作业1:
要求:用requests和BeautifulSoup库方法定向爬取给定网站(http://www.shanghairanking.cn/rankings/bcur/2020 )的数据,屏幕打印爬取的大学排名信息。
输出信息:
| 排名 | 学校名称 | 省市 | 学校类型 | 总分 |
|---|---|---|---|---|
| 1 | 清华大学 | 北京 | 综合 | 852.5 |
| 2 | .... | .... | .... | .... |
代码:
点击查看代码
import requests
from bs4 import BeautifulSoup
import redef crawl_university_ranking_optimized():url = "http://www.shanghairanking.cn/rankings/bcur/2020"headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'}#明确指定正确表头correct_headers = ["排名", "学校名称", "省市", "学校类型", "总分"]try:response = requests.get(url, headers=headers, timeout=10)response.encoding = "utf-8"response.raise_for_status()soup = BeautifulSoup(response.text, "html.parser")table = soup.find("table", class_="rk-table")if not table:raise ValueError("未找到排名表格")#避免解析冗余文本display_headers = correct_headersdata_rows = table.find("tbody").find_all("tr")[:30]if not data_rows:raise ValueError("未提取到数据")print("软科2020中国大学排名(前30名)")print(f"{display_headers[0]:<5}\t{display_headers[1]:<12}\t{display_headers[2]:<4}\t{display_headers[3]:<6}\t{display_headers[4]}")print("-" * 80)for row in data_rows:cols = row.find_all("td")[:5]if len(cols) < 5:continuerank = cols[0].get_text(strip=True)school_name = re.sub(r'[^\u4e00-\u9fa5]', '', cols[1].get_text(strip=True))province = cols[2].get_text(strip=True)school_type = cols[3].get_text(strip=True)total_score = cols[4].get_text(strip=True)#格式化输出print(f"{rank:<5}\t{school_name:<12}\t{province:<4}\t{school_type:<6}\t{total_score}")except requests.exceptions.RequestException as e:print(f"网络错误:{e}")except Exception as e:print(f"解析错误:{e}")if __name__ == "__main__":crawl_university_ranking_optimized()
运行结果:

心得体会:
在开发这个大学排名爬虫的过程中,我遇到了几个颇具启发性的技术难题。最初在数据提取阶段,我发现学校名称字段中混杂了各类非中文字符,这促使我深入研究Unicode编码范围,最终采用正则表达式精准过滤出纯中文内容,这个经历让我认识到数据清洗在信息抓取中的关键作用。
在结果展示环节,我花费了大量时间调整输出格式。由于中英文字符宽度差异,简单的制表符无法实现完美的列对齐,经过反复试验格式化字符串的宽度参数,才找到各列最合适的显示比例。这个过程让我体会到,即使是命令行程序,良好的视觉呈现也能显著提升用户体验。
最值得反思的是异常处理的设计。在初期版本中,当网页结构发生微小变动时,程序就会直接崩溃。这个教训让我意识到防御性编程的重要性,后续我为每个DOM查询操作都添加了健壮性检查,确保在页面结构发生变化时能够优雅降级而非彻底失效。
这些实践中的挑战让我深刻理解到,一个成熟的爬虫项目不仅需要关注核心的数据抓取功能,更要考虑数据质量、输出效果和系统稳定性等多个维度。每个技术难点的突破,都让我对软件开发的全流程有了更全面的认知。
作业2:
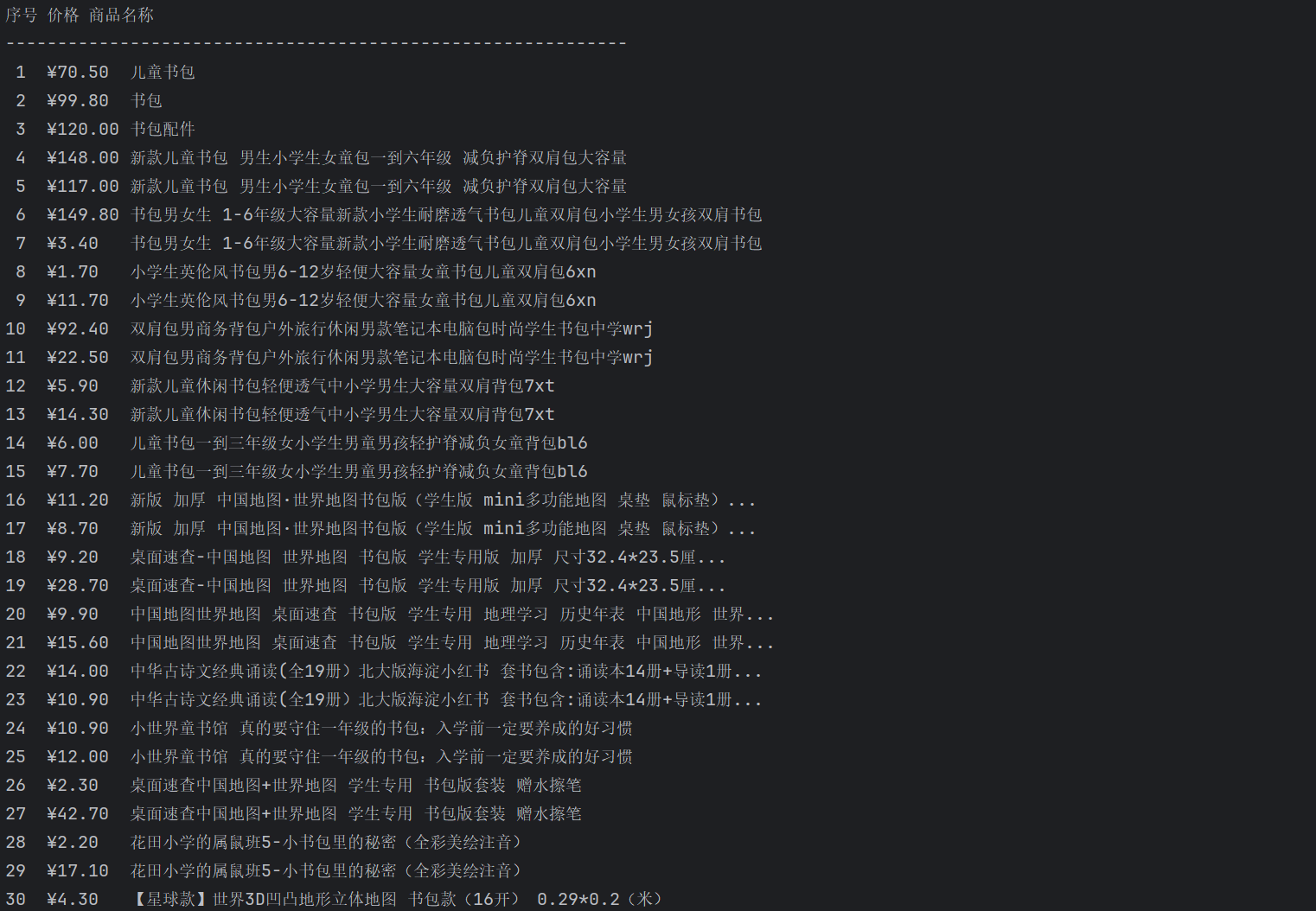
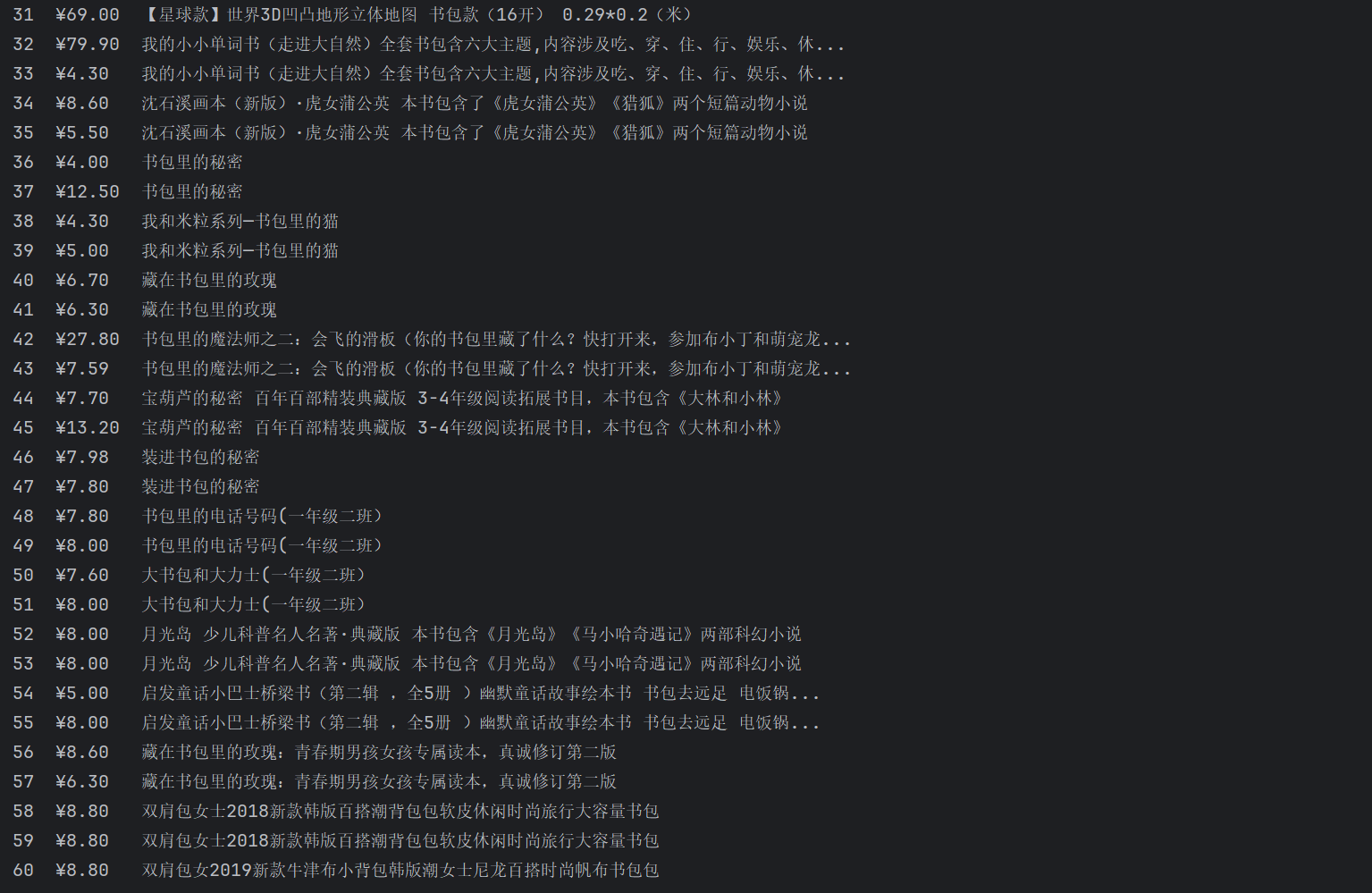
要求:用requests和re库方法设计某个商城(自已选择)商品比价定向爬虫,爬取该商城,以关键词“书包”搜索页面的数据,爬取商品名称和价格。
输出信息:
| 序号 | 价格 | 商品名 |
|---|---|---|
| 1 | 65.00 | xxx |
| 2 | .... | .... |
代码:
点击查看代码
import urllib3
