本文 的 原文 地址
原始的内容,请参考 本文 的 原文 地址
本文 的 原文 地址
尼恩说在前面:
最近大厂机会多了, 在45岁老架构师 尼恩的读者交流群(50+)中,最近有小伙伴拿到了一线互联网企业如得物、阿里、滴滴、极兔、有赞、shein 希音、shopee、百度、网易的面试资格,遇到很多很重要的面试题:
第三方服务经常挂,你的系统怎么保证高可用?
第三方挂了,我们总在背锅。如何 设计一个 靠谱的 高可用方案,让 外部依赖 稳如泰山
前几天 小伙伴面试 希音,遇到了这个问题。但是由于 没有回答好,导致面试挂了。小伙伴面试完了之后,来求助尼恩。
那么,遇到 这个问题,该如何才能回答得很漂亮,才能 让面试官刮目相看、口水直流。
此题 超 考察 候选人 架构思维
优秀的架构设计,恰恰体现在对“异常场景”的处理能力上——这也是面试官通过第三方服务问题,考察候选人架构思维的核心原因。
所以应该花精力做第三方服务的高可用设计,在第三方挂了之后,我们的系统依然能稳定运行,具体可实现三大价值:
(1) 保障核心业务连续性:比如支付接口挂了,能切换到备用渠道,确保用户能正常下单付款
(2) 避免自身系统被拖垮:通过限流、熔断,防止第三方的问题扩散到自身的服务
(3) 降低故障影响范围:非核心功能(如推荐、广告)出问题,不影响用户的核心操作(如浏览、购买)
接下来,我们会从多个维度,详细拆解具体的落地方案,帮你建立一套完整的第三方服务高可用方案。

这里,尼恩给大家做一下系统化、体系化的梳理,使得大家内力猛增,可以充分展示一下大家雄厚的 “技术肌肉”,让面试官爱到 “不能自已、口水直流”,然后实现”offer直提”。
当然,这道面试题,以及参考答案,也会收入咱们的 《尼恩Java面试宝典》V175版本PDF集群,供后面的小伙伴参考,提升大家的 3高 架构、设计、开发水平。
最新《尼恩 架构笔记》《尼恩高并发三部曲》《尼恩Java面试宝典》的PDF,请关注本公众号【技术自由圈】获取,后台回复:领电子书
开篇:第三方服务不稳定的本质
在微服务和分布式架构普及的今天,没有任何系统能脱离外部依赖独立运行。但第三方服务的不稳定性,往往会成为我们系统高可用的“短板”——这部分问题看似是“别人的问题”,实则需要我们从自身架构设计出发,建立一套完整的容错体系。
