TL;DR
过去一年间,生成式推荐取得了长足的实质性进展,特别是在凭借大型语言模型强大的序列建模与推理能力提升整体推荐性能方面。基于LLM(Large Language Models, LLMs)的生成式推荐(Generative Recommendations, GRs)正逐步形成一种区别于判别式推荐的新范式,展现出替代依赖复杂手工特征的传统推荐系统的强大潜力。本文系统全面地介绍了基于LLM的生成式推荐系统(GRs)的演进历程、前沿核心技术要点、关键工程落地挑战以及未来探索方向等内容,旨在帮助读者系统理解GRs在“是什么”(What)、“为什么”(Why)和“怎么做”(How)三个关键维度上的内涵。
一、引言:传统推荐的困境与LLM的破局
随着推荐系统的发展,建模算法大致经历了三种不同的技术范式:
1.1 传统推荐范式的瓶颈
传统推荐范式(即MLR和DLR),侧重于基于手工特征工程和复杂的级联建模结构来预测相似性或排序分数:
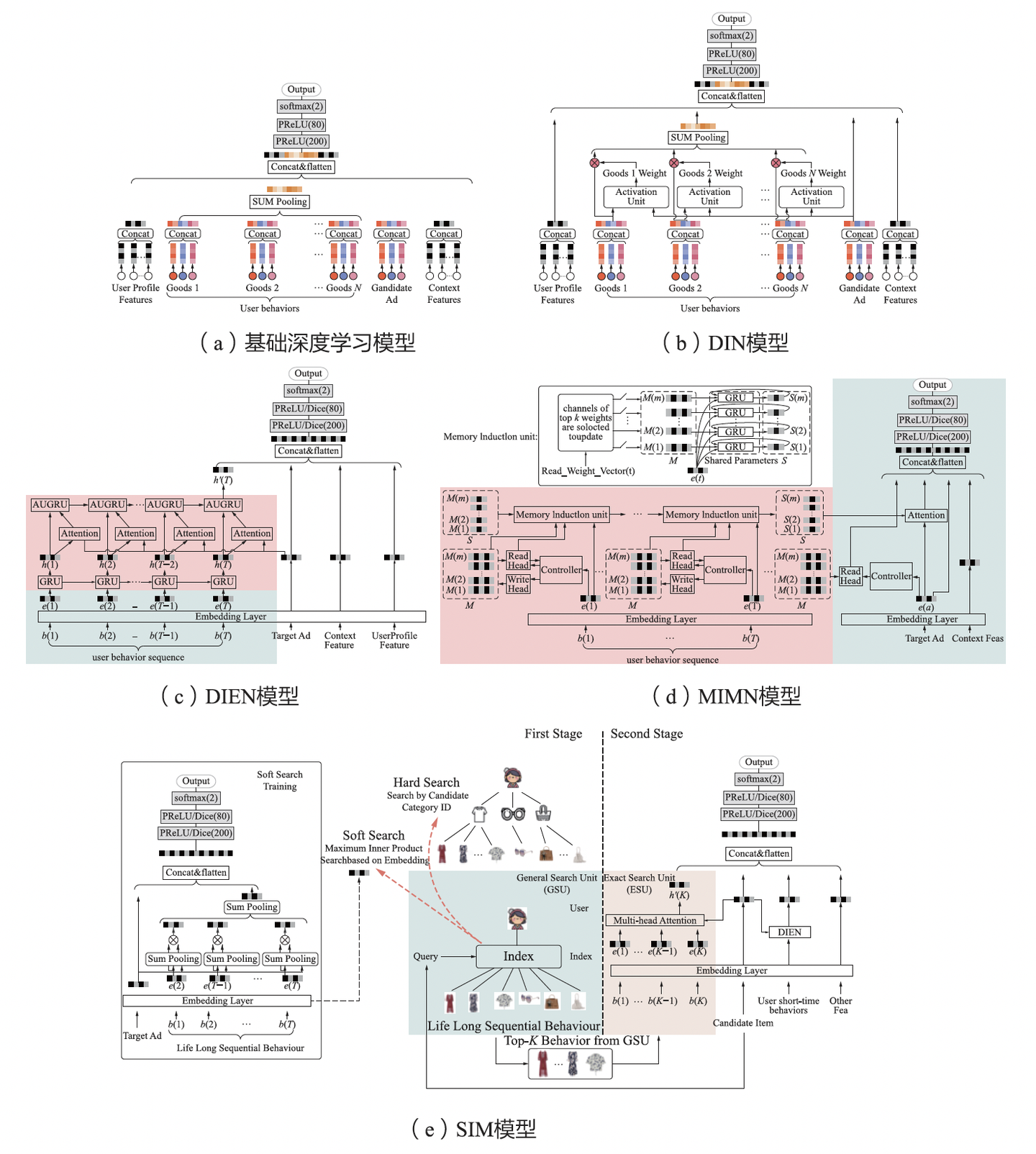
图一:DLRM模型逐渐复杂化
如上图,展示了DLRM模型从简单到复杂的演进:从早期的DWE(Deep Wide and Embedding)模型,到DIN(Deep Interest Network)模型,再到SIM(Search-based user Interest Model)长序列建模,传统推荐对特征和模型结构做了大量迭代和极致挖掘,现阶段暴露了“模型越复杂,优化边际效益越低”的问题,遭遇了明显的增长瓶颈。
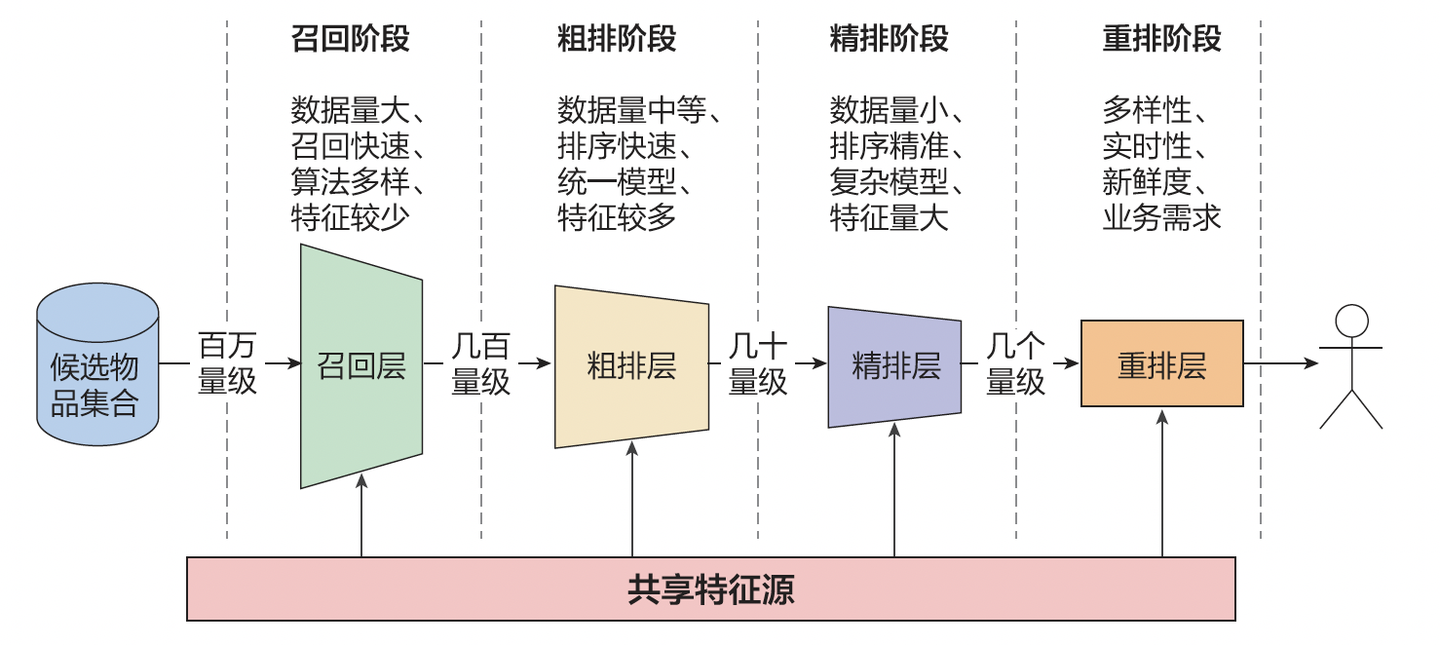
图二:多阶段级联架构
一线算法工程师普遍面临一个困境:简单地增加一些特征或扩大现有模型规模,并不能带来预期的效果提升,模型本身也难以有效“变大”。
分析背后深层次的原因,可以概括成以下几点:
同时系统架构中还发现以下问题:
针对上述问题,大语言模型(LLM)提供了解决问题的新思路。
1.2 LLM的颠覆性潜力
大语言模型(LLM)和视觉语言模型(VLM)等领域已经出现了关键技术突破,如Scaling Law和先进的强化学习(RL)方法等。
大模型研究热点
同时大语言模型的链式推理能力涌现,带来了推荐范式跃迁新契机,可重构推荐系统的“推理逻辑”:
范式变革的本质:从“预测相似性”到“推理用户需求”,LLM可让推荐系统具备推理与创造能力。
1.3 为什么是现在?
