分享一篇最近发表在Nature Methods上的生物智能体: GeneAgent。这是一个基于 LLM 的智能体,用于基因集分析;它通过与生物数据库的自主交互来验证自身输出,从而减少幻觉。在来自不同来源的 1,106 个基因集上的评估表明,GeneAgent 的准确性显著优于 GPT-4。专家评审证实,GeneAgent 生成的功能描述比 GPT-4 更相关、更全面,为理解基因功能提供了有价值的见解,并加速了知识发现。

研究背景
- 1. 基因集合分析(gene-set analysis)旨在解读一组基因背后共有的生物学机制。
- 2. 传统方法(如 GSEA)依赖 GO、MSigDB 等人工数据库,只能解释与已知功能高度重叠的基因集合,对“边缘”或“新”基因集合效果有限。
- 3. 大语言模型(LLM)可生成基因集合的功能描述,但容易产生“幻觉”(hallucination),即可信但错误的内容。
GeneAgent 的创新
- 1. 四步闭环流程
① 生成:用 GPT-4 先给出初步功能名称和分析文本。
② 自验证(self-verification):自动抽取“声明”,调用 18 个生物数据库的 Web API 进行事实核查。
③ 修正:根据核查结果修改功能名称和分析文本。
④ 总结:输出最终名称与解释。 - 2. 多数据库并行
• GSEA 类:g:Profiler、Enrichr(GO、KEGG、Reactome…)
• 文献与注释:NCBI E-utils(Gene、PubMed)
• 自定义:AgentAPI(基因-疾病、蛋白相互作用、复合体等) - 3. 防数据泄露:验证时若基因集合来自某数据库,则屏蔽该数据库,确保公平。
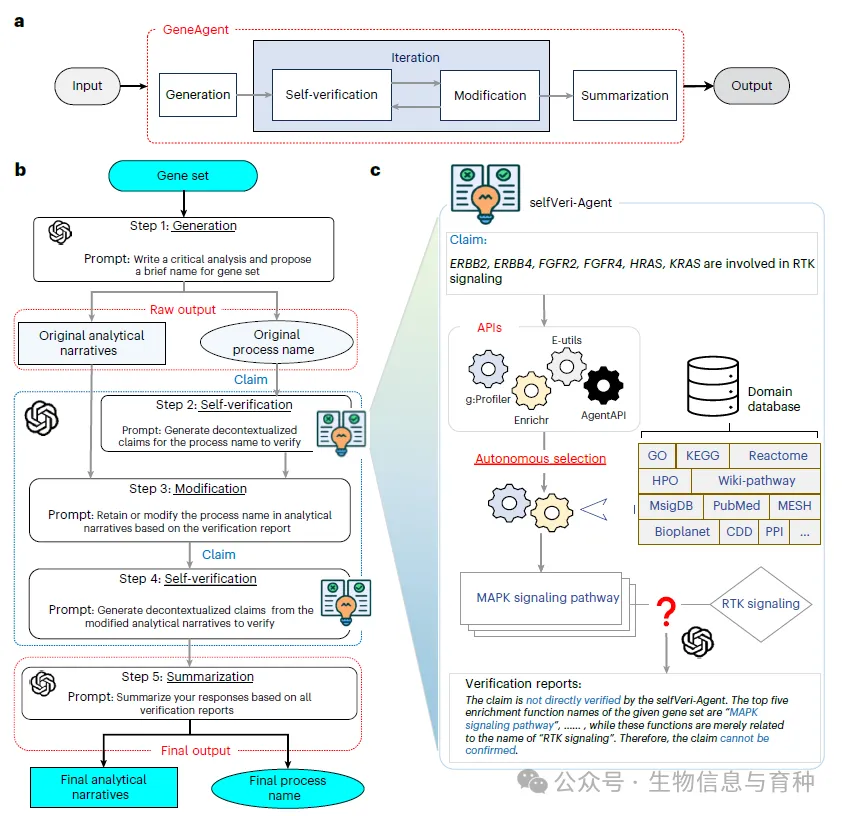
