DAY 43 复习日
作业:
kaggle找到一个图像数据集,用cnn网络进行训练并且用grad-cam做可视化
@浙大疏锦行
数据集使用猫狗数据集,训练集中包含猫图像4000张、狗图像4005张。测试集包含猫图像1012张,狗图像1013张。以下是数据集的下载地址。
猫和狗 --- Cat and Dog
1.数据集加载与数据预处理
我这里对数据集文件路径做了改变
C:\Users\vijay\Desktop\1\
├── train\
│ ├── cats\
│ └── dogs\
└── test\
├── cats\
└── dags\
import torchimport torch.nn as nnimport torch.optim as optimfrom torchvision import datasets, transforms, modelsfrom torch.utils.data import DataLoaderimport matplotlib.pyplot as pltimport numpy as npimport torch.nn.functional as F # 设置随机种子确保结果可复现torch.manual_seed(42)np.random.seed(42) # 设置中文字体支持plt.rcParams["font.family"] = ["SimHei"]plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题 # 检查GPU是否可用device = torch.device("cuda" if torch.cuda.is_available() else "cpu")print(f"使用设备: {device}") # 1. 数据预处理# 训练集:使用多种数据增强方法提高模型泛化能力train_transform = transforms.Compose([ # 新增:调整图像大小为统一尺寸 transforms.Resize((32, 32)), # 确保所有图像都是32x32像素 transforms.RandomCrop(32, padding=4), transforms.RandomHorizontalFlip(), transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2, hue=0.1), transforms.RandomRotation(15), transforms.ToTensor(), transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))]) # 测试集:仅进行必要的标准化,保持数据原始特性test_transform = transforms.Compose([ # 新增:调整图像大小为统一尺寸 transforms.Resize((32, 32)), # 确保所有图像都是32x32像素 transforms.ToTensor(), transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))]) # 定义数据集根目录root = r'C:\Users\vijay\Desktop\1' train_dataset = datasets.ImageFolder( root=root + '/train', # 指向 train 子文件夹 transform=train_transform)test_dataset = datasets.ImageFolder( root=root + '/test', # 指向 test 子文件夹 transform=test_transform) # 打印类别信息,确认数据加载正确print(f"训练集类别: {train_dataset.classes}")print(f"测试集类别: {test_dataset.classes}") # 3. 创建数据加载器batch_size = 64train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)2.模型训练与评估
# 定义一个简单的CNN模型class SimpleCNN(nn.Module): def __init__(self): super(SimpleCNN, self).__init__() # 第一个卷积层,输入通道为3(彩色图像),输出通道为32,卷积核大小为3x3,填充为1以保持图像尺寸不变 self.conv1 = nn.Conv2d(3, 32, kernel_size=3, padding=1) # 第二个卷积层,输入通道为32,输出通道为64,卷积核大小为3x3,填充为1 self.conv2 = nn.Conv2d(32, 64, kernel_size=3, padding=1) # 第三个卷积层,输入通道为64,输出通道为128,卷积核大小为3x3,填充为1 self.conv3 = nn.Conv2d(64, 128, kernel_size=3, padding=1) # 最大池化层,池化核大小为2x2,步长为2,用于下采样,减少数据量并提取主要特征 self.pool = nn.MaxPool2d(2, 2) # 第一个全连接层,输入特征数为128 * 4 * 4(经过前面卷积和池化后的特征维度),输出为512 self.fc1 = nn.Linear(128 * 4 * 4, 512) # 第二个全连接层,输入为512,输出为2(对应猫和非猫两个类别) self.fc2 = nn.Linear(512, 2) def forward(self, x): # 第一个卷积层后接ReLU激活函数和最大池化操作,经过池化后图像尺寸变为原来的一半,这里输出尺寸变为16x16 x = self.pool(F.relu(self.conv1(x))) # 