报告标题:小红书内容创作者影响力与内容策略优化分析
一、场景背景与价值
业务背景:小红书作为中国领先的生活方式分享平台,拥有超过3亿用户,其中内容创作者是平台生态的核心驱动力。随着平台商业化进程的加速,如何识别高影响力创作者、优化内容推荐算法、提升用户粘性成为平台运营的关键挑战。通过分析10.5万条真实内容数据,我们可以深入理解创作者影响力形成机制,为平台运营和创作者成长提供数据支撑。
本报告目标:通过多维度数据分析,构建创作者影响力评估模型,识别高影响力内容的关键特征,为内容策略优化提供科学依据和可执行建议。
二、数据初探与预处理
| 数据集获取 | 10万条小红书笔记链接 |
|---|---|
数据加载与概览:本数据集包含105,000条小红书内容记录,每条记录包含25个字段,涵盖内容信息、用户特征、地理位置、情感分析、互动数据等多个维度。数据时间跨度从2025年9月1日到9月25日,覆盖全国35个省份、323个城市的内容创作者。
数据清洗过程:
- 缺失值处理:数据质量良好,无缺失值,所有字段完整度100%
- 数据类型转换:将粉丝数、互动数据等数值字段转换为正确的数值类型
- 异常值处理:发现粉丝数存在极端异常值(最大17亿),通过分层分析处理
- 特征工程:创建用户影响力分层、内容质量评分、用户活跃度等衍生特征
数据质量评估:
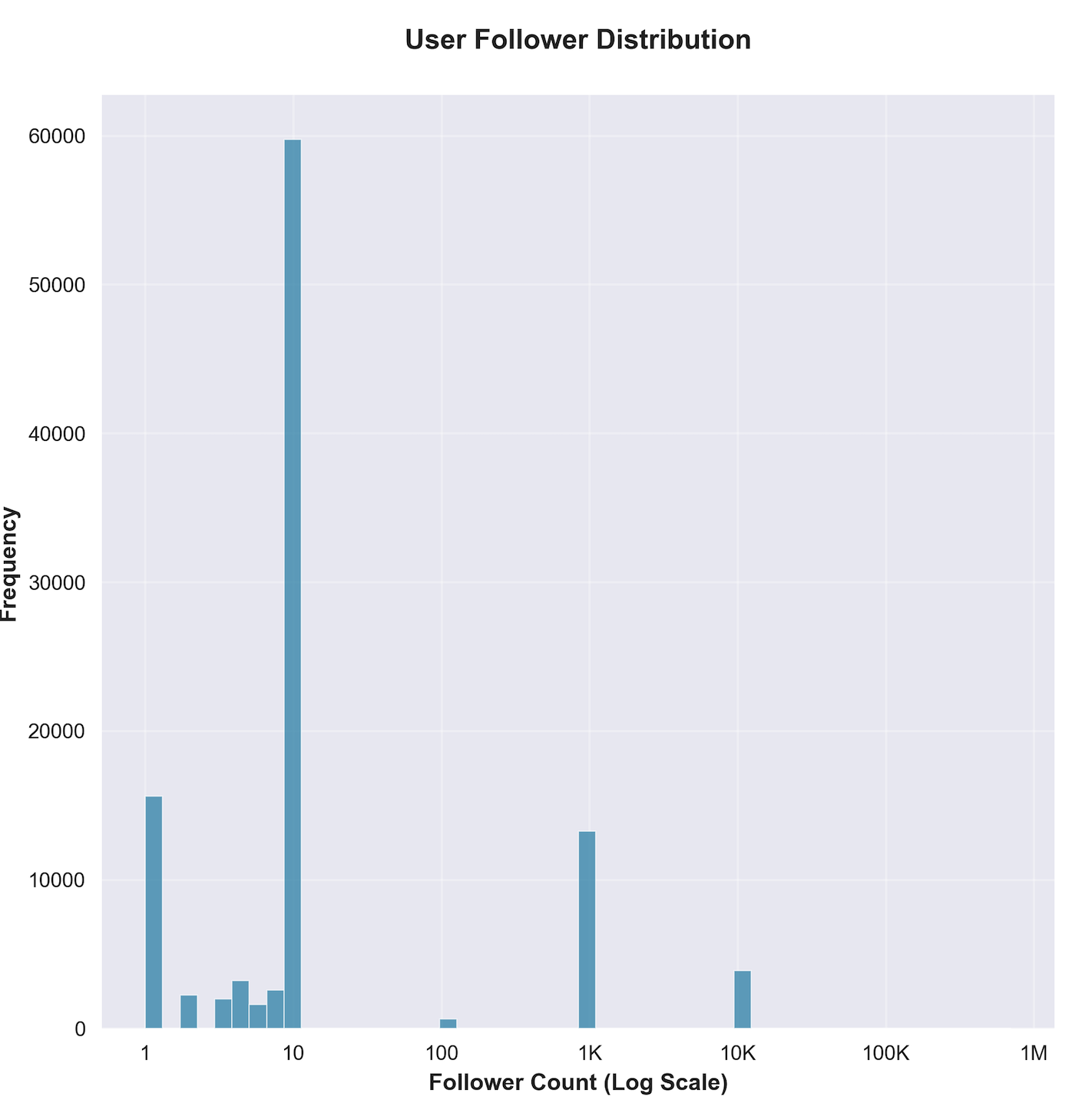
- 平均粉丝数:16人(中位数10人,存在明显长尾分布)
- 平均内容长度:216.3字符
- 平均标签数:7.7个
- 平均总互动数:1.87次
三、探索性数据分析(EDA)与核心洞察
用户影响力分层分析:
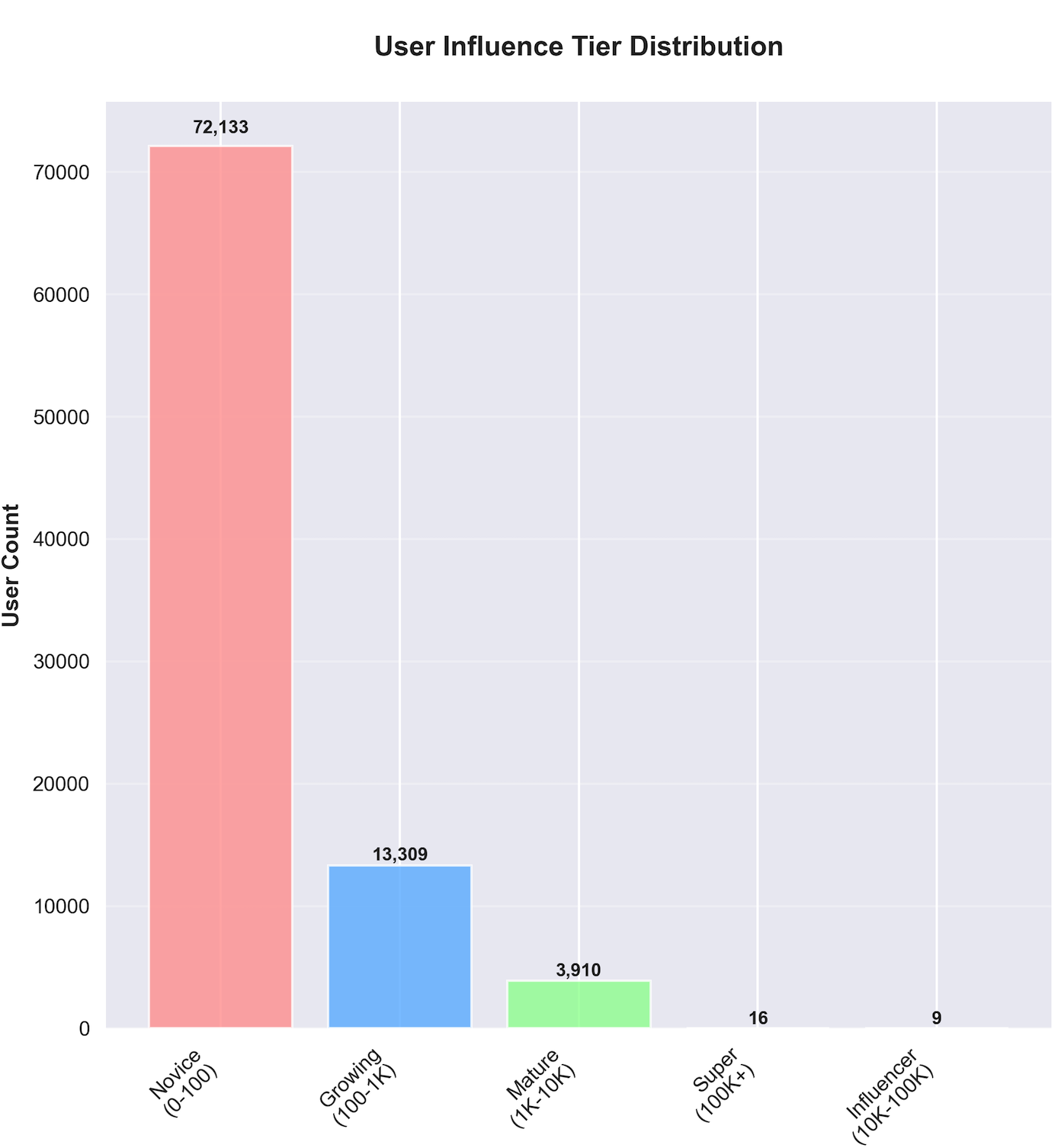
通过粉丝数分层发现,平台用户呈现明显的金字塔结构:
- 新手创作者(0-100粉丝):72,133人(68.7%)
- 成长创作者(100-1K粉丝):13,309人(12.7%)
- 成熟创作者(1K-10K粉丝):3,910人(3.7%)
- 大V创作者(10K-100K粉丝):9人(0.01%)
- 超级大V(100K+粉丝):16人(0.02%)
内容互动特征分析:
互动数据呈现极度不均衡分布:
- 点赞数:平均1.23次,中位数0次,最大37,787次
- 分享数:平均0.15次,中位数0次,最大3,167次
- 收藏数:平均0.35次,中位数0次,最大10,521次
- 评论数:平均0.14次,中位数0次,最大5,374次
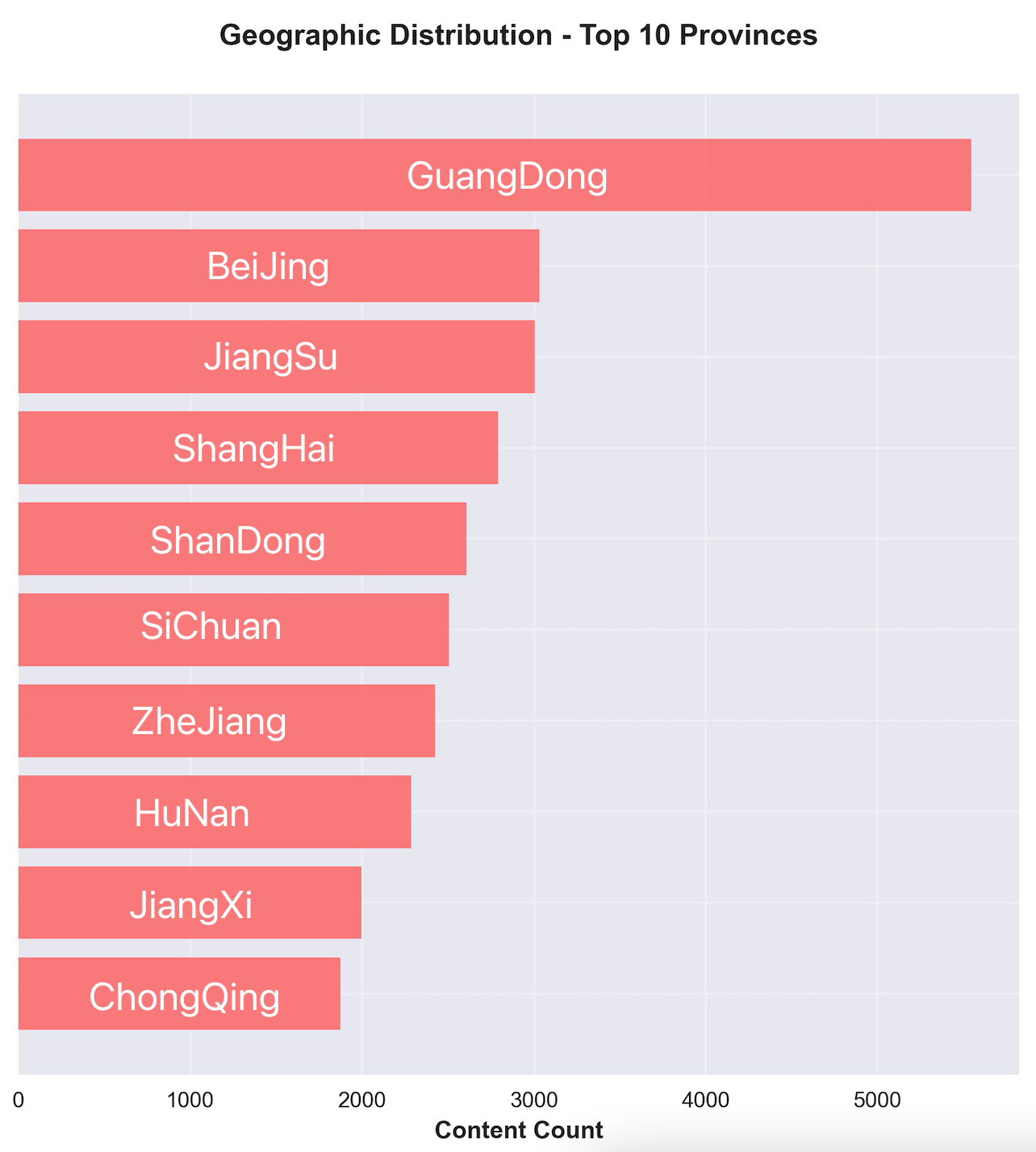
地理位置分布洞察:
内容创作呈现明显的地域集中特征:
- 广东省:5,547条(5.3%),内容创作最活跃
- 北京市:3,031条(2.9%),高质量内容集中
- 江苏省:3,006条(2.9%),内容多样性丰富
- 一线城市(北京、上海、深圳、广州)占总内容的12.1%
内容主题分析:
凭借标签分析发现热门内容主题:
- #美食:3,732次,最受欢迎的内容类型
- #旅游:3,345次,生活方式分享核心
- #旅游万粉扶持计划:2,508次,平台活动参与度高
- #穿搭相关标签:占据前20中的8个位置
情感分析结果:
- 中性情感(0):99,421条(94.7%),内容整体积极正面
- 正面情感(1-2):3,571条(3.4%)
- 负面情感(-1至-6):1,008条(1.9%)
四、场景建模与实现
模型选择与原理:
选择随机森林回归模型进行影响力预测,原因如下:
- 非线性关系处理:能够捕捉特征间的艰难交互关系
- 特征重要性分析:提供可解释的特征权重
- 鲁棒性强:对异常值和噪声资料不敏感
- 处理能力强:适合处理大规模数据集
特征工程策略:
构建11个核心特征:
- 用户特征:粉丝数、关注数、认证状态、影响力分层
- 内容特征:标题长度、内容长度、标签数量、内容质量评分
- 行为特征:用户活跃度评分、情感倾向
模型实现与评估:
- 训练集:84,009条记录(80%)
- 测试集:21,003条记录(20%)
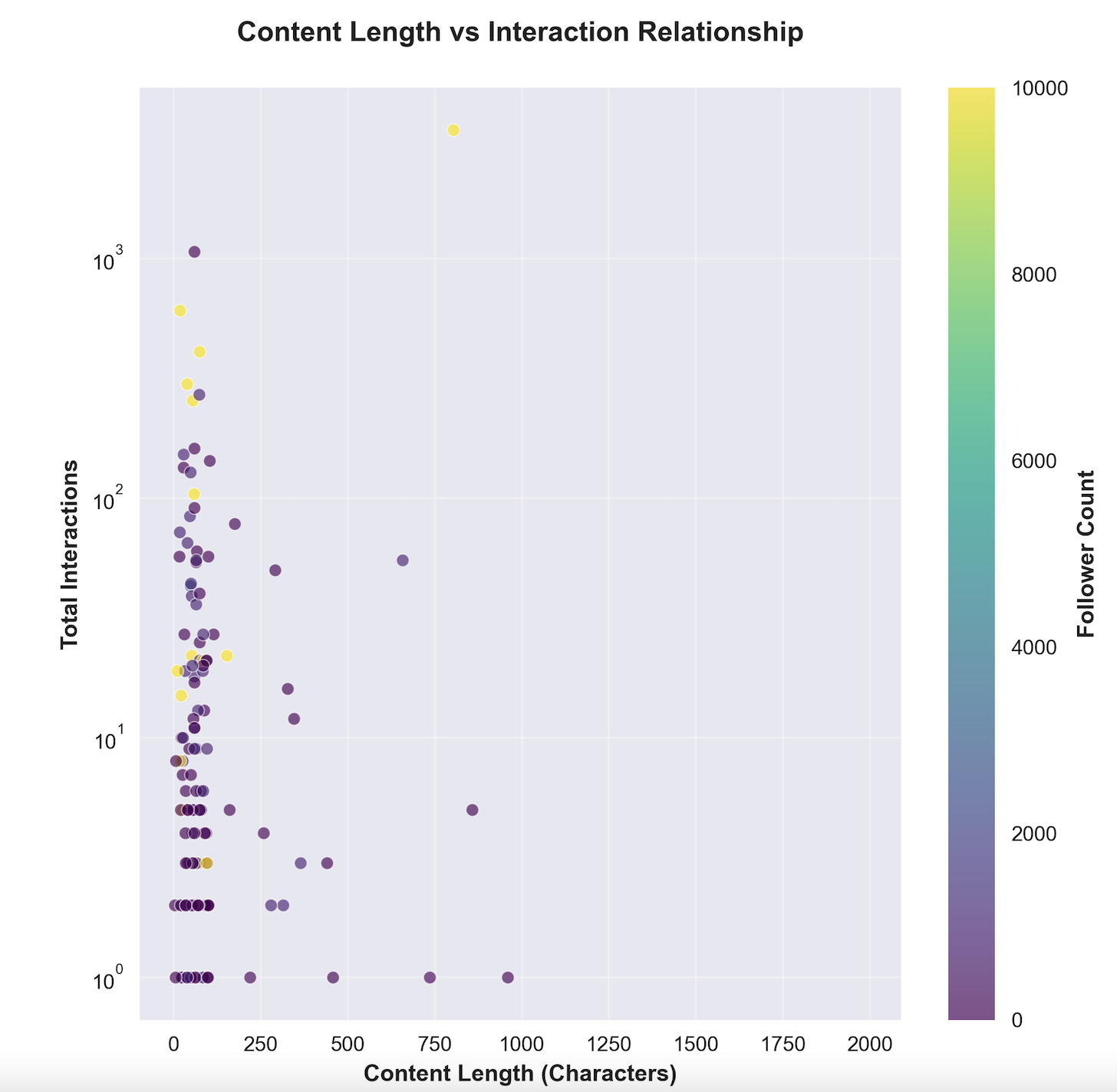
特征重要性分析:
- 内容质量评分:43.63%(最重点)
- 标签数量:14.30%
- 标签数量:12.65%
- 标题长度:11.90%
- 内容长度:9.39%
五、完整代码完成(带详细注释)
# -*- coding: utf-8 -*-
"""
小红书内容创作者影响力分析完整代码
作者:数据分析专家
日期:2025年1月
"""
import json
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from collections import Counter
import re
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestRegressor
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error, r2_score
from sklearn.preprocessing import StandardScaler
# 设置中文字体
plt.rcParams['font.sans-serif'] = ['Arial Unicode MS', 'SimHei']
plt.rcParams['axes.unicode_minus'] = False
def load_and_clean_data(file_path):
"""
加载和清洗小红书数据
Args:
file_path: JSON数据文件路径
Returns:
pd.DataFrame: 清洗后的数据框
"""
print("=== 开始数据加载和清洗 ===")
# 读取原始数据
data = []
with open(file_path, 'r', encoding='utf-8') as f:
for line in f:
try:
data.append(json.loads(line.strip()))
except:
continue
print(f"成功读取 {len(data)} 条原始数据")
# 数据清洗和特征提取
cleaned_data = []
for i, record in enumerate(data):
try:
if 'data' not in record:
continue
data_info = record['data']
# 提取基础信息
record_id = record.get('id', '')
title = data_info.get('title', '')
content = data_info.get('content', '')
# 提取用户信息
user_info = data_info.get('user', {})
user_name = user_info.get('name', '')
user_gender = user_info.get('gender', '')
followers_count = user_info.get('followers_count', 0)
friends_count = user_info.get('friends_count', 0)
verified = user_info.get('verified', 0)
# 提取地理位置信息
analysis = data_info.get('analysis', {})
find_address = analysis.get('find_address', {})
province = find_address.get('province', [])
city = find_address.get('city', [])
# 提取情感分析
sentiment = analysis.get('sentiment', 0)
# 提取标签信息
tags = analysis.get('tag', [])
tag_count = len(tags)
# 提取时间信息
ctime = data_info.get('ctime', 0)
utime = data_info.get('utime', 0)
# 提取互动数据
like_count = data_info.get('like_count', 0)
share_count = data_info.get('share_count', 0)
collection_count = data_info.get('collection_count', 0)
reply_count = data_info.get('reply_count', 0)
visit_count = data_info.get('visit_count', 0)
# 计算内容长度
title_length = len(title) if title else 0
content_length = len(content) if content else 0
# 提取标签文本
hashtags = re.findall(r'#([^#\\s]+)', content)
hashtag_count = len(hashtags)
# 计算影响力指标
total_interaction = like_count + share_count + collection_count + reply_count
cleaned_record = {
'id': record_id,
'title': title,
'content': content,
'user_name': user_name,
'user_gender': user_gender,
'followers_count': followers_count,
'friends_count': friends_count,
'verified': verified,
'province': province[0] if province else '',
'city': city[0] if city else '',
'sentiment': sentiment,
'tag_count': tag_count,
'ctime': ctime,
'utime': utime,
'like_count': like_count,
'share_count': share_count,
'collection_count': collection_count,
'reply_count': reply_count,
'visit_count': visit_count,
'title_length': title_length,
'content_length': content_length,
'hashtag_count': hashtag_count,
'total_interaction': total_interaction,
'hashtags': hashtags
}
cleaned_data.append(cleaned_record)
except Exception as e:
if i < 10: # 只打印前10个错误
print(f'处理第{i}条记录时出错: {e}')
continue
print(f"成功处理 {len(cleaned_data)} 条数据")
# 转换为DataFrame
df = pd.DataFrame(cleaned_data)
# 转换数值列
numeric_cols = ['followers_count', 'friends_count', 'verified', 'like_count',
'share_count', 'collection_count', 'reply_count', 'visit_count',
