参考视频
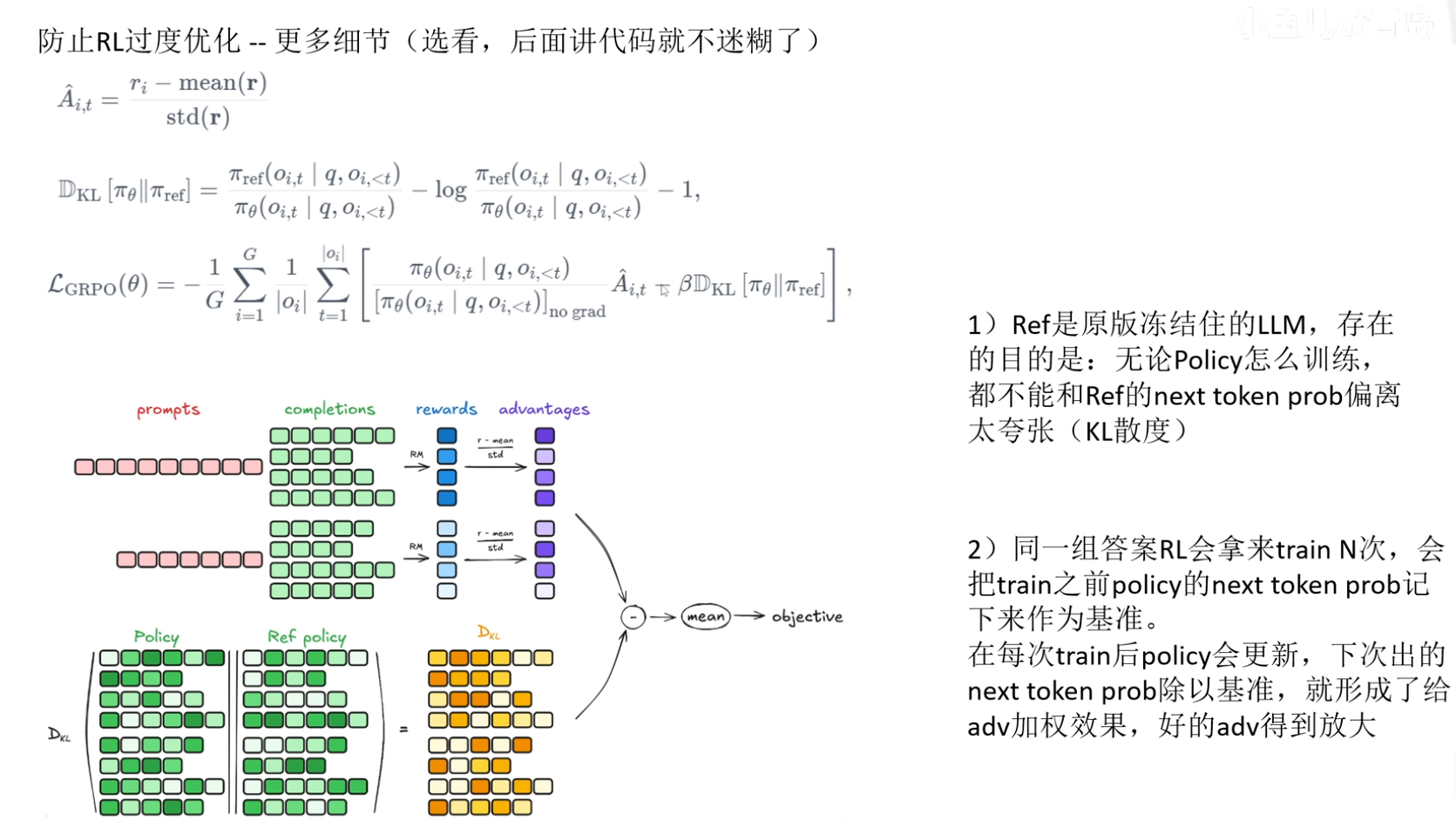
GRPO 指的是 Group Relative Policy Optimization(组相对策略优化),最早由 DeepSeek 在 DeepSeekMath 里提出,用来做 LLM 的 RL(尤其是推理/Chain-of-Thought 任务)的高效替代 PPO 的算法。
PPO 需要一个价值网络/critic来算优势函数(advantage)。在 LLM 里这个东西不好学、还很占显存。GRPO 直接绕开价值网络:同一个提示(prompt)下,采样出一小组(group)答案,用组内相对名次当作优势——谁比“组平均”好就往谁的方向推,谁比“组平均”差就降权。这既利用了偏好/奖励的“相对性”,也节省了大半内存。
采样
给大模型问题Query,让大模型回答,得到Completion,这个过程叫做采样。
关于回答的多样性
问1+1?
,第一种“2”,第二种“等于2”. 这可以通过top K实现,并非每次预测都选择概率最大的token,而是概率前K个可以随机选。