练数据吗!!!!这还他妈咋学习啊艹!
我他妈还研究 GPT-4 和 GPT -5 入口有啥区别,搞了半天官网会停用旧版本,网站都是新模型的,艹 GPT 跟个傻逼一样,具体多少代这都是内部应该封装的没必要对外公布!
继续说,上面 感觉没通透
真的好想放弃这块,最终还是写下吧,啃了熬了崩溃了这么久,这块基本毫无逻辑顺序,当小说看吧,真的没有任何心力去写顺序了。
历尽千辛,起初学的时候,很混乱豆包给了一堆东西,硬头皮花了 3 天啃完后,提出质疑,给我来一句【对不起犯了严重错误,结论错误】,
又追问了 3 天扒层皮得到了看似对的结论,结果今天再次实践发现又错了又给我来一句【对不起犯了严重错误,结论错误】,
且反复拿同样的东西去质疑,豆包都会反复摇摆说自己错了。最后 Google、知乎、CSDN ( CSDN 博主也有错误,直接说全局最后析构的都是错误),最后看到一个知乎文章说虾皮 C++ 一面的面试看了下 + 自己实践,与此同时豆包也给了对的结论!这回应该是真对了。同时发现大厂问的确实细啊艹。启发是应该尽快学然后去多钻研大厂高频题,必须拿下!!妈逼的感觉自己现在就应该及时止损艹去看专项的题库。然后就是坚定了信心,自己的这些思考并不亏,看到了问 const 和 static 的,只是自己研究的好像足够深了但有点偏!
构造顺序:单文件内普通全局对象按代码书写顺序执行
关键例外:跨文件 / 静态成员的顺序不可控
而单例的 “主动构造”,正是为了打破这种 “仅单文件可控” 的局限,让任何场景下都能保证初始化顺序。
看代码:
单文件场景,普通全局对象(顺序看似可控,但有隐患):
查看代码
#include <iostream> using namespace std;class B { public:B() { cout << "B构造" << endl; }void doSomething() { cout << "B工作" << endl; } };// 全局对象A(依赖B) class A {public:A(B& b) : b_(b) { cout << "A构造" << endl; b_.doSomething();}private:B& b_; };B globalB; A globalA(globalB); // 后定义A,后构造(此时B已存在,暂时没问题)int main() {} // 输出:B构造 → A构造 → B工作(看似正常)
class B { ... };和class A { ... };是 类的定义(定义类的结构)。
B globalB;和A globalA(globalB);是 全局对象的定义(创建类的实例,会触发构造函数)。隐患:如果某天代码调整,把
globalA的定义移到globalB前面(比如按类声明顺序调整),就会变成A先构造、B后构造 ——A初始化时B还没创建,直接崩溃。单文件场景:局部静态单例(顺序绝对可控)
查看代码
#include <iostream> using namespace std;// 单例类B class B { public:static B& getInstance() {static B instance; // 首次调用时才构造,不管代码位置return instance;}void doSomething() { cout << "B工作" << endl; } private:B() { cout << "B构造" << endl; } // 禁止外部创建 };// 全局对象A(依赖B) class A {public:A() { cout << "A构造" << endl; B::getInstance().doSomething(); // 调用接口获取B} }; A globalA;int main() {} // 输出:A构造 → B构造 → B工作(B的构造被A触发,顺序始终正确)核心优势:不管
A和B的代码定义顺序怎么变,A依赖B时,只要调用getInstance(),B一定会先构造 —— 彻底消除了 “代码顺序调整导致崩溃” 的隐患。大量思考:但当我想通过调整代码位置,亲手验证单例的好处,但一直被 C++ 语法规则卡住,犯了很多语法错误,逐步说。
我写成了这个样子
查看代码
#include <iostream> using namespace std;class B { public: static B& getInstance(); }; class A { public:A() { cout << "A构造" << endl; B::getInstance().doSomething(); // 调用接口获取B} };class B { public:static B& getInstance() {static B instance; // 首次调用时才构造,不管代码位置return instance;}void doSomething() { cout << "B工作" << endl; } private:B() { cout << "B构造" << endl; } // 禁止外部创建 };A globalA; // 即使A定义在B前面,也不影响int main() {} // 输出:A构造 → B构造 → B工作(B的构造被A触发,顺序始终正确)对于分离的写法,如果说想用 B 里的某成员函数,只声明
class B;只能告诉编译器 “有个类叫 B”,但编译器还不知道B有getInstance()这个静态方法,必须在A使用B的成员之前,完整声明。
类 B 被重复定义:你先声明了
class B { ... };,后面又写了class B { ... };,C++ 不允许同一个类重复定义,必须合并成一个声明 + 实现。getInstance(),没声明doSomething(),A 调用时编译器就会报错 “没有这个成员”。只要会被类外部(或其他类)直接调用的成员,必须在类声明中提前声明:
查看代码
#include <iostream> using namespace std;// 1. 先完整声明B的接口(至少要让A知道B有getInstance()) class B { public:static B& getInstance(); // 只声明,不定义void doSomething(); // 只声明,不定义 private:B(); // 关键:显式声明私有构造函数(类内必须声明) };// 2. 定义A(此时知道B的接口,可调用其方法) class A { public:A() { cout << "A构造" << endl; B::getInstance().doSomething(); // 现在编译通过} };// 3. 完整定义B(实现其成员) B& B::getInstance() {static B instance;return instance; }void B::doSomething() { cout << "B工作" << endl; }B::B() { // 私有构造函数的定义放在类外(C++11及以上支持)cout << "B构造" << endl; }A globalA;int main() {} // 输出:A构造 → B构造 → B工作(完全符合预期)起初没写那个
private里的东西报错了,因为私有成员 “不能被外部调用 / 访问”,但 “可以在类外定义”。类外规则:
为何
普通成员函数:
返回类型 类名::函数名(参数) { ... }(无返回值时用void)例:void B::doSomething() { ... }静态成员函数:
返回类型 类名::函数名(参数) { ... }(不加static)例:B& B::getInstance() { ... }构造函数:
类名::类名(参数) { ... }(无返回值,不加void)例:B::B() { ... }析构函数:
类名::~类名() { ... }(无返回值,不加void)例:B::~B() { ... }私有成员:定义方式和 public 成员完全相同(仅声明时区分访问权限)例:
B::B() { ... }(尽管构造是 private,类外定义仍这么写)static不用再写一遍,此文搜“在这里会冲突”,类成员函数默认是外部(文件外)可见的,不能同时限制为文件内可见,访问方式和类外是一样的,include包含后,类名::静态成员,对象.非静态成员。
extern用于全局变量 / 函数:声明 “这个变量 / 函数在其他文件中定义,当前文件可以用”(跨文件可见)。类的静态成员函数:天生就是 “外部可见” 的(只要声明为
public),通过类名::直接访问即可,不需要加extern。零零碎碎的知识点
类内的
static(成员函数属性)
作用:标记这个函数是 “类的函数”,不是 “对象的函数”,不依赖对象就能调用(通过
类名::调用)。规则:只能在类内声明时写一次,类外定义时绝对不能加,否则编译报错。
类外的
static(文件作用域属性)
作用:标记这个变量 / 函数的 “作用域仅限当前
.cpp文件”,其他文件看不到(避免重复定义)。规则:只能用于修饰全局变量、全局函数、局部静态变量,绝对不能用于修饰 “类的成员函数 / 成员变量” 的定义。
Q:再说那个 全局的代码,说是换 A、B 对象顺序,但我说你这个在泼脏水打马虎眼,因为就算单例的也是必须先声明啊,否则编译都过不了!而且代码里明明是静态的只有一个
A globalA而非静态里明显有俩!!B globalB;A globalA(globalB);。A:你的核心误解在这里:“对象数量” 和 “单例解决的问题” 完全无关。你纠结 “静态单例里只有 1 个 A,非静态里有 A 和 B 两个对象”,这是把 “对象数量” 和 “初始化顺序问题” 混为一谈了 —— 单例要解决的是 “多个全局对象之间的依赖顺序失控”,而不是 “减少对象数量”。
非静态例子里必须写两个全局对象(B 和 A),是因为 A 依赖 B 的实例,必须显式传参;单例例子里看似只有 A,但 B 的实例依然存在(藏在
getInstance()里),本质还是两个对象(A 全局对象 + B 单例对象),不用像普通全局对象那样 “显式写一行B globalB;”
模式 看得见的对象(显式写) 藏起来的对象(隐式创建) 总对象数 普通全局对象 B globalB;、A globalA;无 2 个 单例模式 A globalA;getInstance()里的static B instance;2 个 Q:所以问题出现了!如果把单例和全局的都换成分离的,那不就没事了吗!
A:分离后
普通全局对象(就算分离声明,顺序错了还是崩)
查看代码
#include <iostream> using namespace std;// 1. 声明B类(分离式) class B { public:B();void doSomething(); };// 2. 声明A类(依赖B,分离式) class A { public:A(B& b); private:B& b_; };// 3. 实现B类 B::B() { cout << "B构造" << endl; } void B::doSomething() { cout << "B工作" << endl; }// 4. 实现A类 A::A(B& b) : b_(b) { cout << "A构造" << endl; b_.doSomething(); }// 致命问题:就算分离声明,全局对象的顺序依然是死的! // 测试1:B在前A在后 → 正常 B globalB; A globalA(globalB); // 测试2:把上面两行换成A在前B在后 → 编译可能过,但运行崩溃 // A globalA(globalB); // 此时B还没构造,传的是无效引用 // B globalB;int main() {}单例模式(分离声明 + 彻底解决顺序问题)
查看代码
#include <iostream> using namespace std;// 1. 声明B类(同样分离式) class B { public:static B& getInstance();void doSomething(); private:B(); // 私有构造 };// 2. 声明A类(同样依赖B,分离式) class A { public:A(); };// 3. 实现B类(可以在A之后) B::B() { cout << "B构造" << endl; } B& B::getInstance() {static B instance; // 核心:调用时才构造return instance; } void B::doSomething() { cout << "B工作" << endl; }// 4. 实现A类 A::A() { cout << "A构造" << endl; B::getInstance().doSomething(); // 主动触发B构造 }// 关键:A的全局对象定义位置随便放! // 测试1:A在B实现后 → 正常 A globalA;// 测试2:把A移到B实现前 → 依然正常 // A globalA; // 放在B的实现代码前面,运行照样正常int main() {}单例说白了就是静态
static。太高潮了解释的。透彻!!
