模型复杂程度
一、常见衡量指标
- 参数数量(Number of Parameters)
- 模型包含的可学习参数越多,复杂度越高。
- 例如:
- 线性回归:参数个数 = 特征维数 + 1
- 深度神经网络:每层权重矩阵大小 × 层数
- 例子:ResNet-18(约1100万参数) vs. GPT-3(1750亿参数)
- 模型容量(Model Capacity)
- 表示模型拟合各种函数的能力。
- 高容量模型可以逼近更复杂的数据分布,但也更容易过拟合。
- VC维(Vapnik–Chervonenkis Dimension)
- 理论上衡量模型的表达能力:能将多少样本点任意划分。
- VC维越高,模型越复杂。
- 网络深度与宽度(Depth & Width)
- 深度:层数增加 → 表达更复杂的特征组合。
- 宽度:每层神经元数量多 → 捕获更多模式信息。
- 正则化强度(Regularization Strength)
- L1/L2正则、Dropout、权重衰减等会有效降低模型复杂度。
二、复杂度与性能的关系
| 复杂度 | 优点 | 缺点 |
|---|---|---|
| 低(简单模型) | 易解释、训练快、泛化强 | 可能欠拟合 |
| 适中 | 拟合能力强、泛化良好 | 需要调参 |
| 高(复杂模型) | 强拟合能力、可逼近复杂函数 | 易过拟合、计算量大 |
三、调控模型复杂度的方法
- 减少/增加网络层数或神经元数
- 使用正则化(L1、L2、Dropout、早停等)
- 特征选择或降维(PCA、特征重要性筛选)
- 模型剪枝或量化(减少冗余参数)
- 交叉验证确定合适复杂度
四、形象理解
可以把模型复杂度比作“画画的笔”:
- 一支简单的笔(线性模型)只能画直线;
- 一套彩笔(多层神经网络)可以画出复杂图案;
- 但笔太多又乱用,就容易“涂花”(过拟合)。
训练过程
定义模型
根据观察,宝可梦比数码宝贝的线条要简单,所有将图片转换成线条,根据线条的白色像素多少来判断

Loss 函数
这次为什么选择 Error rate ,因为简单直观,正确输出 0 ,错误输出 1

$h^{all}$ 在Data(all)上一定小于 $h^{train}$ ,因为 all 是所有数据训练出来的,train 只是抽出来的部分数据,但是在其他数据集上不一定比 $h^{train}$小
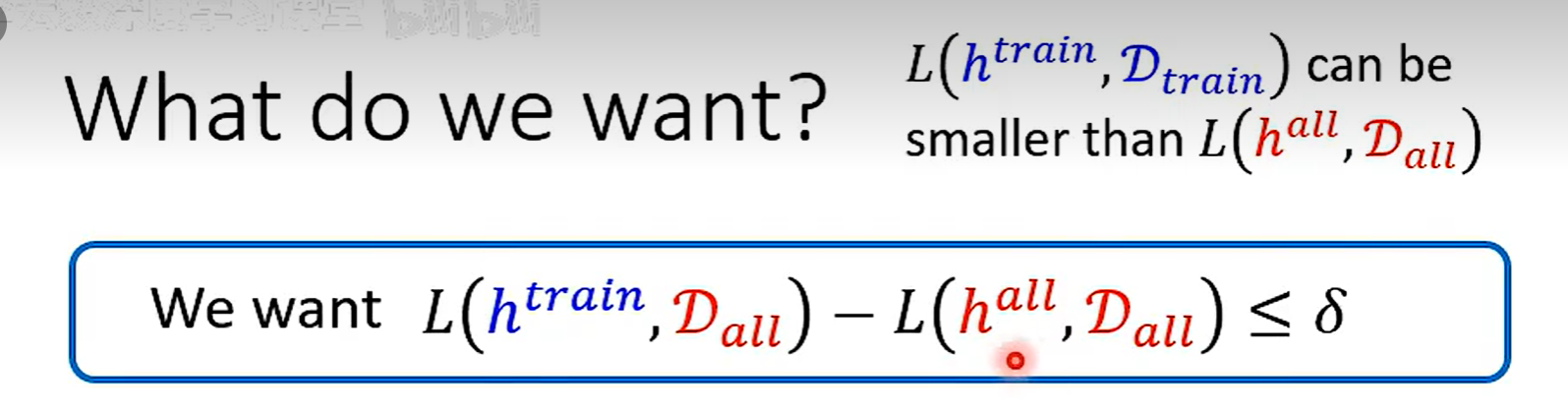
找到一个 h 在Data(train) 和Data(all)上的Loss差不多,两个就会比较接近

训练资料好坏
这个理论不常用,因为这个是个上限,一般 H 都会很大,算出来的一般都会大于 1
N 训练集数
H 参数能选择的个数
$\epsilon$ 自己定义的参数

|H| 越小,N 越大,训练集越好
但是H很小的时候,All 里面不一定有很好的 h 了,虽然痕接近,但是都很差
N一般收集到的资料有限
