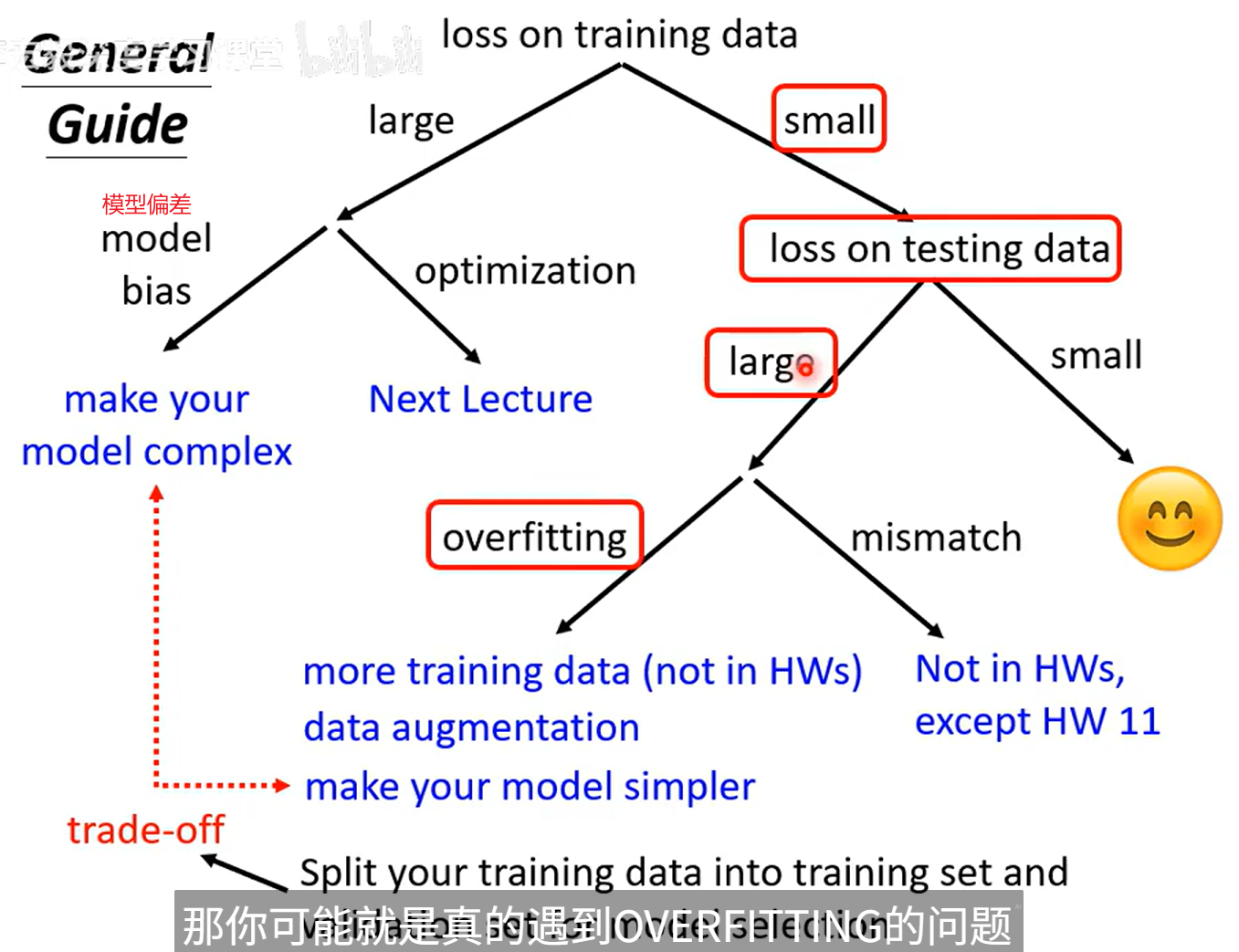
Model Bias(模型偏差)
Bias(偏差) 是机器学习里衡量“模型预测与真实值平均偏离程度”的指标。
它反映模型对目标函数的逼近能力。
Optimization(优化)
在一堆可能的方案中,找到“最好”的那个。
在机器学习里,它的意思更具体:
通过调整模型参数,让损失函数(Loss)最小。
Overfitting(过拟合)
✅ 定义:
模型在训练集上表现很好,但在新数据(测试集)上表现很差。
通俗讲:
模型记住了训练数据,而不是学会了规律。
🔍 现象:
| 训练误差 | 测试误差 | 结论 |
|---|---|---|
| 很低 | 很高 | 过拟合 |
📉 例子:
神经网络有很多层、参数巨大,训练集上准确率 99%,
但一换数据就崩掉,比如只剩 70%。
说明模型拟合了噪声和细节,没学到真正的模式。
🧩 常见原因:
- 模型太复杂(参数太多)
- 训练数据太少
- 特征中噪声多
- 训练太久(loss 继续下降但 val loss 上升)
- 没正则化(没有限制模型自由度)
🛠 解决方法:
| 方法 | 说明 |
|---|---|
| 增加数据量 | 最直接有效 |
| 正则化 | L1/L2、Dropout、Early Stopping |
| 数据增强 | 对图像/文本轻微扰动 |
| 简化模型结构 | 减少层数或参数量 |
| 交叉验证 | 提前发现过拟合趋势 |
⚙Function Mismatch
(函数不匹配 / 模型不匹配)
✅ 定义:
模型假设的形式(函数)不符合真实规律,导致模型无法表示真实关系。
通俗讲:
模型太“笨”,不管怎么学都学不会真实模式。
📉 例子:
真实关系是:
$y = 3x^2 + 2x + 1$。
但你非要用线性模型:
$y^=ax+b$
即使你训练一辈子,它也学不到平方项,误差永远大。
这就是 function mismatch(函数不匹配),
也称为 model bias(模型偏差) 或 underfitting(欠拟合)。
🧩 常见原因:
- 模型形式太简单;
- 特征表达能力不够;
- 先验假设错误(比如强行假设线性);
- 使用了不合适的损失函数或激活函数。
🛠 解决方法:
| 方法 | 说明 |
|---|---|
| 换更复杂模型 | 如从线性回归换成决策树、神经网络 |
| 特征工程 | 加入非线性项、交叉项 |
| 使用更灵活的假设空间 | 比如 kernel 方法或多层网络 |
🔄区别与联系
| 项目 | Overfitting | Function Mismatch |
|---|---|---|
| 中文 | 过拟合 | 函数不匹配(欠拟合/高偏差) |
| 误差类型 | 高方差(Variance) | 高偏差(Bias) |
| 模型表现 | 训练好、测试差 | 训练差、测试也差 |
| 原因 | 模型太复杂 | 模型太简单 |
| 解决 | 降复杂度 / 增正则 | 提升模型能力 |
🎯一句话总结:
Function mismatch 是“学不会”,Overfitting 是“学太多”。