几乎所有互联网系统,都需要通过第三方服务调用
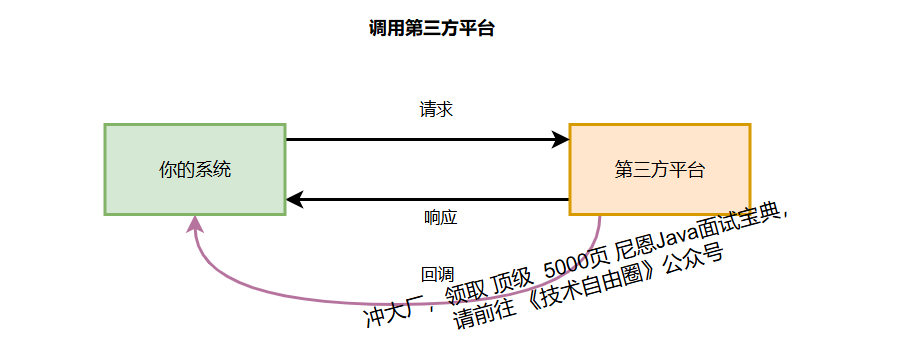
大致场景如下:
- 身份与安全:微信/QQ扫码登录、手机号验证(运营商接口)、人脸识别(第三方AI服务)
- 支付与金融:支付宝/微信支付接口、银行转账/清结算接口、汇率查询(金融数据服务)
- 消息与通知:短信验证码(短信服务商)、App推送(极光/个推)、邮件发送(第三方邮件服务)
- 专业能力服务:天气查询(气象局接口)、地图定位(高德/百度地图)、PDF转码(第三方工具服务)
三大不可控性
之所以要花大量精力应对第三方服务问题,核心原因在于其三大不可控性:
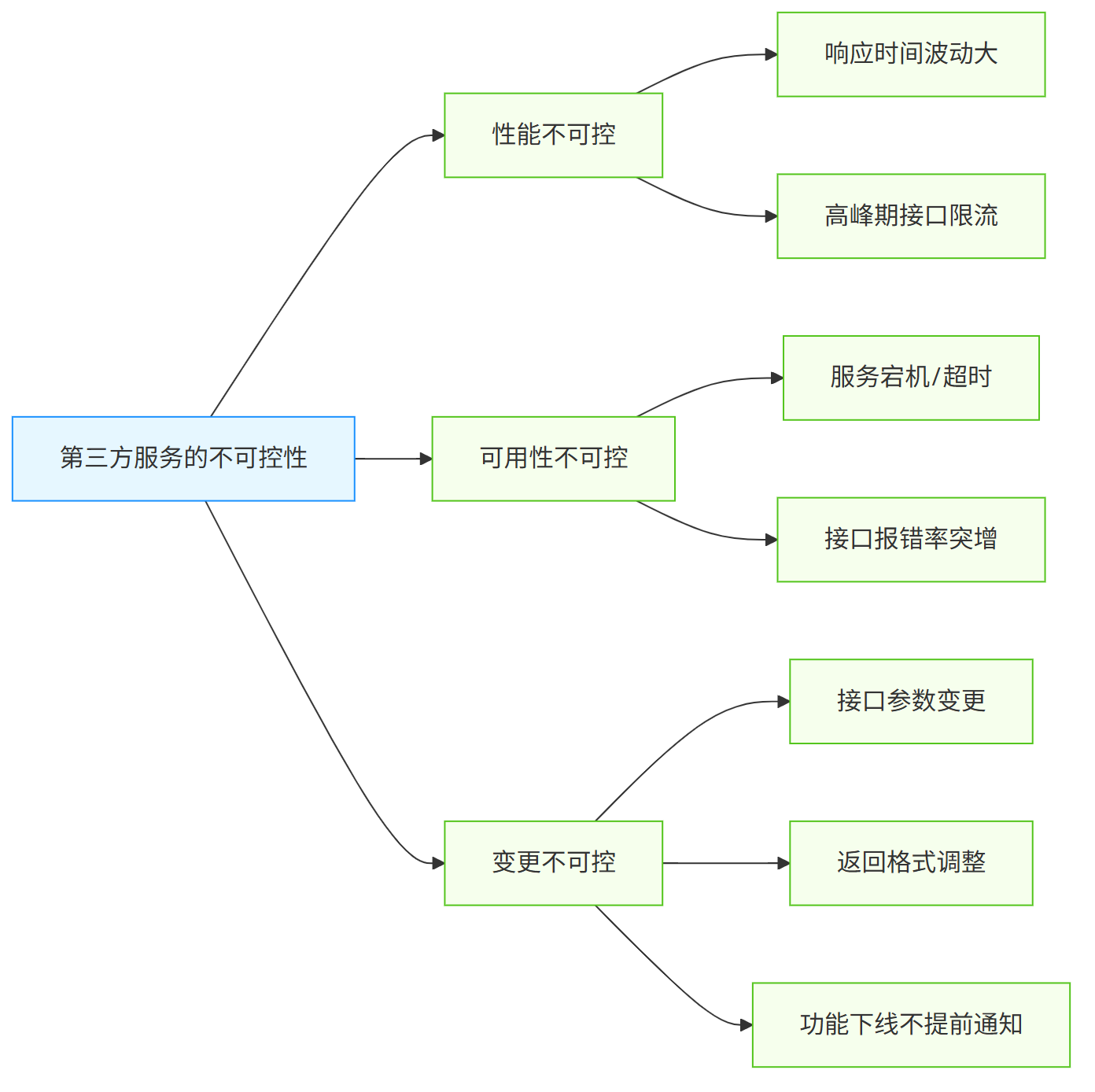
在面试中,经常能看到简历上写“熟悉第三方API对接”,但深入追问后会发现,很多人的工作只停留在“实现基础功能”层面,也就是只是能够调用,容错设计没有涉及
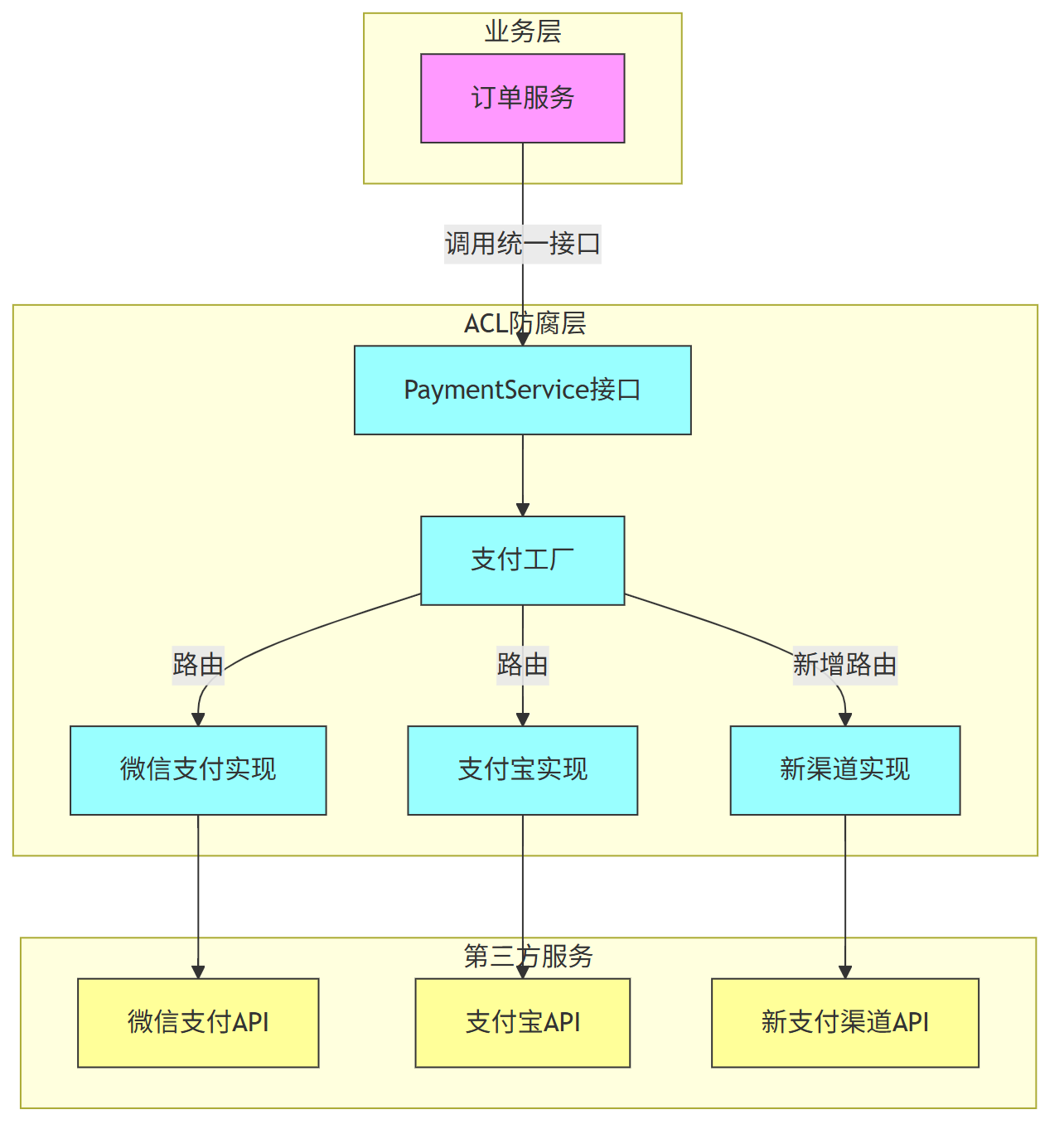
第一招: 引入 ACL防腐层
第三方服务的不稳定性(如宕机、API变更)会直接 打挂 核心业务系统, 后果严重。
第一招 就是 引入 ACL防腐层。
防腐层(ACL)通过接口隔离和协议转换,将外部服务的波动性封装在边界内,使核心系统保持稳定性和技术一致性。
以电商支付场景为例,订单服务只需调用标准支付接口,无需感知微信支付或支付宝的技术细节差异。
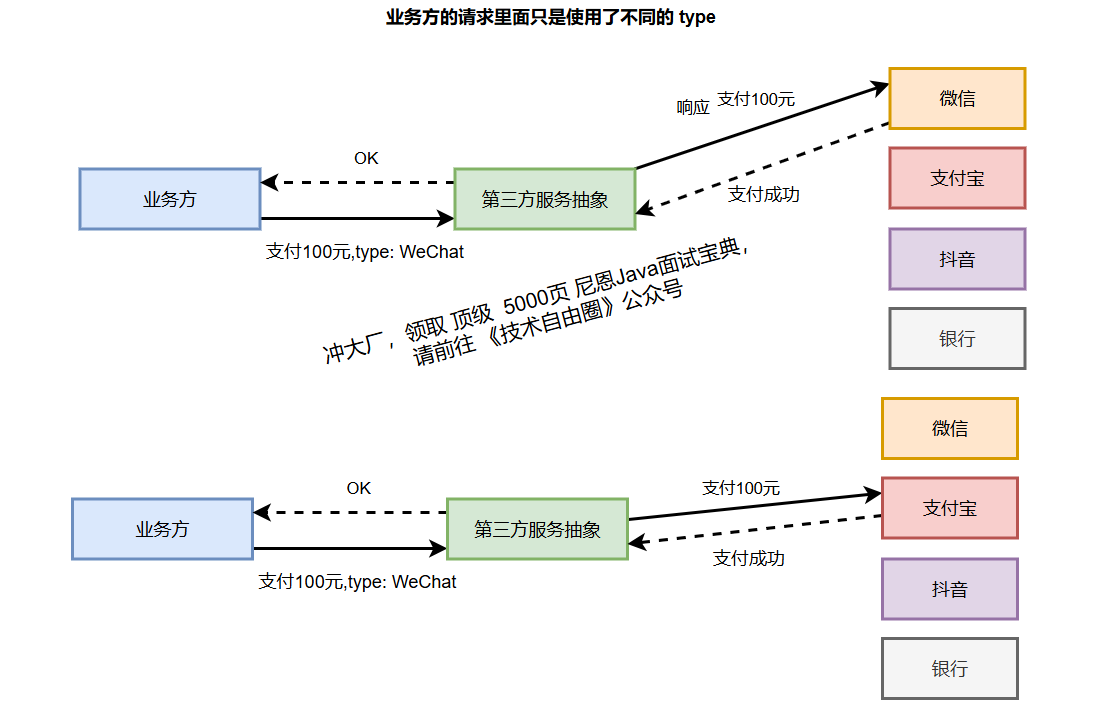
ACL防腐层 屏蔽掉“脏活累活”
一个设计良好的 ACL防腐层 ,可以屏蔽掉所有与具体实现相关的“脏活累活”,如下图:
- 协议转换:HTTP/RPC/私有协议统一适配
- 数据规范:JSON/XML/form-data 统一转换
- 安全处理:MD5/SHA256/RSA 签名验签
- 回调机制:同步/异步通知统一标准化
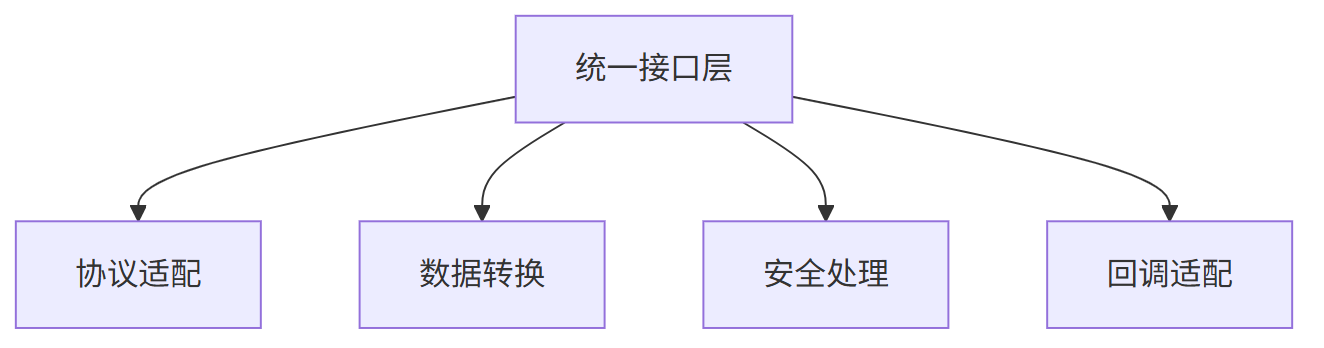
ACL防腐层 设计带来两大核心优势:
优势1:提升研发效率:业务开发者无需学习各种第三方API规范,只需调用标准化接口,大幅降低接入成本。
优势2:增强系统扩展性:新增支付渠道时,只需添加新的实现类并注册到工厂,对上游业务完全透明。
有了这个坚实的 ACL防腐层 ,我们就可以在此基础上实施各种客户端治理策略,为系统高可用打下基础。
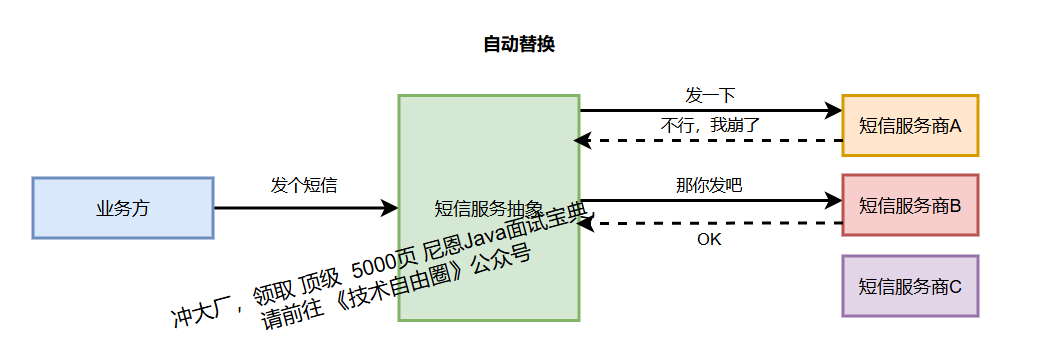
第二招:引入 策略模式 支持 主备 切换
设计 主备 接口,内部service调用第一个三方 的 主接口;主接口 超时后,调用第二个 备接口,未来都直接调用备份接口,直到超时的服务恢复;
当核心第三方服务出现故障时,最直接有效的应对方式就是快速切换到备用渠道。
这种机制类似负载均衡的故障转移思想,但更侧重于业务连续性保障。
以短信服务为例:
假设系统同时接入A、B、C三家供应商,正常情况下优先使用A供应商。当监控发现A的错误率超过阈值(如20%)或响应超时,系统应自动将流量切换到B,确保业务不受影响。
通过策略模式实现供应商动态切换,伪代码如下:
// 策略接口定义
public interface SmsSupplier {SendResult sendSms(String phone, String content);
}// 具体策略实现(示例:供应商A)
public class SupplierA implements SmsSupplier {@Overridepublic SendResult sendSms(String phone, String content) {// 调用供应商A的API实现}
}// 策略上下文(含自动切换逻辑)
public class SmsRouter {private List<SmsSupplier> healthySuppliers; // 健康供应商池public SendResult routeSend(String phone, String content) {for (SmsSupplier supplier : healthySuppliers) {try {return supplier.sendSms(phone, content); // 尝试发送} catch (SupplierException e) {markSupplierUnhealthy(supplier); // 标记故障}}throw