Hadoop完全分布式配置 - 实践
环境
乌班图Linux系统装虚拟机——至少安装两个虚拟机

Hadoop完全分布式环境
1.安装Java、Hadoop
文章:https://blog.csdn.net/2401_86886401/article/details/151230102?spm=1001.2014.3001.5501
可以看到Java和Hadoop的安装方法

2.网络配置
1.网络适配器设置
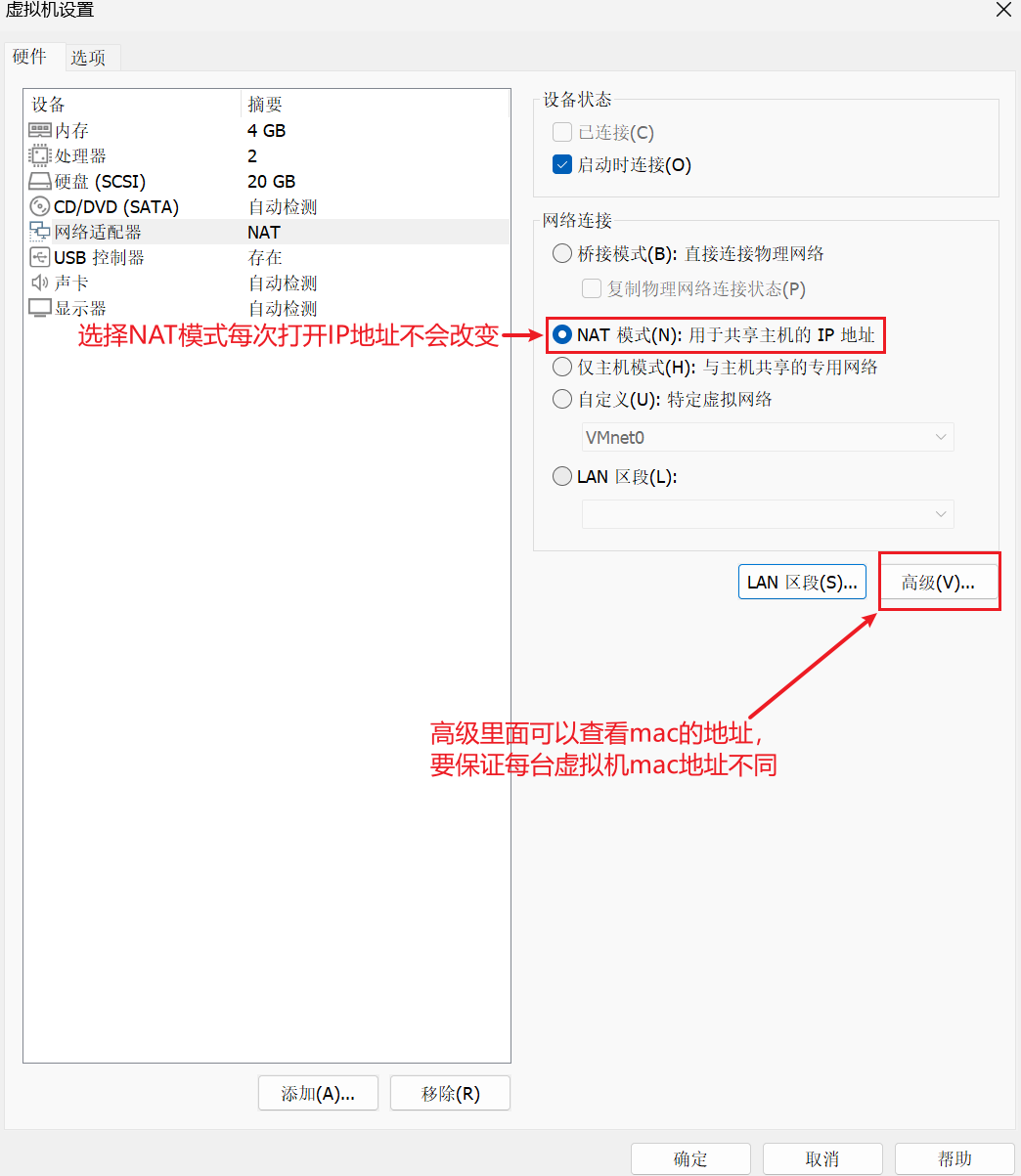
2.使IP地址不改变(NAT模式)
1.查看网关和IP范围
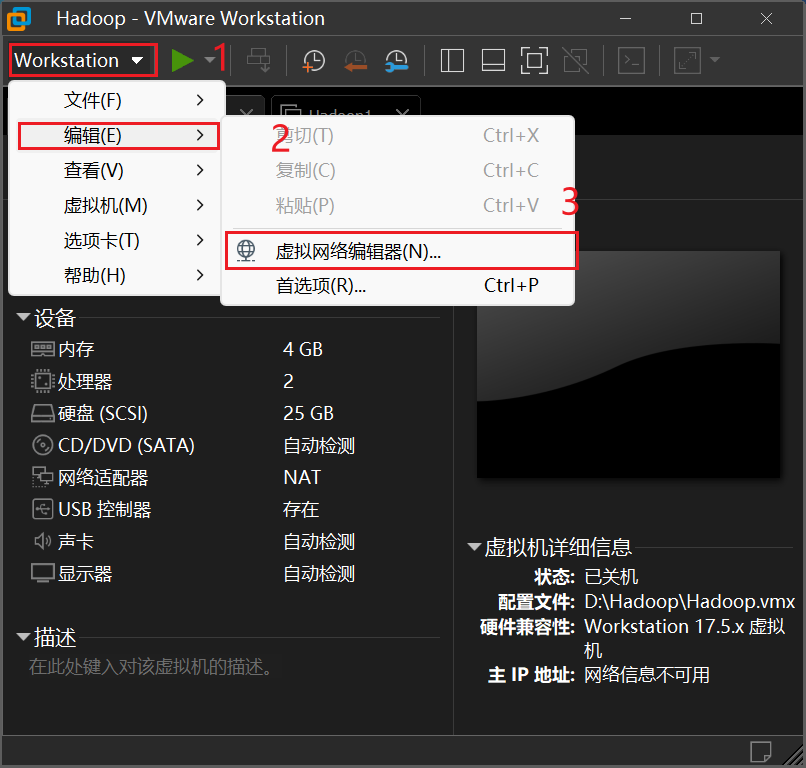
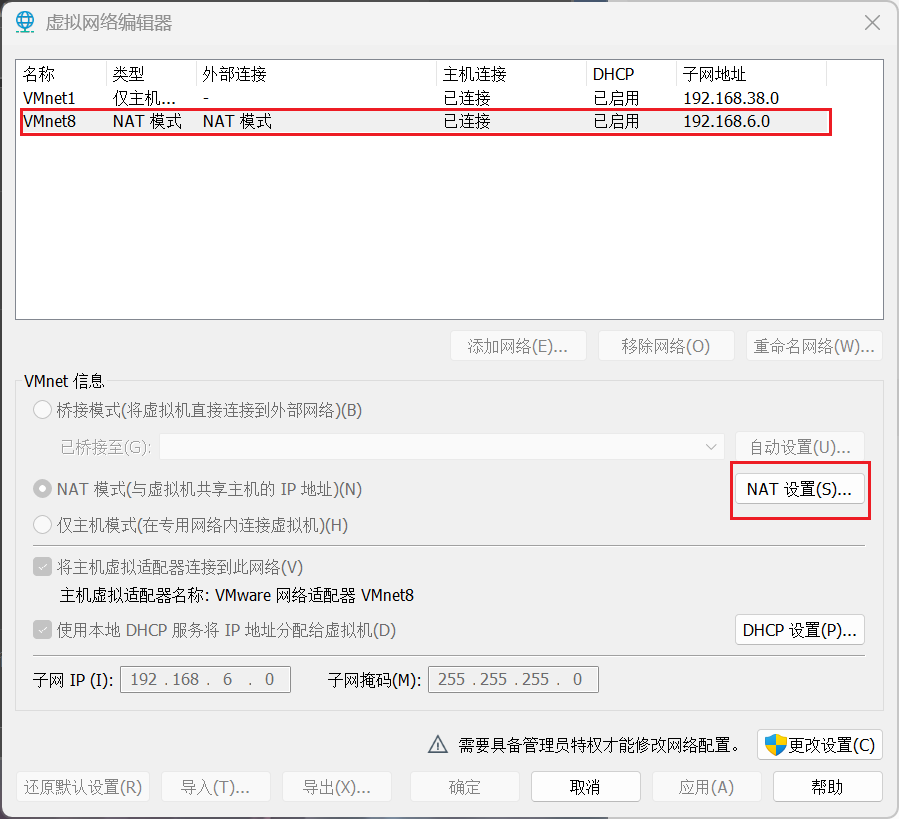 (进入后,记录网关)
(进入后,记录网关)
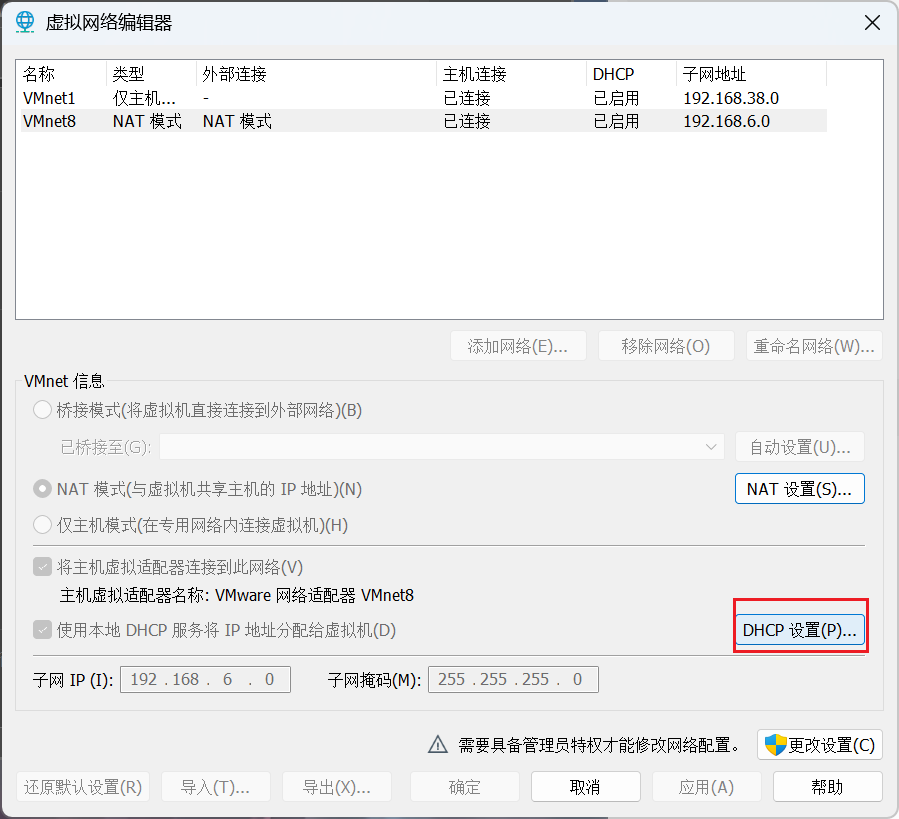 (进入后记录IP范围)
(进入后记录IP范围)
2.在系统中设置静态IP
ip addr
//查看网卡名称(类似ens33、ens160)记住ls /etc/netplan
//查看配置文件名称(较新版本)
//如果上一条失败(自身版本较旧)
sudo nano /etc/network/interfaces//文档编辑格式
auto ens33
iface ens33 inet staticaddress 192.168.6.100 # 你要设置的静态 IP 地址,需在子网内且不冲突netmask 255.255.255.0 # 子网掩码gateway 192.168.5.1 # 网关 IP,即之前看到的dns-nameservers 8.8.8.8 114.114.114.114 # DNS 服务器地址退出文档时“Ctrl+o”-->回车-->“Ctrl+x”
sudo systemctl restart networking
//重启网络服务3.修改主机名(设置一个主节点-Master,一个从节点-Slave1)
1.修改/etc/hostname文件(设置后要重启)
这是储存系统主机名的核心文件
sudo vim /etc/hostname
//打开主机文件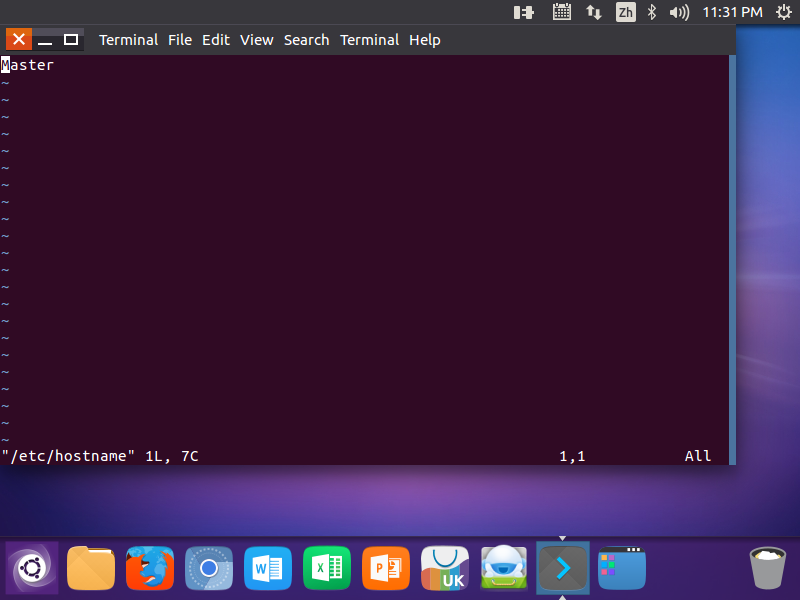 (主节点)
(主节点)
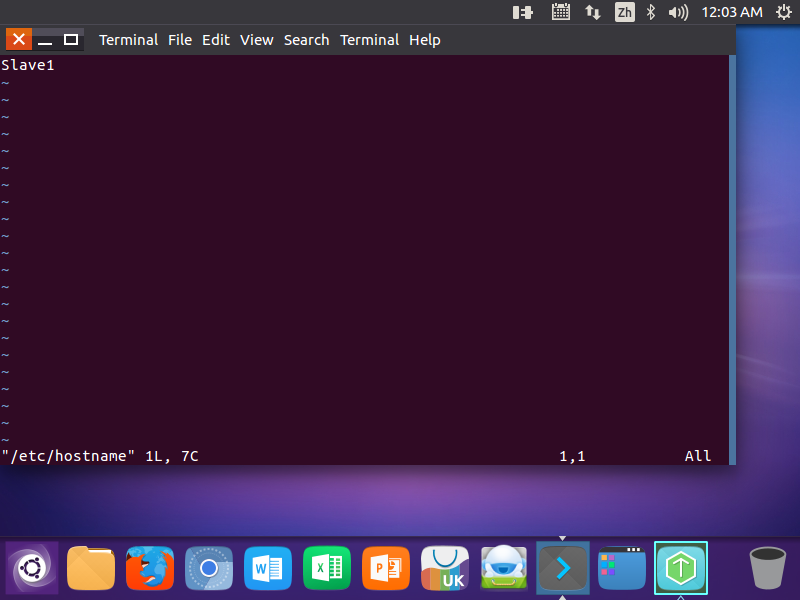 (从节点)
(从节点)
2.修改/etc/hosts文件(地址要设置成ifconfig命令后看到的地址,设置后要重启)
这是一个本地DNS解析文件,用于将主机名映射到IP地址
作用:
1.让系统能通过主机名找到对应的IP
2.避免一些依赖主机名解析的程序错误
sudo vim /etc/hosts
//打开DNS文件![]()
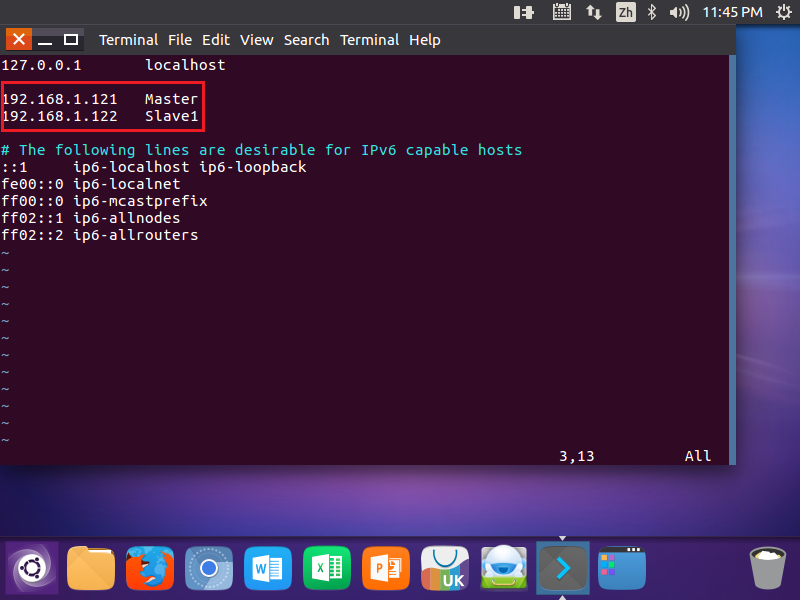 (主机名修改要区分大小写)
(主机名修改要区分大小写)
tip1:在命令模式下点击“i”进入编辑模式
tip2:退出vim编辑要在命令模式(Esc)下输入“:”+“wq”
3.测试是否互通(注意地址是否设置正确,否则不通)
需要两个虚拟机都打开
ping Slave1 -c 3
//用主节点联通从节点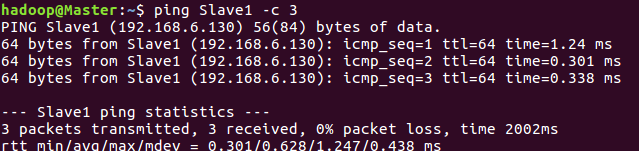 (成功)
(成功)
4.SSH无密码登录节点
1.安装SSH(所有机器都要装)
sudo apt-get install openssh-server
//安装SSH server![]()
2.第一次装可以看博主的伪分布式配置链接:https://blog.csdn.net/2401_86886401/article/details/151230102?spm=1001.2014.3001.5501
3.生成公钥,并无密码登录(有公钥则删除重新生成)
cd ~/.ssh
//如果没有该目录则执行一次“ssh localhost”
rm ./id_rsa*
//如果之前有公钥则删除
ssh-keygen -t rsa
//一直回车就行
cat ./id_rsa.pub >> ./authorized_keys
//令节点能无密码登录![]()
4.将公钥传给其他节点(其他节点也要开机)
scp ~/.ssh/id_rsa.pub hadoop@Slave1:/home/hadoop/
//hadoop是你的从节点的用户名,如果不同,要修改 (有100%则成功)
(有100%则成功)
5.在从节点上将SSH公钥加入授权
mkdir ~/.ssh
//创建文件夹,如果有则不需要创建
查看是否有没有——“ls -l ~/.ssh”![]()
cat ~/id_rsa.pub >> ~/.ssh/authorized_keys
//加入授权![]()
rm ~/id_rsa.pub
//用完删除就行![]()
6.尝试登录
ssh hadoop1@Slave1
//hadoop1是我的从节点用户名,填自己的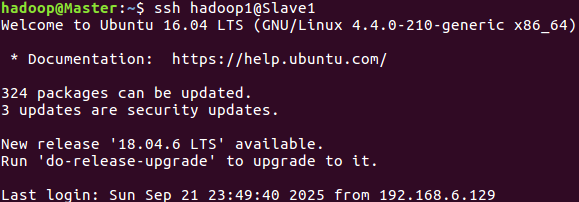
5.配置PATH变量
使hdfs命令能在任意目录生效
在博主https://blog.csdn.net/2401_86886401/article/details/151230102?spm=1001.2014.3001.5501中可以看

start-dfs.sh
//其在任意目录都能运行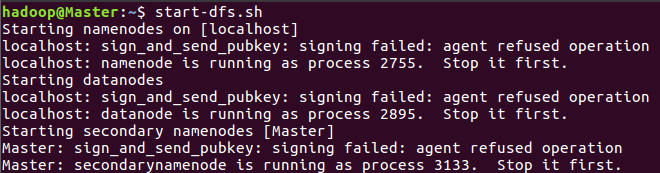
6.配置集群/分布式环境
1.修改workers文件(主、从节点的worker文件都要修改)
需要将所有数据节点的主机名写入文件,一行一个(默认为localhost——把本机作为名称节点和数据节点)。在分布式配置时可以保留localhost,让本机节点既是名称节点也是数据节点,也可以删除localhost,使本机节点只作为名称节点使用
vim /opt/hadoop-3.1.3/etc/hadoop/workers
//编辑workers文件![]()
 (Master作为名称节点使用)
(Master作为名称节点使用)
2.修改core-site.xml文件
参考:https://blog.csdn.net/2401_86886401/article/details/151230102?spm=1001.2014.3001.5501
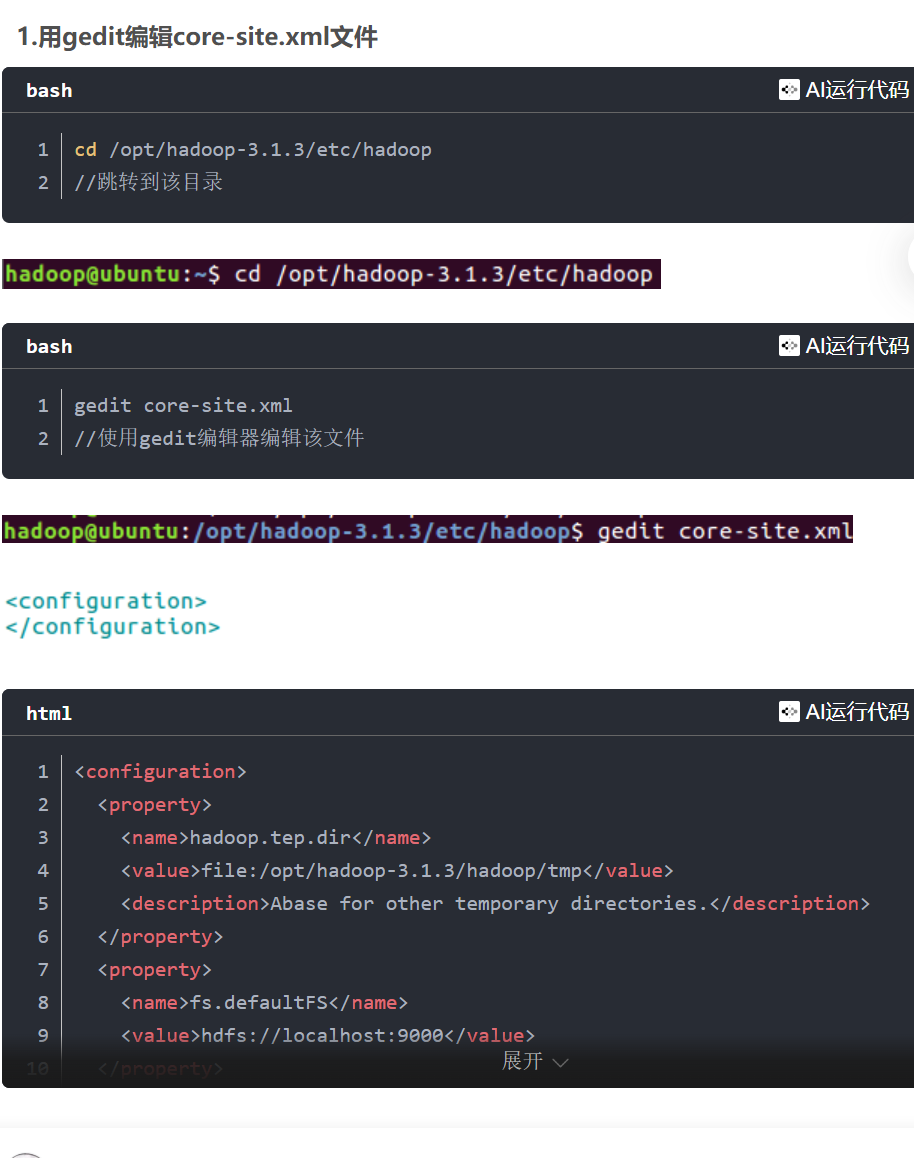
(其中的localhost改为IP地址、Master)
同步从节点
scp /opt/hadoop-3.1.3/etc/hadoop/core-site.xml hadoop1@Slave1:/opt/hadoop-3.1.3/etc/hadoop
//将主节点配置的文件同步给从节点![]()
3.修改hdfs-site.xml文件
参考:https://blog.csdn.net/2401_86886401/article/details/151230102?spm=1001.2014.3001.5501
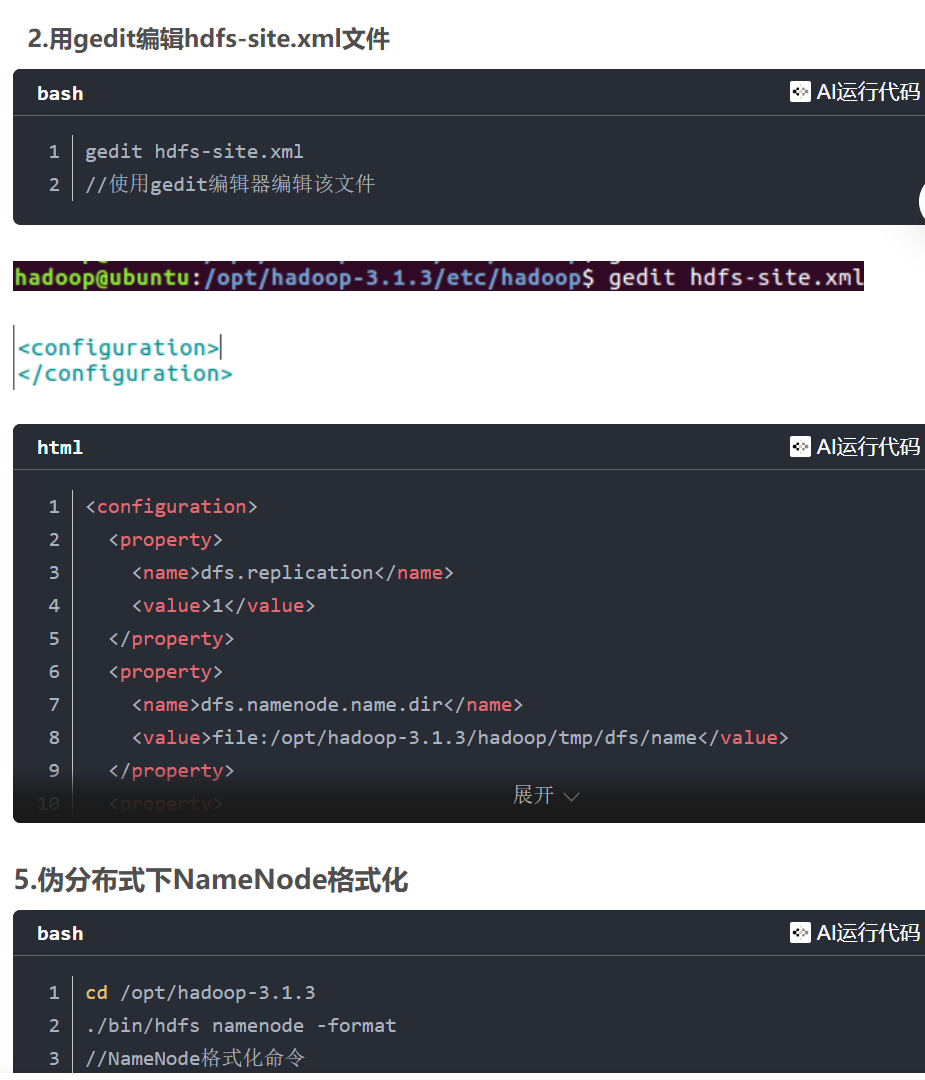
要在文件中多增加一段
dfs.namenode.secondary.http-address Master:50090 dfs.replication 1 dfs.namenode.name.dir file:/opt/hadoop-3.1.3/hadoop/tmp/dfs/name dfs.datanode.data.dir file:/opt/hadoop-3.1.3/hadoop/tmp/dfs/data 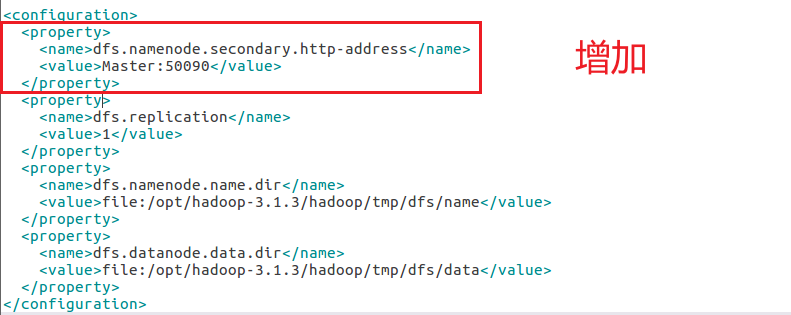
4.修改mapred-site.xml文件
在自己的hadoop文件路径下文件“mapred-site.xml.template”修改为mapred-site.xml(有些自己就是修改后的文件,不用人为修改),然后修改文件配置
mv mapred-site.xml.template mapred-site.xml
//修改文件名,有些不用修改![]()
gedit mapred-site.xml
//打开要修改的文件![]()

mapreduce.framework.name yarn mapreduce.jobhistory.adress Master:10020 mapreduce.jobhistory.webapp.address Master:19888 yarn.app.mapreduce.am.env HADOOP_MAPRED_HOME=/opt/hadoop-3.1.3 mapreduce.map.env HADOOP_MAPRED_HOME=/opt/hadoop-3.1.3 mapreduce.reduce.env HADOOP_MAPRED_HOME=/opt/hadoop-3.1.3 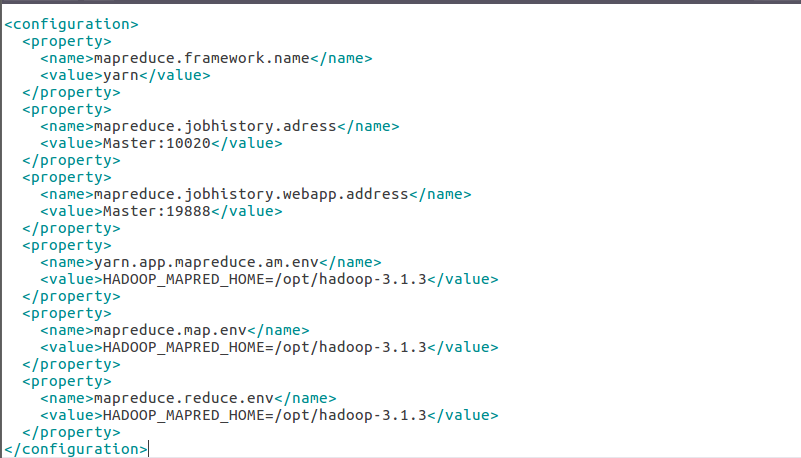
5.修改yarn-site.xml文件
gedit yarn-site.xml
//打开文件![]()

yarn.resourcemanager.hostname Master yarn.nodemanager.aux-services mapreduce_shuffle 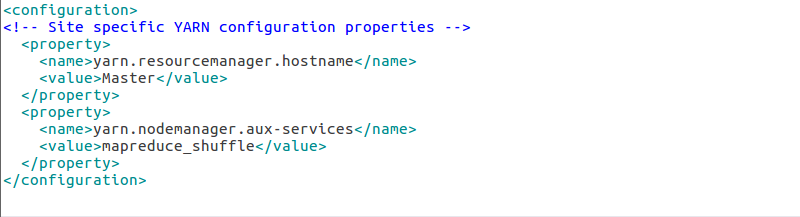
6.将Master的文件复制给从节点(要清除伪分布模式下生成的临时文件)
cd /opt/hadoop-3.1.3
//切换目录
sudo rm -r ./hadoop-3.1.3/tmp
//删除Hadoop临时文件
sudo rm -r ./logs/*
//删除日志文件
cd /opt
//切换目录
tar -zcf ~/hadoop.master.tar.gz hadoop-3.1.3
//先压缩再复制![]()
![]()
![]()
![]()
![]()
scp ~/hadoop.master.tar.gz hadoop1@Slave1:/home/hadoop1
//复制文件到从节点![]()
7.在从节点上解压文件
sudo rm -r /opt/hadoop-3.1.3
//删除旧的
sudo tar -zxf ~/hadoop.master.tar.gz -C /opt
//解压主节点传输文件
sudo chown -R hadoop1 /opt/hadoop-3.1.3
//修改文件和目录的拥有者![]()
![]()
![]()
8.格式化Master名称节点(只需要进行一次)
hdfs namenode -format
//格式化名称节点![]()
9.启动Hadoop
start-dfs.sh
start-yarn.sh
mr-jobhistory-daemon.sh start historyserver 此命令可能弃用,替换为"mapred --daemon start"
//开启Hadoop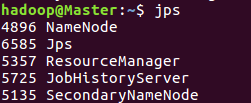 (主节点成功)
(主节点成功)
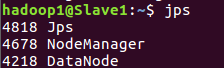 (从节点成功)
(从节点成功)
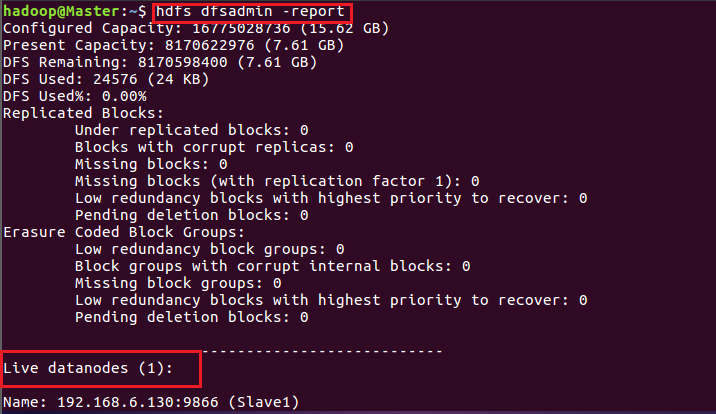 (主节点输入红框命令——成功)
(主节点输入红框命令——成功)
10.分布式实例
start-dfs.sh
start-yarn.sh
mapred --daemon start
//开启服务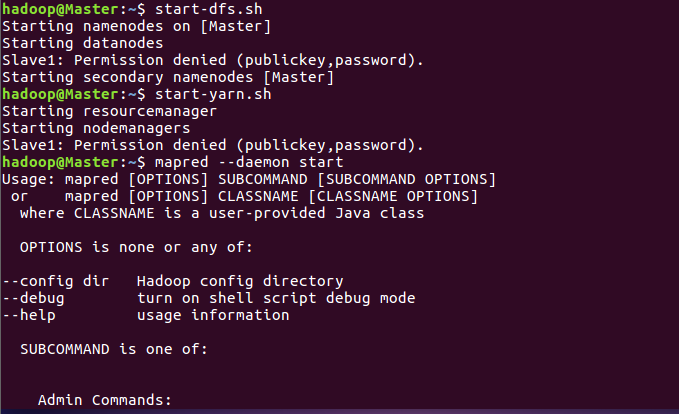
hdfs dfs -mkdir -p /user/hadoop
//创建HDFS上的用户目录
hdfs dfs -mkdir input
//创建一个input目录
hdfs dfs -put /opt/hadoop-3.1.3/etc/hadoop/*.xml input
//将配置文件复制到input目录![]()
![]()
hadoop jar /opt/hadoop-3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar grep input output 'dfs[a-z.]+'
//运行mapreduce作业![]()
会显示进度,如果长时间进度没变化可以重启试试,也可以看硬盘内存够不够
11.关闭Hadoop集群
stop-yarn.sh
stop-dfs.sh
mr-jobhistory-daemon.sh stop historyserver
//关闭Hadoop集群![]()
![]()
![]()