预训练(基础知识广泛学)------微调(具体实操岗前学)------后训练(RLHF专业领域深入学)
策略模型、参考模型、价值模型、奖励模型
策略模型:待后训练的大模型
参考模型:初始的策略模型。
奖励模型(RM):目标是刻画模型的输出是否在人类看来表现不错。即,输入 [提示(prompt),模型生成的文本] ,输出一个刻画文本质量的标量数字。
奖励模型可以看做一个判别式的语言模型,因此我们可以用一个预训练语言模型热启,而后在 [x=[prompt,模型回答], y=人类满意度] 构成的标注语料上去微调,也可以直接随机初始化,在语料上直接训练。
奖励模型的大小最好是跟生成模型的大小相近,这样效果会比较好。理解能力所需要的模型参数规模就得恰好是跟生成模型相近。
基于 RL 进行语言模型优化:
将初始语言模型的微调任务建模为强化学习(RL)问题,因此需要定义策略(policy)、动作空间(action space)和奖励函数(reward function)等基本要素。
- 策略就是基于该语言模型,接收prompt作为输入,然后输出一系列文本(或文本的概率分布);
- 动作空间就是词表所有token在所有输出位置的排列组合(单个位置通常有50k左右的token候选);
- 观察空间则是可能的输入token序列(即prompt),显然也相当大,为词表所有token在所有输入位置的排列组合;
- 奖励函数(reward)则是基于训好的RM模型计算得到初始reward,再叠加上一个约束项来。
基于前面提到的预先富集的数据,从里面采样prompt输入,同时丢给初始的语言模型和我们当前训练中的语言模型(policy),得到俩模型的输出文本y1,y2
然后用奖励模型RM对y1、y2打分,判断谁更优秀。 显然,打分的差值便可以作为训练策略模型参数的信号,这个信号一般通过KL散度来计算“奖励/惩罚”的大小。y2文本的打分比y1高的越多,奖励就越大,反之惩罚则越大。这个信号就反映了当前模型有没有在围着初始模型“绕圈”,避免模型通过一些“取巧”的方式骗过RM模型获取高额reward。
最后,便是根据 Proximal Policy Optimization (PPO) 算法来更新模型参数了。
PPO 算法确定的奖励函数具体计算如下:
将提示 x 输入初始 LM 和当前微调的 LM,分别得到了输出文本 ,将来自当前策略的文本传递给 RM 得到一个标量的奖励 。
将两个模型的生成文本进行比较计算差异的惩罚项,在来自 OpenAI、Anthropic 和 DeepMind 的多篇论文中设计为输出词分布序列之间的 Kullback–Leibler (KL) divergence 散度的缩放,即,这一项被用于惩罚 RL 策略在每个训练批次中生成大幅偏离初始模型,以确保模型输出合理连贯的文本。如果去掉这一惩罚项可能导致模型在优化中生成乱码文本来愚弄奖励模型提供高奖励值。
GRPO 的本质思路:通过在同一个问题上生成多条回答,把它们彼此之间做“相对比较”,来代替传统 PPO 中的“价值模型”。
群体相对策略优化 (GRPO,Group Relative Policy Optimization)是一种强化学习 (RL) 算法,专门用于增强大型语言模型 (LLM) 中的推理能力。与严重依赖外部评估模型(价值函数)指导学习的传统 RL 方法不同,GRPO 通过评估彼此相关的响应组来优化模型。这种方法可以提高训练效率,使 GRPO 成为需要复杂问题解决和长链思维的推理任务的理想选择。
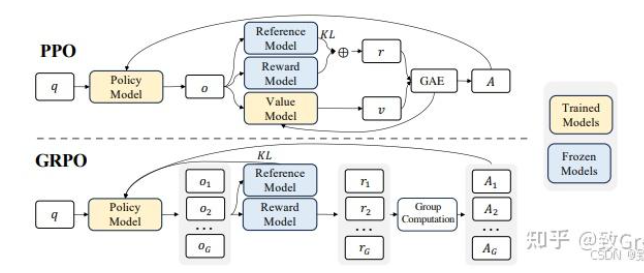
GRPO 训练流程(简化版):
- 生成一组响应:对于每个提示,从 LLM 中生成多个响应的一组。
- 对组进行打分(奖励模型):获取组内所有响应的奖励分数。
- 计算组内相对优势(GRAE —— 组内比较):通过比较每个响应的奖励与组内平均奖励来计算优势。在组内对奖励进行归一化以得到优势。
- 优化策略(使用 GRAE 的 PPO 风格目标函数):使用一个 PPO 风格的目标函数更新 LLM 的策略,但使用这些组内相对优势。