11. Spring AI + ELT
@
- 11. Spring AI + ELT
- ELT
- Document Loaders
- 读取Text
- 读取markdown
- pdf
- B站:
- DocumentSplitter
- TokenTextSplitter
- 自定分割器:
- 分隔经验:
- 分块五种策略
- 1)固定大小分块
- 2)语义分块
- 3)递归分块
- 4)基于文档结构的分块
- 5)基于LLM的分块
- ContentFormatTransformer
- KeywordMetadataEnriching
- SummaryMetadataEnricher
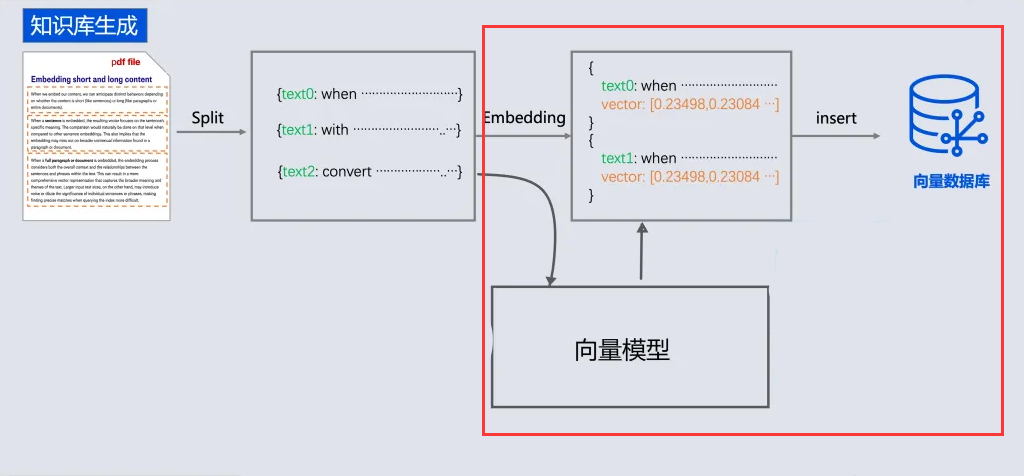
- 文本向量化
- 存储向量
- 向量数据库检索
- 对话阶段
- 提升检索精度—rerank(重排序)
- 为什么需要 rerank
- 重排序:
- 代码
- Document Loaders
- ELT
- 最后:
ELT
在之前,我们主要完成了数据检索阶段, 但是完整的RAG流程还需要有emedding阶段, 即:
提取(读取)、转换(分隔)和加载(写入)

Document Loaders
Document Loaders 文档读取器
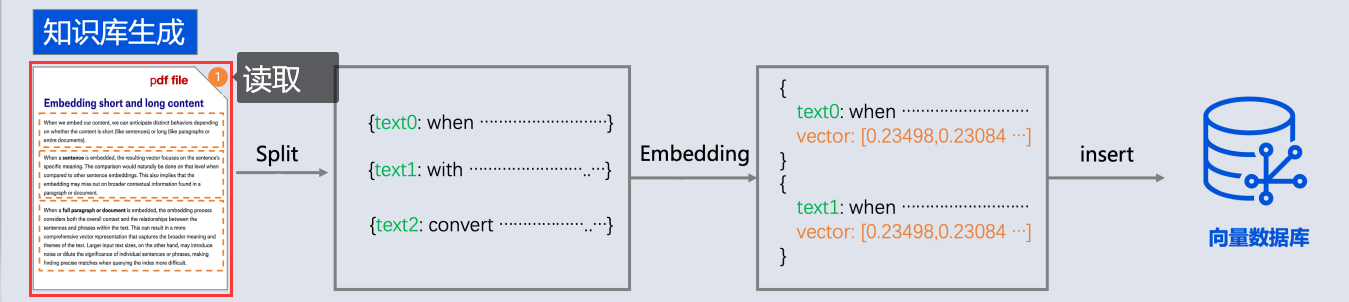
springai提供了以下文档阅读器
- JSON
- 文本
- HTML(JSoup)
- Markdown
- PDF页面
- PDF段落
- Tika(DOCX、PPTX、HTML……)
alibaba ai也提供了很多阅读器
https://github.com/alibaba/spring-ai-alibaba/tree/main/community/document-parsers
- document-parser-apache-pdfbox:用于解析 PDF 格式文档。
- document-parser-bshtml:用于解析基于 BSHTML 格式的文档。
- document-parser-pdf-tables:专门用于从 PDF 文档中提取表格数据。
- document-parser-bibtex:用于解析 BibTeX 格式的参考文献数据。
- document-parser-markdown:用于解析 Markdown 格式的文档。
- document-parser-tika:一个多功能文档解析器,支持多种文档格式。
以及网络来源文档读取器:
https://github.com/alibaba/spring-ai-alibaba/tree/main/community/document-readers

读取Text
@Testpublic void testReaderText(@Value("classpath:rag/terms-of-service.txt") Resource resource) {TextReader textReader = new TextReader(resource);List<Document> documents = textReader.read();for (Document document : documents) {System.out.println(document.getText());}}
读取markdown
<dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-markdown-document-reader</artifactId></dependency>
@Testpublic void testReaderMD(@Value("classpath:rag/9_横店影视股份有限公司_0.md") Resource resource) {MarkdownDocumentReaderConfig config = MarkdownDocumentReaderConfig.builder().withHorizontalRuleCreateDocument(true) // 分割线创建新document.withIncludeCodeBlock(false) // 代码创建新document false 会创建.withIncludeBlockquote(false) // 引用创建新document false 会创建.withAdditionalMetadata("filename", resource.getFilename()) // 每个document添加的元数据.build();MarkdownDocumentReader markdownDocumentReader = new MarkdownDocumentReader(resource, config);List<Document> documents = markdownDocumentReader.read();for (Document document : documents) {System.out.println(document.getText());}}
● PagePdfDocumentReader一页1个document
● ParagraphPdfDocumentReader 按pdf目录分成一个个document
<dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-markdown-document-reader</artifactId></dependency>
@Testpublic void testReaderPdf(@Value("classpath:rag/平安银行2023年半年度报告摘要.pdf") Resource resource) {PagePdfDocumentReader pdfReader = new PagePdfDocumentReader(resource,PdfDocumentReaderConfig.builder().withPageTopMargin(0).withPageExtractedTextFormatter(ExtractedTextFormatter.builder().withNumberOfTopTextLinesToDelete(0).build()).withPagesPerDocument(1).build());List<Document> documents = pdfReader.read();for (Document document : documents) {System.out.println(document.getText());}}// 必需要带目录, 按pdf的目录分document@Testpublic void testReaderParagraphPdf(@Value("classpath:rag/平安银行2023年半年度报告.pdf") Resource resource) {ParagraphPdfDocumentReader pdfReader = new ParagraphPdfDocumentReader(resource,PdfDocumentReaderConfig.builder()// 不同的PDF生成工具可能使用不同的坐标系 , 如果内容识别有问题, 可以设置该属性为true.withReversedParagraphPosition(true).withPageTopMargin(0) // 上边距.withPageExtractedTextFormatter(ExtractedTextFormatter.builder()// 从页面文本中删除前 N 行.withNumberOfTopTextLinesToDelete(0).build()).build());List<Document> documents = pdfReader.read();for (Document document : documents) {System.out.println(document.getText());}}
B站:
<dependency><groupId>com.alibaba.cloud.ai</groupId><artifactId>spring-ai-alibaba-starter-document-reader-bilibili</artifactId></dependency>
@Testvoid bilibiliDocumentReaderTest() {BilibiliDocumentReader bilibiliDocumentReader = new BilibiliDocumentReader("https://www.bilibili.com/video/BV1C5UxYuEc2/?spm_id_from=333.1387.upload.video_card.click&vd_source=fa810d8b8d6765676cb343ada918d6eb");List<Document> documents = bilibiliDocumentReader.get();System.out.println(documents);}
DocumentSplitter
DocumentSplitter文档拆分器(转换器)
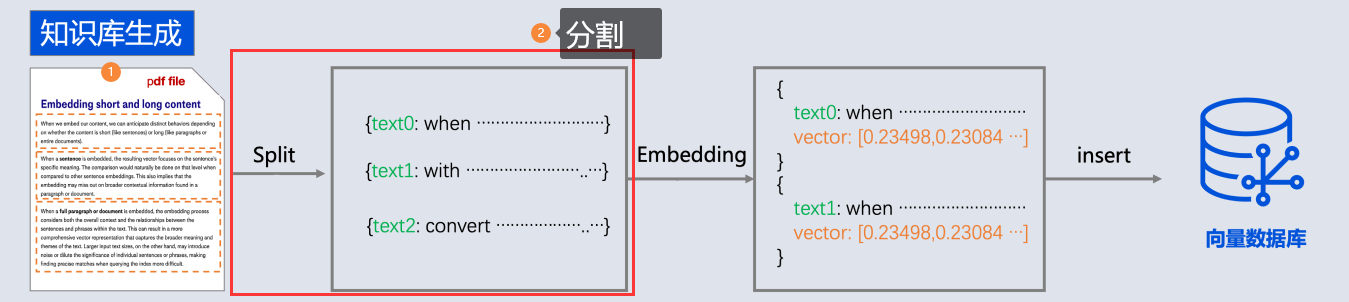
由于文本读取过来后, 还需要分成一段一段的片段(分块chunk), 分块是为了更好地拆分语义单元,这样在后面可以更精确地进行语义相似性检索,也可以避免LLM的Token限制。
SpringAi就提供了一个文档拆分器:
- TextSplitter 抽象类
- TokenTextSplitter 按token分隔
TokenTextSplitter
- chunkSize (默认值: 800) 100
○ 每个文本块的目标大小,以token为单位 - minChunkSizeChars (默认值: 350) 建议小一点
○ 如果块超过最小块字符数( 按照块的最后. ! ? \n 符号截取)
○ 如果块没超过最小块字符数, 不会按照符号截取(保留原块)。
本服务条款适用于您对图灵航空 的体验。预订航班,即表示您同意这些条款。
1. 预订航班
- 通过我们的网站或移动应用程序预订。
- 预订时需要全额付款。 \n
- 确保个人信息(姓名、ID 等)的准确性,因为更正可能会产生 25
- minChunkLengthToEmbed (默认值: 5) 5
○ 丢弃短于此长度的文本块(如果去掉\r\n, 只剩5个有效文本, 那就丢掉)
本服务条
-
maxNumChunks(默认值: 10000)
○ 最多能分多少个块, 超过了就不管了 -
