
价格大幅下降,这是谁给的底气了?必定是成本大幅下降呗,否则不得亏死?那么问题又来了:成本又是怎么大幅下降的了?
2、时至今日,尽管被各种吐槽(其中不乏yan lecun、feifeili等top级学术大佬),但商用的主流LLM架构还是transformer,核心原因就是attention机制:能非常好地提取每个token的语义信息!但这也是有代价的:time&space complex达到了O(n^2)。比如 当 seq =32K 时,QK^T 矩阵大小为 32K × 32K = 10 亿元素 , 计算和显存直接爆炸,这也是LLM成本高的核心原因之一!怎么既能很好地提取语义信息,又能大幅降低时间和空间复杂度了?这个问题从2019年开始就有各路大佬开始研究了。近1年内,主流的降成本方法有:
- native sparse attention,也是deepseek家的,详见:https://www.cnblogs.com/theseventhson/p/18738724
- gated dalta rule,qwen3-next-80B采用的方案,详见:https://www.cnblogs.com/theseventhson/p/19098032
deepseek之前就使用了native sparse attention降本了,这次采用又是哪种新方案降本了?
3、一段long context的长文本,其实不是每个token都很重要的,比如:
- 语气助词“的”、“地”、“了”、“啊”、“吧”等,这些token没任何实质性的语义,计算attention有啥用了?
- “今天天气不错啊,万里无云;我们来聊聊量子力学的现状和未来趋势吧”,这段seq中,很明显重点必定是量子力学的现状和未来趋势了,至于前面说的天气情况完全不重要,计算attention有啥用了?
所以降本的核心思路是:去掉语义不重要的token,只保留语义重要的token计算attention!思路确定了,接下里就要实现了,具体该怎么做了?换句话说,怎么找到语义重要的token了?怎么提出语义不重要的token了?
4、要区分token的语义是否重要,就有个类似“先有蛋还是现有鸡”的问题:
- 如果不遍历整个seq,怎么知道那些token重要、哪些不重要了?
- 如果遍历整个seq,那和标准的全量attention又有啥区别了?time & space complex还怎么降低了?
现在陷入了两难的境地啊! 怎么破局?
记得以前做推荐算法,也面临类似的问题:user登录后需要从亿级别的item中快速找到最合适的几十个item给用户展示,耗时不能超过1~2秒!怎么从亿级别的item中在如此短的时间内找到合适的几十个item了? 于是乎诞生了推荐算法非常经典的方案流程:召回-> 粗排 -> 精排 -> 重排!
- 每次计算,都是做漏斗筛选!
- 召回的计算方案最简单,适合亿级别的大量计算,比如双塔模型;重排的计算最复杂,只适合万级别数量的item计算、排序!
通过上述方式,先用简单的计算,从大量数据中初步筛选过滤,去掉杂质。再用复杂的计算精益求精,得到最终的排序!这里能不能复用这种思路了?
5、 deepseek的3.2 exp的架构如下:
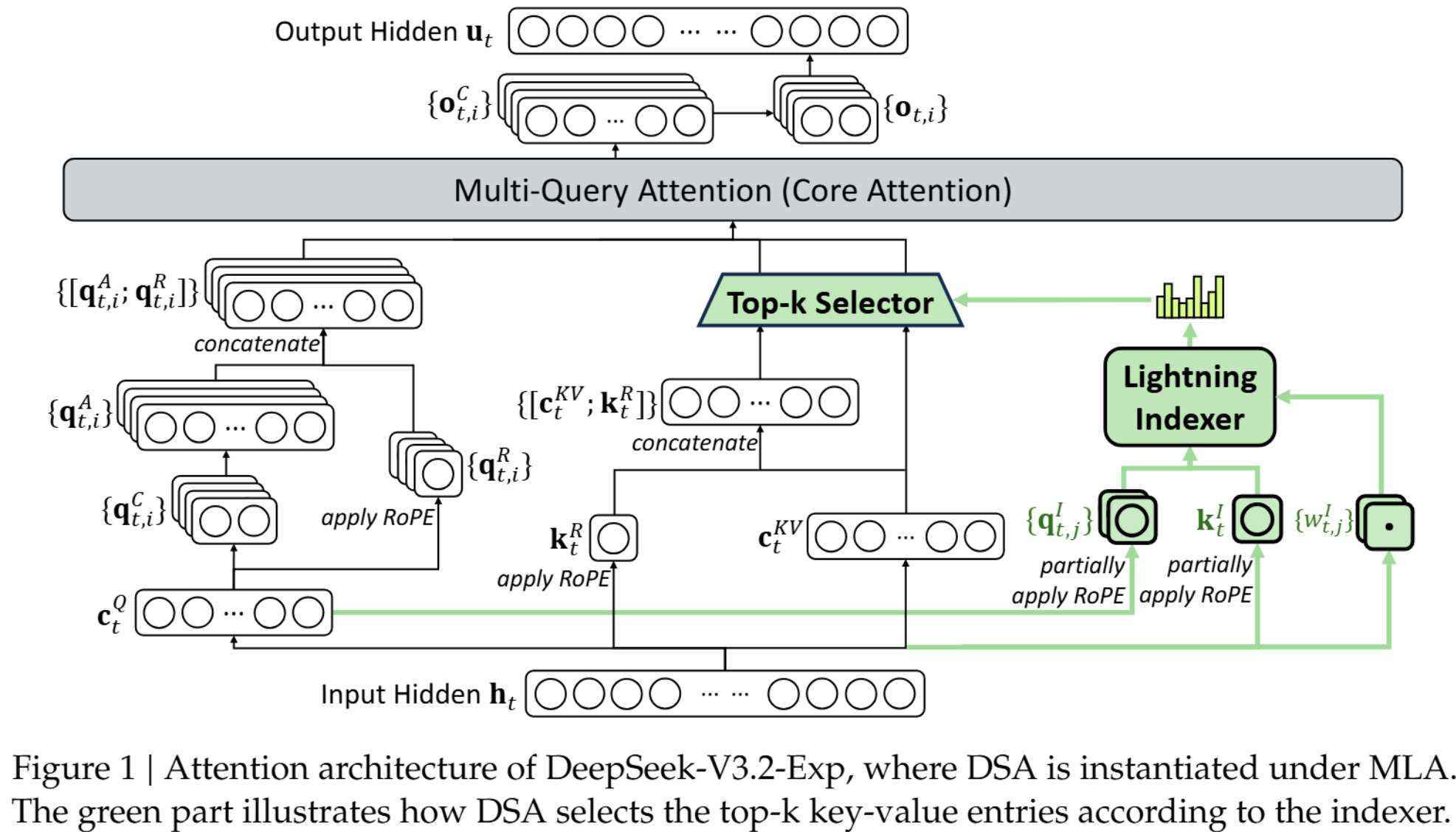
看着很复杂, 其实原理和思路同上面的推荐系统排序一样简单:先用简单的计算从所有token中筛选出重要的token,再用标准的attention计算token之间的weight!筛选重要token就是最核心的创新点了,deepseek官方的描述如下:

概括一下,I_{t,s}就是筛选token的指标,其计算方式如下:
- 轻量投影:将主模型的 token 表示
x_t和x_s通过matrix multi 矩阵乘法投影到低维的索引空间,得到q_{t,j}^I和k_s^I。 - 点积相似度:在每个索引头
j内计算q_{t,j}^I和k_s^I的点积。这里的indexer header类似attention的multi-head,本质是在不同的语义空间提取特征信息! - ReLU 稀疏化:用 ReLU 过滤掉所有非正相关的得分。
- 动态加权融合:用可学习的权重
w_{t,j}^I融合所有索引头的信息,得到最终的标量得分I_{t,s}。
I_{t,s} 分数越高,就表示历史 token s 对当前查询 token t 越重要,在后续的完整注意力计算中就越有可能被选中。
参考:
1、https://github.com/deepseek-ai/DeepSeek-V3.2-Exp/blob/main/DeepSeek_V3_2.pdf