GeneAgent 基因集分析框架 a. 总体流程:包含“生成 → 自验证 → 修正 → 总结”四个模块,其中自验证模块会在修正阶段被反复调用。 b. 工作流程: 输入基因集后,“生成”步骤利用经 Hu 等人¹⁶设计的提示语驱动 LLM,输出初步的过程名称和分析叙述。 “自验证”步骤从过程名称和分析叙述中抽取声明,识别原始输出中的幻觉。 “修正”步骤对过程名称中的幻觉进行校正,并触发对分析叙述的再次验证。 “总结”步骤整合所有信息,输出更新后的过程名称和分析叙述。
性能评估(1,106 个基因集合)
|
指标 |
GeneAgent |
GPT-4 |
提升 |
|
ROUGE-L(GO 数据集) |
0.310 |
0.239 |
↑29% |
|
语义相似度>90% 的集合数 |
170 |
104 |
↑63% |
|
进入前 90 百分位的集合比例 |
76.9% |
74.5% |
↑2.4pp |
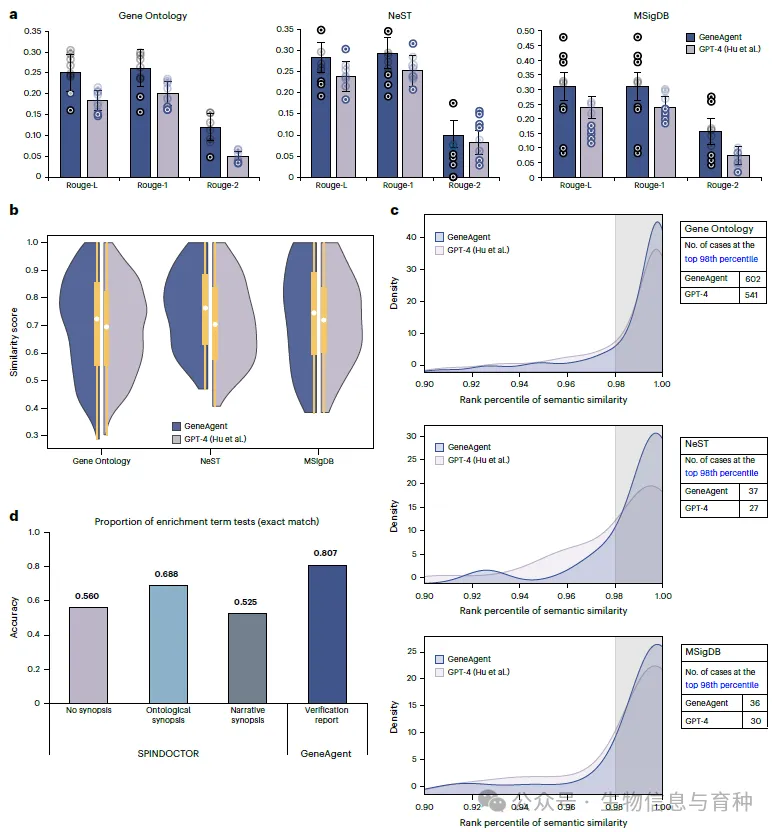
GeneAgent 生成的生物学过程名称与真实值(ground truth)的相似度,显著高于使用 Hu 等人提示语的 GPT-4 结果。 a. 在三个数据集(GO 的 1,000 个基因集、NeST 的 50 个、MSigDB 的 56 个)上,对 GeneAgent 和 GPT-4 的 ROUGE 分数进行了评估。 b. 展示了 GeneAgent 和 GPT-4 在三个数据集上获得的相似度分数分布。用于统计的基因集总数分别为 1,000(GO)、50(NeST)和 56(MSigDB)。 c. 评估了生成名称与其真实值之间的语义相似度在所有候选背景术语中的百分位分布。 d. 衡量了被测试术语与 GSEA 得到的显著富集术语完全匹配的比例。