keepSeparator(默认值: true)
○ 是否在块中保留分隔符、换行符 \r\n
@Testpublic void testTokenTextSplitter(@Value("classpath:rag/terms-of-service.txt") Resource resource) {TextReader textReader = new TextReader(resource);textReader.getCustomMetadata().put("filename", resource.getFilename());List<Document> documents = textReader.read();TokenTextSplitter splitter = new TokenTextSplitter(1000, 400, 10, 5000, true);List<Document> apply = splitter.apply(documents);apply.forEach(System.out::println);}
整个流程如下:
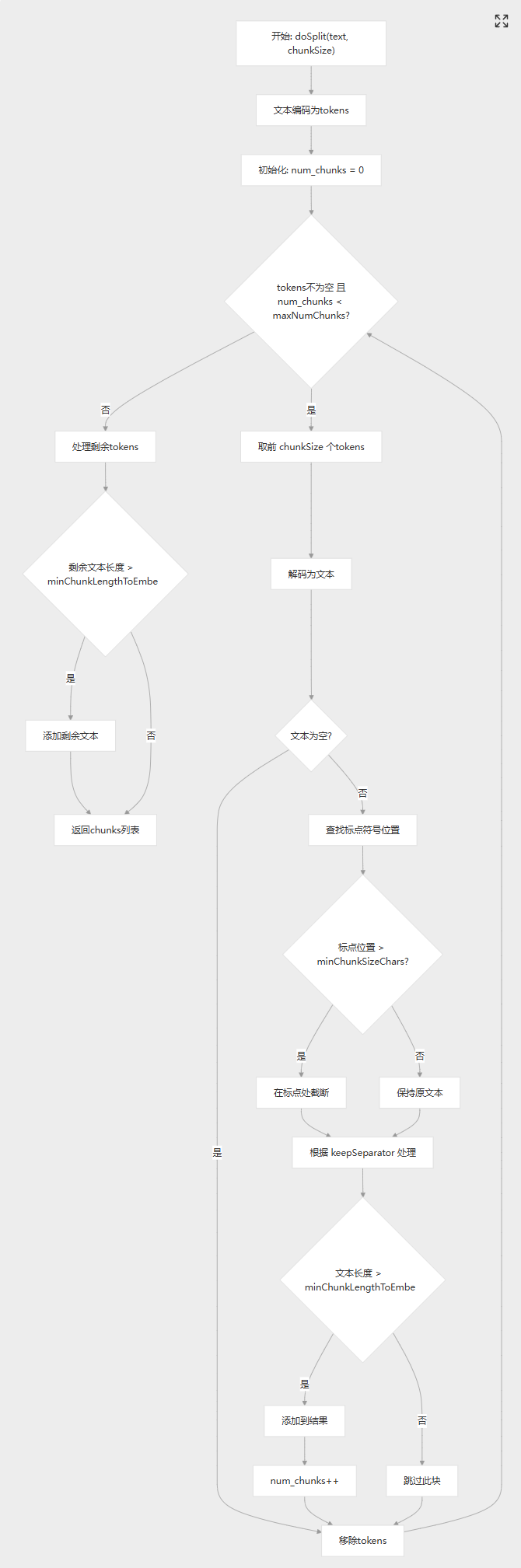
自定分割器:
支持中英文:同时支持中文和英文标点符号
package com.xushu.springai.rag.ELT;public class ChineseTokenTextSplitter extends TextSplitter {private static final int DEFAULT_CHUNK_SIZE = 800;private static final int MIN_CHUNK_SIZE_CHARS = 350;private static final int MIN_CHUNK_LENGTH_TO_EMBED = 5;private static final int MAX_NUM_CHUNKS = 10000;private static final boolean KEEP_SEPARATOR = true;private final EncodingRegistry registry = Encodings.newLazyEncodingRegistry();private final Encoding encoding = this.registry.getEncoding(EncodingType.CL100K_BASE);// The target size of each text chunk in tokensprivate final int chunkSize;// The minimum size of each text chunk in charactersprivate final int minChunkSizeChars;// Discard chunks shorter than thisprivate final int minChunkLengthToEmbed;// The maximum number of chunks to generate from a textprivate final int maxNumChunks;private final boolean keepSeparator;public ChineseTokenTextSplitter() {this(DEFAULT_CHUNK_SIZE, MIN_CHUNK_SIZE_CHARS, MIN_CHUNK_LENGTH_TO_EMBED, MAX_NUM_CHUNKS, KEEP_SEPARATOR);}public ChineseTokenTextSplitter(boolean keepSeparator) {this(DEFAULT_CHUNK_SIZE, MIN_CHUNK_SIZE_CHARS, MIN_CHUNK_LENGTH_TO_EMBED, MAX_NUM_CHUNKS, keepSeparator);}public ChineseTokenTextSplitter(int chunkSize, int minChunkSizeChars, int minChunkLengthToEmbed, int maxNumChunks,boolean keepSeparator) {this.chunkSize = chunkSize;this.minChunkSizeChars = minChunkSizeChars;this.minChunkLengthToEmbed = minChunkLengthToEmbed;this.maxNumChunks = maxNumChunks;this.keepSeparator = keepSeparator;}public static Builder builder() {return new Builder();}@Overrideprotected List<String> splitText(String text) {return doSplit(text, this.chunkSize);}protected List<String> doSplit(String text, int chunkSize) {if (text == null || text.trim().isEmpty()) {return new ArrayList<>();}List<Integer> tokens = getEncodedTokens(text);List<String> chunks = new ArrayList<>();int num_chunks = 0;// maxNumChunks多能分多少个块, 超过了就不管了while (!tokens.isEmpty() && num_chunks < this.maxNumChunks) {// 按照chunkSize进行分隔List<Integer> chunk = tokens.subList(0, Math.min(chunkSize, tokens.size()));String chunkText = decodeTokens(chunk);// Skip the chunk if it is empty or whitespaceif (chunkText.trim().isEmpty()) {tokens = tokens.subList(chunk.size(), tokens.size());continue;}// Find the last period or punctuation mark in the chunkint lastPunctuation =Math.max(chunkText.lastIndexOf('.'),Math.max(chunkText.lastIndexOf('?'),Math.max(chunkText.lastIndexOf('!'),Math.max(chunkText.lastIndexOf('\n'),// 添加上我们中文的分割符号Math.max(chunkText.lastIndexOf('。'),Math.max(chunkText.lastIndexOf('?'),chunkText.lastIndexOf('!')))))));// 按照句子截取之后长度 > minChunkSizeCharsif (lastPunctuation != -1 && lastPunctuation > this.minChunkSizeChars) {// 保留按照句子截取之后的内容chunkText = chunkText.substring(0, lastPunctuation + 1);}// 按照句子截取之后长度 < minChunkSizeChars 保留原块// keepSeparator=true 替换/r/n =false不管String chunkTextToAppend = (this.keepSeparator) ? chunkText.trim(): chunkText.replace(System.lineSeparator(), " ").trim();// 替换/r/n之后的内容是不是<this.minChunkLengthToEmbed 忽略if (chunkTextToAppend.length() > this.minChunkLengthToEmbed) {chunks.add(chunkTextToAppend);}// Remove the tokens corresponding to the chunk text from the remaining tokenstokens = tokens.subList(getEncodedTokens(chunkText).size(), tokens.size());num_chunks++;}// Handle the remaining tokensif (!tokens.isEmpty()) {String remaining_text = decodeTokens(tokens).replace(System.lineSeparator(), " ").trim();if (remaining_text.length() > this.minChunkLengthToEmbed) {chunks.add(remaining_text);}}return chunks;}private List<Integer> getEncodedTokens(String text) {Assert.notNull(text, "Text must not be null");return this.encoding.encode(text).boxed();}private String decodeTokens(List<Integer> tokens) {Assert.notNull(tokens, "Tokens must not be null");var tokensIntArray = new IntArrayList(tokens.size());tokens.forEach(tokensIntArray::add);return this.encoding.decode(tokensIntArray);}public static final class Builder {private int chunkSize = DEFAULT_CHUNK_SIZE;private int minChunkSizeChars = MIN_CHUNK_SIZE_CHARS;private int minChunkLengthToEmbed = MIN_CHUNK_LENGTH_TO_EMBED;private int maxNumChunks = MAX_NUM_CHUNKS;private boolean keepSeparator = KEEP_SEPARATOR;private Builder() {}public Builder withChunkSize(int chunkSize) {this.chunkSize = chunkSize;return this;}public Builder withMinChunkSizeChars(int minChunkSizeChars) {this.minChunkSizeChars = minChunkSizeChars;return this;}public Builder withMinChunkLengthToEmbed(int minChunkLengthToEmbed) {this.minChunkLengthToEmbed = minChunkLengthToEmbed;return this;}public Builder withMaxNumChunks(int maxNumChunks) {this.maxNumChunks = maxNumChunks;return this;}public Builder withKeepSeparator(boolean keepSeparator) {this.keepSeparator = keepSeparator;return this;}public ChineseTokenTextSplitter build() {return new ChineseTokenTextSplitter(this.chunkSize, this.minChunkSizeChars, this.minChunkLengthToEmbed,this.maxNumChunks, this.keepSeparator);}}}
分隔经验:
过细分块的潜在问题
- 语义割裂: 破坏上下文连贯性,影响模型理解。
- 计算成本增加:分块过细会导致向量嵌入和检索次数增多,增加时间和算力开销。
- 信息冗余与干扰:碎片化的文本块可能引入无关内容,干扰检索结果的质量,降低生成答案的准确性。
分块过大的弊端
- 信息丢失风险:过大的文本块可能超出嵌入模型的输入限制,导致关键信息未被有效编码。
- 检索精度下降:大块内容可能包含多主题混合,与用户查询的相关性降低,影响模型反馈效果。
| 场景 | 分块策略 | 参数参考 |
|---|---|---|
| 微博/短文本 | 句子级分块,保留完整语义 | 每块100-200字符 |
| 学术论文 | 段落级分块,叠加10%重叠 | 每块300-500字符 |
| 法律合同 | 条款级分块,严格按条款分隔 | 每块200-400字符 |
| 长篇小说 | 章节级分块,过长段落递归拆分为段落 | 每块500-1000字符 |
不要过分指望按照文本主题进行分隔, 因为实战中的资料太多而且没有规律, 根本没办法保证每个chunk是一个完整的主题内容, 哪怕人为干预也很难。 所以实战中往往需要结合资料来决定分割器,大多数情况就是按token数分, 因为没有完美的, 还可以加入人工干预,或者大模型分隔。
分块五种策略
以下是 RAG 的五种分块策略:
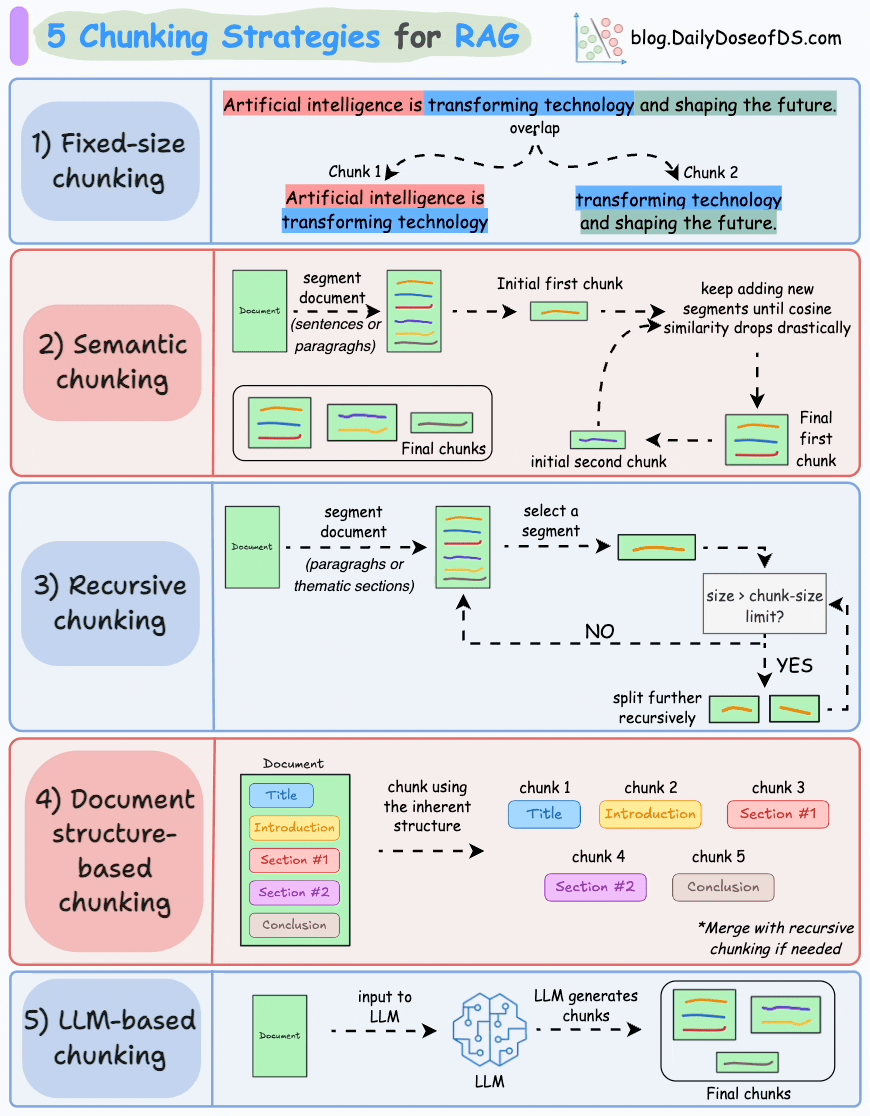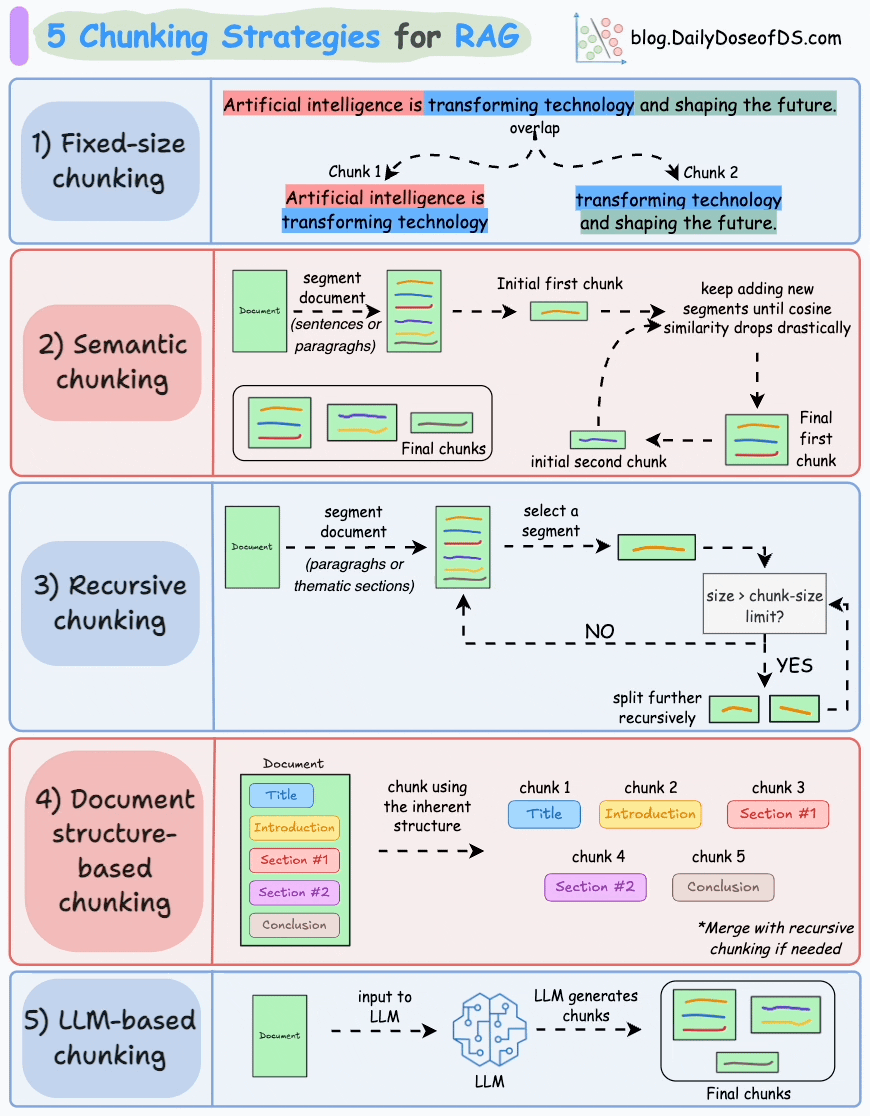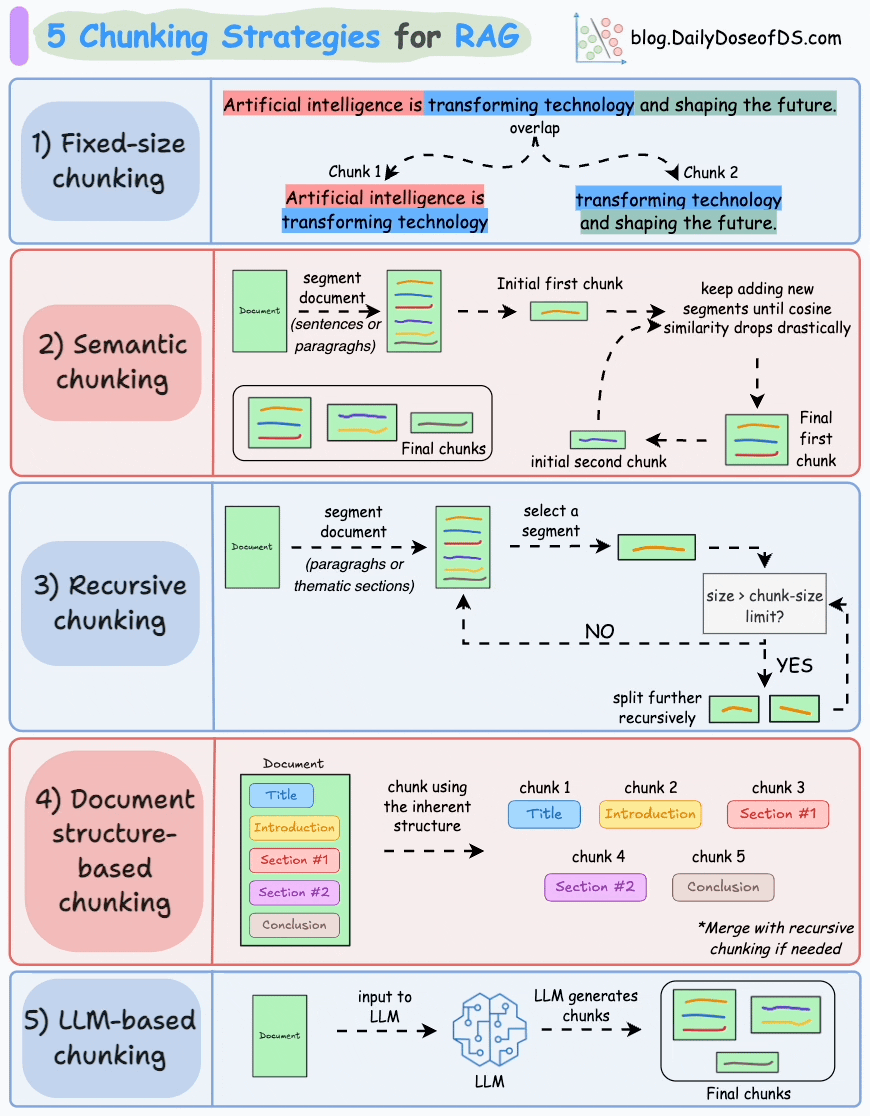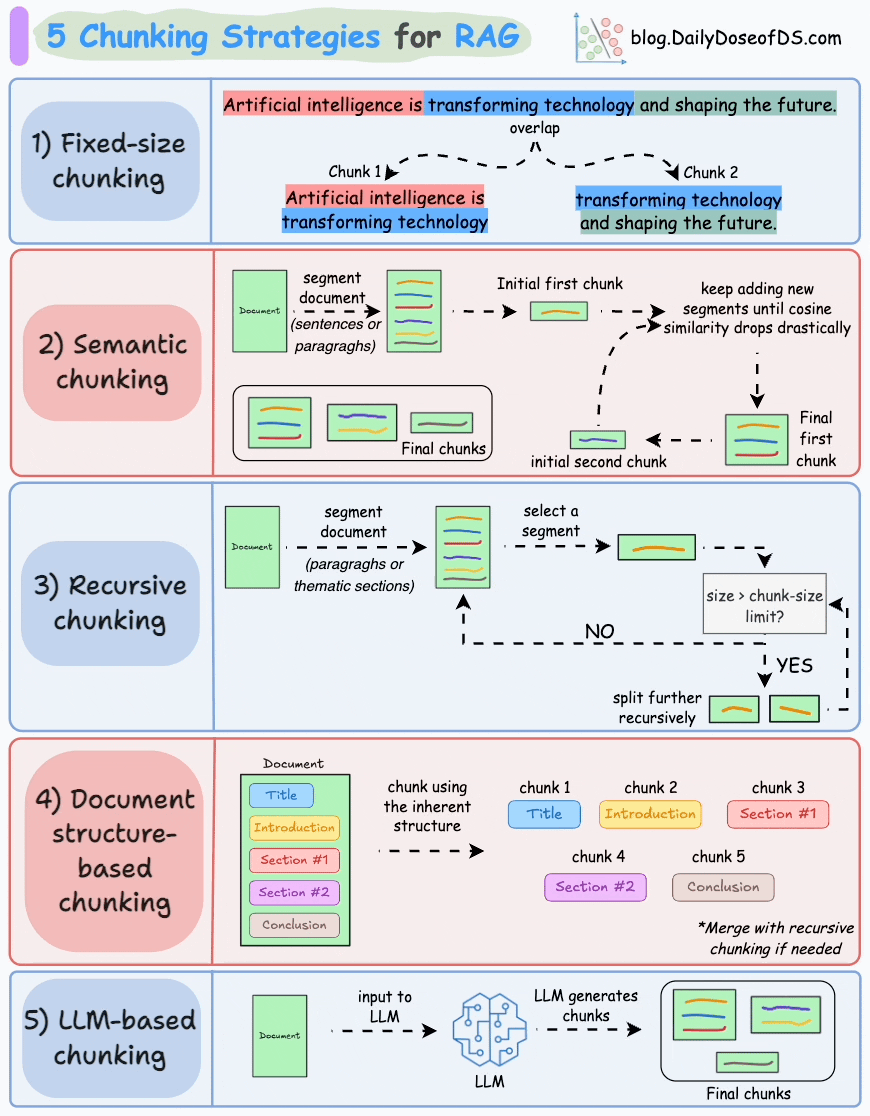
1)固定大小分块
生成块的最直观和直接的方法是根据预定义的字符、单词或标记数量将文本分成统一的段。

由于直接分割会破坏语义流,因此建议在两个连续的块之间保持一些重叠(上图蓝色部分)。
这很容易实现。而且,由于所有块的大小相同,它简化了批处理。
但有一个大问题。这通常会打断句子(或想法)。因此,重要的信息很可能会分散到不同的块之间。
2)语义分块
这个想法很简单。
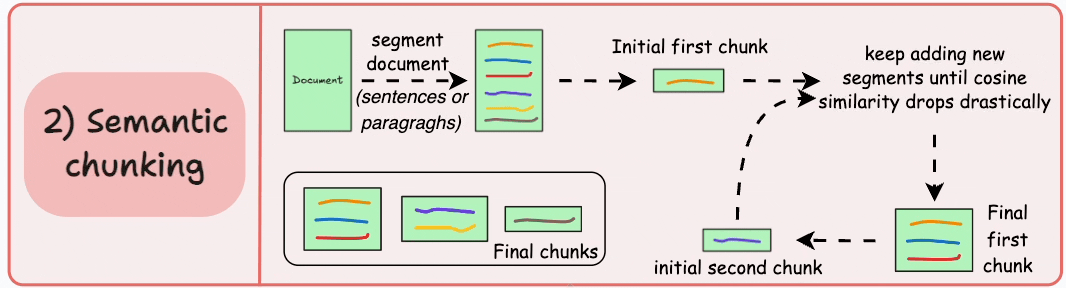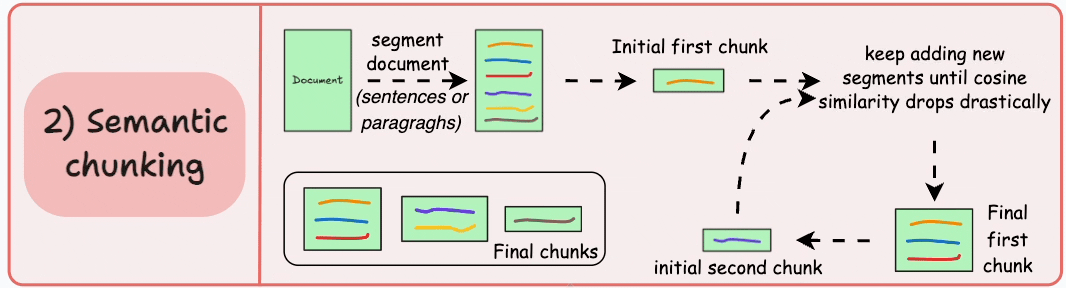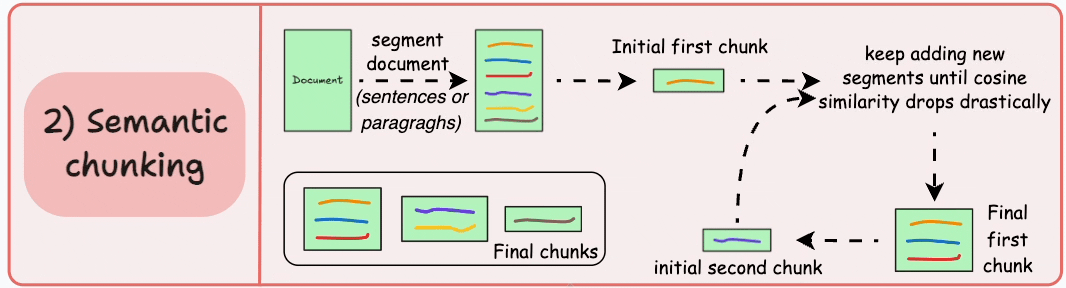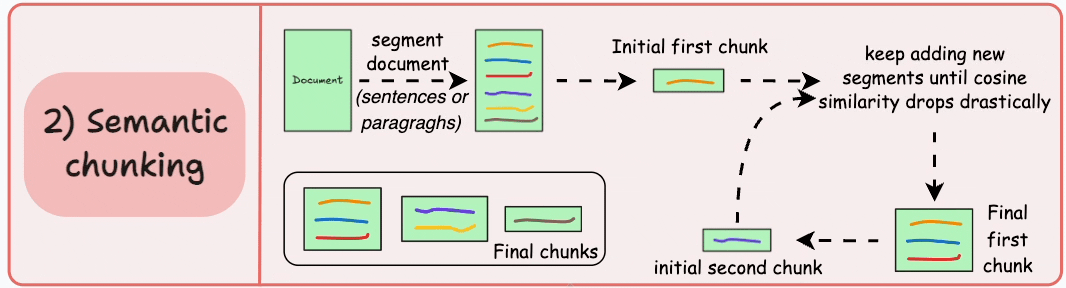
- 根据句子、段落或主题部分等有意义的单位对文档进行细分。
- 接下来,为每个片段创建嵌入。
- 假设我从第一个片段及其嵌入开始。
- 如果第一个段的嵌入与第二个段的嵌入具有较高的余弦相似度,则这两个段形成一个块。
- 这种情况一直持续到余弦相似度显著下降。
- 一旦发生这种情况,我们就开始新的部分并重复。
输出可能如下所示:

与固定大小的块不同,这保持了语言的自然流畅并保留了完整的想法。
由于每个块都更加丰富,它提高了检索准确性,进而使 LLM 产生更加连贯和相关的响应。
一个小问题是,它依赖于一个阈值来确定余弦相似度是否显著下降,而这个阈值在不同文档之间可能会有所不同。
3)递归分块
这也很简单。
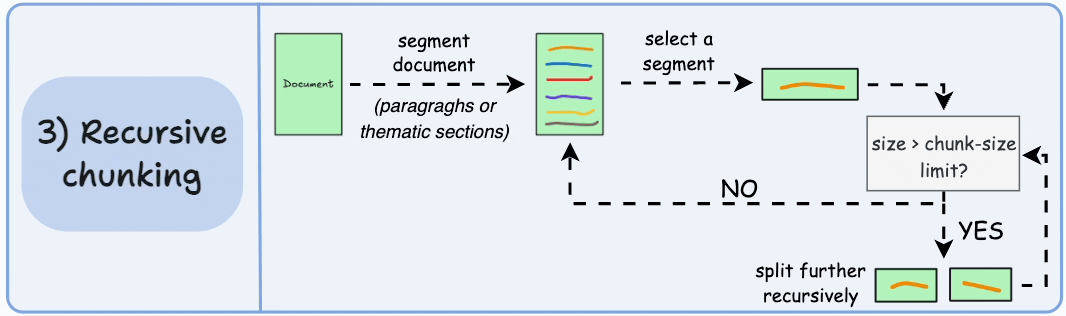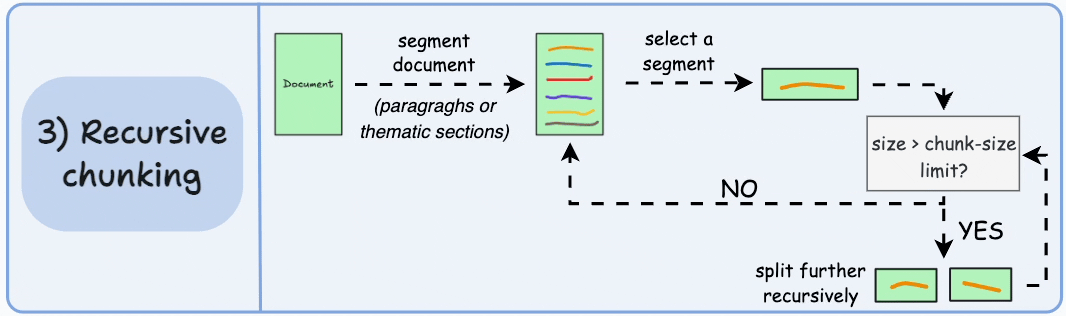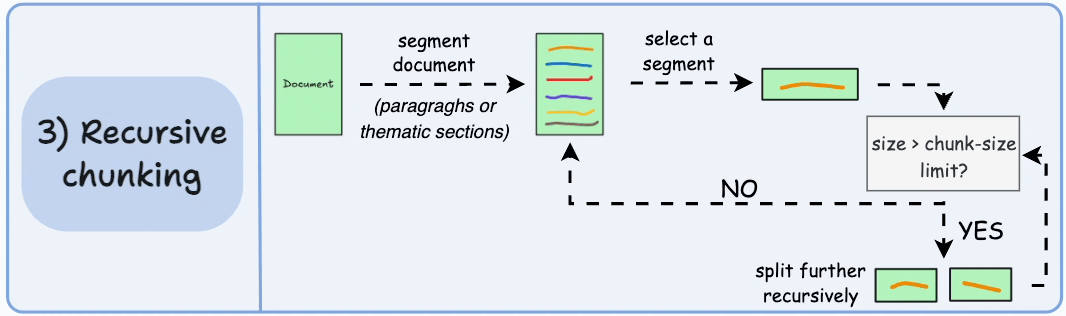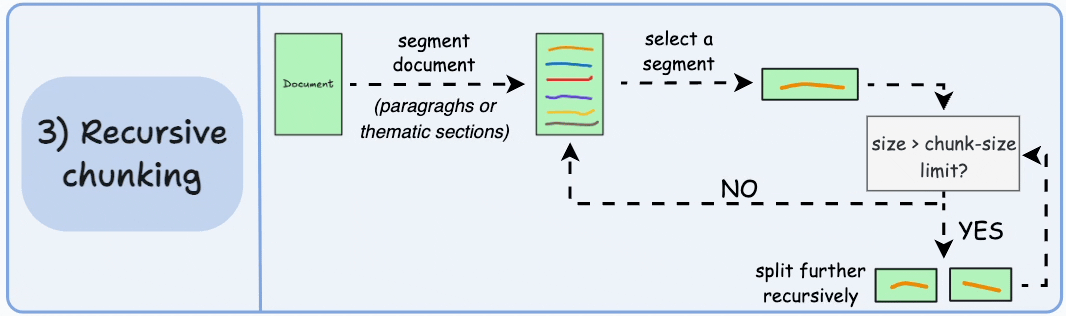
