分布式学习(Distributed Learning)
分布式 DQN(GORILA)
深度强化学习的主要瓶颈是学习速度慢,主要由以下两点决定:
- 样本复杂度(sample complexity):获得令人满意的策略所需的状态转移数量;
- 在线交互限制(online interaction):智能体必须逐步与环境交互才能收集样本。
第二点在现实任务(如机器人)中尤为关键:物理机器人以实时速度运行,因此交互样本获取速率受限。
即使在仿真(如游戏、模拟器)中,环境的运行速度也可能比神经网络训练慢得多。
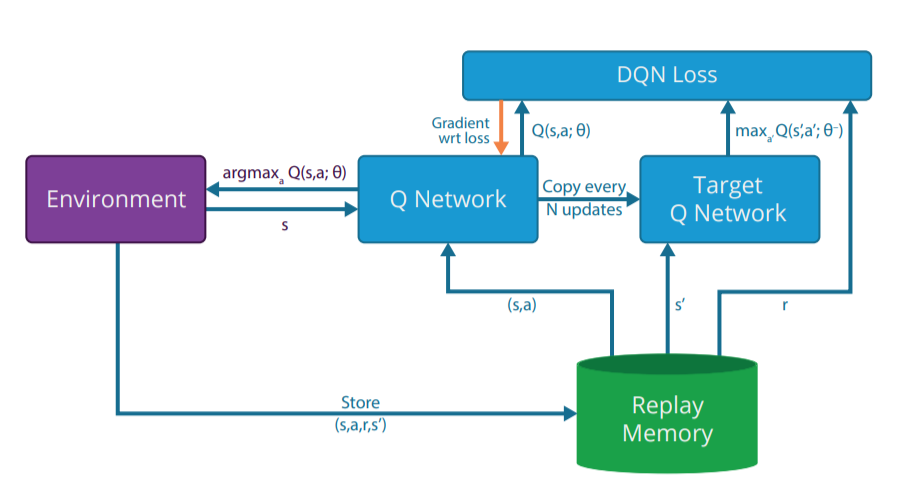