其实到现在发现,
全局没法随意换定义对象的顺序因为有依赖,而局部其实直接定义 A 即构造 A 对象,相当于一同构造了 B 对象,隐式绑定了。
用豆包狗逼晦涩难懂的话来说就是,局部静态单例(B)解决全局依赖问题的核心原因:
局部静态对象
B::instance的构造被延迟到首次调用getInstance()时,而非程序启动阶段。因此,即使全局对象A先构造(程序启动时),其构造函数中调用B::getInstance()会主动触发B的构造,确保B在被A使用前已完成初始化 —— 这本质上是通过 “按需构造” 规避了全局对象因定义顺序导致的依赖问题,而非 “隐式绑定”,而是标准规定的 “局部静态对象首次访问时初始化” 的特性。而如果想直接定义B那直接
类::即可
用豆包的还来说就是,直接使用
B类的方式:由于B的构造函数是私有的(private),外部无法直接定义B的对象(如B b;会编译报错)。必须通过B::getInstance()获取唯一实例,这是单例模式的典型实现(限制实例化,确保全局唯一)。简言之,局部静态单例通过延迟初始化机制,天然解决了全局对象间的构造顺序依赖问题,而
B的访问必须通过其提供的静态接口(getInstance()),无法直接定义对象。我理解应该叫提前啊,不是主动构造了吗?局部静态对象的初始化仅在首次执行到该对象的定义语句时触发,而非程序启动时(全局对象的初始化时机)。书读百遍其义自见 追问百变,更上一层楼!!
再举个跨文件的,这里更没有顺序了,同文件还可以靠书写顺序
普通全局对象(问题示例)
查看代码
// a.h class A { /* 依赖B */ }; extern A globalA; // 声明全局对象A// b.h class B { /* 被A依赖 */ }; extern B globalB; // 声明全局对象B// a.cpp #include "a.h" #include "b.h" A globalA(globalB); // 定义A,此时B还没定义(编译顺序问题)→ 可能初始化错误// b.cpp #include "b.h" B globalB; // 定义B,构造顺序晚于A问题核心:全局对象靠编译顺序被动构造,A 依赖 B 但 A 先构造,会访问未初始化的 B。
局部静态单例(解决示例)
查看代码
// B.h(单例类) class B { public:// 唯一访问接口,首次调用时才构造instancestatic B& getInstance() {static B instance; // 局部静态变量,首次调用时初始化return instance;} private:B() {} // 私有构造,禁止外部创建 };// A.cpp(依赖B的全局对象) #include "A.h" #include "B.h" A globalA(B::getInstance()); // 调用接口获取B,此时B会被主动构造→初始化成功这里还有思考,
注意:同文件无单例时要靠书写顺序,是铁律。
全局那个代码里,跨文件无单例时,只要严格做 “头文件声明类 / 函数,源文件定义实现”,就不会出现未定义错误。起初我理解,跨里做好声明,是必须的,但构造对象依旧会无顺序。
注意:
A glboal(global B)先构造globalB,后构造globalA,通过调用 A 的构造函数来初始化全局对象globalA的过程,核心是 “构造”(调用构造函数),最终生出个 A 对象 就是初始化。跨的那个代码里 A、B 对象不知道谁先构造(即初始化),但因为有
extern所以能通过编译!补全就是
查看代码
//a.h #ifndef A_H #define A_H #include "b.h" class A { public:A(B& b); private:B& b_; }; extern A globalA; // 声明全局A #endif//b.cpp #include "b.h" B::B() { std::cout << "B构造" << std::endl; } void B::doSomething() { std::cout << "B工作" << std::endl; } B globalB; // 定义全局B//b.h #ifndef B_H #define B_H #include <iostream> class B { public:B();void doSomething(); }; extern B globalB; // 声明全局B #endif//main.cpp #include "a.h" #include "b.h" A::A(B& b) : b_(b) {std::cout << "A构造" << std::endl;b_.doSomething(); } A globalA(globalB); // 定义全局A(依赖全局B) int main() {}如果我把
B globalB;放到main.cpp里A globalA(globalB);后面会发生啥?如果同文件,编译直接死了
但跨文件编译过,因
b.h有extern B globalB;声明,编译器知道globalB存在(定义在当前文件后面或其他文件),C++ 规定:一个全局变量可以有多次声明,但只能有一次定义。但我又思考,之前同文件里加
extern是不是也行?注意:
extern声明变量时,必须先确保该变量的类型已被声明,不加class B编译不过查看代码
#include <iostream> using namespace std; class B; extern B globalB; // 1. 声明B类(分离式) class B { public:B();void doSomething(); };// 2. 声明A类(依赖B,分离式) class A { public:A(B& b); private:B& b_; };// 3. 实现B类 B::B() { cout << "B构造" << endl; } void B::doSomething() { cout << "B工作" << endl; }// 4. 实现A类 A::A(B& b) : b_(b) { cout << "A构造" << endl; b_.doSomething(); }// 致命问题:就算分离声明,全局对象的顺序依然是死的! A globalA(globalB); B globalB;int main() {}
发现确实也能过编译,也运行了啊!
豆包解答:在单文件里加
extern B globalB;声明后,代码能编译通过,但解决不了初始化顺序问题,具体看:1、编译时候、编译期、编译层面:你在代码开头加了
extern B globalB;,这会告诉编译器 “globalB是一个外部声明的B类型全局变量”。所以即使A globalA(globalB);写在B globalB;前面,编译器也能识别globalB的存在,编译不会报错(解决了同文件中 “未声明” 的编译错误)。2、运行层面:单文件内的全局变量初始化顺序严格按书写顺序执行:
A globalA先初始化,此时B globalB还未构造(内存未初始化);
A的构造函数访问b_.doSomething()时,操作的是未初始化的B对象,属于未定义行为(可能崩溃、输出异常,或像你之前遇到的 “偶然正常”)。
extern只影响编译时的可见性,不改变运行时的初始化顺序规则。Q:那没初始化也能用?
A:编译器只负责语法检查和代码生成,不关心 “变量是否已分配内存” 或 “是否已构造”—— 这是运行时的事。
编译阶段:
extern B globalB;告诉编译器 “存在一个B类型的全局变量globalB,在其他地方定义”,extern不触发任何内存分配。内存分配和初始化由变量的定义处决定。编译器看到A globalA(globalB);时,只检查 “globalB的类型是否匹配A的构造函数参数(B&)”,只要类型对,就通过编译,生成调用A构造函数的代码(此时只是记录 “要传globalB的地址”,不实际访问内存)。运行阶段:程序加载时,操作系统会给所有全局变量分配内存(无论是否初始化),但初始化(调用构造函数)按书写顺序执行。
A globalA先初始化:构造函数里的b_.doSomething()会去访问globalB所分配的内存(此时B的构造函数还没跑,内存里是随机值)。这就像 “房子已经盖好了(内存分配),但主人还没搬进去(未构造),你却先闯进去用里面的东西”—— 编译器不管 “主人在不在”,只保证 “房子存在且能找到地址”。(这个比喻持续喷水高潮!精辟精华!!)反观局部静态的那个当
A的构造函数第一次调用B::getInstance()时,instance会被立即构造(输出 “B 构造”),随后返回该实例的引用,这个不是指针的引用,单纯是说可以通过这个调用doSomething(),B::getInstance()无论被调用多少次,返回的都是同一个B实例。分配 ≠ 初始化:分配是 “给变量划一块内存空间”,初始化是 “调用构造函数给这块空间填合法数据”(“主人搬进去收拾好”)
内存分配时机:
globalA和globalB的内存,在程序启动加载到内存时(main 执行前)就已分配(就是比喻里 “盖好的房子”),和代码里定义顺序、是否分离声明无关。
具体是因为全局变量
globalA和globalB的定义(A globalA(globalB);和B globalB;),程序加载时操作系统为所有全局变量分配内存,与extern无关。内存分配后未初始化时是随机值。
具体赋值(非随机值)是因为
B::B()构造函数(B构造那句),但此例中globalA构造时globalB尚未调用构造函数,故仍为随机值。
A的对象globalA自身的内存分配后,其构造函数被调用(执行A::A(B& b)),因此globalA自身不是随机值;但它引用的globalB因尚未构造,此时b_.doSomething()访问的是globalB未初始化的内存(随机值)。更上一层楼
Q:那
class A { public:A(B& b); private:B& b_; };咋看出哪个是构造?