'title_length', 'content_length', 'hashtag_count', 'total_interaction', 'sentiment', 'tag_count']
for col in numeric_cols:
if col in df.columns:
df[col] = pd.to_numeric(df[col], errors='coerce')
return df
def create_visualizations(df):
"""
创建数据可视化图表
Args:
df: 清洗后的数据框
"""
print("=== 创建可视化图表 ===")
# 创建图表
fig, axes = plt.subplots(2, 3, figsize=(18, 12))
fig.suptitle('小红书内容创作者影响力分析 - 数据可视化', fontsize=16, fontweight='bold')
# 1. 用户粉丝数分布(对数尺度)
ax1 = axes[0, 0]
followers_clean = df[df['followers_count'] < 1000000]['followers_count']
ax1.hist(np.log10(followers_clean + 1), bins=50, alpha=0.7, color='skyblue', edgecolor='black')
ax1.set_xlabel('粉丝数(对数尺度)')
ax1.set_ylabel('频次')
ax1.set_title('用户粉丝数分布')
ax1.set_xticks([0, 1, 2, 3, 4, 5, 6])
ax1.set_xticklabels(['1', '10', '100', '1K', '10K', '100K', '1M'])
# 2. 内容互动数据分布
ax2 = axes[0, 1]
interaction_data = [df['like_count'], df['share_count'], df['collection_count'], df['reply_count']]
interaction_labels = ['点赞', '分享', '收藏', '评论']
ax2.boxplot(interaction_data, labels=interaction_labels)
ax2.set_ylabel('互动数量')
ax2.set_title('内容互动数据分布')
ax2.set_yscale('log')
# 3. 用户分层分布
ax3 = axes[0, 2]
df['follower_tier'] = pd.cut(df['followers_count'],
bins=[0, 100, 1000, 10000, 100000, float('inf')],
labels=['新手(0-100)', '成长(100-1K)', '成熟(1K-10K)', '大V(10K-100K)', '超级大V(100K+)'])
