实验2:深度学习基础
| 姓名和学号? | |
|---|---|
| 本实验属于哪门课程? | 中国海洋大学25秋《软件工程原理与实践》 |
| 实验名称? | 实验2:深度学习基础 |
| 博客链接: | 选做 |
实验内容
代码练习
pytorch练习
练习过程和结果如下:
定义数据

定义操作
其中我发现 v = torch.arange(1, 5) $v$默认创建为整数类型,导致$m$与$v$不能做向量积,所以我将$v$转换成浮点型再做运算。
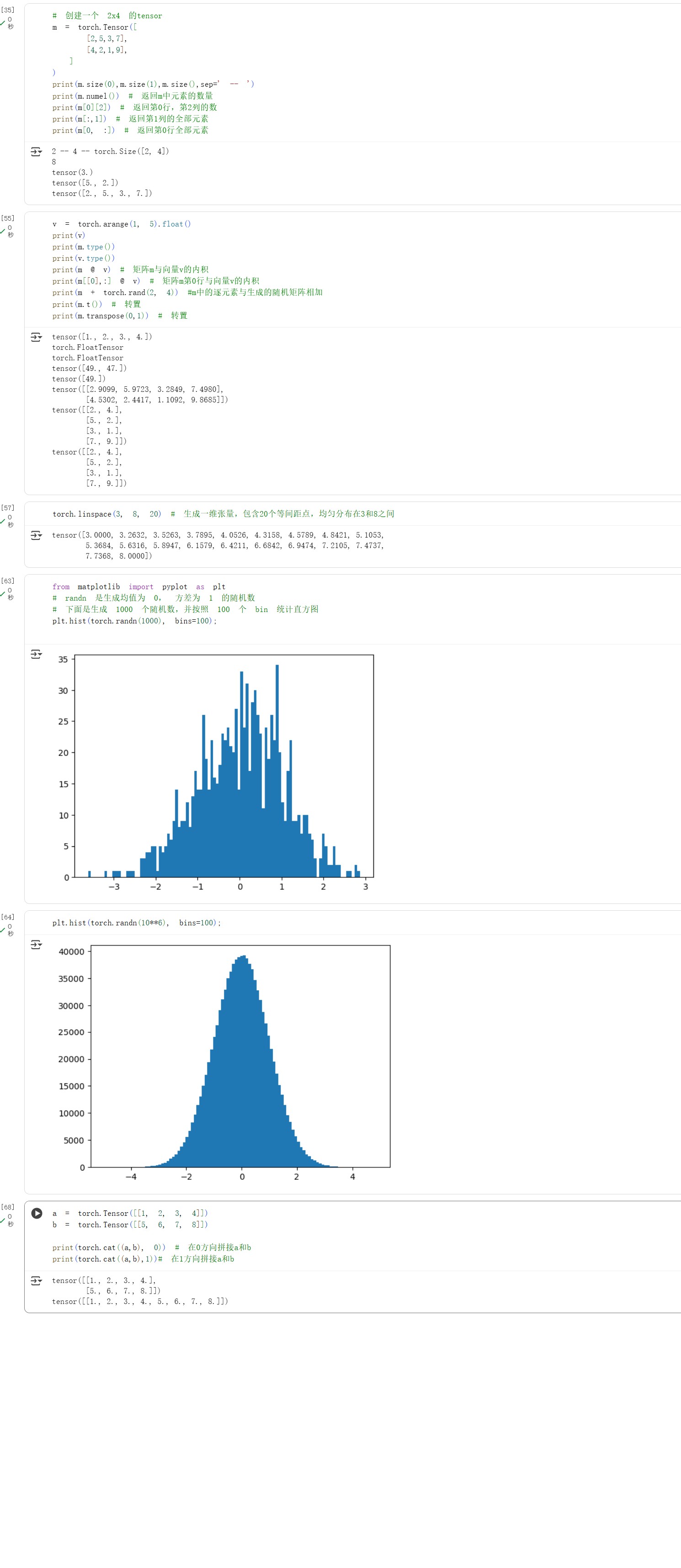
螺旋数据分类
使用线性模型和两层神经网络,在相同的学习率($0.001$)和 L2 正则化参数下,分别用 SGD 和 Adam 优化器进行分类,都训练 1000 次。
基础数据绘制
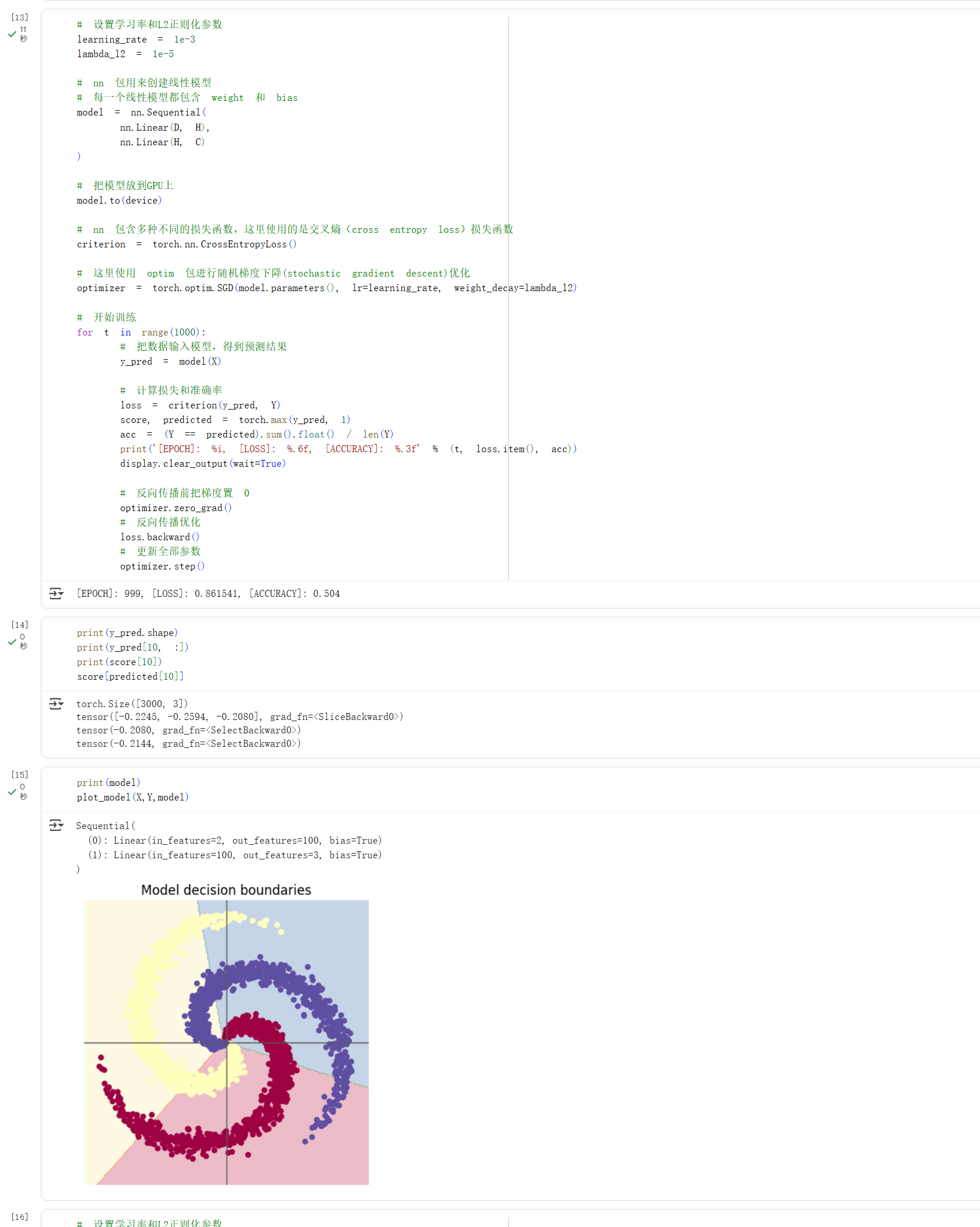
构造线性模型分类
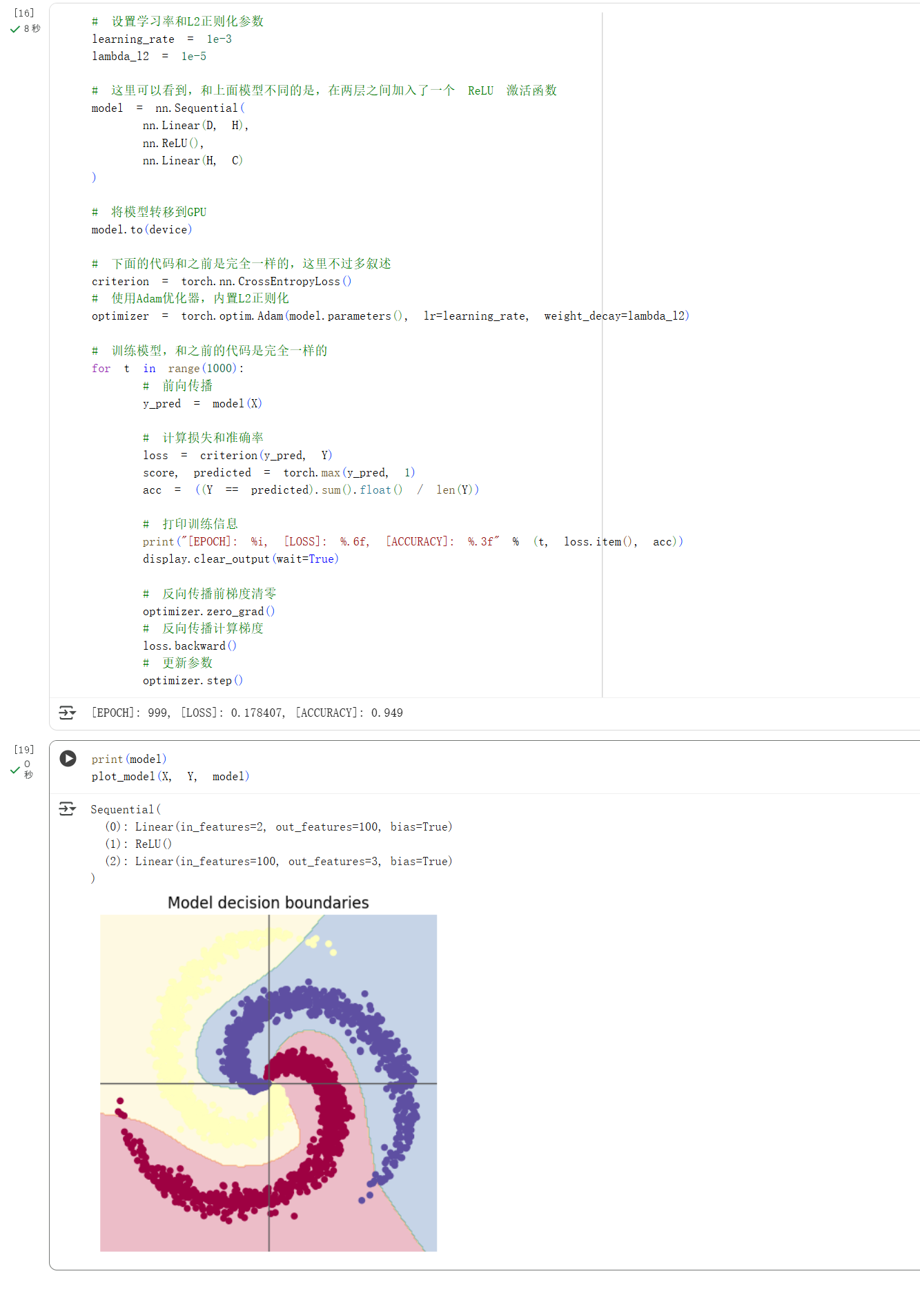
构造两层神经网络分类
问题总结与体会
【第⼆部分:问题总结】思考下⾯的问题
1、AlexNet有哪些特点?为什么可以比LeNet取得更好的性能?
- AlexNet的特点:
- 它具有更深的网络结构和足够大的数据集
- 它将更深的网络结构和足够大的数据集相结合
- 它使用ReLU激活函数,有效的缓解了梯度消失问题
- 为什么可以比LeNet取得更好的性能?
- ALexNet有八层(5卷积 + 3全连接),而LeNet有五层(2卷积 + 2全连接);更深的层次就意味着网络可以学习到更复杂的层次。所以AlexNet性能更好。
- AlexNet 是第一个成功大规模使用 ReLU 作为激活函数的 CNN。ReLU 只是一个简单的
max(0, x)操作,比涉及指数运算的 Sigmoid/Tanh 快得多。所以AlexNet的计算更高效。 - AlexNet使用Dropout正则化,来防止模型过拟合。而LeNet的正则化技术简单,不如AlexNet的正则化技术。
- AlexNet的数据集规模大于LeNet。
2、激活函数有哪些作⽤?
答:
激活函数是神经网络的基石,没有激活函数,神经网络就失去了大部分的能力。
- 引入非线性的特征:激活函数一般是非线性的,使整个神经网络具有非线性的拟合能力。如果没有激活函数,无论网络多深,它也只是一个线性模型。
- 激活函数可以决定神经元的激活状态:激活函数决定了神经元接收到多强的信号才能被激活或触发。
- 激活函数的梯度特性直接关系到反向传播算法的效果,也就是模型是否可以有效学习。
3、梯度消失现象是什么?
答:
首先说一下梯度下降的含义:参数沿负梯度方向更新可以使函数值下降。
梯度消失现象:
- 在深层神经网络中,因为在反向传播算法中,从输出层向输入层方向传播的梯度会随着层数的增加快速降低,最终趋近于零;导致网络前面的层的权重参数得不到有效的更新,使网络早期层无法有效从数据中学习。所以增加深度会造成梯度消失,误差无法传播。同时多层神经网络会陷入局部极值,难以训练。
- 原理:因为计算第$i$层权重的梯度时,需要将损失函数对网络输出的梯度,一层一层的乘以中间层的偏导数;而连乘中每一项都包含激活函数的导数,在梯度小时问题中,罪魁祸首就是这些导数值小于1,导致结果是一个趋于零的数字,也就是梯度消失。
4、神经网络是更宽好还是更深好?
答: 更深比较好。
-
当神经元总数一定时,增加网络的深度比增加宽度带来更强的网络表示能力,也就是可以产生更多的线性区域。
-
因为深度和宽度对函数复杂度的贡献是不同的,深度的贡献是指数增长的,而宽度的贡献是线性的。
5、为什么要使⽤Softmax?
- softmax可以通过指数化和归一化,将抽象的值转化为一个真实的概率分布。
- softmax可以方法差距,优化训练,为模型的训练过程提供了清晰强大的优化信号。
- 为梯度下降算法提供了明确的优化方向,让训练更高效、稳定。
6、SGD 和 Adam 哪个更有效?
答:
螺旋数据分类这一实验中,我们发现在学习率为$0.001$和L2正则化参数的情况下,SGD 模型的准确率为 50.4%,而 Adam 模型的准确率为 94.9%。在螺旋数据分类这个任务中,我们发现Adam明显优于SGD。
之后通过查阅资料我发现在追求极致性能的场景下,SGD可以帮你突破性能瓶颈,达到比Adam更高的精度。所以没有绝对的最优,只有更合适的选择。
体会与感悟
过程中遇到的问题
在pytorch练习中,我发现 v = torch.arange(1, 5) $v$默认创建为整数类型,而$m$是float类型,所以$m$和$v$不能做向量积。报错后通过询问AI得以改正。
体会
在本次实验中,我对深度学习基础原理的理解深化了,尤其凸显了模型架构设计的关键性。在螺旋数据集分类任务中,单纯的线性模型表达能力有限,最终准确率仅为50.4%,与随机猜测无异;而通过引入带有非线性激活函数的两层神经网络,模型性能实现了飞跃,准确率显著提升至94.9%。这一对比直观地揭示了激活函数为模型赋予非线性决策能力的核心价值。本次实验也让我关注到优化器选择对训练的影响,Adam的表现明显好于SGD。