在常见的单机结构中:
- 神经网络(值网络与目标网络)运行在 GPU;
- 环境仿真与经验回放(ERM)运行在 CPU;
- 由于 CPU–GPU 间通信速度慢,GPU 经常处于空闲状态。
GORILA 框架
Google DeepMind 提出了 GORILA(General Reinforcement Learning Architecture) 框架 [@Nair2015],用于通过分布式执行者(actors)与学习者(learners)加速 DQN 训练。
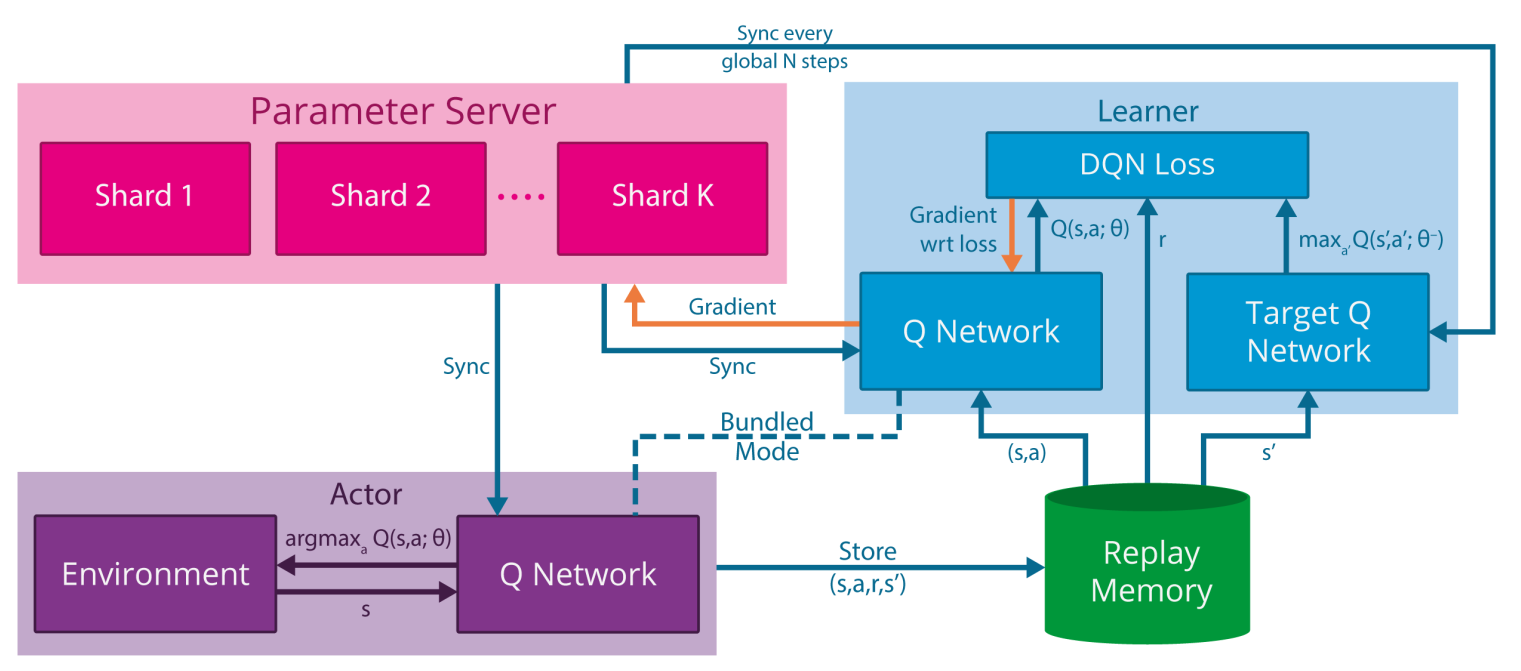
