> 数组:内存布局、越界陷阱、字符数组与字符串区别、多维数组万能拆解法,看完就能搞定连续内存!
一、数组本质:连续内存块
| 变量散定义 | 数组定义 | 内存 guarantee |
|---|---|---|
int a,b,c; |
int a[3]; |
连续 |
| 地址随机 | 元素依次排布 | 可指针偏移 |
语法释义:
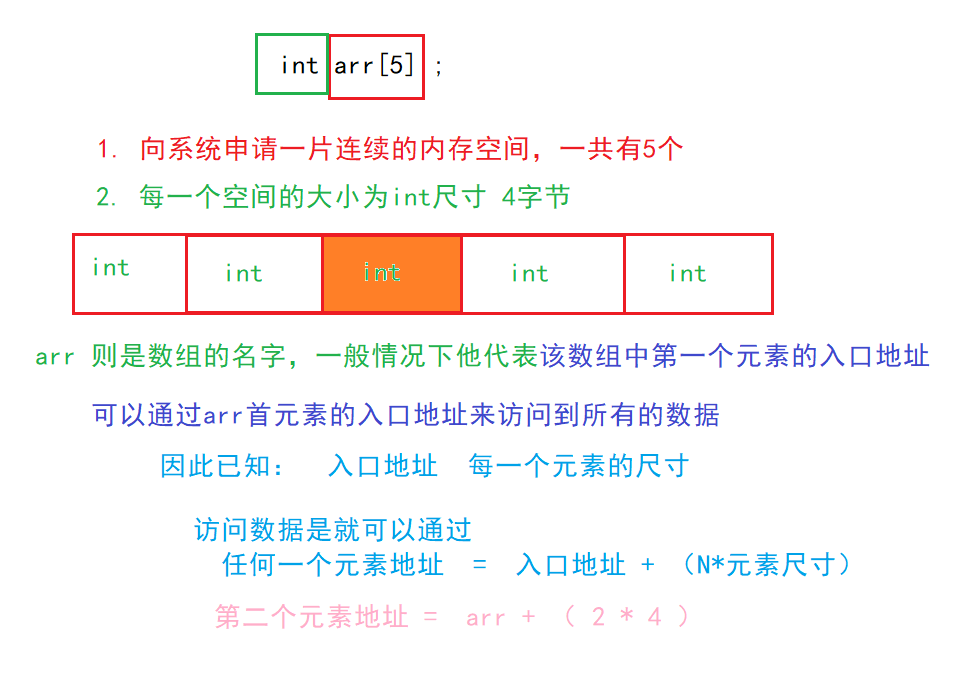
- arr 是数组名,即这片连续内存的名称
- [5] 代表这片连续内存总共分成5个相等的格子,每个格子称为数组的元素
- int 代表每个元素的类型,可以是任意基本类型,也可以是组合类型,甚至可以是数组
int arr[5]; // 地址:arr ≡ &arr[0]
printf("%p %p\n", arr, &arr[0]); // 值完全相同
二、定义 · 初始化 · 越界
| 写法 | 是否合法 | 初始值 | 备注 |
|---|---|---|---|
int a[5]; |
✅ | 随机 | 局部变量 |
int a[5] = {1,2,3}; |
✅ | 1,2,3,0,0 | 不完全初始化补0 |
int a[] = {1,2,3,4,5}; |
✅ | 1~5 | 编译器自动计数 |
int a[3] = {1,2,3,4,5}; |
❌ | 警告+丢弃 | 越界初始化 |
int a[0]; |
❌/扩展 | GNU扩展 | 零长数组,仅GNU可用 |
口诀:定义必须给长度,初始化可省略,越界编译阶段就报警
三、访问与越界演示
- 越界访问
int a[5] = {10,20,30,40,50};
a[5] = 99; // 越界!C不会报错,但行为未定义
- 实验: 越界可能篡改相邻变量
int a[3] = {1,2,3};
int x = 10;
a[3] = 100; // 越界写入,x 可能被改成100
printf("x=%d\n", x);

运行结果不确定,取决于编译器布局——千万别这么干!