new AllSuppliersDownException(); // 全渠道熔断}// 基于健康检查更新供应商池void refreshHealthySuppliers() {healthySuppliers = allSuppliers.stream().filter(s -> healthChecker.isHealthy(s)) // 健康检测.collect(Collectors.toList());}
}代码关键点:
(1) SmsSupplier 策略接口统一服务协议
(2) SmsRouter 动态选择可用供应商
(3) refreshHealthySuppliers 定时更新健康池
引入 策略模式 支持 主备 切换 关键设计要点:
1)健康检测维度
- 响应时间:>3000ms视为异常
- 错误率:连续5次失败触发熔断
- 超时率:10秒内超时率>40%自动隔离
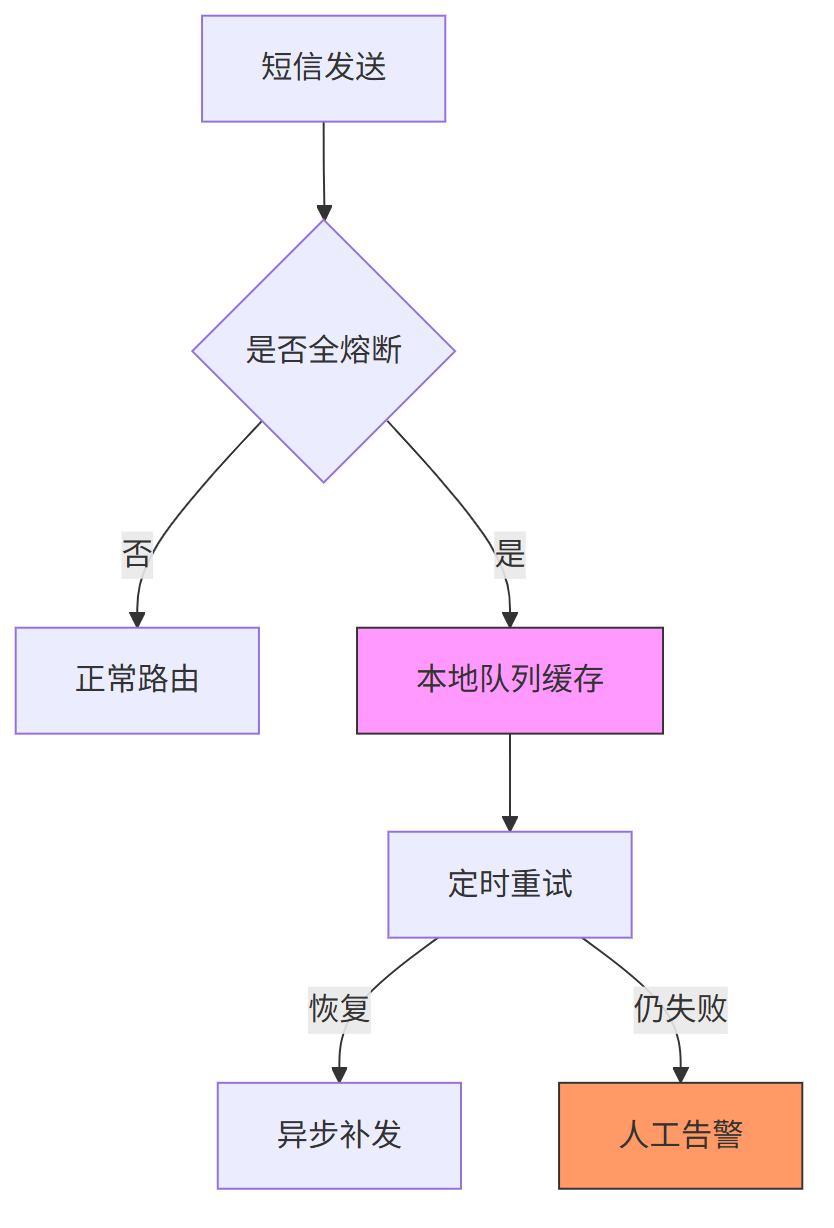
2)多级降级策略
当所有渠道不可用时启动应急方案:
3)实际案例:
某金融系统采用动态权重路由,根据供应商历史成功率自动分配流量(如A:B:C = 7:2:1)。
当A供应商响应时间从200ms升至1500ms时,10秒内自动将权重调整为2:7:1,实现无感切换。
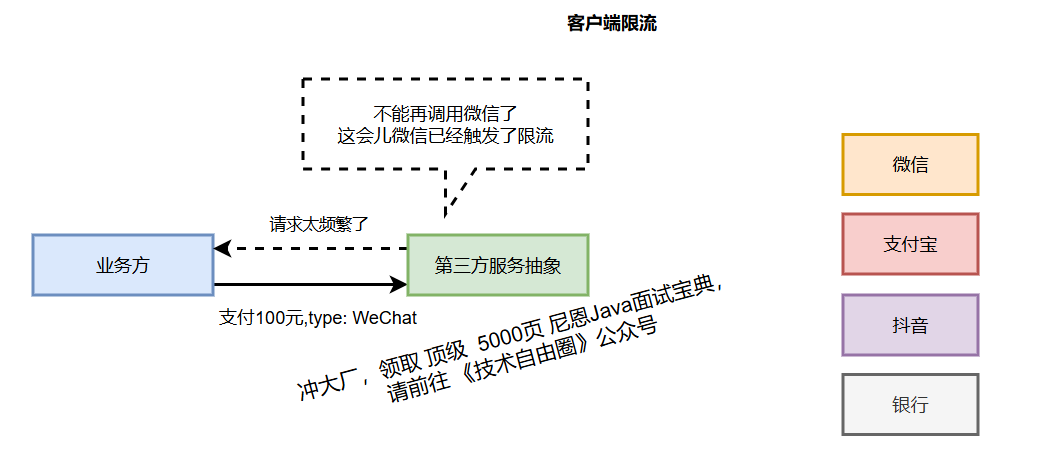
第三招:引入流量防卫层 , 精准限流 保障不会过载
第三方服务通常设有严格的API调用限制(如每秒10次)。盲目超量请求不仅会被直接拒绝,还会浪费系统资源并增加下游压力。
在客户端实施精准限流,能在发起网络调用前拦截超额请求,实现快速失败和资源保护。
在我们的防卫层中,提前根据第三方的限流规则,配置一个与之匹配的客户端限流器(如使用Guava RateLimiter或Sentinel)。
这样,在发起调用之前就主动拦截掉超额的请求,既能快速失败,又能省去一次必然无效的网络调用。
流量防卫层 4大限流策略设计
下面通过4大限流策略设计,进行精细化限流
1)多级限流配置:
- 针对核心服务设置更宽松的限流阈值
- 非核心服务设置严格限流,优先保障核心流程
2)动态调整机制:
- 监控第三方服务响应状态,异常时自动降低限流阈值
