第一题:
核心代码及运行结果
点击查看代码
import requests
from bs4 import BeautifulSoup
import pandas as pd
import redef main():"""主函数 - 包含所有爬虫功能"""url = "http://www.shanghairanking.cn/rankings/bcur/2020"try:response = requests.get(url)response.encoding = 'utf-8'soup = BeautifulSoup(response.text, 'html.parser')# 查找并处理数据ranking_data = []table_rows = soup.find_all('tr')for i, row in enumerate(table_rows[1:], 1): # 跳过表头try:cols = row.find_all('td')if len(cols) >= 4:text = cols[1].get_text(strip=True)match = re.search(r'([^A-Za-z]*(?:大学|学院|学校))', text)university_name = match.group(1).strip() if match else text.split()[0]# 提取其他信息rank = cols[0].get_text(strip=True)province = cols[2].get_text(strip=True)school_type = cols[3].get_text(strip=True)score = cols[4].get_text(strip=True) if len(cols) > 4 else "N/A"if rank and university_name:ranking_data.append({'排名': rank,'学校名称': university_name,'省市': province,'学校类型': school_type,'总分': score})except:continueprint(f"{'排名':<4} {'学校名称':<18} {'省市':<8} {'学校类型':<8} {'总分':<8}")print("-" * 50)for item in ranking_data:print(f"{item['排名']:<4} {item['学校名称']:<16} {item['省市']:<6} {item['学校类型']:<6} {item['总分']:<8}")except Exception as e:print(f"爬取失败: {e}")if __name__ == "__main__":main()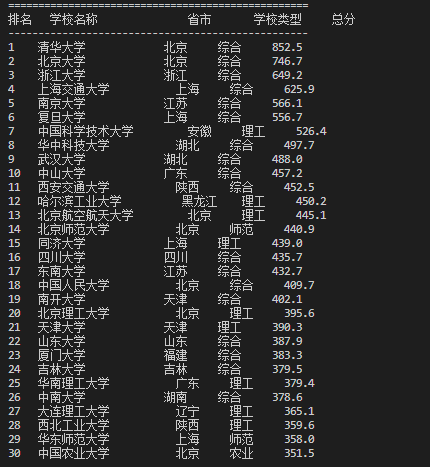
实验心得:
查看网页源代码可见网页结构大体如下
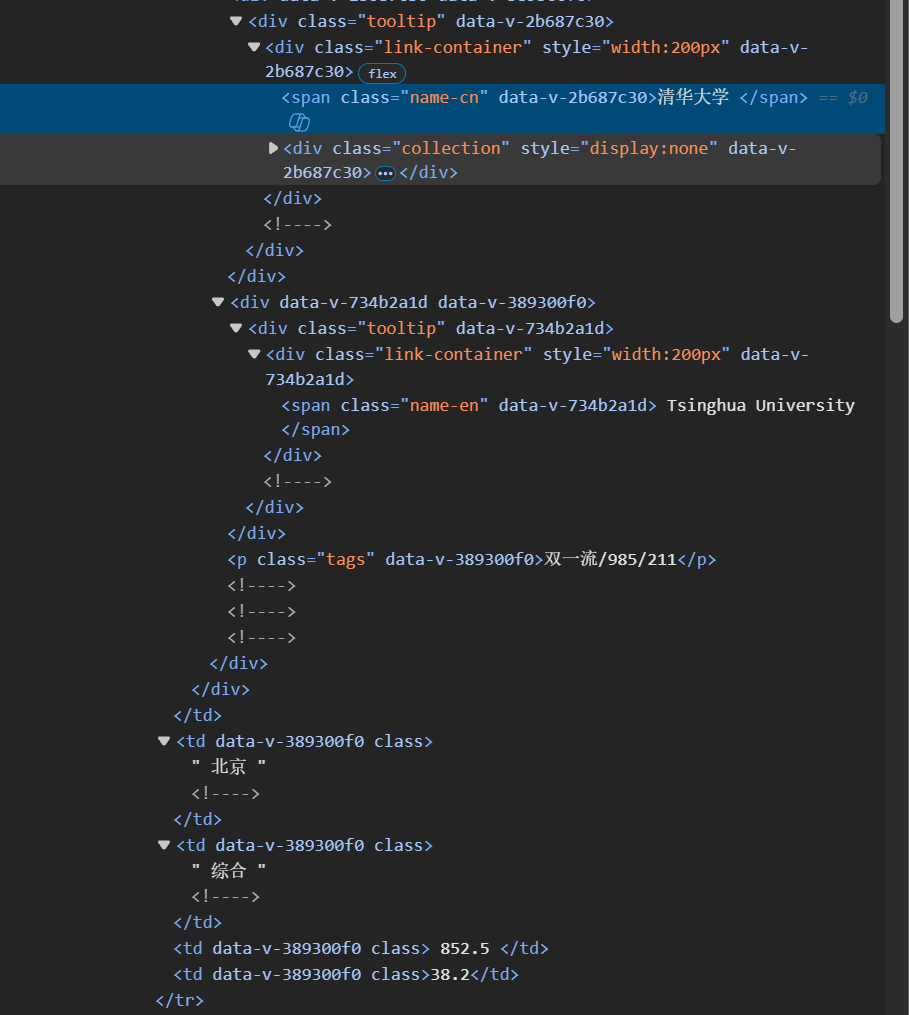
<table><tr> <!-- 表头行 --><th>排名</th><th>学校名称</th><th>省市</th><th>学校类型</th><th>总分</th></tr><tr> <!-- 数据行 --><td>1</td><td><div class="tooltip"><div class="link-container"><span class="name-cn">清华大学</span><span class="name-en">Tsinghua University</span></div><p class="tags">双一流/985/211</p></div></td><td>北京</td><td>综合</td><td>852.5</td></tr><!-- 更多数据行... -->
</table>
步骤分解:
- HTTP请求与网页获取 代码解析:
requests.get(url):获取整个HTML文档response.encoding = 'utf-8':确保中文字符正确解码BeautifulSoup():将HTML字符串转换为可查询的DOM树
- 表格行查找 HTML结构映射:
<table><tr>...</tr> ← 被find_all('tr')找到<tr>...</tr> ← 被find_all('tr')找到<tr>...</tr> ← 被find_all('tr')找到...
</table>
find_all('tr'):查找所有<tr>标签返回一个包含所有表格行的列表包括表头行和数据行
- 跳过表头处理 HTML结构映射:
<tr> <!-- 第0行:表头,被跳过 --><th>排名</th><th>学校名称</th><th>省市</th><th>学校类型</th><th>总分</th>
</tr>
<tr> <!-- 第1行:数据行,开始处理 --><td>1</td><td>清华大学...</td><td>北京</td><td>综合</td><td>852.5</td>
</tr>
- 单元格提取代码解析:
find_all('td'):查找当前行的所有单元格len(cols) >= 4:确保至少有4列数据- 每个
cols[i]对应HTML中的第i个<td>元素
- 提取核心算法 正则表达式详细分析:
输入文本: "清华大学Tsinghua University双一流/985/211"
正则模式: ([^A-Za-z]*(?:大学|学院|学校))匹配过程:
1. [^A-Za-z]* 匹配 "清华" (非英文字符)
2. (?:大学|学院|学校) 匹配 "大学"
3. 捕获组() 捕获 "清华大学"
4. 忽略后面的英文和标识符
- 其他字段提取 HTML结构映射:
<tr><td>1</td> ← rank = cols[0].get_text() = "1"<td>...</td> ← (已处理)<td>北京</td> ← province = cols[2].get_text() = "北京"<td>综合</td> ← school_type = cols[3].get_text() = "综合"<td>852.5</td> ← score = cols[4].get_text() = "852.5"
</tr>
第二题
核心代码及运行结果
点击查看代码
import urllib.request
from bs4 import BeautifulSoup
def main():# 当当网书包搜索页面url = "https://search.dangdang.com/?key=%CA%E9%B0%FC&category_id=10009684#J_tab"# 创建请求对象req = urllib.request.Request(url)response = urllib.request.urlopen(req, timeout=10)html = response.read().decode('gbk')soup = BeautifulSoup(html, 'lxml')# 提取商品信息names = soup.find_all('a', attrs={'class': 'pic', 'name': 'itemlist-picture'})prices = soup.find_all(name='span', class_="price_n")print(f"{'序号':<4} {'价格':<12} {'商品名称'}")print("-" * 80)# 确保名称和价格数量匹配min_count = min(len(names), len(prices))# 输出商品信息for i in range(min_count):name_text = names[i]["title"]price_text = prices[i].text.strip()print(f"{i+1:<4} {price_text:<12} {name_text}")if __name__ == "__main__":main()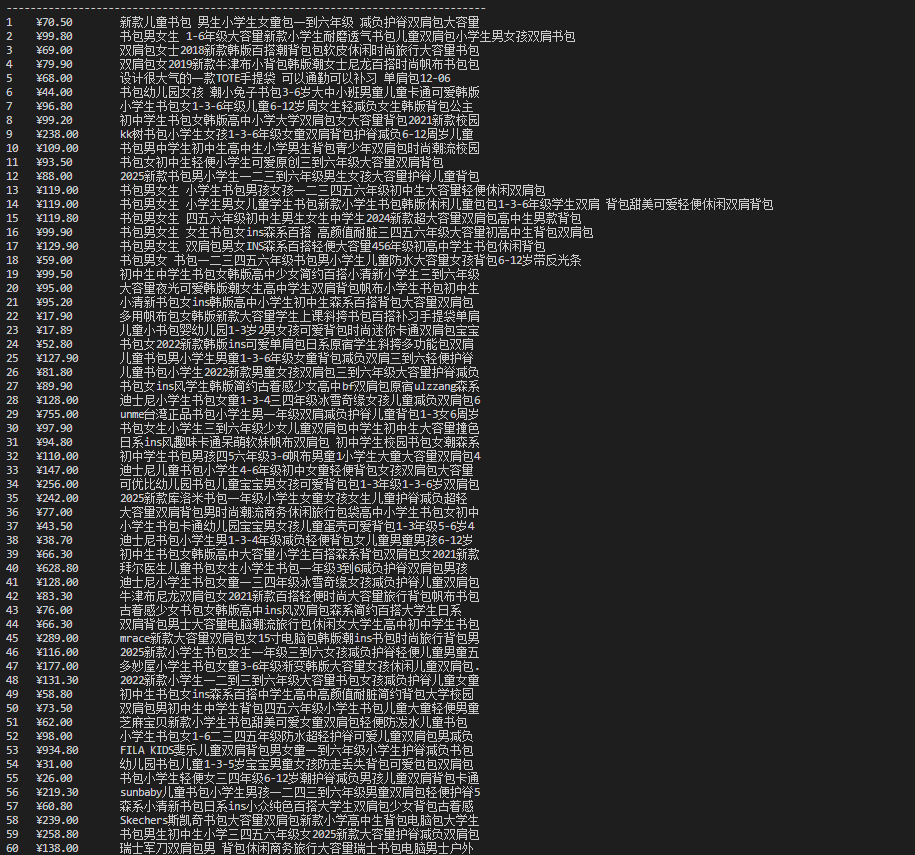
实验心得
由于大网站反爬机制,这里选择爬取当当网,这个爬虫程序采用了"获取-解析-提取-展示"的经典四段式逻辑结构。整个程序的核心思想是模拟人类浏览网页的行为:打开当当网的书包搜索页面,找到页面上的商品信息,然后将这些信息整理成表格形式展示给用户
商品名称提取语法:

- soup.find_all() - BeautifulSoup的核心方法,用于查找所有匹配的元素
- 'a' - 目标HTML标签名(锚点标签)
- attrs={'class': 'pic', 'name': 'itemlist-picture'} - 属性字典,指定元素必须同时具备的属性
商品价格提取语法:

- name='span' - 明确指定标签名为span
- class_="price_n" - 指定CSS类名
第三题
核心代码与运行结果
点击查看代码
import requests
from bs4 import BeautifulSoup
import os
from urllib.parse import urljoin, urlparse
import re
def main():# 目标网页URLurl = "https://news.fzu.edu.cn/yxfd.htm"download_folder = "fzu_news_images"# 获取网页内容response = requests.get(url)response.encoding = response.apparent_encoding or 'utf-8'# 解析HTMLsoup = BeautifulSoup(response.text, 'html.parser')image_urls = set()# 查找所有img标签img_tags = soup.find_all('img')for img in img_tags:src = img.get('src')if src:# 转换为绝对URLabsolute_url = urljoin(url, src)# 检查是否为图片格式if any(ext in absolute_url.lower() for ext in ['.jpg', '.jpeg', '.png']):image_urls.add(absolute_url)print(f"发现 {len(image_urls)} 个图片链接")# 下载图片success_count = 0failed_count = 0for