主要思想:
- 多个执行者各自运行环境副本,能并行收集 \(N\) 倍的样本;
- 各执行者将转移 \((s,a,r,s')\) 发送到经验回放池(可分布式存储);
- 多个学习者从回放池中采样小批量,计算损失梯度 \(\frac{\partial \mathcal{L}(\theta)}{\partial \theta}\);
- 参数服务器(主网络)汇总梯度并更新权重;
- 定期同步执行者与学习者的参数。
这种分布式架构可显著提高样本采集与训练速度,但也需要在执行者数量、学习者数量、同步频率之间权衡。
过多学习者可能降低稳定性,更新频率太低会导致梯度不准确。
GORILA 的最终性能与单 GPU DQN 相近,但训练时间从 12–14 天缩短至 2 天(2015 年的结果)。
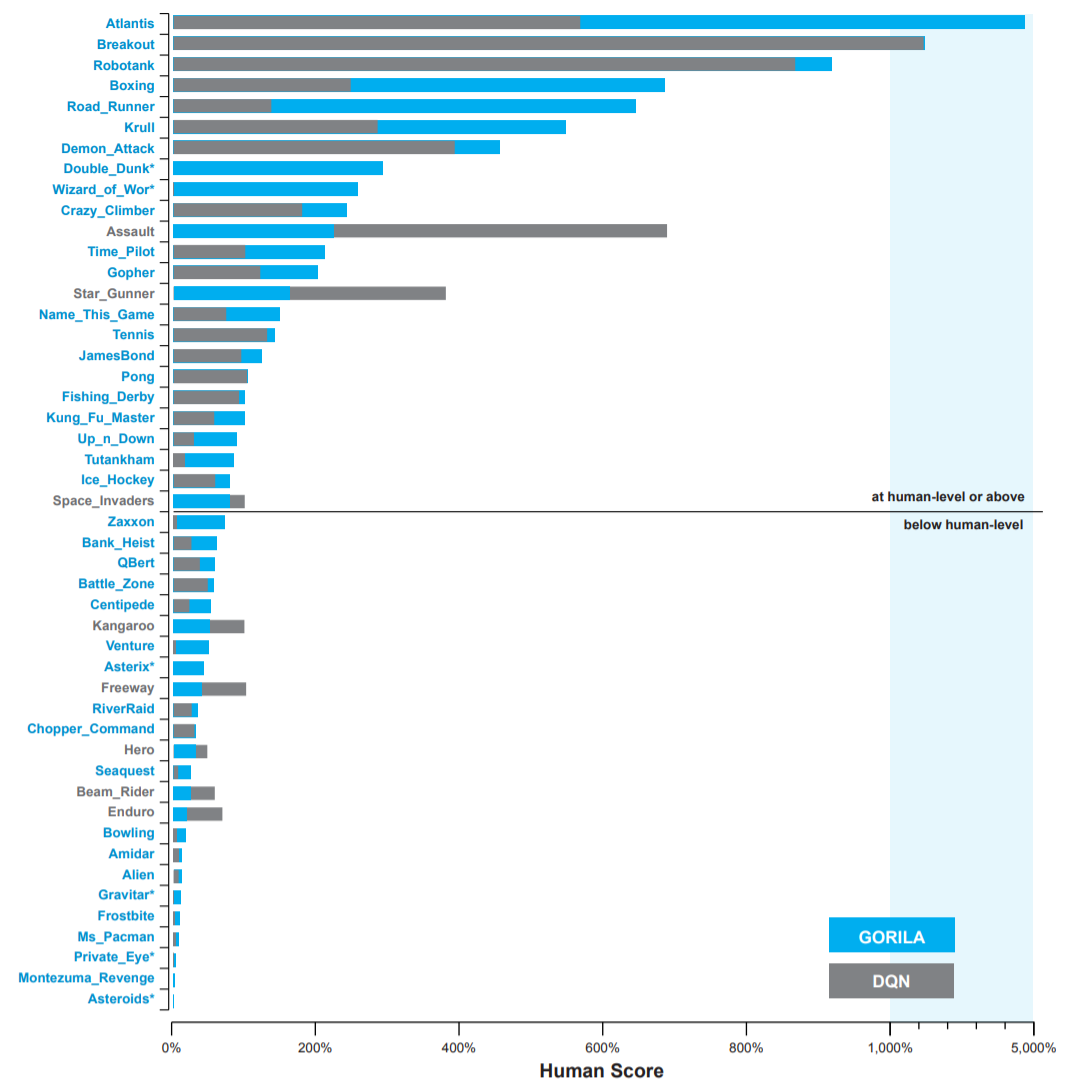
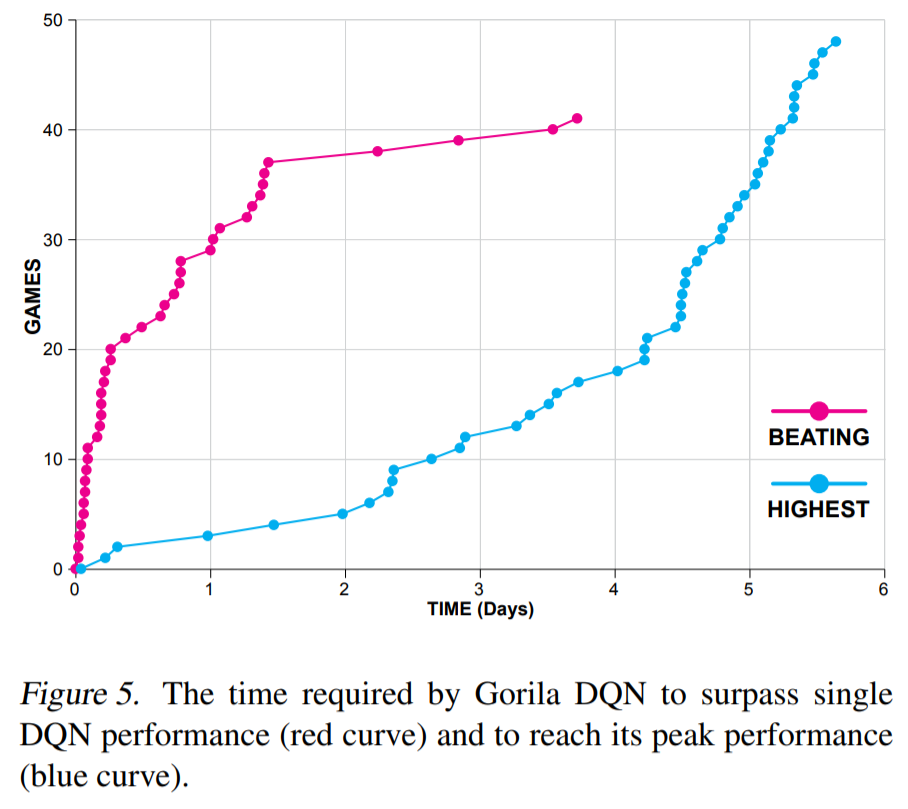
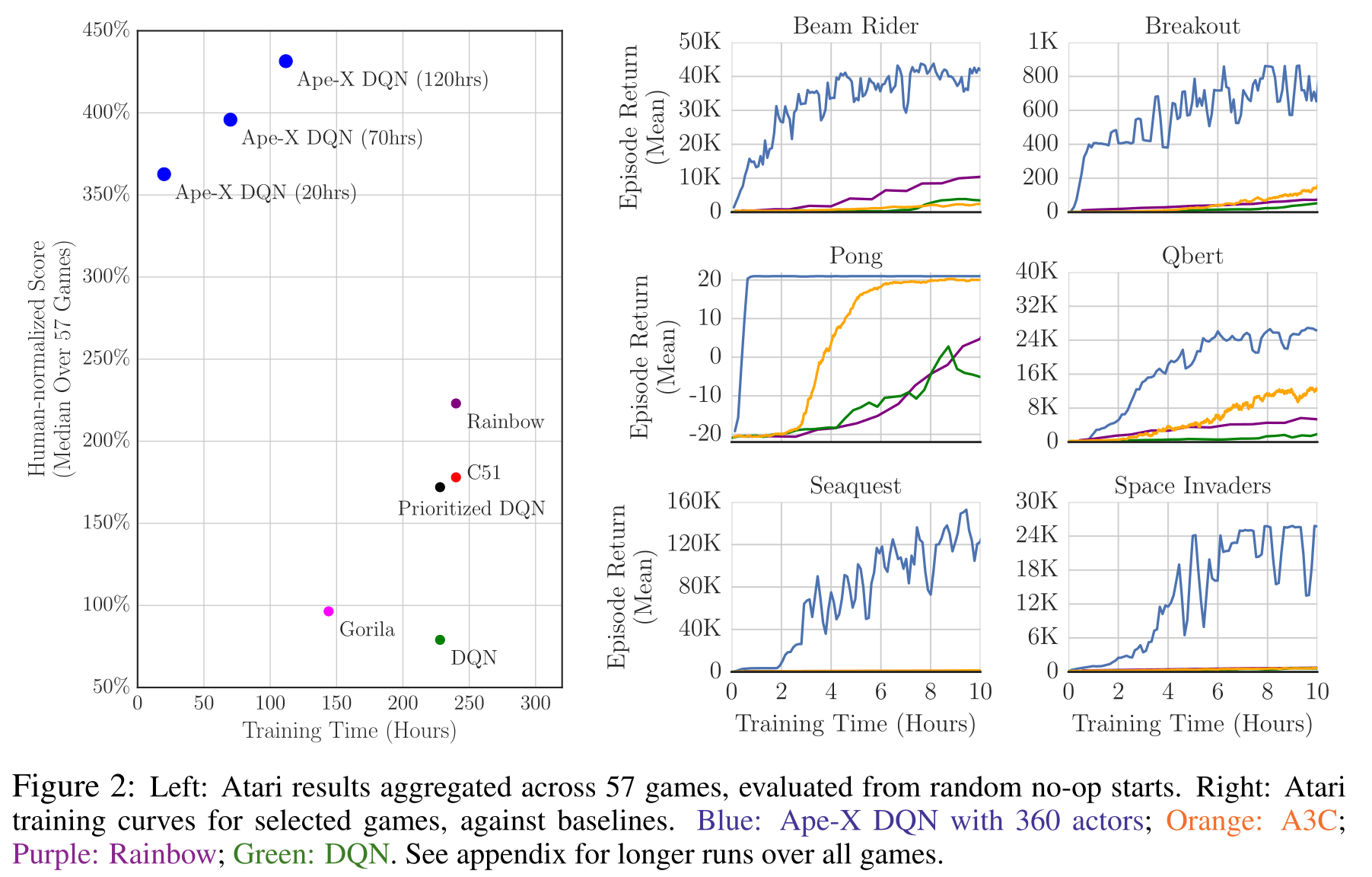
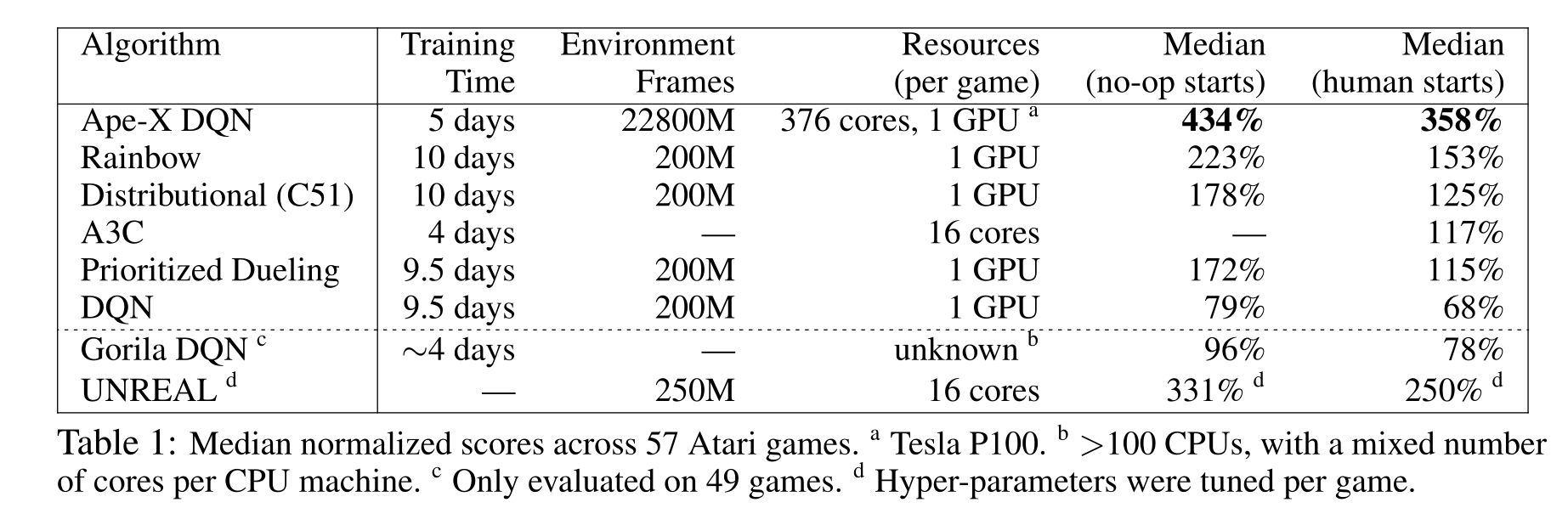
Ape-X