第二个卷积层后接ReLU激活函数和最大池化操作,输出尺寸变为8x8 x = self.pool(F.relu(self.conv2(x))) # 第三个卷积层后接ReLU激活函数和最大池化操作,输出尺寸变为4x4 x = self.pool(F.relu(self.conv3(x))) # 将特征图展平为一维向量,以便输入到全连接层 x = x.view(-1, 128 * 4 * 4) # 第一个全连接层后接ReLU激活函数 x = F.relu(self.fc1(x)) # 第二个全连接层输出分类结果 x = self.fc2(x) return x # 初始化模型model = SimpleCNN()print("模型已创建") # 如果有GPU则使用GPU,将模型转移到对应的设备上model = model.to(device) # 训练模型def train_model(model, train_loader, test_loader, epochs=10): # 定义损失函数为交叉熵损失,用于分类任务 criterion = nn.CrossEntropyLoss() # 定义优化器为Adam,用于更新模型参数,学习率设置为0.001 optimizer = torch.optim.Adam(model.parameters(), lr=0.001) for epoch in range(epochs): # 训练阶段 model.train() running_loss = 0.0 correct = 0 total = 0 for i, data in enumerate(train_loader, 0): # 从数据加载器中获取图像和标签 inputs, labels = data # 将图像和标签转移到对应的设备(GPU或CPU)上 inputs, labels = inputs.to(device), labels.to(device) # 清空梯度,避免梯度累加 optimizer.zero_grad() # 模型前向传播得到输出 outputs = model(inputs) # 计算损失 loss = criterion(outputs, labels) # 反向传播计算梯度 loss.backward() # 更新模型参数 optimizer.step() running_loss += loss.item() _, predicted = outputs.max(1) total += labels.size(0) correct += predicted.eq(labels).sum().item() if i % 100 == 99: # 每100个批次打印一次平均损失和准确率 print(f'[{epoch + 1}, {i + 1}] 损失: {running_loss / 100:.3f} | 准确率: {100.*correct/total:.2f}%') running_loss = 0.0 # 测试阶段 model.eval() test_loss = 0 correct = 0 total = 0 with torch.no_grad(): for data in test_loader: images, labels = data images, labels = images.to(device), labels.to(device) outputs = model(images) test_loss += criterion(outputs, labels).item() _, predicted = outputs.max(1) total += labels.size(0) correct += predicted.eq(labels).sum().item() print(f'测试集 [{epoch + 1}] 损失: {test_loss/len(test_loader):.3f} | 准确率: {100.*correct/total:.2f}%') print("训练完成") return model # 训练模型try: # 尝试加载预训练模型(如果存在) model.load_state_dict(torch.load('cat_classifier.pth')) print("已加载预训练模型")except: print("无法加载预训练模型,训练新模型") model = train_model(model, train_loader, test_loader, epochs=10) # 保存训练后的模型参数 torch.save(model.state_dict(), 'cat_classifier.pth') # 设置模型为评估模式model.eval()
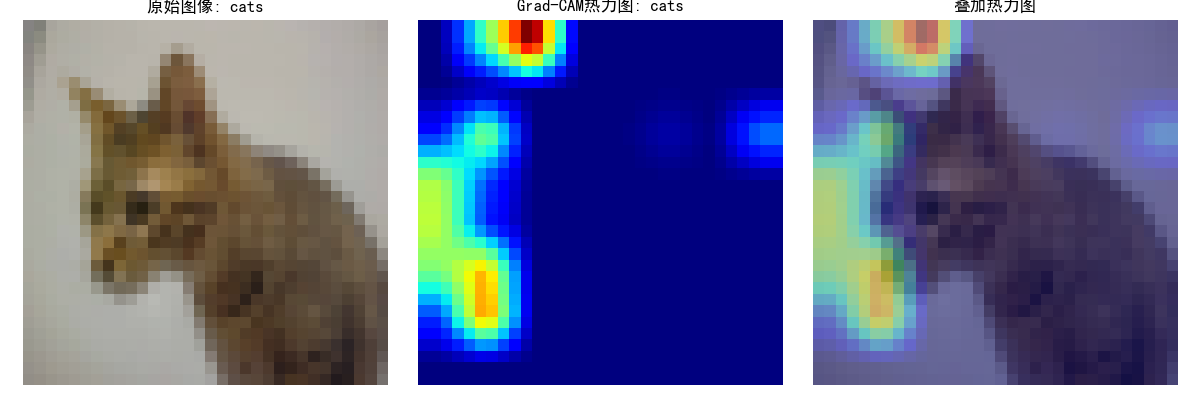
3. Grad-CAM实现
# Grad-CAM实现class GradCAM: def __init__(self, model, target_layer): self.model = model self.target_layer = target_layer self.gradients = None self.activations = None # 注册钩子,用于获取目标层的前向传播输出和反向传播梯度 self.register_hooks() def register_hooks(self): # 前向钩子函数,在目标层前向传播后被调用,保存目标层的输出(激活值) def forward_hook(module, input, output): self.activations = output.detach() # 反向钩子函数,在目标层反向传播后被调用,保存目标层的梯度 def backward_hook(module, grad_input, grad_output): self.gradients = grad_output[0].detach() # 在目标层注册前向钩子和反向钩子 self.target_layer.register_forward_hook(forward_hook) self.target_layer.register_backward_hook(backward_hook) def generate_cam(self, input_image, target_class=None): # 前向传播,得到模型输出 model_output = self.model(input_image) if target_class is None: # 如果未指定目标类别,则取模型预测概率最大的类别作为目标类别 target_class = torch.argmax(model_output, dim=1).item() # 清除模型梯度,避免之前的梯度影响 self.model.zero_grad() # 反向传播,构造one-hot向量,使得目标类别对应的梯度为1,其余为0,然后进行反向传播计算梯度 one_hot = torch.zeros_like(model_output) one_hot[0, target_class] = 1 model_output.backward(gradient=one_hot) # 获取之前保存的目标层的梯度和激活值 gradients = self.gradients activations = self.activations # 对梯度进行全局平均池化,得到每个通道的权重,用于衡量每个通道的重要性 weights = torch.mean(gradients, dim=(2, 3), keepdim=True) # 加权激活映射,将权重与激活值相乘并求和,得到类激活映射的初步结果 cam = torch.sum(weights * activations, dim=1, keepdim=True) # ReLU激活,只保留对目标类别有正贡献的区域,去除负贡献的影响 cam = F.relu(cam) # 调整大小并归一化,将类激活映射调整为与输入图像相同的尺寸(32x32),并归一化到[0, 1]范围 cam = F.interpolate(cam, size=(32, 32), mode='bilinear', align_corners=False) cam = cam - cam.min() cam = cam / cam.max() if cam.max() > 0 else cam return cam.cpu().squeeze().numpy(), target_class # 可视化Grad-CAM结果的函数import warningswarnings.filterwarnings("ignore")import matplotlib.pyplot as plt# 设置中文字体支持plt.rcParams["font.family"] = ["SimHei"]plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题# 选择一个随机图像# idx = np.random.randint(len(test_dataset))idx = 102 # 选择测试集中的第101张图片 (索引从0开始)image, label = test_dataset[idx]print(f"选择的图像类别: {test_dataset.classes[label]}") # 转换图像以便可视化def tensor_to_np(tensor): img = tensor.cpu().numpy().transpose(1, 2, 0) mean = np.array([0.485, 0.456, 0.406]) std = np.array([0.229, 0.224, 0.225]) img = std * img + mean img = np.clip(img, 0, 1) return img # 添加批次维度并移动到设备input_tensor = image.unsqueeze(0).to(device) # 初始化Grad-CAM(选择最后一个卷积层)grad_cam = GradCAM(model, model.conv3) # 生成热力图heatmap, pred_class = grad_cam.generate_cam(input_tensor) # 可视化plt.figure(figsize=(12, 4)) # 原始图像plt.subplot(1, 3, 1)plt.imshow(tensor_to_np(image))plt.title(f"原始图像: {test_dataset.classes[label]}")plt.axis('off') # 热力图plt.subplot(1, 3, 2)plt.imshow(heatmap, cmap='jet')plt.title(f"Grad-CAM热力图: {test_dataset.classes[pred_class]}")plt.axis('off') # 叠加的图像plt.subplot(1, 3, 3)img = tensor_to_np(image)heatmap_resized = np.uint8(255 * heatmap)heatmap_colored = plt.cm.jet(heatmap_resized)[:, :, :3]superimposed_img = heatmap_colored * 0.4 + img * 0.6plt.imshow(superimposed_img)plt.title("叠加热力图")plt.axis('off') plt.tight_layout()plt.savefig('grad_cam_result.png')plt.show() print("Grad-CAM可视化完成。已保存为grad_cam_result.png")