i, image_url in enumerate(image_urls, 1):print(f"[{i}/{len(image_urls)}] {image_url}")# 下载图片img_response = requests.get(image_url, timeout=30)img_response.raise_for_status()# 生成文件名parsed_url = urlparse(image_url)original_filename = os.path.basename(parsed_url.path)# 确保文件名安全safe_filename = re.sub(r'[<>:"/\\|?*]', '_', original_filename)filepath = os.path.join(download_folder, safe_filename)# 保存图片with open(filepath, 'wb') as f:f.write(img_response.content)print(f"下载成功: {safe_filename} ({len(img_response.content)} bytes)")success_count += 1 print("-" * 50)print(f"下载完成!")print(f"总计: {len(image_urls)} 个图片")print(f"成功: {success_count} 个")print(f"失败: {failed_count} 个")print(f"保存位置: {os.path.abspath(download_folder)}")
if __name__ == "__main__":main()
实验心得
在主函数的开始部分,程序定义了两个重要的配置参数。第一个是目标网页的URL地址,这里设置为福州大学新闻网的一个页面,用户,可以根据需要修改这个地址来爬取其他网站的图片。第二个参数是图片保存的本地文件夹名称,设置为"fzu_news_images",程序会自动创建这个文件夹来存储下载的图片文件。
接下来程序开始获取目标网页的内容。使用requests模块的get方法向指定的URL发送HTTP GET请求,服务器返回的响应包含了网页的HTML代码。为了确保中文内容能够正确显示,程序会自动检测网页的字符编码格式。如果服务器响应中包含编码信息,就使用apparent_encoding属性获取的编码,否则默认使用UTF-8编码。这一步骤对于处理包含中文内容的网页非常重要。
获取到网页内容后,程序使用BeautifulSoup库将HTML文本解析成一个可操作的文档对象。BeautifulSoup会自动分析HTML的标签结构,建立一个文档树,使得我们可以方便地查找和提取其中的各种元素。同时,程序创建了一个Python集合(set)来存储发现的图片URL地址。使用集合的好处是可以自动去除重复的URL,避免下载相同的图片文件。


程序从HTML的img标签中提取图片链接。程序使用BeautifulSoup的find_all方法查找网页中所有的img标签,这些标签通常包含网页中直接显示的图片。对于每个找到的img标签,程序会获取其src属性的值,这个属性包含了图片的URL地址。由于网页中的图片链接可能是相对路径(如"images/photo.jpg"),程序使用urljoin函数将这些相对路径转换为完整的绝对URL地址。然后程序会检查这个URL是否包含目标图片格式的扩展名(.jpg、.jpeg或.png),只有符合条件的URL才会被添加到图片链接集合中。