- 结合业务高峰期自动调整(如电商大促期间提高支付接口限流)
3)限流后的处理策略:
- 核心请求:加入队列等待重试
- 非核心请求:直接返回友好提示
- 批量任务:延迟执行或分片处理
4)多层次限流保护
可以设计多层次限流保护策略,在不同维度上实施流量控制,避免单一限流点的局限性。建立多级管控体系。
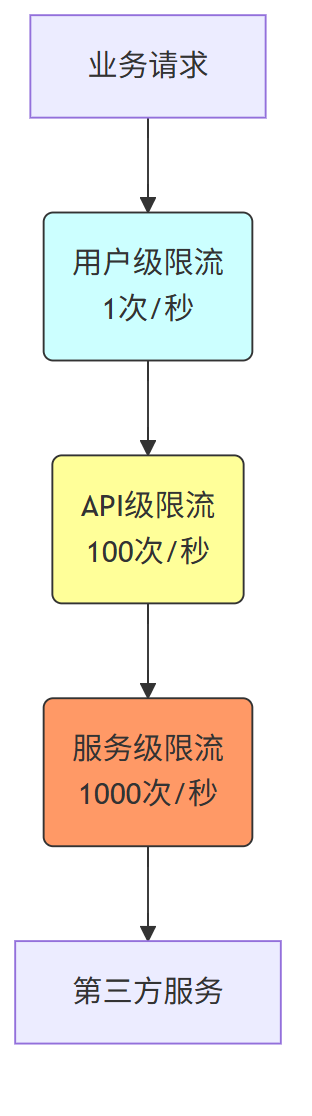
实战案例:某电商平台在双十一期间采用三级限流
- 用户层:单个用户每秒最多下单2次,防止黄牛刷单
- API层:支付接口每秒限流5000次,保护支付系统
- 服务层:整体订单服务限流20000 QPS,保护下游库存和物流系统
第四招: 引入容错机制,完成 超时控制与失败重试
在实际业务中,第三方服务出现响应缓慢或偶发性错误十分常见。
如果每次出现网络抖动或服务短暂不可用,都直接向业务层返回失败,会导致业务方不得不自行处理各种重试逻辑。
这不仅增加了业务开发的复杂度,也容易造成重试策略的碎片化和不一致。
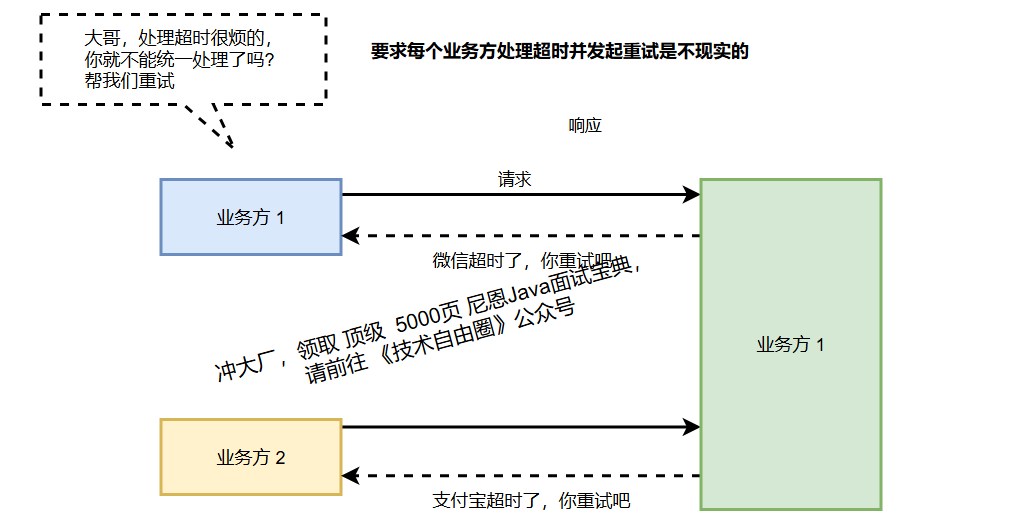
因此,在ACL防腐层对可重试的错误进行统一拦截和自动重试,对提升系统整体的可用性十分关键。
但需要注意的是,重试的前提是第三方接口必须满足幂等性。
特别是涉及写操作(如创建订单、支付扣款等)时,如果缺乏幂等设计,盲目重试可能导致数据重复或资金多次扣除等严重问题。
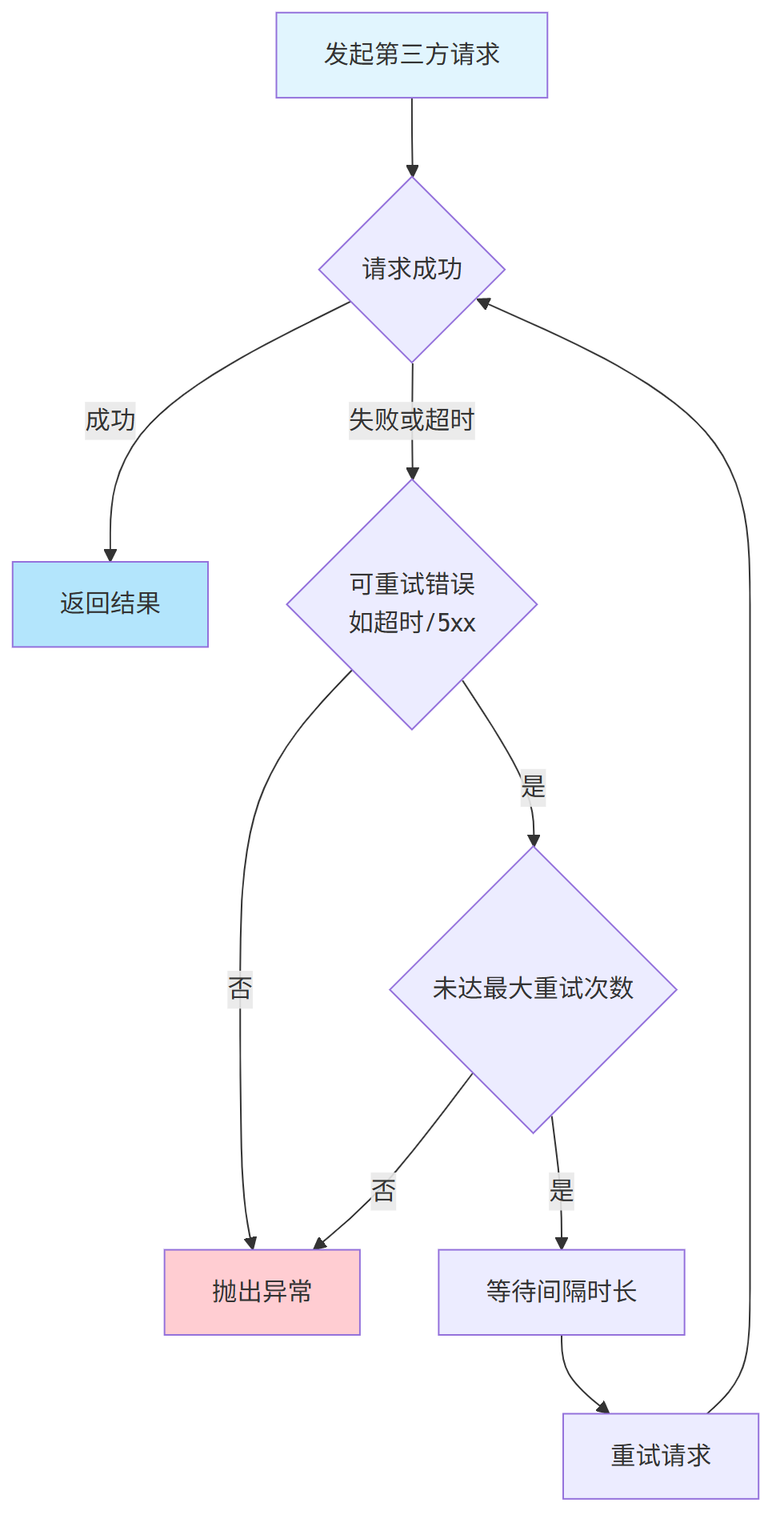
建议使用一种“渐进式后退重试策略”(Backoff Retry),避免因密集重试对下游服务造成雪崩压力。
常见的策略包括:固定间隔重试、指数退避重试、随机延迟重试等。
以下是使用指数退避重试的示例代码:
// 使用 Retryer 构建重试机制(Guava Retrying 库示例)
Retryer<Boolean> retryer = RetryerBuilder.