深度研究是各大AI平台都比较比较常见的智能体,无论是国外的OpenAI、Google或是国内的Kimi、阿里等都提供了此功能。只需要通过输入想要研究探索的主题该智能体就会自动通过网络检索、调用工具等抓取与用户关心的该主题的相关内容,然后输出该主题的报告/文章。
对于DeepResearch这种比较常见的智能体是否还有造轮子的意义呢,答案是肯定的。通过造轮子这种常见、流程简单的智能体比较容易跨进学习相关框架、Agent开发的的门槛。这类智能体最关键的还是Search的数据源质量怎样,如果Search得到的数据质量不高,再怎样也得不到比较高质量的文章/报告。
本文除了介绍极简深度研究智能体的实现外在文章的最后还会开源相关代码。
智能体结构
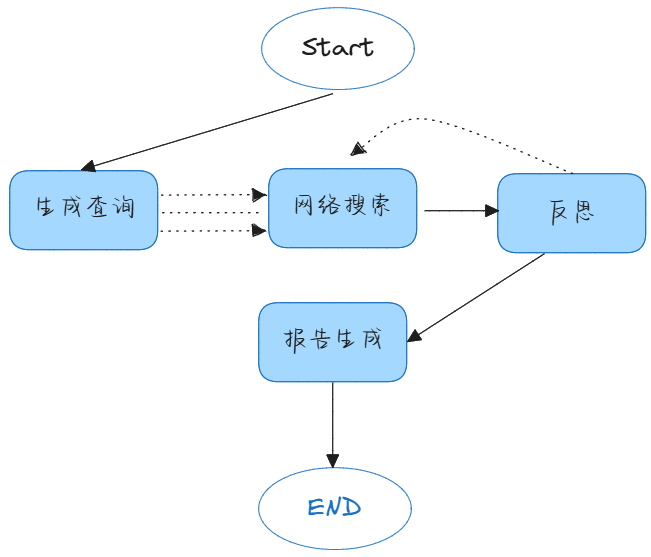
本文所述极简深度检索智能体包含五个Agent,生成查询Agent、网络搜索Agent、反思Agent、报告生成Agent。
* 生成查询Agent:根据用户输入的内容提交给大模型,对该原始问题进行查询生成,生成一个或多个多样化的查询。使得在下一步的Agent从能够搜索到更多有用的信息。此Agent生成的是一个或多个查询列表:
{"query_list":{"query":["子查询"],"rationale":"简要解释这些查询与研究主题的相关性"}}
此Agent的工作:
1、发起模型调用生成子查询
2、根据子查询列表发起N次[网络检索Agent]请求(并发)
* 网络检索Agent:根据[生成查询Agent]所生成的查询列表调用网络工具进行检索,此处的网络检索工具可以是Tavily、博查或搜索引擎或自己开发的工具等。将网络检索到的网络资料提交到大模型,生成关于在 生成查询Agent 阶段所提供问题的研究摘要。
此Agent的工作:
1、根据[生成查询Agent]生成的查询列表发起一次或多次网络检索。
2、针对该[查询列表]生成一份或多份研究摘要。
* 反思Agent:Agent收到[网络检索Agent]所生成的研究摘要是由N个[网络检索Agent]生成的,并分析其所生成的摘要与用户的[原始问题]是否存在知识缺口或还需要深入探索的领域来决定是否已经满足用户[原始问题]的回答,或还需要返回【网络检索Agent】进行进一步的网络检索。
此Agent生成:{
"is_sufficient": 是否充分,
"knowledge_gap": 描述缺失或需澄清的信息,
"follow_up_queries": 针对缺口提出的具体问题,
"research_loop_count": 当前循环次数,
"number_of_ran_queries": 子查询个数,
}
此Agent的工作:
1、判断[网络检索Agent]生成的摘要是否存在知识缺口。
2、是则返回[网络检索Agent],否则进入[报告生成Agent]。
* 报告生成Agent:根据用户[原始问题]以及[网络检索Agent]阶段所生成的摘要,生成最终的研究报告/文章。
智能体实现
下面是代码为极简深度研究的Agent构建关键代码,创建generate_query、web_research、reflection、finalize_answer节点,以及两条边continue_to_web_research、evaluate_research,用于控制数据的流转。下面是LangGraph的实现代码。
def _build_graph(self):# 创建 Agent Graphbuilder = StateGraph(OverallState, config_schema=Configuration)# 定义将在循环中使用的节点builder.add_node("generate_query", generate_query)builder.add_node("web_research", web_research,retry=RetryPolicy(max_attempts=3))builder.add_node("reflection", reflection)builder.add_node("finalize_answer", finalize_answer)# 将 generate_query 设置为入口点 即该节点为首个被调用的节点builder.add_edge(START, "generate_query")# 添加条件边,在并行分支中继续执行搜索查询builder.add_conditional_edges("generate_query", self._continue_to_web_research, ["web_research"])# 连接网络搜索节点到反思节点builder.add_edge("web_research", "reflection")# 评估研究结果builder.add_conditional_edges("reflection", self._evaluate_research, ["web_research", "finalize_answer"])# 最终确定答案builder.add_edge("finalize_answer", END)return builder.compile(name="research-agent")
continue_to_web_research:[生成查询]与[网络搜索]之间的边,根据查询[生成查询]生成子查询并发起N个[网络检索Agent]请求。
evaluate_research:[反思Agent]与[网络检索Agent]和[报告生成Agent]之间的边,根据研究循环次数以及子问题的摘要是否充分决定跳转到哪个节点。
网络检索:这里现在使用的是 Tavily,在Tavily返回数据后再次发起请求获取详细的页面信息,目前看数据质量也不是很好,但也比使用无头浏览器包装一层的的搜索引擎数据质量好不少。
前端
目前页面只弄了发起Agent的SSE请求,在Agent运行时各Agent节点状态变动时的页面展示以及最后结果输出的展示。
扩展
目前智能根据网络搜索的结果进行研究报告生成,生成内容的质量取决于搜索结果的质量,可扩展方向包括加入上传文件的检索、网络搜索内容过滤等。
这里也只是算是一个全栈的智能体示例,虽然这里用的是LangGraph,但个人并不喜欢LangGraph,框架封装过于复杂。目前各类Agent框架很多用哪个全凭个人喜好,或这不用框架自己实现Agent的封装。
GitHub代码此代码仓库包含了前后端代码。https://github.com/linxin26/Open-DeepResearch
文章首发地址:https://mp.weixin.qq.com/s/Dmx3XBVal7hgiJ7_BP7-5g