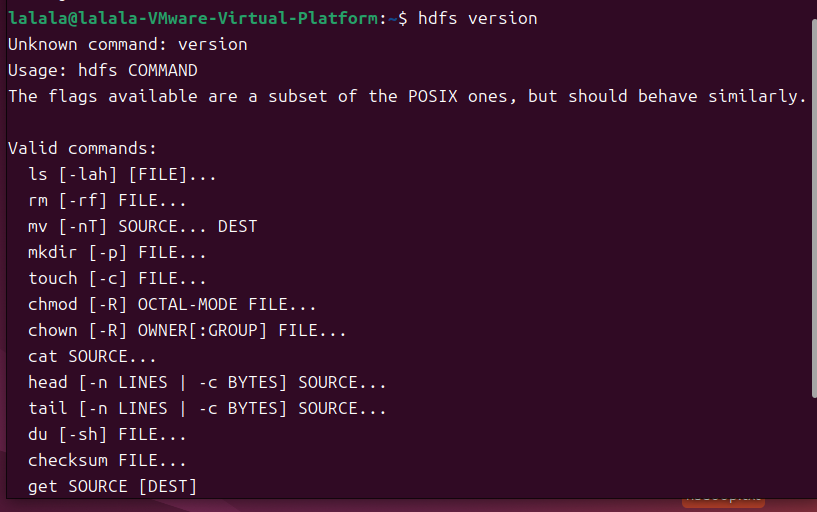
当遇到如下问题,大致是安装包有问题,需要重新下载安装包,但是直接用命令行下载需要十个小时,这边在widows上下载好在传送到虚拟机
接着按照以下步骤
结合你当前hdfs命令功能受限的问题,以下是彻底修复Hadoop环境的详细操作步骤,确保能正常执行MapReduce词频统计任务:
一、卸载现有异常Hadoop环境
-
查找当前
hdfs命令位置:
执行以下命令确认异常hdfs的安装路径:which hdfs假设输出为
/usr/local/bin/hdfs(非标准Hadoop路径)。 -
删除异常Hadoop文件:
若存在非官方Hadoop安装,执行:sudo rm -rf /usr/local/bin/hdfs # 根据实际路径删除 sudo rm -rf /usr/local/hadoop # 若存在旧安装目录,一并删除
二、安装官方完整Hadoop(以3.3.4版本为例)
1. 安装依赖
sudo apt update
sudo apt install -y openjdk-8-jdk ssh rsync
验证Java安装:
java -version # 应显示openjdk版本信息
2. 下载并解压Hadoop
# 下载官方包(国内可使用镜像加速)
wget https://archive.apache.org/dist/hadoop/common/hadoop-3.3.4/hadoop-3.3.4.tar.gz# 解压到/usr/local
sudo tar -zxf hadoop-3.3.4.tar.gz -C /usr/local# 重命名为hadoop并授权
sudo mv /usr/local/hadoop-3.3.4 /usr/local/hadoop
sudo chown -R lalala:lalala /usr/local/hadoop # 替换为你的用户名
3. 配置环境变量
编辑~/.bashrc文件:
nano ~/.bashrc
在末尾添加:
# Java环境
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
# Hadoop环境
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
生效配置:
source ~/.bashrc
4. 验证Hadoop安装
执行:
hadoop version
若输出Hadoop 3.3.4版本信息,说明基础安装成功。
三、配置Hadoop伪分布式模式
1. 配置SSH免密登录
# 生成密钥
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
# 授权本地登录
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 600 ~/.ssh/authorized_keys
# 测试免密登录
ssh localhost # 应无需密码直接登录,执行exit退出
2. 修改Hadoop配置文件
所有配置文件位于$HADOOP_HOME/etc/hadoop:
-
core-site.xml:
nano $HADOOP_HOME/etc/hadoop/core-site.xml在
<configuration>中添加:<property><name>fs.defaultFS</name><value>hdfs://localhost:9000</value> </property> -
hdfs-site.xml:
nano $HADOOP_HOME/etc/hadoop/hdfs-site.xml添加:
<property><name>dfs.replication</name><value>1</value> <!-- 伪分布式单节点,副本数设为1 --> </property> <property><name>dfs.namenode.name.dir</name><value>/usr/local/hadoop/hdfs/name</value> </property> <property><name>dfs.datanode.data.dir</name><value>/usr/local/hadoop/hdfs/data</value> </property> -
mapred-site.xml:
cp $HADOOP_HOME/etc/hadoop/mapred-site.xml.template $HADOOP_HOME/etc/hadoop/mapred-site.xml nano $HADOOP_HOME/etc/hadoop/mapred-site.xml添加:
<property><name>mapreduce.framework.name</name><value>yarn</value> <!-- 使用YARN作为MapReduce框架 --> </property> -
yarn-site.xml:
nano $HADOOP_HOME/etc/hadoop/yarn-site.xml添加:
<property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value> </property> <property><name>yarn.resourcemanager.hostname</name><value>localhost</value> </property>
3. 格式化NameNode(首次安装执行)
hdfs namenode -format
看到SUCCESS提示说明格式化成功。
四、启动Hadoop并验证
-
启动HDFS和YARN:
start-dfs.sh # 启动HDFS start-yarn.sh # 启动YARN -
检查进程:
jps应显示以下进程(缺一不可):
- NameNode
- DataNode
- SecondaryNameNode
- ResourceManager
- NodeManager
-
验证HDFS命令功能:
hdfs version # 应输出Hadoop版本 hdfs dfs -mkdir -p /user/lalala/input # 创建输入目录(成功无报错) -
验证Web界面:
打开浏览器访问:- HDFS Web界面:
http://localhost:50070(能正常打开) - YARN Web界面:
http://localhost:8088(能正常打开)
- HDFS Web界面:
五、上传文件并运行MapReduce任务
-
上传本地文件到HDFS:
# 假设wordfile1.txt和wordfile2.txt在当前目录 hdfs dfs -put wordfile1.txt wordfile2.txt /user/lalala/input/ # 验证上传 hdfs dfs -ls /user/lalala/input/ # 应显示两个文件 -
运行词频统计程序:
使用Hadoop自带的wordcount示例(无需手动编译):hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.4.jar wordcount /user/lalala/input /user/lalala/output -
查看结果:
hdfs dfs -cat /user/lalala/output/part-r-00000应输出正确的词频统计结果。
按以上步骤操作后,你的Hadoop环境将恢复正常,可顺利完成词频统计任务。