<Boolean>newBuilder().retryIfException(throwable -> throwable instanceof SocketTimeoutException) .retryIfResult(result -> result == false) // 按条件重试.withWaitStrategy(WaitStrategies.exponentialWait(1000, 5, TimeUnit.MINUTES)) .withStopStrategy(StopStrategies.stopAfterAttempt(5)) // 最大重试5次.build();// 执行需重试的方法
retryer.call(() -> callThirdPartyService(params));注释说明:
retryIfException:指定哪些异常触发重试(如超时、5xx错误)。exponentialWait:指数退避策略,首次等待1秒,后续每次等待时间指数增长,最长不超过5分钟。stopAfterAttempt:设置最大重试次数,避免无限重试。
重试策略虽然能大幅提升系统的容错能力,但仍需谨慎使用。务必与第三方确认接口的幂等性,并在重试日志中加入请求ID便于链路追踪。
第五招:引入 熔断降级,防止系统雪崩
当第三方服务出现严重性能问题或持续报错时,继续盲目地发送请求不仅无法获取有效结果,还会大量占用本系统的线程、连接等宝贵资源,可能引发连锁反应导致自身服务被拖垮。
这种情况俗称“雪崩效应”。
为防止这种情况,我们需要引入熔断器模式(Circuit Breaker)。
其核心思想类似于电路保险丝:当故障达到一定阈值时,自动“熔断”,在一段时间内停止所有对故障服务的调用,给予其恢复时间。
同时,系统应具备降级(Fallback) 能力,在熔断触发后能返回一个预设的、有业务意义的兜底结果,从而保证核心业务的继续运行。
一个健壮的熔断策略通常基于错误率和慢调用比例这两个关键指标来动态决策。
熔断器通常包含三种状态,并在这三种状态间自动切换:
- 关闭(CLOSED):请求正常通过,熔断器会持续监控调用结果。
- 打开(OPEN):当错误率或慢调用比例超过阈值,熔断器打开,所有请求被立即拒绝,不再调用下游服务。
- 半开(HALF-OPEN):熔断器打开一段时间后,会自动进入半开状态,尝试放行少量请求。根据这些试探请求的结果,决定是恢复至关闭状态,还是再次打开。
以下是使用 Resilience4j 库实现熔断的示例代码:
// 1. 配置熔断器规则