import rehttp = urllib3.PoolManager()
def crawl_dangdang():url = "https://search.dangdang.com/?key=书包&act=input"#发送HTTP请求response = http.request('GET', url, headers={"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36"}, timeout=15)html_content = response.data.decode('gbk', errors='ignore')#提取商品名称names = re.findall(r'title="([^"]*书包[^"]*)"', html_content)names = [name.strip() for name in names if name.strip()][:60]#提取价格prices = []price_patterns = [r'<span class="price_n">¥([\d.]+)</span>',r'<span class="search_now_price">¥([\d.]+)</span>',r'<span[^>]*>\s*¥\s*([\d.]+)\s*</span>',r'¥\s*(\d+\.?\d*)']for pattern in price_patterns:prices = re.findall(pattern, html_content)if prices:prices = [f"¥{p}" for p in prices][:60]break# 输出结果print("序号\t价格\t商品名称")print("-" * 60)for i, (name, price) in enumerate(zip(names, prices), 1):short_name = name[:40] + '...' if len(name) > 40 else nameprint(f"{i:2d}\t{price}\t{short_name}")if __name__ == "__main__":crawl_dangdang()
运行结果:
心得体会:
在项目技术选型过程中,我曾将淘宝、京东等主流电商平台作为首要目标,但这些平台均配备了完善的反爬虫机制,需要处理复杂的Cookie动态维护、请求头全链路伪装以及JavaScript动态渲染等高级技术难题,这已超出我的技术范畴。经过在技术社区的多方调研,我在小红书等平台了解到当当网采用相对宽松的反爬策略,其服务端渲染模式使得基础HTTP请求即可获取完整的页面数据,数据结构清晰且稳定。基于对自身技术能力的客观评估和项目周期的现实考量,我最终选择以反爬门槛较低的当当网作为数据源,在保证项目可行性的同时,确保在有限开发资源下实现数据采集的稳定性和可维护性。
