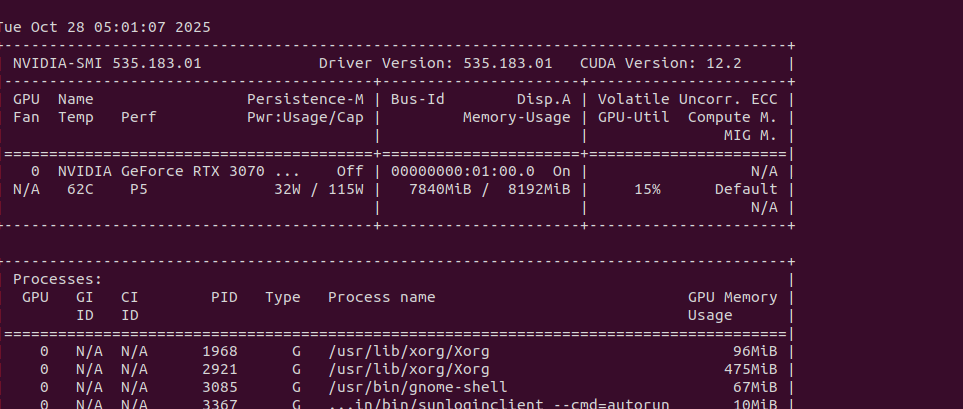
测试代码
import os
import cv2
import torch
import numpy as np
import time
from transformers import AutoModelForZeroShotObjectDetection, AutoProcessor
from transformers.image_utils import load_image
import matplotlib.pyplot as plt# 设置CUDA内存配置
os.environ['PYTORCH_CUDA_ALLOC_CONF'] = 'expandable_segments:True'
torch.cuda.empty_cache()# 在预处理时添加resize操作
def preprocess_image(image, scale):# 保持宽高比缩放,短边=target_sizewidth, height = image.size#scale = target_size / min(width, height)new_size = (int(width / scale), int(height / scale))return image.resize(new_size)# 初始化模型和处理器
def initialize_model(model_path):device = "cuda" if torch.cuda.is_available() else "cpu"processor = AutoProcessor.from_pretrained(model_path)model = AutoModelForZeroShotObjectDetection.from_pretrained(model_path,torch_dtype=torch.float16,device_map="auto").to(device)return processor, model, device# 执行目标检测
def detect_objects(image, processor, model, device, text_labels):inputs = processor(images=image, text=text_labels, return_tensors="pt").to(device)with torch.no_grad(), torch.autocast(device_type="cuda", dtype=torch.float16):outputs = model(**inputs)results = processor.post_process_grounded_object_detection(outputs,threshold=0.3,target_sizes=[(image.height, image.width)])return results[0]# 可视化检测结果(添加FPS显示)
def visualize_detection(image, result, fps=None):img = cv2.cvtColor(np.array(image), cv2.COLOR_RGB2BGR)colors = [(255, 0, 0), (0, 255, 0), (0, 0, 255), (255, 255, 0), (255, 0, 255)]# 绘制检测结果for i, (box, score, label) in enumerate(zip(result["boxes"], result["scores"], result["labels"])):if score < 0.3: # 使用阈值过滤continuexmin, ymin, xmax, ymax = [int(round(coord)) for coord in box.tolist()]color = colors[i % len(colors)]cv2.rectangle(img, (xmin, ymin), (xmax, ymax), color, 2)label_text = f"{label}: {score.item():.2f}"(text_width, text_height), _ = cv2.getTextSize(label_text, cv2.FONT_HERSHEY_SIMPLEX, 0.5, 1)cv2.rectangle(img, (xmin, ymin - text_height - 10), (xmin + text_width, ymin), color, -1)cv2.putText(img, label_text, (xmin, ymin - 5), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (255, 255, 255), 1)# 添加FPS显示if fps is not None:fps_text = f"FPS: {fps:.1f}"cv2.putText(img, fps_text, (10, 30), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 255, 0), 2)return cv2.cvtColor(img, cv2.COLOR_BGR2RGB)# 主函数:处理文件夹中的图像(添加FPS计算)
def process_folder_images(folder_path, model_path,img_scale=1):# 获取并排序所有DJI_*.JPG文件image_files = sorted([f for f in os.listdir(folder_path) if f.startswith('DJI_') and f.lower().endswith('.jpg')])if not image_files:print("未找到DJI_*.JPG格式的图像文件")return# 初始化模型processor, model, device = initialize_model(model_path)text_labels = ["vehicle", "person", "building", "tree", "power line", "agricultural machinery", "water body"]# 创建可调整大小的窗口cv2.namedWindow('Zero-Shot Object Detection', cv2.WINDOW_NORMAL)current_index = 0total_images = len(image_files)# FPS计算变量fps = 0prev_time = 0curr_time = 0while True:# 开始计时start_time = time.time()# 加载当前图像image_path = os.path.join(folder_path, image_files[current_index])image = load_image(image_path)image = preprocess_image(image,img_scale) # 缩放2倍# 执行检测result = detect_objects(image, processor, model, device, text_labels)# 计算处理时间inference_time = time.time() - start_timefps = 1.0 / inference_time if inference_time > 0 else 0# 可视化结果(传入FPS)result_img = visualize_detection(image, result, fps)# 显示结果cv2.imshow('Zero-Shot Object Detection', cv2.cvtColor(result_img, cv2.COLOR_RGB2BGR))# 打印处理信息(包含FPS)print(f"处理: {image_files[current_index]} ({current_index + 1}/{total_images}) | FPS: {fps:.1f}")#print(torch.cuda.memory_summary()) # 打印显存分配情况# 等待按键key = cv2.waitKey(0) & 0xFF# 按键处理if key == 27 or key == ord('q'): # ESC或q退出breakelif key == ord('n') or key == 32 or key == 83 or key == 2: # 下一张current_index = (current_index + 1) % total_imageselif key == ord('p') or key == 81 or key == 3: # 上一张current_index = (current_index - 1) % total_imagescv2.destroyAllWindows()# 使用示例
if __name__ == "__main__":folder_path = "/media/r9000k/DD_XS/2数据/2RTK/data_1_nwpuUp/data3_1130_13pm/300_location_14pm/images" # 图像文件夹路径model_path = "./" # 模型路径img_scale=1 # 缩放process_folder_images(folder_path, model_path,img_scale)