生成式推荐在2025年迎来爆发并非偶然,而是LLM技术成熟度与推荐工业场景需求共振的结果。
1、LLM生态成熟
京东自研大模型推理引擎xLLM优化: https://aicon.infoq.cn/2025/beijing/presentation/6530 xLLM已经开源, https://github.com/jd-opensource/xllm/,敬请关注!
2、工业级验证
在过去一年中,Scaling Law在推荐场景的验证打破了传统DLRM的性能天花板,各种GRs系统在实际工业场景中取得了较好的线上效果提升,验证了商业价值。这其中包括Meta GR、美团MTGR、百度COBRA、字节RankMixer和快手OneRec等公司的工作,
工业届落地: 召回: Google TIGER [2023.5]:https://arxiv.org/pdf/2305.05065 Meta LIGER [2024.11]:https://arxiv.org/pdf/2411.18814 百度 COBRA [2025.3]:https://arxiv.org/pdf/2503.02453v1排序: Meta GR [2024.2]:https://arxiv.org/pdf/2402.17152 美团MTGR [2025.5]:https://zhuanlan.zhihu.com/p/1906722156563394693 百度GRAB [2025.5]:https://mp.weixin.qq.com/s/mT8DmHzgc3ag57PVMqZ3Rw 字节RankMixer [2025.7]:https://www.arxiv.org/abs/2507.15551端到端生成: OneRec Technical Report [2025.6]:https://arxiv.org/abs/2506.13695 (2月份初版:https://arxiv.org/abs/2502.18965) 美团EGA-v2 [2025.5]:https://arxiv.org/abs/2505.17549
迎来爆发的前提本质是生产力的跃迁,LLM能同时解决效果、效率和冷启动三大难题,为传统架构升级提供了新方案。
二、技术演进:从模块化到端到端的生成式架构
2.1 LLM4Rec:技术探索前夜
LLM爆火伊始,学术界和工业届便有不少尝试和探索:
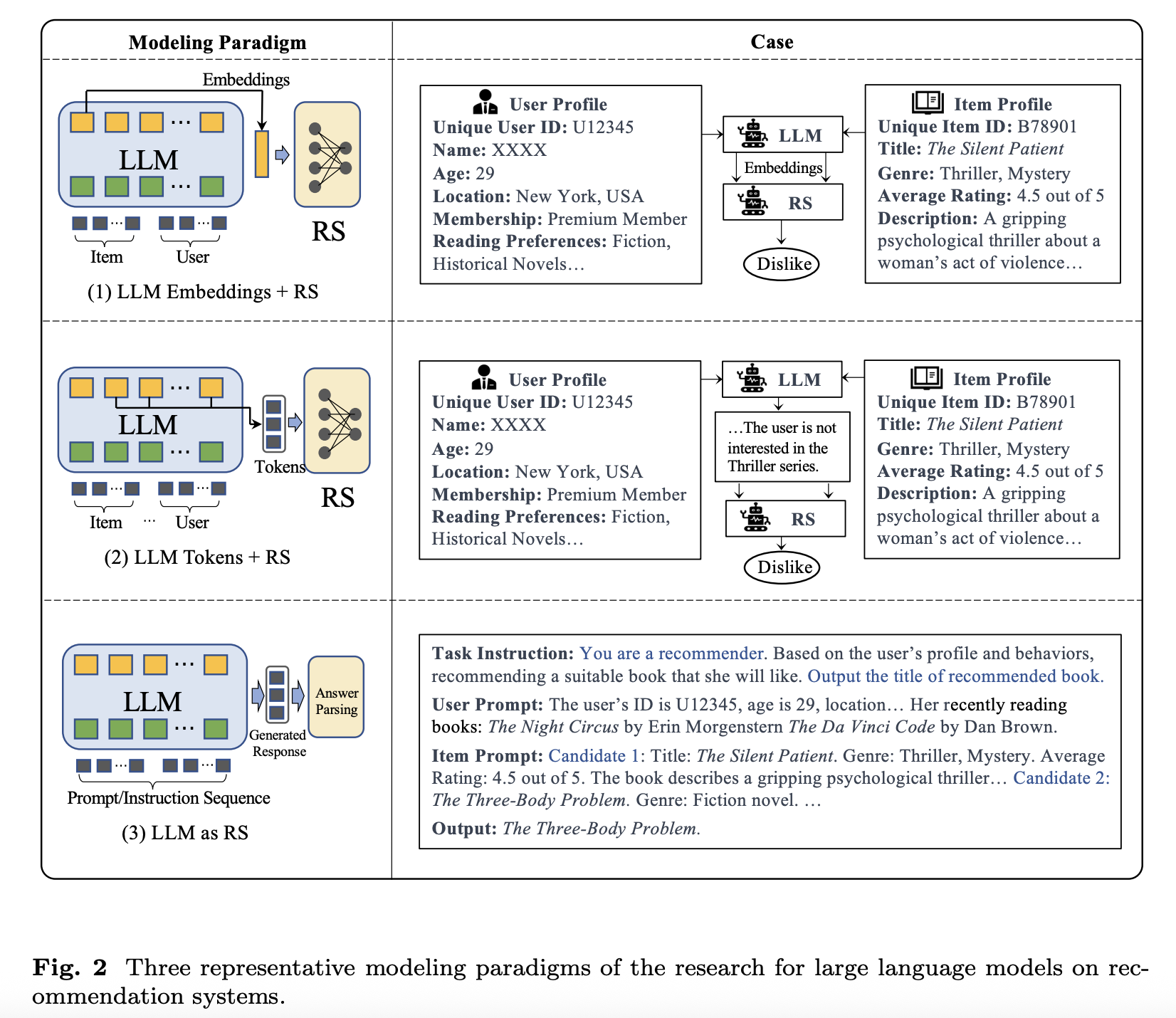
reference: 《A Survey on Large Language Models for Recommendation》
总的来说有三种探索范式:
1、LLM Embeddings + RS
2、LLM Tokens + RS
3、LLM as RS
小结:探索落地主要集中在离线链路的预加工任务,未对推荐系统(RS)的在线链路产生实质影响。 范式3(LLM as RS)直接引入原生LLM的成本过高,实际落地难度大。
2.2 生成式推荐Online应用范式
LLM4Rec之后,最近半年在线链路GRs的应用落地如雨后春笋,目前业界主流有两大类方式:
1、与传统级联系统的相应模块协作或模块替换
2、直接应用生成模型进行端到端推荐
本文后续章节将结合核心技术要点,对几个开山代表作Paper做简要介绍。
2.3 GRs核心技术要点:抽丝剥茧
2.3.1 判别式->生成式的转变
2.3.1.1 什么是生成式推荐?