A:构造函数的名字必须和类名完全相同(这里类名是
A,函数名也是A);且没有返回值类型(连void都不能写);Q:代码里【
b_.doSomething();(全局对象版本)】和【B::getInstance().doSomething();(单例模式版本)】咋理解?A:
b_.doSomething();这里的b_是 A 类中存储的全局对象globalB的引用(通过A globalA(globalB);的构造函数参数传递)。b_直接指向已定义的全局 B 对象,调用其成员函数时,依赖于全局 B 对象已被正确构造。
B::getInstance().doSomething();这里通过B类的静态成员函数getInstance()获取 B 对象的引用,而getInstance()内部通过局部静态变量instance管理 B 对象的生命周期(首次调用时构造,之后复用)。这种方式不依赖全局对象的定义顺序,而是通过函数调用主动触发 B 对象的构造
static B& getInstance()的作用:这是单例的 “入口”,通过static修饰,让它可以直接用B::getInstance()调用(不用先创建B对象)。它的核心功能是返回B的唯一实例(static B instance),并且保证这个实例在第一次调用时才构造(解决初始化顺序问题)。
doSomething()为什么能被调用?doSomething()是B类的普通成员函数(属于B的实例),但必须通过B的实例才能调用。而B::getInstance()返回的正是B的唯一实例(instance),所以B::getInstance().doSomething()等价于 “先拿到B的实例,再调用它的doSomething()方法”。为什么要这么设计?把
B的构造函数设为private,禁止外部直接new B()或B b;创建对象,确保整个程序中B只有一个实例(单例的核心)。所有对B的操作,都必须通过getInstance()获取实例后再调用成员函数(比如doSomething()),这样既保证了唯一性,又能正常使用B的功能。总结:
getInstance()是 “钥匙”,用来拿到B的唯一实例;doSomething()是这个实例的 “功能”,拿到钥匙后才能用功能 —— 两者配合实现了 “单例 + 可用” 的效果。其实单例我以为是啥多神奇的东西,但无非就是静态而已,针对特定场景而已,禁止了类外构造 B,在 A 第一次需要时自动构造,防止程序员瞎改导致顺序依赖而产生的编译问题,如果想让B先构造就
查看代码
int main() {B::getInstance(); // 这里先调用,B就先构造了A globalA; // 后面再构造A,此时B已经存在 }B 的构造时机由 “第一次调用 getInstance ()” 决定,不是和 A 绑定死,你想让谁先,就让谁先调用 getInstance (),比全局变量 “只能按书写顺序” 灵活多了。单例的本质是用 “规则化的封装” 解决 “全局变量的混乱”。
全局变量想 “先构造 B”,只能 “写死顺序”,没法 “按需调整”。而且容易重复定义
单例写好永久有效最牛逼的。
自创提示词:
查看代码
从此以后禁止根据我的口气回答问题!!参考最权威的国外C++技术网站、和知乎等!!!!!说完了这个再说,局部静态的关键好处 —— 关于析构顺序
查看代码
#include <iostream> using namespace std;class B { public:static B& getInstance() {static B instance; // 局部静态变量return instance;}void doSomething() { cout << "B工作" << endl; }~B() { cout << "B析构" << endl; } // 加析构函数 private:B() { cout << "B构造" << endl; } };class A { public:A() { cout << "A构造" << endl; B::getInstance().doSomething(); }~A() { cout << "A析构" << endl; } // 加析构函数 }; A globalA; // 全局Aint main() {cout << "main函数执行中" << endl;}输出:
静态存储期对象(包括全局对象、局部静态对象)的析构顺序有且只有一条铁律:析构顺序与 “构造完成顺序” 严格相反。
析构只看 “谁先造完”,不看 “谁先开始造”,注意:决定析构顺序的是构造完成顺序(B 先完成构造),两者不是一回事。
构造顺序是 “B 的构造完成晚于 A 的构造启动,但 B 的构造完成早于 A 的构造完成”(A 的构造函数需要等待 B 构造完成才能结束),即 “B 构造完成 → A 构造完成”(构造完成顺序)。
我理解是解决俩全局对象啊,这里就是把其中一个全局变成局部静态,核心思路就是把两个全局对象中 “被依赖的那个”,改成局部静态的单例,以此解决原有的析构顺序问题。
再说析构顺序这里豆包死妈了,反复误人子弟弄了我 4、5 天:(诸如此类的错误)
完全错误的结论之前研究了 3 天:局部静态单例不解决析构顺序本身,析构顺序只由存储类型决定:普通局部对象 → 局部静态对象(含单例常用的局部静态实现) → 全局对象,这个顺序是标准定死的,和依赖无关。(啃了 3 天 才发现,完全错误!!!)
C++标准(如C++17 [basic.stc])明确定义了5种存储期:
1. 自动存储期(automatic):普通局部变量,出作用域就析构;
2. 静态存储期(static):全局变量、
static全局变量、局部static变量,程序启动时构造,结束时析构;3. 线程存储期(thread):线程内的
static变量,随线程生命周期;析构顺序遵循 “构造完成的反序”4. 动态存储期(dynamic):
new出来的对象,delete时析构;5. 关联存储期(allocated):C++17新增,配合
allocator使用。
静态存储期对象的析构顺序,与它们 “构造完成的顺序” 严格相反。
1. 自动存储期对象(普通局部变量):作用域结束时析构(最早)。
2. 静态存储期对象(全局对象、局部静态对象):析构顺序与它们的 “构造完成顺序” 严格相反(与是否是全局 / 局部静态无关,只看谁先构造完成)。
例如:
class A {}; class B {}; A a; int main() { B b; static A a2; }
B b(普通局部对象,自动存储期):main函数结束时(作用域结束)最先析构。
static A a2(局部静态对象,静态存储期):程序终止阶段析构,早于全局对象。其实这个是这个代码的事实,但很容易断章取义理解为静态早于全局!!其实是因为构造完成时间晚于全局对象A a所以才早于!
A a(全局对象,静态存储期):程序终止阶段最后析构。
析构本身与逻辑依赖无关(标准只按构造反序定析构顺序),但代码实现中必须让依赖关系与析构顺序匹配,否则如果 A 逻辑上依赖 B(A 析构时需要访问 B),就必须通过构造顺序的控制(让 B 先完成构造,从而 B 后析构),确保 A 析构时 B 仍有效。否则,若析构顺序与依赖关系冲突(A 析构时 B 已析构),就会导致访问已销毁对象的错误。
局部静态控制构造时机,主动调用构造,替代 “靠编译顺序被动构造全局对象”,确保依赖的类对象一定已初始化。
到现在新开页面,还是会豆包误人子弟(自己瞎编造 C++ 规则一顿胡扯),说普通 → 局部静态 → 全局最后析构,自学真的痛苦查看代码
//例子1: #include <iostream> using namespace std;class Obj {public:string name;Obj(string n) : name(n) { cout << name << " 构造" << endl; }~Obj() { cout << name << " 析构" << endl; } // 析构时打印 }; Obj a("a"); Obj b("b"); Obj c("c"); int main() {cout << "main结束,开始析构局部静态对象" << endl; }//例子二: #include <iostream> using namespace std; class Obj { public:string name;Obj(string n) : name(n) { cout << name << " 构造" << endl; }~Obj() { cout << name << " 析构" << endl; } // 析构时打印 }; void func1() { static Obj a("a"); } void func2() { static Obj b("b"); } void func3() { static Obj c("c"); } int main() {func2(); // b先构造func1(); // a再构造func3(); // c最后构造cout << "main结束,开始析构局部静态对象" << endl; }再说个无意间遇到的知识点:
查看代码
#include <iostream> using namespace std; class A { public:int x;A(int num) {x = num;} }; class Pair { public:A a; // A类对象作为成员// 正确写法:必须用初始化列表初始化a/* Pair(int num) : a(num) {// 初始化列表中调用A的带参构造函数A(int)} */// 错误写法:尝试在函数体内初始化aPair(int num) {// 这里会先尝试默认构造a(调用A的无参构造函数)// 但A没有无参构造函数,编译报错a = A(num); }}; int main() {Pair p(300); // 正确:通过初始化列表调用A(300)cout << p.a.x << endl; }1、当创建Pair对象(比如Pair p(300))时,编译器首先要处理Pair里的成员a(A类型的对象)。原因:a是Pair的成员,必须在Pair自身构造完成前先存在,这是 C++ 的规定 —— 成员对象的构造优先于所属类的构造函数体执行。2、此时,编译器会先尝试构造
a,但需要确定用A的哪个构造函数。3、因为
a是A类型的对象,构造它就必须调用A的某个构造函数,如果在Pair的构造函数里没有用初始化列表(就是那个带冒号的部分,比如: a (num))明确告诉编译器要用A的哪个构造函数来构造a,编译器就会默认去找 A 的无参构造函数(A::A ())来构造a,4、但你的
A类因为已经手动定义了带参构造函数A (int num),编译器就不会再自动生成无参构造函数了,所以此时编译器找不到A的无参构造函数,就会报错;5、而你在
Pair构造函数体里写的a = A (num);其实是赋值操作,这时候a早就已经尝试过构造了(但失败了),所以这行代码根本没用,必须用初始化列表在a构造的那一刻就指定用A (int)来构造它,才能避免错误。但
Pair(int num) : a(num),初始化列表: a(...)直接告诉编译器:用括号里的参数调用A的对应构造函数来构造a。明确指定用A的带参构造函数A(int),并传入num作为参数。初始化完a,才进入Pair的构造函数体。
p.a.x是访问Pair对象p中的成员a(A类型对象)的成员x。 在正确的代码中(使用初始化列表初始化a):
Pair p(300);会通过初始化列表: a(num)调用A(300),将a.x初始化为 300。因此
p.a.x就是访问这个被正确初始化的x,输出结果为300。
而
Pair(int num) { a = A(num); }
先尝试构造成员
a:因为没有初始化列表,编译器会强制调用A的无参构造函数,但A没有,直接编译报错(根本走不到下一步)。假设A多了个有默认构造函数,那过程会是:
先调用
A的无参构造函数构造a(此时a.x可能是垃圾值,因为无参构造没初始化)。- 进入
Pair构造函数体,执行a = A(num);:先临时构造一个A对象(用num初始化x),再把这个临时对象的值赋给a(此时a.x才变成num)。这种方式的问题:
多了一次无参构造和一次赋值,效率低。
若
A没有无参构造函数(就像你的代码),直接编译失败。而初始化列表
: a(num)是直接构造,只调用一次A(int),一步到位,既高效又能避免依赖无参构造的问题。初始化列表
: a(num)不会产生垃圾值,也不存在 “覆盖” 的过程 —— 它是一步到位直接用num初始化a。类比再次解释下,如果A里有两种写法:
A(int num) { x = num; }:先调用x的默认构造函数(对基本类型int来说,就是不初始化,可能是垃圾值),然后进入构造函数体,执行x = num赋值操作,覆盖掉原来的值。
