对象无关的零样本异常检测
创新点有三个:(1)对象不可知文本提示关注图像的异常/正常,而不是对象语义;(2)文本编码器调优来优化原始文本空间;(3)DPAM(V-V)通过增强局部视觉语义来提高分割性能。
论文主要用的是辅助AD数据集(提前标注好“正常/异常图像 + 像素级掩码”的数据集,如MVTec AD(含金属螺母、胶囊等15类缺陷)),医疗辅助数据集(如ColonDB)。
VLM有强大的零样本识别能力(包括异常检测在内的各种视觉任务)
需要对象无关的零样本识别能力(当目标域不具有相关训练数据时(违反数据隐私策略、保护患者敏感信息等))
类似CLIP之类的VLM被训练成更关注class语义而不是正常/异常。原因是:文本提示模板是“A photo of a [cls]”
回顾一下CLIP:
CLIP的文本编码器:传递类名为cls的文本提示模板G(A photo of a [cls]),以得到对应的文本嵌入。
CLIP的图像编码器:传递图像,得到全局视觉嵌入和局部视觉嵌入。
异常模式保持相似,例如金属螺母和板上的划痕、晶体管和印刷电路板的错位、各种器官表面的肿瘤/病变等。所以我们改变文本提示模板为:
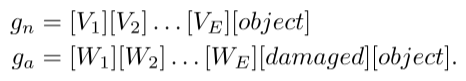
这里的[V]、[W]都是可学习的(在训练过程中值会不断调整)。这里的[V1][V2]可能在训练之后分别代表着[表面平滑]、[形状规则],[W1][W2]可能在训练之后分别代表着[局部划痕]、[边缘突变],这样gn、ga两个模板在训练之后就分别充分吸取了正常、异常的特征。
一、优化gn、ga模板的过程(全局-局部上下文优化):
总损失 = 全局损失 + λ × 局部损失的加权和
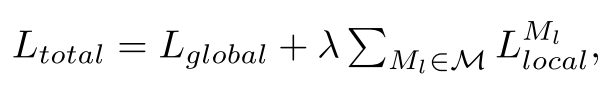
(1)全局损失:判断这张图是异常图还是正常图

这里的fi是全局视觉嵌入,匹配的也是gn、ga对应的文本嵌入。
Lglobal:分别计算fi和gn、ga的余弦相似度,用交叉熵损失来优化。
(2)局部损失:定位“异常在图像的哪个像素”
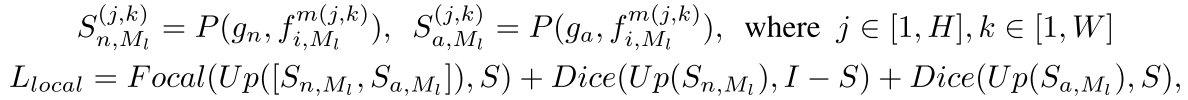



掩码S一般公开数据集自带。
二、文本编辑器的调整
为什么要调整文本编码器?
因为CLIP的文本编码器原本是为“图像-物体类别语义对齐”预训练的,而我们希望文本空间能捕捉“异常/正常”的通用语义,所以需要对文本编码器进行调整。
对文本编码器的优化集中在“前9层”


为什么只替换“前缀”?
原始token的后P-Q个包含CLIP预训练的通用语义(如“[object]、[damaged]”的基础语义),保留它们可避免文本空间完全偏离视觉-语言对齐的基础。

三、图像编码器的调整
DPAM机制:将原始的Q-K注意力替换为V-V自注意力。
CLIP的Q-K注意力机制会导致视觉编码器过度关注全局物体语义,而忽略局部异常特征。(DeCLIP提出的注意力偏移问题)
四、推理过程
1、图像级异常检测:用P(ga,fi)判断是否异常。

2、像素级异常分割:定位“异常在哪里”




最后给个推理实例:

五、下面是实验部分:
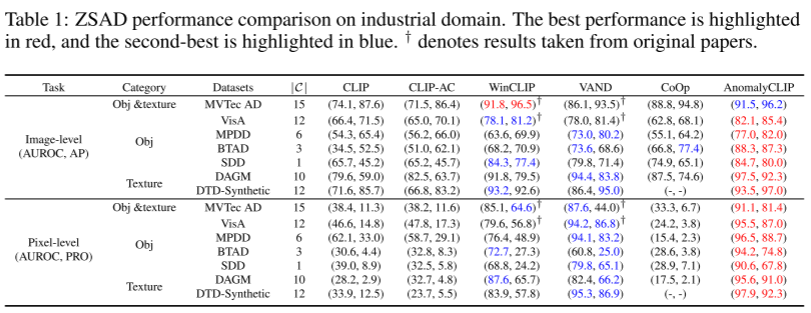
工业检测数据集(7个):MVTec AD、VisA、MPDD、BTAD、SDD、DAGM、DTD-Synthetic
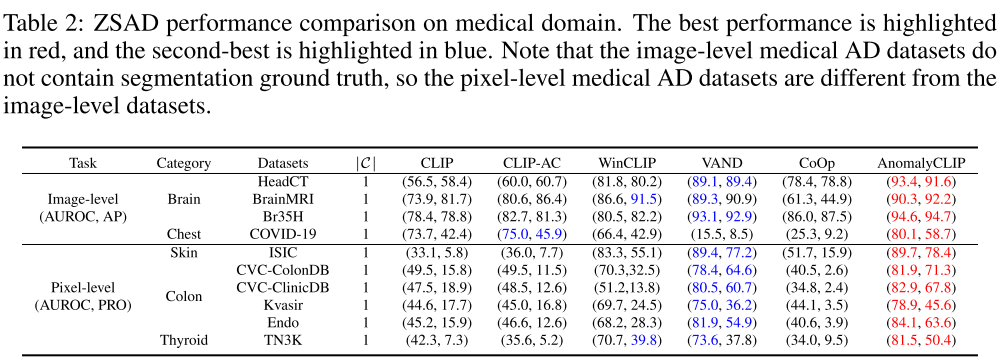
医学成像数据集(10个):皮肤癌ISIC、结肠息肉CVC-ClinicDB、CVC-ColonyDB、Kvasir、Endo、甲状腺结节TN3K、脑肿瘤HeadCT、脑MRI、Br35H、新冠肺炎COVID-19
对比的SOTA:CLIP、CLIP-AC、WinCLIP、VAND、CoOp
工业异常检测评价指标(3个):AP、AUROC、AUPRO
工业检测的比较结果(table 1):
医疗影像的比较结果(table 2):