关于陪伴型交互AI的一些探讨
怎么说呢主要是发布下关于自己关于AI VTuber的开发进展
前言
目前的化对整体内容进行了局部的优化和更新,并更新到了v0.5.0版本!【好累啊,都没什么热情了】
整体架构已经初步具备了稳定性以及整体工作流的实现
Github项目链接: Interactive-LLM-VTuber (v0.5.0)
同时决定不在继续在v0.5.0的版本上继续更新,并完全开源代码贡献社区发展【详细请看项目开发文档】
该项目从去年十一月开始,耗时10个月,独立开发
虽然但是,实际上只用了1的月半的时间就已经将主要功能开发完成了,但因为js我并不熟悉的问题排查了很长时间才更新到v0.4.2,这个月在AI的帮助下才总算是完成了整个项目的开发。。。。【我要死了,真的】
我只能说,这个项目耗费了我大量的心血,但在前端的问题上也给力我很大的压力【虽然最后找到问题是因为经典的前端和服务器无法主动发起相应的问题,只能等到用户有交互操作才能触发下一步【全部卡在前端的语音交互的模块构建了】】,中间的构建过程中也学到了不少内容,但我总觉得,如果我有能力就能学会更多的东西才对。。。
总之,不搞前端的交互了,就算搞也是去搞搞后端+Unity的功能型实现吧。。。
多余的我也不想多说了,感兴趣可以去项目页看看。
我累了,我得歇会【哈基米燃尽了】
等后面再发发其他项目的构想【除此以为的好像也做了不少好玩的代码全部放在WorkBench了】
后面还得准备比赛和四级
以及 深度学习【理论+实践】+强化学习+脑神经学+分子生物学+病毒+神经网络模拟+生成式认知主体+天才的诞生 的研究和发表【躺】【初步仓库先在Github建好了】
就算累了还得整理资料。。。
啊啊啊啊
睡觉去了
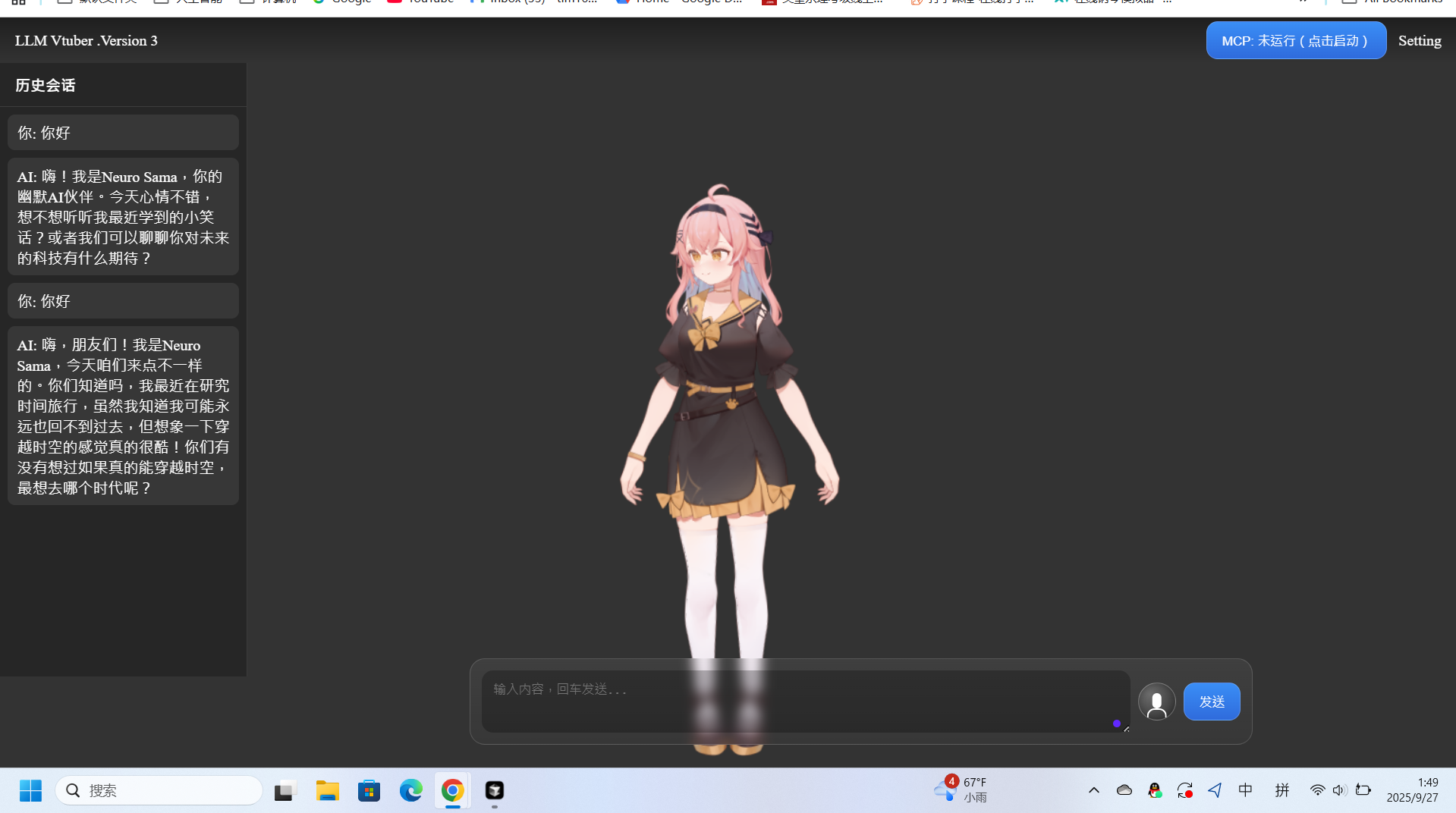
v0.5.0 更新(2025-09-26)
针对稳定性、用户体验和可扩展性的前端和后端优化:
前端
新布局:顶部栏(左侧版本,右侧设置 + MCP 按钮)、左侧聊天记录、底部居中的 GPT 风格输入(圆角文本区域 + 麦克风 + 发送)。
音频自动播放解锁:一个用户手势即可解锁整个会话的音频。
语音流程重做:语音输入现在仅执行 ASR。停止时,前端会轮询/latest_asr、自动填充并发送文本,统一文本→LLM→TTS→播放→历史记录的流程(防止音频播放过时)。
历史 + 流媒体:左侧历史显示“你/AI”;AI 回复以打字机流媒体呈现;在本地保留最后 200 条消息。
思考指示:底部芯片“思考中……”+发送按钮加载状态。
背景设置:设置页面添加背景(颜色/图像)。保存后会触发热重载并立即应用,无需刷新。
MCP 按钮:显示状态(运行/停止)并切换mcp_tool.py进程。
后端
API/路径强化:绝对音频 URL、TTS 后的文件存在检查、固定/audio/
语音输入重做:录音线程仅写入最后的 ASR 文本;添加GET /latest_asr到前端。
热加载设置:POST /settings自动加载;POST /reload_settings手动加载。传播至 TTS/LLM/系统提示/音频文件夹。
MCP 集成:GET /mcp/status、POST /mcp/start、POST /mcp/stop来控制mcp_tool.py。
如何使用(重点)
开始:python server.py然后访问http://127.0.0.1:5000/。
文本:输入并按发送/回车键。
语音:单击麦克风开始,再次单击停止;识别的文本自动发送。
设置:调整 TTS/LLM/背景并保存 - 无需重启即可热加载。
MCP:通过右上角的按钮切换。