A(int num) : x(num) {}:在初始化列表中直接用num初始化x,跳过默认构造 + 赋值的过程,直接完成x的初始化,更高效(尤其对复杂类型,能避免不必要的操作)。
再说个无意间发现的东西:
查看代码
class Resource { public:// 关键:通过这个函数获取实例,里面是局部静态对象static Resource& get_instance() {static Resource instance; // 局部静态对象:第一次调用时构造,析构在A之后return instance;}void do_work() { cout << "Resource正常工作\n"; }private:// 构造/析构私有化,禁止外部创建Resource() { cout << "Resource构造\n"; }~Resource() { cout << "Resource析构\n"; }Resource(const Resource&) = delete; // 禁止拷贝 };
Resource(const Resource&) = delete;是 C++11 引入的语法,用于明确禁止类的拷贝构造函数。具体来说,拷贝构造函数是类中用于通过已有对象创建新对象的特殊函数(形式为
类名(const 类名& 已有对象))。默认情况下,编译器会为类自动生成拷贝构造函数,允许通过Resource a = b;或Resource a(b);这样的方式拷贝对象。而
= delete;则是显式告诉编译器:删除这个函数,不允许任何地方使用它。在单例模式中,这样做的目的是防止通过拷贝创建多个实例。因为单例的核心是 “全局唯一实例”,如果允许拷贝,就可能通过拷贝原实例生成新的实例,破坏单例的唯一性。所以必须禁止拷贝构造函数,确保无法通过拷贝创建新对象。
static 保证的是 “局部静态对象本身唯一”,但没法阻止外部通过 “拷贝这个唯一对象” 来创建新对象。简单说,static 的作用是限定 “instance” 这个对象的创建规则:第一次调用 get_instance () 时构造,之后一直复用同一个。但如果不禁止拷贝构造,外部代码仍能这么操作:
先通过
Resource& r1 = Resource::get_instance();拿到唯一实例 r1。再用
Resource r2 = r1;(调用拷贝构造函数)创建一个新的 r2。此时 r2 是 r1 的拷贝,属于全新对象,这就破坏了 “全局唯一” 的单例核心规则。
所以
Resource(const Resource&) = delete;是一道 “兜底防线”:哪怕有了 static 局部对象,也要明确禁止拷贝,从根本上杜绝通过拷贝生成新实例的可能,彻底保证单例的唯一性。static Resource& get_instance() {:
static确保了只有一个实例(局部静态对象仅初始化一次),而&(引用)是为了安全返回这个唯一实例—— 如果返回值(Resource)会触发拷贝,破坏单例唯一性;返回指针(Resource*)可能被误删。引用既保证能访问实例,又避免了这些问题,二者配合实现单例的核心:唯一实例 + 全局访问。返回引用确实能避免通过返回值导致的拷贝,但
Resource(const Resource&) = delete;是从根源上禁止拷贝行为 —— 即使在类内部或其他意外场景中,任何试图拷贝实例的操作(比如Resource a = Resource::get_instance();)都会直接编译报错,进一步强化了单例 “不可拷贝” 的特性,是更彻底的防护。返回引用是 “避免通过返回值拷贝”,而删除拷贝构造是 “禁止任何形式的拷贝”,二者配合能更严格地保证单例的唯一性。
假设没写
Resource(const Resource&) = delete;,只靠返回引用:
正常通过
get_instance()获取引用时,确实不会拷贝,没问题。但如果有人故意写
Resource copy = Resource::get_instance();,这行代码会尝试调用拷贝构造函数(用已有的实例复制一个新对象)。此时编译器会默认生成一个拷贝构造函数,导致出现第二个实例,单例就被破坏了。加上
= delete后,编译器会明确禁止这个拷贝构造行为。只要有人试图拷贝实例(包括上面这种情况),编译阶段就会报错,从根本上杜绝了 “意外拷贝出多个实例” 的可能。“避免常规使用时的拷贝”,就是指我们正常用单例的场景 —— 通过get_instance()获取实例并使用 —— 不会产生多余拷贝。比如你写Resource& res = Resource::get_instance();,这里用引用接收返回值,没有新对象生成,这是 “常规使用”,返回引用刚好能满足这种需求,不会触发拷贝。但如果返回的不是引用而是值(比如
Resource get_instance()),那哪怕是常规使用Resource res = Resource::get_instance();,也会拷贝一份实例出来,单例就不唯一了。所以返回引用,本质是保证 “正常用的时候不会不小心多复制一个实例”,这就是 “避免常规使用时的拷贝”。再看个代码练练手:
查看代码
#include <iostream> using namespace std;class Resource { public:Resource() { cout << "Resource构造\n"; }~Resource() { cout << "Resource析构\n"; }void do_work() { cout << "Resource正常工作\n"; } };class A { public:A() { cout << "A构造\n"; res.do_work();}~A() { cout << "A析构\n"; res.do_work();} private:Resource res; };A a; int main() {cout << "main执行\n";}
起初以为说的东西是这个,但其实不是,
res是A的成员变量,C++ 中 “成员变量的生命周期完全依附于所属对象”:
构造时:先构造
res(成员),再构造A(对象本身)析构时:先执行
A的析构函数体(此时res仍存活,所以do_work()能正常调用),再析构res这种 “成员依附于对象” 的关系,天然保证了 “被依赖的成员
res后于A析构”,所以安全。这和单例解决的问题完全不同:单例解决的是独立全局对象之间的依赖顺序问题,而这段代码是 “对象与其成员” 的依赖,后者由 C++ 的类成员规则天然保证安全,不需要单例。
注意几个细节:创建对象时会自动创建并初始化其
private成员。但构造如果是
private,类外不能直接创建对象,但类内静态函数/静态成员初始化时,能调用private构造来创建对象,因为非静态成员/函数必须依赖“已存在的对象”才能调用,而private构造的场景下,类外根本造不出对象,只有静态成员/函数不依赖对象直接在类内独立调用private构造创建对象。这也豆包举错的例子。之前做AI宣传片视频就发现了,真的是大模型现在只能一根筋,生视频只能一个要素一个要素来,让豆包给代码例子也是,妈逼的为了举出单例的代码,各种编译报错,没声明的东西就先用,各种傻逼错误,真的骂不起,耗不起,反反复复一天都在犯错。每学一个知识点都在自己人工手动给豆包做训练修正他的所有错误,唉!
凌晨 4 点睡不着思考这个问题,最后发现狗逼豆包在这绕我,这么简单点破事解释这么晦涩难懂。
对普通局部对象(非静态、非全局):代码书写顺序 = 运行时构造顺序(写在前面的先构造,写在后面的后构造);严格遵循 “构造顺序相反” 的析构规则。
void test() {ObjectA a; // 1. 代码写在「前面」→ 运行时先构造(a先创建)ObjectB b; // 2. 代码写在「后面」→ 运行时后构造(b后创建) }对局部静态对象:构造顺序由「首次调用函数的时间」决定(跟代码书写位置无关,只看运行时第一次触发它的时机)。A 依赖 B 指 A 运行需 B 提供功能或数据。
析构后有时候依旧可以访问
C++ 不强制检查对象是否已析构,析构只是调用析构函数并标记内存可回收,仅执行清理逻辑(如释放资源),并不会立刻即使物理清除内存数据,数据可能暂时保留,直到被覆盖,提升效率。只有栈上对象在所在函数 / 代码块结束时回收,堆上对象在手动调用
delete时回收,全局 / 静态对象在程序退出时才真正回收。C++ 不提供内置机制检查对象是否已析构,需手动设计逻辑保证访问安全。这种 “能访问” 恰恰是最危险的,因为它会掩盖内存违规的真相。
好多东西都想复杂了,学完感觉就这啊?更何况 Java 了,学 C++ 都总感觉没东西,就这啊?所以不断往深入学。
狗东西豆包
再看个东西练手:
查看代码
// x.h #ifndef X_H #define X_H #include <iostream> class X { public:X() { std::cout << "X 构造" << std::endl; }~X() { std::cout << "X 析构" << std::endl; } }; X& getX() {static X inst;return inst; } #endif// y.h #ifndef Y_H #define Y_H #include "x.h" class Y { public:Y() { std::cout << "Y 构造,调用getX()" << std::endl;getX(); }~Y() { std::cout << "Y 析构,调用getX()" << std::endl;getX(); } }; #endif// main.cpp #include "y.h" #include <iostream> Y g_y; int main() {std::cout << "main 开始" << std::endl;getX();std::cout << "main 结束" << std::endl; }输出:
查看代码
Y 构造,调用getX() X 构造 main 开始 main 结束 Y 析构,调用getX() X 析构因为
getX()函数中定义了局部静态对象X inst,根据 C++ 规则,局部静态对象在第一次被调用时初始化(构造)。
Y g_y是全局对象,其构造函数会在main函数执行前被调用,此时getX()被首次调用,触发X inst的构造。小菜一碟直接过。
再回头看【局部静态对象能解决全局对象依赖问题】就懂了
再看个例子:
查看代码
#include <iostream> using namespace std;class Obj { public:string name;Obj(string n) : name(n) { cout << name << " 构造" << endl; }~Obj() { cout << name << " 析构" << endl; } };void func() {static Obj s("局部静态s"); // 首次调用func()时构造 }Obj g("全局g");// 全局对象(程序启动时构造)int main() {Obj m("普通局部m"); // main里的普通局部对象func(); // 触发局部静态对象s的构造cout << "main结束" << endl; }//互换一下 func() 和 全局 就懂了,非常好的例子 //其实说全局最后也没啥问题,但架不住有特殊,还是先构造,后析构来吧再看个例子:
查看代码
#include<iostream> using namespace std; class Resource { public:int* buf;Resource() { cout<<"Res构造"<<endl;buf = new int[10]; }~Resource() { delete[] buf; cout<<"Res析构"<<endl;}static Resource* get() {static Resource inst; // 局部静态对象return &inst;} };class A { public:A(){cout<<"g_a构造"<<endl;Resource::get()->buf[0] = 0; }~A() {cout<<"g_a析构" <<endl;Resource::get()->buf[0] = 0; } }; A g_a;class B { public:B(){cout<<"g_b构造"<<endl;}~B() {cout<<"g_b析构"<<endl;/* Resource::get()使用资源 */ } }; B g_b;int main(){cout<<"main"<<endl;return 0;cout<<"结束"<<endl; }没想到还有我起初没意识到、忽略了、没留意的问题,现在再说说些细节,深入抽插!!
