一 设计模式是什么
设计模式是软件工程中针对常见设计问题的、经过验证的、可复用的解决方案。它不是具体的代码实现,而是一套 “设计模板” 或 “思想指导”,用于解决软件设计中反复出现的问题(如 “如何灵活创建对象”“如何降低类之间的耦合”“如何让对象协作更高效” 等)。
设计模式的核心价值在于:
- 复用经验:凝聚了前人解决同类问题的最佳实践,避免重复造轮子;
- 统一标准:提供通用的设计术语(如 “工厂模式”“观察者模式”),便于团队沟通;
- 提升质量:遵循设计模式能让代码更灵活、可维护、可扩展,符合 “高内聚、低耦合” 的设计目标。
常说的 “设计模式” 通常指 1994 年《设计模式:可复用面向对象软件的基础》(又称 “GoF 书”)中提出的 23 种经典模式,这些模式基于面向对象思想,至今仍是软件设计的核心参考。
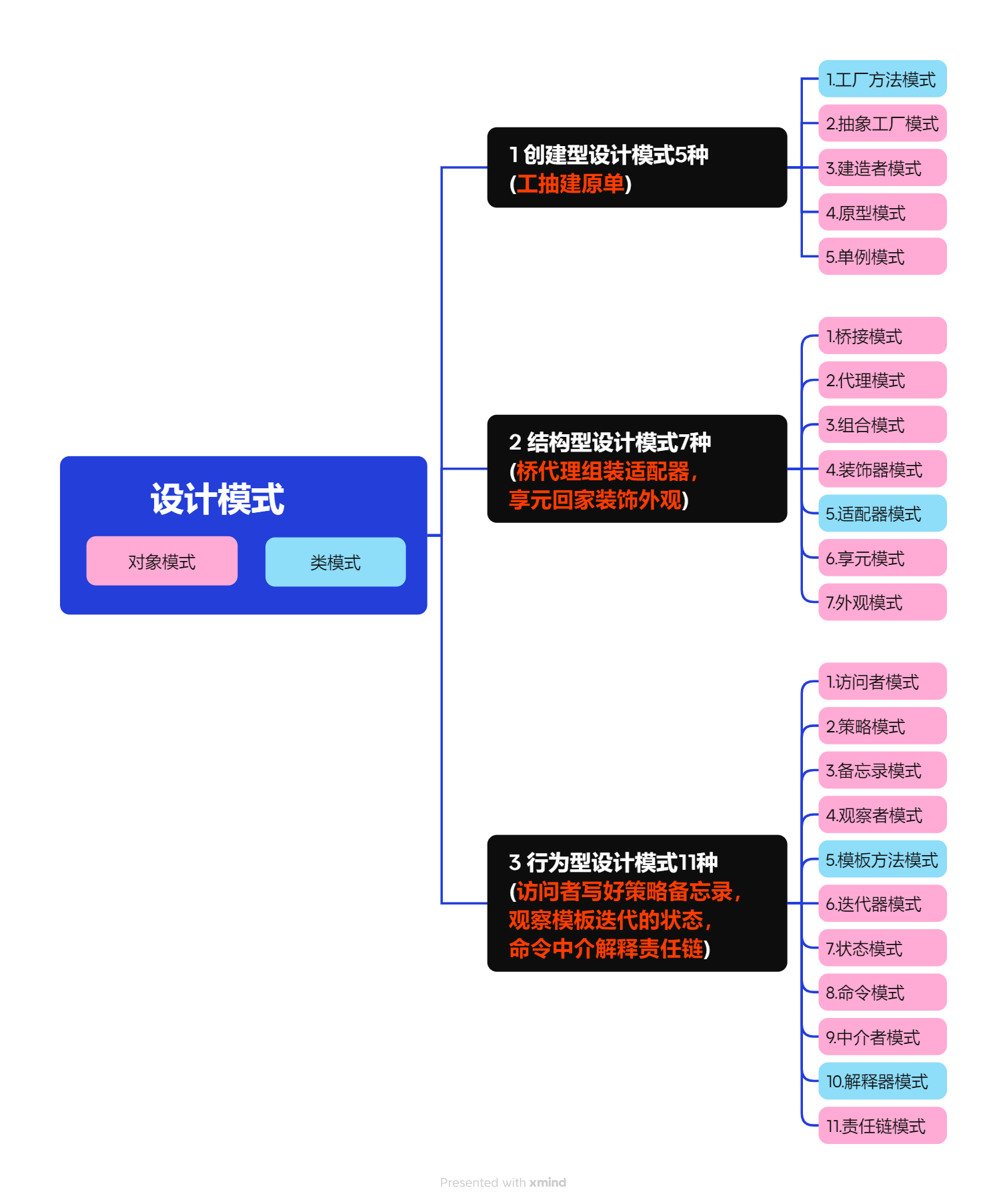
设计模式的分类
1. 按范围分类
- 类模式:处理类与类之间的静态关系(如继承、实现),结构在编译时确定,灵活性较低。
- 对象模式:处理对象与对象之间的动态关系(如组合、关联、委托),结构在运行时可调整,灵活性更高。
2. 按使用目的分类
- 创建型模式:专注于 “对象创建机制”,解耦对象创建与使用,优化对象实例化过程。
- 结构型模式:专注于 “类 / 对象的组合结构”,优化类与对象的组织方式,实现功能复用或结构灵活调整。
- 行为型模式:专注于 “对象间的交互与职责分配”,优化对象协作方式,解决行为协调、通信等问题。
设计模式1-创建型模式
作用:通过封装对象创建的细节,提供灵活的对象创建机制,解耦对象的创建与使用,以应对不同场景下的对象实例化需求。
1.1 简单工厂模式(Simple Factory Pattern)
一、什么是简单工厂模式?
简单工厂模式是创建型模式中最基础的一种,其核心思想是:由一个专门的工厂类负责创建所有产品对象。客户端无需直接创建产品,只需向工厂类传递指定参数,工厂类根据参数判断并返回对应的产品实例。
简单说:“你告诉工厂想要什么,工厂给你造出来,你不用管怎么造的”。
它不属于 GoF 的 23 种经典设计模式,但因其简单实用,常被作为学习设计模式的入门案例。
二、为什么需要简单工厂模式?(作用)
在没有工厂模式时,客户端需要直接创建各种产品对象,导致代码耦合高、扩展难。简单工厂模式的核心作用是:
- 解耦 “对象创建” 与 “对象使用”:客户端只需关心 “要什么产品”,无需知道 “产品如何创建”(如无需知道类名、构造逻辑),降低耦合。
- 集中管理创建逻辑:所有产品的创建逻辑放在工厂类中,便于统一维护(如修改创建规则时,只需改工厂,不用改所有客户端)。
- 简化客户端代码:客户端通过参数(如字符串、枚举)获取产品,无需记忆复杂的类名,代码更简洁。
三、反例:没有简单工厂模式的问题
假设我们要设计一个绘图工具,支持绘制圆形(Circle)、矩形(Rectangle)和三角形(Triangle)。
不使用简单工厂的实现:
// 1. 定义图形接口
interface Shape {void draw();
}// 2. 具体图形实现
class Circle implements Shape {@Overridepublic void draw() {System.out.println("绘制圆形");}
}class Rectangle implements Shape {@Overridepublic void draw() {System.out.println("绘制矩形");}
}class Triangle implements Shape {@Overridepublic void draw() {System.out.println("绘制三角形");}
}// 3. 客户端直接创建对象(问题所在)
public class Client {public static void main(String[] args) {// 客户端必须知道所有具体类名,才能创建对象Shape circle = new Circle();Shape rectangle = new Rectangle();Shape triangle = new Triangle();circle.draw();rectangle.draw();triangle.draw();}
}
问题分析:
- 耦合过高:客户端与具体产品类(
Circle、Rectangle)强绑定,若产品类名修改(如Circle改为Round),所有客户端都要改。 - 扩展困难:新增产品(如 “正方形”)时,需修改客户端代码(新增
new Square()),违反 “开闭原则”(对扩展开放,对修改关闭)。 - 创建逻辑分散:若创建产品需要复杂逻辑(如初始化参数、校验),会导致客户端代码臃肿,且重复逻辑无法复用。
四、正例:使用简单工厂模式解决问题
核心改进:新增一个 “工厂类”,集中处理所有产品的创建逻辑,客户端只与工厂交互。
使用简单工厂的实现:
// 1. 图形接口(不变)
interface Shape {void draw();
}// 2. 具体图形实现(不变)
class Circle implements Shape {@Overridepublic void draw() {System.out.println("绘制圆形");}
}class Rectangle implements Shape {@Overridepublic void draw() {System.out.println("绘制矩形");}
}class Triangle implements Shape {@Overridepublic void draw() {System.out.println("绘制三角形");}
}// 3. 新增:简单工厂类(核心)
class ShapeFactory {// 根据参数创建对应产品public static Shape createShape(String type) {Shape shape = null;switch (type) {case "circle":shape = new Circle();break;case "rectangle":shape = new Rectangle();break;case "triangle":shape = new Triangle();break;default:throw new IllegalArgumentException("未知图形类型:" + type);}return shape;}
}// 4. 客户端使用工厂获取产品(简化)
public class Client {public static void main(String[] args) {// 客户端只需传递参数,无需知道具体类名Shape circle = ShapeFactory.createShape("circle");Shape rectangle = ShapeFactory.createShape("rectangle");Shape triangle = ShapeFactory.createShape("triangle");circle.draw();rectangle.draw();triangle.draw();}
}
改进效果:
-
解耦成功:客户端不再依赖具体产品类(
Circle等),只依赖接口Shape和工厂ShapeFactory,耦合度大幅降低。 -
扩展更易:新增 “正方形” 时,只需:
-
新增
Square implements Shape; -
在
ShapeFactory的createShape方法中添加case "square": return new Square();,客户端代码无需任何修改,符合 “开闭原则”。
-
-
创建逻辑集中:若创建产品需要复杂逻辑(如
Circle需要初始化半径),只需在工厂的createShape中修改,所有客户端共享这一逻辑,避免重复代码。 -
创建逻辑集中:若创建产品需要复杂逻辑(如
Circle需要初始化半径),只需在工厂的createShape中修改,所有客户端共享这一逻辑,避免重复代码。
五、实现简单工厂模式的关键
- 定义抽象产品接口:所有具体产品必须实现同一个接口(如
Shape),确保工厂返回的对象可以被客户端统一使用(多态)。 - 设计工厂类:工厂类通常是一个包含静态方法的工具类(如
ShapeFactory的createShape),方法根据参数(字符串、枚举等)判断并创建具体产品。 - 参数传递规范:客户端通过参数告诉工厂 “要什么产品”,参数需简单易懂(如 “circle”“rectangle”),避免使用复杂标识。
- 处理异常情况:工厂需对无效参数(如不存在的产品类型)抛出异常,避免返回
null导致客户端出错(如示例中的IllegalArgumentException)。
记住:简单工厂的本质是 “集中创建”,让客户端 “只问结果,不问过程”。
1.2 工厂方法模式(Factory Method Pattern)
一、什么是工厂方法模式?
