理解大语言模型中的 Token
对于大型语言模型(LLM, Large Language Mode)来说,token(词元)是它处理文本的基本单位。当你向 ChatGPT 输入 “Hello world!” 时,它并不是把两个单词与标点符号看作一个整体,而可能被分成四个 token:["Hello", " world", "!", "\n"]。
token 在 LLM 世界中主宰一切:你向模型发送 token,以 token 为单位付费,模型阅读、理解、处理的也是 token。

1. 什么是 Token(词元)?
Token 是 LLM 处理文本时的最小单元,也被称为 “词元” 。
但 token 并不总是等同于一个词。根据不同的分词方式,一个 token 可以是:
- 一个字符
- 一个子词(subword,指单词的一部分)
- 一个完整单词
- 标点符号
- 特殊符号
- 空白字符
举例来说,根据不同不同的分词方法,句子 “I love machine learning!” 可能被分成:["I", "love", "machine", "learning", "!"],也可能被分成:["I", " love", " machine", " learn", "ing", "!"]
2. 为什么分词很重要?
分词在以下几个方面起着关键作用:
- 词表管理
LLM 的词表是有限的(通常在 3 万到 10 万 token 之间)。将每一个可能的单词都列进词表几乎不可能,因此分词方法将罕见或复杂的词拆成可重用的子词单元(例如 “extraordinary” → “extra” + “ordinary”),避免每个单词都必须对应一个 token。 - 处理未知词汇
好的分词方法可以把模型没见过的新词拆成已知的子词,从而让模型依然能理解这个词的结构与含义。比如,如果模型没见过 “biocatalyst” 这个词,它可能拆成 “bio” + “catalyst” 两个子词来理解。 - 计算效率
文本序列的长度直接影响计算开销。一个好的分词方法可以减少表示同一篇文章所需的 token 数量,从而节约计算资源。 - 模型性能
分词方式影响模型对文本结构、语义关系的捕捉能力。若分词不合理,可能破坏词与词之间的关联性或扭曲意义。
3. LLM 如何读取 token
在文本被分词后,接下来要把这些符号型的 token 转为数字形式,以便神经网络处理。流程如下:
- 每个 token 在词表中对应一个唯一的整数 ID(称为 词元 ID)。例如:
“Hello” → 15496
“ world” → 995 - 这些 token ID 接着被映射为高维的实数向量,也就是 embeddings(词嵌入向量)。通常这些向量的维度可能是 512、1024 或更高。这些嵌入向量能够捕捉 token 之间的语义关系:相似的 token 在向量空间中距离更近。
![embeddings_cn]()
- 模型通过这些向量在高维空间中做运算、推理、生成输出。模型学习和理解的,其实是高维向量之间的关系,而不是字面上的 token 字符。
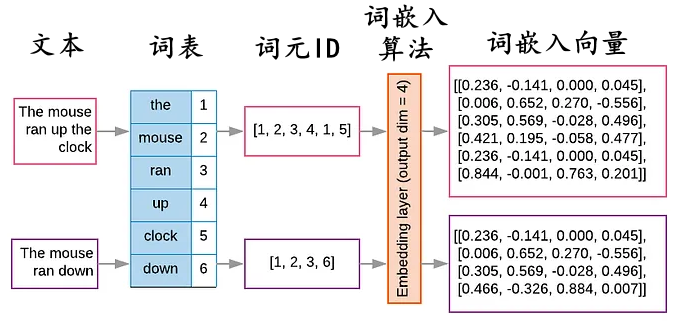
通过这个过程,模型就能知道在向量空间里 “king” 与 “queen” 是有联系的,“run” 与 “running” 之间也互有关联。
4. 常见的分词方法
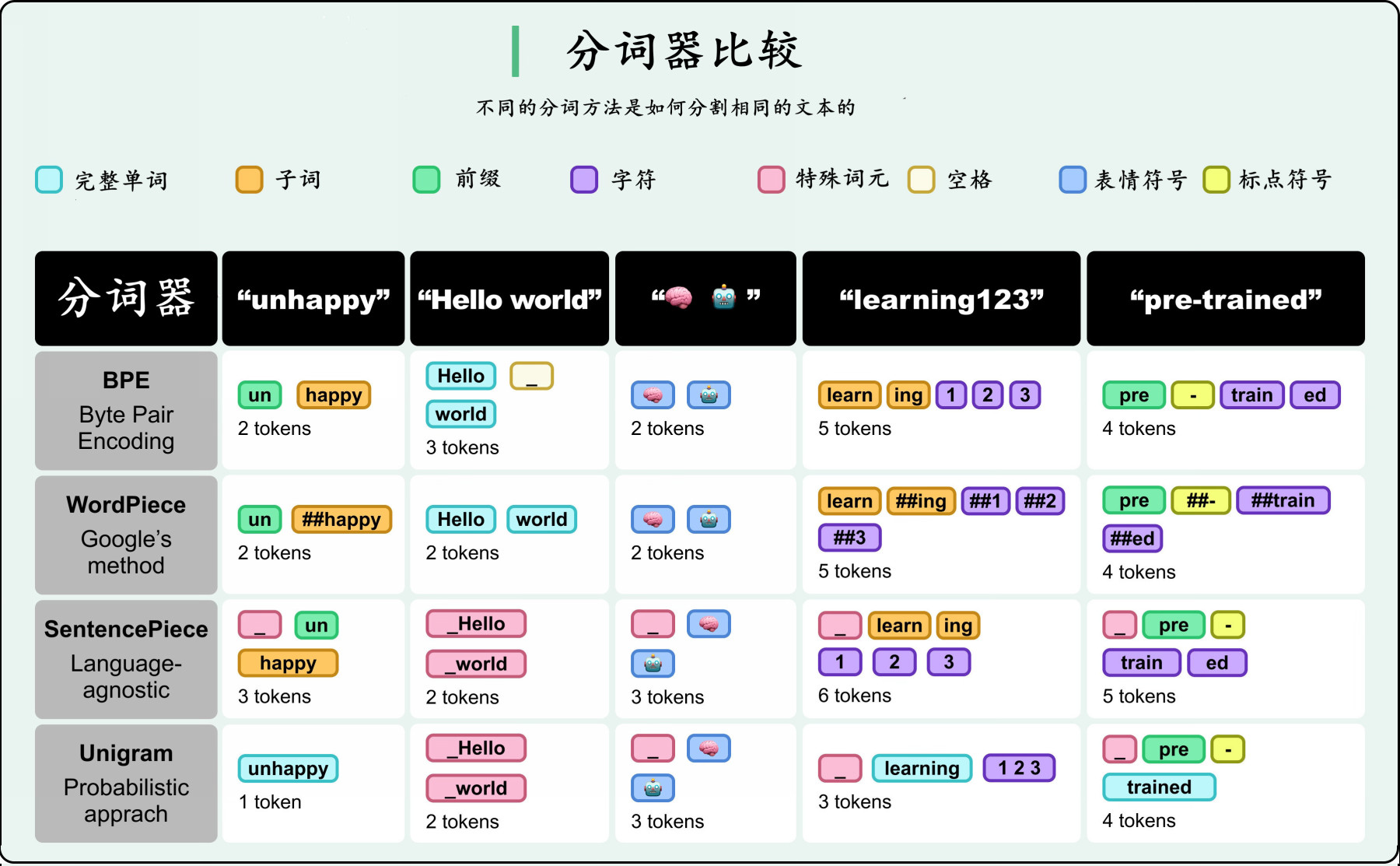
(1) BPE(Byte Pair Encoding)
BPE 是目前很多 LLM 使用的分词方式(如 GPT-2、GPT-3、GPT-4)。
工作原理:
- 初始词表,以单个字符为单位
- 统计训练语料中相邻字符对的出现频率
- 反复合并频率最高的字符对,形成新的 token
- 直至达到目标词表大小
BPE 生成一个灵活的子词词表,既可以表示常见词,也能拆分稀有词;有助于模型处理拼写错误、复合词和未知术语。
它的一个变种是 byte-level BPE,可以直接在 UTF-8 字节级别进行操作,这样即使遇到训练中未出现的字符也能得到表示,不需要设置 “unknown token”。

(2) WordPiece
WordPiece 是 Google 提出的分词方法,常见于 BERT、DistilBERT、Electra 等模型。
工作原理:
- 同样从单个字符级别起步
- 但选取合并对时不仅看频率,还考虑训练语料的似然性
- 使用前缀符号(如 “##”)来标识一个不在单词头部的子词。例如 “unhappy” 可能被拆为
["un", "##happy"]。这使得模型在拆分和重建单词时都能保持结构和语义的正确性。
(3) SentencePiece
SentencePiece 是 Google 的一个工具包,不依赖特定语言的预处理,可以直接对原始文本进行操作(包括空格符号)。
工作原理:
- 将输入文本视为原始的 Unicode 字符流,包括空格
- 空格被保留为一个特殊符号(通常是「 」)
- 可以实现 BPE 或 Unigram 语言模型算法
比如 “Hello world” 可能被分成 ["▁Hello", "▁world"],其中 “▁” 表示空格边界。SentencePiece 消除了对特定语言预分词的需求,对那些没有明确单词边界的语言(如日语、汉语)也能较好处理。
(4) Unigram
Unigram 常和 SentencePiece 一起使用,是一种概率性的方法。
工作原理:
- 从一个较大的子词候选集合开始
- 迭代移除那些对训练语料表示能力影响最小的子词
- 通过概率模型决定最终保留哪些子词
与 BPE 或 WordPiece 的合并方式不同,Unigram 是“减法式”的策略,这使得它能保留更广泛的分词选项,并在推理时具有更大的灵活性。
5. Token 与上下文窗口
LLM 有一个最大可处理的 token 数量上限,即上下文窗口(Context Window)。这个上限决定了以下方面:
- 输入长度:模型在生成回应前可以考虑多少文本。
- 输出长度:在一次补全中可以生成多少内容。
- 连贯性:在较长的对话或文档中,模型维持主题一致性的能力。
早期模型如 GPT-2 的上下文窗口约为 1,024 个 token;GPT-3 为 2,048 个 token。如今一些先进模型的上下文容量可达 100 万以上。
6. 关于分词你应当知道的事
Token 计数
理解 token 计数对于以下工作非常重要:
- 估算调用 LLM 接口的费用(通常按 token 计费)
- 保证对话在上下文窗口范围之内
- 设计更高效的提示词(prompt)
