 解决了Typora 笔记迁移 Obsidian 图片链接转换问题,实现了自动化`---->![[Pasted image 20221223164738.png]]`
解决了Typora 笔记迁移 Obsidian 图片链接转换问题,实现了自动化`---->![[Pasted image 20221223164738.png]]`附件:Typora 笔记迁移 Obsidian 图片链接转换
需求
将typora笔记库迁移到Obsidian,但是typora的图片使用的是严格markdown ![](),Obsidian是wiki ![[]]。
笔记库文件夹下面有超级多的.md笔记,手动操作太慢了,因此采用Python进行处理,进行批量修改文章链接格式。
---->![[Pasted image 20221223164738.png]]
由于Obsidian是wiki ![[]] 因此后面采用程序或手动方式,将所有的图片移动到Obsidian仓库下指定图片文件夹即可,例如asset
思路
1、检测该链接是否为图片?
3、替换``为`![[任意内容]`---->`![[Pasted image 20221223164738.png]`
实践
备份整个目标文件夹,打压缩!拷贝该文件夹副本进行操作。
参考目录
|-- 转换
| |-- typora_to_obsidian.py
| `-- 综合软件使用教程 # 目标文件夹
| |-- Database
安装python,网上教程很多,不再赘述。
-
保存脚本: 将下面的代码保存为一个
.py文件,例如rename_md.py。 -
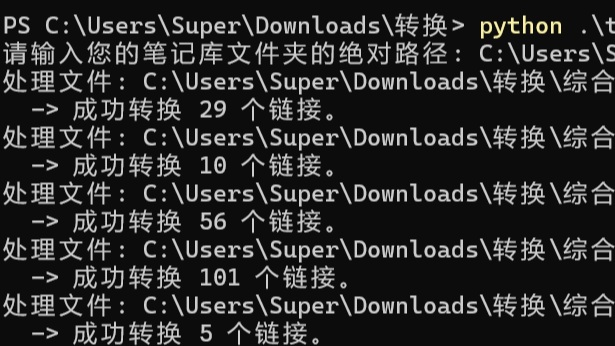
运行脚本: 打开终端或命令行工具,进入你保存脚本的目录,然后运行它:
typora_to_obsidian.py程序会提示您输入笔记库的文件夹路径。只需将文件夹的绝对路径复制粘贴进去,然后按回车键即可。

-
检查结果: 脚本会自动扫描该文件夹及其所有子文件夹中的
.md文件,并完成链接的替换。处理过程会显示在终端中。
检查
谨慎一下,要进行检查,打开修改后的任意.md笔记,在typora中进行正则表达式查找:
!\[([^\[\]]*)\]\(([^()]*)(\s+["'].*?["'])?\) 可见,下面没有被替换的均为网络链接格式和示范笔记。
手动将转换成功的.md笔记移动到Obsidian笔记库中的新的位置。
采用程序或手动方式,将所有的图片移动到Obsidian仓库下指定图片文件夹即可,例如asset
打开一篇笔记,可见正常显示。

因此,本次转换图片链接操作成功!

