导读
《Federated Machine Learning: Concept and Applications》
《A Comprehensive Survey of Privacy-preserving Federated Learning》
本文主要对上面两篇联邦学习(FL)综述文章进行了概括总结。
1、FL概念与分类
FL的定义
定义:联邦学习允许多个客户端在不交换原始数据的情况下协作训练全局模型,其目标是控制模型精度损失在可接受范围内,以实现数据隐私保护与模型性能的平衡。
δ-Accuracy:FL在分布式节点协作得到的模型与传统数据集合上训练的模型精度的差值在δ以内,则说明该FL具有δ-精度损失。
有效性:存在至少一个客户端满足联邦学习协作完成的模型所得到的精度要比这个客户端在本地训练的模型精度要高。
FL的训练过程
FL系统两个主要角色:客户端、服务器。
训练过程:
Step1.服务器初始化模型、权重,分配任务,激活客户端。
Step2.在客户端进行本地模型训练和更新。客户端接收全局模型信息并使用本地数据集更新本地模型参数,完成训练后将本地模型参数发送到服务器融合。
Step3.服务器全局模型融合和更新。服务器首先聚合所选客户端发送的信息,然后将更新的信息发送回客户端,最终目标是获得全局最优模型参数。
满足终止条件(到达迭代次数或者准确度大于阈值),服务器终止训练,聚合更新并将全局模型分发给所有客户端。
伪代码分析
服务器从n个客户端中随机选择m个客户端组成集合进行训练,根据选中的m个客户端的本地模型返回的权重按本地数据量加权平均聚合,一共进行R轮。
被选中的客户端将训练后的模型参数和本地数据量返回给服务器。

FL的分类
水平联邦学习:不同参与者的数据在特征空间上相似,但在样本空间上不同。类比:不同银行的用户特征相似(年龄、收入),但用户群体不同。通信架构:客户端-服务器(c-s)、点对点(p2p)。
水平联邦可以划分为client-server和peer-to-peer架构。客户端-服务器体系结构使用集中计算,因为有一个中央服务器用于编排整个训练过程。点对点架构使用去中心化计算,因为没有中心服务器,每轮训练中都会随机选择一个客户端作为服务器。
k个具有相同数据结构的参与者在参数或云服务器的帮助下协作学习机器学习模型。过程分四步:
Step 1: 参与者在本地计算训练梯度,使用加密,差分隐私或秘密共享技术掩盖梯度的选择,并将掩蔽的结果发送到服务器;
Step 2: 服务器执行安全聚合(在不了解有关任何参与的信息情况下);
Step 3: 服务器将汇总结果发回给参与者;
Step 4: 参与者使用解密的梯度更新各自的模型。
peer-to-peer架构有两种通信协议: 1、循环传输。客户端组织成一个循环链,依照链的顺序发送更新模型,满足终止条件后停止训练。 2、随机传输。在这个协议中,客户随机挑选另一个客户并发送模型信息,后者收到信息后使用本地数据集更新收到的信息,然后同样随机发送给别的客户机。直到满足停止条件后停止。
垂直联邦学习:不同参与者的数据在样本空间上相似,但在特征空间上不同。类比:同一地区的银行和电商,用户群相同,但特征不同。通信架构:有/无第三方协调器。
有第三方:C1和C2不直接交换敏感信息,通过C3中转。计算和通信的负担部分转移给了C3。安全性较高,但存在单点故障/信任风险。如果C3被攻破或与某一方合谋,隐私可能泄露。
无第三方:C1和C2直接进行多轮安全通信。双方需要执行更多的加密、解密和交互步骤。安全性更高。消除了对第三方的依赖,隐私保护完全由密码学协议(同态加密、秘密共享等)保证。
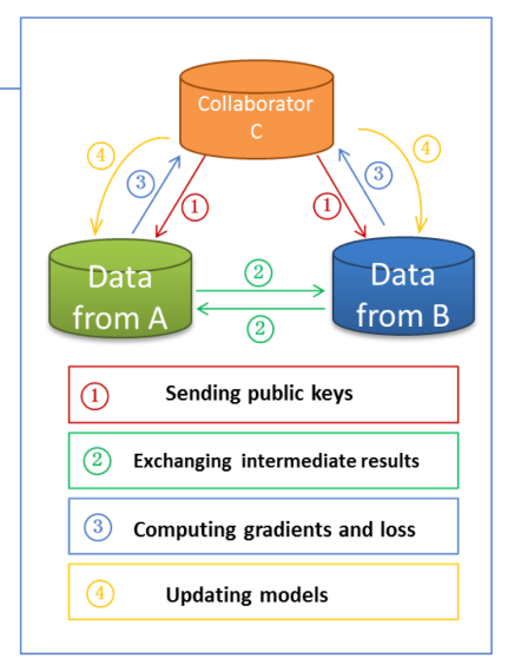
联邦迁移学习:样本和特征空间都很少重叠。可分为3类:基于实例、基于特征、基于参数的FTL。
基于实例:假设源域中数据集中的一些标记实例可以重新加权并应用于目标域中的训练。(水平样本重新加权,垂直提取有好特征的样本)
基于特征:最小化域差异学习良好的特征表示,从而可以有效地编码从源域到目标域的转换知识。(水平最小化数据集差异,垂直最小化特征差异)
基于参数:利用源域和目标域模型之间共享的参数或超参数的先验分布来有效地编码转换知识。(水平训练全局模型,根据不同客户端微调。垂直训练对齐标签样本预测模型来预测未对齐标签样本)
2、相关概念与工作
分布式机器学习:分为数据并行、模型并行。数据并行:数据分区,本地训练模型。模型并行:模型划分,在本地用全部数据集进行训练。
移动边缘计算:通过更靠近边缘用户的地方执行计算任务减少网络的拥塞。因此,它可以为客户快速部署新服务或应用程序。
分割计算:无需与中央服务器交换数据集。每个用户将一个模型训练切割层。然后将中间参数传输到中央服务器,完成剩余层的训练。
隐私保护的机器学习:参数服务器将数据存储在分布式工作节点上,通过中央调度节点分配数据和计算资源,从而更有效地训练模型。
联邦数据库系统:联邦数据库系统在彼此交互的过程中不包含任何隐私保护机制
3、通用隐私保护机制综述
隐私保护的三种类型的通用隐私保护机制:加密技术、扰动技术和匿名技术
加密技术
同态加密:一种加密方法,允许在加密后的数据上直接进行计算,而无需先解密数据。分为部分同态加密(只支持+ or *)和完全同态加密(同时支持+ and *)。
秘密共享:形式为(t,n),即对于n个参与方,至少有t个参与方共享才能够重新重构秘钥。 原理是将秘密分成若干份,交给不同的人去保管,设定管理秘密的一定数量的人贡献出自己持有的秘密,就可以恢复秘密。
多方安全计算:假设存在 n 个参与方 P1, P2 ... Pn,每个参与方都有一个私有输入数据 Xi,所有参与方共同计算某个函数 f(x1,x2 ... xn),且要求在计算结束时,每个参与方 Pi 只能得到私有输入数据 Xi 的输出,而不能获取其他参与方的输入信息及输出结果信息。
扰动技术
差分隐私:基于概率统计模型来量化数据集中实例的隐私信息泄露程度。分为全局差分隐私技术和局部差分隐私技术。全局有可信第三方,在查询结果上加噪声。局部无可信第三方,每个用户在本地加噪声。
加性扰动:加法:通过添加来自特定分布(例如均匀分布或高斯分布)的随机噪声来保护原始数据的隐私。
乘性扰动:乘法:使用来自特定分布的噪声与原始数据相乘,将原始数据点转换到某个空间。与加性扰动相比,乘性扰动更有效,因为从乘性扰动的扰动数据重建原始数据更困难。
匿名技术
保持已发布数据的实用性的同时,通过删除可识别信息来实现基于组的匿名化。有三种广泛可用的匿名技术:k-匿名,l-多样性,t-亲密度。这些技术主要是为了结构化数据开发的,包括主要的三个属性:ID,敏感属性,非敏感属性。
隐私保护指标
1、度量数据集隐私损失的隐私指标。(隐私损失了多少)2、度量受保护数据的效用指标。(数据还有多有用)
4、PPFL分类与综述
5w场景分类法
WHO:内部参与者(参与客户端和中央服务器)和外部参与者(模型消费者和窃听者)。 风险从高到低依次为:恶意服务器 > 恶意模型使用者 > 恶意客户机 > 窃听者。
WHAT:被动攻击:被动黑盒攻击和被动白盒攻击。黑盒只能查询结果,而不能访问模型参数或中间训练更新。白盒可以访问中间训练更新、模型参数和查询结果。 主动攻击旨在主动影响训练过程,提取训练数据集的敏感信息。 影响:主动攻击>被动白盒攻击>被动黑盒攻击。