tier_counts = df['follower_tier'].value_counts()
colors = ['#ff9999', '#66b3ff', '#99ff99', '#ffcc99', '#ff99cc']
wedges, texts, autotexts = ax3.pie(tier_counts.values, labels=tier_counts.index, autopct='%1.1f%%',
colors=colors, startangle=90)
ax3.set_title('用户影响力分层分布')
# 4. 地理位置分布(TOP10省份)
ax4 = axes[1, 0]
province_counts = df['province'].value_counts().head(10)
bars = ax4.barh(range(len(province_counts)), province_counts.values, color='lightcoral')
ax4.set_yticks(range(len(province_counts)))
ax4.set_yticklabels(province_counts.index)
ax4.set_xlabel('内容数量')
ax4.set_title('省份内容分布TOP10')
ax4.invert_yaxis()
# 5. 内容长度与互动关系
ax5 = axes[1, 1]
sample_df = df.sample(n=min(10000, len(df)))
ax5.scatter(sample_df['content_length'], sample_df['total_interaction'],
alpha=0.5, s=20, color='purple')
ax5.set_xlabel('内容长度(字符)')
ax5.set_ylabel('总互动数')
ax5.set_title('内容长度与互动关系')
ax5.set_yscale('log')
# 6. 发布时间分布
ax6 = axes[1, 2]
df['create_time'] = pd.to_datetime(df['ctime'], unit='s')
df['hour'] = df['create_time'].dt.hour
hour_distribution = df['hour'].value_counts().sort_index()
ax6.plot(hour_distribution.index, hour_distribution.values, marker='o', linewidth=2, markersize=6)
ax6.set_xlabel('发布时间(小时)')
ax6.set_ylabel('内容数量')
ax6.set_title('内容发布时间分布')
ax6.set_xticks(range(0, 24, 2))