CircuitBreakerConfig config = CircuitBreakerConfig.custom().failureRateThreshold(50) // 错误率阈值:50%。当请求失败率超过50%时触发熔断。.slowCallRateThreshold(80) // 慢调用阈值:80%。慢于5秒的调用视为慢调用,比例超80%则触发。.slowCallDurationThreshold(Duration.ofSeconds(5)) // 定义慢调用的时间界限:5秒。.waitDurationInOpenState(Duration.ofSeconds(30)) // 熔断器在OPEN状态的等待时间:30秒后进入HALF_OPEN状态。.slidingWindowType(SlidingWindowType.COUNT_BASED) // 基于调用次数统计故障率。.slidingWindowSize(20) // 统计窗口大小:最近20次调用。.build();// 2. 创建熔断器实例
CircuitBreaker circuitBreaker = CircuitBreaker.of("thirdPartyService", config);// 3. 使用熔断器装饰业务调用,并指定降级策略
CheckedFunction0<String> decoratedSupplier = CircuitBreaker.decorateCheckedSupplier(circuitBreaker, () -> callThirdPartyService(params)); // 核心业务调用String result = Try.of(decoratedSupplier) // 尝试执行.recover(throwable -> getFallbackResult(params)) // 如果调用失败(包括被熔断器拒绝),执行降级方法.get(); // 获取最终结果,要么是正常结果,要么是降级结果注释说明:
failureRateThreshold:这是触发熔断的核心阈值之一,通常根据下游服务的稳定性进行调整。slowCallRateThreshold:关注响应时间而非直接错误,能有效防止因下游服务变慢而导致的资源池耗尽。recover:提供业务降级逻辑,例如返回缓存旧数据、默认值或空结果,是保证系统韧性的关键。
