作业1
1.大学排名动态网页爬取实验
题目要求:用requests和BeautifulSoup库方法定向爬取给定网址(http://www.shanghairanking.cn/rankings/bcur/2020 )的数据,屏幕打印爬取的大学排名信息。
核心代码
#提取排名:定位<div class="ranking">标签,清除空格rank_elem = cols[0].find('div', class_=lambda x: x and 'ranking' in x)#提取学校中文名:定位<span class="name-cn">标签,清除空格name_elem = cols[1].find('span', class_='name-cn')#提取省市:直接取第3列文本,清除空格和注释province = cols[2].text.strip().replace('<!-- -->', '')#提取学校类型:直接取第4列文本,清除空格和注释category = cols[3].text.strip().replace('<!-- -->', '')#提取总分:直接取第5列文本,清除空格和注释score = cols[4].text.strip().replace('<!-- -->', '')
运行结果

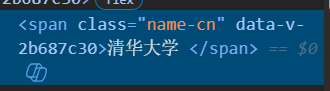
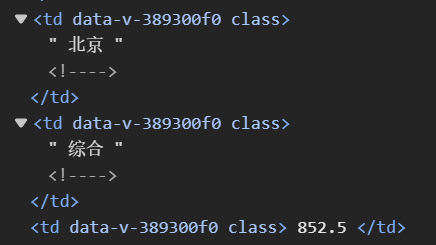
提取我们需要的排名,学校名称,省市,学校类型,总分
2.心得体会
爬取的时候要注意不要把985,211还有英文提取,只要中文名。不足的是有些大学名字比较长,格式不够好,有些没对齐
作业2
1.商城商品比价定向爬虫实验
题目要求:用requests和re库方法设计某个商城(自已选择)商品比价定向爬虫,爬取该商城,以关键词“书包”搜索页面的数据,爬取商品名称和价格。
核心代码
pattern = r'<a[^>]*title="([^"]*)"[^>]*>.*?[\u4e00-\u9fa5]*\s*¥?\s*([\d.]+)'
首先用正则表达式匹配包含title属性的a标签,提取商品名称,然后提取价格(包含小数点)
运行结果
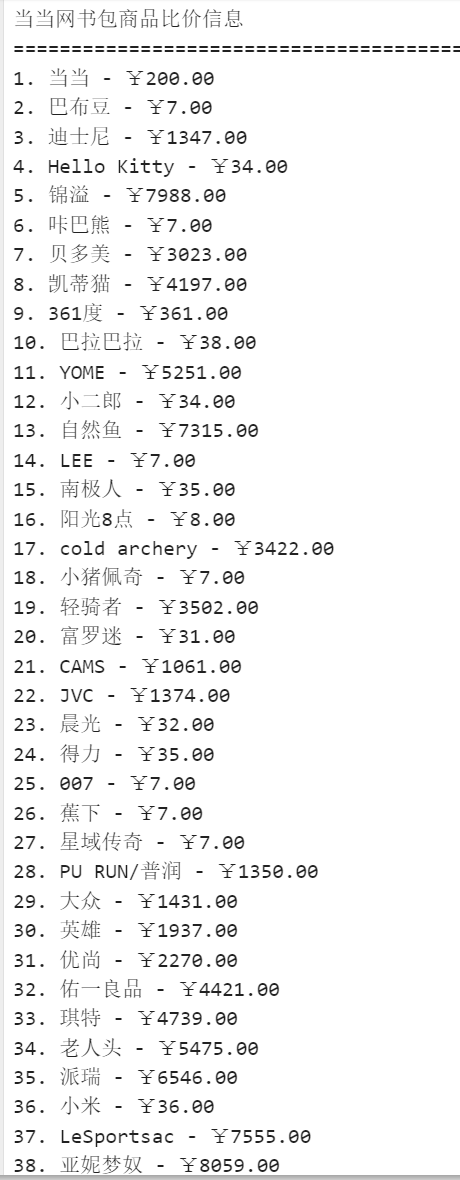
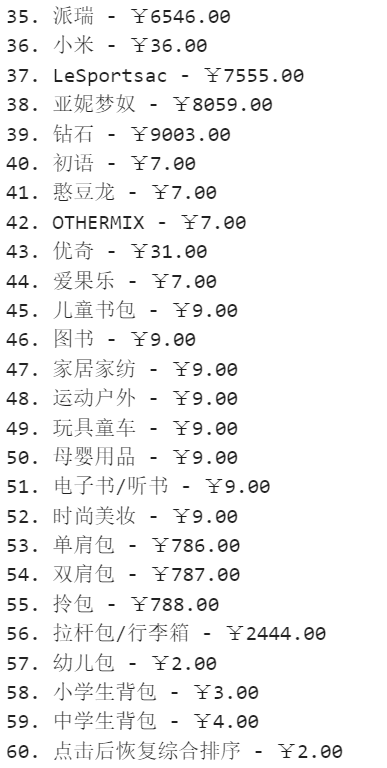
2.心得体会
一开始尝试了京东,淘宝,天猫,都失败了,这些反爬机制太强了。最后选择当当网,主要就是通过正则表达式来提取我们需要的数据,不足的是有些没用的数据也被提取了。
作业3
1.网页图片批量下载实验
题目要求:爬取一个给定网页(https://news.fzu.edu.cn/yxfd.htm)或者自选网页的所有JPEG、JPG或PNG格式图片文件
核心代码
pattern = r'<img[^>]*src=["\']([^"\']*\.(?:jpg|jpeg|png))["\'][^>]*>'
用正则表达式匹配img标签
patterns = [r'<a[^>]*href=["\']((?:ztwy1/)?\d+\.htm)["\'][^>]*>',r'<a[^>]*href=["\'](/\d+\.htm)["\'][^>]*>',]
匹配翻页链接的模式

运行结果

一共爬取了22张图片,总共2页,图片都保存到本地文件夹里
2.心得体会
我爬取的是 https://news.fzu.edu.cn/ztwy1.htm,首先爬取第一页的所有img,然后翻页继续爬取,直到没有下一页。