- DeepSeek-OCR: Contexts Optical Compression
- TL;DR
- Method
- DeepEncoder
- DeepDecoder
- Data
- Experiment
- 总结与思考
- 相关链接
DeepSeek-OCR: Contexts Optical Compression
link
时间:25.10.20
单位:DeepSeek
作者相关工作:Haoran Wei,加入DeepSeek之前在旷视,之前做过Vary。
项目主页:
https://github.com/deepseek-ai/DeepSeek-OCR
TL;DR
探索的任务:通过2D OCR能否压缩long context信息。
模型架构:核心模块包括DeepEncoder与DeepSeek3B-MoE-A570M的Decoder。
- DeepEncoder:将高分辨率的图片压缩为少量视觉token。
- DeepSeek Decoder:输入image tokens + prompts,输出结果
意义:该工作对于long context压缩 以及 记忆遗忘机制 都有巨大的潜力。
Method

DeepEncoder
SAM(80M):输入图像首先由SAM-base进行处理,该模型基于窗口注意力机制,对图像进行细致的视觉特征提取(而非直接出MASK)。
Conv: 两步Conv下采样,将视觉特征编码经过16x下采样进行压缩
CLIP(300M):Image Encoder部分,再将patch embedding层移除
Q:什么是压缩率?
压缩率 = 原始文本token数量 / 使用的视觉token数量
Q:压缩率高有什么好处?
DeepSeekOCR提供一种新文本表示方式,光学编码:将原始文本内容渲染成图像格式。压缩率高,意味着光学编码后,DeepSeek-Encoder编码出的视觉token信息密度比text token还高。在实际应用中,可能不需要专门光学编码,可以是:
- 文档扫描件或截图
- 程序化生成的文本图像
- 现有的文档图像资料
DeepDecoder
- 采用混合专家模型(MoE)设计,共64个专家
- 推理时激活6个路由专家+2个共享专家(约570M激活参数)
- 在保持3B模型表达能力的同时,享受500M小模型的推理效率
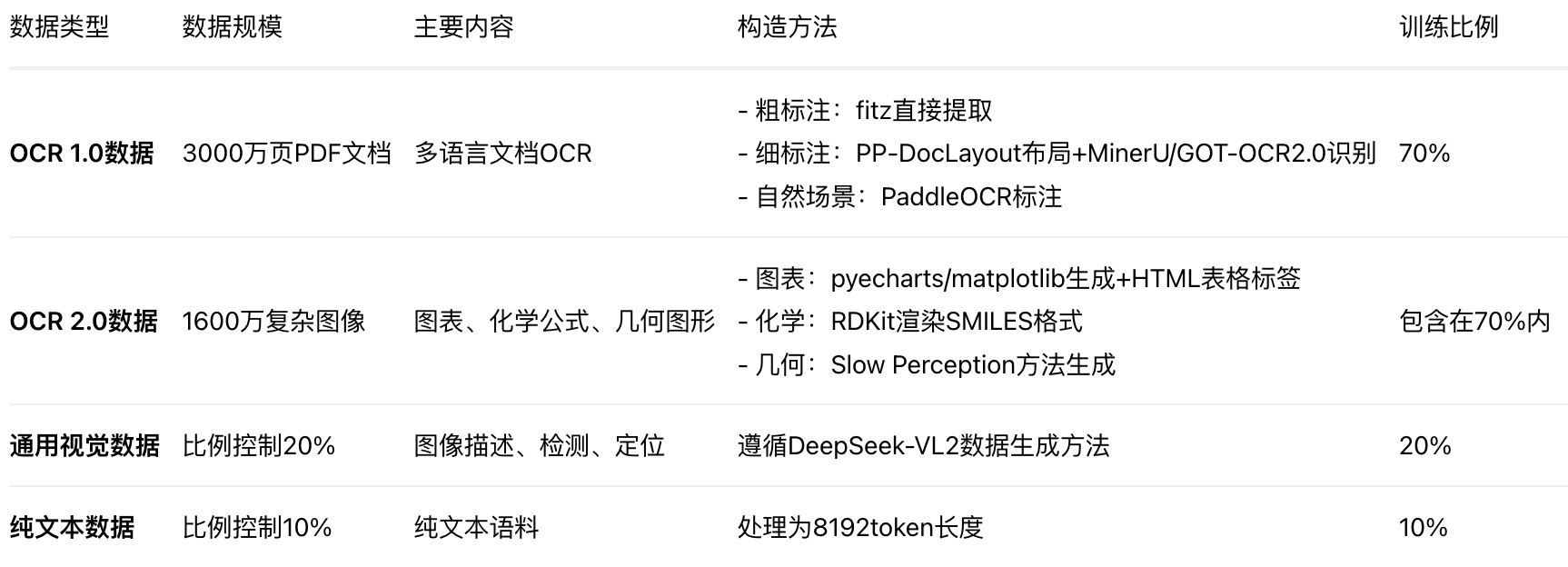
Data
多批次数据构成
Experiment
不同压缩率对应的实验结果

与多阶段OCR、E2E OCR方法的对比

总结与思考
10倍压缩率情况下能达到97%的识别成功率,说明至少有97%的text信息已经被编码进来了,有10倍的压缩率,那证明比直接使用text作为输入性价比更高,在long context的场景下还是非常有价值的。
相关链接
https://www.zhihu.com/search?type=content&q=DeepSeek-OCR%3A Contexts Optical Compression