
原文:https://mp.weixin.qq.com/s/GLEa3fIc67uX9IK50LDeNw
全文摘要
本文介绍了一种名为Qwen-Image的图像生成基础模型,它在复杂文本渲染和精确图像编辑方面取得了显著进展。为了解决复杂文本渲染的挑战,作者设计了一个全面的数据管道,包括大规模数据收集、过滤、注释、合成和平衡,并采用渐进式训练策略,逐步提高模型对段落级描述的理解能力。此外,为了增强图像编辑的一致性,作者引入了改进的多任务训练范例,将传统的文本到图像(T2I)和文本图像到图像(TI2I)任务与图像到图像(I2I)重建相结合,有效地对齐Qwen2.5-VL和MMDiT之间的潜在表示。实验结果表明,Qwen-Image在多个公共基准测试中表现出色,在一般图像生成和编辑方面具有强大的能力,特别是在中文文本生成方面表现突出,超过了现有最先进的模型。这突显了Qwen-Image的独特地位,作为结合广泛通用能力和卓越文本渲染精度的领先图像生成模型。
论文链接:https://arxiv.org/abs/2508.02324
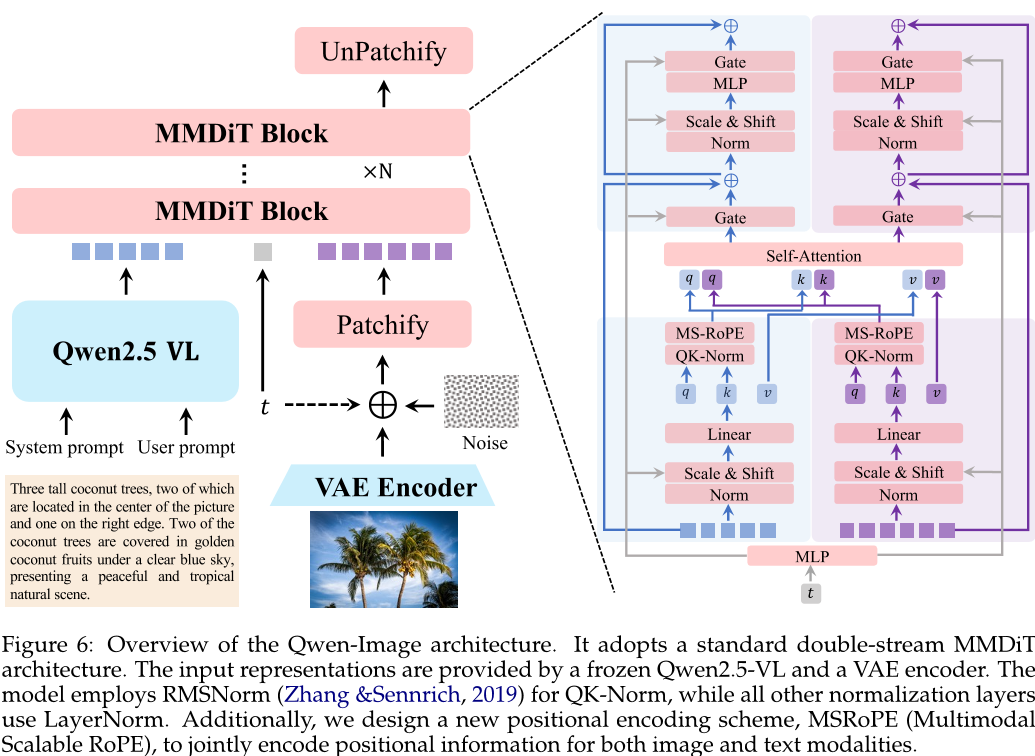


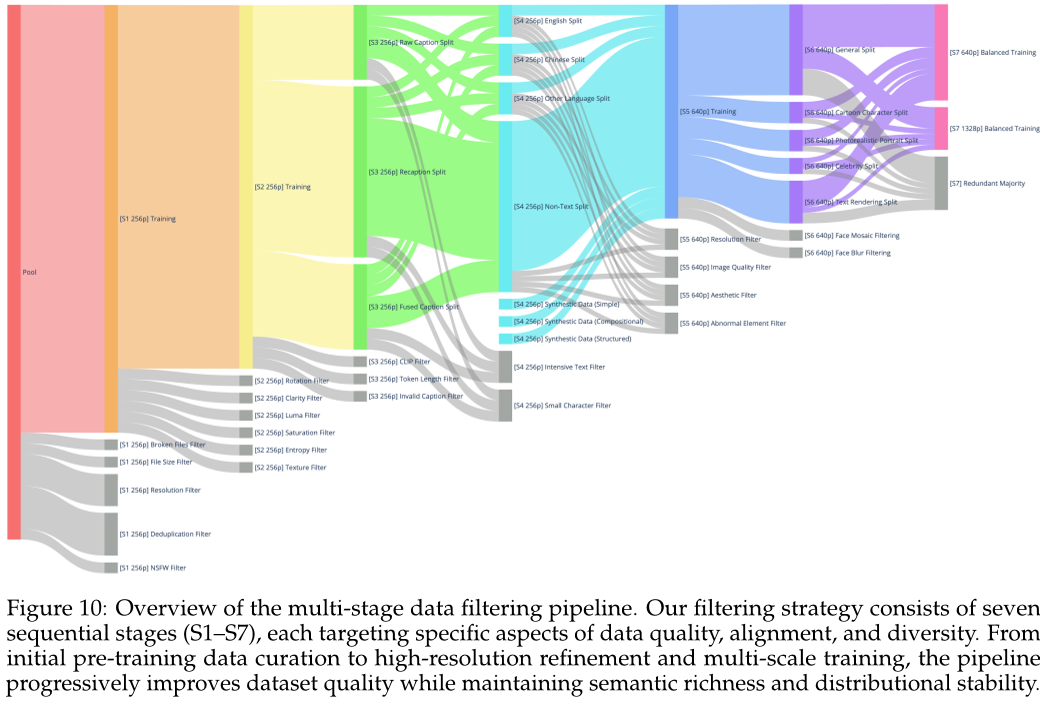
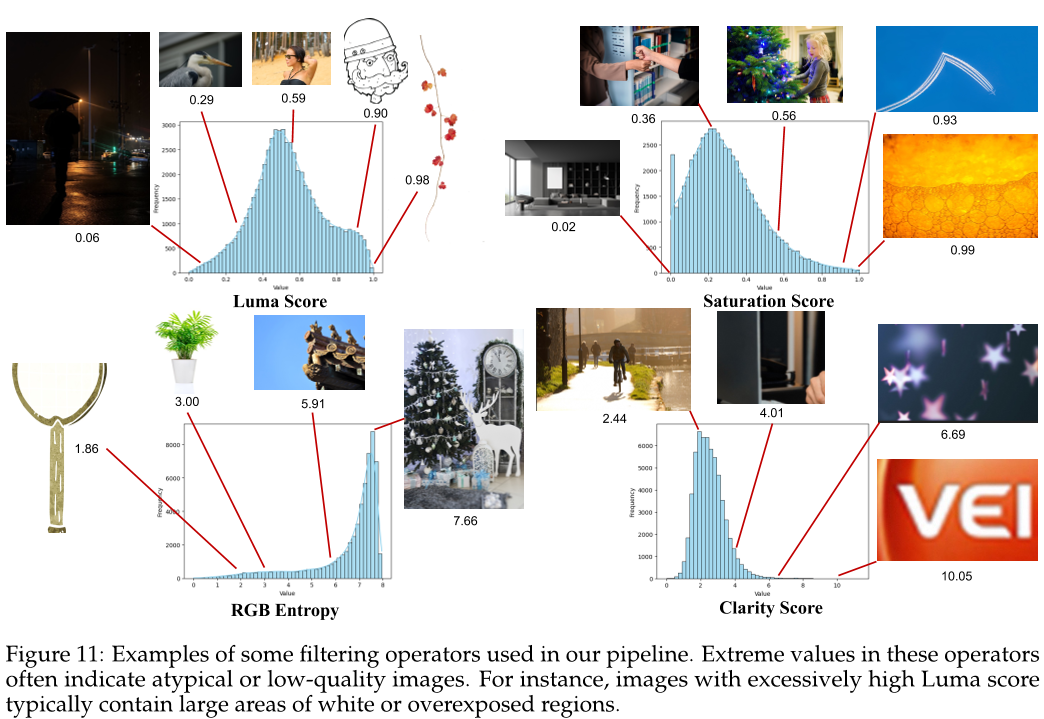
论文方法
方法描述
本文提出的 Qwen-Image 模型采用了多阶段预训练策略,包括增强分辨率、整合文本渲染、精炼数据质量、平衡数据分布以及合成补充数据等五个阶段。同时,在预训练后还进行了监督微调和强化学习两个阶段的训练。在预训练过程中,使用了 Producer-Consumer 框架来实现数据处理与模型训练的分离,并通过混合并行化策略(结合数据并行和张量并行)来提高训练效率。在优化训练过程中,作者采用了分布式优化器和激活检查点技术,并最终选择了分布式优化器作为主要优化手段。此外,为了进一步提升模型性能,作者还扩展了 Qwen-Image 模型以支持多种图像生成任务,如基于指令的图像编辑、新颖视图合成以及计算机视觉任务等。
