目录
- VLM2VEC: TRAINING VISION-LANGUAGE MODELS FOR MASSIVE MULTIMODAL EMBEDDING TASKS
- TL;DR
- Method
- Dataset
- Experiment
- Q&A
- Q:VLM2Vec与普通VLM有什么区别?难道仅仅是会将embedding存出来?
- Q:与CLIP/BLIP这类多模态模型的区别?
- Q:query与target embedding为什么是从VLM的最后一层的最后一个token?
- Q:为什么负样本存在一定噪声,加大Batch就可以缓解?
- Q:阅读3.2章节,说明如何通过GradCache增大BatchSize?与梯度累积有什么区别?
- 总结与思考
- 相关链接
VLM2VEC: TRAINING VISION-LANGUAGE MODELS FOR MASSIVE MULTIMODAL EMBEDDING TASKS
link
- 时间:24.10
- 单位:University of Waterloo, Salesforce Research
- 相关领域:大规模多模态表征学习
- 作者相关工作:Ziyan Jiang
- 被引次数:65
- 项目主页:https://github.com/TIGER-AI-Lab/VLM2Vec
TL;DR
Embedding模型是semantic语义相似性、信息检索与聚类等任务的关键模型。本工作针对embedding模型有三个contribution:
- 提出MMEB(大规模多模态embedding benchmark);
- VLM2VEC模型利用对比学习将任意VLM模型转为embedding模型;
- 效果上在MMEB benchmark上相对于已有方法;
Method
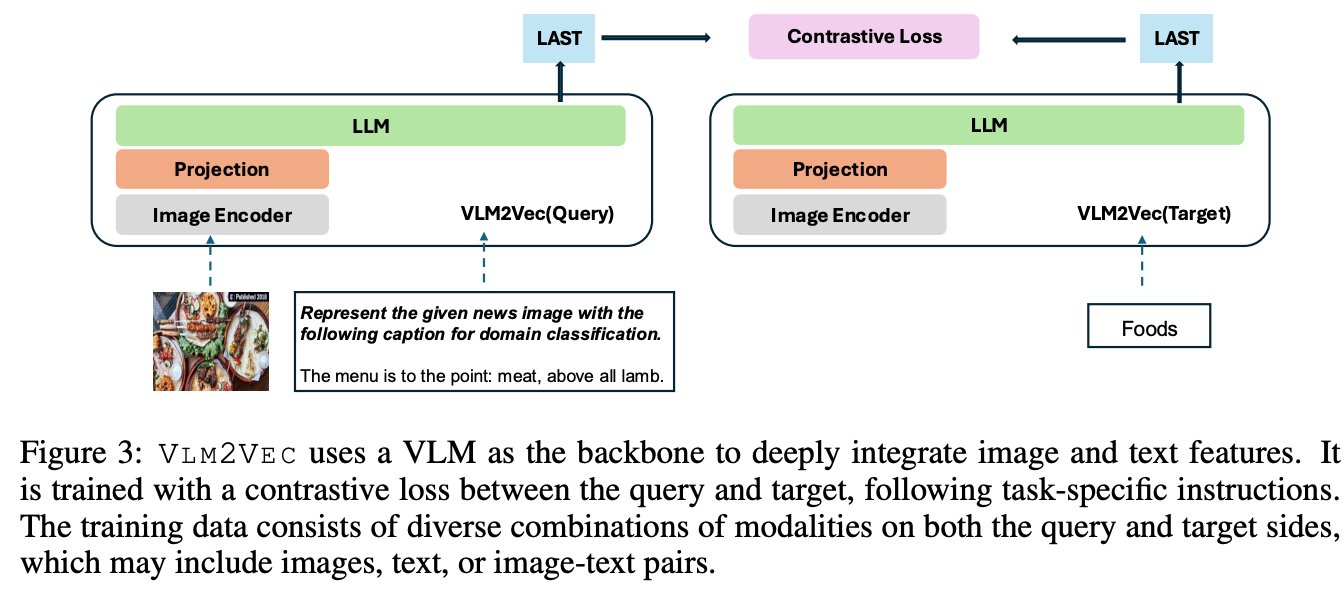
将query或者target输入VLM之后,将最后一层最后一个token取出作为embedding,通过以下公式来对齐query与target特征空间。
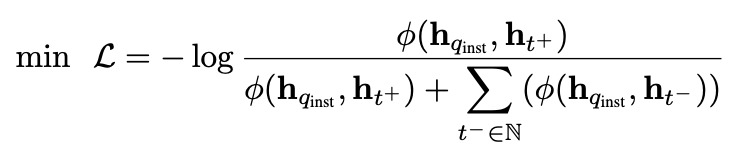
其中 \(h_{q}\)与\(h_{t}\)分别为query与target,可以是图、文或者图文对。
Dataset
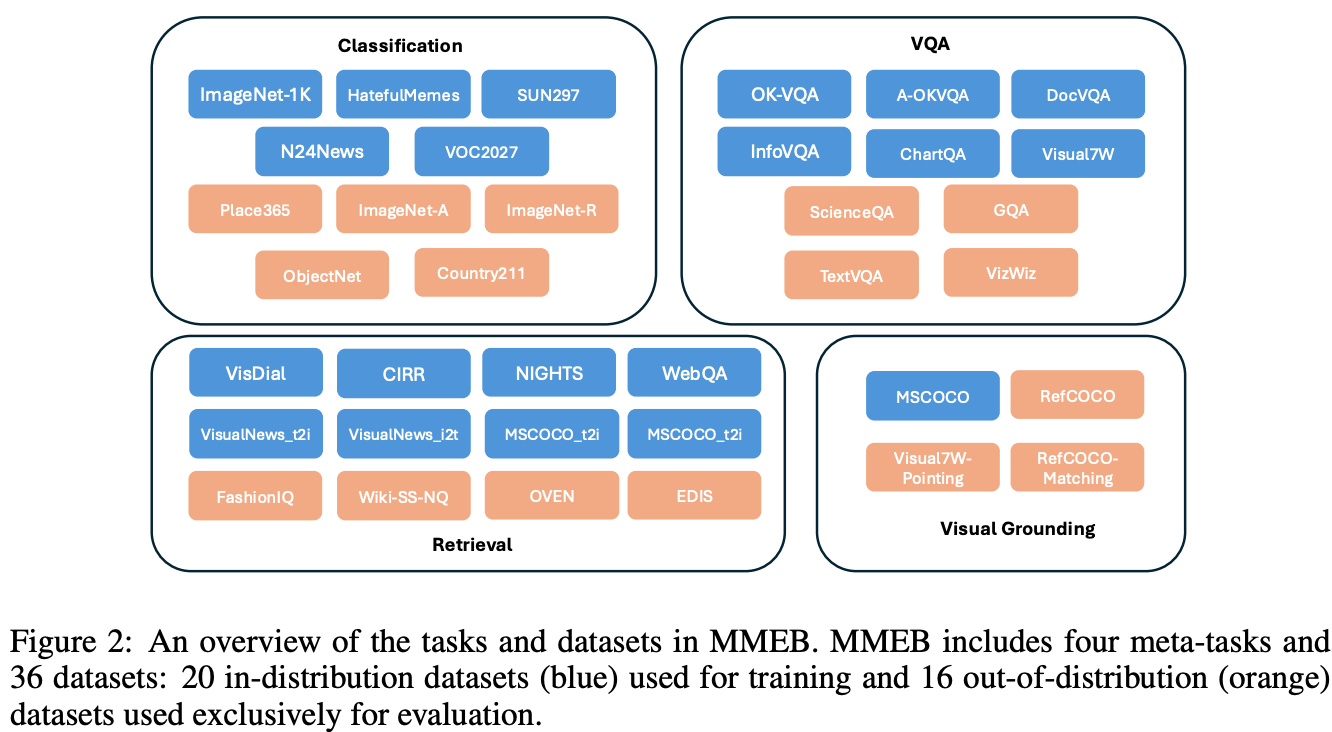
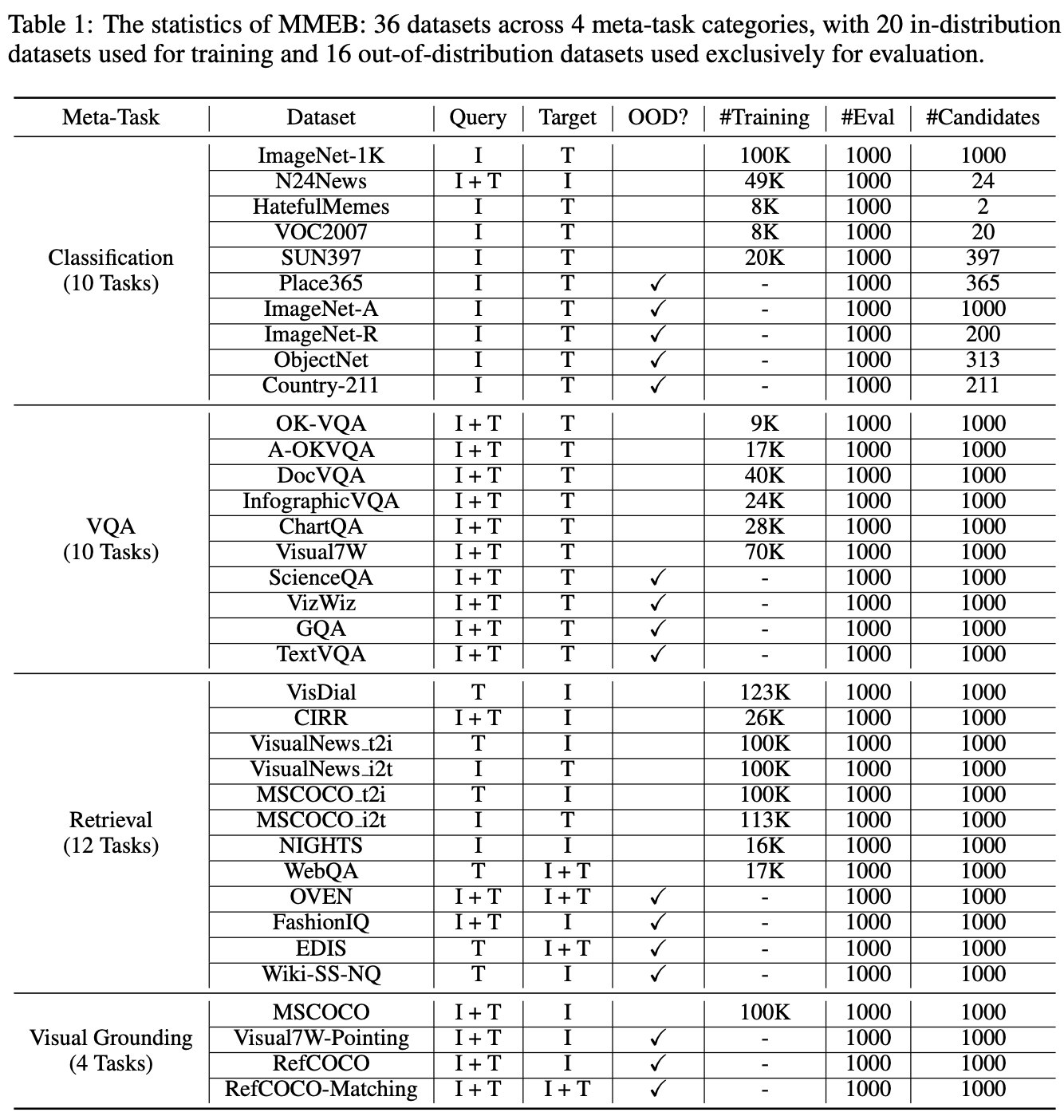
MMEB(massive multimodal embedding benchmark)
任务类型的图示说明

MMEB数据包含4个任务类别,总共36个数据集,以下表格与图示说明任务与子数据集之间的关系
Experiment
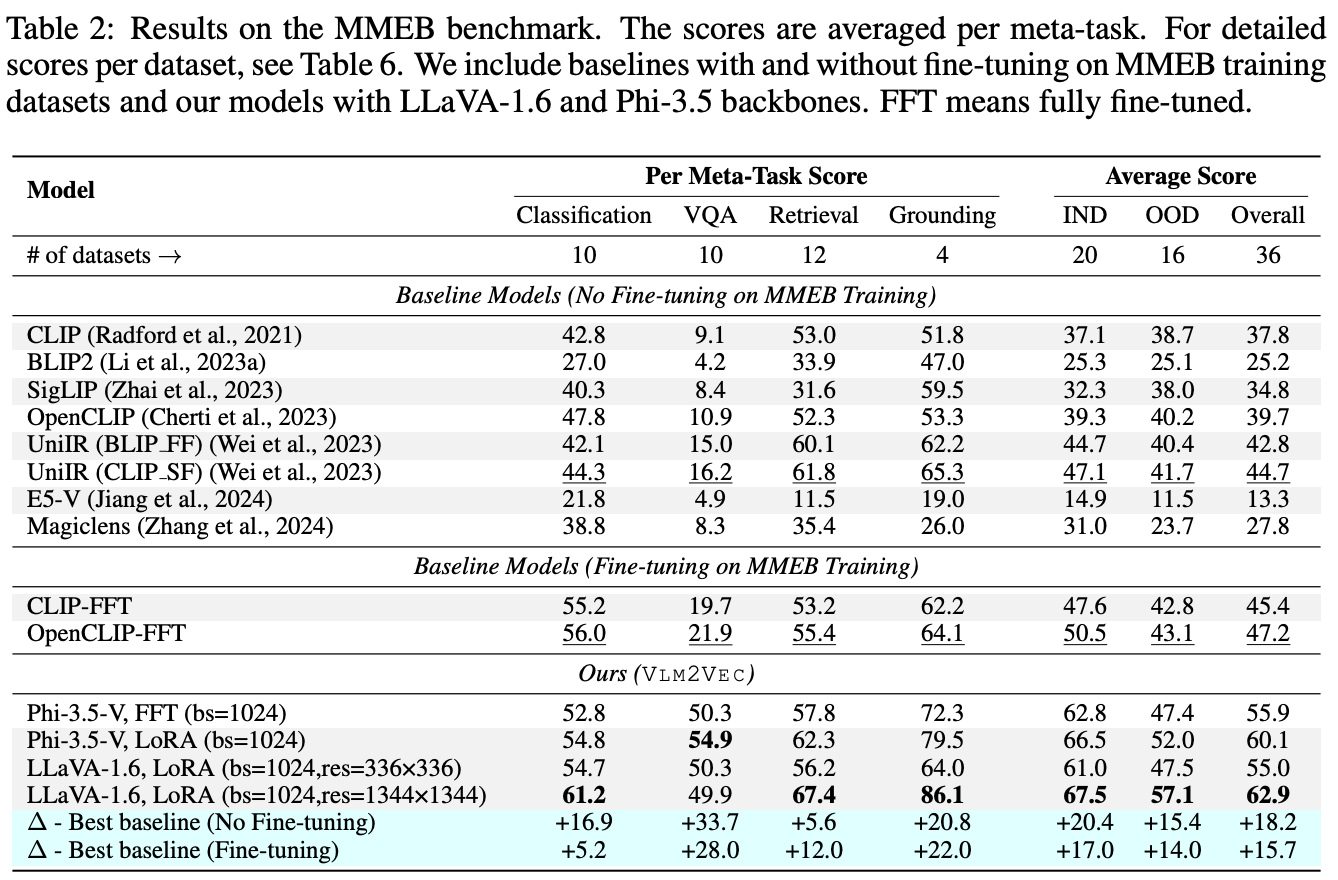
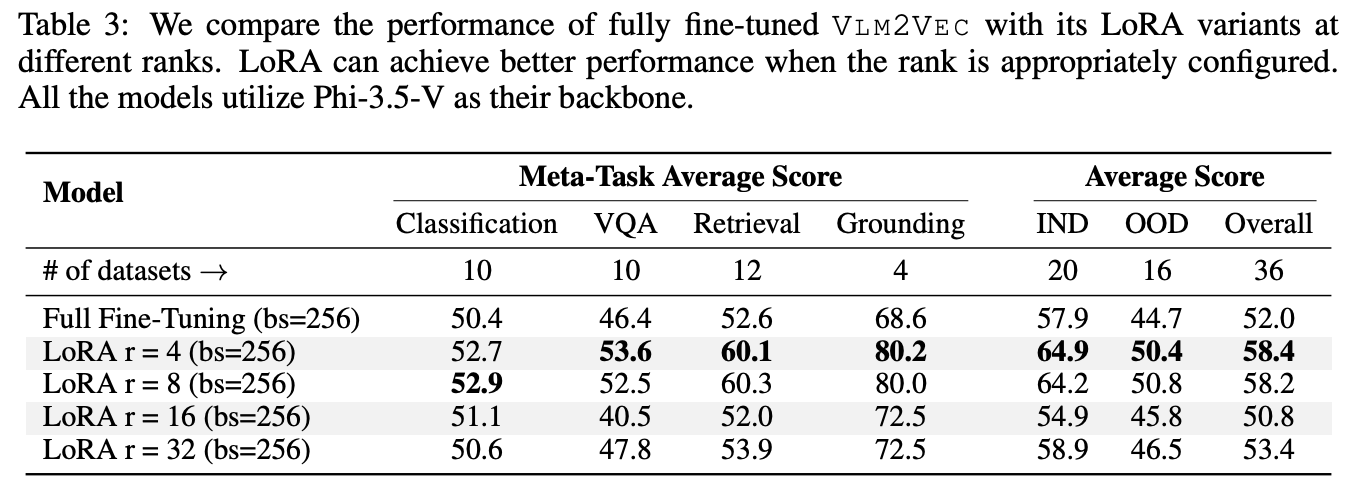
LoRA微调结果反而比全模型更好,一种高能性是LoRA参数量更少,不容易在Finetune数据集上过拟合。
Q&A
Q:VLM2Vec与普通VLM有什么区别?难道仅仅是会将embedding存出来?
- 指令跟随能力:VLM2Vec能够理解和执行自然语言指令,根据不同的任务要求生成相应的嵌入表示,这是普通VLM不具备的专业化能力。
- 对比学习优化:通过大规模的对比学习训练,VLM2Vec的嵌入空间被优化用于相似性计算和检索任务,而普通VLM的输出空间主要针对生成任务优化。
Q:与CLIP/BLIP这类多模态模型的区别?

Q:query与target embedding为什么是从VLM的最后一层的最后一个token?
- 信息完整性:最后一个token在Transformer架构中聚合了前面所有token的信息
- 表示一致性:确保不同模态的输入都能转化为统一格式的向量表示
Q:为什么负样本存在一定噪声,加大Batch就可以缓解?
- 负样本存在噪声的原因:标注错误、语义模糊
- 为什么大BatchSize能够缓解:更大的batch提供更多随机负样本,降低个别噪声样本的影响
Q:阅读3.2章节,说明如何通过GradCache增大BatchSize?与梯度累积有什么区别?
GradCache
- 梯度累积:解决的是前向传播和反向传播过程中的内存瓶颈。它通过“化整为零”的策略,将一个大批次分割成多个小批次顺序处理,并累积梯度,最终进行一次参数更新,从而模拟大批次训练的效果。
- GradCache:解决的是对比学习任务本身的内存瓶颈。在对比学习中,计算损失需要在一个批次内进行大量的样本间交互(如计算所有样本对的相似度)。GradCache通过“解耦计算依赖”的策略,将嵌入表示的计算与对比损失的计算分离,从而真正实现超大批次的对比学习。
总结与思考
方法相对而言比较容易想到,建立了比较完善的Benchmark全面证明方法的有效性。
相关链接
https://zhuanlan.zhihu.com/p/1918974886321305223