判别式推荐:
生成式推荐:
总的来说,判别式推荐是封闭式的,从圈定的候选集合中去排序,产生用户喜欢的物品列表。而生成式推荐是开放式的,无中生有的生成用户喜欢的物品列表。
那么,“无中生有”的生成具体是怎么做的呢?
2.3.1.2 Google TIGER:召回阶段用自回归生成式模型
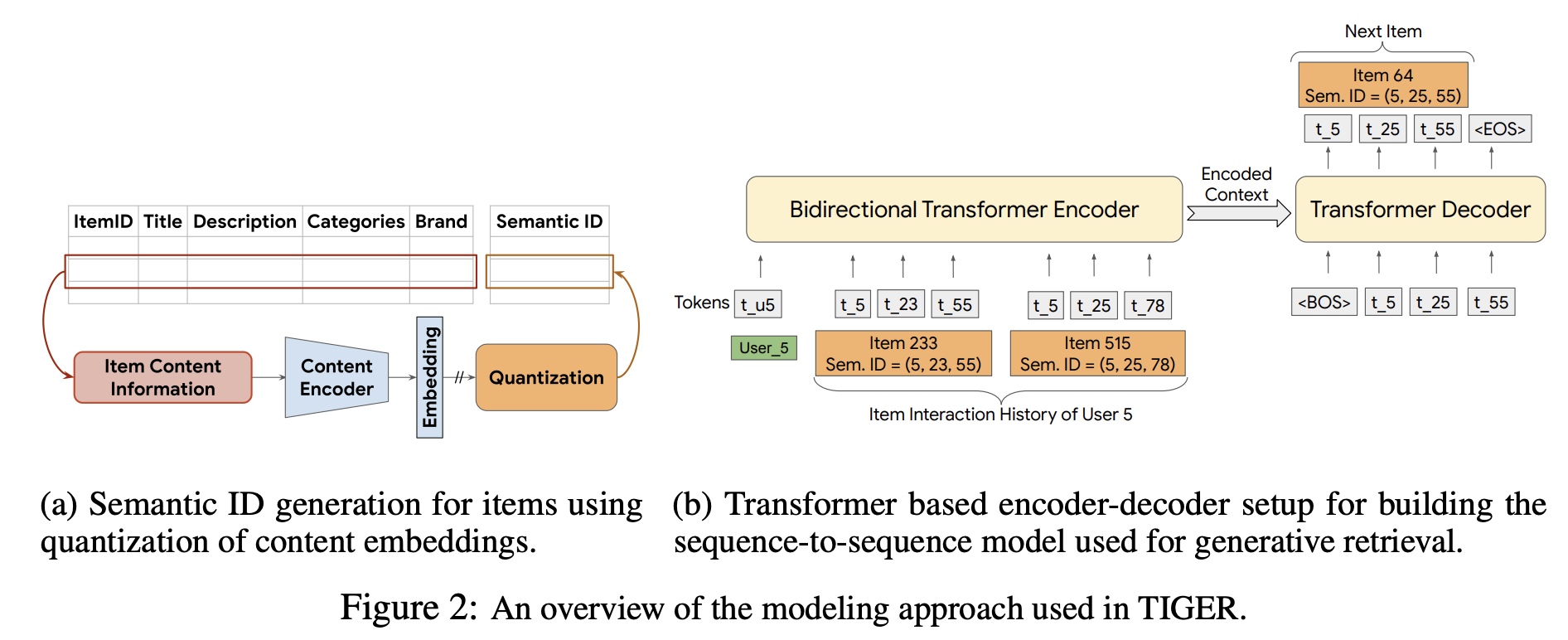
核心价值:首次将自回归生成引入召回阶段,通过语义 ID 压缩 Item 空间,为生成式推荐提供了“无中生有”的技术范式。 局限性:仅适用于召回阶段,未解决精排与重排的端到端问题。 Paper:《Recommender Systems with Generative Retrieval》
作者借鉴LLM的模型结构以及自回归生成的方法,以自回归方式直接预测标识下一个item的编码词组,因此它被视为生成式检索模型。
词嵌入(Vocab Embedding):以LLM为例,词嵌入规模即所有Token ID大小(与英文单词有对应关系,约15万规模)。
“无中生有”的生成过程本质是与整个词嵌入计算概率分布,再根据概率取Top。
2.3.1.3 Meta GR:精排阶段发现Scaling Law