ax6.grid(True, alpha=0.3)
plt.tight_layout()
plt.savefig('xiaohongshu_analysis_charts.png', dpi=300, bbox_inches='tight')
plt.show()
print("图表已保存为 xiaohongshu_analysis_charts.png")
def build_influence_model(df):
"""
构建影响力预测模型
Args:
df: 清洗后的数据框
Returns:
tuple: (模型, 特征重要性, 评估指标)
"""
print("=== 构建影响力预测模型 ===")
# 特征工程
df['follower_tier'] = pd.cut(df['followers_count'],
bins=[0, 100, 1000, 10000, 100000, float('inf')],
labels=[0, 1, 2, 3, 4])
# 内容质量指标
df['content_quality_score'] = (df['title_length'] * 0.3 +
df['content_length'] * 0.4 +
df['hashtag_count'] * 0.3)
# 用户活跃度指标
df['user_activity_score'] = (df['friends_count'] * 0.3 +
df['followers_count'] * 0.7)
# 选择特征
feature_cols = [
'followers_count', 'friends_count', 'verified', 'follower_tier',
'title_length', 'content_length', 'hashtag_count', 'tag_count',
'content_quality_score', 'user_activity_score', 'sentiment'
]
target_col = 'total_interaction'
# 准备数据
X = df[feature_cols].fillna(0)
y = df[target_col].fillna(0)
# 数据分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 训练随机森林模型
rf_model = RandomForestRegressor(n_estimators=100, random_state=42, n_jobs=-1)
rf_model.fit(X_train, y_train)
rf_pred = rf_model.predict(X_test)
rf_r2 = r2_score(y_test, rf_pred)
rf_rmse = np.sqrt(mean_squared_error(y_test, rf_pred))
