1. 前言
list 中使用的函数与之前所学的,并无太多的区别,下面只简单的讲解一些特殊的地方。List 是链表,是之前数据结构所说的带头双向循环链表,使用 list 时需要包含头文件 --- list。原型为:template < class T, class Alloc = allocator<T> > class list。
2. list 类
1. 初始化
list 支持无参初始化,n 个 val 值初始化,大括号初始化,迭代器区间初始化,如下代码所示:
template
void Print(list lt)
{
for (auto& e : lt)
{
cout lt1; // 无参初始化
list lt2(10, 2); // n 个 val 值初始化
Print(lt2);
vector v = { 1, 3, 5, 7, 9 };
listlt3(v.begin(), v.end()); // 迭代器区间初始化
Print(lt3);
list lt4 = { 1, 2, 3, 4, 5 }; // 大括号初始化
Print(lt4);
return 0;
}代码运行结果:

特殊的是支持用数组来初始化,如下代码所示:
int arr[10] = { 1, 3, 5, 7, 9, 2, 4, 6, 8, 0 };
list lt5(arr + 2, arr + 7);
Print(lt5);运行结果:

为什么可以用数组来初始化呢?这里实际上调用了迭代器区间初始化函数。但是该函数的参数明明是迭代器,为什么可以传指针呢?指针是一种特殊的迭代器(前提是该指针是指向数组的指针,容器的迭代器不一定是指针),指向数组的指针的行为符合迭代器,迭代器的行为本质上模拟的就是指向数组的指针。
在之前实现 vector 时,提到了算法库中的 sort 函数,该函数的原型为:template <class RandomAccessIterator> void sort (RandomAccessIterator first, RandomAccessIterator last)。它的参数为迭代器区间,它也可以接收数组指针。
2. 迭代器
1. 迭代器是通用的遍历容器的方式,并且封装了容器的底层,屏蔽了容器结构的差异和底层实现的细节
2. 迭代器可以复用/通用,实现算法时,用迭代器函数模板方式实现,跟底层容器结构解耦
3. 支持迭代器也就支持范围for
在查看 cplusplus 网站时,也许会发现有些迭代器起的名字有些不同,如下图所示:
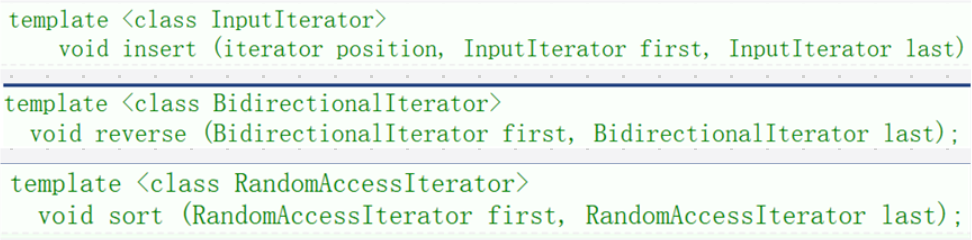
InputIterator 是只写迭代器,BidirectionalIterator 是双向迭代器,RandomAccessIterator 是随机迭代器。实践中容器迭代器分为三种类型:单向,双向,随机,它们是从功能的角度进行分类的,所有迭代器的都有的功能:++ ,*,!=;这三种迭代器的功能上有些许不同:
1. 单向迭代器支持:++,*,!=
2. 双向迭代器除了通用功能之外,还支持 - -
3. 随机迭代器除了通用功能之外,还支持 - - /+ /-
怎么知道容器的迭代器是什么类型呢?在 cplusplus 网站上搜索相应的容器,向下划至Member types ,就可以看到了,拿 list 举例子:
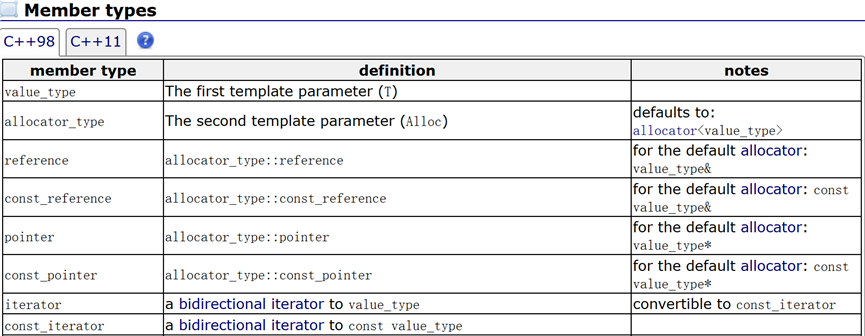
总结:
1. 单向:单链表/哈希表
2. 双向:红黑树/双向链表list
3. 随机:string/vector/双端队列deque
一个容器的迭代器是哪种类型由容器的底层结构决定,迭代器支持什么功能与容器的底层支不支持有很大的关系。从算法角度来看,一个算法不是所有的容器都可以使用(就如上述所说的算法库中的 sort 排序算法),算法对迭代器是有一些要求的,算法的迭代器名字就是要求;算法要求传什么类型的迭代器就传什么类型的迭代器,如果不符合它的要求,程序会报错。
但是如果算法要求传单向迭代器,既可以传单向,也可以传双向和随机;如果算法要求传双向迭代器,既可以传双向,也可以传随机。为什么可以这样呢?单向双向随机迭代器之间的关系是继承关系,单向是双向和随机的父类,双向是随机的父类,子类是特殊的父类,要求传父类,可以传子类(了解即可,在继承部分会详细讲解)。
设计迭代器时除了单向双向随机,还有只读和只写迭代器,然而实际使用中并不会使用自读和只写迭代器:

3. sort 函数
list 中提供了 sort 函数,但是算法库中不是存在一个 sort 函数吗,用现成的不行吗?为什么 list 这里还要提供一个函数?因为算法库中的 sort 函数要求传随机迭代器,list 的迭代器是双向的,算法库中的 sort 函数不支持 list 。但是 list 提供的 sort 没什么用,为什么呢?对比算法库中的 sort 函数和 list 的 sort 函数的效率:
生成一百万个随机数,将这些随机数存储到 vector 和 list 容器中,vector 使用算法库中的 sort 函数排序这一百万个数,list 使用自己的 sort 函数排序一百万个数,对比两者排序所需要的时间。
效率比较代码:
srand(time(0));
const int N = 1000000;
vector v;
list lt;
for (int i = 0; i < N; i++)
{
auto e = rand() + i;
v.push_back(e);
lt.push_back(e);
}
int begin1 = clock();
sort(v.begin(), v.end());
int end1 = clock();
int begin2 = clock();
lt.sort();
int end2 = clock();
printf("vector sort:%d\n", end1 - begin1);
printf("list sort:%d\n", end2 - begin2);运行结果:
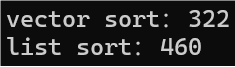
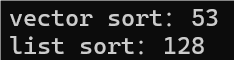
这个结果可能不太明显,因为这个是在 debug 版本下运行的结果,接下来在 release 版本下运行代码,结果如下图所示:
再来演示一个场景 --- 生成一百万个随机数,将这些随机数都存储在 list 的实例化对象 lt1 和 lt2 中,其中用 lt1 的迭代器区间初始化 vector 实例化的对象 v,接下来的操作与前面的一样,比较两者排序所需的时间。
效率比较代码:
srand(time(0));
const int N = 1000000;
list lt1;
list lt2;
for (int i = 0; i v(lt1.begin(), lt1.end());
int begin1 = clock();
sort(v.begin(), v.end());
int end1 = clock();
int begin2 = clock();
lt2.sort();
int end2 = clock();
printf("list copy vector sort:%d\n", end1 - begin1);
printf("list sort:%d\n", end2 - begin2);运行结果:

为什么 debug 版本下与 release 版本下的运行效率差这么多呢?算法库中的 sort 函数的底层运用了快速排序算法,list 中的 sort 函数的底层运用了归并排序算法。快速排序算法中使用了递归,在debug 版本下显示不出递归算法的优势;在 release 版本下会自动优化递归算法,所以两个版本下,效率会差很多。
既然算法库中的 sort 函数的底层使用了快速排序算法,list 中的 sort 函数的底层使用了归并排序算法。在学习数据结构排序时,我们知道两个算法针对数组的排序效率是差不多的,时间复杂度均为nlogn。但是针对链表的排序效率是不同的,为什么呢?这与 cpu 高速缓存命中率有关(了解即可)。
所以一般默认存储数据优先使用顺序表 vector 容器,这也是为什么在写那些算法体的时候,提供的容器是 vector。数据是存储在内存中的,vector 和 list 容器的不同之处在于,一个内存空间是连续的,一个内存空间是不连续的。
4. remove 函数和 splice 函数
remove 函数的函数原型为:void remove (const value_type& val),其函数的功能为:从容器中移除与 val 比较结果相等的所有元素。
代码:
list lt1 = { 2,4,5,3,7,3,7,2,1,3 };
Print(lt1);
lt1.remove(3);
Print(lt1);运行结果:

splice 函数的函数原型为:void splice (iterator position, list& x, iterator i),其函数的功能为:将元素从 x 转移到容器中,并将它们插入至指定位置。
代码:
listlt2 = { 2, 4, 6, 8, 0 };
Print(lt2);
auto it = find(lt2.begin(), lt2.end(), 0);
lt2.splice(lt2.begin(), lt2, it);
Print(lt2);运行结果:

3. 结言
list 中许多函数的功能与 string 和 vector 容器的并无二异,掌握了 string 中的函数的使用方法,list 的函数也不在话下。本文最重要的部分是迭代器部分,之后模拟实现 list 时,最重要的部分也是迭代器部分。