核心价值:验证了推荐场景的 Scaling Law,在特征构建、模型结构和训练方法上采用了生成式模型的理念和方法论,推动生成式推荐向精排阶段渗透。 局限性:特征工程简化过度导致复现难度高,需结合传统 DLRM 特征才能提升效果。另外它是精排模型的替换升级,并非端到端直接生成推荐结果。 Paper:《Actions Speak Louder than Words: Trillion-Parameter Sequential Transducers for Generative Recommendations》
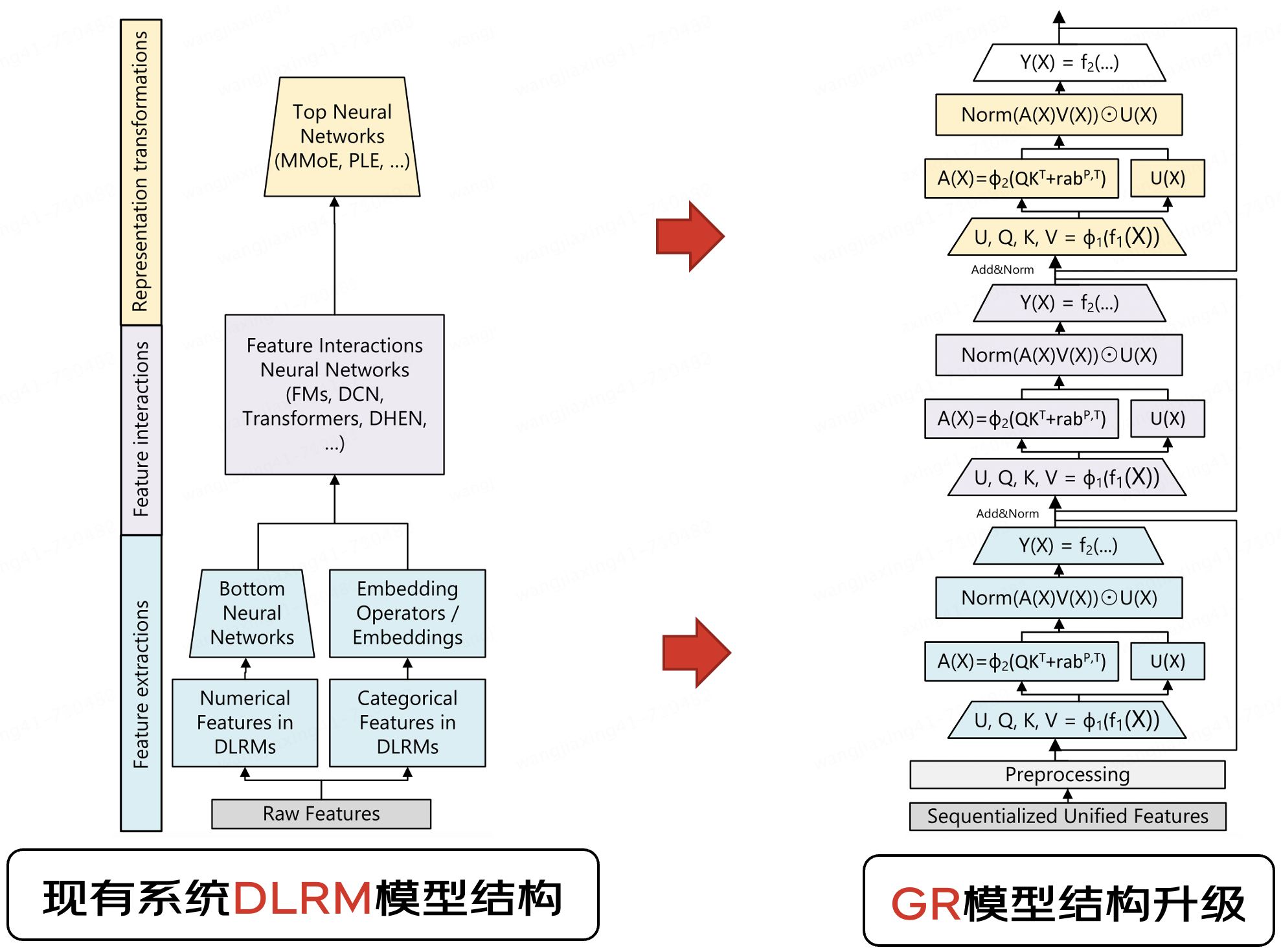
Meta GR模型结构创新HSTU
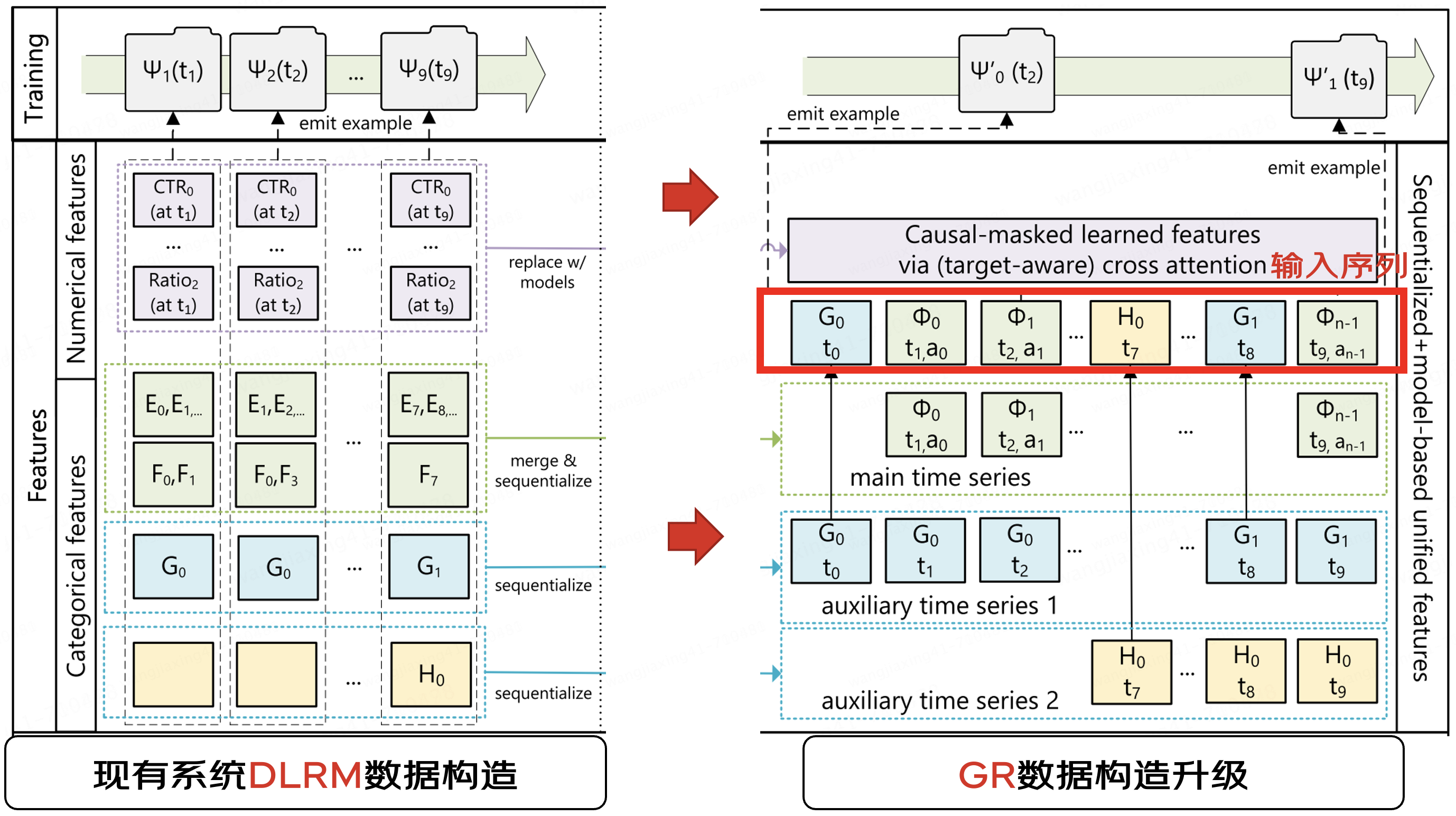
Meta GR特征设计
2.3.2 基于语义ID的生成:压缩Item空间,提升泛化性与生成效率
自Google TIGER提出后, 基于语义ID(Semantic ID)方式的生成式推荐就成为了近两年的研究热点,各大公司也提出了不少优化方案,例如百度的COBRA、快手的OneRec等都使用了语义ID的方案,并做了微创新。
1、为什么语义ID这么受青睐?