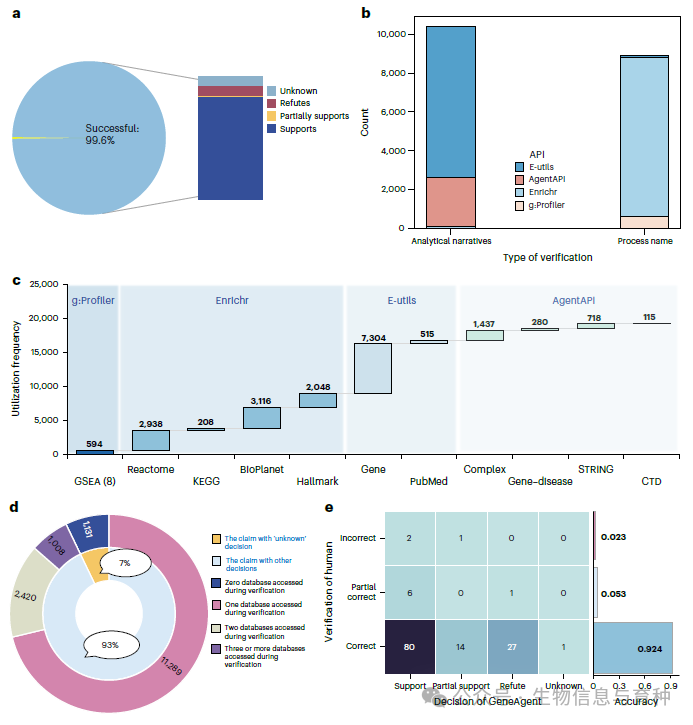
GeneAgent 通过自主调用 Web API 与领域数据库交互,从而缓解幻觉问题。 a. 统计了从 1,106 个基因集中收集的 15,903 条声明的验证结果,包括 selfVeri-Agent 做出的各类别比例。“Successfully”表示这些声明获得了 selfVeri-Agent 返回的有效验证报告。 b. 展示了用于验证“过程名称”和“分析叙述”的四类 Web API 的分布(y 轴)。 c. 显示了在 GeneAgent 自验证阶段,不同后端数据库(x 轴)的使用频率。 d. 统计了支持 selfVeri-Agent 为输入声明做出决策时所调用的数据库数量。 e. 给出了从 10 个基因集中随机选出的 132 条声明的人工验证结果。
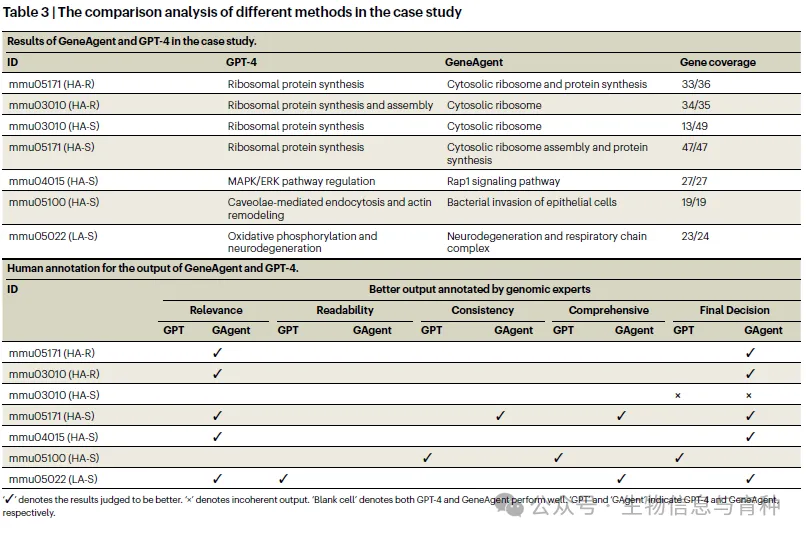
真实案例
小鼠 B2905 黑色素瘤 7 个新基因集合
- • 专家盲评:GeneAgent 在“相关性、全面性”上优于 GPT-4。
- • 例:mmu05022(LA-S)
GPT-4 → “氧化磷酸化与神经退行”
GeneAgent → “神经退行与呼吸链复合体”,并指出 Ndufa10、Atxn1l、Gpx7 的具体作用,获得专家认可。
结论与局限
- • GeneAgent 把 LLM 的生成能力与专家数据库的验证能力结合,显著减少幻觉,提升基因集合注释的准确性。
- • 已验证跨物种稳健性(人、鼠)。
- • 局限:仅基于 GPT-4;评估指标仍有改进空间;数据库覆盖度决定验证上限。
- • 代码、数据、在线演示均已开源:https://github.com/ncbi-nlp/GeneAgent