嵌入(Embedding)是RAG流程里非常关键的一个步骤。它处理的是数据提取和分块之后的内容,嵌入的好坏直接影响系统能不能准确地表示和检索信息。这篇文章会讲清楚嵌入是什么、怎么工作的,还有怎么挑选合适的模型。
经典的RAG工作流
典型的RAG流程包含这几步:
首先是数据提取,从文档、网站、数据库等数据来源收集文本。然后分块,把文本切成更小但有意义的单元,并且要保持上下文完整。接着就需要嵌入处理,把每个分块转成固定长度的数值向量。然后向量存储这步把嵌入放进向量数据库,常用的有FAISS、Weaviate、Pinecone这些。
最后是检索和生成。用户查询进来后,先把查询嵌入,找到语义相似的向量,再用这些向量生成回答。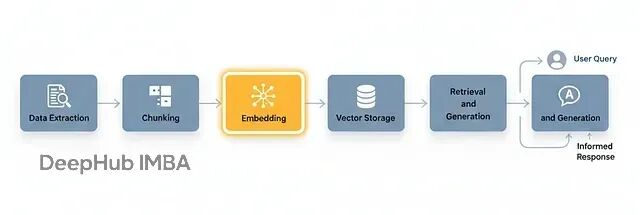
嵌入步骤保证了语义相似的文本在向量空间里位置相近,这样检索就不是简单的关键词匹配,而是基于实际含义。
https://avoid.overfit.cn/post/8224fc3532aa44e588d9882d16e2b6b2