四、字符数组 vs 字符串
| 定义 | 内存布局 | 可读写 | 长度/结尾 |
|---|---|---|---|
char s[] = "abc"; |
栈数组{'a','b','c','\0'} |
✅ | 自动补\0 |
char *s = "abc"; |
指向只读常量区 | ❌ | 自动补\0 |
char s[3] = {'a','b','c'}; |
无\0 |
✅ | 纯字符数组,不是字符串 |
char s1[] = "abc"; // sizeof(s1)=4
char *s2 = "abc"; // sizeof(s2)=8(64位指针)
结论: 要可修改字符串,请用字符数组;要只读、省内存,用字符指针指向常量。
- 实际应用示例
#include <stdio.h>int main(void)
{// 字符数组 - 可修改char str1[] = "Hello";str1[0] = 'h'; // ✅ 正确:修改栈上的数组printf("%s\n", str1); // hello// 字符指针 - 只读char *str2 = "World";// str2[0] = 'w'; // ❌ 错误:段错误,试图修改常量区// 纯字符数组 - 无结束符char str3[3] = {'a','b','c'};printf("%zu\n", sizeof(str3)); // 3// printf("%s\n", str3); // ❌ 危险:可能越界读取return 0;
}
五、多维数组:二维就是「数组的数组」
1. 定义与初始化
int a[2][3] = { // 2行3列{1, 2, 3}, // a[0][0] a[0][1] a[0][2]{4, 5, 6} // a[1][0] a[1][1] a[1][2]
};
2. 内存排布:行主序(Row-Major)
地址低 → 高
|1|2|3|4|5|6|连续 12 字节
3. 可以省略「最高维」
int a[][3] = { // 编译器数行{1,2,3},{4,5,6},{7,8,9} // 自动推断为 int[3][3]
};
错误示例: nint a[2][] = {...}; ❌ 编译器无法推断列数
4. 遍历二维数组
// 遍历二维数组
int matrix[2][3] = {{1,2,3}, {4,5,6}};
for (int i = 0; i < 2; i++) {for (int j = 0; j < 3; j++) {printf("matrix[%d][%d] = %d\n", i, j, matrix[i][j]);}
}
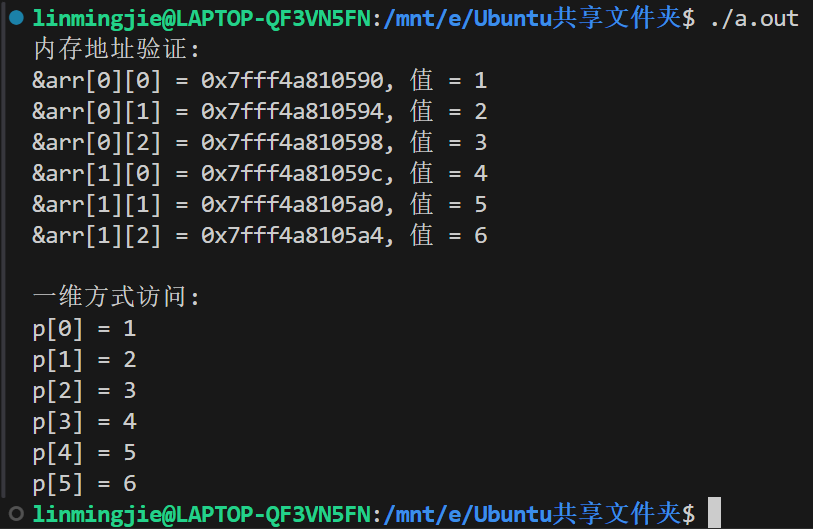
5. 连续内存验证实验
#include <stdio.h>int main(void)
{int arr[2][3] = {{1,2,3}, {4,5,6}};// 验证连续内存printf("内存地址验证:\n");for (int i = 0; i < 2; i++) {for (int j = 0; j < 3; j++) {printf("&arr[%d][%d] = %p, 值 = %d\n", i, j, &arr[i][j], arr[i][j]);}}// 用一维方式访问int *p = &arr[0][0];printf("\n一维方式访问:\n");for (int i = 0; i < 6; i++) {printf("p[%d] = %d\n", i, p[i]);}return 0;
}
- 运行示例
六、万能拆解法:任何数组 = 「元素类型」+ 「数组名[个数]」
| 原始声明 | 拆解步骤 | 元素类型 | 数组部分 |
|---|---|---|---|
int a[4]; |
int a[4] |
整型 | 一维整型数组 |
int b[3][4]; |
int [4] b[3] |
4元素整型数组 | 3 个「int[4]」 |
int *c[6]; |
int * c[6] |
整型指针 | 6 个「整型指针」 |
int (*d[7])(int,float); |
int(*)(int,float) d[7] |
函数指针 | 7 个「函数指针」 |
口诀:去掉「数组名[个数]」剩下的就是元素类型;多维从最外层开始拆。
拆解步骤详解
示例1: int a[4];
- 去掉
a[4]→ 剩下int - 元素类型:
int - 数组:4个整型元素的数组
示例2: int b[3][4];
- 去掉
b[3]→ 剩下int [4] - 元素类型:
int [4](4元素整型数组) - 数组:3个「int[4]」的数组
示例3: int *c[6];
- 去掉
c[6]→ 剩下int * - 元素类型:
int *(整型指针) - 数组:6个整型指针的数组
示例4: int (*d[7])(int,float);
- 去掉
d[7]→ 剩下int (*)(int,float) - 元素类型:
int (*)(int,float)(函数指针) - 数组:7个函数指针的数组
实际应用
#include <stdio.h>// 函数声明
int add(int a, float b) { return a + (int)b; }
int sub(int a, float b) { return a - (int)b; }int main(void)
{// 应用万能拆解法int a[4] = {1,2,3,4}; // 4个int的数组int b[3][4] = {{1,2,3,4}, {5,6,7,8}, {9,10,11,12}}; // 3个int[4]的数组int x = 10, y = 20, z = 30;int *c[6] = {&x, &y, &z, NULL, NULL, NULL}; // 6个int*的数组int (*d[7])(int,float) = {add, sub, NULL}; // 7个函数指针的数组printf("a[2] = %d\n", a[2]);printf("b[1][2] = %d\n", b[1][2]);printf("*c[1] = %d\n", *c[1]);printf("d[0](5, 2.5) = %d\n", d[0](5, 2.5));return 0;
}
记忆技巧:
-
从标识符开始,向右看直到遇到右括号,再向左看
-
[]优先级高于*,所以int *p[5]是指针数组,int (*p)[5]是数组指针 -
复杂声明可以从内向外层层剥离
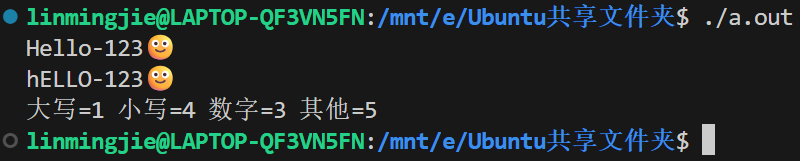
七、综合实战:字符统计 + 大小写翻转
功能:
- 读取一行字符
- 统计大写、小写、数字、其他
- 把大写转小写、小写转大写后输出
#include <stdio.h>
#include <ctype.h>#define MAX 128int main(void)
{char buf[MAX];int upper = 0, lower = 0, digit = 0, other = 0;/* 1. 读取一行 */fgets(buf, MAX, stdin);/* 2. 遍历统计 + 翻转 */for (int i = 0; buf[i] != '\0' && buf[i] != '\n'; ++i) {char ch = buf[i];if (isupper(ch)) { ++upper; putchar(tolower(ch)); // 大→小,使用tolower更安全}else if (islower(ch)) { ++lower; putchar(toupper(ch)); // 小→大,使用toupper更安全}else if (isdigit(ch)) { ++digit; putchar(ch); }else { ++other; putchar(ch); }}putchar('\n');/* 3. 结果 */printf("大写=%d 小写=%d 数字=%d 其他=%d\n", upper, lower, digit, other);return 0;
}
运行示例: