📘今日学习总结
一、语言模型基础能力的建立:预训练
1.1 预训练的核心思想
- 目标:通过大规模无监督文本学习语言表示。
- 方式:
- 自回归预测下一个词:
\[\mathcal{L}_{\text{LM}}(\mathbf{u}) = \sum_{t=1}^{T} \log P(u_t \mid \mathbf{u}_{<t}) \]- 使用自然语言指令(prompt)引导模型完成任务。
1.2 多任务学习
- 形式:\(Pr(output∣input,task)\)
- 痛点:任务形式多样,难以统一。
- 解决方案:将所有任务转化为自然语言生成问题,统一为文本预测任务。
1.3 无监督预训练为何有效?
- 预训练建模的是更大空间的文本生成任务 \(Pr(postfix∣prefix)\)
- 随着数据变化,模型学习多种“任务”,如:
- 内容补全、数学计算、情感分析、语义推理、知识补全等。
二、预训练数据工程
核心观点:当模型架构与训练方式固定后,数据工程成为关键。
2.1数据采集
2.1.1 采集途径
- 已有数据集:如 RefinedWeb、DCLM、Dolma。
- Common Crawl:
- 大规模网页爬取数据。
- 可按查询、域名、规则过滤子集。
- 合成数据:
- 使用模型生成文本(如问答对、文档)。
- 案例:Phi-1、Nemotron-4、WizardLLM 系列。
2.1.2 数据类型
- 通用文本:网页、书籍(C4、Wikipedia、Books3)
- 专用文本:
- 多语文本:提升多语言理解
- 科学文本:arXiv、教材
- 代码:GitHub、Stack Exchange
2.2 数据预处理
2.2.1 预处理流程
- 数据采集 → 质量过滤 → 去重 → 隐私保护 → 词元化
2.2.2 质量过滤方法
- 启发式规则:
- 语种识别、标点分布、句子长度、点赞数、困惑度等。
- 关键词过滤:
- 过滤HTML标签、垃圾词汇、隐私信息等。
- 分类器过滤:
- 训练文本分类器判别质量,可集成多个分类器。
2.2.3 敏感内容过滤
- 过滤PII(如电话、邮箱、IP)
- 防止模型泄露隐私
2.2.4 数据去重
- 粒度:句子级、文档级、数据集级
- 方法:
- 精确匹配(后缀数组)
- 近似匹配(MinHash)
2.2.5 数据集污染
- 训练数据与测试数据重叠会导致评估失真
- 建议开发者和基准维护者检查数据重叠
2.3 词元化(分词)
2.3.1 传统分词问题
- 分词歧义、低频词多、未登录词问题
2.3.2 子词分词方法
- BPE(Byte Pair Encoding):
- 从字符开始,迭代合并高频词对
- WordPiece:
- 类似BPE,但基于语言模型评分选择合并
- Unigram:
- 从大词表开始,迭代删除最不重要的词元
2.3.3 分词器选用原则
- 无损重构
- 高压缩率
- 适应领域:如中文需扩词表,数字需统一分词方式
2.4 数据配比
2.4.1 数据规模定律
- KM Scaling Law:模型规模与数据规模同步增长
- Chinchilla Scaling Law:建议更多算力分配给数据(约20:1)
2.4.2 配比策略
- 增加多样性:多源异构数据
- 优化混合:学习最优数据组成
- 增强特定能力:如增加代码数据提升编程能力
2.4.4 自动化配比方法
- DoReMi:
- 使用代理模型优化领域权重
- 最小化最坏情况损失
- 数据配比定律:
- 预测不同混合比例下的性能,提前优化配比
2.5 数据课程
2.5.1 定义
- 按特定顺序或分布安排训练数据,动态调整数据混合
2.5.2 示例
| 模型 | 数据课程 |
|---|---|
| CodeLLaMA | 2T 通用词元 → 500B 代码密集型词元 |
| CodeLLaMA-Python(Python化) | 2T 通用词元 → 500B 代码相关词元 → 100B Python 代码相关词元 |
| Llemma(数学化) | 2T 通用词元 → 500B 代码相关词元 → 50∼200B 数学相关词 元 |
2.5.3 动态批次配比
- 类似DoReMi,逐批次优化数据配比
- 粒度更细,提升训练效率
三、继续预训练