看似静态最后析构?呵呵大错特错!!!还是那句话!只与构造顺序有关!
先解释这里为啥这样输出:【谁先完成构造,谁后析构】,到现在豆包还反复会说,局部静态晚于什么,但现在我其实终于懂这句话了,并没有错!!
程序启动时,先初始化全局对象
g_a,进入g_a的构造函数。在构造函数中调用Resource::get(),触发inst的构造,即inst先完成构造,inst构造完成后,g_a的构造函数继续执行(剩余代码),直到结束,g_a完成构造,所以构造完成顺序是inst先,所以他最后析构!构造完成顺序:
inst→g_a→g_b析构顺序(反序):g_b→g_a→inst。这里我又想到好多细节,慢慢说这个代码一定安全吗?不,说过了,这玩意不是神奇钥匙,全看开发者咋用,
查看代码
#include<iostream> using namespace std; class Resource { public:int* buf;Resource() { cout<<"Res构造"<<endl;buf = new int[10]; }~Resource() { delete[] buf; cout<<"Res析构"<<endl;}static Resource* get() {static Resource inst; // 局部静态对象return &inst;} };class A { public:A(){cout<<"g_a构造"<<endl;}~A() {cout<<"g_a析构" <<endl;Resource::get()->buf[0] = 0; } }; A g_a;int main(){Resource::get(); }
因为
inst的构造完成顺序晚于g_a,所以存在野指针风险:g_a的析构函数中调用Resource::get()->buf[0] = 0时,inst已经析构(buf已被delete[]释放),此时访问buf属于操作已释放的内存,会导致未定义行为(可能崩溃、数据错乱等)。需写代码段人,确保
inst的构造完成顺序早于所有访问它的全局对象,所以这里也看出来了,单例这逼玩意不是万能的。还要注意,代码里的
Resource::get();放全局会报错,C++ 的全局作用域(函数外部)只能放:
变量声明 / 定义(如
int a;、A g_a;)函数声明 / 定义(如
void func() {})类声明 / 定义
命名空间、typedef 等
而
Resource::get();是一个函数调用语句,必须放在函数内部(如main()里、类的成员函数里)才能执行。那么回头看那句很歧义的话很误导人的话:【根据标准,
inst的析构必须晚于所有在它构造时已经存在的对象(即g_a和g_b)】其实不是说咔咔咋无脑写都会晚,涉及到开发者的书写规范!!!而且本身
inst他最先完成的构造,根本不是晚于构造时已存在的对象!!完全错误!再比如,如果你A构造不涉及inst,B构造涉及,那顺序就是,A、inst、B,这时候如果A析构的时候访问inst就错了。Q:代码里的
*和&A:在单例模式中,
static Resource* get()和static Resource& get()的核心区别在于 返回类型的安全性和使用方式,但本质上都指向同一个inst实例:
返回指针(
Resource*):
语法上允许对返回值使用
delete(虽然这里inst是静态对象,delete会导致未定义行为,但编译器不报错),存在被误操作的风险。使用时需要通过
->访问成员(如get()->buf)。指针可能被人不小心写成
delete 指针,虽然这里删不掉(inst是静态对象),但这样写本身就不对,容易出问题。比如有人可能误写代码delete Resource::get();。因为
get()返回的是指针(Resource*),语法上允许对指针用delete,但这里的指针指向的是局部静态对象inst,而静态对象的生命周期由系统管理,手动delete会导致未定义行为,比如程序崩溃,而如果返回引用(Resource&),语法上就不能对引用用delete(编译器直接报错),从根源上避免了这种低级错误。返回引用(
Resource&):
语法上禁止对引用使用
delete(编译器直接报错),从根源上避免了误销毁的风险,更安全。使用时通过
.访问成员(如get().buf),更符合对象的自然访问方式。我代码里写
return 0后还有代码,意图是想证明豆包解释时出现的“函数结束前析构”这几个字,其实说的就是在return 0之前。跨文件也不一定安全,若文件 A 的局部静态对象
inst依赖文件 B 的全局对象obj,但inst先构造而obj未构造,此时访问obj会导致未定义行为(访问未初始化对象)。而且,就算和 B 无关,比如 AB 两个,A 调用的局部静态,但代码先执行的 B。再说我之前没意识到的东西:
之前没仔细思考,看到
Res里的析构就认为是静态局部的析构,现在都懂了全局和局部静态之后,回头看局部静态的析构,感觉好大的疑惑,第一次调用
Resource::get()时构造inst,析构就是调用~Res,Q:不对啊,我理解析构函数里写的是析构
new出的buf,然后就是默认析构,难道默认析构会析构static静态的???A:类的 static 成员属于类本身,不属于任何对象,默认析构函数只负责销毁当前对象的非 static 成员,不会处理 static 成员。
但
inst是Resource类的对象实例,其析构过程就是调用Resource类的析构函数~Resource()。1.
inst是什么?属于谁?
inst是Resource类的局部静态对象,定义在static Resource* get()这个静态成员函数里。
它不属于
get()函数本身,而是属于 “静态存储期”(和全局对象一样,生命周期贯穿程序始终,只是首次调用get()时才初始化)。它是一个实实在在的
Resource类实例(对象),不是函数的一部分,也不是静态成员变量(静态成员变量属于类,这里inst是函数内的局部静态对象,仅在get()内可见,但生命周期全局)。2.
inst会被析构吗?谁来析构它?会被析构,且一定由
Resource类的析构函数~Resource()来析构。
所有对象(包括局部静态对象)生命周期结束时,都会自动调用其所属类的析构函数。
inst是Resource的对象,所以它的析构就是执行~Resource()。
~Resource()里的delete[] buf,正是释放inst对象自己的非静态成员buf(因为buf是inst在构造时new的,属于inst的一部分)。可我感觉
inst也没有buf啊?
inst是Resource类的对象实例,buf是Resource类的非静态成员变量—— 只要类的对象,就一定包含该类的非静态成员。简单说:
Resource类定义了int* buf;,这意味着每个Resource对象(包括inst)都会有一个属于自己的buf成员。inst在构造时(执行Resource()构造函数),会给 “自己的buf” 分配内存(buf = new int[10]);inst析构时(执行~Resource()),会释放 “自己的buf”(delete[] buf)。
buf是inst这个对象的 “零件”,就像 “车” 有 “轮子”,inst(车)必然有buf(轮子),~Resource()就是拆轮子的过程。3.
inst的析构时机?
inst是静态存储期对象,其析构时机遵循 “构造完成顺序的反序”:
全局对象
g_a、g_b在main前就构造完成。
inst在第一次调用get()时构造完成(你的代码中,g_a和g_b的析构函数会调用get(),所以inst的构造完成时间晚于g_a、g_b)。因此析构顺序是:
g_a析构 →g_b析构 →inst析构(执行~Resource()释放buf)。混淆 “静态成员函数里的局部静态对象” 和 “类的静态成员”:
inst是局部静态对象(属于静态存储期的对象实例),不是类的静态成员(静态成员属于类,比如get()本身是静态成员函数)。Q:~Res里只要cout了buf析构一定是inst也就是get函数触发的?
A:是的。
~Resource()是Resource类的析构函数,只有Resource类的对象析构时才会调用它。代码中唯一的
Resource对象就是get()里的局部静态对象inst(没有其他Resource对象被创建),所以~Resource()里的cout<<"buf析构",一定是inst析构时触发的。没有其他可能 —— 因为没有第二个
Resource对象,也就不会有其他对象触发这个析构函数。Q:我没懂一般代码不都是就算没有
get也会有析构吗?那时候析构的是啥?肯定不是get,那这不就说明析构的时候不止是inst的get吗?A:为什么 “没有
get()也可能有析构”?—— 因为创建了其他Resource对象你说的 “没有
get()也会析构”,前提是代码里手动创建了Resource类的对象。比如:// 没调用get(),但主动创建了Resource对象 Resource obj; // 普通局部对象 // 或 Resource* p = new Resource; // 动态对象这种情况下,析构的是你手动创建的
obj(局部对象出作用域时析构)或p指向的对象(delete p时析构)——析构的是 “具体的Resource对象”,不是某个函数。你原代码里 “只有
get()会触发~Resource()”—— 因为只有get()里创建了唯一的Resource对象你原代码中,没有任何地方手动写Resource obj或new Resource,唯一的Resource对象就是get()里的局部静态对象inst。只有当inst析构时(程序结束前,按静态存储期规则),才会调用~Resource();没有其他Resource对象,自然不会有其他东西触发这个析构函数。总结:
析构的不是 “函数”(比如
get()),而是 “类的对象”(比如inst、obj)。有多少个
Resource对象,就会触发多少次~Resource();没有对象,~Resource()永远不会被调用。你原代码里只有
inst这一个Resource对象,所以~Resource()只能是inst析构触发的;如果代码里多创建一个Resource对象,就会多一次~Resource()的调用(析构那个新对象)。Q:如果没有任何代码掉调用get 是不是永远没有
~Res的析构?A:如果从未调用
get(),inst就不会被创建(局部静态对象的初始化是 “按需进行” 的,不调用get()就不会触发其构造)。而~Resource()是Resource对象的析构函数,只有当Resource对象存在且生命周期结束时才会被调用。既然inst从未被创建,自然不会有~Resource()的调用。所以,不调用get()→inst不构造 → 不存在Resource对象 → 永远不会执行~Resource()。代码里所有的
Res的构造、析构,根本原因是inst这个对象的存在,get()只是触发inst构造的 “开关”。
Resource的构造(Res构造):因为g_a或g_b的析构函数调用了Resource::get(),第一次调用get()时,会触发局部静态对象inst的构造,从而执行Resource的构造函数。
Resource的析构(buf析构):程序结束前,静态存储期的inst会析构,从而执行Resource的析构函数。
get()的作用只是 “首次调用时创建inst,并返回其地址”,它本身不直接导致构造 / 析构,真正触发的是inst这个对象的生命周期(构造→析构)。如果没有inst,get()再被调用也不会有Resource的构造 / 析构。析构是
inst触发的。get()只是获取inst的工具,本身不会参与析构。inst作为静态存储期对象,在程序结束前会自动析构,此时必然调用其所属类Resource的析构函数 —— 这是inst自身生命周期结束的自然结果,与get()无关。只要inst存在过,其析构就由自身生命周期决定,和get()没关系。
inst是局部静态对象(唯一、全局生命周期),成员变量属于类的实例(随实例生灭),两者性质不同。Q:这里有几个
Res对象就会析构几次?每个对象都有一个inst?A:不对。单例模式中
Resource只有 1 个对象(即inst),所以只析构 1 次。inst是局部静态对象,整个程序中仅存在 1 份,和Resource的其他对象(若有的话)无关 —— 但单例模式会禁止创建其他对象,确保只有inst存在。Q:如果创建3个Res对象呢?