前文提到自回归生成过程需与整个Vocab Embedding进行 Logits 计算。当前大语言模型(如Qwen3,多国语言)的Vocab Embedding大小约为 15 万 Token。若将生成计算依赖的全库Vocab Embedding替换为京东的40亿商品,
因此,要实现高效的商品“无中生有”式生成,必须压缩Vocab Embedding规模。
语义ID(Semantic ID)通过将十亿级稀疏Item ID抽象、归纳为更高层的万级别语义表示,实现了Vocab Embedding规模的显著压缩,其核心目的有二:
(1)大幅减少稀疏参数规模、降低过拟合风险:将item参数体量与传统LLM的Vocab Embedding对齐至同一量级(从40亿压缩到万级),有效降低过拟合风险,结合多模态提取item语义ID,提升模型泛化能力;
(2)支持高效生成式范式:语义ID即Token的总量可控(万级别),不仅支撑生成式训练,更能实现高效的生成推理。通过语义ID将Item空间从40亿压缩至万级,使自回归生成的logits计算开销降低 99.9%。
2、语义ID的生成过程
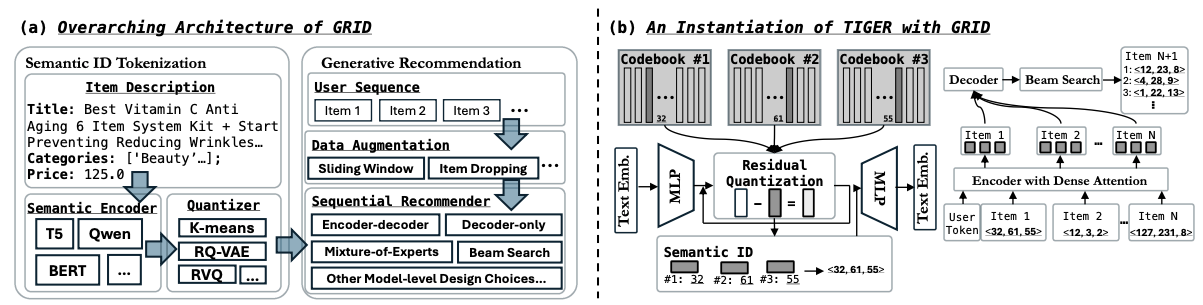
基于语义ID的生成式推荐过程
如上图所示,基于语义ID的生成式推荐主要分为两个阶段:
1)Item提取Embedding,再量化成语义ID
使用预训练LLM/LVM(文本、图像多模态)对Item提取Embedding之后, 业界最常用以下两种量化方式来提取语义ID:
语义ID提取完成后,每个item会被表示为类似<32, 61, 55>的三元组,该三元组与item一一对应。
2)Next语义ID生成预测
基于Beam Search的自回归生成方式,可生成多个Semantic ID三元组(如<12, 23, 8>、<4, 28, 9>等)。实际在生成阶段可能会遇到“模型幻觉”问题,并不是所有的三元组都能映射成真实的item_id,需要边生成边做有效性过滤。
2.3.3 稀疏特征依然很重要
生成式模型结构以及基于Semantic语义ID的自回归生成提供了很好的范式,但输入信号表达上很快发现了瓶颈。
1、Meta GR效果难以复现
分析原因是对特征工程简化太厉害,只保留了行为序列item id和action,其余dense特征、item side info等特征全部删除,导致输入信号表达有限。
美团MTGR基于Meta GR基础上,保留了全部DLRM原始特征,线上效果有大幅提升。
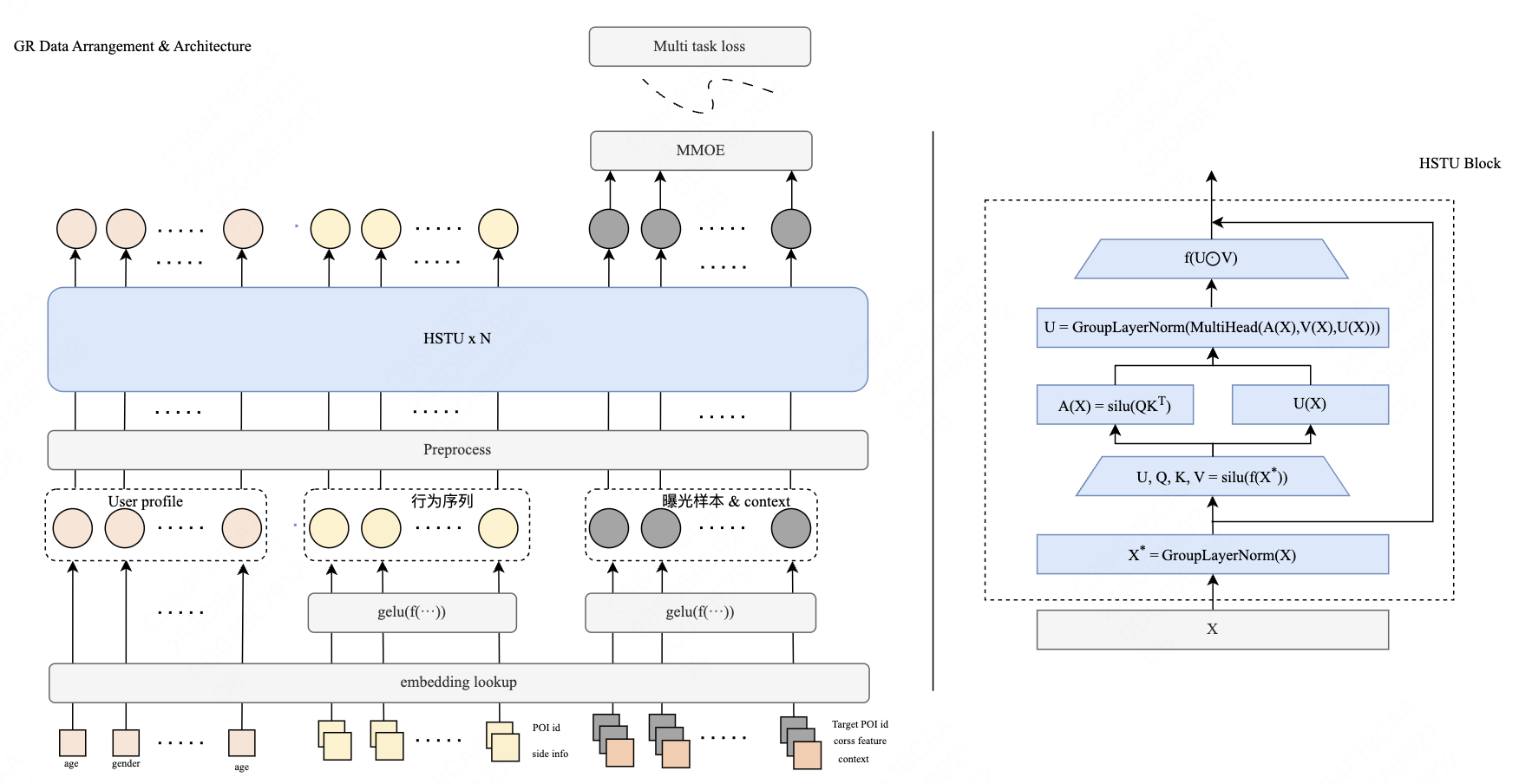
MTGR模型架构图
2、快手OneRec在最新技术方案里也加上了稀疏特征
OneRec 2月份技术方案( https://arxiv.org/pdf/2502.18965 )模型输入为Semantic ID序列(与TIGER一致,由用户行为序列item id转化而来),而四个月后,OneRec Technical Report和OneRec V2方案输入已改为稀疏ID特征,主要原因还是Semantic ID的表达能力有限。
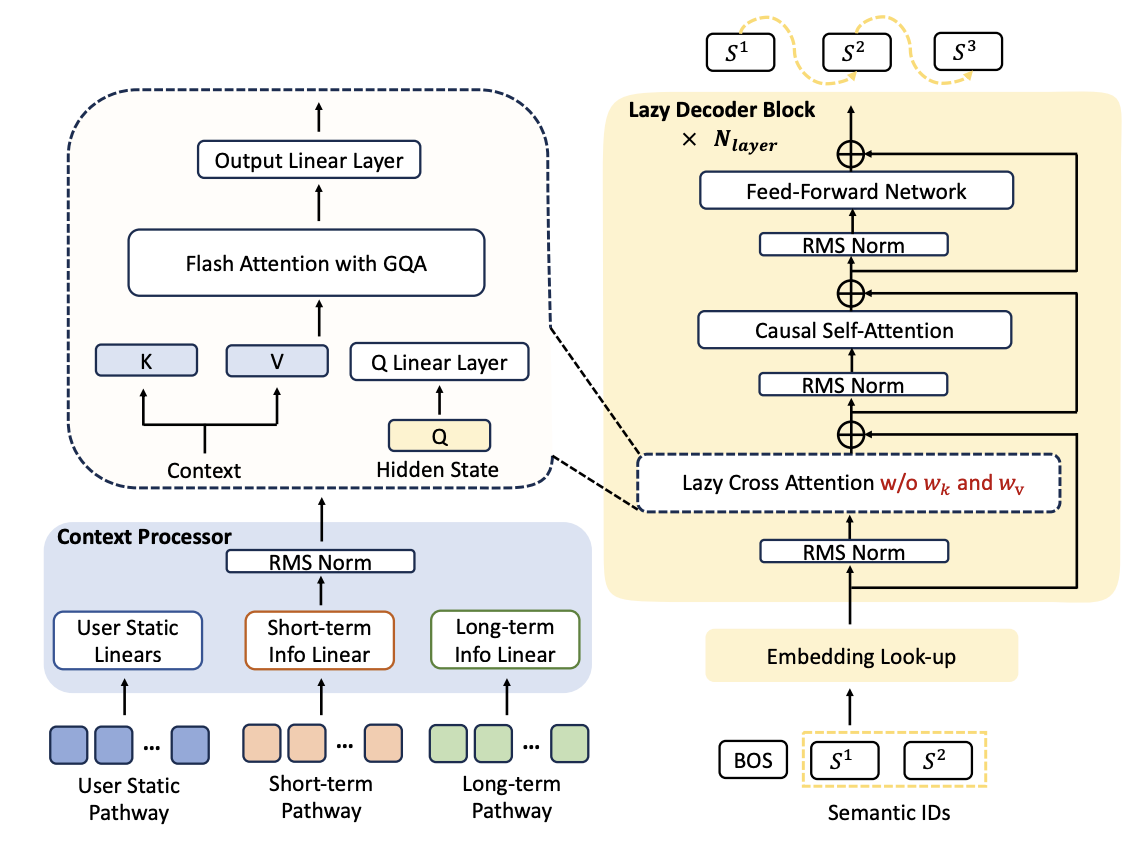
OneRec V2技术架构
OneRec沿用了Encoder-Decoder结构,相较于Google TIGER原生方案,主要异同点如下:
需要注意的是OneRec V2模型架构换称“Lazy Decoder-Only”,在笔者看来仍然是Encoder-Decoder结构,只是Encoder部分去掉了双向Attention变简单了,用户行为序列还需要与CrossAttention结合,这个是与LLM Decoder-Only最关键的区别。
从工程视角看,
2.3.4 Encoder-Decoder vs Decoder-Only
目前基于Next Token预测的生成式模型架构主要分为两类:
在当前阶段,Encoder-Decoder架构在推荐系统中处理长用户行为序列以编码用户兴趣的任务上效果可能更优(注:目前尚缺消融实验对比,结论将持续更新)。相比于LLM Decoder-Only架构,Decoder采用Fully Visible Cross Attention,核心在于关联用户兴趣与候选Item。其计算复杂度显著低于自注意力,有效降低了长序列建模的资源消耗与推理时延,是实现高性能推荐的关键设计。
不过Decoder-Only架构在LLM大语言建模上取得了巨大成功,基于开源模型做微调天然可保留“世界知识”的能力,同时随着GRs模型规模的持续扩大和训练数据的积累,其在推荐领域的潜力仍需密切关注和探索。
三、工程攻坚:主要考量和挑战
作为推荐领域的新范式,GRs在工业应用中面临诸多挑战。
3.1 模型的演变驱动工程架构升级
3.1.1 LLM/DLRM/GRs异同点
| DLRM传统推荐模型 | LLM大语言模型 | GRs生成式推荐模型 | |
| Feature Engineering | ID化、分桶、交叉组合统计特征... | ❌ | ✅ 稀疏长序列建模,需求与特性同DLRM |
| ❌ | Tokenizer,token字符到token id的转换 | ✅ Tokenizer/DeTokenizer,原始用户行为序列与Semantic ID(int)的转换 | |
| Feature Store | 100G~10T量级,用户属性、用户行为序列、商品信息等 | ❌ | ✅ 行为序列特征,量级同DLRM |
| ❌ | Tokenizer词表,M级别 | ✅ Tokenizer词表,用户序列Item ID与Semantic ID的KV映射,量级十GB级 | |
| Embedding | 稀疏ID Embedding:10G~1TB级大规模稀疏参数 | ❌ | ✅ 稀疏ID同DLRM |
| ❌ | Vocab Embedding(即Token Embedding): <10G | ✅ Semantic ID(Vocab Embedding)大小基本同LLM,GB级大小 | |
| Model | 复杂模型结构: DNN+Attention等变种结合; Dense大小几十M | ❌ | ✅ 行为序列建模同DLRM |
| ❌ | Transformer为主体,模型结构收敛; Dense参数量1B~1T | ✅ Dense Transformer/HSTU等,Dense大小0.1B~10B | |
| 生成方式 | Point-wise Scoring | Autoregressive generation | Autoregressive generation |