在英语上下文中,大致估算为:
- 1 token ≈ 4 个字符
- 1 token ≈ 0.75 个单词
- 100 token ≈ 75 个单词(大致一段话)
(注意:这个估算在其它语言或特定语境下可能偏差较大)
分词的怪异现象
- 非英语语言
很多 LLM 的分词器主要针对英语设计,因此对于其他语言(尤其是词汇结构差异较大的语言),其分词效率较低,常常一个词被拆成多个 token,导致上下文承载效率下降。 - 特殊字符
表情符号、罕见字符或特定格式可能占用多个 token,这可能扭曲语义或使 token 使用量急剧增加。例如,像「」这样的单个 emoji 表情符号可能会消耗多个 Token,具体取决于分词器。 - 数字与代码
数字或代码常被拆分成多个 token(如 “123.45” 可能被拆成 ["123", ".", "45"]),这对模型进行精确的数值推理或代码理解是种挑战。 - 代码生成与理解
编程语言讲究精确定界,若分词打断了操作符、变量名或缩进结构,模型在生成或理解代码时可能出错。良好对齐的代码分词可以提高模型在补全、格式化和错误检测方面的准确性。
7. “3.11 vs 3.9” 这个经典问题
LLM 常常在表面看起来简单的问题上出错,例如 “3.11 比 3.9 大吗?”。分词可以解释其原因:
在分词过程中,数字 “3.11” 被拆为[ “3”, “.”, “11”];而 “3.9” 被拆为 [“3”, “.”, “9”]。对 LLM 模型而言,它并不是在比较两个浮点数的大小,而是在对一串符号 token 做统计模式匹配,以预测接下来应该出现什么文本。
如今的模型有多种方式来回答这些问题:
- 随机猜测:由于 LLM 是非确定性的,有时会对这种问题给出正确答案,有时错。在这个问题引起重视以前,模型基本都是随机猜测。
- 训练中被“硬编码”校正:针对这类问题,通过专门的 SFT 训练数据进行微调再训练,让模型学会在这些经典小测试中给出正确答案。
- 辅助工具:如今很多模型可访问计算工具、数学推理模块等,来精确比较数字。
- 提示词设计与上下文:如果提示语或上下文强调这是一道数学题,模型可能更倾向正确答案。
8. 结论
- 分词(tokenization)是 LLM 将文本拆解为可处理单元、再映射为数字向量的基础机制。例如 “Hello world!” 最终可能被表示为一组 token,再被映射至高维向量,神经网络在此基础上进行模型训练、推理与生成。
- 主流分词方法包括 BPE、WordPiece 与 SentencePiece(包括 Unigram 变体)。
- 分词直接影响成本(按 token 计费)、上下文容量(模型能处理的 token 数量)以及模型性能(尤其是在多语言、数字、代码等场景下)。
通过理解分词方法及其局限性,可以帮助我们更好地设计提示词、估算使用成本、诊断模型行为问题,并深入理解现代 AI 的能力与局限。
机器人点评
Token 是各类关于大模型的文章经常出现的词,这里做了一个完整、清晰的介绍,希望能帮大家更好的理解和应用大语言模型。
因为核能领域存在很多专业词汇,尤其是各种不同堆型里的系统、设备、部件名称,这些称呼属于通用大语言模型里的“特殊单词”了。为了模型能够更好的理解核能 SSC 之间的关联关系,建议在核能 LLM 应用开发中,建立专用的词表。