A:单例模式的核心就是禁止创建多个对象(通常通过私有化构造函数实现),所以正常情况下根本无法创建多个
Res对象。若强行绕开限制创建多个,那就不是单例了,此时每个对象都会析构一次,但这违背了单例的设计初衷。Q: 不对吧 ? 静态的是
inst跟Res无关A:
inst是Resource类的局部静态实例,本质是Resource类型的对象,和Resource类直接相关 —— 它的类型就是Resource,构造 / 析构都遵循Resource的规则。静态性只决定它的生命周期(全局)和唯一性,不改变它是Resource对象的本质。Q:
查看代码
#include<iostream> using namespace std; class Resource { public:int* buf;Resource() { cout<<"Res构造"<<endl;buf = new int[10]; }~Resource() { delete[] buf; cout<<"Res析构"<<endl;}static Resource* get() {static Resource inst; // 局部静态对象return &inst;} }; Resource eA; Resource eee; int main(){}输出: Res构造 Res构造A:这违背了单例模式的设计(单例应禁止创建多个实例)。若要实现单例,需将
Resource的构造函数私有化(private: Resource() { ... }),阻止外部创建eA、eee这类额外对象,确保只有inst是唯一实例。必须手动实现单例模式的核心限制。单例模式的 “不能创建多个对象”,不是 C++ 语法天然禁止的,而是开发者通过代码刻意限制的 —— 最关键的就是把类的构造函数设为private(私有),这样外部就无法直接用Resource eA;这种方式创建对象了。查看代码
class Resource { private: // 关键:构造函数私有化Resource() { // 现在外部无法直接创建对象了cout << "Res构造" << endl;buf = new int[10];} public:// ... 其他成员不变static Resource* get() {static Resource inst; // 唯一能创建对象的地方return &inst;} };这时再写
Resource eA;就会编译报错,因为外部无法访问私有构造函数,这样才能确保只有get()里的inst这一个对象 —— 这才是单例模式的 “本质”:通过代码限制,强制只能有一个实例。在单例模式中(构造函数私有化后),只能通过类提供的静态方法
get()来访问唯一实例,比如:// 访问单例对象的成员 Resource::get()->buf[0] = 10; // 用->访问指针指向的成员第一次调用
get()时会自动创建唯一实例inst,后续调用get()只是返回已创建的实例。
Resource对象最多只有 1 个(就是get()里的局部静态对象inst)。后续调用get()返回的都是同一个对象(因为inst一旦创建就不会再重新初始化,局部静态对象的生命周期贯穿整个程序,且仅初始化一
Resource类本身不是静态的,可以创建多个,但单例模式通过代码限制,让它只能有一个实例。你可以把Resource类想象成 “图纸”,inst是用这张图纸造出来的 “唯一产品”。图纸(类)本身不是静态的,但通过限制(私有化构造函数),让这张图纸只能造出一个产品(实例)Q:首次调用时创建inst,并返回其地址,地址存哪里了?
A:
get()返回的inst的地址(&inst),会被调用者接收和使用,但不会被自动 “存储” 在某个固定地方,完全取决于调用时如何处理。比如你的代码中,
g_a的析构函数里调用Resource::get()->buf[0] = 0,这里get()返回的地址只是临时用来访问buf,用完后就不再保留;如果其他地方调用get(),会再次拿到同一个地址(因为inst是唯一的)。查看代码
// 第一次调用:创建inst,返回其地址 Resource* p1 = Resource::get(); // 第二次调用:直接返回已存在的inst的地址(和p1相同) Resource* p2 = Resource::get(); cout << (p1 == p2); // 输出1,证明是同一个地址炸而裂之、牛而逼之、母牛屁股挂鞭炮 —— 牛逼到爆!小母牛到南极 —— 牛逼到了极点!!老子精通了艹!一把辛酸泪!
C++ 链接对话都删了,扒拉对话复盘整理的时候,很多都跳跃穿插的,回答太乱了,直接整理完一块就删一块。
留一行个尾巴便于新增内容,否则引用的格式很难调
留一行个尾巴便于新增内容,否则引用的格式很难调
留一行个尾巴便于新增内容,否则引用的格式很难调
类的构造函数花括号内的代码(函数体) 中的操作,属于赋值,而非初始化。
具体区分:
初始化:在成员变量获得内存的同时赋予初始值,包括:
成员变量声明时的就地初始化(
int a = 10;)构造函数初始化列表(
MyClass() : a(10) {})初始化只在对象创建时执行一次,且顺序严格遵循声明顺序。
赋值:在成员变量已经初始化(获得内存)之后,重新修改其值。例如构造函数体中的
a = 10;,此时a早已完成初始化(可能是默认值或随机值),这只是后续的赋值操作,顺序由代码书写决定,与声明顺序无关豆包死妈玩意说的跟主流傻逼一样!很没底层的准确逻辑,很适用于傻逼脑残大众。其实以上都有垃圾值!
初始化:先分内存(此时有垃圾值),立即赋值(覆盖垃圾值)。 两步连续执行,合称 “初始化”,最终无垃圾值。
赋值:变量已存在(可能有值,非 “垃圾值” 阶段),用新值覆盖旧值,最终也无垃圾值。
两者最终结果都是变量有确定值,无垃圾值,但初始化是 “变量诞生时赋值”,赋值是 “变量已存在后改值”。
代码:
查看代码
#include <iostream>class Example { private:int a; // 声明int b; // 声明public:// 初始化列表(初始化)Example(int val) : a(val) {// 花括号内(赋值)b = val;} };int main() {Example obj(10); }
a通过初始化列表初始化b在构造函数体(花括号内)中赋值。总结:构造函数体中的操作是赋值,初始化仅由就地初始化和初始化列表完成,且初始化顺序只看声明顺序。
咋验证这个顺序的事?
查看代码
#include <iostream>// 自定义类型,构造时打印信息 struct Int {int value;Int(int v) : value(v) {std::cout << "Int constructed with value: " << v << std::endl;} }; class Test {Int a; // 声明顺序1Int b; // 声明顺序2 public:// 初始化列表写b在前、a在后Test() : b(1), a(b.value) {} };int main() {Test t; }输出:
这代码又引出一堆屁事,逐个解释:
C++ 中
struct和class都能定义构造函数,构造函数不是class专属的。流程:
Test t;:分配内存执行Test t;时,操作系统为Test对象分配内存,内存大小 =Int a的大小 +Int b的大小(每个Int含 1 个int,总大小为 8 字节,按声明顺序在内存中连续排列:a在前,b在后)。此时内存中是随机二进制值(未初始化垃圾值)。触发Test类的默认构造函数Test() : b(1), a(b.value) {},按声明顺序初始化成员:
先初始化
a(Test 类中a声明在b前)→ 需要调用Int的构造函数初始化a,参数是b.value这个是b的垃圾值也叫随机值→ 执行Int的构造函数Int(int v) : value(v) { ... }(Int 结构体的构造函数)→ 打印Int constructed with value: 随机值(这里实际看到的 0)→a初始化完成再初始化
b(Test 类中b声明在a后)→ 需要调用Int的构造函数初始化b,参数是1→ 再次执行Int的构造函数Int(int v) : value(v) { ... }→ 打印Int constructed with value: 1→b初始化完成初始化为啥拐到
Int里的构造去了?
Int是自定义类型,int是基本类型,C++ 对这两种类型的初始化规则完全不同:如果是
int a(基本类型):初始化时直接给内存赋值,不需要调用任何函数。比如a = 5就是直接把 5 写入a的内存地址,没有函数调用过程。如果是
Int a(自定义类型):C++ 规定:自定义类型的对象必须通过构造函数初始化,编译器不知道如何初始化它,必须由你写的构造函数Int(int v)来完成初始化。所以每当创建Int类型的对象,编译器会强制调用Int的构造函数。开多大?
int a的内存通常开 4 字节,赋值a=5:直接将二进制的 5 写入这 4 字节内存中。
Int a的内存,包含一个int成员,因此和int相同,初始化时先分配这 4 字节内存,再调用Int的构造函数,将参数值写入这 4 字节(本质和int存值方式一样,只是多了构造函数的调用过程)。验证完毕。
先声明的,先初始化。无论你列表里咋写,编译器都会给你重新排列下,注意不是重新排声明顺序,是重新排初始化列表里的初始化顺。
看似好像没啥事,但有个例子:初始化列表的 “值” 有顺序依赖,这里应该举一个错误的例子,但豆包给出的我一直觉得例子是正确的,然后反复质疑豆包,豆包依旧给我扯强行解释,就说例子错了,耽误我整整两天,写代码实验也发现不出哪里错,最后深度思考死全家狗逼豆包承认错误了,附上 问答链接(心性磨练出来了)。
我自己学,没人可以交流,豆包反复误人子弟却又是我唯一的救命稻草,没办法。而且豆包尽管垃圾,但百度文心、通义千问、腾讯的玩意没有能用的艹、Deepseek、问小白,全试过了,豆包还是里面最好的!Chatgpt不想用,因为魔法万一突然挂了,如果我正在导管子那也就难受一会,但这问知识 24h 必须随时可以问东西,万一挂了就真难受。
大量的砸时间,何时能熬出头
class MyClass {int num; // 声明1:先声明int* arr; // 声明2:后声明 public:MyClass() : arr(new int[num]), num(5) {} // 错误写法 };质疑自己
质疑自己,真的好痛苦,大厂的真都会这些且钻研到我这种程度吗?咋感觉就我这么蠢钻研这些,东西真的好多啊,真的值得吗?