首先,根据固有分隔符(如段落或章节)进行分块。
接下来,如果每个块的大小超出了预定义的块大小限制,则将其拆分成更小的块。但是,如果块符合块大小限制,则不再进行进一步拆分。
输出可能如下所示:

如上图:
- 首先,我们定义两个块(紫色的两个段落)。
- 接下来,第 1 段被进一步分成更小的块。
与固定大小的块不同,这种方法还保持了语言的自然流畅性并保留了完整的想法。
然而,在实施和计算复杂性方面存在一些额外的开销。
4)基于文档结构的分块
这是另一种直观的方法。
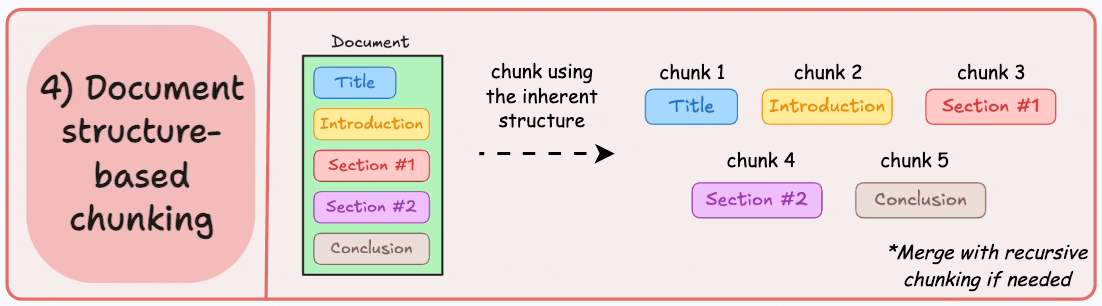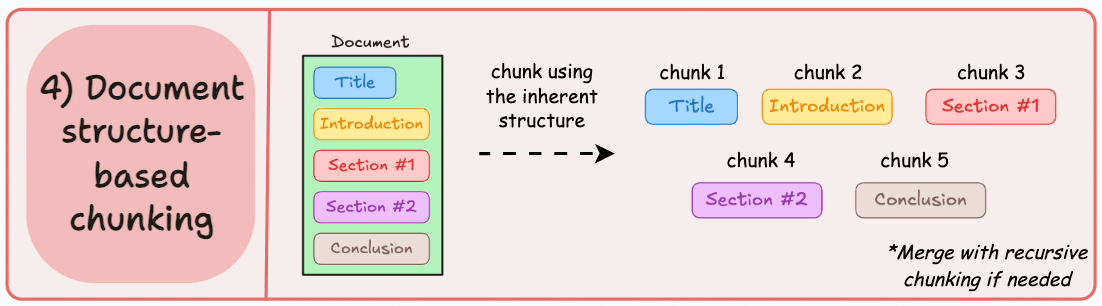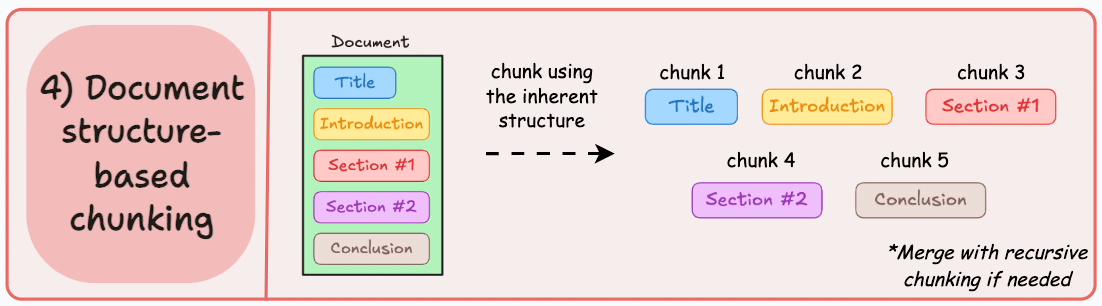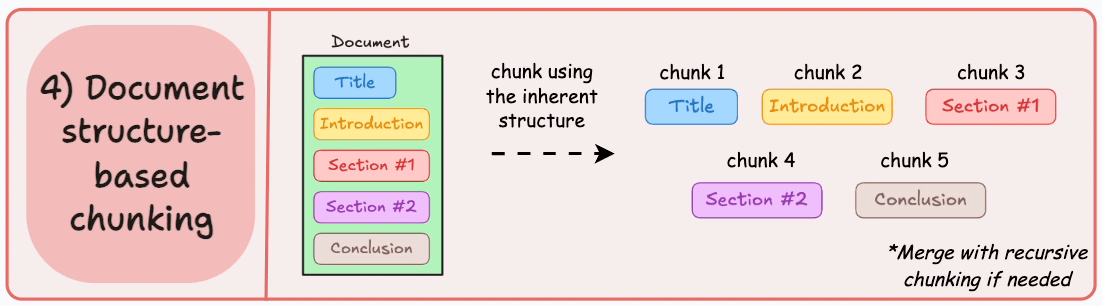
它利用文档的固有结构(如标题、章节或段落)来定义块边界。
这样,它就通过与文档的逻辑部分对齐来保持结构完整性。
输出可能如下所示:

也就是说,这种方法假设文档具有清晰的结构,但事实可能并非如此。
此外,块的长度可能会有所不同,可能会超出模型令牌的限制。您可以尝试使用递归拆分进行合并。
5)基于LLM的分块

既然每种方法都有优点和缺点,为什么不使用 LLM 来创建块呢?
可以提示 LLM 生成语义上孤立且有意义的块。
显然,这种方法将确保较高的语义准确性,因为 LLM 可以理解超越简单启发式方法(用于上述四种方法)的上下文和含义。
唯一的问题是,它是这里讨论的所有五种技术中计算要求最高的分块技术。
此外,由于 LLM 通常具有有限的上下文窗口,因此需要注意这一点。
每种技术都有其自身的优势和劣势。
我观察到语义分块在很多情况下效果很好,但同样,您需要进行测试。
选择将在很大程度上取决于内容的性质、嵌入模型的功能、计算资源等。
我们很快就会对这些策略进行实际演示。
同时,如果您错过了,昨天我们讨论了构建依赖于成对内容相似性的强大 NLP 系统的技术(RAG 就是其中之一)。
ContentFormatTransformer
检索到的内容最终会发给大模型, 由该组件决定发送到模型的RAG内容
private static final String DEFAULT_TEXT_TEMPLATE = String.format("%s\n\n%s", TEMPLATE_METADATA_STRING_PLACEHOLDER,TEMPLATE_CONTENT_PLACEHOLDER);
即:假设:
● 文本内容:"The World is Big and Salvation Lurks Around the Corner"
● 元数据:Map.of("fileName", "xushu.pdf")
最终发送给大模型的格式化内容是:
source: xushu.pdfThe World is Big and Salvation Lurks Around the Corner
很少会去改, 了解即可
KeywordMetadataEnriching
使用生成式AI模型从文档内容中提取关键词并将其添加为元数据,为文档添加关键词标签,提升检索精度
new KeywordMetadataEnricher(chatModel, 5);
- chatModel 需要提取关键字的模型
- 关键字数量
@Testpublic void testKeywordMetadataEnricher(@Autowired DashScopeChatModel chatModel,@Value("classpath:rag/terms-of-service.txt") Resource resource) {TextReader textReader = new TextReader(resource);textReader.getCustomMetadata().put("filename", resource.getFilename());List<Document> documents = textReader.read();ChineseTokenTextSplitter splitter = new ChineseTokenTextSplitter();List<Document> apply = splitter.apply(documents);// 通过传入大模型,让大模型提取文件内容当中的 5 个关键字KeywordMetadataEnricher enricher = new KeywordMetadataEnricher(chatModel, 5);// 关键字的提取,根据标签提取apply= enricher.apply(apply);for (Document document : apply) {System.out.println(document.getText());System.out.println(document.getText().length());}apply.forEach(System.out::println);}
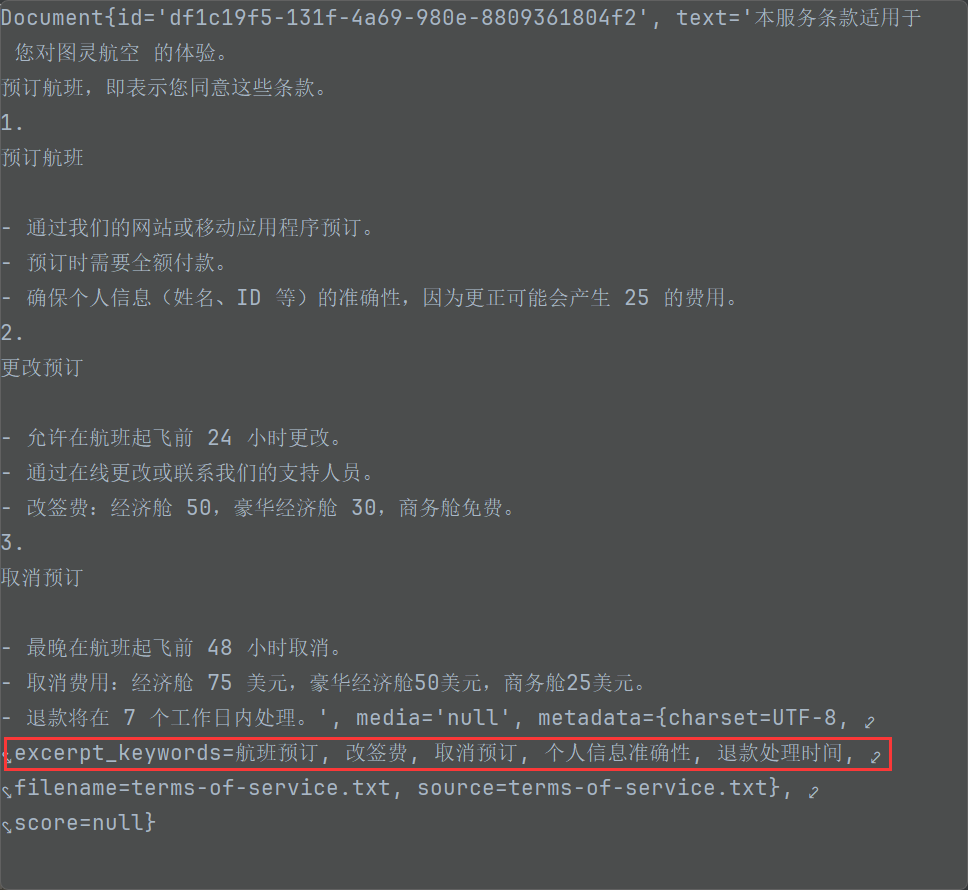
提取到的关键字的作用:
帮助做元数据过滤。 并不参数向量数据库的相似性检索
KeywordMetadataEnriching 生成出来的关键字无法进行元数据过滤?