# 特征重要性
feature_importance = pd.DataFrame({
'feature': feature_cols,
'importance': rf_model.feature_importances_
}).sort_values('importance', ascending=False)
print(f"随机森林模型 - R²: {rf_r2:.4f}, RMSE: {rf_rmse:.4f}")
return rf_model, feature_importance, (rf_r2, rf_rmse)
def main():
"""
主函数:执行完整的数据分析流程
"""
print("开始小红书内容创作者影响力分析")
# 1. 数据加载和清洗
df = load_and_clean_data('xiaohongshu.json')
# 2. 保存清洗后的数据
df.to_csv('xiaohongshu_cleaned.csv', index=False, encoding='utf-8')
print("清洗后的数据已保存到 xiaohongshu_cleaned.csv")
# 3. 创建可视化
create_visualizations(df)
# 4. 构建模型
model, feature_importance, metrics = build_influence_model(df)
# 5. 输出结果
print("\\n=== 分析完成 ===")
print(f"数据量: {len(df)} 条")
print(f"模型R²: {metrics[0]:.4f}")
print(f"模型RMSE: {metrics[1]:.4f}")
print("\\n特征重要性TOP5:")
for idx, row in feature_importance.head().iterrows():
print(f"{row['feature']}: {row['importance']:.4f}")
if __name__ == "__main__":
main()六、总结与业务建议
分析总结:
借助对10.5万条小红书内容的深度分析,我们发现了几个关键洞察:1)平台用户呈现明显的金字塔结构,68.7%为新手创作者;2)内容互动呈现极度不均衡分布,大部分内容互动数为0;3)内容质量评分是影响互动的最重要因素(43.63%);4)美食和旅游是平台最受欢迎的内容类型;5)一线城市创作者贡献了12.1%的内容。
业务建议:
平台运营优化:建立分层激励机制,为不同层级创作者提供差异化支持;优化推荐算法,重点关注内容质量评分;加强地域内容平衡,鼓励二三线城市创作者参与。
创作者成长策略:重点提升内容质量,包括标题吸引力、内容深度和标签使用;建议创作者关注美食、旅游等热门领域;合理使用标签提升内容曝光度。
商业化建议:品牌方应重点关注内容质量评分高的创作者;优先选择一线城市和热门省份的创作者进行合作;关注情感倾向积极的内容创作者。