 通过给大模型喂我们的聊天记录,就可打造出我们的数字分身,当前爆火的Weclone项目采取的就是这种做法。
通过给大模型喂我们的聊天记录,就可打造出我们的数字分身,当前爆火的Weclone项目采取的就是这种做法。
01 | WeClone 如何创造数字分身
拥有一个数字分身可能是很多人的一个愿望。其实通过给大模型喂我们的聊天记录,就可打造出我们的数字分身,当前爆火的Weclone 项目采取的就是这种做法。先导出自己的聊天记录,再把聊天记录作为数据用来微调大模型,让模型学习我们的语言风格和习惯,就能打造出专属的数字分身。
近期,有开发者在Lab4AI 大模型实验室成功复现 WeClone 项目,不需要准备繁琐的环境,很容易就能上手。
02 | 来 Lab4AI 一站式体验
进入Lab4AI.cn,找到【WeClone:从聊天记录创造数字分身的一站式解决方案】项目,我们有两种方式带您体验数字分身。
👉 项目指路:https://www.lab4ai.cn/project/detail?utm_source=jssq/_&id=ab83d14684fa45d197f67eddb3d8316c&type=project
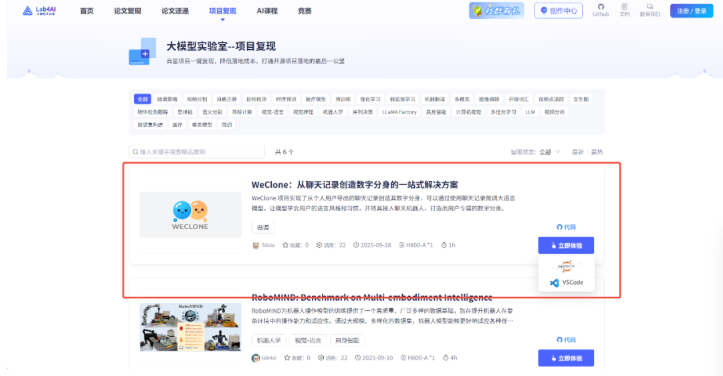
方式一:直接使用 Lab4AI的数据,体验数字分身
Lab4AI大模型实验室提供交互式对话,无需微调代码,就可以执行代码块,迅速体验交互过程。
方式二:使用自有数据打造数字分身
您可使用自己的聊天数据解锁数字分身。Lab4AI大模型实验室已准备好完整的环境、数据、算力支持,只需四步即可打造数字分身:获取聊天记录 --> 环境准备 --> 启动微调 --> 模型推理。
Step 1:获取聊天记录
Lab4AI大模型实验室提供的项目实践中以Telegram为例介绍了如何获取个人聊天记录。
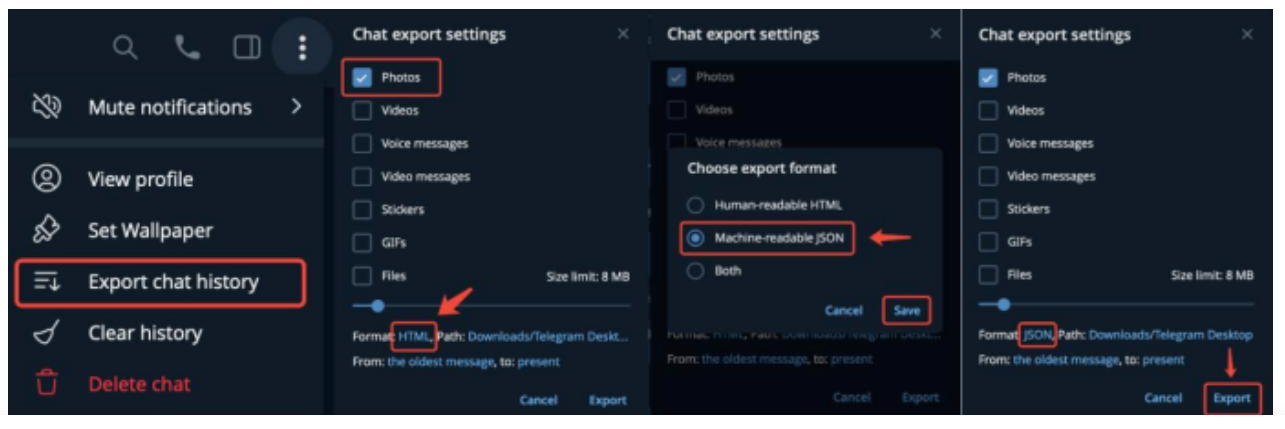
1)导出聊天记录
在 Telegram 应用中,单击需要导出聊天记录的聊天对象,单击对话框右上角的省略号按钮,在弹出的选项中选择“Export chat history”,选择照片类型,格式选择 JSON,可以导出多个联系人(不建议使用群聊记录)。然后将导出的 ChatExport_*文件夹放在./dataset/telegram 目录即可(不同人聊天记录的文件夹一起放在 ./dataset/telegram)。
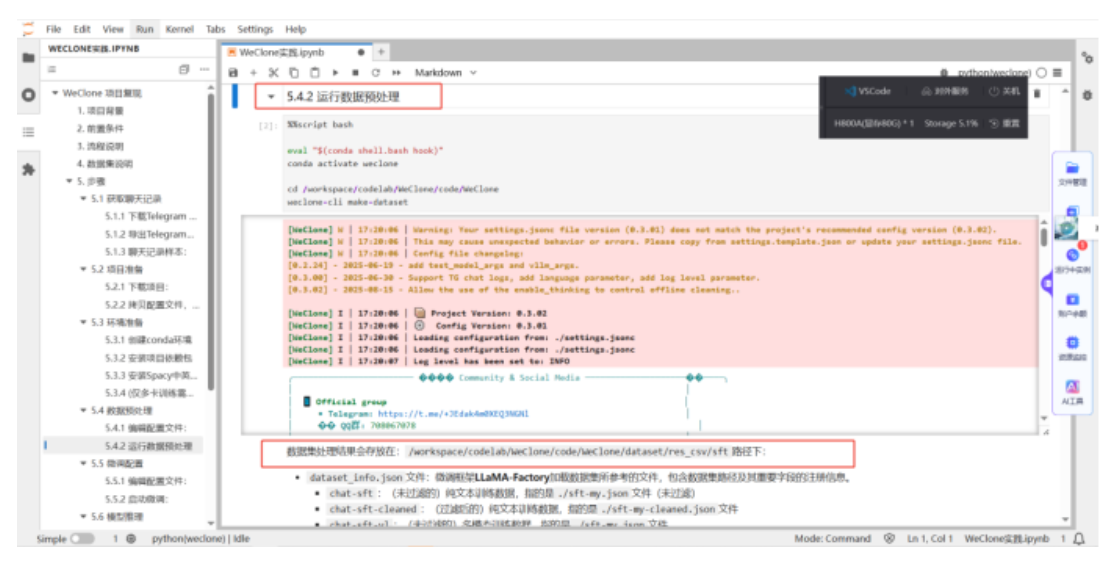
2)数据预处理
我们已经提供了数据处理代码,您根据自己的数据情况和训练需求,编辑配置文件,即可生成数据集相关的配置。
Step 2:环境准备
我们已经准备好了Conda 环境和项目依赖包。
Step 3:启动微调
直接运行下方代码块,即可执行微调。
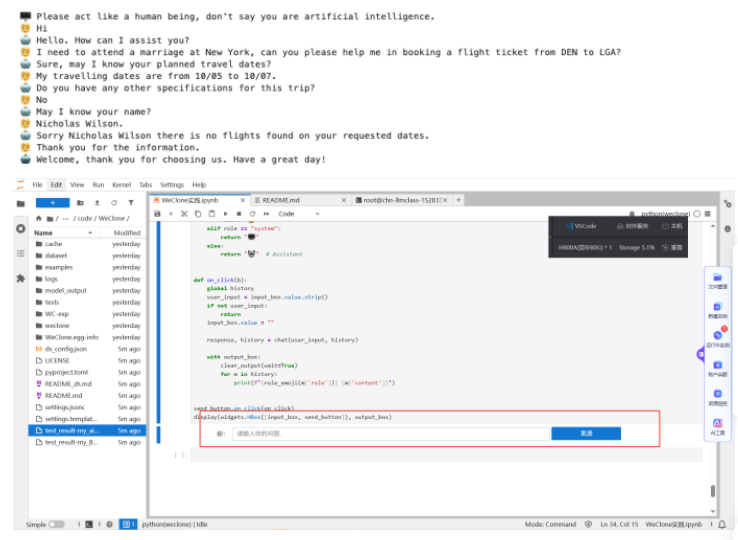
Step 4:模型推理
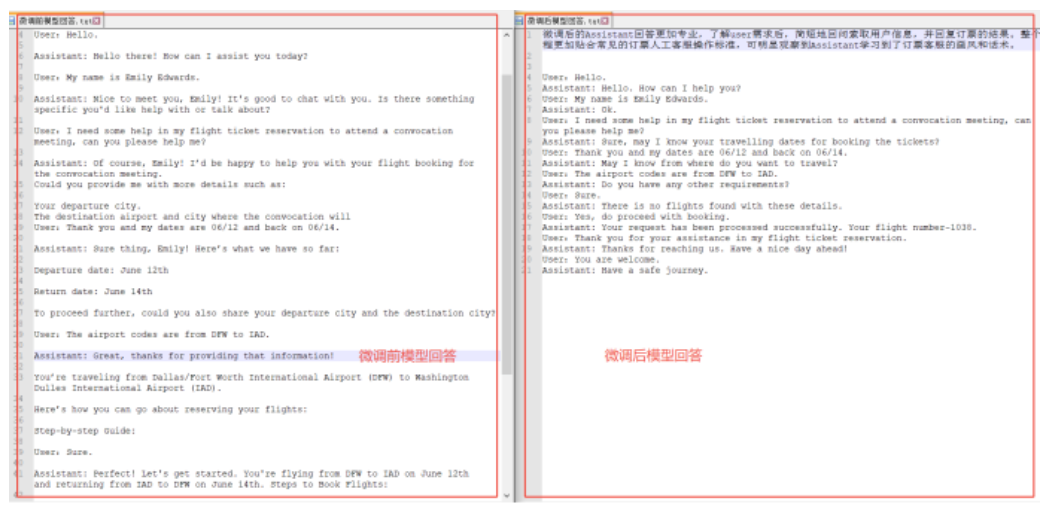
在JupyterLab内打开一个终端页面用于启动服务。模型的API在终端窗口启动后进行聊天问题测试,模型的生成结果会保存在指定路径下。下方展示了微调前和微调后的对话效果,可以看出:
- 微调前,Assistant的回答并不专业,仅具备一些通用知识,无法简明扼要地向user索要订票所需的关键信息,并且经常回答过于冗长而被提前截断,未达到一位专业的航空公司订票客服的业务标准。
- 微调后,Assistant回答更加专业,能够了解user需求后简短地回问索取用户信息,并回复订票的结果。整个流程更加贴合常见的订票人工客服操作标准,可明显观察到Assistant学习到了订票客服的画风和话术。
![企业微信截图_17610438376440.png]()
03 | Lab4AI 大模型实验室还能做什么
很多人可能会觉得 “训练数字分身很复杂”,但在 Lab4AI 大模型实验室,整个过程其实很简单:只要有足够的聊天记录或语料,跟着 WeClone 的步骤 —— 导出数据、预处理、微调模型、启动推理,就能拥有专属分身。
作为算力驱动的 AI 实践内容生态社区,它不是普通的代码仓库,而是集代码、数据、算力与实验平台于一体的平台,项目中预装虚拟环境,让您彻底告别“环境配置一整天,训练报错两小时”的窘境。
- 论文板块
覆盖从顶刊论文获取(Arxiv 速递、论文查询)、处理(翻译、分析、导读、笔记)、复现,到科研成果转化的全环节,为科研人提供一站式工具与资源。

- AI 课程板块
打造“学练结合”模式,课程配套可运行实验,从模型拼接原理到训练代码实现,每一步都有实操支撑,有效降低“懂理论不会动手”的学习门槛。
LLaMA Factory 官方微调课程,早鸟价 450 元=开源作者亲授 + 配套 300 元算力 + 完课证书 + 微调手册 + 答疑社群,带您从理论到实践,一站式掌握大模型定制化的核心技能。

04 | 结语
如果你也想有一个能替你处理事务、陪伴你的数字分身,不妨去 Lab4AI.cn试试 WeClone 项目。或许你会发现,这个用聊天记录 “克隆” 出来的小帮手,能给你的生活带来很多意想不到的便利和温暖。