SummaryMetadataEnricher
使用生成式AI模型为文档创建摘要并将其添加为元数据。它可以为当前文档以及相邻文档(前一个和后一个)生成摘要,以提供更丰富的上下文信息 。
场景: 有顺序关联的文档,比如西游记小说的RAG,‘三打白骨精的故事以及后续剧情’。
- 技术文档:前后章节有依赖关系
- 教程内容:步骤之间有逻辑顺序
- 法律文档:条款之间有关联性
- 学术论文:章节间有逻辑递进
@Testpublic void testSummaryMetadataEnricher(@Autowired DashScopeChatModel chatModel,@Value("classpath:rag/terms-of-service.txt") Resource resource) {TextReader textReader = new TextReader(resource);textReader.getCustomMetadata().put("filename", resource.getFilename());List<Document> documents = textReader.read();ChineseTokenTextSplitter splitter = new ChineseTokenTextSplitter();List<Document> apply = splitter.apply(documents);SummaryMetadataEnricher enricher = new SummaryMetadataEnricher(chatModel,List.of(SummaryMetadataEnricher.SummaryType.PREVIOUS,SummaryMetadataEnricher.SummaryType.CURRENT,SummaryMetadataEnricher.SummaryType.NEXT));apply = enricher.apply(apply);}
文本向量化

向量化存储之前在“文本向量化”介绍了, 就是通过向量模型库进行向量化
代码:
依然通过Qwen向量模型进行向量化: 将第分割的chunk进行向量化
@Testpublic void testTokenTextSplitter( @Autowired DashScopeEmbeddingModel embeddingModel,@Value("classpath:rag/terms-of-service.txt") Resource resource) {TextReader textReader = new TextReader(resource);textReader.getCustomMetadata().put("filename", resource.getFilename());List<Document> documents = textReader.read();ChineseTokenTextSplitter splitter = new ChineseTokenTextSplitter(100);List<Document> apply = splitter.apply(documents);for (Document document : apply) {float[] embedded = embeddingModel.embed(document);}}
存储向量
但是我告诉你其实 , 我们通过向量数据库存储document, 可以省略向量化这一步, 向量数据库会在底层自动完成向量化
for (Document document : apply) {float[] embedded = embeddingModel.embed(document);
}// 替换为: 写入=向量化+存储
vectorStore.write(apply);
@Testpublic void testTokenTextSplitter(@Autowired VectorStore vectorStore,@Value("classpath:rag/terms-of-service.txt") Resource resource) {TextReader textReader = new TextReader(resource);textReader.getCustomMetadata().put("filename", resource.getFilename());List<Document> documents = textReader.read();ChineseTokenTextSplitter splitter = new ChineseTokenTextSplitter(100);List<Document> apply = splitter.apply(documents);vectorStore.add(apply);}
向量数据库检索
代码:
需要先将文本进行向量化, 然后去向量数据库查询,
// 3. 相似性查询SearchRequest searchRequest = SearchRequest.builder().query("预定航班").topK(5).similarityThreshold(0.3).build();List<Document> results = vectorStore.similaritySearch(searchRequest);// 4.输出System.out.println(results);
完整代码:
@Testpublic void testRag(@Autowired VectorStore vectorStore,@Value("classpath:rag/terms-of-service.txt") Resource resource) {// 1. 读取TextReader textReader = new TextReader(resource);textReader.getCustomMetadata().put("filename", resource.getFilename());List<Document> documents = textReader.read();// 2.分隔ChineseTokenTextSplitter splitter = new ChineseTokenTextSplitter(100);List<Document> apply = splitter.apply(documents);// 3. 向量化+写入vectorStore.write(apply);// 3. 相似性查询SearchRequest searchRequest = SearchRequest.builder().query("退费需要多少费用").topK(5).similarityThreshold(0.3).build();List<Document> results = vectorStore.similaritySearch(searchRequest);// 4.输出System.out.println(results);}