作业2:
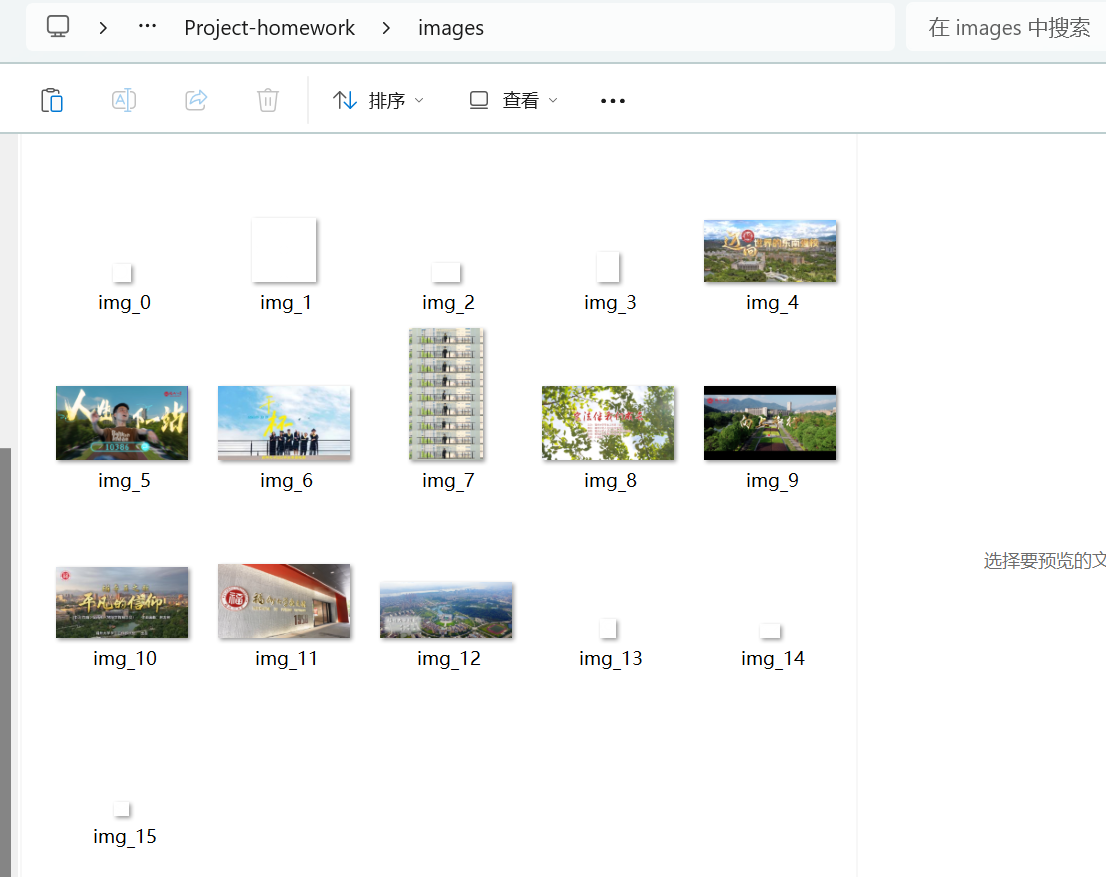
要求:爬取一个给定网页(https://news.fzu.edu.cn/yxfd.htm) 或者自选网页的所有JPEG、JPG或PNG格式图片文件
输出信息:将自选网页内的所有JPEG、JPG或PNG格式文件保存在一个文件夹中
代码:
点击查看代码
import os
import re
import requests
from urllib.parse import urljoindef crawl_fzu_news():"""爬取福州大学新闻网图片"""url = 'https://news.fzu.edu.cn/yxfd.htm'response = requests.get(url, headers={'User-Agent': 'Mozilla/5.0'}, timeout=10)html = response.content.decode('utf-8', errors='ignore')img_urls = re.findall(r'<img.*?src="(.*?)"', html, re.IGNORECASE)valid_imgs = []for src in img_urls:if 'icon' in src.lower() or 'logo' in src.lower():continuefull_url = urljoin(url, src)if re.search(r'\.(jpg|jpeg|png)$', full_url, re.IGNORECASE):valid_imgs.append(full_url)#下载图片if not os.path.exists('images'):os.makedirs('images')for i, img_url in enumerate(valid_imgs):try:response = requests.get(img_url, timeout=10)ext = '.jpg' if '.jpeg' in img_url else os.path.splitext(img_url)[1]with open(f'images/img_{i}{ext}', 'wb') as f:f.write(response.content)print(f'下载成功: img_{i}{ext}')except Exception as e:print(f'下载失败 {img_url}: {e}')if __name__ == '__main__':crawl_fzu_news()
运行结果: