1. 逻辑存储结构
InnoDB 的逻辑存储结构是其管理数据、支撑核心能力的底层骨架,它以 “表空间→段→区→页→行” 的五层架构,将数据从宏观存储容器到微观记录层层划分。这套结构不仅决定了数据在磁盘的存储与访问规则,更是理解 B+ 树索引、事务、MVCC 等 InnoDB 核心特性的关键前提 —— 本章将从宏观到微观拆解这套结构,帮你建立对 InnoDB 底层工作逻辑的整体认知。
表空间(Tablespace):顶层存储容器
- 定义:InnoDB 逻辑存储的最高层次,是所有数据(系统数据、用户数据、索引等)的总仓库
- 类型:
- 系统表空间:默认
ibdata1文件,存储数据字典、undo 日志等核心系统数据 - 独立表空间:也就是每一张用户表,每个用户表都对应着一个
.ibd文件(由innodb_file_per_table控制),独立存储表的数据和索引,便于单表管理。
- 系统表空间:默认
- 作用:通俗来讲,表空间就是用来隔离不同数据(系统数据 / 用户表),是我们整个逻辑存储结构中的最上层建筑。
段(Segment):功能化的数据组,与B+树直接关联
- 定义:表空间下按功能划分的存储单元,是B+树索引的存储容器
- 类型:
- 数据段:对应表的聚簇索引B+树(InnoDB 中聚簇索引包含了数据行的全部信息,与数据物理存储绑定,数据段即为聚簇索引的存储载体)
- 索引段:每个非聚簇索引对应一个独立的索引段,存储非聚簇索引B+树的所有节点。
- 回滚段:存储
undo日志,用于事务回滚和MVCC,与B+树无关。(在系统表空间中)
- 作用:按功能隔离索引数据(聚簇索引 / 非聚簇索引),确保不同所用不相互干扰,通俗说,一个段就是一棵B+树
区(Extent):段的最小分配单位,平衡效率与碎片化
- 定义:连接段与页的中间层,是段申请空间的最小单位,固定为1MB(默认页大小为16KB,包含64个连续页)
- 作用:
- 避免碎片化:如果直接由段申请页(B+树节点),那么会出现大量页在磁盘空间不连续的情况,所以在申请时,我们设计了一个聚合单元---区,来批量的申请连续的页,这些页在磁盘上物理连续,提升B+树查询的“连续IO效率(减少磁头移动)。
- 降低管理成本:批量分配区代替零散分配页,减少空间管理的映射关系,减少系统开销。
- 适配段增长:一次分配1MB空间,满足段(B+树)一段时间的增长,减少频繁空间申请的性能损耗。
页(Page):最小 IO 单位,对应 B+ 树的节点
- 定义:InnoDB 与磁盘交互的最小单位(默认16KB),是B+树节点的物理载体。
- 与B+树关系::
- 每个B+树节点(叶子+非叶子)都完整存储在一个页中,确保一次 I/O 可以加载 / 写入一个节点。
- 非叶子节点(索引页):存储 “索引键 + 子节点指针”,用于索引导航。
- 叶子节点(数据页 / 索引页):聚簇索引的叶子节点存储完整行记录;非聚簇索引叶子节点存储“索引键+主键”(用于回表)
- 类型:数据页、索引页、undo 页、redo 页等
行(Row):最小数据单元,存储用户记录
- 定义:对应表中的一条记录,是存储用户数据的最小逻辑单位。
- 存储特性:
- 行数据按“行格式”(默认的
Dynamic)存储,含隐藏列:**DB_ROW_ID、DB_TRX_ID、DB_ROLL_PTR),支持MVCC和事务管理。 - 若行数据过大(超过页空间-约15KB),会触发“行溢出”:大字段核心部分(20字节前缀,含溢出页指针)存于原始数据页,剩余部分存于“溢出页”
- 行数据按“行格式”(默认的
- 与B+树关系:行是聚簇索引B+树叶子节点的组成单元,按逐渐有序存储在叶子节点(数据页)中。
关于隐藏列的补充:
InnoDB 行的三个隐藏列(
DB_ROW_ID、DB_TRX_ID、DB_ROLL_PTR)是支撑其事务、MVCC(多版本并发控制)和行标识的 “底层基石”,它们不对外显示(用SELECT *查不到),但会自动为每行数据添加(部分列按需生成)。
1.DB_ROW_ID:行的 “默认唯一标识”(可选)
- 作用:当表没有显式定义主键,且没有非空唯一索引时,InnoDB 会自动生成该列作为行的 “隐形主键”,确保每行有唯一标识。
- 特性:
- 类型为 6 字节无符号整数,按插入顺序自增;
- 若表有主键或非空唯一索引,InnoDB 会用这些索引列作为行的唯一标识,不会生成
DB_ROW_ID(避免冗余)。- 核心用途:填补 “无主键表” 的唯一标识空缺,保证行的物理唯一性,支持 InnoDB 内部的行管理(如页内排序)。
2.
DB_TRX_ID:行的 “事务版本标识”
- 作用:记录最后一次修改该行的事务 ID(包括插入、更新、删除操作),是 MVCC 判断 “行版本可见性” 的核心依据。
- 特性:
- 类型为 6 字节整数,每个事务启动时会分配一个全局唯一的事务 ID;
- 每次事务修改该行(如
UPDATE/DELETE),都会将当前事务 ID 写入DB_TRX_ID,覆盖旧值。- 核心用途:MVCC 中,通过对比 “当前事务 ID” 与行的
DB_TRX_ID,判断该行数据对当前事务是否 “可见”(比如:若行的DB_TRX_ID大于当前事务 ID,说明是未来事务修改的,不可见)。3.
DB_ROLL_PTR:行的 “历史版本指针”
- 作用:指向该行 “历史版本数据” 在 undo 日志中的位置,是事务回滚和 MVCC 读取 “旧版本数据” 的关键。
- 特性:
- 类型为 7 字节指针,本质是 undo 日志页的地址 + 页内偏移;
- 每次修改行时,InnoDB 会先将该行的 “修改前数据” 存入 undo 日志,再用
DB_ROLL_PTR指向这个 undo 日志条目;- 多次修改后,
DB_ROLL_PTR会形成 “版本链”(最新行指向最近一次的旧版本,旧版本再指向更早的版本)。- 核心用途:
- 事务回滚时:通过
DB_ROLL_PTR找到 undo 日志中的旧数据,将行恢复到修改前状态;- MVCC 读时:若当前行版本不可见,通过
DB_ROLL_PTR追溯历史版本,直到找到可见的旧版本。三者协同作用:支撑 InnoDB 事务与并发
三个隐藏列并非孤立,而是共同服务于 InnoDB 的核心能力:
- 无主键时,
DB_ROW_ID保证行唯一;- 事务修改行时,
DB_TRX_ID标记版本,DB_ROLL_PTR记录历史;- MVCC 读时,通过
DB_TRX_ID判可见性,通过DB_ROLL_PTR找旧版本;- 事务回滚时,通过
DB_ROLL_PTR恢复数据。
简单说:它们是 InnoDB 实现 “事务安全” 和 “高并发读写” 的 “隐形基础设施”。
2. 架构
MySQL5.5 开始就选择 InnoDB 作为默认存储引擎,他擅长处理事务,具有崩溃恢复的特性,在日常开发中使用广泛。下面为InnoDB架构图,左侧为内存结构,右侧为磁盘结构。
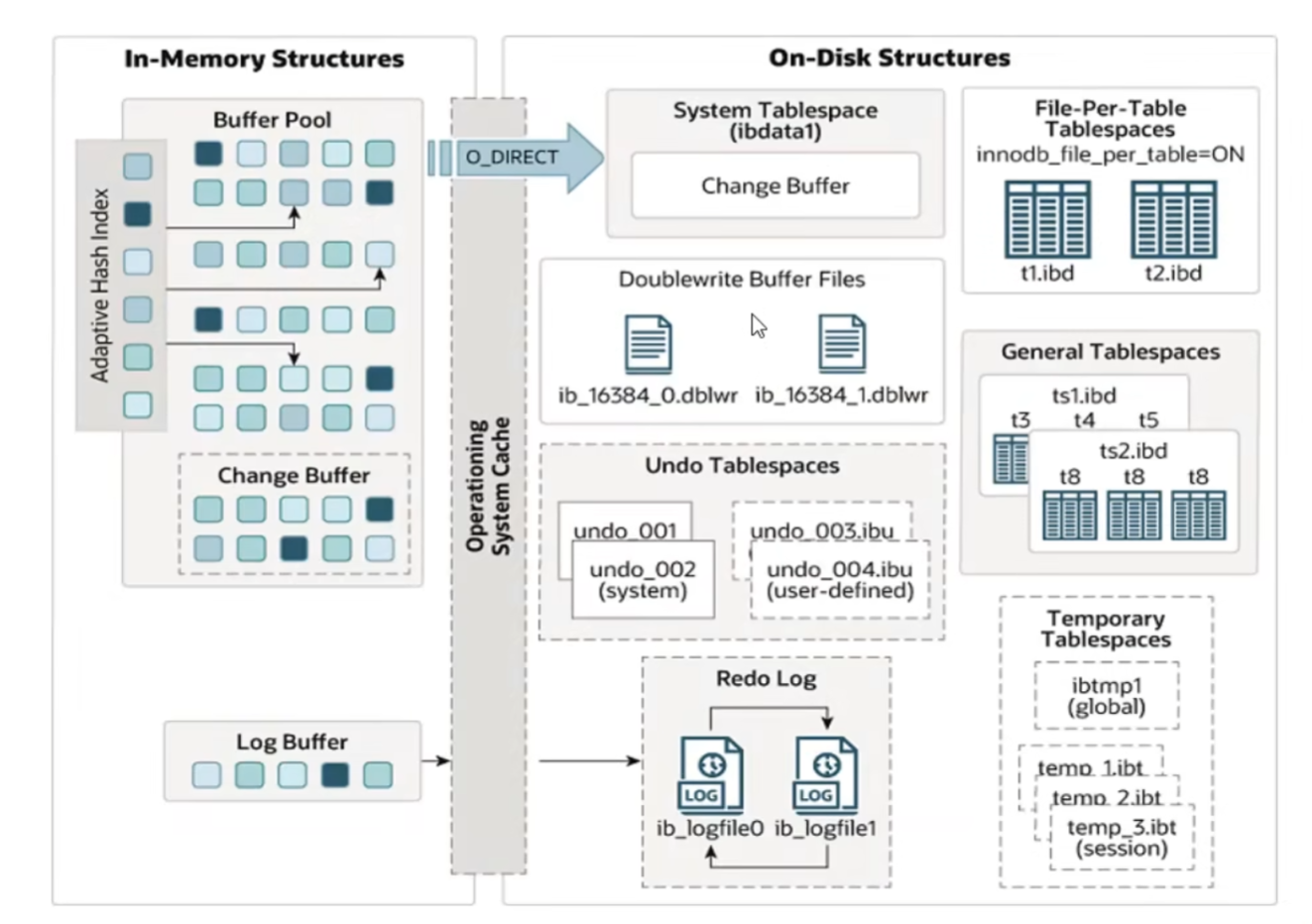
内存结构
上图中可以看到MySQL内存结构主要有四个部分:Buffer Pool(缓冲池)、Change Buffer(变更缓冲)、Adaptive Hash Index(自适应哈希索引)、Log Buffer(日志缓冲区)。其中Buffer Pool是内存结构的核心,通常占物理内存的 50%-70%,所有组件共同作用以减少磁盘 IO,加速数据访问。
-
Buffer Pool:核心数据缓存区
作用为:缓存磁盘上的热点数据页(数据页、索引页、undo页等),让后续操作在内存中完成,避免频繁访问磁盘
(1)缓存的内容
缓冲池的缓存单位为“页”(与磁盘页大小一致,默认16KB),主要包括:
- 数据页:聚簇索引叶子节点的页(存储完整业务行数据)
- 索引页:非叶子节点的索引页(键+指针)、非聚簇索引的叶子节点页(索引键+主键)
- undo页:缓存undo日志页,加速事务回滚和MVCC版本读取
(2)内部管理
- LRU 链表(最少使用链表):只发生过读的页
- Free 链表(空闲页链表):未使用过的页
- Flush 链表(脏页链表):发生过修改的页,后台线程定时将脏页批量刷盘,减少磁盘 IO
-
Change Buffer:优化非聚集索引的写操作
非聚簇索引的修改较为随机,不像主键索引:直接顺序写入磁盘,所以为了提高性能,当发生DML时(数据不在 Buffer Pool),会先将修改的操作记录在 Change Buffer 中,将修改缓存下来,等到被修改的数据进入到 Buffer Pool 时,再做合并,合并出修改后的数据再一起写回磁盘。
-
Adaptive Hash Index:自适应 hash 索引
用于优化对 Buffer Pool 数据的查询。InnoDB 存储引擎会监控对表中各索引页的查询,如果观察到 hash 索引可以提速,则建立哈希索引。
这玩意一般不需要人工干预,是系统根据情况自动完成的。参数:
adaptive_hash_index -
Log Buffer:日志缓冲区
用来保存要写入磁盘中的log日志数据(redo log、undo log),默认大小为 16MB,日志缓冲区的日志会定期刷新到磁盘中。如果需要更新、插入或删除多行的事务,可以增加日志缓冲区的大小来节省磁盘 IO
参数:
innodb_log_buffer_size:缓冲区大小innodb_flush_log_at_trx_commit:日志刷新到磁盘时机Log Buffer 的刷盘时机由参数 innodb_flush_log_at_trx_commit 控制,常见配置: 0:事务提交时不刷盘,仅依赖后台线程每 1 秒刷盘(性能最高,但崩溃可能丢失 1 秒内的日志); 1(默认):事务提交时强制刷盘(最安全,崩溃无数据丢失,但性能略低); 2:事务提交时仅刷到操作系统缓存,操作系统定期刷盘(平衡安全与性能,崩溃可能丢失操作系统缓存中的日志)。