熔断器的状态流转是整个策略的核心,其决策过程可通过下图清晰展示:
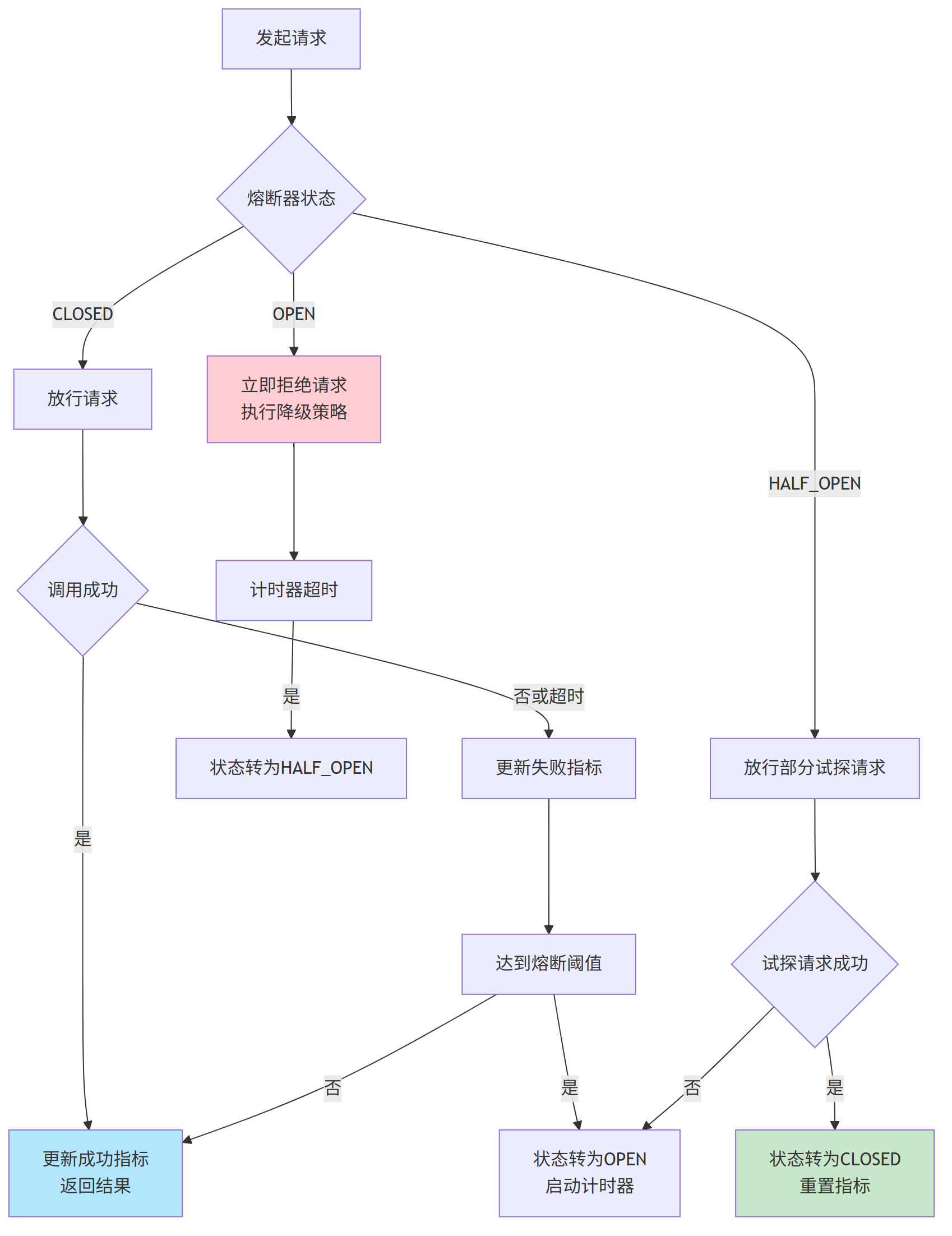
熔断降级是系统弹性的重要保障,在实际应用中,通常将熔断器与分布式配置中心(如Nacos、Apollo)结合,实现动态调整阈值和手动强制切换状态,以便在复杂故障场景下进行更灵活的人工干预。
第六招:全链路可观测性
面对不可控的第三方服务,完善的监控体系不是可选项,而是必选项。
当问题发生时,清晰的链路追踪和准确的指标数据是我们快速定位、明确责任边界的唯一凭据。
没有可观测性 机制,所有的高可用设计都像是在盲人摸象。
现代可观测性体系建立在三大支柱之上:指标(Metrics)、日志(Logs) 和链路(Traces)。三者联动,才能完整还原每一次调用的真相。
核心监控指标(Metrics):
在客户端集成监控组件(如Prometheus客户端),抓取以下关键指标:
- 性能指标:每次调用的耗时(平均值、P95、P99)
- 流量指标:QPS、并发线程数
- 错误指标:成功率、错误率(按错误类型细分)
- 治理指标:限流触发次数、熔断器状态变化、重试次数
监控指标只有配上合理的告警才能真正发挥作用。告警必须分层分级,避免警报疲劳:
- P0级警报(电话/短信):针对核心业务接口,当错误率在2分钟内超过30%或完全不可用时,立即通知研发人员紧急处理。
- P1级警报(即时通讯工具):当P99响应时间连续5分钟超过预定阈值,或熔断器被触发,通知相关技术人员关注。
- 业务通知(邮件/站内信):当确认第三方服务出现较长时间(如30分钟)的不可用,及时通知业务方团队,便于其评估影响并启动业务侧降级方案。
分布式链路追踪系统(如SkyWalking)是定位问题的利器。它为每个请求分配一个全局唯一的Trace ID,串联起从用户端到多个第三方服务的完整调用链。
第七招:引入异步降级,保护核心业务不牵连
...................由于平台篇幅限制, 剩下的内容(5000字+),请参参见原文地址
原始的内容,请参考 本文 的 原文 地址
本文 的 原文 地址