工厂方法模式是创建型模式的核心模式之一,其核心思想是:定义一个创建产品的抽象工厂接口,让子类(具体工厂)决定实例化哪个产品类。父类只负责声明创建产品的 “接口”,不关心具体创建逻辑;具体产品的创建由对应的具体工厂完成。
简单说:“每个产品都有专属工厂,抽象工厂规定‘怎么造’,具体工厂负责‘造什么’”。
它是对 “简单工厂模式” 的升级,解决了简单工厂中 “工厂类臃肿、新增产品需修改工厂” 的问题。
二、为什么需要工厂方法模式?(作用)
简单工厂模式通过 “一个工厂造所有产品” 实现了创建与使用的解耦,但存在 “工厂类耦合所有产品创建逻辑” 的缺陷。工厂方法模式的核心作用是:
- 彻底符合 “开闭原则”:新增产品时,只需新增 “具体产品类” 和 “对应的具体工厂类”,无需修改原有工厂或客户端代码(简单工厂需修改工厂类)。
- 职责更单一:每个具体工厂只负责创建一种产品(如 “圆形工厂只造圆形”),避免简单工厂中 “一个工厂管所有产品” 导致的逻辑臃肿。
- 扩展性更强:产品家族扩展时(如新增 10 种图形),只需对应新增 10 个工厂,原有代码零修改,系统更稳定。
- 多态性更彻底:客户端通过抽象工厂接口调用,具体工厂和产品的替换完全透明(如用 “正方形工厂” 替换 “圆形工厂”,客户端无需感知)。
三、反例:简单工厂模式的局限性
延续 “绘图工具” 场景:支持圆形、矩形、三角形,现在需要新增 “正方形”。
简单工厂模式的实现(问题复现):
// 图形接口和具体图形(不变)
interface Shape { void draw(); }
class Circle implements Shape { @Override public void draw() { System.out.println("绘制圆形"); } }
class Rectangle implements Shape { @Override public void draw() { System.out.println("绘制矩形"); } }// 简单工厂类(问题核心)
class ShapeFactory {public static Shape createShape(String type) {switch (type) {case "circle": return new Circle();case "rectangle": return new Rectangle();// 新增正方形:必须修改工厂类的switch逻辑(违反开闭原则)case "square": return new Square(); default: throw new IllegalArgumentException("未知图形");}}
}// 新增正方形产品
class Square implements Shape { @Override public void draw() { System.out.println("绘制正方形"); } }
问题分析:
简单工厂模式中,新增产品必须修改工厂类的创建逻辑(如在switch中加case),这直接违反了 “开闭原则”(对扩展开放,对修改关闭)。若产品种类增多(如 10 种、20 种图形),ShapeFactory的createShape方法会变得异常庞大,逻辑混乱,维护成本极高。
四、正例:用工厂方法模式解决问题
核心改进:将 “一个工厂造所有产品” 拆分为 “一个产品对应一个工厂”,通过抽象工厂接口定义创建规范,具体工厂实现对应产品的创建。
工厂方法模式的实现:
// 1. 抽象产品:定义所有产品的通用接口
interface Shape {void draw();
}// 2. 具体产品:实现抽象产品(每种图形对应一个类)
class Circle implements Shape {@Overridepublic void draw() {System.out.println("绘制圆形");}
}class Rectangle implements Shape {@Overridepublic void draw() {System.out.println("绘制矩形");}
}class Square implements Shape { // 新增产品:正方形@Overridepublic void draw() {System.out.println("绘制正方形");}
}// 3. 抽象工厂:定义创建产品的接口(核心)
interface ShapeFactory {Shape createShape(); // 声明创建产品的方法,不关心具体实现
}// 4. 具体工厂:每个产品对应一个专属工厂,实现抽象工厂
class CircleFactory implements ShapeFactory {@Overridepublic Shape createShape() {return new Circle(); // 只负责创建圆形}
}class RectangleFactory implements ShapeFactory {@Overridepublic Shape createShape() {return new Rectangle(); // 只负责创建矩形}
}class SquareFactory implements ShapeFactory { // 新增工厂:正方形工厂(对应新增产品)@Overridepublic Shape createShape() {return new Square(); // 只负责创建正方形}
}// 5. 客户端:通过抽象工厂接口使用,不依赖具体工厂和产品
public class Client {public static void main(String[] args) {// 客户端只需要知道抽象工厂和抽象产品ShapeFactory circleFactory = new CircleFactory();Shape circle = circleFactory.createShape();circle.draw(); // 绘制圆形ShapeFactory squareFactory = new SquareFactory(); // 使用新增的工厂Shape square = squareFactory.createShape();square.draw(); // 绘制正方形(新增功能,客户端代码无需修改)}
}
改进效果:
- 完全符合开闭原则:新增 “正方形” 时,只需新增
Square(具体产品)和SquareFactory(具体工厂),原有Shape、ShapeFactory及其他工厂 / 产品代码无需任何修改。 - 职责单一:每个具体工厂只负责一种产品的创建(如
CircleFactory只造圆形),逻辑清晰,避免了简单工厂的 “上帝类” 问题。 - 客户端彻底解耦:客户端只依赖
Shape(抽象产品)和ShapeFactory(抽象工厂),完全不知道具体产品和工厂的存在(如无需知道Circle或CircleFactory的类名),替换产品时只需换一个具体工厂即可(如用SquareFactory替换CircleFactory)。
五、实现工厂方法模式的关键
- 定义抽象产品接口:所有具体产品必须实现同一个接口(如
Shape),确保客户端能通过抽象接口统一使用(多态)。 - 定义抽象工厂接口:抽象工厂中声明一个创建产品的抽象方法(如
ShapeFactory的createShape()),该方法返回抽象产品类型(Shape),不包含任何具体创建逻辑。 - 具体工厂与产品一一对应:每个具体产品(如
Circle)必须有一个对应的具体工厂(如CircleFactory),具体工厂的createShape()方法返回对应的具体产品实例(new Circle())。 - 客户端依赖抽象:客户端代码中只能出现抽象工厂(
ShapeFactory)和抽象产品(Shape)的引用,不能直接使用具体工厂或产品(如new CircleFactory()是创建工厂的唯一耦合点,但可通过配置文件 / 反射进一步解耦)。
记住:工厂方法的本质是 “将产品创建的责任交给子类”,让系统在扩展时 “只加代码,不改代码”。
1.3 抽象工厂模式(Abstract Factory Pattern)
一、什么是抽象工厂模式?
抽象工厂模式是创建型模式中最复杂但最强大的一种,其核心思想是:提供一个接口,用于创建一系列相互关联或相互依赖的产品族(Product Family),而无需指定它们的具体类。
这里的关键概念:
- 产品族:指属于同一品牌 / 系列、相互配合使用的一组产品(如 “华为手机 + 华为充电器”“苹果手机 + 苹果充电器”)。
- 产品等级结构:指同一类型但不同品牌的产品(如 “华为手机、苹果手机、小米手机” 都属于 “手机” 这一产品等级)。
简单说:“抽象工厂定义‘造哪些产品’,具体工厂负责‘造某一系列的所有产品’,确保产品族内的产品能兼容配合”。
二、为什么需要抽象工厂模式?(作用)
工厂方法模式解决了 “单一产品的创建” 问题,但当需要创建一系列相互依赖的产品时(如一套电脑组件需匹配品牌,一套 UI 组件需统一风格),工厂方法会暴露明显缺陷。抽象工厂模式的核心作用是:
- 保证产品族内的兼容性:同一具体工厂创建的产品(如 “戴尔 CPU + 戴尔内存”)天然兼容,避免客户端因组合不同品牌产品(如 “戴尔 CPU + 苹果内存”)导致的不兼容问题。
- 隔离产品族的创建与使用:客户端只需关心 “使用哪一系列产品”(如 “用戴尔系列”),无需知道具体产品的创建细节,也无需手动组合产品(工厂会自动创建配套产品)。
- 简化产品族的切换:更换产品族时(如从 “戴尔系列” 换成 “苹果系列”),只需替换具体工厂,客户端代码无需修改(符合 “开闭原则”)。
三、反例:工厂方法模式处理产品族的局限
假设我们要设计一个电脑组装系统,需创建 “CPU” 和 “内存” 两种产品,且同一品牌的 CPU 和内存才能兼容(如 “英特尔 CPU” 需配 “英特尔内存”,“AMD CPU” 需配 “AMD 内存”)。
用工厂方法模式的实现(问题复现):
// 1. 产品等级1:CPU
interface CPU { void work(); }
class IntelCPU implements CPU { @Override public void work() { System.out.println("英特尔CPU工作"); } }
class AmdCPU implements CPU { @Override public void work() { System.out.println("AMD CPU工作"); } }// 2. 产品等级2:内存
interface Memory { void store(); }
class IntelMemory implements Memory { @Override public void store() { System.out.println("英特尔内存存储"); } }
class AmdMemory implements Memory { @Override public void store() { System.out.println("AMD内存存储"); } }// 3. 工厂方法:每个产品等级对应一个工厂
interface CPUFactory { CPU createCPU(); }
class IntelCPUFactory implements CPUFactory { @Override public CPU createCPU() { return new IntelCPU(); } }
class AmdCPUFactory implements CPUFactory { @Override public CPU createCPU() { return new AmdCPU(); } }interface MemoryFactory { Memory createMemory(); }
class IntelMemoryFactory implements MemoryFactory { @Override public Memory createMemory() { return new IntelMemory(); } }
class AmdMemoryFactory implements MemoryFactory { @Override public Memory createMemory() { return new AmdMemory(); } }// 4. 客户端:手动组合产品(问题核心)
public class Client {public static void main(String[] args) {// 客户端需要自己选择配套的工厂,容易出错CPUFactory cpuFactory = new IntelCPUFactory(); // 选英特尔CPU工厂MemoryFactory memoryFactory = new AmdMemoryFactory(); // 错误:选了AMD内存工厂CPU cpu = cpuFactory.createCPU();Memory memory = memoryFactory.createMemory();cpu.work(); // 英特尔CPU工作memory.store(); // AMD内存存储(不兼容,实际会出问题)}
}
问题分析:
工厂方法模式中,每个产品等级(CPU、内存)对应独立的工厂,客户端需要手动选择多个工厂来组合产品。这会导致:
- 兼容性风险:客户端可能误选不同品牌的工厂(如 “英特尔 CPU+AMD 内存”),导致产品不兼容;
- 产品族管理复杂:若产品族包含 10 种产品(CPU、内存、显卡、主板...),客户端需要创建 10 个工厂并手动匹配,代码臃肿且易出错;
- 切换产品族成本高:从 “英特尔系列” 换成 “AMD 系列” 时,客户端需要修改所有工厂的创建代码(如把
IntelCPUFactory换成AmdCPUFactory,同时把IntelMemoryFactory换成AmdMemoryFactory),不符合 “开闭原则”。
四、正例:用抽象工厂模式解决问题
核心改进:将 “同一产品族的所有产品创建” 封装到一个具体工厂中,抽象工厂定义 “需要创建哪些产品”,具体工厂负责 “创建某一系列的所有产品”,确保产品兼容。
抽象工厂模式的实现:
// 1. 定义产品等级结构(CPU和内存)
interface CPU {void work();
}
class IntelCPU implements CPU {@Overridepublic void work() {System.out.println("英特尔CPU工作");}
}
class AmdCPU implements CPU {@Overridepublic void work() {System.out.println("AMD CPU工作");}
}interface Memory {void store();
}
class IntelMemory implements Memory {@Overridepublic void store() {System.out.println("英特尔内存存储");}
}
class AmdMemory implements Memory {@Overridepublic void store() {System.out.println("AMD内存存储");}
}// 2. 抽象工厂:定义创建产品族的接口(核心)
interface ComputerComponentFactory {// 声明创建产品族中所有产品的方法(CPU和内存)CPU createCPU();Memory createMemory();
}// 3. 具体工厂:每个工厂负责创建一个产品族(英特尔系列、AMD系列)
class IntelFactory implements ComputerComponentFactory {@Overridepublic CPU createCPU() {return new IntelCPU(); // 英特尔工厂造英特尔CPU}@Overridepublic Memory createMemory() {return new IntelMemory(); // 英特尔工厂造英特尔内存(天然兼容)}
}class AmdFactory implements ComputerComponentFactory {@Overridepublic CPU createCPU() {return new AmdCPU(); // AMD工厂造AMD CPU}@Overridepublic Memory createMemory() {return new AmdMemory(); // AMD工厂造AMD内存(天然兼容)}
}// 4. 客户端:通过抽象工厂获取整个产品族(无需关心具体产品)
public class Client {public static void main(String[] args) {// 选择产品族:只需指定一个具体工厂(如英特尔系列)ComputerComponentFactory factory = new IntelFactory();// 从工厂获取配套产品(无需手动匹配,天然兼容)CPU cpu = factory.createCPU();Memory memory = factory.createMemory();cpu.work(); // 英特尔CPU工作memory.store(); // 英特尔内存存储(兼容)// 切换产品族:只需换工厂,其他代码不变(符合开闭原则)factory = new AmdFactory();cpu = factory.createCPU();memory = factory.createMemory();cpu.work(); // AMD CPU工作memory.store(); // AMD内存存储(兼容)}
}
改进效果:
- 产品族兼容性保障:同一具体工厂(如
IntelFactory)创建的CPU和Memory必然属于同一品牌(英特尔),避免客户端误组合导致的不兼容问题。 - 产品族管理简化:客户端只需选择一个具体工厂,即可获取该系列的所有产品(无需创建多个工厂),代码更简洁。
- 产品族切换便捷:从 “英特尔系列” 换成 “AMD 系列” 时,只需将
new IntelFactory()改为new AmdFactory(),客户端其他代码完全不变,严格符合 “开闭原则”。
五、实现抽象工厂模式的关键
-
明确 “产品族” 和 “产品等级”:
-
产品等级:同一类型的产品(如 CPU、内存、显卡),对应抽象产品接口(
CPU、Memory); -
产品族:同一品牌 / 系列的一组产品(如英特尔系列包含英特尔 CPU、英特尔内存),对应具体工厂(
IntelFactory)。
抽象工厂的核心是 “按产品族组织工厂”,而非按产品等级。
-
-
抽象工厂接口定义产品族的创建方法:抽象工厂接口(如
ComputerComponentFactory)中,每个方法对应一个产品等级的创建(createCPU()对应 CPU,createMemory()对应内存),方法返回值为抽象产品类型(CPU、Memory)。 -
具体工厂实现产品族的创建:每个具体工厂(如
IntelFactory)必须实现抽象工厂的所有方法,且返回的产品必须属于同一产品族(如英特尔 CPU + 英特尔内存),确保兼容性。 -
客户端依赖抽象工厂和抽象产品:客户端代码中只能出现抽象工厂(
ComputerComponentFactory)和抽象产品(CPU、Memory)的引用,不能直接使用具体工厂或产品,确保切换产品族时的透明性。
记住:抽象工厂的本质是 “封装产品族的创建”,让客户端 “一键获取配套产品”。
1.4 建造者模式(Builder Pattern)
一、什么是建造者模式?
建造者模式是 ** 创建型模式中专注于 “复杂对象构建”** 的模式,其核心思想是:将复杂对象的构建过程与它的表示分离,使得同样的构建过程可以创建不同的表示。
简单说:“分步构建复杂对象,相同的步骤能造出不同样子的产品”。
这里的 “复杂对象” 指由多个部件(或子对象)组成,且构建过程需要遵循一定步骤的对象(如电脑由 CPU、内存、硬盘等组成,需按顺序组装;披萨由饼底、酱料、配料等组成,需分步制作)。
二、为什么需要建造者模式?(作用)
当创建一个包含多个部件的复杂对象时,直接通过构造函数或 setter 方法会导致代码混乱、步骤失控。建造者模式的核心作用是:
- 简化复杂对象的构建:将对象的构建拆分为多个独立步骤(如 “装 CPU→装内存→装硬盘”),每个步骤由专门的方法处理,逻辑更清晰。
- 控制构建顺序:通过 “指挥者” 统一管理步骤顺序(如必须先装主板再装 CPU),避免客户端因步骤错误导致对象状态异常。
- 支持多样化表示:同一套构建步骤(如 “制作披萨” 的 “做饼底→加酱料→放配料”),通过不同的 “具体建造者” 可创建不同产品(如 “玛格丽特披萨”“ Pepperoni 披萨”)。
- 隔离构建细节与使用:客户端只需指定 “要什么产品”,无需知道具体部件和构建步骤(如只需说 “要一台游戏本”,建造者会自动处理细节)。
三、反例:没有建造者模式的问题
假设我们要创建一个 “电脑” 对象,包含 CPU、内存、硬盘、显卡、操作系统等部件,且构建需遵循一定顺序(如先装硬件,再装系统)。
不使用建造者模式的实现:
// 复杂产品:电脑
class Computer {private String cpu;private String memory;private String hardDisk;private String graphicsCard;private String os;// 问题1:参数过多,构造函数臃肿(若有10个部件,参数列表会极长)public Computer(String cpu, String memory, String hardDisk, String graphicsCard, String os) {this.cpu = cpu;this.memory = memory;this.hardDisk = hardDisk;this.graphicsCard = graphicsCard;this.os = os;}// 问题2:若允许分步设置,无法保证顺序(如先装系统再装硬件,逻辑错误)public void setCpu(String cpu) { this.cpu = cpu; }public void setOs(String os) { this.os = os; }// ... 其他setter方法
}// 客户端:直接创建或分步设置(问题集中爆发)
public class Client {public static void main(String[] args) {// 方式1:构造函数参数太多,易传错顺序(如把内存参数传给硬盘)Computer gamingPC = new Computer("Intel i9", "32GB", "1TB SSD", "RTX 4090", "Windows 11");// 方式2:分步setter,可能出现步骤错误(先装系统,再装硬件,逻辑上不成立)Computer officePC = new Computer(null, null, null, null, null);officePC.setOs("Windows 10"); // 错误:还没装硬件就装系统officePC.setCpu("Intel i5");}
}
问题分析:
- 参数爆炸:复杂对象的部件越多,构造函数参数越长,可读性差且易传错顺序;
- 步骤失控:用 setter 方法分步设置时,客户端可能违反构建逻辑(如先装系统再装硬件),导致对象处于无效状态;
- 扩展性差:若需新增部件(如 “散热器”),必须修改构造函数或新增 setter,违反 “开闭原则”;
- 表示单一:难以通过同一套逻辑创建不同配置的产品(如 “游戏本” 和 “办公本” 需分别写构造逻辑,重复代码多)。
四、正例:用建造者模式解决问题
核心改进:将 “构建步骤” 与 “产品表示” 分离,通过 “抽象建造者” 定义步骤,“具体建造者” 实现细节,“指挥者” 控制顺序,最终构建出不同配置的产品。
建造者模式的实现:
// 1. 复杂产品:电脑(只关注数据和功能,不关心构建)
class Computer {private String cpu;private String memory;private String hardDisk;private String graphicsCard;private String os;// 私有构造函数,仅允许建造者访问private Computer() {}// 设置部件的方法(由建造者调用)public void setCpu(String cpu) { this.cpu = cpu; }public void setMemory(String memory) { this.memory = memory; }public void setHardDisk(String hardDisk) { this.hardDisk = hardDisk; }public void setGraphicsCard(String graphicsCard) { this.graphicsCard = graphicsCard; }public void setOs(String os) { this.os = os; }@Overridepublic String toString() {return "电脑配置:CPU=" + cpu + ", 内存=" + memory + ", 硬盘=" + hardDisk + ", 显卡=" + graphicsCard + ", 系统=" + os;}
}// 2. 抽象建造者:定义构建步骤(核心)
interface ComputerBuilder {void buildCpu(); // 装CPUvoid buildMemory(); // 装内存void buildHardDisk(); // 装硬盘void buildGraphicsCard(); // 装显卡void installOs(); // 装系统Computer getResult(); // 返回构建好的产品
}// 3. 具体建造者1:构建游戏本(高配置)
class GamingComputerBuilder implements ComputerBuilder {private Computer computer = new Computer(); // 持有产品实例@Overridepublic void buildCpu() {computer.setCpu("Intel i9-13900K");}@Overridepublic void buildMemory() {computer.setMemory("64GB DDR5");}@Overridepublic void buildHardDisk() {computer.setHardDisk("2TB SSD");}@Overridepublic void buildGraphicsCard() {computer.setGraphicsCard("NVIDIA RTX 4090");}@Overridepublic void installOs() {computer.setOs("Windows 11 专业版");}@Overridepublic Computer getResult() {return computer;}
}// 4. 具体建造者2:构建办公本(基础配置)
class OfficeComputerBuilder implements ComputerBuilder {private Computer computer = new Computer();@Overridepublic void buildCpu() {computer.setCpu("Intel i5-13400");}@Overridepublic void buildMemory() {computer.setMemory("16GB DDR4");}@Overridepublic void buildHardDisk() {computer.setHardDisk("512GB SSD");}@Overridepublic void buildGraphicsCard() {computer.setGraphicsCard("集成显卡"); // 办公本无需独立显卡}@Overridepublic void installOs() {computer.setOs("Windows 10 家庭版");}@Overridepublic Computer getResult() {return computer;}
}// 5. 指挥者:控制构建顺序(确保步骤正确)
class Director {// 指挥建造者按顺序执行步骤public Computer construct(ComputerBuilder builder) {builder.buildCpu(); // 第一步:装CPUbuilder.buildMemory(); // 第二步:装内存builder.buildHardDisk(); // 第三步:装硬盘builder.buildGraphicsCard(); // 第四步:装显卡builder.installOs(); // 第五步:装系统(必须在硬件之后)return builder.getResult();}
}// 6. 客户端:通过指挥者和具体建造者获取产品
public class Client {public static void main(String[] args) {// 创建指挥者(负责流程)Director director = new Director();// 构建游戏本:用游戏本建造者Computer gamingPC = director.construct(new GamingComputerBuilder());System.out.println(gamingPC); // 输出高配置游戏本// 构建办公本:用办公本建造者(步骤不变,产品不同)Computer officePC = director.construct(new OfficeComputerBuilder());System.out.println(officePC); // 输出基础配置办公本}
}
改进效果:
- 步骤可控:指挥者
Director严格控制构建顺序(先硬件后系统),避免客户端出错,确保对象状态有效; - 构建与表示分离:
Computer只负责存储数据,ComputerBuilder负责具体部件的构建,Director负责流程,职责清晰; - 支持多样化产品:同一套步骤(
construct方法),通过不同建造者(GamingComputerBuilder/OfficeComputerBuilder)可创建不同配置的电脑,复用构建逻辑; - 扩展方便:新增 “设计本” 时,只需新增
DesignComputerBuilder实现ComputerBuilder,无需修改指挥者或产品类,符合 “开闭原则”; - 客户端简化:客户端只需选择具体建造者,无需知道部件细节和步骤顺序(如不用关心 “先装 CPU 还是内存”)。
五、实现建造者模式的关键
- 定义复杂产品类:包含多个部件,提供部件的设置方法(通常构造函数私有,仅允许建造者访问)。
- 抽象建造者接口:声明所有构建步骤的方法(如
buildCpu()、installOs()),以及返回最终产品的getResult()方法。 - 具体建造者实现:每个具体建造者对应一种产品表示(如游戏本、办公本),实现抽象建造者的所有方法,负责具体部件的创建和组装。
- 指挥者控制流程:指挥者持有抽象建造者引用,通过调用建造者的步骤方法,按固定顺序完成构建(确保步骤正确,避免客户端干预)。
- 客户端只选建造者:客户端创建具体建造者,交给指挥者,最终从指挥者或建造者获取产品,全程不参与构建细节。
记住:建造者模式让复杂对象的创建 “步骤化、清晰化、可定制化”。
1.5 原型模式(Prototype Pattern)
一、什么是原型模式?
原型模式是 ** 创建型模式中专注于 “通过复制生成对象”** 的模式,其核心思想是:通过复制一个已存在的 “原型对象” 来创建新对象,而无需重新执行复杂的初始化过程。
简单说:“以旧对象为模板,复制出一个新对象,新对象的初始状态和原型一致,后续可独立修改”。
这里的 “原型” 指已初始化完成的对象,复制(克隆)过程由原型自身提供,客户端只需调用克隆方法即可快速获取新对象,无需关心对象的创建细节。
二、为什么需要原型模式?(作用)
当对象的创建过程复杂(如需要读取配置文件、查询数据库、进行复杂计算)或成本较高(如耗时、耗资源)时,直接通过new关键字创建新对象会导致效率低下、代码重复。原型模式的核心作用是:
- 提高对象创建效率:复制现有对象(内存层面的拷贝)比重新执行初始化逻辑(如 IO 操作、计算)更快,尤其适合大对象或创建频繁的场景。
- 简化对象创建逻辑:客户端无需知道对象的初始化细节(如构造函数参数、依赖关系),只需调用克隆方法,代码更简洁。
- 支持动态生成对象:可在运行时根据原型动态克隆出不同状态的对象(如基于一个 “基础文档” 克隆出多个 “个性化文档”)。
- 避免构造函数的约束:当对象的构造函数复杂(如私有构造、多参数)或不允许直接调用时,克隆是获取新对象的有效方式。
三、反例:没有原型模式的问题
假设我们要创建一个 “报表对象”,其初始化需要读取模板文件、加载数据、设置样式,过程复杂且耗时。
不使用原型模式的实现:
// 复杂对象:报表(创建成本高)
class Report {private String template; // 报表模板(需从文件读取)private String data; // 报表数据(需从数据库查询)private String style; // 报表样式(需计算生成)// 构造函数:初始化过程复杂且耗时public Report() {this.template = readTemplateFromFile(); // 读取文件(IO操作,耗时)this.data = queryDataFromDB(); // 查询数据库(网络操作,耗时)this.style = calculateStyle(); // 复杂计算(耗CPU)System.out.println("报表初始化完成(耗时操作)");}// 模拟耗时操作private String readTemplateFromFile() { return "报表模板内容"; }private String queryDataFromDB() { return "报表数据"; }private String calculateStyle() { return "样式:字体12号,居中"; }// 设置报表标题(个性化修改)public void setTitle(String title) {System.out.println("报表标题设置为:" + title);}
}// 客户端:多次创建报表对象(问题核心)
public class Client {public static void main(String[] args) {// 第一次创建:执行耗时初始化Report report1 = new Report();report1.setTitle("第一季度报表");// 第二次创建:再次执行耗时初始化(重复浪费资源)Report report2 = new Report();report2.setTitle("第二季度报表");// 第三次创建:第三次执行耗时初始化...Report report3 = new Report();report3.setTitle("第三季度报表");}
}
问题分析:
- 效率低下:每次创建
Report对象都要重复执行 “读文件、查数据库、计算样式” 等耗时操作,即使这些初始内容完全相同(如模板和样式不变),也会造成资源浪费; - 代码冗余:若需要创建多个 “初始状态相同、仅个性化信息不同” 的对象(如不同标题的报表),重复的初始化逻辑会导致代码臃肿;
- 扩展性差:若初始化逻辑变更(如模板来源从文件改为网络),所有创建
Report的地方都需修改,违反 “开闭原则”。
四、正例:用原型模式解决问题
核心改进:让原型对象自身提供 “克隆” 方法,客户端通过复制原型获取新对象,避免重复初始化。
原型模式的实现(基于 Java 的Cloneable接口):
// 1. 原型接口:实现Cloneable(标记接口,指示对象可克隆)
class Report implements Cloneable {private String template;private String data;private String style;private String title; // 新增标题(个性化字段)// 构造函数:仅初始化一次原型public Report() {this.template = readTemplateFromFile();this.data = queryDataFromDB();this.style = calculateStyle();System.out.println("原型报表初始化完成(仅执行一次耗时操作)");}// 核心:重写clone方法,实现对象克隆@Overrideprotected Report clone() {try {// 调用父类的clone(),完成内存层面的拷贝return (Report) super.clone();} catch (CloneNotSupportedException e) {throw new RuntimeException("克隆失败", e);}}// 个性化方法:设置标题public void setTitle(String title) {this.title = title;System.out.println("报表标题设置为:" + title);}// 模拟耗时操作(不变)private String readTemplateFromFile() { return "报表模板内容"; }private String queryDataFromDB() { return "报表数据"; }private String calculateStyle() { return "样式:字体12号,居中"; }
}// 2. 客户端:通过克隆原型创建新对象
public class Client {public static void main(String[] args) {// 1. 创建原型对象(仅执行一次耗时初始化)Report prototype = new Report();// 2. 克隆原型,获取新对象(无需重复初始化,效率高)Report report1 = prototype.clone();report1.setTitle("第一季度报表");Report report2 = prototype.clone();report2.setTitle("第二季度报表");Report report3 = prototype.clone();report3.setTitle("第三季度报表");}
}
改进效果:
- 效率提升:仅原型对象执行一次耗时初始化,后续新对象通过克隆(内存拷贝)生成,避免重复的 IO、数据库操作,大幅节省资源;
- 代码简化:客户端无需关心
Report的初始化细节,只需调用clone()即可获取新对象,逻辑更清晰; - 个性化灵活:克隆出的新对象与原型初始状态一致,但可独立修改个性化字段(如标题),互不影响;
- 扩展性增强:若初始化逻辑变更,只需修改原型的构造函数,所有克隆操作不受影响,符合 “开闭原则”。
记住:原型模式的本质是 “对象的自我复制”,让创建新对象像 “复制粘贴” 一样简单高效。
1.6 单例模式(Singleton Pattern)
一、什么是单例模式?
单例模式是创建型模式中最常用的模式之一,其核心思想是:保证一个类在整个应用程序中只有一个实例对象,并提供一个全局访问点供外界获取该实例。
简单说:“一个类只能 new 一次,所有人用的都是同一个对象”。
二、为什么需要单例模式?(作用)
在实际开发中,某些类的对象需要被全局共享(如配置信息、日志工具),或创建 / 销毁成本极高(如数据库连接池、线程池)。若允许多次创建这类对象,会导致资源浪费、状态混乱等问题。单例模式的核心作用是:
- 节省系统资源:避免频繁创建和销毁重量级对象(如数据库连接),减少内存占用和性能损耗。
- 保证数据一致性:全局只有一个实例,所有操作都基于该实例,避免多实例导致的状态冲突(如日志工具多实例可能导致日志写入混乱)。
- 提供全局访问点:外界无需关心实例的创建细节,通过统一接口即可获取实例,简化代码调用。
三、反例:没有单例模式的问题
假设我们设计一个 “日志工具类”,用于向文件写入日志。若不使用单例模式,可能出现以下问题:
不使用单例模式的实现:
// 日志工具类(非单例)
class Logger {private FileWriter writer; // 日志文件写入流// 构造函数:打开日志文件(耗时操作)public Logger() {try {this.writer = new FileWriter("app.log", true); // 追加模式System.out.println("日志文件打开成功");} catch (IOException e) {throw new RuntimeException("日志文件打开失败", e);}}// 写入日志public void log(String message) {try {writer.write(message + "\n");writer.flush();} catch (IOException e) {throw new RuntimeException("日志写入失败", e);}}// 关闭文件(若忘记调用,会导致资源泄漏)public void close() {try {writer.close();System.out.println("日志文件关闭");} catch (IOException e) {throw new RuntimeException("日志文件关闭失败", e);}}
}// 客户端:多次创建日志对象(问题核心)
public class Client {public static void main(String[] args) {// 第一次创建:打开日志文件Logger logger1 = new Logger();logger1.log("操作1:用户登录");// 第二次创建:再次打开日志文件(重复占用资源)Logger logger2 = new Logger();logger2.log("操作2:数据查询");// 可能忘记关闭某个实例,导致文件句柄泄漏logger1.close(); // 只关闭了logger1,logger2的流未关闭}
}
问题分析:
- 资源浪费:每次创建
Logger都会打开日志文件,多个实例同时持有文件句柄,浪费系统资源; - 数据不一致:多实例写入日志可能导致内容错乱(如两个实例同时写入,内容交织);
- 资源泄漏风险:若客户端忘记关闭某个实例,会导致文件句柄长期占用,系统异常;
- 全局状态混乱:若日志工具需要维护全局配置(如日志级别),多实例会导致配置不统一(一个实例设为 “INFO”,另一个设为 “ERROR”)。
四、正例:用单例模式解决问题
核心改进:通过私有构造函数阻止外界直接创建实例,内部维护唯一实例,并提供全局访问方法。
单例模式的常见实现方式
单例模式有多种实现方式,核心是 “阻止多实例创建” 和 “保证全局唯一”,不同方式在线程安全、懒加载(延迟初始化)等方面有差异。
1. 饿汉式(Eager Initialization)
思想:类加载时就创建实例(“饿”,迫不及待初始化),天然线程安全。
class Logger {// 1. 私有静态实例:类加载时初始化,保证唯一private static final Logger INSTANCE = new Logger();// 2. 私有构造函数:阻止外界newprivate Logger() {try {this.writer = new FileWriter("app.log", true);System.out.println("日志文件打开成功");} catch (IOException e) {throw new RuntimeException("日志文件打开失败", e);}}// 3. 公共静态方法:提供全局访问点public static Logger getInstance() {return INSTANCE;}// 日志相关代码(省略)private FileWriter writer;public void log(String message) { /* ... */ }public void close() { /* ... */ }
}// 客户端使用:
public class Client {public static void main(String[] args) {// 只能通过getInstance()获取实例,多次调用返回同一个对象Logger logger1 = Logger.getInstance();Logger logger2 = Logger.getInstance();System.out.println(logger1 == logger2); // true(同一实例)logger1.log("操作1:用户登录");logger2.log("操作2:数据查询"); // 同一实例,日志写入有序logger1.close(); // 一次关闭即可}
}
优点:实现简单,类加载时初始化,天然线程安全(JVM 保证类加载过程是线程安全的);缺点:若实例创建成本高(如占内存大)且程序可能永远用不到,会导致资源浪费(“饿” 得太早)。
2. 懒汉式(Lazy Initialization,线程不安全版)
思想:第一次使用时才创建实例(“懒”,用的时候再初始化),但多线程环境下可能创建多个实例。
class Logger {// 1. 私有静态实例:初始为null,延迟初始化private static Logger instance;// 2. 私有构造函数private Logger() { /* 初始化逻辑 */ }// 3. 公共静态方法:第一次调用时创建实例public static Logger getInstance() {if (instance == null) { // 问题:多线程可能同时进入此判断instance = new Logger(); }return instance;}// 日志相关代码(省略)
}
优点:延迟初始化,避免资源浪费;缺点:多线程环境下不安全 —— 若两个线程同时执行if (instance == null),会创建两个实例,违反单例原则。
3. 懒汉式(线程安全版,加锁)
思想:在getInstance()方法上加synchronized锁,保证多线程下只有一个线程能创建实例。
class Logger {private static Logger instance;private Logger() { /* 初始化逻辑 */ }// 加锁保证线程安全public static synchronized Logger getInstance() {if (instance == null) {instance = new Logger();}return instance;}
}
优点:延迟初始化,线程安全;缺点:synchronized锁会导致性能损耗 —— 即使实例已创建,每次调用getInstance()仍需加锁,效率低。
4. 双重检查锁(Double-Checked Locking,DCL)
思想:两次检查实例是否为null,仅在第一次创建时加锁,兼顾线程安全和性能。
class Logger {// 1. volatile关键字:防止指令重排序(关键!)private static volatile Logger instance;private Logger() { /* 初始化逻辑 */ }public static Logger getInstance() {// 第一次检查:若实例已存在,直接返回(无需加锁,提升性能)if (instance == null) { synchronized (Logger.class) { // 第二次检查:防止多线程同时通过第一次检查后,重复创建if (instance == null) { instance = new Logger(); }}}return instance;}
}
关键细节:
volatile关键字:阻止 JVM 对instance = new Logger()进行指令重排序(可能导致其他线程获取到 “未完全初始化的实例”);- 双重检查:外层检查避免频繁加锁,内层检查防止多线程竞争时重复创建。
优点:延迟初始化,线程安全,性能高(仅首次创建时加锁);缺点:实现较复杂,需理解volatile和指令重排序的原理。
5. 静态内部类(Holder 模式)
思想:通过静态内部类延迟初始化实例,利用 JVM 类加载机制保证线程安全。
class Logger {// 1. 私有构造函数private Logger() { /* 初始化逻辑 */ }// 2. 静态内部类:仅在被调用时才加载private static class LoggerHolder {// 内部类加载时创建实例,JVM保证线程安全private static final Logger INSTANCE = new Logger();}// 3. 公共方法:调用内部类的实例public static Logger getInstance() {return LoggerHolder.INSTANCE;}
}
原理:
- 外部类
Logger加载时,内部类LoggerHolder不会被加载; - 第一次调用
getInstance()时,LoggerHolder被加载,创建INSTANCE,JVM 保证类加载过程是线程安全的,因此实例唯一。
优点:延迟初始化,线程安全,实现简单(无需手动加锁),性能高;缺点:无法通过反射破坏单例(相对其他方式更安全)。
6. 枚举单例(Enum Singleton)
思想:利用 Java 枚举的特性(枚举实例天生唯一,且由 JVM 保证)实现单例,是《Effective Java》推荐的方式。
// 枚举单例:枚举值就是唯一实例
enum Logger {INSTANCE; // 唯一实例// 枚举的构造函数默认私有,且仅执行一次Logger() {try {this.writer = new FileWriter("app.log", true);System.out.println("日志文件打开成功");} catch (IOException e) {throw new RuntimeException("日志文件打开失败", e);}}// 日志相关方法private FileWriter writer;public void log(String message) { try {writer.write(message + "\n");writer.flush();} catch (IOException e) {throw new RuntimeException("日志写入失败", e);}}public void close() { /* ... */ }
}// 客户端使用:
public class Client {public static void main(String[] args) {Logger logger1 = Logger.INSTANCE;Logger logger2 = Logger.INSTANCE;System.out.println(logger1 == logger2); // true(同一实例)logger1.log("操作日志");}
}
优点:
- 实现极简,一行代码定义实例;
- 天生线程安全(JVM 保证枚举实例的创建是线程安全的);
- 防反射和序列化破坏(其他方式可能被反射强制创建实例,枚举则不会)。
缺点:枚举实例在类加载时初始化(非懒加载),若实例创建成本极高且可能不用,会浪费资源。
五、单例模式的破坏与防护
某些场景下,单例模式可能被 “破坏”(创建多个实例),需针对性防护:
1. 反射破坏与防护
问题:通过反射调用私有构造函数,可强制创建新实例。
// 反射破坏饿汉式单例(其他非枚举方式同理)
public class Test {public static void main(String[] args) throws Exception {// 获取私有构造函数Constructor<Logger> constructor = Logger.class.getDeclaredConstructor();constructor.setAccessible(true); // 绕过私有访问限制Logger reflectionInstance = constructor.newInstance(); // 创建新实例Logger normalInstance = Logger.getInstance();System.out.println(reflectionInstance == normalInstance); // false(破坏成功)}
}
防护:在构造函数中检查实例是否已存在,若存在则抛出异常(枚举单例天然免疫)。
private Logger() {if (INSTANCE != null) { // 饿汉式示例throw new RuntimeException("单例模式禁止反射创建实例");}// 初始化逻辑...
}
2. 序列化破坏与防护
问题:对单例实例序列化后再反序列化,会生成新实例(枚举单例天然免疫)。
防护:重写readResolve()方法,返回已有实例。
class Logger implements Serializable {// 其他单例代码...// 反序列化时调用,返回已有实例,避免创建新对象private Object readResolve() {return INSTANCE;}
}
六、总结
单例模式的核心是 “唯一实例 + 全局访问”,通过私有构造和静态方法保证一个类在应用中只有一个实例,解决了资源浪费和状态不一致的问题。
实际开发中,推荐优先使用枚举单例(简单、安全)或静态内部类(懒加载、高效);若需懒加载且考虑性能,可选择双重检查锁。需注意避免过度使用单例(如非必要的工具类),以免引入测试困难和扩展性问题。
记住:单例模式的本质是 “控制实例数量”,只在 “必须全局唯一” 的场景下使用。