3.1 定义与用途
- 定义:在已有预训练模型基础上,使用新数据进一步训练。
- 用途:
- 英文转多语(如 Llama 3 中文化)
- 通用转专用(如 CodeLlama、长文本扩展)
3.2 挑战:灾难性遗忘
- 现象:新训练损害原有能力(如英文能力下降)
- 原因:
- 参数已收敛,新数据分布不同
- 新数据质量或适配性不佳
3.3 解决方案
- 合成高质量数据:增强中英文数理能力
- 设计数据课程:保持原有能力的同时引入新知识
3.4 面向特定学科的数据合成
3.4.1 流程
- 种子语料筛选:从网页数据中提取科学相关语料(如 StackExchange)
- Prompt 设计:基于种子语料生成问答对
- 小模型合成:降低推理成本
3.4.2 示例:科学问答合成
- 输入:网页片段
- 输出:结构化问答对(Problem + Solution)
3.5 Llama3-SynE 案例
3.5.1 数据配比
| 数据类型 | 中 | 英 | 词元数 |
|---|---|---|---|
| 网页 | ✓ | ✓ | 45.18B |
| 百科全书/图书 | ✓ | ✓ | 4.92B |
| 问答 | ✓ | ✓ | 15.74B |
| 学术论文/数学语料/代码 | X | ✓ | 4.92B |
| 合成数据 | X | ✓ | 7.93B |
| 总计 | 100B |
3.5.2 数据课程(粗粒度)
- 阶段1:双语适配
- 中:英 = 2:8
- 按 PPL 排序
- 阶段2:合成增强
- 中:英:合成 = 1:7:2
3.5.3 数据课程(细粒度)
- PPL 动态调整:
- 计算每类 PPL 变化
- 动态调整采样比例
- 合成数据阶段:随机采样,不排序
3.5.4 评测结果
- 中文、数学、科学能力显著提升
- 英文能力基本保持
3.6 YuLan-Mini 案例
3.6.1 模型特点
- 2.4B 参数,1.08T 高质量词元
- 数据全开放,流程高效
3.6.2 数据策略
- 严格过滤:去重、质量打分、主题分类、去污染
- 合成数据:数学、代码、科学三大类
- 数据课程:三段式训练
- 热身(10B)
- 稳定(990B)
- 退火(80B)
3.6.3 退火训练
- 引入高质量数据、长文本、指令数据
- 学习率逐步衰减
3.6.4 评测结果
- 在多项基准(MATH, MBPP, MMLU 等)上表现优异
- 训练效率高,数据使用高效
四、训练优化技术
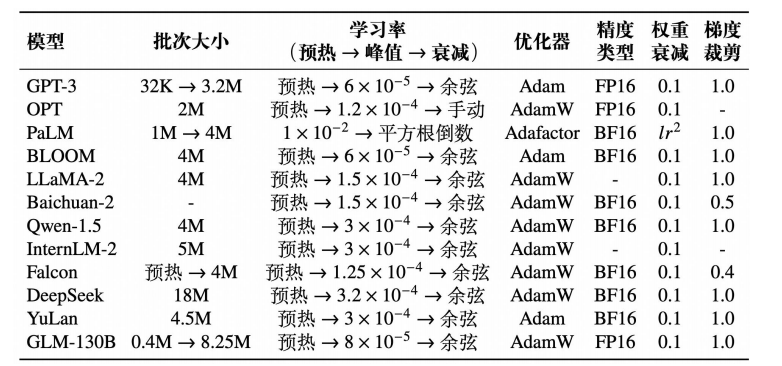
4.1 优化器设置
4.2 3D 并行训练
- 数据并行:复制模型,分数据,合并梯度
- 模型并行:
- 张量并行:参数拆分,多卡计算
- 流水线并行:层拆分,串行计算
4.3 激活重计算
- 前向传播时不保存所有激活值,反向时重新计算
- 显著减少显存占用
4.4 混合精度训练
- 前向/反向:FP16
- 优化器:FP32
- 显存减半,速度提升
五、模型参数量估计
5.1 LLaMA 参数量:
- Transformer 层数 \(L\)
- 隐含层维度 \(H\)
- 中间状态维度 \(H'\)
- 注意力头数 \(N\)
- 上下文窗口长度 \(T\)
- 词表大小 \(V\)
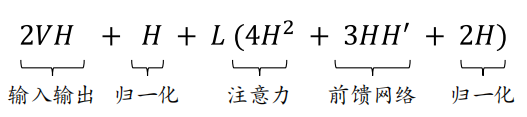
5.2 组成部分:
- 词嵌入层:\(VH\)
- 输出层:\(VH\)
- 归一化层:\((2L+1)H\)
- 注意力层:\(4LH^2\)
- 前馈网络:\(3LHH'\)
5.3 示例:LLaMA 7B
- V=32000,L=32,H=4096,H′=11008V=32000,L=32,H=4096,H′=11008
- 参数量 ≈ 6.74B
5.4训练显存估计
5.4.1 显存组成:
- 模型参数 + 优化器:16P 字节(P 为参数量)
- 激活值:每层输入 + softmax 输入
- 其他:框架、ZeRO、中间结果、碎片
5.4.2 激活值显存:
- 每层输入:\(2BTH\)
- softmax 输入:\(4BTV\)
- 总计:\(2LBTH+12BTV\)
5.4.3 单卡显存公式(使用 ZeRO-3):
