XPath,全称是 XML Path Language,即 XML 路径语言,它是一门在 XML 文档中查找信息的语言。它最初是用来搜寻 XML 文档的,但是它同样适用于 HTML 文档的搜索。
| 表 达 式 | 描 述 |
|---|---|
| nodename | 选取此节点的所有子节点 |
| / | 从当前节点选取直接子节点 |
| // | 从当前节点选取子孙节点 |
| . | 选取当前节点 |
| .. | 选取当前节点的父节点 |
| @ | 选取属性 |
//title[@lang='eng'] 这就是一个 XPath 规则,它代表选择所有名称为 title,同时属性 lang 的值为 eng 的节点。
bookstore:选取 bookstore 元素的所有子节点。/bookstore: 选取根元素 bookstore。注释:假如路径起始于正斜杠( / ),则此路径始终代表到某元素的绝对路径!bookstore/book: 选取属于 bookstore 的子元素的所有 book 元素。//book: 选取所有 book 子元素,而不管它们在文档中的位置。bookstore//book: 选择属于 bookstore 元素的后代的所有 book 元素,而不管它们位于 bookstore 之下的什么位置。//@lang: 选取名为 lang 的所有属性
在 XPath 中,contains( ) 是一个非常实用的字符串匹配函数,用于判断某个节点的文本或属性是否包含指定的子字符串,特别适合处理模糊匹配场景(如属性值含动态部分、多值属性等)
基础语法:contains(目标字符串, 待匹配的子字符串)
html = '<a href="/book/123" class="title">红楼梦</a>'
//a[@class="title"]/text() # 按class定位,提取文本
//a[contains(@href, "/book/")]/text() # 按href部分内容定位

一句话总结: / 是“直线路径”,// 是“地毯式搜索”。
通配符使用
XPath提供了多种通配符来简化表达式:
- *:匹配任何元素节点
示例://*[@id='content']匹配任何id为content的元素 - @*:匹配任何属性节点
示例://div[@*]匹配所有带属性的div元素 - node( ):匹配任何类型的节点
示例://div/node( )匹配div的所有子节点
xpath基本概念
xpath解析:最常用且最便捷高效的一种解析方式。通用性强。
xpath解析原理
1.实例化一个etree的对象,且需要将被解析的页面源码数据加载到该对象中
2.调用etree对象中的xpath方法结合xpath表达式实现标签的定位和内容的捕获。
○ 将本地的html文件中的源码数据加载到etree对象中:
etree.parse(filePath)
○ 可以将从互联网上获取的原码数据加载到该对象中:
etree.HTML('page_text')
案例:

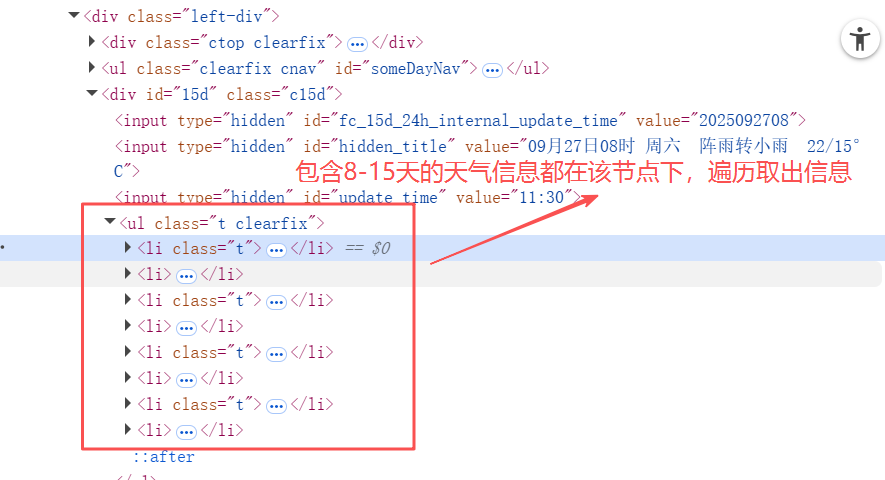
# 需求:获取昆明8-15天天气预报
import requests
from lxml import etree
url = 'https://www.weather.com.cn/weather15d/101290101.shtml'
headers = {'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/139.0.0.0 Safari/537.36'
}
response = requests.get(url,headers=headers)
response.encoding = 'utf-8'
# print(response.text)# 解析html为元素树
tree = etree.HTML(response.text)
lis = tree.xpath('//div[@id="15d"]/ul/li')
for li in lis:date = li.xpath('./span[1]/text()')[0]weather = li.xpath('./span[2]/text()')[0]temperature_max = li.xpath('./span[3]/em/text()')[0]temperature_min = li.xpath('./span[3]//text()')[1]print(date,weather,temperature_max,temperature_min)