代码
Python代码
import os
import re
import sysdef convert_image_links(directory):"""遍历指定目录下的所有 Markdown 文件,并将 Typora 格式的图片链接转换为 Obsidian 格式。Typora 格式 1: Typora 格式 2: Obsidian 格式: ![[image.png]]"""# 支持常见的图片文件扩展名image_extensions = ['png', 'jpg', 'jpeg', 'gif', 'bmp', 'svg', 'webp']# 构建正则表达式,用于匹配 Typora 的图片链接# 解释:# !\[.*?\]\( : 匹配 "? : 匹配并忽略路径部分 (e.g., "./Database/")。# (?:...) 是一个非捕获组。# .* 表示任意字符,/ 是路径分隔符。? 表示路径是可选的。# (.*?) : 捕获图片文件名 (非贪婪模式)。这是我们需要的核心内容。# \. : 匹配文件名和扩展名之间的点。# ({}) : 将支持的图片扩展名插入正则表达式。# \) : 匹配最后的 ")"pattern_str = r'!\[.*?\]\((?:.*/)?(.*?\.({}))\)'.format('|'.join(image_extensions))# 添加 re.IGNORECASE 标志以忽略扩展名的大小写image_pattern = re.compile(pattern_str, re.IGNORECASE)# 遍历指定目录for root, _, files in os.walk(directory):for filename in files:if filename.endswith('.md'):file_path = os.path.join(root, filename)try:with open(file_path, 'r', encoding='utf-8') as f:content = f.read()# 使用正则表达式查找并替换所有匹配的链接# sub 函数的第二个参数 r'![[\1]]' 中的 \1 代表正则表达式中第一个捕获组的内容,# 也就是我们需要的图片文件名 (e.g., "image-20250726104501340.png")new_content, num_replacements = image_pattern.subn(r'![[\1]]', content)if num_replacements > 0:# 如果发生了替换,则将新内容写回文件with open(file_path, 'w', encoding='utf-8') as f:f.write(new_content)print(f"处理文件: {file_path}")print(f" -> 成功转换 {num_replacements} 个链接。")except Exception as e:print(f"处理文件 {file_path} 时出错: {e}", file=sys.stderr)print("\n所有文件处理完毕!")if __name__ == '__main__':# 提示用户输入要处理的文件夹路径# 在 Windows 上,你可以直接复制文件夹路径,例如: C:\Users\YourName\Documents\MyNotes# 在 macOS 或 Linux 上,路径类似: /Users/YourName/Documents/MyNotestarget_directory = input("请输入您的笔记库文件夹的绝对路径: ")if os.path.isdir(target_directory):convert_image_links(target_directory)else:print("错误: 您输入的不是一个有效的文件夹路径。", file=sys.stderr)正则表达式代码
!\[([^\[\]]*)\]\(([^()]*)(\s+["'].*?["'])?\)
这个正则表达式 !\[([^\[\]]*)\]\(([^()]*)(\s+["'].*?["'])?\) 是用来精确匹配并提取标准 Markdown 格式的图片链接的各个部分的。
整体结构
这个表达式匹配的完整格式是: 
它被分成了几个主要部分来分别捕获 alt text (替代文本)、 image_path (图片路径) 和 optional title (可选的标题)。
各部分详解
| 正则表达式部分 | 含义解释 |
|---|---|
! |
匹配一个字面量的感叹号 !,这是 Markdown 图片语法的起始标志。 |
\[ |
匹配一个字面量的左方括号 [。因为 [ 是元字符,所以需要用 \ 来转义。 |
([^\[\]]*) |
第一个捕获组 (Group 1): • (...):定义一个捕获组,用于提取括号内的匹配内容。 • [...]:定义一个字符集。 • ^:在字符集 [] 内部表示“非”,即匹配任何不包含在后面的字符。 • \[\]:这里指的是 [ 和 ] 这两个字符。 • *:表示匹配前面的字符集零次或多次。 作用:捕获方括号 [] 之间的所有内容,即图片的 替代文本 (alt text)。 |
\] |
匹配一个字面量的右方括号 ]。 |
\( |
匹配一个字面量的左圆括号 (。 |
([^()]*) |
第二个捕获组 (Group 2): • (...):定义捕获组。 • [^()]:匹配任何不是 ( 也不是 ) 的字符。 • *:匹配零次或多次。 作用:捕获圆括号 () 之间的内容,即图片的 路径或URL (image_path)。 |
(\s+["'].*?["'])? |
第三个捕获组 (Group 3),且为可选部分: • (...):定义捕获组。 • ?:表示整个第三个捕获组是可选的(可以出现0次或1次)。 • \s+:匹配一个或多个空白字符(如空格)。 • ["']:匹配一个双引号 " 或一个单引号 '。 • .*?:非贪婪匹配。匹配任意字符 (.) 零次或多次 (*),但尽可能少地匹配 (?),直到遇到下一个模式。 • ["']:匹配一个结束的双引号 " 或单引号 '。 作用:捕获可选的图片标题 (title),它由空格和引号包围。 |
\) |
匹配一个字面量的右圆括号 )。 |
总结
!\[ ... \]: 匹配![alt text]的框架。(...): 括号内的部分是捕获组,意味着在查找替换时,你可以用$1,$2,$3(或\1,\2,\3,取决于具体工具) 来引用这些捕获到的内容。$1对应([^\[\]]*),即图片的替代文本。$2对应([^()]*),即图片的路径。$3对应(\s+["'].*?["'])?,即可选的、带引号的标题。
这个正则表达式可以准确地处理包含或不包含可选标题的各类标准 Markdown 图片链接,同时避免错误匹配嵌套的括号或格式不规范的文本。
注意事项
- 备份: 强烈建议在运行此脚本前,先备份你的整个文件夹。 文件重命名是一个不可逆的操作,以防万一出现非预期的结果。
参考
- [wiki链接和markdown链接 对比 互相转换](https://garden.czchx.cc/czc知识库/笔记/知识库搭建/1-obsidian笔记/子/wiki链接和markdown链接 对比 互相转换/)
- PKMer_Wiki 链接和 markdown 链接之间的转换
- 一文搞懂正则表达式 - 知乎