方法改进
相比于传统的图像生成模型,Qwen-Image 模型采用了多阶段预训练策略,能够逐步提高数据质量和模型性能。同时,使用 Producer-Consumer 框架实现了数据处理与模型训练的分离,提高了训练效率。在优化训练过程中,作者采用了分布式优化器和激活检查点技术,并最终选择了分布式优化器作为主要优化手段。此外,为了进一步提升模型性能,作者还扩展了 Qwen-Image 模型以

论文实验
本文介绍了作者使用Qwen-Image进行的多项实验,并与其他图像生成模型进行了比较。首先,作者通过性能评估来比较了Qwen-Image与五种封闭源代码API的性能差异,结果显示Qwen-Image在重建质量和文本跟随能力方面表现最好。其次,作者对Qwen-Image在文本到图像(T2I)和图像编辑(TI2I)任务上的性能进行了全面评估。在T2I任务中,作者使用四个公开基准测试了Qwen-Image的表现,并与其他领先的模型进行了比较。结果表明,Qwen-Image在多个维度上都表现出色,特别是在多物体生成和空间关系生成方面。在TI2I任务中,作者对Qwen-Image进行了五个方面的定量和定性评估,包括文本和材料编辑、对象添加/删除/替换、姿势操纵、连锁编辑和新颖视图合成等。结果表明,Qwen-Image在多个任务上都表现出色,特别是在文本和材料编辑以及对象添加/删除/替换方面。总之,本文展示了Qwen-Image作为一种强大的开放源代码图像生成模型的能力,可以用于各种视觉生成任务。




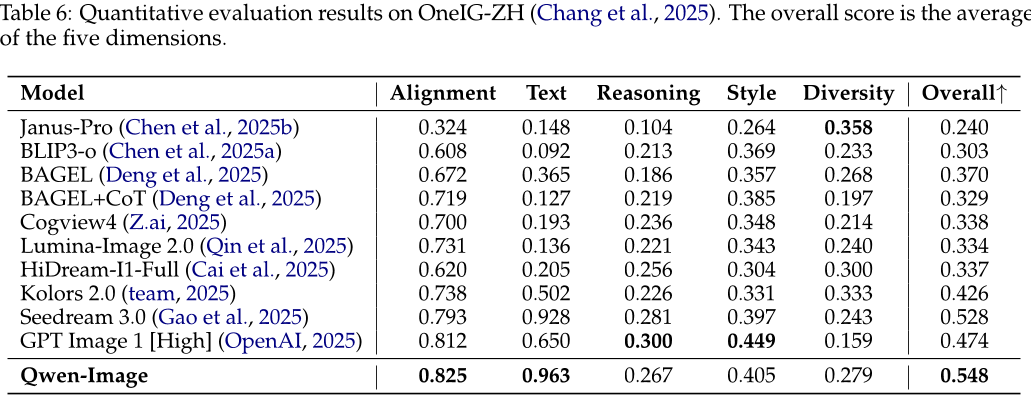
论文总结
文章优点
- Qwen-Image在图像生成领域实现了重大突破,不仅能够实现复杂的文本渲染,还能够在精确编辑方面取得显著进展。
- 通过构建全面的数据管道并采用渐进式课程学习策略,Qwen-Image大大提高了其生成复杂文本的能力。
- 改进了多任务训练范例和双编码机制,显著增强了编辑的一致性和质量,有效地提高了语义连贯性和视觉保真度。
- 在公共基准测试中,Qwen-Image在广泛的图像生成和编辑任务上表现出最先进的性能,标志着大型基础模型演化的里程碑。
方法创新点
- Qwen-Image作为“图像生成”模型,在图像生成中的优先级重新定义了生成建模。它强调文本与图像之间的准确对齐,特别是在具有挑战性的文本渲染任务中。
- Qwen-Image作为“图像”生成模型,在图像理解中展示了生成框架可以有效地执行经典理解任务。例如,在深度估计中,虽然Qwen-Image没有超越专门的歧视模型,但它取得了接近它们的表现。
- Qwen-Image作为“图像”生成模型,在三维和视频生成方面的表现表明其具有超出二维图像合成的强大泛化能力。
- Qwen-Image作为“视觉生成”模型,在集成理解和生成方面的进步推动了感知和创造之间无缝整合的愿景。
未来展望
- Qwen-Image代表了一种新的理念,不仅仅是高级的图像生成模型,而是一种模式转换,如何构思和建立多模态基础模型。
- 它的贡献超出了技术指标,挑战了社区重新思考生成模型在感知、界面设计和认知建模中的角色。
- 通过强调在图像生成中复杂文本渲染的重要性,并通过图像编辑的角度解决经典理解任务如深度估计等,Qwen-Image指向了一个未来:(1)生成模型不仅仅产生图像,而是真正地理解它们;(2)理解模型不再局限于被动歧视,而是通过内在的生成过程实现理解。
- 随着我们继续扩展和改进这些系统,视觉理解和生成之间的边界将进一步模糊,为真正交互、直观和智能的多模态代理铺平道路。