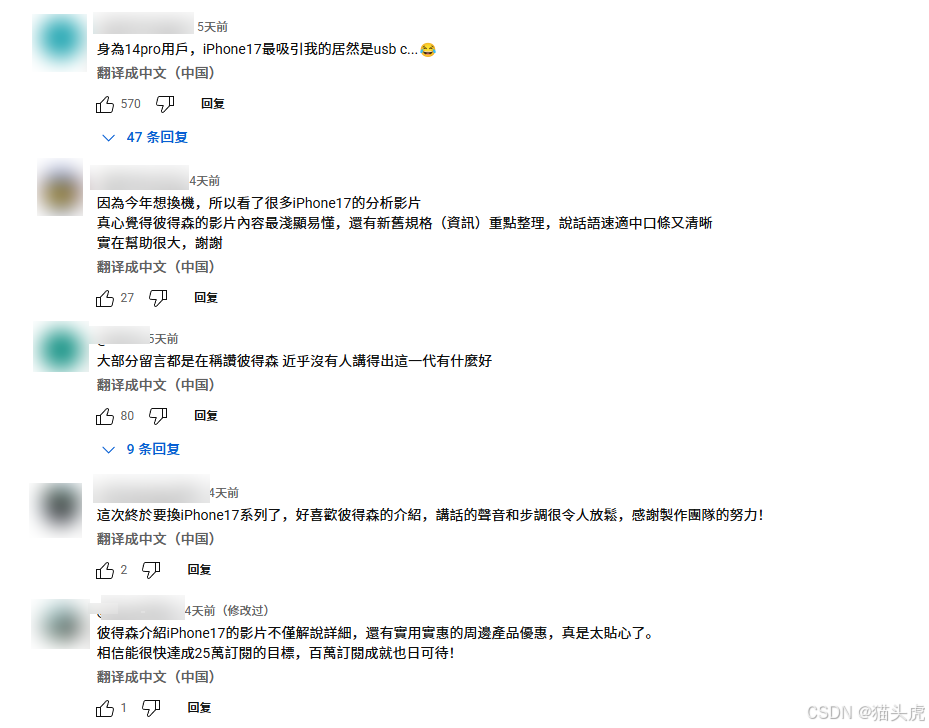
如何利用海外 NetNut 网络代理与 AICoding 实战获取 iPhone 17 新品用户评论数据?
一、引言
在数据驱动时代,开发者与研究者越来越依赖跨境数据采集来洞察用户需求、分析市场趋势。以 iPhone 17 为例,如何高效汇总 YouTube 评论、海外论坛反馈、社交媒体讨论,是许多人关心的问题。但在实践中常常会遇到 IP 封锁、访问限制、反爬虫机制 等挑战。
本文基于“海外代理(示例采用 NetNut)+ 官方 API + 大模型分析”的思路,演示如何稳定、合规地抓取 iPhone 17 新品相关评论,并用大模型做情感分析与观点提炼。文中保留你的全部图片与原始代码,并额外提供健壮化脚本与合规清单,方便直接落地。
@
- 如何利用海外 NetNut 网络代理与 AICoding 实战获取 iPhone 17 新品用户评论数据?
- 一、引言
- 二、没有高质量海外代理 IP 会怎样?
- 三、海外代理 IP 的类型与优势
- 四、实战:抓取 YouTube 视频评论信息
- 1. 需求分析
- 2. 技术方案设计
- 3. 代码实战
- 3.1 示例代码
- 3.2 推荐增强版(可选):更健壮的 YouTube 评论抓取脚本
- 4. 运用大模型对 YouTube 评论做情感分析
- 4.1 示例代码
- 4.2(可选)增强版:批量情感标注与主题提炼
- 五、如何挑选高质量海外代理 IP
- 六、常见报错与排查速查表
- 七、总结
二、没有高质量海外代理 IP 会怎样?
当你用本地 IP 或低质量免费代理采集海外网站时,常见问题包括:
- IP 封锁频发:主流站点(如 Apple、Amazon、X/Twitter 等)对异常流量和非本地 IP 有严格风控,高频或并发访问易触发封禁。
- 请求被拒或限速:同一 IP 可能被限流,导致效率低下。
- 验证码/滑块验证:易触发人机验证,打断自动化流程。
- 数据不完整:频繁被封或失败导致抓取残缺,甚至无法有效获取。
常见错误:403 Forbidden、429 Too Many Requests、401 Unauthorized、503 Service Unavailable、Connection/Read Timeout、Cloudflare 5XX(如 520/521/525)等。
三、海外代理 IP 的类型与优势
一般分为三类,每类适用场景不同:
动态住宅 IP:来自全球真实家庭宽带(ISP)设备,可信度最高。
- 难以被识别为爬虫,匿名性与稳定性更好
- 支持动态切换 IP,适合大规模/分布式采集
- 适用于反爬严格、风控敏感的网站

移动 IP:来自移动网络运营商,分配给手机等设备,信任度极高。
- 更高的信任度,极难被封
- 适合采集移动端友好内容或 APP 接口

机房/数据中心代理:来自云厂商或机房(非“真实用户”IP),但性能优异
- 成本低、带宽大、速度快
- 适合对匿名性要求不高、采集量大的场景

适用场景速览
| 类型 | 匿名性 | 稳定性 | 成本 | 适用场景 |
|---|---|---|---|---|
| 住宅IP | 高 | 高 | 较高 | 反爬虫强的网站 |
| 移动IP | 极高 | 高 | 最高 | 移动端/APP采集 |
| 机房代理 | 低 | 中 | 低 | 公开数据/低敏感网站 |
说明:代理服务商众多,可按预算、地区覆盖、并发/带宽、合规要求自选。本文对品牌不做商业背书,示例仅为技术演示。
四、实战:抓取 YouTube 视频评论信息
1. 需求分析
目标视频:如「iPhone 17 Pro / 17 Pro Max 深度分析」等评测视频
核心要素:
- 获取所有评论(主评论与回复)
- 评论内容、作者、发布时间等结构化信息
- 保存为本地文件,便于后续分析
数据结构目标:原始 JSON + 结构化摘要
时效与稳定性:
- 时效性:评论更新快,建议定时采集
- 稳定性:YouTube 存在风控与配额,建议优先使用官方 API;必要时在合规前提下使用高质量代理提升连接稳定性
2. 技术方案设计
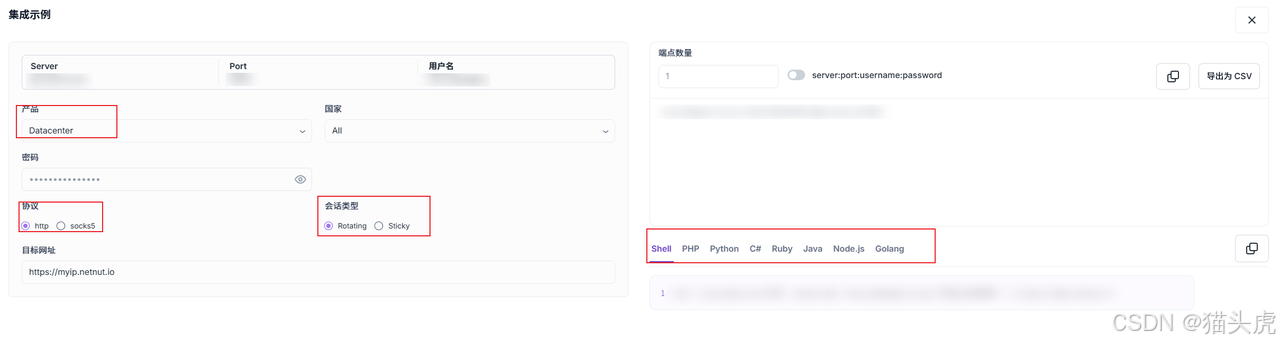
代理服务商(示例):NetNut

代理配置:账号、密码、服务器、端口等,支持动态切换 IP

快速集成:按会话类型、协议、语言选择
请求头伪装(多数场景仅 UA 即可)
header = {"user-agent": 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.109 Safari/537.36 OPR/84.0.4316.31','Content-Type': 'application/json;charset=UTF-8',
}
合规提醒
- 优先使用 YouTube Data API v3 等官方接口,遵守平台 ToS 与配额政策
- 不采集受限/敏感个人信息;公开展示时注意匿名化
- 控制请求速率与并发,避免影响对方服务
- 使用代理前确保法律允许且与目标平台政策不冲突
3. 代码实战
3.1 示例代码
import json
import requests
your_api_key = '' # 填入你的API Key
video_id = '' # 目标视频ID
username = ''
password = ''
server = 'gw.netnut.net'
port = '5959'
proxy = {'http': f'http://{username}:{password}@{server}:{port}','https': f'http://{username}:{password}@{server}:{port}',
}
params = {'part': 'snippet,replies','maxResults': 100, # 最大100'textFormat': 'pythonText','videoId': video_id,'key': your_api_key
}
count = 0
with open('data.txt', 'w', encoding='utf-8') as f:s = requests.get(url, headers=header, params=params, proxies=proxy, timeout=15)data = s.json()if 'items' not in data:print("Error:", data)else:for i in data['items']:f.write(json.dumps(i, ensure_ascii=False) + '\n')count += 1print(f"采集完成,共保存 {count} 条评论到 data.txt")
import json
import requests# 你的API Key
your_api_key = '' # ← 填入你的API Key
video_id = '' # 目标视频ID# NetNut代理信息
username = ''
password = ''
server = 'gw.netnut.net'
port = '5959'
proxy = {'http': f'http://{username}:{password}@{server}:{port}','https': f'http://{username}:{password}@{server}:{port}',
}url = 'https://youtube.googleapis.com/youtube/v3/commentThreads'
header = {"user-agent": 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.109 Safari/537.36 OPR/84.0.4316.31','Content-Type': 'application/json;charset=UTF-8',
}
params = {'part': 'snippet,replies','maxResults': 100, # 最大100'textFormat': 'pythonText','videoId': video_id,'key': your_api_key
}count = 0
with open('data.txt', 'w', encoding='utf-8') as f:s = requests.get(url, headers=header, params=params, proxies=proxy, timeout=15)data = s.json()if 'items' not in data:print("Error:", data)else:for i in data['items']:f.write(json.dumps(i, ensure_ascii=False) + '\n')count += 1print(f"采集完成,共保存 {count} 条评论到 data.txt")
with open('data.txt', 'w', encoding='utf-8') as f:while True:s = requests.get(url, headers=header, params=params, proxies=proxy, timeout=15)data = s.json()if 'items' not in data:print("Error:", data)breakfor i in data['items']:f.write(json.dumps(i, ensure_ascii=False) + '\n')count += 1next_token = data.get('nextPageToken')if not next_token:breakparams['pageToken'] = next_token
运行截图
3.2 推荐增强版(可选):更健壮的 YouTube 评论抓取脚本
说明:在不改变你原始代码的前提下,这里额外提供一个健壮化版本,包含完整分页、指数退避重试、可选代理、JSONL/CSV 导出与日志。若你只需要保留原始代码,此段可按需删除;若需要直接跑通且提升稳定性,建议采用该增强版。
# -*- coding: utf-8 -*-
"""
YouTube 评论抓取(增强版)
- 官方 API: commentThreads
- 分页/重试/可选代理
- 导出 JSONL + CSV
"""
import os
import csv
import json
import time
import random
import logging
from typing import Dict, Optionalimport requestsAPI_URL = "https://www.googleapis.com/youtube/v3/commentThreads"# ======= 用户需设置 =======
YOUTUBE_API_KEY = os.getenv("YOUTUBE_API_KEY", "") # 或直接填入字符串
VIDEO_ID = os.getenv("YOUTUBE_VIDEO_ID", "") # 目标视频 ID
USE_PROXY = False # 没有代理也可运行
PROXY_HOST = os.getenv("PROXY_HOST", "gw.netnut.net")
PROXY_PORT = os.getenv("PROXY_PORT", "5959")
PROXY_USER = os.getenv("PROXY_USER", "")
PROXY_PASS = os.getenv("PROXY_PASS", "")
OUTPUT_JSONL = "youtube_comments.jsonl"
OUTPUT_CSV = "youtube_comments.csv"
MAX_RESULTS = 100 # 每页 1~100
TEXT_FORMAT = "plainText" # or "html"
TIMEOUT = 20# ======= 日志 =======
logging.basicConfig(level=logging.INFO, format="%(asctime)s %(levelname)s: %(message)s")def build_proxies() -> Optional[Dict[str, str]]:if not USE_PROXY:return Noneauth = f"{PROXY_USER}:{PROXY_PASS}@" if PROXY_USER else ""proxy = f"http://{auth}{PROXY_HOST}:{PROXY_PORT}"return {"http": proxy, "https": proxy}def backoff_sleep(retry: int):base = 1.5jitter = random.uniform(0, 0.5)time.sleep(min(60, base ** retry + jitter))def fetch_page(page_token: Optional[str], proxies: Optional[Dict[str, str]]):params = {"part": "snippet,replies","videoId": VIDEO_ID,"maxResults": MAX_RESULTS,"textFormat": TEXT_FORMAT,"key": YOUTUBE_API_KEY,}if page_token:params["pageToken"] = page_tokenheaders = {"User-Agent": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 ""(KHTML, like Gecko) Chrome/124.0 Safari/537.36"}for attempt in range(6):try:resp = requests.get(API_URL, headers=headers, params=params, proxies=proxies, timeout=TIMEOUT)if resp.status_code == 200:return resp.json()elif resp.status_code in (403, 429, 500, 502, 503, 504):logging.warning("HTTP %s: %s", resp.status_code, resp.text[:200])backoff_sleep(attempt)else:resp.raise_for_status()except requests.RequestException as e:logging.warning("Request error: %s", e)backoff_sleep(attempt)raise RuntimeError("Repeated failures fetching page.")def normalize_item(item: dict) -> dict:sn = item.get("snippet", {})top = sn.get("topLevelComment", {}).get("snippet", {})return {"comment_id": item.get("id"),"author": top.get("authorDisplayName"),"text": top.get("textDisplay") if TEXT_FORMAT == "html" else top.get("textOriginal"),"like_count": top.get("likeCount"),"published_at": top.get("publishedAt"),"updated_at": top.get("updatedAt"),"reply_count": sn.get("totalReplyCount"),}def main():assert YOUTUBE_API_KEY and VIDEO_ID, "请先设置 YOUTUBE_API_KEY 与 VIDEO_ID"proxies = build_proxies()# 输出文件准备jsonl_fp = open(OUTPUT_JSONL, "w", encoding="utf-8")csv_fp = open(OUTPUT_CSV, "w", encoding="utf-8", newline="")csv_writer = csv.DictWriter(csv_fp, fieldnames=["comment_id","author","text","like_count","published_at","updated_at","reply_count"])csv_writer.writeheader()count = 0page_token = Nonetry:while True:data = fetch_page(page_token, proxies)items = data.get("items", [])for it in items:row = normalize_item(it)jsonl_fp.write(json.dumps(row, ensure_ascii=False) + "\n")csv_writer.writerow(row)count += 1page_token = data.get("nextPageToken")logging.info("Fetched %d, nextPageToken=%s", count, page_token)if not page_token:breakfinally:jsonl_fp.close()csv_fp.close()logging.info("完成,共写入 %d 条评论到 %s / %s", count, OUTPUT_JSONL, OUTPUT_CSV)if __name__ == "__main__":main()
4. 运用大模型对 YouTube 评论做情感分析
4.1 示例代码
from openai import OpenAIclient = OpenAI(api_key=api_key, base_url="https://api.deepseek.com")
prompt = f"""\n{html_content}"""response = client.chat.completions.create(model="deepseek-chat",messages=[{"role": "system", "content": "You are a helpful assistant"},{"role": "user", "content": prompt},],stream=False
)
print(response.choices[0].message.content)
import json
from openai import OpenAI# 你的DeepSeek API Key
api_key = "你的API_KEY"# 读取本地评论文件,提取评论内容
comments = []
with open('data.txt', 'r', encoding='utf-8') as f:for line in f:try:item = json.loads(line)# 主评论内容comment = item['snippet']['topLevelComment']['snippet']['textDisplay']comments.append(comment)except Exception as e:continuecomments = comments[:50]
comments_text = "\n".join([f"{i+1}. {c}" for i, c in enumerate(comments)])# 构造prompt
prompt = f"""请对以下YouTube视频评论内容进行总结提炼,提取主要观点、亮点,并做简要的情感分析(如正面、负面、中性),输出简明扼要的中文总结:\n评论内容如下:\n{comments_text}"""# 调用DeepSeek大模型API
client = OpenAI(api_key=api_key, base_url="https://api.deepseek.com")response = client.chat.completions.create(model="deepseek-chat",messages=[{"role": "system", "content": "You are a helpful assistant"},{"role": "user", "content": prompt},],stream=False
)print("总结与情感分析:\n")
print(response.choices[0].message.content)
结果示意

4.2(可选)增强版:批量情感标注与主题提炼
若你需要结构化结果(JSONL)、更稳健的批量调用与退避重试,可参考下述增强版;若仅保留原始代码即可跑通,可忽略本段。
# -*- coding: utf-8 -*-
"""
情感与主题提炼(增强版)
- 从 JSONL 读取
- 分批调用大模型
- 输出结构化结果
"""
import os
import json
import time
import random
from typing import Listfrom openai import OpenAIINPUT_JSONL = "youtube_comments.jsonl"
OUTPUT_JSONL = "youtube_comments_labeled.jsonl"
API_KEY = os.getenv("DEEPSEEK_API_KEY", "")
BASE_URL = "https://api.deepseek.com"
MODEL = "deepseek-chat"client = OpenAI(api_key=API_KEY, base_url=BASE_URL)def backoff_sleep(i: int):time.sleep(min(60, 1.5 ** i + random.uniform(0, 0.5)))def load_comments(max_n: int = 500) -> List[str]:arr = []with open(INPUT_JSONL, "r", encoding="utf-8") as fp:for line in fp:obj = json.loads(line)text = obj.get("text") or ""if text.strip():arr.append(text.strip())if len(arr) >= max_n:breakreturn arrdef label_batch(batch: List[str]) -> str:prompt = ("请你以中文对下面一组 YouTube 评论进行情感分类(正面/中性/负面),""并抽取每条评论的1~2个主题或观点关键词。""仅返回JSON数组,每条形如:"'{"text": "...", "sentiment": "正面|中性|负面", "keywords": ["k1","k2"]}。\n\n'"评论列表:\n" + "\n".join([f"{i+1}. {t}" for i, t in enumerate(batch)]))for i in range(6):try:resp = client.chat.completions.create(model=MODEL,messages=[{"role": "system", "content": "You are a helpful assistant."},{"role": "user", "content": prompt},],stream=False,temperature=0.2,)return resp.choices[0].message.contentexcept Exception as e:backoff_sleep(i)raise RuntimeError("模型调用多次失败")def main():comments = load_comments(max_n=1000)batch_size = 25with open(OUTPUT_JSONL, "w", encoding="utf-8") as out:for i in range(0, len(comments), batch_size):batch = comments[i:i+batch_size]result = label_batch(batch)out.write(result.strip() + "\n")print(f"完成:结果写入 {OUTPUT_JSONL}")if __name__ == "__main__":main()
五、如何挑选高质量海外代理 IP
关键评估维度

- IP 质量:真实住宅/移动 IP,ASN/地理覆盖是否满足目标站点风控要求
- 成功率与稳定性:丢包与断线情况
- 并发与带宽:是否能支撑大规模任务
- 会话黏连:是否支持 Sticky Session
- 合规与透明:来源合法、隐私政策清晰
- 价格/计费:按流量/并发/IP 数等
为何以 NetNut 为示例 :NetNut 官网

-
全球覆盖/节点规模示意
![在这里插入图片描述]()
-
动态切换/匿名性示意
![在这里插入图片描述]()
-
文档与集成示意
![在这里插入图片描述]()
-
大规模/实时任务稳定性示意
![加粗样式]()




再次强调:选择任何代理前,请确认其合规来源与服务条款,并确保你的使用场景与目标平台政策不冲突。本文仅提供技术思路与中立示例。
六、常见报错与排查速查表
| 现象/状态码 | 可能原因 | 建议处理 |
|---|---|---|
| 401 Unauthorized | API Key 无效/未启用 | 在 GCP 启用 YouTube Data API v3,更新 Key |
| 403 Forbidden | 超配额/权限/地区限制 | 降低频率、等待配额、检查 API 项目与授权 |
| 429 Too Many Requests | 速率过高 | 退避重试、降低并发/节流 |
| 5XX/Cloudflare 5XX | 目标端临时故障 | 指数退避+重试,必要时更换出口路由 |
| 超时/连接失败 | 网络/代理不稳 | 增加超时、重试,校验代理质量 |
| 数据不完整 | 分页未拉全/解析错误 | 检查 nextPageToken 与字段映射;保存原始 JSON |
七、总结
对于 iPhone 17 等全球热点的用户反馈采集,“官方 API + 合规代理(可选)+ 大模型分析” 是兼顾稳健与效率的路径:
- 官方 API 提供结构化与稳定字段;
- 高质量代理在跨境网络与可用性上提供保障;
- 大模型可在观点提炼/情感判别/主题聚类上加速洞察。
本文福利🧧:https://netnut.cn/?utm_medium=influen&utm_source=liyanbin