| 这个作业属于哪个课程 | https://edu.cnblogs.com/campus/gdgy/Class34Grade23ComputerScience |
|---|---|
| 这个作业要求在哪里 | https://edu.cnblogs.com/campus/gdgy/Class34Grade23ComputerScience/homework/13477 |
| 这个作业的目标 | 实现一个3000字以上论文查重程序 |
1.github链接
https://gitee.com/elysiak/3123004456
2.psp表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 20 | 15 |
| Estimate | 估计这个任务需要多少时间 | 20 | 15 |
| Development | 开发 | 500 | 558 |
| Analysis | 需求分析(包括学习新技术) | 120 | 150 |
| Design Spec | 生成设计文档 | 20 | 18 |
| Design Review | 设计复审 | 20 | 15 |
| Coding Standard | 代码规范(为目前的开发制定合适的规范) | 10 | 5 |
| Design | 具体设计 | 25 | 30 |
| Coding | 具体编码 | 120 | 150 |
| Code Review | 代码复审 | 20 | 30 |
| Test | 测试(自我测试,修改代码,提交修改) | 30 | 25 |
| Reporting | 报告 | 60 | 70 |
| Test Report | 测试报告 | 30 | 30 |
| Size Measurement | 计算工作量 | 15 | 15 |
| Postmortem & Process Improvement Plan | 事后总结,并提交过程改进计划 | 20 | 20 |
| 合计 | 530 | 588 |
3.计算模块接口的设计与实现过程
程序关系图
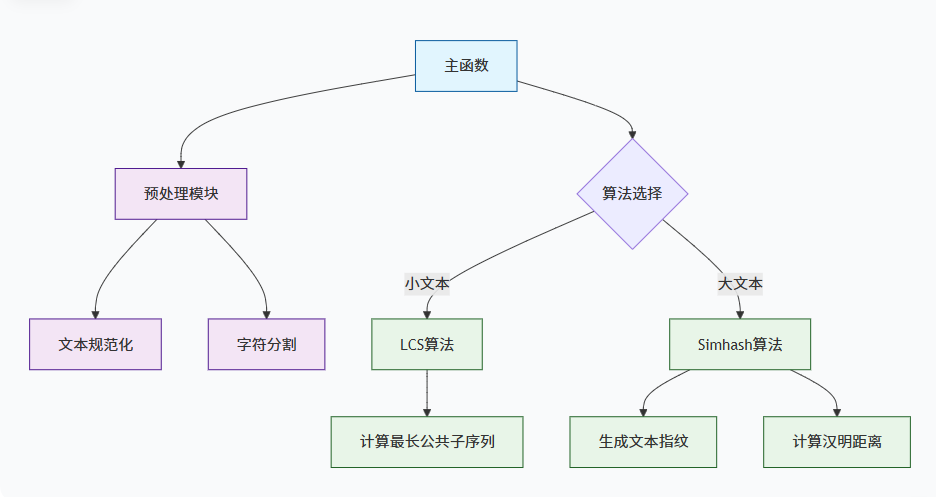
提取字符串split_utf8()
实现过程
首先遍历输入字符串的每个字节
然后根据UTF-8编码规则判断当前字符的字节长度:
- 如果字节值小于0x80,是单字节ASCII字符
- 如果字节值与0xE0进行与操作结果为0xC0,是双字节UTF-8字符
- 如果字节值与0xF0进行与操作结果为0xE0,是三字节UTF-8字符
- 如果字节值与0xF8进行与操作结果为0xF0,是四字节UTF-8字符
- 根据确定的字符长度,提取子字符串并添加到结果向量中
最后跳过已处理的字节,继续处理下一个字符
处理字符串preprocess_text()
初始化结果字符串
遍历输入文本
标点符号检测
- 使用 ispunct() 函数检测字符是否为标点符号,如果字符是标点符号,则跳过不处理
小写转换
- 对于非标点符号的字符,使用 tolower() 函数将其转换为小写
构建结果字符串
计算两个字符串序列的最长公共子序列(LCS)长度compute_lcs()以及Simhash实现
compute_lcs()实现过程
获取两个输入序列的长度m和n
如果任一序列为空,直接返回0
创建一个二维的动态规划表,只保留两行以节省空间
使用双重循环填充动态规划表:
如果当前字符匹配,LCS长度增加1
如果字符不匹配,取上方或左方单元格中的最大值
使用滚动数组技术,只保留当前行和上一行,减少空间复杂度
返回动态规划表右下角的值,即LCS的长度
Simhash实现过程
初始化阶段:
设置指纹长度为64位(平衡精度和计算效率)
创建长度为64的整数向量v,初始化为0,用于累加每个特征的权重特征哈希化:
遍历输入文本的所有特征(token)
对每个特征计算64位哈希值,将特征映射到固定长度的二进制表示权重累加:
对于每个特征的哈希值,检查其每一位
如果某位为1,在对应位置加1;如果为0,则减1
这相当于为每个特征在64个维度上"投票",正票表示该特征支持该位为1,负票表示支持该位为0生成指纹:
遍历累加结果向量v
如果某位的累加值为正,设置最终指纹的对应位为1
如果为负或零,保持该位为0
这样就得到了代表整个文本的64位Simhash指纹最后计算海明距离
4.计算模块接口部分的性能改进
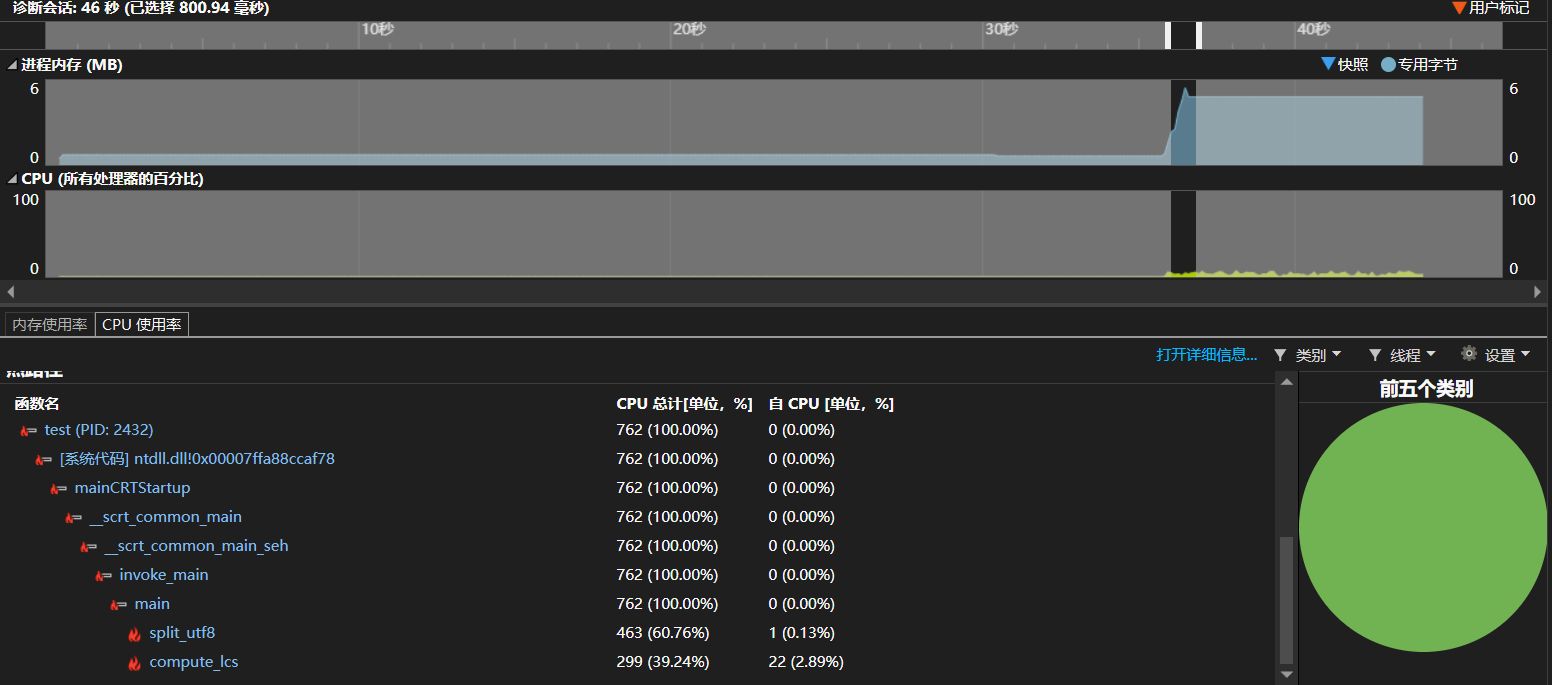