对话阶段
如果结合ChatClient 可以直接将检索和Advisor整合在一起
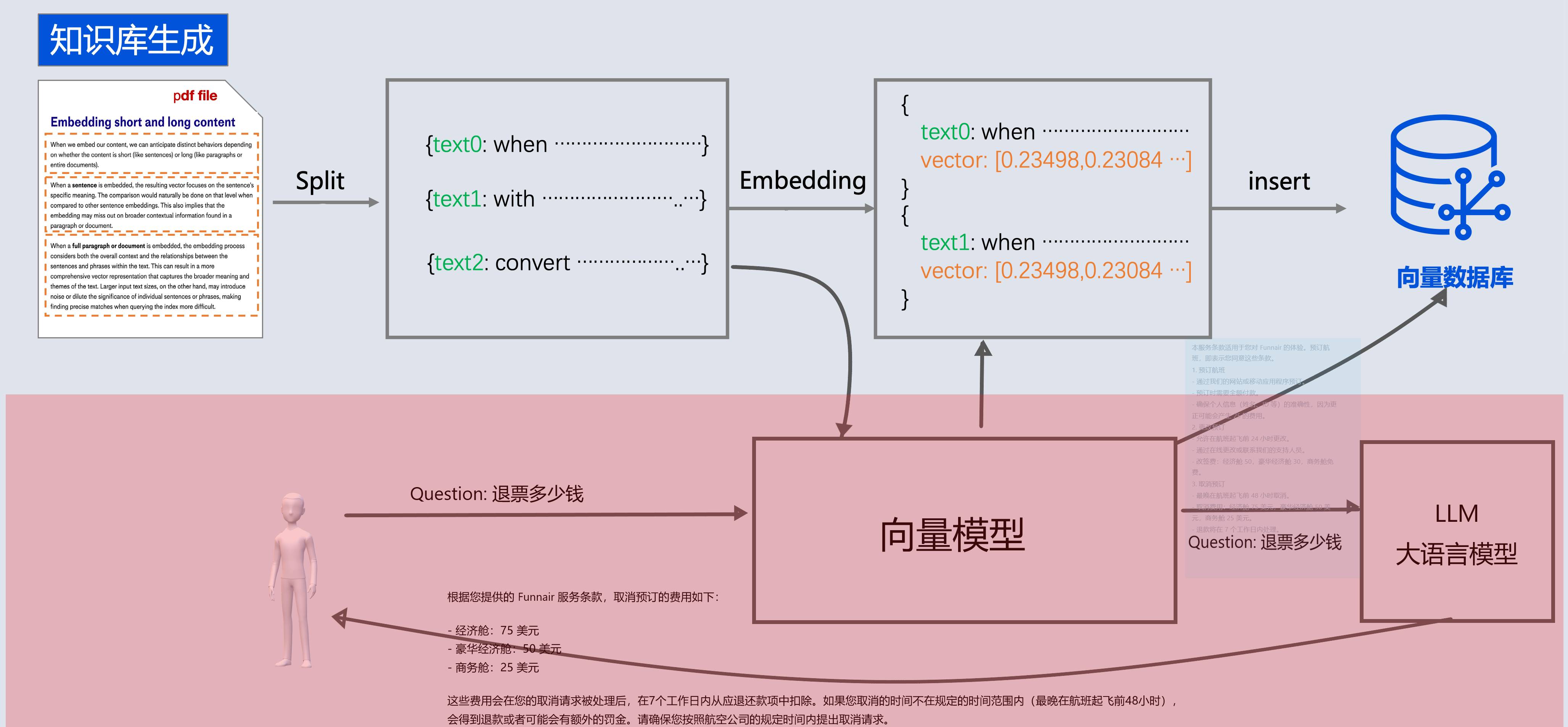
@Testpublic void testRagToLLM(@Autowired VectorStore vectorStore,@Autowired DashScopeChatModel chatModel,@Value("classpath:rag/terms-of-service.txt") Resource resource) {TextReader textReader = new TextReader(resource);textReader.getCustomMetadata().put("filename", resource.getFilename());List<Document> documents = textReader.read();ChineseTokenTextSplitter splitter = new ChineseTokenTextSplitter(100);List<Document> apply = splitter.apply(documents);vectorStore.write(apply);// 3. 相似性查询 ChatClient chatClient = ChatClient.builder(chatModel).build();String message="退费需要多少费用?";String content = chatClient.prompt().user(message).advisors(new SimpleLoggerAdvisor(),QuestionAnswerAdvisor.builder(vectorStore).searchRequest(SearchRequest.builder().query(message).topK(5).similarityThreshold(0.3).build()).build()).call().content();System.out.println(content);}
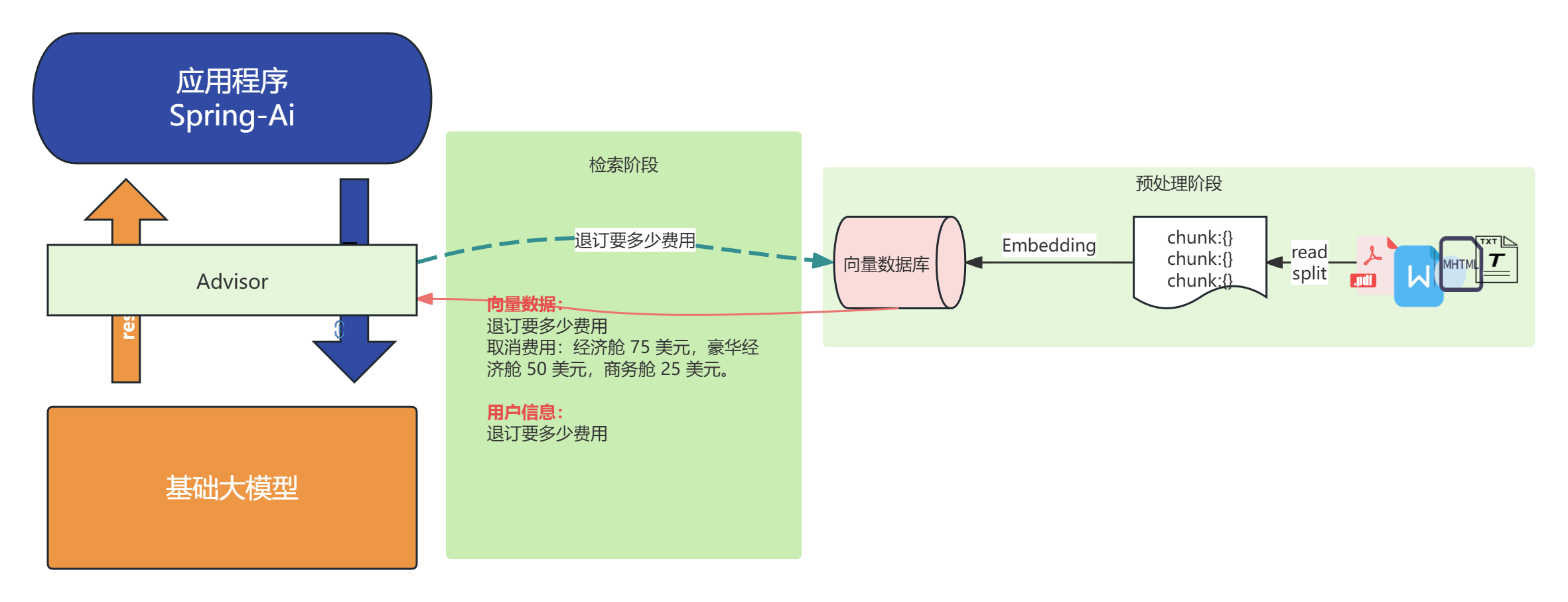
SpringAI整个过程原理:
提升检索精度—rerank(重排序)
为什么需要 rerank
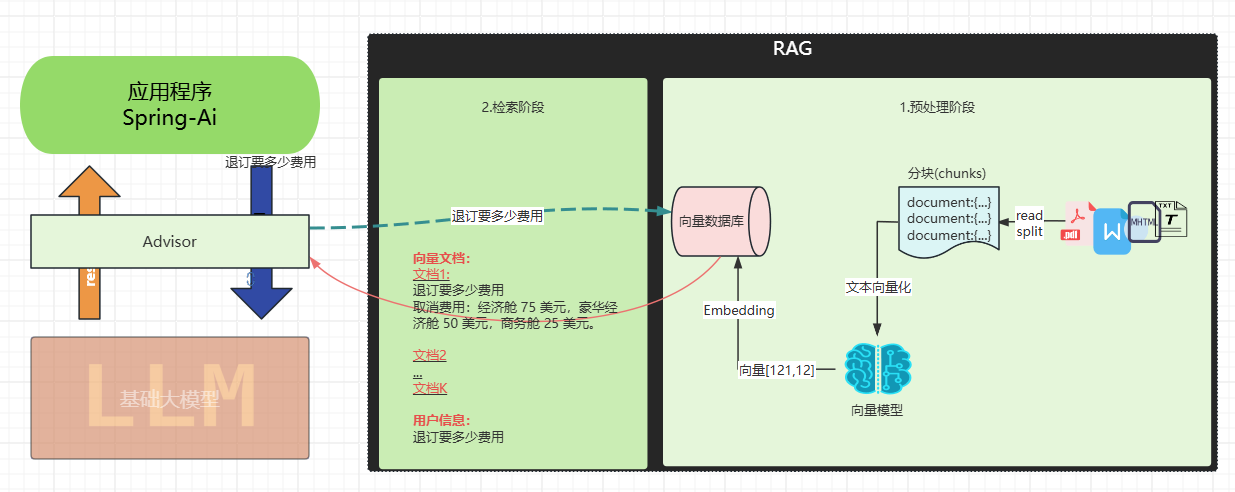
传统的向量检索存在几个关键问题:
语义相似度的局限性:向量检索主要基于余弦相似度等数学计算,但相似的向量表示不一定意味着内容一定绝对相关。单纯的向量相似度无法充分理解查询的真实意图和上下文。
排序质量不佳:初始检索的排序往往不是最优的,可能将不太相关的文档排在前面,尤其性能差的向量模型更为明显。
上下文理解缺失:传统检索(完全依赖向量数据库和向量模型)缺乏对查询和文档完整上下文的深度理解,容易出现语义漂移问题。
重排序:
主要在检索阶段进行改进:

二阶段优化架构: rerank 采用"粗排+精排"的两阶段架构。第一阶段快速检索大量候选文档,第二阶段使用专门的重排序模型进行精确评分。
专业化模型: 重排序模型(如gte-rerank-hybrid)专门针对文档相关性评估进行训练,能够更准确地计算查询与文档的语义匹配度。
分数阈值过滤: 通过设置最小分数阈值,可以过滤掉低质量的文档,确保只有高相关性的内容被保留。在实现中可以看到这个过滤逻辑:
动态参数调整: 支持根据实际效果动态调整 topN 等参数,优化最终返回的文档数量和质量。
代码
说明:
为了更好的测试
- 我这里用的事ollama一个性能较差的向量模型, 这样才能更好体现他瞎排的顺序
- 我分隔的比较小new ChineseTokenTextSplitter(80,10,5,10000,true);为了有更多的document;
- 粗排需要设置数量较大的topk(建议200) , 精排(默认topN5)
@SpringBootTest
public class RerankTest {@BeforeEachpublic void init(@Autowired VectorStore vectorStore,@Value("classpath:rag/terms-of-service.txt") Resource resource) {// 读取TextReader textReader = new TextReader(resource);textReader.getCustomMetadata().put("filename", resource.getFilename());List<Document> documents = textReader.read();// 分隔ChineseTokenTextSplitter splitter = new ChineseTokenTextSplitter(80,10,5,10000,true);List<Document> apply = splitter.apply(documents);// 存储向量(内部会自动向量化)vectorStore.add(apply);}@TestConfigurationstatic class TestConfig {@Beanpublic VectorStore vectorStore(OllamaEmbeddingModel embeddingModel) {return SimpleVectorStore.builder(embeddingModel).build();}}@Testpublic void testRerank(@Autowired DashScopeChatModel dashScopeChatModel,@Autowired VectorStore vectorStore,@Autowired DashScopeRerankModel rerankModel) {ChatClient chatClient = ChatClient.builder(dashScopeChatModel).build();RetrievalRerankAdvisor retrievalRerankAdvisor =new RetrievalRerankAdvisor(vectorStore, rerankModel, SearchRequest.builder().topK(200).build());String content = chatClient.prompt().user("退票费用").advisors(retrievalRerankAdvisor).call().content();System.out.println(content);}
}
重排前:
排第一的doucment跟退费并没有关系:

重排后:
排第一的document:

最后:
“在这个最后的篇章中,我要表达我对每一位读者的感激之情。你们的关注和回复是我创作的动力源泉,我从你们身上吸取了无尽的灵感与勇气。我会将你们的鼓励留在心底,继续在其他的领域奋斗。感谢你们,我们总会在某个时刻再次相遇。”