WHEN:训练阶段、推理阶段。 训练阶段风险主要在模型更新时。 推理阶段风险与最终模型有关。1、基于模型参数的攻击。利用模型参数进行推理攻击,提取参与者训练数据集的敏感信息。2、基于模型查询的攻击。隐私泄露主要是由推理攻击引起的。
WHERE:权重更新、梯度更新和最终模型。训练过程:梯度/权重泄露风险 传输中的梯度或权重更新源于私有数据,可能被恶意参与者或窃听者获取,用于推断原始信息。 模型聚合:权重分析风险 恶意服务器或参与者可通过分析聚合权重,并比较不同轮次的模型差异,来实施更复杂的属性推断攻击。 模型发布:最终模型泄露风险(最严重)发布的最终模型编码了全部训练数据的特征。
WHY:隐私攻击的目的通常是推断训练数据集的敏感信息推理攻击可以分为四类: 1、类代表的推理:生成代表样本,这些代表样本不是训练数据集的真实数据实例,但可以用来研究训练数据集的敏感信息;2、成员关系的推断:确定一个数据样本是否已被用于模型训练;3、训练数据的属性推断:对训练数据集的属性信息进行推断;4、推理训练样本和标签:重建原始训练数据样本和相应的标签.
PPFL方法分为四类:基于加密的、基于扰动的、基于匿名的、混合的PPFL方法
基于加密的PPFL:主要利用加密技术进行隐私保护,可分为三类: 基于同态加密、基于秘密共享、基于安全多方计算的PPFL方法。基于加密的PPFL方法精度无损且安全性高,但计算和通信开销巨大,适用于对隐私要求极高且资源充足的应用场景。
基于扰动的PPFL:有四种:全局差分隐私、局部差分隐私、加性扰动、乘性扰动。基于扰动的PPFL实现简单,提供可证明的隐私保证,但噪声会降低数据效用,需根据实际需求调整噪声强度。
基于匿名的PPFL:基于匿名的PPFL能保持较好的数据效用,主要针对结构化数据,隐私保证弱于差分隐私,适合对隐私要求适中的场景。
混合PPFL的优势:混合PPFL结合多种隐私技术,如先用SMC安全聚合再施加少量DP噪声,旨在平衡隐私、效用和效率,是未来研究的重要方向。
5、应用与挑战
应用
智能医疗:目标:提升疾病诊断等模型的性能。场景:敏感医疗数据分散在各医院,难以集中。联邦学习允许各医院本地训练模型,仅共享模型更新。结合迁移学习 弥补数据标签不足的问题,能充分利用分散数据提升模型性能,推动医疗AI发展。
智能零售:目标:提供个性化推荐。场景:用户的购买力(银行)、喜好(社交网络)、产品特征(电商)数据分散在三方。联邦学习能在不导出数据的情况下联合三方特征,构建精准推荐模型,实现互利共赢。
金融风控:目标:检测“多头借贷”等风险。场景:银行A和银行B希望找出共同的借款用户,但不愿暴露各自的全部客户名单。利用联邦学习的加密技术,可以安全地找出重合用户名单,而不会泄露非重合用户的隐私。
挑战:一些潜在的开放研究问题和方向
1、平衡难题:核心是在数据隐私和模型效用/效率之间找到最佳平衡。添加隐私保护(加密或噪声)通常会降低精度或增加开销。
2、保护训练数据:需有效保护传输的梯度/权重,防止其泄露原始数据信息。加密法安全但慢,扰动法快速但影响精度,需优化或结合使用。
3、保护最终模型:需防御从发布的最终模型或API中发起的推理攻击。解决思路包括加密模型、或提供个性化模型而非全局模型。
4、消除数据记忆:需防止模型“记住”训练数据中的隐私信息。解决方法包括对数据或训练过程进行匿名化处理。
5、优化与新场景:需优化防御机制效率,并研究在无中心服务器等新架构下的隐私问题。
6、融合技术:结合多种技术(如差分隐私+安全多方计算)的混合框架是未来主要方向。
相关链接:【阅读笔记】PPFL全面综述文章: A Comprehensive Survey of Privacy-preserving Federated Learning-CSDN博客
综述:《联邦学习:概念与应用》 - 知乎