由图可以看出性能瓶颈显然是compute_lcs函数即计算两个字符串序列的最长公共子序列(LCS)长度的函数,它占据了cpu的大部分使用时间,而分割字符串的函数几乎可以忽略不计
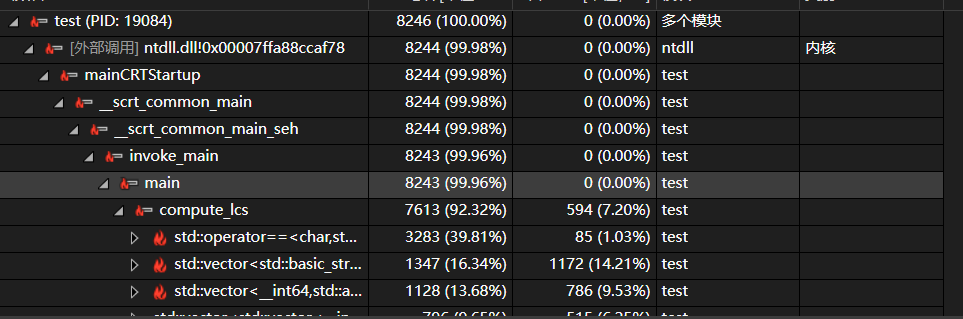
优化前
优化后
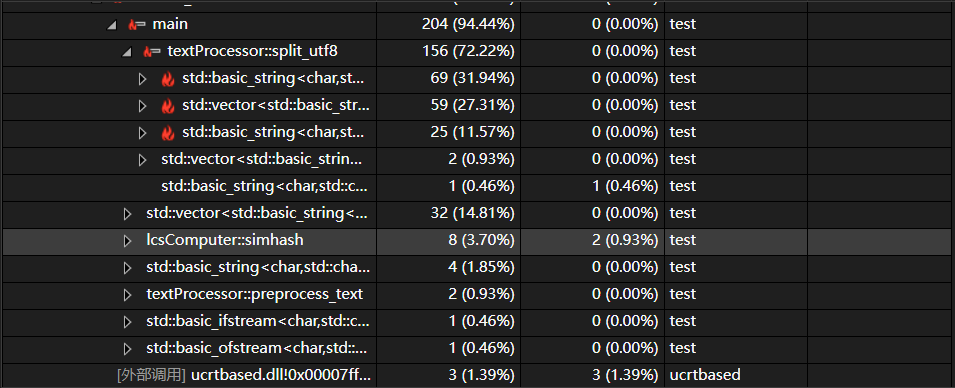
- 优化思路:结合了Simhash算法,虽然速度得到极大的提高,但是相较于求最长公共子序列查重率误差较大,对于同一个文本Simhash得出的结果为0.98,而求lcs得出的结果为0.86。所以当 Simhash算法得出的结果无法较为确定的判断时就使用求lcs的方法,且因执行Simhash的时间很短,效率不会造成很大的影响
5.计算模块部分单元测试展示
测试结果
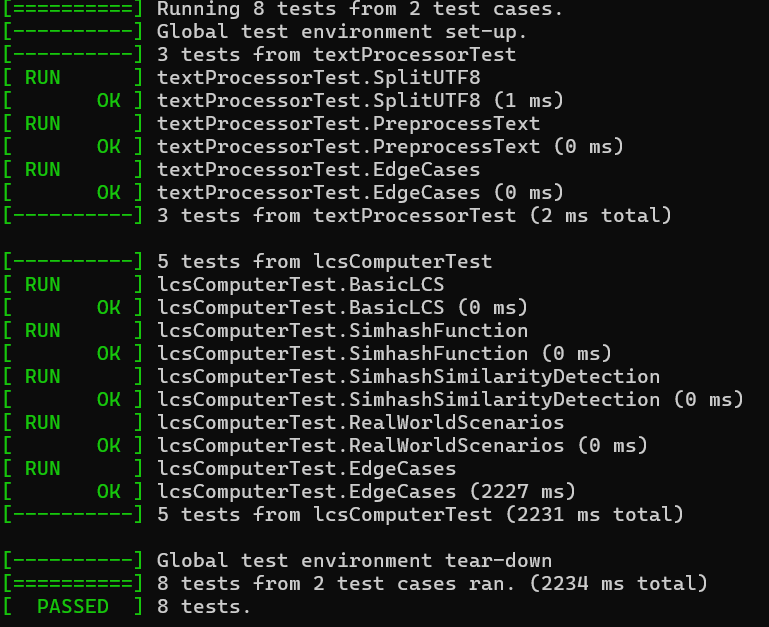
部分代码展示
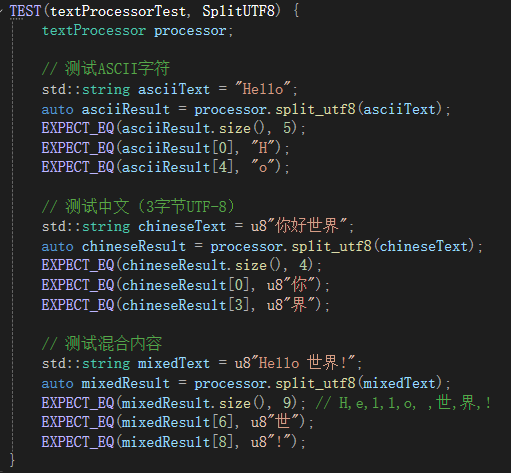
首先测试对utf-8字符的分割,即对中文和英文以及它们的混合情况测试,查看它们分割是否准确
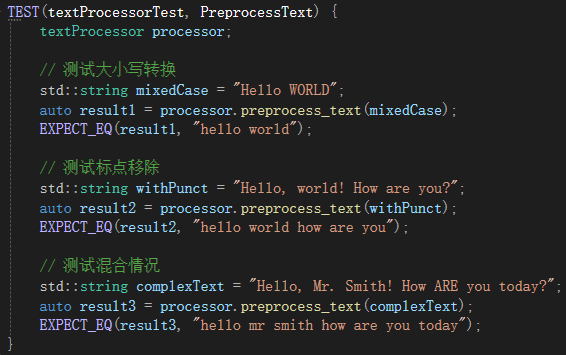
然后测试对文本标点符号及英文大小写的处理,还有它们的混合情况
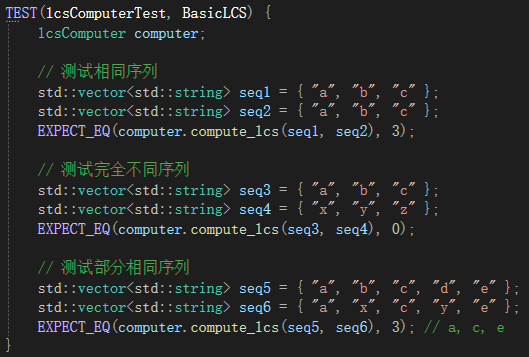
再测试求得的的lcs是否准确

最后测试Simhash函数计算对部分的情况产生的误差是否能够接受
6.计算模块部分异常处理说明

