- 查询当前数据库的所有表: SHOW TABLES;
- 查询表的结构:DESC 表名
- 查询指定表的建表语句 SHOW CREATE TABLE 表名
- 删除表DROP TABLE [IF EXISTS] 表名 [表名2 表名3 ...]
- 删除指定表,并重新创建该表TRUNCATE TABLE 表名
- 创建表
CREATE TABLE 表名(字段1 字段1类型[COMMENT 字段1注释],字段2 字段2类型[COMMENT 字段2注释],......字段n 字段n类型[COMMENT 字段n注释]
)[COMMENT 表注释]
eg :如何创建下面的表
| id | name | age | gender |
|---|---|---|---|
| 1 | 猪头 | 43 | 男 |
| 2 | 秃头 | 38 | 男 |
| 3 | 贵头 | 33 | 女 |
语句如下:
CREATE TABLE TB_USER(ID INT COMMENT 'ID',NAME VARCHAR(50) COMMENT '姓名',AGE INT COMMENT '年龄',GENDER VARCHAR(1) COMMENT '性别'
) COMMENT '用户表';
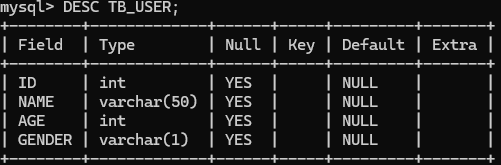
我们通过DESC查看表的结构:
DESC TB_USER;
那么我们如何找到我们刚才的注释呢?
SHOW CREATE TABLE TB_USER;
可以看到

创建表的时候我们并没有写到 ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci语句,这是什么呢?### 后续会更新
- ENGINE=InnoDB
- DEFAULT CHARSET=utf8mb4 表的默认字符集
- COLLATE=utf8mb4_0900_ai_ci 默认的排序规则
注意我们使用TRUNCATE TABLE 表名的时候,需要注意TRUNCATE的拼写,同时这个指令不能用IF EXISTS语句,TRUNCATE语句最后的效果就是删除了表中的数据,但是保留了表的结构
关于MySQL的数据类型
整数数值类型
| 类型 | 大小 | 描述 |
|---|---|---|
| TINYINT | 1byte | 小整数值 |
| SMALLINT | 2bytes | 大整数值 |
| MEDIUMINT | 3bytes | 大整数值 |
| INT/INTEGER | 4byte | 大整数值 |
| BIGINT | 8bytes | 极大整数值 |
| FLOAT | 4bytes | 单精度浮点数值 |
| DOUBLE | 8bytes | 双精度浮点数 |
| DECIMAL | 小数值 |
注意decimal在使用的时候需要指定精度和标度,
例如123.45的精度就是12345总共的位数也就是5,标度也就是45,小数的位数2
当我们进行项目搭建的时候,我们可能考虑到内存占用的问题,例如当我们创建一个表,其中的一个关键字是年龄,年龄的范围不会超过tinyint的范围,且不可能是负数,在tinyint后面添加unsigned,所以创建时候尽可能的减小内存:
CREATE USER(ID INT,AGE TINYINT UNSIGNED,NAME VARCHAR(50)
);
同时我们也要注意,在使用小数类型的时候,都可以定义精度(位数)和标度(小数点后几位),但是实际使用的时候,float和double都不推荐使用精度和标度的定义,只有decimal使用的时候进行精度和标度的定义
字符数值类型
| 类型 | 大小 | 描述 |
|---|---|---|
| CHAR | 0-255bytes | 定长字符串 |
| VARCHAR | 0-65535bytes | 不定长字符串 |
| TINYBLOB | 0-255bytes | 不超过255字节的二进制数据 |
| TINYTEXT | 0-255bytes | 短文本字符串 |
| BLOB | 0-65535bytes | 二进制形式的长文本数据 |
| TEXT | 0-65535bytes | 长文本数据 |
| MEDIUMBOLB | 0-16777215bytes | 二进制形式的中等长度文本数据 |
| MEDIUMTEXT | 0-16777215bytes | 中等长度文本数据 |
| LONGBLOB | 0-294967295bytes | 二进制形式的极大文本数据 |
| LONGTEXT | 0-294967295bytes | 极大文本数据 |
对于定长字符串char,在对于定长文本处理时候性能更好,而varchar对于不定长的字符串处理时性能较差
举个例子,我们创建一个char(10),我们就算创建一个长度为1的字符串,其占用的内存也是10个字符长度所占用的内存,而varchar(10)中创建几个字符的字符串对应的就占用多少字符的字符串的内存
实际使用:
char gender(1) comment '性别', --性别字符串长度不变
varchar username(50) comment '用户名' --用户名长度可变
日期类型
| 类型 | 大小 | 格式 | 描述 |
|---|---|---|---|
| DATE | 3bytes | YYYY-MM-DD | 日期值 |
| TIME | 3bytes | HH:MM:SS | 时间值或持续时间 |
| YEAR | 1bytes | YYYY | 年份值 |
| DATETIME | 8bytes | YYYY-MM-DD HH:MM:SS | 混合日期和时间值 |
| TIMESTAMP | 4bytes | YYYY-MM-DD HH:MM:SS | 混合日期和时间值,时间戳 |
对于上面的操作,我们通过下面的案例进行一个总结
eg :设计一个员工表,要求如下:
- 编号(纯数字)
- 员工工号(字符串类型,长度不超过10位)
- 员工姓名 (字符串类型,长度不超过10位)
- 性别
- 年龄
- 身份证号(二代身份证为18位数,且末尾可能是X)
- 入职时间(取年月日即可)
CREATE TABLE STUFFS(ID INT COMMENT '编号',STU_ID CHAR(10) COMMENT '员工工号',STU_NAME VARCHAR(10) COMMENT '员工姓名',GENDER CHAR(1) COMMENT '性别',AGE TINYINT UNSIGNED COMMENT '年龄',IDCARD CHAR(18) COMMENT '身份证号',D_DATE DATE COMMENT '入职时间'
) COMMENT '员工信息表';
我们前面讲了如何创建一个表,以及字段的类型,那么我们创建完成一个表之后,如何修改字段,如何在原有表的基础上添加字段呢?
DDL修改表的操作
- 添加字段 ALTER TABLE 表名 ADD 字段名 类型(长度) [COMMENT 注释] [约束];
- 修改数据类型ALTER TABLE 表名 MODIFY 字段名 新数据类型(长度) [COMMENT 注释]
- 修改字段名和字段类型ALTER TABLE 表名 CHANGE 旧字段名 新字段名 类型(长度) [COMMENT 注释] [约束]
- 删除字段 ALTER TABLE 表名 DROP 字段名
- 修改表名 ALTER TABLE 表名 RENAME TO 新表名
写的时候注意ALTER的拼写,不要拼成ALERT,同时后面的TABLE不要忘了
同时,也要注意的是修改数据类型或修改字段名会修改字段,原来的字段的注释会被删除
但是修改表名不会改变表中原有的数据
同时,也要注意的是修改数据类型或修改字段名会修改字段,原来的字段的注释会被删除
但是修改表名不会改变表中原有的数据