我每一个小节任何关键词任何C++基础知识对象知识,包括之前学所有知识也是,全部都事无巨细自己写代码实际踩坑测试,耽误了耗费了无数时间,哎~~~~(>_<)~~~~
豆包回答(这回真的不错,之前豆包就是个误人子弟的狗逼)(之前就质疑过,是不是自己事无巨细的把别人实战实践才能了解想到遇到的东西,提前自己思考踩坑了,豆包说不是,更复杂的需要实际项目遇到,举了个例子我看的头大)(别人是先了解后实战强化逐步进阶,我不用,我学东西慢,直接自己想到所有坑点和未来项目的坑点)
每次熬不下去就【中科院黄国平博士致谢论文】、【篮球人物小明的罗斯纪录片】、【艾弗森个人纪录片只用一招就晃过全联盟桀骜不驯的球场答案】
自言自语自己做过的东西心路历程,给面试官说,尽管这狗逼乌烟瘴气的世道,我的东西没人会看到会倾听
c++真的那么难吗?爸爸的病永远无法治好,而我只要学,吃饭睡觉拉屎都想各种没理解的知识点,学一份就有一份的收货
人是环境的产物,绝境可以塑造一个人。破而后立大彻大悟。
细心、好钻研,这两点没人能取代我,哪怕 C9 的也,无所谓。精力旺盛、极强的自制力、意志力、学习能力、生存能力、为人处事待人接物人情世故、我学任何东西都是亲自写代码踩坑思考对标别人的实战进阶项目中才能遇到的问题,我学一个 2min 就能阅读完的东西要学 2 天,面试官问的我一定都自己思考写过代码实践过,但我问面试官的他一定会被我问住
豆包真的不无脑附和我和无脑道歉了(不对,只是知识点不同,之前 private 的问题还是会错误回答)
仿佛过了一个世纪一样漫长,继续说我们的顺序的事
我把踩过的坑都记录下来,
查看代码
#include<iostream> using namespace std; class Myclass { public:int* arr; // 声明1:arr在前int num; // 声明2:num在后Myclass() : arr(new int[num]), num(5) {} cout<<arr<<" "<<num<<endl; };Myclass M; int main(){}错误原因很明确:
cout语句直接写在了类的定义体中(类的成员声明区域),而类体中只能放成员声明(变量、函数),不能直接写可执行语句(如cout)。
cout可以写在类的成员函数内部(包括构造函数、析构函数、普通成员函数等),因为成员函数是可执行代码的载体。将
cout写入构造函数里
cout<<arr<<" "<<num<<endl;中,arr输出的是动态数组的首地址(new 分配的内存块的起始位置,如0x5566b82a9eb0)。arr本身就是指向数组首元素的指针,因此arr的值就是数组内数据的首地址。例如输出的0x5566b82a9eb0既是arr指针的值,也是数组第一个元素的内存地址。第一个元素
arr[0]或*arr。
arr(new int[num])就是在堆上分配一个能存num个int的数组,然后把数组首地址存在arr里。
int a[10]:在栈上分配固定大小(10 个 int)的数组,大小编译时确定,离开作用域自动释放。
new int[num]:在堆上分配大小为num(可动态变化)的数组,大小运行时确定,必须手动用delete[]释放,否则内存泄漏。测试垃圾值:
查看代码
#include<iostream> using namespace std; class Myclass { public:int* arr;int num;Myclass() : arr(new int[get_num_before_init()]), num(5) {cout << "arr地址: " << arr << ", num初始化后: " << num << endl;} private:// 初始化arr前先获取num的原始值int get_num_before_init() {int temp = num; // 此时num未初始化,取到垃圾值cout << "num初始化前的垃圾值: " << temp << endl;return temp;} };Myclass M; // 全局对象,程序启动时构造 int main(){}如果
num的垃圾值恰好是 0,那么arr(new int[num])会分配一块 “大小为 0 的 int 数组”。C++ 允许new int[0]这种写法(语法合法),它会返回一个 “非空的无效指针”—— 指针本身有地址,但指向的内存块大小为 0(不能访问任何元素,否则是越界)。简单说:此时arr指向的数组 “长度为 0”,没有有效元素。这里的 “非空” 指的是指针变量本身的值不是
nullptr(有一个具体的内存地址),但 “无效” 指的是这个地址指向的内存块大小为 0,不能用来访问任何元素(比如arr[0]就是越界行为)。举个例子:int* p = new int[0];此时p不是nullptr(有实际地址),但p指向的内存块长度为 0,所以*p或p[0]都是错误的,因为没有可访问的元素。简单说:指针有 “名分”(地址),但没有 “实际地盘”(有效内存),所以叫 “非空的无效指针”。查看代码
class MyClass {public:int num; int* arr; MyClass() : num(5), arr(new int[num]) {// 用memset将数组初始化为0(仅作用于已分配的内存)memset(arr, 0, sizeof(int) * 10); // 假设最多测试10个元素} };在构造函数里写
memset,它的执行时机是:每次创建这个类的对象时,在成员初始化列表完成后(也就是num被赋值为 5、arr指向新分配的数组后),会执行构造函数体内的代码,包括memset。简单说:每个对象被构造时,都会走一遍memset。比如你创建两个MyClass对象:MyClass a; // 构造a时,执行memset初始化a.arr MyClass b; // 构造b时,执行memset初始化b.arr两个对象的
arr数组都会被memset处理,各自独立。这里的关键是
arr实际分配的大小 和memset操作的大小 不一致,会出问题。
arr实际分配的大小:构造函数初始化列表里arr(new int[num]),而num被初始化为 5,所以arr指向的是一个 能容纳 5 个int的数组(总大小是5 * sizeof(int))。
memset操作的大小:代码里memset(arr, 0, sizeof(int) * 10),意思是从arr指向的地址开始,往内存里写 10 个int大小的 0(总大小是10 * sizeof(int))。问题所在:你只分配了 5 个
int的空间,却强行往里面写 10 个int的内容,这会 越界访问内存(操作了不属于arr的内存)。后果是不确定的,可能导致程序崩溃、数据错乱,或者暂时没报错但隐藏隐患。正确的做法是让
memset的大小和实际分配的大小一致,比如:memset(arr, 0, sizeof(int) * num);(因为num是 5,刚好匹配分配的大小)。
Q:我之前懂了单例模式,线程安全咋回事?(这里引出了相当精华透彻的东西,之前完全没注意到,甚至说之前完全没懂)
A:单例模式和线程安全密切相关,尤其是在多线程环境下,基础的单例实现(比如之前的
static B instance)可能存在线程安全问题。看代码:
#include <iostream> using namespace std;class B { public:// C++11起,局部静态变量初始化是线程安全的static B& getInstance() {static B instance; // 多线程同时调用时,只有一个线程会初始化return instance;}void doSomething() { cout << "B工作(线程安全)" << endl; }private:B() { cout << "B构造" << endl; }// 禁止拷贝和赋值(彻底保证唯一性)B(const B&) = delete;B& operator=(const B&) = delete; };C++11(2011年发布,之前是 C++ 03) 之后,这段代码(
static B instance;作为局部静态变量)本身就自动具备线程安全性,不需要你额外手写任何线程同步代码(比如加锁)。原因是:C++11 标准强制要求编译器对 “局部静态变量的初始化” 做特殊处理 —— 当多个线程同时首次进入
getInstance()时,编译器会自动插入底层同步逻辑(类似加锁解锁),确保instance只被初始化一次,其他线程会等待初始化完成后再访问。也就是说,这段代码的写法没变,但 C++11 标准给它赋予了线程安全的特性。你不需要额外封装或修改,直接这么写就够了。
注意:无论 C++11 前后,
static B instance;作为 函数内的局部静态变量,其本质都是 “在首次调用函数时初始化,且仅初始化一次”,整个程序生命周期内只有一个实例,应用场景比如:
控制共享资源:比如操作同一个配置文件的 “配置类”若有 A、B、instance 三个实例,A 修改了 “服务器地址”,B 可能还在用旧地址,instance 又改了别的参数 —— 三个实例的配置数据完全不一致,程序调用时会混乱(比如一会儿连对地址,一会儿连错)。只有一个实例时,所有代码都读 / 写这同一个实例的配置,数据永远统一。
管理全局状态:比如记录用户登录状态的 “用户类”若有多个实例,可能出现 “instance 标记用户已登录,A 实例却标记未登录” 的情况 —— 程序判断登录状态时,有时让进、有时不让进,逻辑直接崩溃。单实例能保证 “登录 / 未登录” 是全局唯一的状态,不会自相矛盾。
节省资源开销:比如创建成本很高的 “数据库连接类”数据库连接需要建立网络链路、验证权限,创建一次很耗时间 / 内存。若每次用都新建一个实例(A、B、instance),会同时存在多个连接,既浪费服务器资源,还可能触发数据库的 “最大连接数限制”,导致新连接失败。单实例只需创建一次,所有代码复用这个连接,高效又省资源。
这就是唯一目的,保证一个,但多线程下容易掉链子,不小心创建多个,本身步骤是:
检查变量是否已初始化;
若未初始化,执行构造(初始化)。
单线程下:这两步是 “串行” 的,不会穿插,自然不会重复初始化。
多线程下(C++11 前):这两步可能被 “打断”—— 比如线程 A 刚做完 “检查未初始化”,还没来得及构造,线程 B 就冲进来也做 “检查未初始化”,最终导致两者都执行构造,出现多个实例。
C++11 后:编译器会自动给这两步加 “锁”,确保同一时间只有一个线程能执行 “检查 + 构造”,其他线程只能等,从而保证唯一。
所以我们说 C++ 11 前不安全,那 C++ 11 之后就没事了吗?不也有问题,C++ 11 只是保证了线程安全,但这里有很多我之前忽视的东西,我一直以为
static语法规则本身就只有一个了,怎么还那么多屁事呢?其实忽略了手动创建这个事,我起初理解不是静态全局就一个吗?咋手动建还能建立多个??不是说以后再Resource::get()拿到的还是第一次用的那个地址吗?咋可能有多个??单例光有局部静态还不够,必须禁止外部创建新实例,上面构造函数
private后就无法外部新弄对象了,只提供public的getInstance,最重要的是class B { private:B() {} // 私有构造函数 public:static B& getInstance() {static B instance; // 唯一能创建实例的地方return instance;} };这里我之前没意识到,
instance本身就是B类的一个实例,构造如果不是private, 那当B b;、B c;后,这里b、c、instance都是平级的!!!相互独立的不同实例(总共多个B实例)。私有化构造函数后,外部无法创建a、b这样的实例,只能通过getInstance()获取instance,而instance作为局部静态变量只会被初始化一次,所以整个程序中只有这一个B实例。这就是关键点,我之前一直把
instance当成B的某个成员函数/变量了,验证instance里也有类的全部东西查看代码
#include <iostream> using namespace std;class Test { public:int num = 0; // 成员变量void print() { cout << "num = " << num << endl; } // 成员函数 private:Test() {} // 构造函数私有化(单例基础) public:// 获取静态局部实例的唯一接口static Test& getInstance() {static Test instance; // 静态局部实例return instance;} };int main() {// 1. 通过单例接口获取静态局部实例Test& static_inst = Test::getInstance();static_inst.num = 100; // 操作成员变量static_inst.print(); // 调用成员函数// 2. 验证:再次获取的是同一个实例,成员变量已被修改Test::getInstance().print(); }如果去掉就会变成
查看代码
#include <iostream> using namespace std;class Test { public:int num = 0; void print() { cout << "num = " << num << endl; } Test() {} // 构造函数改为public,允许外部创建对象 public:static Test& getInstance() {static Test instance; return instance;} };int main() {// 1. 创建普通实例ATest A;A.num = 10;A.print(); // 输出 num = 10// 2. 创建普通实例BTest B;B.num = 20;B.print(); // 输出 num = 20// 3. 单例的静态实例Test& static_inst = Test::getInstance();static_inst.num = 100;static_inst.print(); // 输出 num = 100 }多个对象会导致 成员变量
num完全独立——A 修改的是 A 的num,B 修改的是 B 的num,静态实例修改的是自己的num,三者互不干扰。如果这个类是管理配置、登录状态等需要 “全局统一” 的数据,多对象会导致数据混乱(比如一处用 A 的num=10,另一处用 B 的num=20,逻辑不一致)。
真的好痛苦
居然还要学的除了数据库Redis还有分布式,不学完全不行(后续学习路线)
昨晚导管子但没素材,无聊,无意间查到知乎里大厂 Linux C++ 服务端开发的面试题,脑子一片空白,今天来问下豆包(第一次查面试,为了看需不需要学分布式啥的):
构造函数可以是虚函数吗?不可以:
虚指针在对象构造过程中(而非完全创建后)被初始化,且只有类包含虚函数时,对象才会有虚指针。
虚函数的实现依赖虚表(vtable),而虚表是属于对象实例的,需要在对象构造完成后才存在。但构造函数的作用是创建对象本身,在调用构造函数时,对象还未完全创建,虚表尚未初始化,因此无法支持虚函数调用。
构造函数的目的是初始化当前类的成员,而虚函数的意义是 “动态绑定”(根据对象实际类型调用对应函数)。构造函数调用时,对象的实际类型就是当前类(不存在 “子类对象在构造时调用父类虚构造函数” 的场景),虚函数的动态绑定特性在这里毫无意义。
动态绑定的核心是:当对象的虚指针指针初始化完成后(指向所属类的虚表),通过基类指针 / 引用调用虚函数时,会根据虚指针指向的实际类的虚表,找到并执行该类的虚函数实现。
基类里有个虚函数,然后他子类重写,此时如果说整个子类的对象,此时对象诞生完就有了一个指向子类的虚指针。用基类指针 / 引用 “间接操作” 子类对象,这时候才需要靠虚函数和虚表来 “认对” 实际要调用的函数,也是动态绑定的核心使用场景
查看代码
class Base { // 基类 public:virtual void show() { cout << "Base的show" << endl; } };class Derived : public Base { // 子类,重写虚函数 public:void show() override { cout << "Derived的show" << endl; } };int main() {Derived d; // 子类对象,虚指针指向Derived的虚表Base* ptr = &d; // 基类指针,指向子类对象dptr->show(); // 关键:用基类指针调用show() }这里
ptr是基类指针,但它指向的是子类对象 d。
如果没有虚函数(非动态绑定):编译器会按 “指针类型(Base)” 调用
Base::show()。有虚函数(动态绑定):编译器会通过 “对象 d 的虚指针” 找到
Derived的虚表,最终调用Derived::show()—— 这才是动态绑定的意义,不管指针是基类还是子类类型,都能调用 “对象实际类型” 的函数。基类指针确实只能访问基类中声明的成员(包括虚函数),无法直接访问子类新增的成员(这是 “类型安全” 的限制,不会丢弃对象,只是编译时只能看到基类接口)。
但对于基类中声明的虚函数,即使通过基类指针调用,也会根据指针指向的 “实际对象类型”(子类对象),动态绑定到子类的重写版本 —— 这正是虚函数的核心作用,和 “能否访问子类新增成员” 无关。
查看代码
class Base { public:virtual void show() { cout << "Base"; } // 基类虚函数 };class Derived : public Base { public:void show() override { cout << "Derived"; } // 重写基类虚函数void extra() { cout << " 子类独有函数"; } // 子类新增函数 };int main() {Derived d;Base* ptr = &d; // 基类指针指向子类对象ptr->show(); // 正确:调用Derived::show()(动态绑定)// ptr->extra(); // 错误:基类指针无法访问子类新增成员(编译报错) }虚函数的动态绑定功能,要在对象完全构造完成后才能正常使用,构造函数执行期间用不了。
反之,析构函数通常建议声明为虚函数(尤其是当类可能被继承时),目的是确保子类对象销毁时能正确调用自身的析构函数,避免内存泄漏。虚析构会触发动态绑定
当用基类指针 / 引用指向子类对象,并通过它销毁对象时:
非虚析构:只按 “指针类型(基类)” 调用基类析构,子类资源泄漏。
虚析构:按 “对象实际类型(子类)” 调用析构,先子后父,无泄漏。
若类不会被继承,析构函数可不用设为虚(但设了也无错,只是多一点虚表开销)。
算法 A 对,阅读理解做对题,我之前一年半这么深钻研,目的只是为了能看懂面试题的答案,唉,路漫漫啊,还需要高压面试,看各种面试题,就像内功,完全无法施展出来,唉,很多东西都是两码事,步骤太多了,阿根廷对自己进行了革命,但只有拿到大力神杯的那一刻所有的隐忍和努力才有回报
继续看作者的教程:
派生类对象构造时,会先构造所有基类,再构造自身:
先按规则初始化所有基类(虚基类优先于非虚基类,非虚基类按继承列表顺序);
再初始化派生类的成员变量(按声明顺序);
最后执行派生类构造函数体中的代码。
这作者还真有两下子啊,例子真好,都包括了,之前我例子都是基类
析构顺序:
先析构自己相关的,再析构基类
执行派生类自身的析构函数体
析构派生类的成员变量(按成员变量 声明的逆序 析构)
析构所有基类(按基类构造顺序的逆序)
查看代码
#include <iostream>class Base { public:Base() { std::cout << "Base constructor" << std::endl; }~Base() {std::cout << "Base destructor" << std::endl;} };class Base1 { public:Base1() { std::cout << "Base1 constructor" << std::endl; }~Base1() {std::cout << "Base1 destructor" << std::endl;} };class Base2 { public:Base2() { std::cout << "Base2 constructor" << std::endl; }~Base2() {std::cout << "Base2 destructor" << std::endl;} };class Base3 { public:Base3() { std::cout << "Base3 constructor" << std::endl; }~Base3() {std::cout << "Base3 destructor" << std::endl;} };class MyClass : public virtual Base3, public Base1, public virtual Base2 { public:MyClass() : num1(1), num2(2) {std::cout << "MyClass constructor" << std::endl;}~MyClass() {std::cout << "MyClass destructor" << std::endl;}private:int num1;int num2;// 这个是为了看成员变量的初始化顺序Base base; };int main() {MyClass obj;}输出:

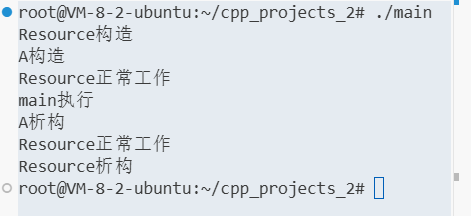




关于 C++析构函数可以抛出异常吗?
解释下抛异常:
throw是报错,try-catch是接报错并处理。查看代码
int main() {int x = 10, y = 0;// try包裹“可能抛异常的代码”try {divide(x, y); // 调用divide,这里可能抛异常}// catch接住“string类型的异常”(和throw的类型对应)catch (string errMsg) {// 处理异常:打印错误信息,程序不会崩溃cout << "捕获到错误:" << errMsg << endl; }cout << "程序继续执行..." << endl; // 异常处理后,程序能正常往下走 }