Ape-X [@Horgan2018] 在分布式 DQN 的基础上进一步改进,提出:
- 使用单个学习者 + 多个执行者的结构;
- 结合优先经验回放(PER);
- 使用 n-step 回报 与 双重对偶 DQN。
这种结构下,数百个并行执行者能极大提高样本采集速度。
在相同的训练时间下,性能与收敛速度都远超 DQN。
仅用 360 个 CPU 核 + 1 个 GPU,在 20 小时内达到人类 3 倍表现。
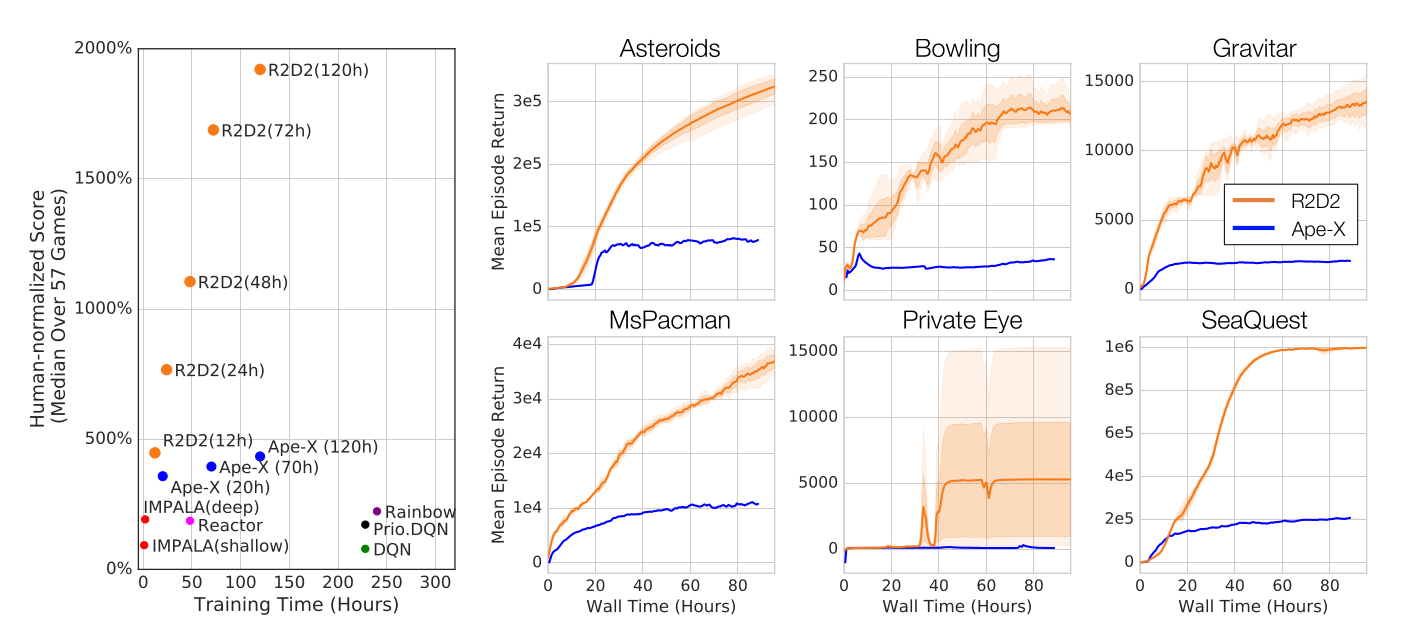
R2D2(Recurrent Replay Distributed DQN)
R2D2 [@Kapturowski2019] 结合了 Ape-X 与 DRQN 的思想,具有以下特点:
- 双重对偶 DQN + n-step 回报(\(n=5\));
- 优先经验回放;
- 分布式结构:256 个 CPU 执行者 + 1 个 GPU 学习者;
- 在卷积层后加入 LSTM 层,以解决部分可观测问题(POMDP)。
此外,R2D2 还解决了 LSTM 的工程性问题(如初始状态选择),
一度成为 Atari-57 基准 的最新最优算法。
分布式多执行者学习已成为现代深度强化学习的标准做法,只需增加计算核心(或多台机器人),即可大幅提升性能与效率。