从上述归纳表格可以看到,在特征抽取、特征存储、Embedding规模以及Dense模型复杂度以及结果生成方式等角度,GRs融合了DRLM的稀疏处理和LLM的稠密生成特性,这使得AI Infra工程实现面临独特的复杂性和资源挑战。
3.1.2 生成式推荐GRs的发展趋势
结合以上特点,我们大胆地对生成式推荐GRs的发展趋势做了预判,总结成了Dense Scaling Up、Sparse Scaling Up和生成范式三个技术象限,如何在三维技术象限上既要、又要、还要是个亟需解决的技术命题。
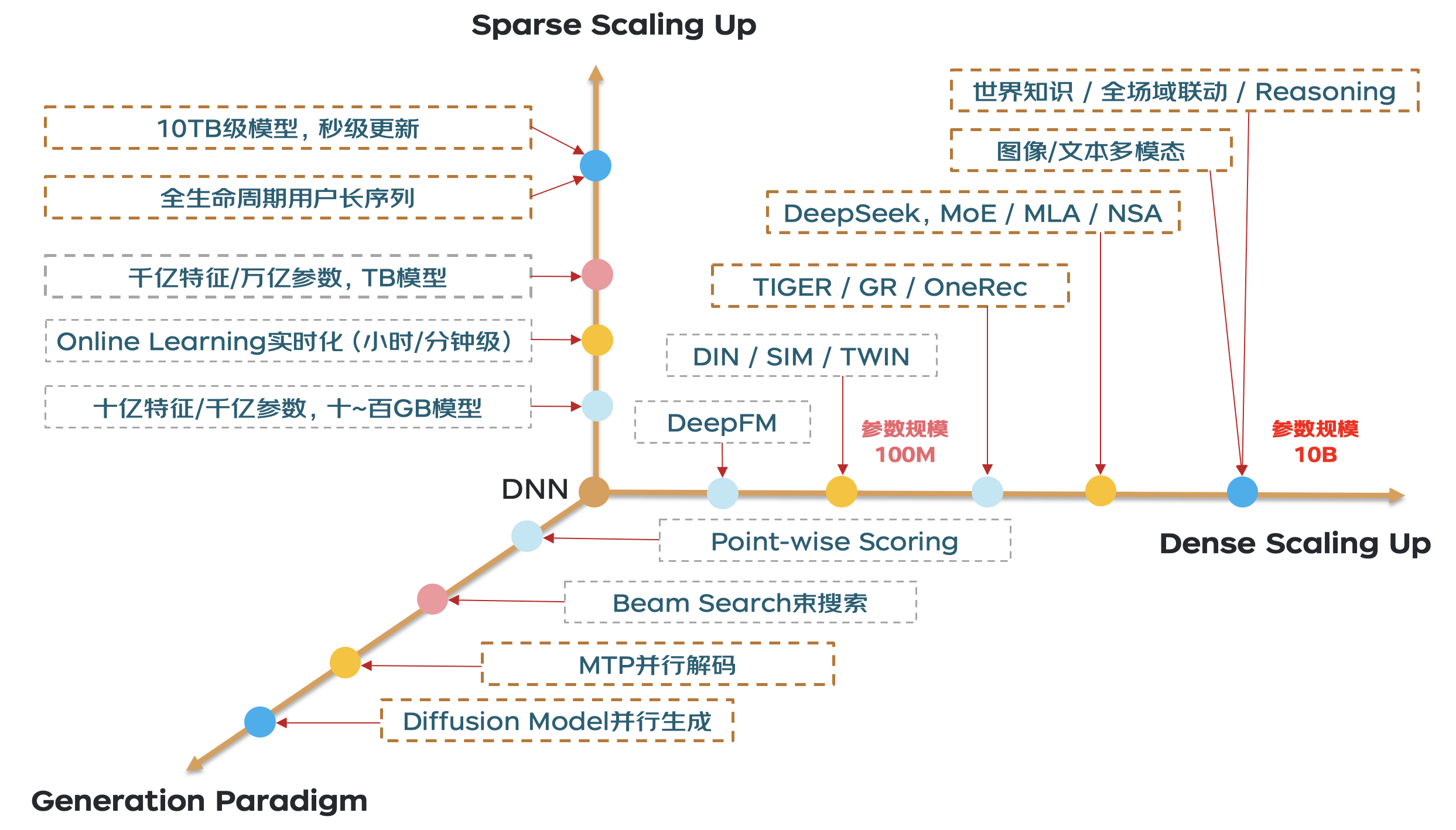
生成式推荐GRs发展趋势研判
(1)Sparse Scaling Up:由于用户序列中的稀疏特征仍然非常重要,生成式推荐系统(GRs)仍需应对大规模稀疏Embedding的分布式扩展与Online Learning在线学习时效性的挑战。在全站全域数据以及全生命周期用户长序列建模的加持下,实现10TB级别Embedding的秒级流式更新,仍是一个值得持续深入探索的技术方向。
(2)Dense Scaling Up:目前传统的DLRM或类似Meta GR的精排模型中,稠密参数规模大多不到百兆,而大语言模型(LLM)已经达到了几百B甚至上T的参数量级。未来若要实现基于世界知识的全场景联动甚至推理能力,必然需要引入图像、文本更多模态,扩大模型参数规模。同时考虑到推理计算资源成本,结合混合专家(MoE)结构达到10B参数规模是一条可行路径。
(3)Generation Paradigm:传统DLRM的输入是预先确定的候选目标(Target),对每个Target与公共的用户/上下文信息进行两两打分,这是一种逐点打分(Point-wise Scoring)范式。当前生成式推荐已采用广度优先的束搜索(Beam Search)生成方式,但这仅是一个起点,束搜索的自回归生成方式调度开销较大,导致生成效率偏低。借鉴大语言模型(如DeepSeek)中的MTP并行解码技术,以及扩散模型(Diffusion Model)的并行生成能力,我们相信未来会出现更高效的并行生成方案。
小结:我们的初衷是工程先行,借鉴大语言模型(LLM)领域的前沿技术能力(如MLA/NSA、MTP/Diffusion等),构建能够同时支持Sparse Scaling Up、Dense Scaling Up以及多种生成范式的高效生成与推理系统。这不仅涵盖若干前沿技术点,更是一条具备高度可行性的技术发展路径!
3.2 训练策略升级:多阶段训练与强化学习
3.2.1 TensorFlow到PyTorch的技术栈转变
传统DLRM模型的训练与推理主要基于TensorFlow技术栈,而LLM模型则普遍采用PyTorch技术栈,其在低精度量化、FlashAttention加速、TP/DP/PP等多维分布式并行训练能力建设较为完善。
在生成式推荐的新范式下,Dense模型的训练与推理优化若基于PyTorch技术栈迭代、复用LLM能力,将具有较高的ROI。
理论上这些工作没有可行性风险,但工作量巨大,包括但不限于以下内容:
PyTorch动态图便于离线灵活构图,允许纯Python逻辑与PyTorch代码混合编写,但在线推理无法执行Python代码,因此必须从离线导出仅包含原生PyTorch OP表达的静态图(类似于TensorFlow)。如何有效约束算法逻辑,以及如何高效、自动化地导出原生计算图,是务必解决的关键问题。
3.2.2 多阶段联合训练与强化学习