磁盘架构
InnoDB 的磁盘结构是数据持久化存储的载体,与内存结构(如缓冲池、日志缓冲区)对应,主要由 表空间文件、redo 日志文件、undo 日志文件 三大核心模块构成,此外还有表结构定义文件等辅助文件。这些文件共同实现数据的持久化、事务恢复和逻辑存储管理,是 InnoDB 数据不丢失的基础。
-
表空间文件:核心数据存储在题
表空间文件是 InnoDB 磁盘结构的核心,直接对应逻辑存储结构中的表空间,用于存储所有业务数据、索引、回滚段等核心信息。
(1)系统表空间
- 文件表示:默认生成
ibdata1文件,可配置多个文件或自动扩展 - 存储内容:
- InnoDB 数据字典(记录数据库、表、索引的元数据,如“表user的字段类型、索引结构”)
- 回滚段:MySQL5.x 及 8.0 未配置独立 undo 表空间时,回滚段和 undo 日志存于此
- 临时表空间的溢出数据
(2)独立表空间
- 文件标识:每个用户表对应一个独立文件,命名未
表名.ibd,由参数innodb_file_per_table=ON控制 - 存储内容:
- 对应表中“数据段”
- 对应表中索引段
- 表的 undo 日志
(3)undo 表空间
- 文件标识:MySQL8.0 默认生成
undo_001、undo_002两个文件(可配置数量) - 存储内容:
- 所有事物的undo日志(用于回滚和MVCC版本读取)
- 回滚段(MySQL8.0 后,回滚段从系统表空间迁移至undo表空间)
(4)临时表空间
- 文件标识:会话临时表:
#innodb_tmp目录下的临时文件和全局临时表空间ibtmp1文件 - 存储内容:
- 会话临时表:
CREATE TEMPORARY TABLE创建的表的数据和索引 - 排序、分组等操作产生的临时结果集
- 会话临时表:
- 文件表示:默认生成
-
重做日志文件(redo log):事务 “不丢数据” 的保障
redo log 是 InnoDB 实现 “崩溃恢复” 和 “事务持久性” 的核心,没它数据可能丢:
- 文件:默认 2 个
ib_logfile0/ib_logfile1(循环写入,避免单点故障)。 - 作用:记录 “数据物理修改的日志”(比如 “修改 user 表 id=100 的 age 为 25”),数据库崩溃后重启,通过它恢复 “已提交但没写到表空间的数据”。
- 关键:顺序写磁盘(比表空间的随机写快 10 倍以上),按固定大小循环覆盖(需先确保日志对应的数据已刷到表空间)。
- 文件:默认 2 个
-
辅助文件:配合核心文件工作
这类文件不存核心业务数据,但运维和故障排查离不开:
- (1)表结构文件:xxx.frm(MySQL 5.x)/ 内置到.ibd(8.0)
- 5.x 版本:每个表 1 个
表名.frm,存表结构(字段名、类型、约束);8.0 后合并到*.ibd里,不再单独生成。
- 5.x 版本:每个表 1 个
- (2)错误日志:error.log
- 存 InnoDB 启动 / 崩溃 / 恢复的错误信息(比如 “redo log 损坏导致启动失败”),排障必看。
- (1)表结构文件:xxx.frm(MySQL 5.x)/ 内置到.ibd(8.0)
3. 事务原理
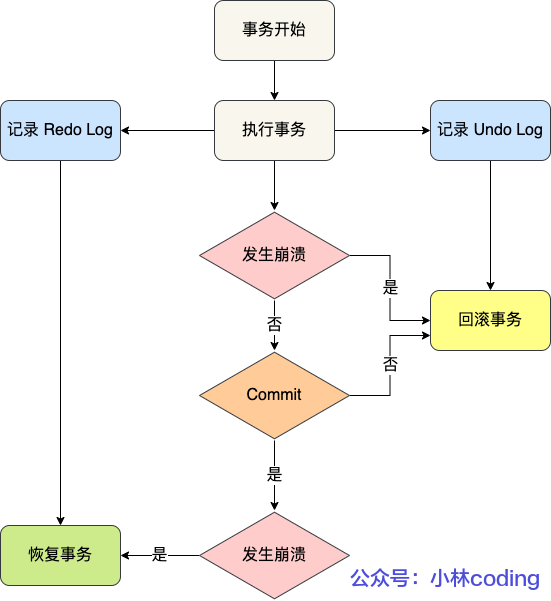
Redo Log
Redo Log 记录的是事务提交时数据页的物理修改,是用来实现事务的持久性
该日志文件由两部分组成:重做日志缓冲(redo log buffer)以及重做日志文件(redo log file),前者在内存中,后者在磁盘中。
当事务提交之后会把所有修改信息都存到该日志文件中,用于在刷新脏页到磁盘发生错误时,进行数据恢复使用。
注意:
- redo log 采用了
Write-ahead logging(WAL),这个操作在事务提交前先将数据写入 redo log buffer,然后将 redo log 刷盘写入磁盘,这时再告诉 Server 层保存好了,可以提交事务了,然后再进行脏页写回磁盘,如果发生了崩溃,可以利用redo log 恢复- 事务提交前发生崩溃的话,没啥事,就是事务执行失败了,数据也不会发生更改,redo log 丢了也没事。
- redo log 在磁盘中是顺序的、循环的文件,redo log 的写入速度 > 脏页写回磁盘的速度,使用才使用 redo log
Undo Log
回滚日志,用于记录数据被修改前的信息,作用有俩:提供回滚和 MVCC
它保证了事务的 ACID 特性中的原子性(Atomicity)。
在事务没提交之前,MySQL 会先记录更新前的数据到 undo log 日志文件里面,当事务回滚时,可以利用 undo log 来进行回滚。如下图: