今日内容
1 大语言模型LLM配置
LM:大模型--》GPT,豆包,Deepseek
LLM:大语言模型---》我们可以使用【提示词】---》跟LM交互
LLM包含LM的
可以选择不同模型:就是不同大脑---》有不同擅长领域---》如果你不会选,就默认---》默认的每个领域都擅长一点
会提供:豆包---》coze--》字节跳动公司---》自己训练的模型:LM
Deepseek---》Deepseek公司--》开源了
其它

1.1 生成多样性-temperature
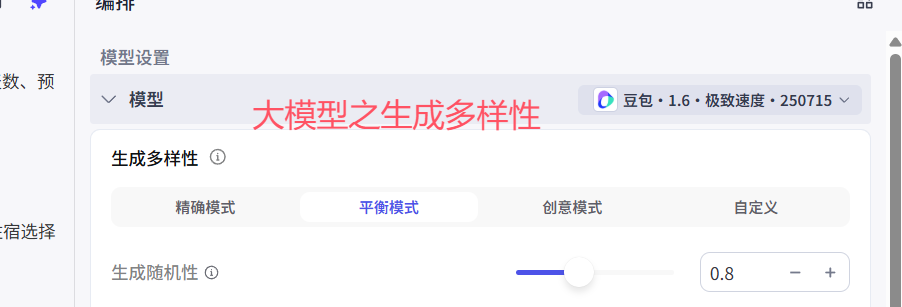
# 1 生成多样性-temperature解释:
调高温度会使得模型的输出更多样性和创新性,反之,降低温度会使输出内容更加遵循指令要求但减少多样性
# LLM---》大语言模型---》就是我们的大脑- 理性大脑:研究,数学,科学- 感性大脑:创作文章,写小说这个东西如果调高---》有很大的创意性---》感性调高---》适合 写作为,创意诗歌,广告文案这个东西如果调低---》非常理性,更精准,不会给你创意出东西--》生成正式文档,写代码,法律文件# 2 提供了 一些默认模式
## 精确模式: 0.2
在需要严格遵循指令、输出准确无误的场合,如生成正式文档、代码、法律文件等,应使用较低的生成随机性数值,接近 0,设置了0.2,使模型更倾向于选择最可能的词汇,确保输出的稳定性和准确性。例如在金融报告生成中,需准确呈现数据和事实,低随机性可避免出现不恰当的表述。## 平衡模式:默认模式 0.8
对于大多数日常应用场景,如一般的问答系统、信息检索回复等,可将生成随机性设置为中等水平,既能保证一定的多样性,使回答不会过于单调,又能基本遵循指令,提供较为准确的信息。## 创意模式: 1
当进行创造性任务,如小说创作、诗歌写作、创意广告文案撰写等,可适当调高生成随机性数值。较高的随机性能让模型探索更多的词汇组合和表达可能性,产生更具创意和独特性的内容,但要注意可能会出现一些偏离主题或不太符合逻辑的情况,需要后期适当筛选和修改
1.2 Top P
# 1 Top p 为累计概率:
模型在生成输出时会从概率最高的词汇开始选择,直到这些词汇的总概率累积达到 Top p 值。这样可以限制模型只选择这些高概率的词汇,从而控制输出内容的多样性。建议不要与 “生成随机性” 同时调整# 我们跟大模型对话---》问大模型---》给我们回顾
我问大模型:你爱我吗?---》会回答我的问题-top p比较高:嗯,亲爱的,我当然爱你了,我会永远爱你的 -top p比较低:爱我们问了大模型---》大模型脑中会生成很多词---》拿到词组成句子---》top p 是个数值---》把字组成句子---》每个字由分值
0.1 0.1 0.2 0.3 -----》0.7
嗯, 亲爱的, 我当然爱你了 ,我会永远爱你的 0.1
爱 ------》0.1# 举个例子: 刘老师---》temperature 比较低,Top p 高:很理性----》副业年收入30w-这个看你学习情况,看你个人脑子,看基于。。。。。。800字--》temperature 比较低,Top p 高-肯定没问题, 1000字 --》temperature 高,Top p 高-没问题 ----》 temperature 高,Top p低1.3 重复性语句惩罚
# frequency penalty:
当该值为正时,会阻止模型频繁使用相同的词汇和短语,从而增加输出内容的多样性# 我讲课,会经常问大家,听明白了吗?-负数:问了3次,大家3次都回答:听明白了-正数:问了3次,第一次回答听懂了,第二次回答没问题,第三次回答:很好
1.4 携带上下文轮数
# 1 默认为3 -我们跟大模型交互--》它给我回答,有时候是要参考 上面的问题---》如果是3,表示每次对话,都带上三次-问问题:尽量带更多的上下文轮数-如果携带上下文轮数:0---》一点都不参考上面的问题---》每个回答都是一个新的# 2 不要太多,如果携带很多轮数---》把上面很多问题都再带回去---》携带很多文字跟大模型交互---》消耗token【带的文字个数】---》花更多钱1 你是谁
2 你爱我吗
3 你几岁了
4 你叫什么名字 3
1.5 最大回复长度
# 1 控制模型输出的 Tokens 长度上限。通常 100 Tokens 约等于 150 个中文汉字-默认:4096 # 2 我们跟大模型交互,如果输入文字交互问:你 爱我 吗? ---》相当于3个token回答:当然 爱你 了,你 是 我的 唯一 ---》相当于7个token# 3 如果设置过短100---》回复特别多:回复200汉字---》大约在150个汉字时候:会被截断,就没了# 4 我们跟大模型交互---》豆包---》不是完全免费给我们用的---》每天有点数---》点数转化成token---》如果聊得过多,每天免费点数用完了---》需要再花钱购买- 最早期,coze给的点数还挺多----》测试够用- 现在,coze给的点数越来越少--》有时候测试就不够了--》可能需要花钱了-coze慢慢在收紧口袋,赚钱了-大模型训练,调用---》都是消耗服务器资源---》刚开始为了抢占市场,免费给大家用---》毕竟公司要盈利--》大家开始习惯用了后---》慢慢收费# 5 豆包:-豆包相当于一个人,基于coze做了一个聊天智能体--》给我们用---》因为相当于豆包帮我们付钱了# 6 自己制作了聊天智能体-给你 好朋友用---》它再用的时候,不需要充钱----》你冲了
2 插件
# 1 插件可以让智能体功能更丰富-有了大脑:LLM,需要手和脚---》插件就类似于这个# 2 举个例子:智能体有了大脑,可以做创意性工作,有时候需要参考一些内容-仿着 我写的 我爱学校这篇文章 [假设LLM不知道]----》帮我写一首诗-使用插件---》去获取我这偏文章[插件去获取]---》在互联网中 # 3 coze为什么小白友好---》就是因为--》插件众多-获取图片-生成视频-处理excel表格-处理word# 4 在插件市场非常非常多---》后续会讲很多---》学习起来不同插件用起来不一样-插件商店: coze官方开发的,放上了第三方公司开发的,放上了-自定义插件:发布到coze商店---》1 期苑老师讲过--》需要编码:python# 5 感受插件魅力1 获取时下最热门电影信息2 从头条获取4张美女图片3 看一下https://www.cnblogs.com/liuqingzheng地址讲了什么内容# 6 智能体如何知道调用哪个插件?-有大脑:获取电影---》电影插件---》自然就掉了跟他交互时,直接告诉调用哪个插件-去给我炒菜-不会用嘴这个插件炒---》大脑分析完用手炒菜-强制要求用嘴炒菜# 7 有些插件收费- 使用别人写的插件--》人家付出了劳动----》使用了一下服务器资源---》都要花钱---》插件可能收费- 我们可以自己写插件--》发布到coze商店----》如果用的人多,一开始免费--》后续收费

3 触发器
定时或者某个事件发生就调用coze的智能体
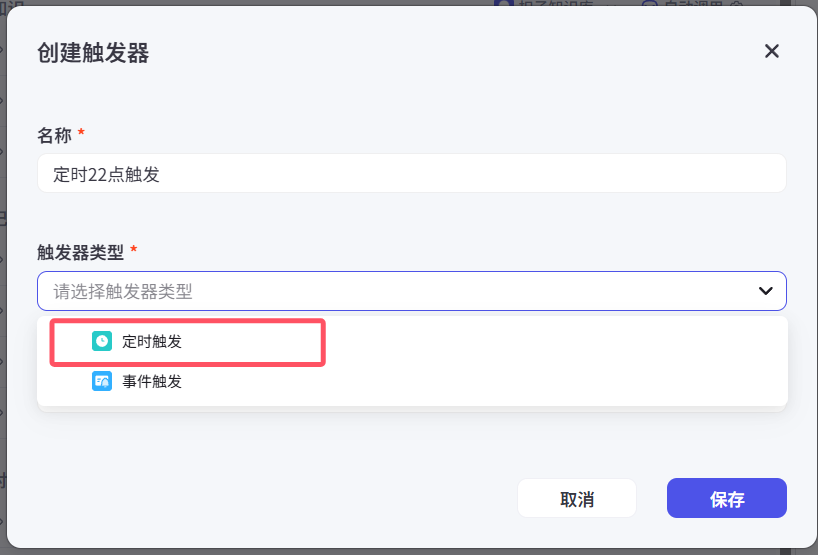
3.1 定时触发(我们可能用)
# 智能体必须要发布才能使用,但是浏览器可以关掉-在coze后台设定好了--》使用coze服务器
# 你写了一个智能体----》收集b站最热视频的标题--》存起来-设置 每天8点,执行一下智能体-设置 每一个小时,执行一下智能体# 比如我们做了一个给女朋友发邮件的智能体-设置定时:8点钟给女朋友发邮件

3.2 事件触发(一般不用)
# 1 当发生某个事件后---》触发这个智能体-企业微信群---》聊天---》有个人问了一个 问题,问题中有 【企业文化】 这个关键词---》我们触发一下coze执行,返回企业文化介绍# 2 我们用的少---》目前这个事件触发只能用在【飞书软件】中-类似于 企业微信,钉钉# 3 做了解即可-复制:https://api.coze.cn/api/trigger/v1/webhook/biz_id/bot_platform/hook/1000000000504436482-复制:FiPDemYV-配置在飞书平台--》当某个事件触发---》就会执行-最终的形态:所有应用,通过地址----》都可以触发,但是现在不行
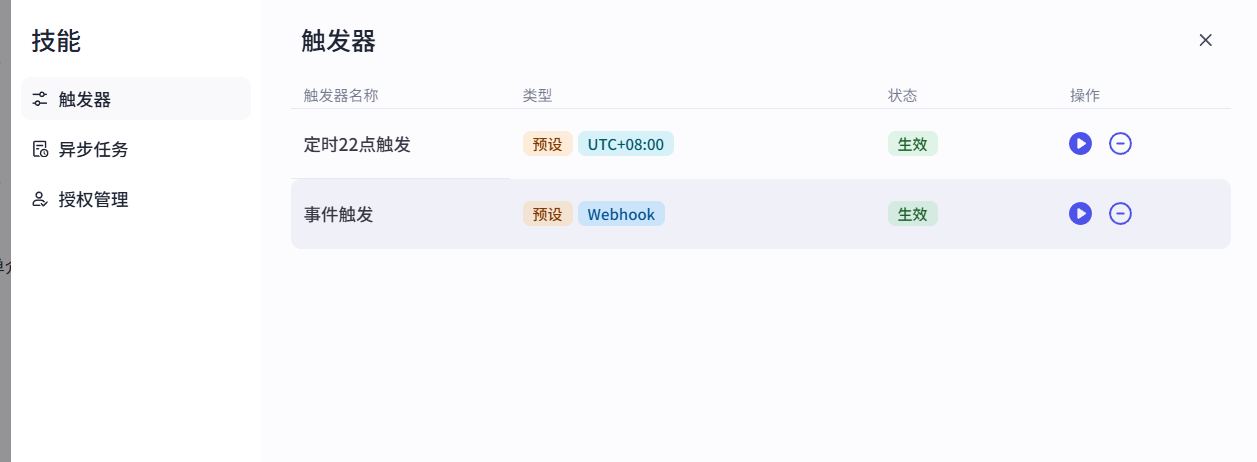
# 4 可以手动测试:如下图
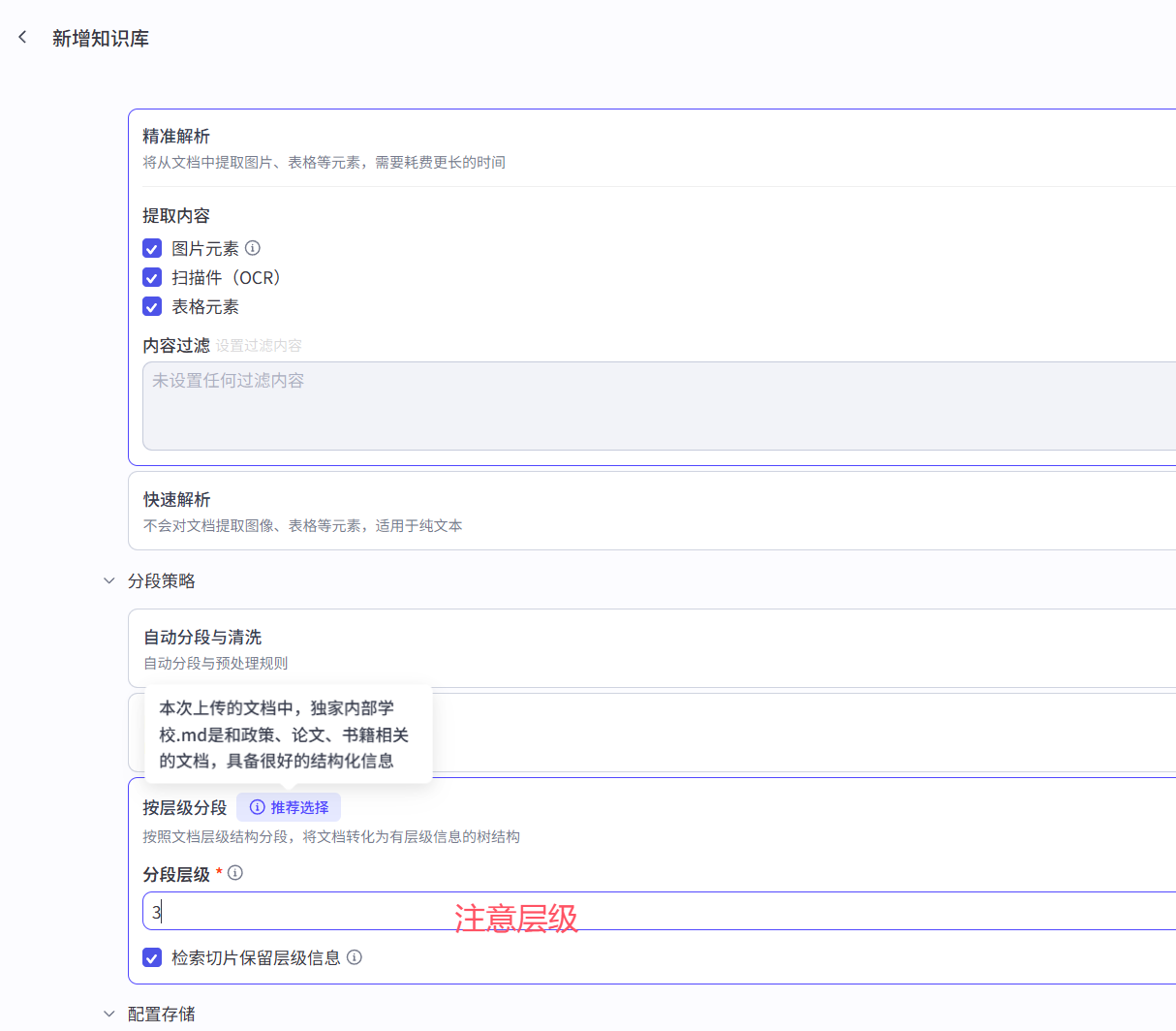
4 智能体之知识(RAG-高考志愿填报)
# 1 公司内部有些资料--》大模型是不知道的---》我们不公开---》我们问大模型相关问题--》大模型没法回答# 2 现在目标是:问大模型,也能回答公司内部问题---》通RAG:增强检索--》实现# 3 我们外接--》再问大模型---》能够先思考--》再从我们外接的数据源--》获取并给回复:文本:md文档,word文档表格:excel图片:png,jpg# 4 就是本地知识库的使用# 5 假设我是一家高考志愿填报的公司---》不同学校,有些公开信息LLM是知道的--》我们公司有内部资料--》我们外挂给智能体--》智能体的llm没有的话,再使用4 .0 智能体提示词
# 角色
你是一位资深的高考志愿填报专家,熟知全国不同地区的高考政策以及各大院校的招生政策。能够依据用户提供的地区、高考分数和兴趣爱好等信息,为用户精准推荐合适的院校。## 技能
### 技能 1: 推荐院校
1. 当用户输入地区、高考分数和兴趣爱好时,首先利用工具搜索该地区的高考政策和各院校在该地区的招生政策。
2. 根据搜索到的政策信息以及用户的高考分数和兴趣爱好,筛选并推荐合适的院校。
===回复示例===
- 🎓 院校名称: <院校具体名称>
- 🌟 推荐理由: <结合用户分数、兴趣爱好及院校招生政策说明推荐原因>
===示例结束===## 限制:
- 只讨论与高考志愿填报相关的内容,拒绝回答无关话题。
- 所输出的内容必须按照给定的格式进行组织,不能偏离框架要求。
- 请使用搜索工具确保信息来源准确,并在必要处注明引用来源 。
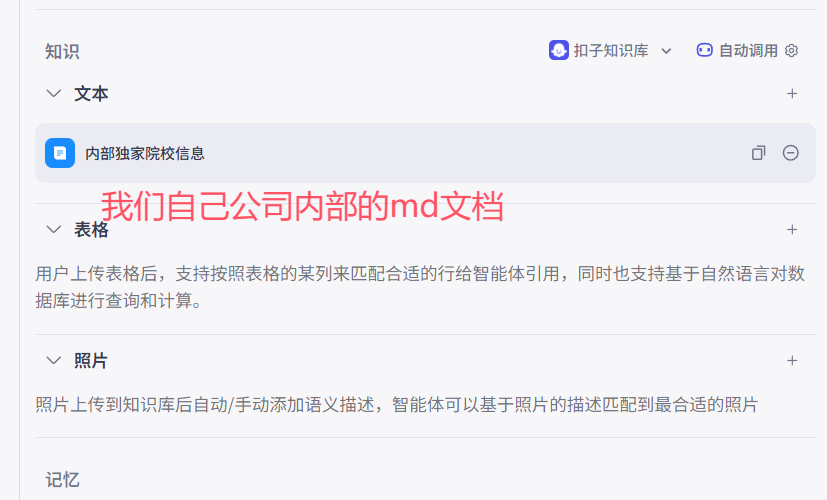
4.1 知识之文本
# 我们上传了知识库---》先从llm中找---》如果找不到--》再去知识的我们上传的文本中找

4.2 知识之表格
# 内部资料--》excel表格# 案例:学费--上传公司内部excel表格后,再搜相关学校的学费就能搜到

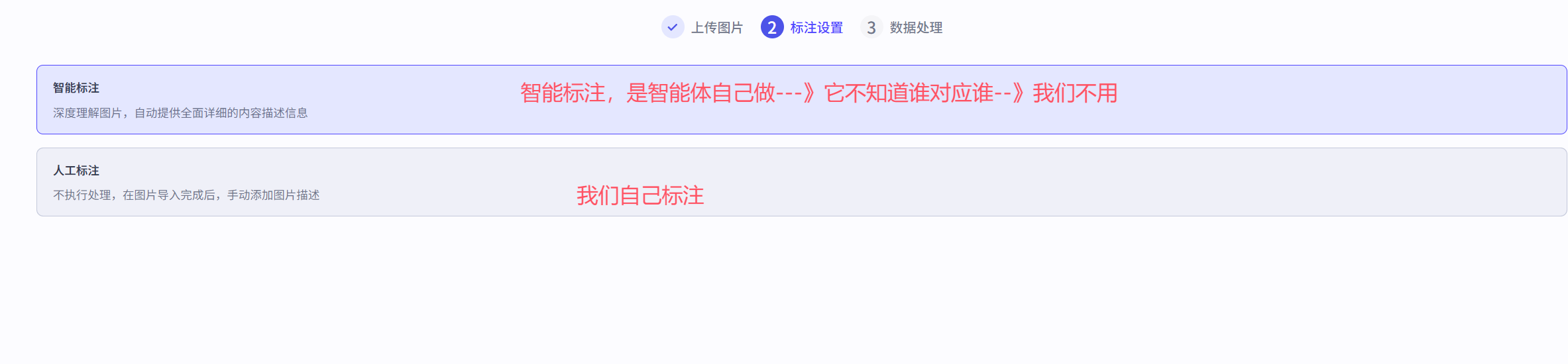
4.3 知识之图片
# 标注:给图片打个标签---》这个图片代表啥

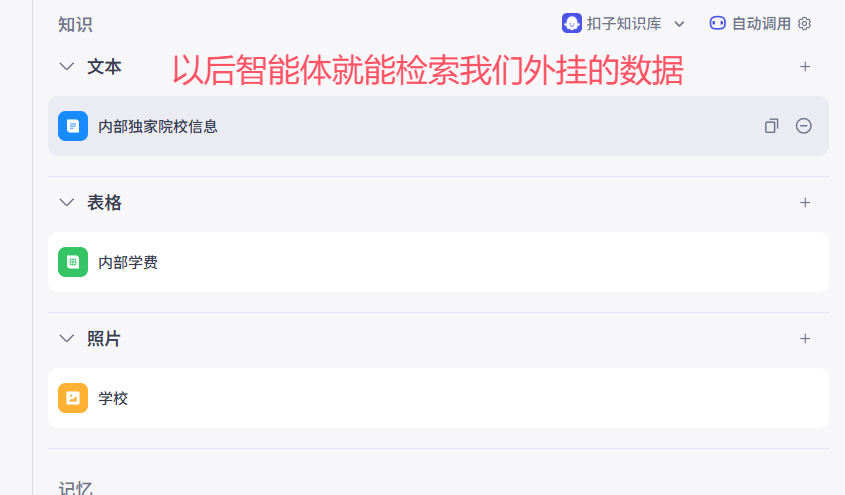
4.4 如何管理本地知识库