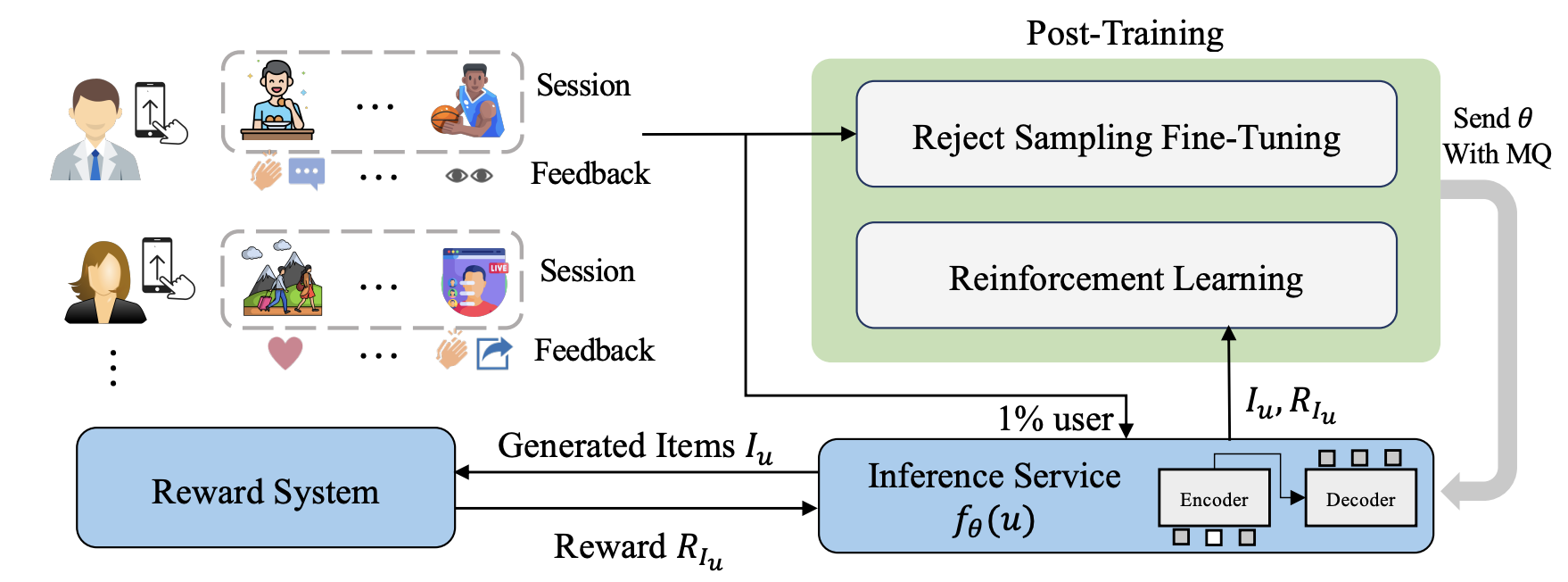
The overall process of GRs post-training
GRs 的核心问题在于如何设计训练方法和目标以适配推荐任务,需要从传统的单阶段训练,跃迁式的往多阶段训练模式升级。
单阶段训练:模型在一个阶段完成推荐任务, 通常专注于召回或排序。
多阶段训练:分为预训练和微调两阶段。根据微调方式不同,又分为:
这些训练模式、解决方案的升级,极大的增加了离线链路的复杂性。
3.3 推理性能瓶颈:工业级在线的百毫秒级生死线
推荐系统在线链路时延要求较高,通常全链路在百毫秒级别要求,同时用户流量在几万~几十万QPS。伴随LLMs复杂架构带来的是推理时延和资源成本的增加,这是GRs落地的极大挑战和阻碍。
生成式推荐在线架构示意
3.3.1 用户行为序列的高效生产、存储与查询
用户行为序列(如浏览、点击、收藏、加工等时序事件)是生成式推荐范式的核心驱动数据,相比于传统推荐,生成式推荐由于去掉了很多item相关的特征,这使得用户行为数据的重要性成为核中核。
在新范式下,
为实现上述目标,对数据时序保证、毫秒级时效性、通信数据量、存储资源量等都提出了较大的挑战。
3.3.2 生成式推理优化
尽管可借鉴 LLM 的成熟经验,但在训练和推理环节仍需大量结合特定场景和模型结构的针对性优化工作,LLM 技术并不是总能开箱即用于 GRs。
目前在深入探索并实践多项关键技术路径:
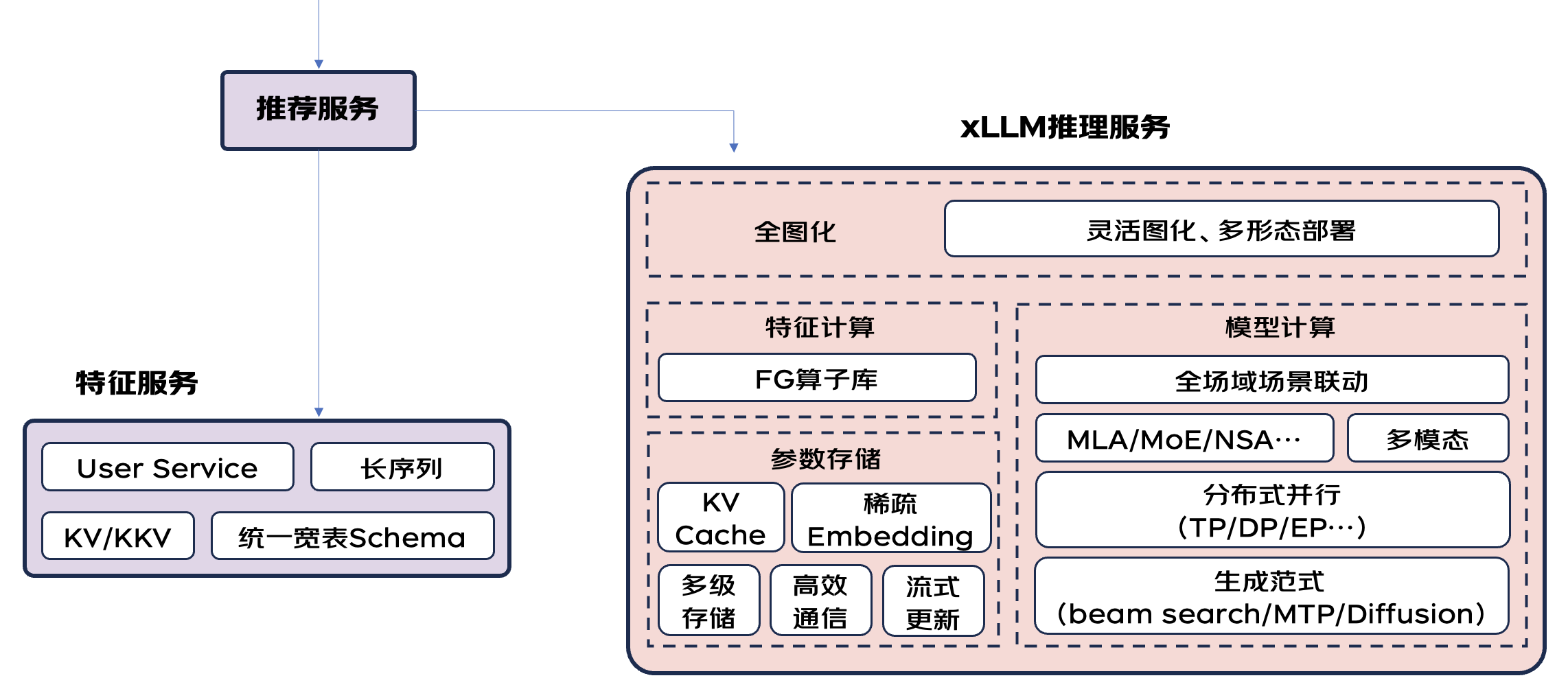
如下图所示,借鉴LLM大模型推理目前在系统、模型和硬件层面的深水区优化工作和进展,生成式推荐GRs也是如此:未来的核心优化技术手段,都需要深刻理解业务场景、深入理解模型结构,挖掘场景、模型和硬件的性能极限。
LLM大模型推理核心优化方向
限于篇幅原因,未来会将更多的工程实现解密,与大家分享这一路以来的优秀工程优化实践经验。
四、未来方向
未来GRs的探索将聚焦于以下几个前沿方向:
五、结语:技术拐点已至
生成式推荐并非简单的渐进式优化,而是推荐系统的一次认知升维:
未来十年,生成式推荐将重新定义人、货、场的连接方式——这要求我们在算法创新、工程实践与业务洞察上持续突破,共同打造推荐系统智能化的新纪元。
附录参考:
https://aicon.infoq.cn/2025/beijing/presentation/6530
https://arxiv.org/abs/2506.13695
https://arxiv.org/pdf/2305.05065
https://arxiv.org/abs/2507.06507
https://arxiv.org/abs/2503.02453
https://arxiv.org/abs/2402.17152
https://mp.weixin.qq.com/s/eS01m0pam0boYC4WQdZ-lA
https://zhuanlan.zhihu.com/p/1906722156563394693
https://zhuanlan.zhihu.com/p/1918350919508140128
https://mp.weixin.qq.com/s/mT8DmHzgc3ag57PVMqZ3Rw
https://www.arxiv.org/abs/2507.15551