微信视频号:sph0RgSyDYV47z6
快手号:4874645212
抖音号:dy0so323fq2w
小红书号:95619019828
B站1:UID:3546863642871878
B站2:UID: 3546955410049087

-
显存规格:存储能力大比拼
在显存规格这一块,百度昆仑芯 3 代 P800 和华为昇腾 910B2 等表现亮眼✨百度昆仑芯 3 代 P800 拥有 96GB HBM3 显存,这大容量就像一个超级大仓库,能为复杂计算任务存超多数据,数据处理起来那叫一个流畅,一点不卡顿。华为昇腾 910B呢,虽然显存容量是 64GB HBM2E,但在特定应用场景里,也完全能 hold 住场面,满足需求。

添加图片注释,不超过 140 字(可选)
-
显存带宽:数据传输速度之争
说到显存带宽,沐曦 / 曦云 C550 简直是一骑绝尘,以 1600 到 1800GB/s 左右的超高带宽 C 位出道🚀高显存带宽意味着数据传输跟坐火箭似的快,能大大减少数据读取等待时间,整体运算效率 “唰” 地就上去了。海光 K100 AI 版的 896 GB/s 显存带宽也不错,处理大规模数据时也有自己的优势,表现可圈可点。

添加图片注释,不超过 140 字(可选)
-
接口类型:PCle 与 OAM 的对决
接口类型上,PCle 接口和 OAM 接口各有各的好。PCle 接口兼容性超广,传输速度又快,好多产品都爱用它,像华为 Atlas300T A2 训练卡、天数智芯 / 天域 150S 等,用它就像给设备配上了万能钥匙🔑而 OAM 接口在一些特定产品里作用重大,百度昆仑芯 3 代 P800、华为昇腾 910B2 等就靠它实现更高效的硬件集成与扩展,也是相当厉害👍
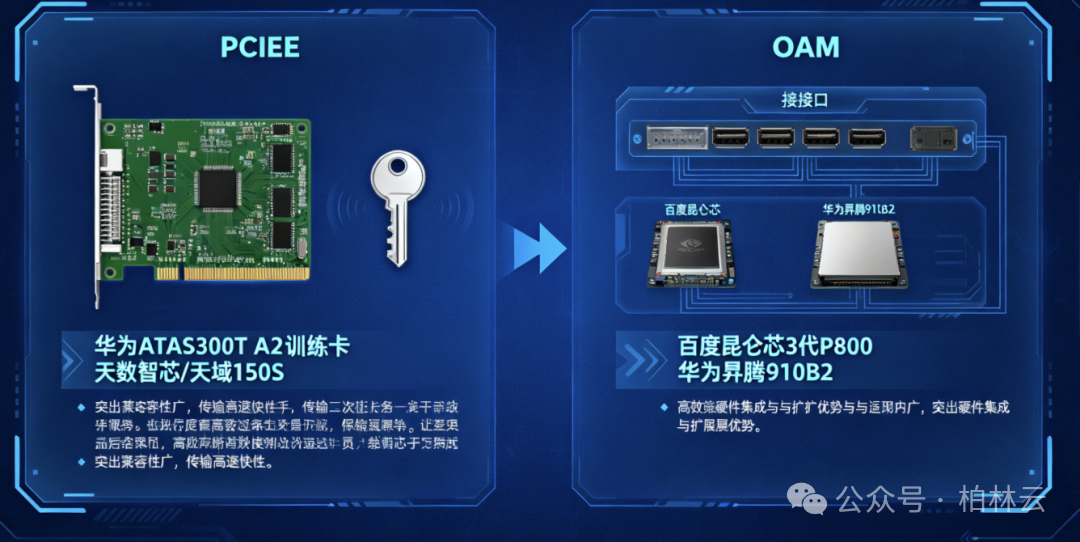
添加图片注释,不超过 140 字(可选)
-
训练算力精度:FP16 算力大揭秘
训练算力精度方面,FP16 算力精度是关键指标。华为昇腾 910B2 达到了 376 TFLOPs,这训练能力强得没话说,就像一个超级学霸,学起新知识又快又好。沐曦 / 曦云 C550 的 240 TFLOPs 以及天数智芯 / 天域 150S 的 224 TFLOPs 也不容小看,在深度学习模型训练这些场景里,能快速处理海量数据,加速模型训练过程,妥妥的助力小能手。

添加图片注释,不超过 140 字(可选)
推理算力精度:INT8 算力的较量
推理算力精度同样关键,INT8 算力精度备受关注。华为昇腾 910B2 的 762 TPOS 表现突出,在推理阶段处理低精度数据超高效,像智能安防、自动驾驶这些对实时性要求高的领域,它就是 “救星”🌟沐曦 / 曦云 C550 的 560 TPOS 和天数智芯 / 天域 150S 的 384 TPOS 在各自定位的场景中也表现良好,各有各的闪光点。

添加图片注释,不超过 140 字(可选)
综合实力点评
综合来看,每一款纯国产 GPU 都有自己独特的优势和适用场景。百度昆仑芯 3 代 P800 在显存规格和训练算力上表现出色,是数据存储和训练的一把好手;华为昇腾 910B2 凭借高推理算力精度在实际应用中占据重要地位,解决实际问题超厉害;沐曦 / 曦云 C550 则在显存带宽和训练算力方面表现亮眼,数据传输和训练都很拿手。
当下的国产算力,正处在 “破局突围” 与 “持续成长” 并行的关键阶段。对于国产算力的未来,一方面,希望技术迭代能更 “稳” 更 “快”—— 既要持续攻克核心技术难题,缩小与国际领先水平的差距,也要保证产品的稳定性和兼容性,让更多企业敢用、好用;另一方面,期待形成更完整的 “产学研用” 生态,让芯片研发、软件适配、行业应用之间形成良性循环,不再依赖单一企业或领域的突破,而是凝聚全产业链的力量。
微信视频号:sph0RgSyDYV47z6
快手号:4874645212
抖音号:dy0so323fq2w
小红书号:95619019828
B站1:UID:3546863642871878
B站2:UID: 3546955410049087
参考文献链接
纯国产GPU性能对比,谁才是国产算力之王?